中国人工智能学会通讯——从语料库中习得的语义包含类人的偏见

摘要:机器学习是一种通过发现现有数据的模式来获得人工智能的方法。在这篇文章中,我们证明将机器学习应用于普通人类语言会产生类人的语义偏见。我们采用被广泛使用的纯统计机器学习模型,利用内隐联想测试的测量方式,复现了一系列已知的偏见,这些统计机器学习模型都是从一个标准的万维网语料库中训练得到的。研究结果表明,文本语料库包含可重现且准确的偏见印记,这些印记包括对昆虫或者鲜花的中立观点,或者对种族或性别的有问题的态度,甚至是对职业或姓名的性别分布现状的简单验证。我们的方法将有助于识别和处理文化乃至技术中存在的偏见。
我们发现,标准的机器学习可以从反映人类日常文化的文本数据中学习到刻板偏见。从文本语料库中获取包括文化刻板印象和经验关联在内的语义的想法,虽然在语料库语言学领域已为人们所了解[1-2],但是我们的发现从三个方面补充了这一想法。首先,我们用词向量方法[3]——一个强大的工具来提取文本语料库中获取的语义关联;这种方法实质上放大了原始统计信息中的信号。其次,我们对已有文献记载的人类偏见的复现可能会产生研究人类偏见态度和行为的工具和见解。最后,由于我们是在已经训练好的机器学习组件(主要是GloVe词向量)上进行实验,我们发现,文化的刻板印象已经在人工智能技术领域广泛传播。
在展示我们的研究结果之前,首先讨论文章涉及的关键术语并描述我们使用的工具。术语因学科而异;这些定义是为了文章能够清晰的表述。在人工智能和机器学习领域,偏差(bias)一般指的是先验信息,这种先验信息是智能活动的必要前提[4]。然而,如果这些信息来源于引起有害行为的人类文化,那么这种偏差将会是有问题的。这篇文章中,我们把这种偏差叫做“刻板印象(stereotyped)”,基于这种偏差做出的行为称为“偏见行为(prejudiced)”。
内隐联想测验(IAT)是人们定量检测和记录人类偏见的主要来源。IAT表明,当对象被要求匹配两个他们认为相似的概念时,相较于匹配两个他们认为不同的概念,在反应时间上有很大的差异。我们提出了我们的第一种方法——词向量联想测验(WEAT),它是一种类似于I AT的统计测试,我们将其应用到AI领域里广泛使用的词的语义表示上,也就是词向量。基于词的上下文,词向量把每个词表示为向量空间中的一个约300维的向量。我们将一对向量之间的距离(更准确的表述是它们之间的余弦相似度——一种测量关联性的方法)类比为IAT中的反应时间。WEAT方法对I AT中测试过的一系列单词的词向量进行了比较。我们将在下面对WEAT方法作更细节的描述。
与本文最密切相关的是同时期Bolukbasi等人[6]的工作,他们提出了一种给词向量“消除偏见”的方法。我们的工作是与之相辅相成的,因为我们专注的是严格论证词向量中存在的类人偏见。而且,我们的方法不需要用代数公式去表示偏见,而对所有类型的偏见都有一个代数表示也是不可能的。此外,我们还研究了当代社会的刻板印象与经验数据之间的关系。
使用上述语义关联的度量方法,已经能够复现我们测试的每一种刻板印象。我们选择了研究一般性社会态度的IAT测试,而不是针对一些子群体进行研究,并且这些测试的目标词和属性词(非图像)列表都是可以得到的。测试的结果总结在表1中。
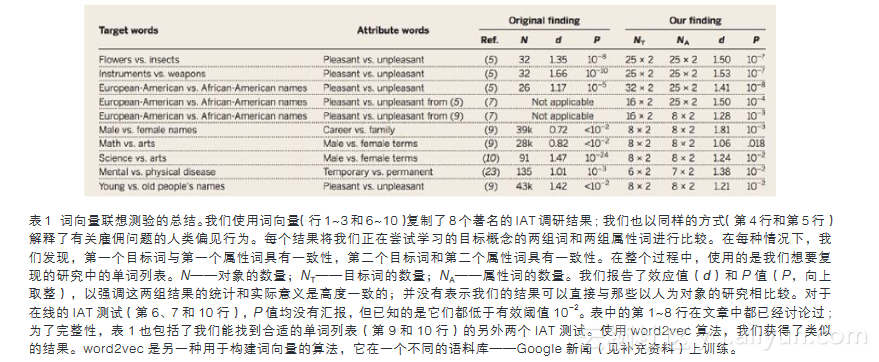
Greenwald等人通过对他们认为在人类中普遍存在而没有引起社会关注的偏见的研究,引入和验证了IAT[5]。我们为了同样的目的,复现了这些无害的结果。具体而言,他们根据人们对四对组合(鲜花+令人愉快的、昆虫+令人不快的、鲜花+令人不快的和昆虫+令人愉快的)的反应延迟情况,证明花明显比昆虫更令人感觉愉快。Greenwald等人以Cohen’s d来衡量效应值。Cohen’s d计算方式为两个延迟时间(毫秒记)对数的差值除以标准差。一般d的小、中、大值分别为0.2、0.5和0.8。他们进行的比较鲜花和昆虫的IAT测试有32名参与者,产生了值为1.35(P<10-8)的效应值。我们采用我们的方法也进行了测试,观察到同样的预期关联,效应值大小为1.50(P<10-7)。同样,我们也复现了Greenwald等人的发现[5],证明乐器明显比武器更令人愉快(见表1)。
值得注意的是,这些词向量之所以“了解”鲜花、昆虫,乐器和武器的属性,并不是根据对世界的直接体验得到的,而是根据词与邻近词的共现统计学习得到的隐含信息。
接下来,我们使用相同的技术来证明机器学习像其他事物一样容易吸收刻板印象。Greenwald等人[5]发现仅仅通过姓名就可以发现种族的极端影响。他们发现,与一系列非裔美国人姓名相比,人们更容易把欧裔美国人姓名与令人愉快的词语联系起来。
在复现这一结果时,因为一些早期的非裔美国人姓名出现频率不够高,并没有出现在语料库中,我们被迫对测试样例作了微小调整。我们随机删除了相同数量的欧裔美国人的姓名,以平衡这两种姓名中样例的数量。我们在关键字列表中列出了省略和删除的样例(见补充材料)。
在另一个广受瞩目的研究中,Bertrand和Mullainathan[7]给1 300份招聘广告发出了近5 000份简历,这些简历除了候选者的姓名不同,其他并无差别。他们发现,欧裔美国候选者获得面试机会的概率比非裔美国候选者提高了50%。在后续的研究中,他们认为隐含偏见有助于解释这些影响[8]。
我们使用词向量为这个假设提供了额外的佐证。我们测试了他们研究中用到的姓名,以获得它们和愉悦程度的关联。和之前一样,我们需要删除一些低频的姓名。我们使用“令人愉快/令人不快”两组不同的样例证实了这种关联:这些样例来源于最初的IAT论文和后发表的一个较短的修订版本[9]。
谈到性别偏见,我们复现了一个发现:与男性姓名相比,女性姓名相较于与职业词汇的关联,更多地与家庭词汇关联在一起。这个IAT测验是在线进行的,因此拥有一个更大的主题池,但是有更少的关键词。不过即使只有这些缩减的关键词集,我们仍然复现了IAT的结果。我们还复制了一个在线的IAT测试,发现男性词汇与数学词汇关联更强,而女性词汇(例如“女人”和“女孩”)与艺术词汇关联更强[9]。最后,我们还复现了一项实验室研究,表明女性词汇与艺术词汇关联更强,而与科学词汇关联较弱[10]。
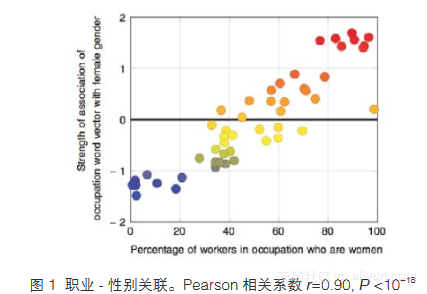
在确定了IAT记载的刻板印象也存在于词向量中之后,我们进而研究相同的词向量如何与性别分布的真实数据相关联。有研究者发现,隐含的性别-职业偏见与职业参与中的性别差距有关;然而,性别和职业之间的关系是复杂的,它们可能是相辅相成的[11]。为了更好地揭示这种关系,我们研究了职业词汇与性别的关联和劳动力参与数据之间的相互关系。图1的x坐标轴的数据来源于美国劳工统计局(https://www.bls. gov/cps/cpsaat11.htm)发布的2015年数据,该数据提供了职业的类别和在这些类别下具有确定工作的女性所占百分比的相关信息。通过应用我们设计的第二种方法——词向量事实联想测试(WEFAT),我们发现GloVe词向量与2015年美国的50个职业中女性所占百分比强相关。
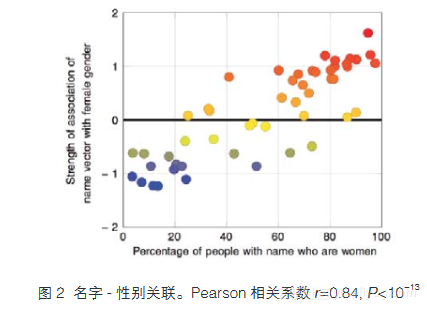
同样,我们研究了性别与中性姓名的真实关联,中性姓名这里指的是两性都可以使用的姓名。我们能够找到的与这个研究相关的最新信息是1990年人口普查时的姓名和性别统计数据。也许是因为我们的姓名数据来源于较早的时期,姓名和性别的关联弱于2015年的职业与性别的统计关联,但仍然十分显著。图2中,x轴数据来自1990年美国人口普查的数据(https://www.census.gov/main/www/cen1990.html),y轴的数据与前一个测试相同。
词向量是将单词表示为向量空间中的点[12]。对于本文中的所有结果,我们使用当前效果最好的GloVe词向量,其中两个词向量的相似度大体上与这两个词在文本中共现的词的相似程度相关[13]。以GloVe为代表的词向量算法,通过降维来显著增强简单共现概率中发现的信号。在与本文实验相仿的早期实验中(基于自由关联而不是隐式关联),原始的共现概率方法的结果非常差[14-15]。
我们使用作者预训练好的GloVe词向量,不再自己训练词向量。这样做能够确保公正性,简化了重现我们结果的过程,也让我们能够复现词向量在机器学习真实应用中的效果。我们使用了四种语料库中最大的语料库,即从互联网的大规模爬取中获得的“Common Crawl”语料库,其中包含8 400亿个词次(也就是词)。这个语料库中的词是区分大小写的,最终包含220万个不同的词项。每个词项对应一个300维的向量,这个向量由此词在大小为10的窗口中与其他词的共现次数学习得到。
在补充材料中,我们使用另一个语料库和对应词向量,也展示了一个大致相似的结果。
下面我们将描述WEAT方法的细节部分。借鉴IAT文献里的术语,考虑两组目标词(如程序员、工程师、科学家;护士、老师、图书管理员)和两组属性词(如男人、男性;女人、女性)。这里我们设置零假设(null hypothesis):两组目标词之间与两组属性词的相对相似度没有差异。置换测试通过计算属性词的随机排列产生观测的(或比之更大的)样本均值差的概率来计算零假设的(不)可能性。

这是对两个分布(目标词和属性词之间的关联)分离程度的归一化度量。这里我们再次说明,这里的P值和效应值的意义与IAT中的意义不同,因为在我们的实验中“对象”是词语而不是人。
WEFAT方法使我们能够进一步研究词向量,如何捕获隐含在文本语料库中的关于世界的经验信息。这里我们考虑一组目标概念,例如职业,以及与每个概念相关的且可用实值度量的真实世界属性,例如相应职业中女性所占的百分比。我们想研究与一个概念相对应的向量是否隐含了这些属性的知识,即给定一个向量,是否有一种算法可以提取或预测其中的属性。原则上,我们可以使用任何算法,但在这篇文章中,我们选择仿照WEAT,对目标概念与某些属性单词的关联进行测试。
形式上,现在考虑一组目标词W和两组属性词A、B。每个单词w∈W有一个属性pw与之相关联。与每个词向量相关联的统计量是该词与对应属性的归一化关联分数,如下所示:

下面我们详细阐述这个成果的深层含义。在心理学领域,我们通过一个不同的设定来复现IAT测试的结果,增加了I AT测试的可信度。此外,我们的方法可能会产生一种有效的途径,来探索以前未知的隐式关联。研究人员在推测隐性关联时,可以在将人类当作被测对象之前,首先在合适的语料库上使用WEAT方法进行测试。类似地,给定各个群体创造的大型语料库,我们的方法可以用来快速发现不同群体之间的偏见差异。如果WEAT通过测试和复现得到证实,它也可以为我们提供探索无法被测试的隐性关联的途径,例如探索历史上的人群的隐式关联。
我们已经证明,词向量不仅隐含刻板印象,而且蕴含其他知识,诸如鲜花令人产生发自内心的愉悦感,或者职业的性别分布情况。这些结果支持了语言学中的分布式假设,即词汇的统计语境捕捉到了我们表达的语义[16]。我们的研究也将有助于Sapir-Whorf假说[17]的讨论,因为我们的工作表明,行为可以被隐含在语言使用过程中的文化历史所驱动,而这些历史在不同语言之间有明显的不同。
需要强调的是,我们复现了每一个我们测试的I AT记录的关联结果。我们的研究结果的数量、多样性和实际意义,提高了所有隐含的人类偏见都被反映在语言的统计特性中的可能性。这一假设需要进一步研究来检验,同时,将语言与其他模态数据(特别是视觉数据)进行比较,以观察它们是否具有相似的强大解释力,也需要进一步的研究验证。
我们的研究结果还提出了一个零假设来解释人类偏见行为的起源,即语言隐含地传递群体内/群体外的身份信息。也就是说,在为个人作出有偏见的决定提供一个明确或惯常的解释之前,我们必须确定这不是一个简单的由语言吸收的统计学规律再现产生的结果。同样,在为刻板印象如何实现代际传递或群体扩散设计复杂的模型之前,我们必须检查,仅通过语言学习是否足以解释(一些)观察到的偏见的传播现象。
我们的工作对人工智能和机器学习也会有影响,因为这些技术可能会延续文化中的刻板印象[18]。我们的研究结果表明,如果我们建立一个智能系统,充分学习语言的属性以便能够理解和使用它,在这个过程中,该智能系统也将获得历史文化的关联,而其中一些可能是令人反感的。一些流行的在线翻译系统已经包含了我们研究的一些偏见(见补充材料)。随着人工智能在我们的社会中被赋予更多的代理职责,这个问题可能会引起更多的关注。如果机器学习技术被用到简历筛选过程中,那么它将会引入文化的刻板印象,可能会随之导致带有偏见的结果。对此,我们建议明确指明这些技术导致的哪些行为是可以接受的行为。在研究机器学习中的公平的新兴领域中,有类似的方法,它在做决定时规定和执行没有偏见的数学公式[19-20]。另一种方法存在于模块化的人工智能系统,如认知系统中。在这种系统中,统计规律的隐性学习可以被划分出来,并通过适当行为规则进行显式指导[21-22]。当然,在将无监督机器学习方法构建的模块引入决策系统时,我们需要谨慎对待。
( 原文:Caliskan, A., Bryson, J.J. and Narayanan, A., 2017. Semantics derived automatically from language corpora contain human-like biases. Science, 356(6334), pp.183-186. Vancouver, 2017.)
参考文献略

中国人工智能学会通讯——从语料库中习得的语义包含类人的偏见相关推荐
- 中国人工智能学会通讯——神经环路研究最新进展及对类脑计算的启示 1.复杂科学...
刚才讲到深度学习,脑环路和深度学习可能有一些相似性,但有些是不同的地方.我的演讲有两部分内容,一方面我一直强调复杂科学对整个领域的影响:另外和它相关的话题就是大脑的连接结构. 1.复杂科学 我们是生活 ...
- 中国人工智能学会通讯——基于视频的行为识别技术 1.7 视频的深度分段网络...
1.7 视频的深度分段网络 下面介绍另外一个工作,是我们和 CUHK.ETH 联合开展的,这个工作考 虑视频的分段特性,我们知道视频可以分 成很多段,每一段有不同的内容.我们 开发了一个深度模型,对不 ...
- 中国人工智能学会通讯——智能系统测评:挑战和机遇
上面的四个报告从四个维度讨论了智能系统测评的不同方面--产业.基础.基础和伦理.我受中国人工智能学会的委托,组织这次分论坛,为此对这个领域做了一些调研和思考,从现状和挑战这两个方面做了一些初步总结. ...
- 中国人工智能学会通讯——无智能,不驾驶——面向未来的智能驾驶时代 ( 下 )...
到目前为止似乎比较完美,而实际还 存在着一些问题.我们现在看到很多道 路上面,交通标志牌它的分布非常稀疏, 可能每过一两公里才能够检测出来一个 交通标志牌,因为毕竟这个深度学习算 法是目前最完美的,它 ...
- 中国人工智能学会通讯——深蓝、沃森与AlphaGo
在 2016 年 3 月 份,正当李 世石与AlphaGo 进行人机大战的时候,我曾经写过 一 篇< 人 工 智 能 的 里 程 碑: 从 深 蓝 到AlphaGo>,自从 1997 年深 ...
- 《中国人工智能学会通讯》——3.15 社交媒体中的谣言识别研究及其发展趋势...
3.15 社交媒体中的谣言识别研究及其发展趋势 随着计算机和互联网技术的不断发展,社会已经进入了信息互联和人的互联高度融合的时代,人们可以在网络上自由地发布.传播和获取信息:人与人之间的联系也更加紧密 ...
- 《中国人工智能学会通讯》——12.33 众包知识库补全方法概览
12.33 众包知识库补全方法概览 本章介绍众包知识库补全的方法概览,如图 1所示.其基本思想包含两个部分,其一,利用多种数据源,如现有的多个知识库.Web 结构化数据等,提取知识数据,并将不同数据源 ...
- 中国人工智能学会通讯——沿着Marr的道路前进——视觉计算的前世今生
眼睛是动物和人类感受世界的关键器官之一.通常认为,人类获取的外界信息中视觉要占到70%~80%的部分:同时与视觉相关的部分占据人类大脑皮层功能分区里最大的一块面积.能充分理解眼睛和与之相关的视觉处理机 ...
- 《中国人工智能学会通讯》——1.23 国际评测
1.23 国际评测 自动问答的研究历史可以上溯到 50 时代,图灵首次提出用人机对话来检验机器智能.在 60 年代问答技术主要服务于数据库的自然语言界面,70 年代则聚焦于交互式对话系统,70 年代末 ...
最新文章
- 打开python的步骤_python RE 常见的打开方法
- 大数据催生决策新模式 未来将改变更多
- Office365-----Skype for business
- iOS开发--线程通信
- Vue axios发送Http请求
- Python自动化测试框架有哪些?
- artTemplate基本用法
- 4G换5G关口,智能手机如何抢回“失去的一个月”
- MacOS下SVN的使用
- 基于深度学习的咖啡叶病害识别和严重程度评估(源代码+数据集)
- Android的JNI【实战教程】3⃣️--Java调用C代码
- aliez歌词_请问aLiez完整版中文 +罗马音歌词
- vue 富文本编辑器,插件
- 蓝牙无线自制串口模块连接穿越机配置工具
- 基于STM32智能RFID刷卡汽车位锁控制系统设计
- UnityHub 无需登录 傻瓜教程 一键搞定
- asp.ne服务器代码显示http://l.longtailvideo.com/download/5/9/logo.png不可用,在Window Server2008 服务器上无法播放MP4媒体问题
- 数字通信中为什么需要时钟线
- Tyvj1474 打鼹鼠
- CEO、COO、CFO、CTO是什么意思?