中国人工智能学会通讯——无智能,不驾驶——面向未来的智能驾驶时代 ( 下 )...

到目前为止似乎比较完美,而实际还 存在着一些问题。我们现在看到很多道 路上面,交通标志牌它的分布非常稀疏, 可能每过一两公里才能够检测出来一个 交通标志牌,因为毕竟这个深度学习算 法是目前最完美的,它有时候还会错过 一个交通标志牌,这时候怎么办呢?我 们会发现在路面上也有非常明显的视觉 特征,我只要把路面的这些视觉特征识 别出来进行匹配,其实是有连续的绝对 的视觉参考的。所以我们做的办法是, 把这个路面粘贴起来。这个粘贴的方法 很简单,跟我们手机拍场景图片一样, 我们慢慢移动的时候可以把这个场景粘 贴出来,粘贴出来以后就变成这么一条 一条连贯的路面,然后在驾驶的时候, 我实时看到的路面跟地图做一次匹配, 这样就能够比较准确知道我在什么样的 地方。这个算法本身可以做到鲁棒。
所以从绝对定位到相对定位,再加视觉参考点,从视觉参考点再到外面的交通标 志牌,再到路面的视觉特征参考点,通过 一系列方法,我们使得这么一个定位做的 非常棒。当然,有时候在车库里面,我们 可能又要寻找其他的方法,这里其实用的 就是一个 Video Slam 的技术。
这些都是定位的方法,未来还有另外一 个帮助,就是高精地图。地图一般是用来 导航的,但它也能够帮助我们做定位,它 能够使得定位更加准确。此外,它还有两 个功能,第一个是它给我们提供了一些预 见性,比如说我们看到这个地方,知道 500 米以后要上匝道,或者它能够提前让我们 知道这里面有一个坡,这时候能够使得我 们的驾驶规划更好;另外一个就是提供了 鲁棒性,如果我们定位不准的话,地图能 够帮助纠正。
现在高精度地图有不同的种类,比如 像谷歌这样的高精度地图,是基于激光雷 达点云的,它是非常大的高精度地图,1 公 里差不多一两个 GB 左右。还有像地图厂商 做的高精度地图,它就可能不一定有点云, 它只有这些已经抽象出来的几何的这样一 些符号,这些几何符号已经足够帮助我们 通过其他的手段进行定位了。这些几何符 号的信息也是非常丰富的,想象一下,比 如说路肩有多高,它也会标志出来;比如 说这个交通灯是在空间的什么位置,红、黄、 绿它是竖着的还是横着的,它都会为我们 标出来,这样能够弥补现在我们汽车人工 智能的不足。
有了这些矢量的几何表示以后,我们就 可以进行匹配了。这只是显示一种匹配的做 法,即把这些质量的地图重新渲染出来,变 成图片,原来是矢量的,它只有一些箭头线, 然后把它重新渲染出来;渲染出来变成图片 以后,再进行图片之间的匹配,它就能够做 的更好,这就是地图和定位的问题。
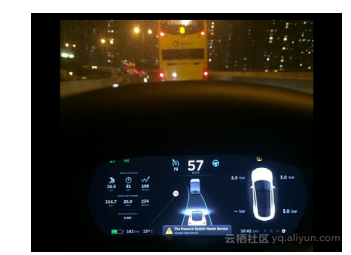
第三,对人工智能要求更高了,从感 知向认知要进行跨越。认知的第一阶段, 我们提到过,只要去检测那些不能撞的东 西,或者检测那些该识别的东西,这个在 计算机视觉里面它的说法叫做 detection by recognition,我们必须先 recognize,这样 detect 出来的东西它的视觉特征在你的数据 库里必须要存在的。然而这意味着就是一 个边界的问题,因为数据库毕竟是有限的, 万一出现了那些在我们的数据库里并不存 在,但同时又不能撞的东西,很可能就识 别不出来了。比如我们的车开到了印度的 街上,印度的街上有牛在走,牛这个特征 可能从来不在数据库里,就无法识别出来, 很可能就撞上去了。所以,它需要更好地 去理解这个世界,当然理解这个世界可能 也是分不同的阶段。最简单的,这是特斯 拉最新版的 Autopilot 里面的功能,在它的 仪表盘上大家可以看到,它能够把前面的 一辆车用图标显示出来,但这次它不但显 示出来前边有一辆车,而且知道这是什么 样的车,比如说这是一辆客车,还是一辆 摩托车,还是一列载重的货车。其实自动 驾驶的时候,我们要有一个策略是说离大 货车远一点,所以这已经代表比刚才的第 一阶段进一步了,它不仅仅是检测出来, 而且能够检测出来是什么样的东西,我们 是不是需要离它远一点。另外,车辆检测 的下一步就会变得,我不但能够检测出来 有车,而且这个车的朝向是什么样子的, 它占用的三维的几何空间是怎样的,这个 也能够检测出来。
再下一步就涉及到语义分割。做计算 机视觉的话都知道,我不但有 classification detection、object classification detection, 还有 semantic segmentation。语义分割我们 知道,把整个画面所有的像素都会赋予一 个颜色,这个颜色就是一个标签,代表它 是一种什么样的东西,这是用一种算法叫 做 segnet,也是深度学习的一种算法,它 能够近乎实时地把每一帧的每个点给它分 割出来,比如紫色代表的是路面、橙色代 表的是车道线、深蓝色色代表车、蓝色代 表人行道等等。这种分割其实就比原来的 detection by recognition 更加鲁棒,因为它 基本上对于这个世界场景中的每一块区域 都做了一个判断。而且这个分割对车道线 检测也很有用,前面的车道线检测是通过 最简单的图像处理就是边缘检测来的,而 这个语义分割出来的车道线可以更准确。
但是对于语义分割,如果说路面上有 几辆车,它都是用同一种颜色去标识,不 区分到底是哪辆车。再下一步叫做 instance segmentation,做实际分割的时候,每辆 车都可以把它的边界圈出来,用不同的 颜色标出,这就是从语义分割到 instance segmentation。之前的语义分割中整个路面 都是用紫色标识出来的,但是有时候这是 不够的,比如说双向路,双向路是不能在 整个路面上行驶,只能够在这个方向上的 那一半的路面上行驶,所以我们要进一步 去理解这个道路的这些标识的语义,能够 把真正行驶的区域标识出来。
还有在很多场景下,车道线并不清晰, 或者车道线被大雪覆盖了,或者没有车道 线、没有路肩,这时候深度学习就非常有用。 因为它并不是明确的特征,是通过大量的 概率计算出来的一个特征,它能够把这么 一个没有明确的马路边界的这么一条土路 也能够识别出来,而且有时候仅仅是识别 出来马路的这么一个几何区域还不够。
针对另一个应用,我们知道车行驶的时 候是有风噪和胎噪的,通过胎噪能够把道 路的干或者湿检测出来,这时候这种信息 对于我们下一步自动驾驶的规划和控制是 非常有用的,所以这是第一阶段。第一阶 段是说识别那些原来该识别的东西,到理 解整个世界。
第二阶段,从简单的不撞,要到更加舒 适的驾乘感受。什么叫做舒适的驾乘感受, 举个例子。在北京的三环上行驶,上路之 前在车顶上放了一枚硬币、一个打火机、 一个盒子这三样东西,然后在三环上加速、 减速、换道,行驶多公里再下来,如果这 三样东西还是稳稳地放在那边,就满足舒 适的标准。这意味着我们在做规划的时候, 它是一个多目标的优化,不仅仅安全性是 一个目标,舒适型也是一个目标。
这里面就需要很多的能力,第一个就是 对道路更加精细的感知,尤其是路面上可 能有一些东西能否检测出来。比如,路面 上有一块石板,还有一个球从前面滚过去, 这个对于我们是不是能够做到安全和舒适 的驾驶非常重要,所以我们利用双目摄像 头,要把这块石板和这个球检测出来。
另外一个,就是从确定经验到自学习。 如何理解呢?今天我们的自动驾驶系统, 前面感知这部分是用深度学习的,但到后 面规划和控制,它其实还是基于一套经验 专家系统。经验专家系统说的比较通俗一 点是什么意思?就是基于规则、基于查表 的这样一套系统,就是一个确定的经验, 它是不能学习的,这部分是前面已经学好 了的,放到这个车里面就固定了。但是近 期研制出了一套系统,叫做端到端的深度 学习。又该怎么理解呢?之前我们是每一 步做一件事情,比如说深度学习先把事件 的模型建立出来,然后再通过专家系统做 规划和决策,最后变成控制能力。而端到 端的深度学习完全不一样了,它直接视频 进去,控制命令出来,中间的步骤全部省掉, 这是深度学习的一个优势,它能够实现端 到端。但是,它里面真正有意义的地方就 是自学习,它能够在开的过程当中不断去 学习这个人的驾驶行为。
这种方法本身也并不新,我们可以看 到 2005 年深度学习的一个大师叫做 Yann Lecun,他写了一篇论文,用端到端的学习 去做避障。最近像 Nvidia,就真正地用卷 积神经网络实现了一套端到端学习的一个 方法。它用三个摄像头作为数据的输入, 同时方向盘的转动作为另外一个数据的输 入。它把这两个作为输入来训练这个深度 学习卷积神经网络的模型,最后就出来一 套这个系统,现在已经工作的非常不错。 这是一套思路,就是通过卷积神经网络这 样的一套系统,端到端做深度学习。
还有一套系统,就是基于强化学习了。 现在强化学习在决策当中使用的越来越多, 强化学习包括哪些东西呢?最后要学习出 来一个驾驶的策略,这里面包括了环境的 一些数据,还包括一个 cost function。在真 正的自动驾驶当中,它的环境包括了如距 离前车的距离、马路两边的距离等等这些 数据。而 cost 包括了一些奖励和惩罚,如 我们在单位时间里面开的里程多就给予奖 励,就是单位时间里我们开了更多的距离 就给我们奖励;如果我们压上了路肩或者 撞上了其他的车就给我们扣分,通过这样 的方法不断的学习,学出来更优的一个网 络。强化学习我们知道是不需要标注数据 的,它事实上现在被认为就是未来做自动 驾驶决策当中更好的一种手段。我这里边 加上一个深度——深度强化学习,可以不 接受简单的这些参数,我刚才说这些参数 是事先要算出来,跟其他车的距离或者是 跟两边马路的距离、速度等等,而深度强 化学习的一种典型形态直接送图片进去就 可以,通过深度的强化学习,它能够直接 地帮我们把这个策略学习出来。
还有一种做法,就是这里面加上一个 驾驶风格的学习,就是希望驾驶员开了一个月以后,能够学到他的驾驶风格。这里 面很有意思,并不是说最终我直接就是能 够通过强化学习法将驾驶的策略学出来, 而是说,我根据我现在开的这个行为反推 出来他的驾驶风格,这个驾驶风格其实就 是这么一个 cost function。所以,这里边 用到了一种方法大家可以去注意一下, 叫 做 inverse reinforcement Learning、 反 过来的 reinforcement Learning。标准的 reinforcement Learning 是,我从这边的已 经知道的 cost function 能够学出来一个具体 的驾驶行为,而反过程是指我有这个驾驶 行为我能不能学出来这个 cost function,所 以这也是一个比较有趣的场景。
关于端到端的学习做一个总结,首先它 有优点,非常简单,不学习先验的知识,而 且它训练出来的东西,虽然说不清、道不明, 但是跟我们人开车的车感比较相同。因为, 我们人开车的时候并不会去目测离前车道 有多远,只是一种感觉,所以这是它的优点。 但是缺点也有很多,第一,它需要学习大 量的高质量的训练样本,如果它的样本不 够,训练出来的模型 Demo 可以,但是没 办法去处理开放环境下各种不确定情况。 想一想,传统的方式每个阶段有多种传感 器,做相互的交叉验证,每个阶段都可以 把错误率限制在某一个阈值底下。但是端 到端的深度学习,首先只有摄像头;其次, 中间这些东西都不存在,变成了一个黑盒 子。黑盒子缺乏可解释性,缺乏可解释性 它的应用就会受到限制,而且它不太灵活。 它只是在这辆车上学出来让我这样去控制, 但是我换一辆车,它车身底层的动力学特 性就不一样,底盘的这些标定的参数不一 样,就会出现问题——我开一辆小车跟开 一辆大货车肯定是不一样的——所以它换 一辆车就必须重新学习。而且它学不到一 些隐性的知识。其实我们人在开车的时候 有大量的隐性知识,比如说,我今天停车 停在离这辆车远一点,为什么呢?可能是 因为这辆车是一个豪车,我不想碰到它; 明天我离它远一点,可能是因为这个停车 位地面上有水洼,而这些语境知识很难能 端到端的学习学出来。
第三,我们开个玩笑叫“从咏春木人 桩到少林 18 铜人”。什么意思呢?叶问在 练咏春拳的时候是跟一个静态的木人桩练, 但是真正自动驾驶在开的时候,道路上可能 有十几个如狼似虎的人类在驾驶,而且他 们开车可能有的激进、有的拘束,这时候 我们就像闯少林 18 铜人一样,需要动态地 去判断态势,去评估每一个人或者是道路 上的物体的动静,预测他的行为,合理地 获得路权。比如最简单的就是对物的判断, 如果从前车上掉下来一个桶,那么我们到 底怎么去做,是紧急制动,还是赶紧转到 另外一条车道上,这时候我们人是有判断 的。如果它是很轻的桶,我就轻轻地制动 一下就行了,撞上也无所谓;如果是一个 很重的东西,比如像一个洗衣机摔了下来, 我们这时候肯定得进行制动,所以这时候 这种判断就非常重要,现在也有用循环神 经网络来推理这样的动态物体的特性。
我们刚才说要预测每一个个体或者群 体的行为,这里面他们的行为是有高度不确定性的,这时候可能我们要从监督学习 往强化学习的方向走。因为,监督学习学 出来的东西是一个判断,它对环境是没有 影响的,而强化学习学出来的东西是对环 境有长期影响的,所以这时候需要强化学 习,或者是像马尔可夫决策过程,或者是 循环神经网络,等等。
这里举一个例子。一辆最简单的车在很 多行人的环境里面行驶,最简单的一种做 法,就是看见有人在动我就刹车,这样车就 一顿一顿的,如果说我能够对环境里面每 个行人的运行轨迹进行建模,比如说去预 测他的行动轨迹怎么样,他这个轨迹跟我 前行的轨迹是不是相交,如果不相交我就 不用去刹车了。这里就用到了一个 POMDP 这样一个算法,其实就是一个马尔可夫决 策过程。当然更复杂的情况下,我们发现 马尔可夫决策过程也不够用,因为马尔可 夫决策过程很简单,下一个状态就取决于 当前的状态和行为。但是真正上路的时候, 每个驾驶者都是不可预测的,这时候我们 需要强化学习这样的方法。比如像这样一 个场景里面,一辆车要并到一个环岛里面, 它就要选择最合适的时机去并线。该如何 选择呢?它就是要去判断,这辆车开车开 比较猛,那辆车开车开的比较拘束的。怎 么判断?一点点往前挪,看司机是加速, 还是会减速。这就是一个不可预测的过程。
其实从本质上来说,开车跟 AlphaGo 很相似。AlphaGo它看到盘面上的各种棋子, 来决定下一步该怎么走,最后的赢面有多 大。其实他通过两个网络,一个叫 Policy Network,另外一个叫 Value Network, 去判断下一步该怎么下。真正的一个开 车过程也是非常类似的,AlphaGo 用的方 法很早就存在了,比如说上世纪 80 年代 reinforcement Learning 已经开发出了 policy function 和 value function 这么一个概念, 到 Q Learning 90 年代的时候就已经变得 Policy Network 和 Value Network,只不过 那时还不是深度的神经网络,是非常浅的 网络;DeepMind 把它变成了一个深度的 Policy Network 和 Value Network。所以 这样一套方法其实在自动驾驶里面也可以 使用,只不过就是 Deep Q Network 它的计 算量是非常大的,有时候效果也并不是最 好的,所以后面大家在 Deep Reinforcement Learning 基础上又开发出像策略梯度,或者 像 GPS 等等这样的方法进一步去优化。
Yann Lecun 把强化学习分成一类,跟监 督学习和非监督学习并行的一类,而且他能 够去解决数据贫穷的问题。因为原来的监督 学习要做得好的话,数据量的需求非常大, 强化学习如果跟模拟器结合起来的话,事实 上可以去产生很多的数据,它可以通过产生 大量的数据,再通过 reward function 最后找 出来一条最好的道路,所以非常好。
最后,对智能驾驶当中的深度学习做一 个总结。首先,数据来源。我们可以通过 开放数据,比如从谷歌街景里面把路面数 据拿出来的,或者自己装载行车记录仪通 过驾驶把这些图片抽取出来,然后通过一 种众包的方法去标注。我们标注数据越多 肯定训练出来的模型越好,当然标注是有成本的,比如说标一条车道线可能要 2 元 钱,画出一个汽车的 bounding box 可能是 2 毛钱。于是慢慢地又有人开发出来一些方 法,通过机器标注,再加上去审核的方式, 能够减少标注的成本。
还有刚才提到端到端的深度学习。我们注意,首先它要装三个摄像头;同时它需要 这么一个方向盘的转角的数据要过来,而这 个转角数据要通过 Can 总线。我们需要去改 装一辆车,并不是所有的研究人员都有这样 的财力和能力去改装一辆车,所以现在也有 很多的科研单位很聪明,去改赛车的游戏。 为什么呢?赛车游戏里面既有图片,又人玩 游戏时候的控制数据,到底是左转还是右转、 加速还是减速,把这些数据放在一起的话, 也能够训练出端到端模型。现在的现状就是 有用 CNN 的,有用 RNN 的,也有深度强化 学习的,做各种各样东西的检测,做分割, 做行为的分析、预测、端到端等等。而现在 一般来说规模都不算大,比如说一二十层, 至多几千万个参数就足够了,它跟我们在广 告当中的深度学习其实规模小很多,这可以 理解。为什么呢?因为车载的计算芯片的能 力毕竟是有限的,而且现在大家往往是,在 训练端用浮点数,在识别端就用定点,因为 定点它能够更好地在一些 DSP 这些芯片上 运行。
现在我觉得可能其中的一种核心竞争力就在于,我们是不是能够采到更多的数 据;采到更多的数据以后,是不是能够有 对这么大规模数据的标注能力和训练能力。 我们刚才说,通过机器标注再加人审核的 一种方法,可能是使得标注成本能够降低 100 倍、1 000 倍,所以这个是核心竞争力了。 当然,未来深度学习的算法还有待再突破。
而深度学习不是免费的,是需要成本 的。CPU 的灵活性最大,而像 ASIC 这样 的一个固定的芯片,它的功耗低,深度学 习能力强。但是 ASIC 肯定不能用,为什么 呢?因为未来几年深度学习的算法还会有 大的变化。CPU 太慢了,GPU 有点小贵, FPGA 价格比 GPU 便宜一点。但是这个算 法把它移植上去还需要时间,一般移植一 套算法可能需要几个月,现在所说的神经 网络的加速器是非常好的,只不过它什么 时候能商业化,什么时候能符合车规也是 一个问题。所以现在我们也要考虑怎么在 现在的车规芯片上能够把这些深度学习运 行起来。当然一种方法就是用传统识别算法 来取代深度学习,比如车道线检测,不用 深度学习也能够做的很好。第二,采用多 任务的网络,一套网络能够把各种各样的 东西识别出来。第三就是用各种各样的优化 的方法,比如图像可以压缩,把分辨率降低; 比如说把 1 080 P 的降到只有 100×200;还 有做模型的压缩,模型压缩可能也从不同的 层面去压缩,我们可以把一些卷积层去掉, 也可以把这些连接去掉,可以做一些量化, 用更少的比特去代表,甚至对模型再进一步 用霍夫曼的方法进行压缩等等。还有就是通 过级联算法。什么叫做级联算法呢?就是在 不同的阶段有些算法用传统的机器学习的方 法,而在一些需要识别复杂特征的阶段用深 度学习。还有比如说,怎样能够减少 region proposal,现在里面的识别基本上都是基于region based,一般 region 可能数目非常多, 可能有 5 000 个,如果能够想办法把它降到 100 个,而且它的识别效率不降低,这些都 是能够提升性能降低成本的方法。还有就是 针对硬件做特殊的优化,等等。
最后说一下,现在还有很多没有解决的 挑战,就是人工智能与鲁棒性的关系。但是 在汽车上面这套系统非常复杂,一台奔驰的 S 级轿车,上面的代码量是一架波音 787 梦 想客机上代码量的 16 倍,非常复杂;一架 飞机的软件测试的验证成本可能占到它总成 本的一半。而且很多东西比代码更难,就是 数据,以及在这之上的随机算法和机器学习。 想象一下,未来一台车出场的时候,两台车 是一模一样的,但是在两个不同用户的手里 用了一个月,这两台车就完全不一样了,因 为大量随机的算法自学习的能力。这时候就 会出现很多问题,比如把牙刷识别成为一个 棒球棒是没有问题的,但是我们在自动驾驶 的情况下,如果识别错了就会有问题。
所以目前来说,在自动驾驶领域的深度 学习还存在着一些障碍。第一就是这套系统 并没有一个非常确定的置信度,这个对于车 厂来说它是要怀疑的,因为我们没有足够的 置信度。举个例子,在特斯拉那起车祸出来 以后,马斯克给自己辩解,他说这个车行驶 了 1.3 亿英里才死了一个人,全美国的平均 水平是 9000万英里死一个人,全世界平均 水平 6 000 万英里死一个人,所以车比人还 是行驶的安全。但是我们都知道,这个样本 量太小了,没有统计的显著性,如果第二天再死一个人,就变成 6 500 万英里,所以, 我们一定要给它一个置信度。兰德公司就通 过一套数学模型推理出来说,如果要有足够 的数据去证明自动驾驶比人行驶的安全,有 95% 的置信度的话,需要行驶 100 亿英里, 一台车不停地要行驶 500 年,所以没有一家 车厂是能够达到的。利用的方法就是通过模 拟仿真,再加上强化学习来积累里程,其实 现在谷歌一天能够在模拟器里面开几百万英 里,它就是通过这样的方法。
还有一个难题就是深度学习本身是一 个黑盒子,黑盒子是没有可解释性的,这是 十分麻烦的,无法将生命交托的。首先我 们因为数据的偏差就有可能出问题,比如 谷歌他们做的一个工作,用深度学习去识 别哑铃,它识别出来一个网络,想要进行 可视化,看看这个特征是不是有道理。而 可视化出来的一个网络后,他们发现每一 个哑铃边上都带着一条胳膊——识别出来 的哑铃都带着一条肉色的胳膊。为什么呢? 就是因为它输入的数据集都是肉色的胳膊, 所以这就是一个所谓的 train set poisoning, 或者是 bias。
还有,人们认为生成出来一些的图片, 欺骗深度学习,比如这张图片,我们人眼 看是没有任何意义的,而深度学习识别出 来是个猎豹。
所以,现在一个非常火的方向就是对抗 训练,通过生成性的对抗网络,它生成出来 一些错误的图片;然后再训练一个辨别器, 辨别器去判断到底是一个错误还是正确的招 聘,通过这样一种方法来增加其鲁棒性。
还有很多没有解决的挑战。第一个, 我们有没有可能通过一些预训练的模型, 通过迁移学习来增加它的鲁棒性,我们也 看到有这样的案例,在 ImageNet 上训练出 来的模型再在我们标注出来的这个数据集 上去训练,发现它的效果就更好。第二个, 深度学习本身只是一个概念的模型,我能 不能把它跟传统基于符号主义的人工智能 结合起来;就是把一些背景知识,把一些 逻辑推理能够结合起来,我停车为什么没 有停在那边,是因为这是一辆豪车,这些 知识是可以跟它结合起来的。第三个就是 Yann Lecun 最近说的,他认为预测学习未来 会变得非常重要;他认为,预测学习可能比 非监督学习变得更重要。比如通过对行驶的 视频进行预测来自动驾驶。前段时间有一个 黑客,他的工作就是这样的,当然他具体地 也涉及到了 Auto encoder,加上中间的生成 性对抗网络,加上循环神经网络预测。
还有一个就是自监督学习。我认为自 监督学习未来也会非常有用,尤其是我们 在现实生活当中,采集的数据当中可能是 有多种 modelity。比如我们同时看一头牛, 又听见了叫声,这样我们就可以使得两种 modelity 相互进行标注,我们不需要人去标 注,而是通过多个模态来相互进行标注。
还有就是学习开车的感觉,因为人开车 并不是精确地计算到底距离是多少,而是 一种感觉。
还有就是更低成本的检测和规划算法。 之前提到过的蝗虫的检测,只需要一个神 经元,为什么呢?因为可能在传感器这边 配合。还有就是 Fleet Learning,把它叫做 基于云的一个驾驶,它非常有用,我们想 象一下,比如摄像头看不远的话,能不能 靠前面的摄像头看到的东西帮我们看的更 远;如果是在这个时间我们看不到的话, 下一个时间另外一辆车看到了它能不能教 给我,这个是人工智能厉害的地方。为什 么呢?因为我们现在每个人一年开 1 万公 里,其学习到的东西很有限;如果 1 万台车, 每台车一年开 1 万公里,它们把学习的东 西都汇聚在一起,就是 1 亿公里了,所以 Fleet Learning 就非常重要。
(续完)
(本文根据吴甘沙在中国人工智能学会首期 “人工智能前沿讲习班”的现场报告整理)

驭势科技联合创始人兼 CEO,前英特尔中国研究院院长、首席工程师。现致力于研发最先进的自动驾驶技术, 以改变这个世界的出行。
中国人工智能学会通讯——无智能,不驾驶——面向未来的智能驾驶时代 ( 下 )...相关推荐
- 中国人工智能学会通讯——智能系统测评:挑战和机遇
上面的四个报告从四个维度讨论了智能系统测评的不同方面--产业.基础.基础和伦理.我受中国人工智能学会的委托,组织这次分论坛,为此对这个领域做了一些调研和思考,从现状和挑战这两个方面做了一些初步总结. ...
- 中国人工智能学会通讯——深蓝、沃森与AlphaGo
在 2016 年 3 月 份,正当李 世石与AlphaGo 进行人机大战的时候,我曾经写过 一 篇< 人 工 智 能 的 里 程 碑: 从 深 蓝 到AlphaGo>,自从 1997 年深 ...
- 中国人工智能学会通讯——基于视频的行为识别技术 1.7 视频的深度分段网络...
1.7 视频的深度分段网络 下面介绍另外一个工作,是我们和 CUHK.ETH 联合开展的,这个工作考 虑视频的分段特性,我们知道视频可以分 成很多段,每一段有不同的内容.我们 开发了一个深度模型,对不 ...
- 中国人工智能学会通讯——机器人组件技术在智能制造系统中的应用
摘要:随着工业4.0时代的到来,如何将传统工厂改造成为个性化.网络化.柔性生产的智能制造系统成为了当前的研究热点.本文从智能制造系统和智能机器人系统的相似性出发,构建了基于机器人组件技术的智能制造系统 ...
- 《中国人工智能学会通讯》——2.5 智能汽车人机交互与人机协同技术 的研究进展...
2.5 智能汽车人机交互与人机协同技术 的研究进展 汽车车载人机交互系统是信息化技术发展的产物,实现了人与车之间的对话功能.驾驶员可通过该系统,掌握车辆状态信息(车速.里程.当前位置.车辆保养信息等) ...
- 中国人工智能学会通讯——智力测试与智能测评的对比思考
因为我的研究方向是心理学,不是特别懂计算机的东西,像陈老师说的,我们2013年很有可能开始一个合作,后来没有进行下来,我们希望来做一下机器人的智能测试.我想跟大家说为什么我对这个研发感兴趣,刚才陈老师 ...
- 《中国人工智能学会通讯》——2.31 跨环境抽象(Abstracting Across Environments)
2.31 跨环境抽象(Abstracting Across Environments) 人工智能领域的一个长期目标是实现人工通用智能,一个单一的学习程序可以同时在完全不同的领域进行学习和行动,可以转换 ...
- 中国人工智能学会通讯——后深度学习时代的人工智能
1956 年,在美国达特茅斯学院举行的一次会议上,"人工智能"的研究领域正 式确立.60 年后的今天,人工智能的发展正进入前所未有的大好时期.我今天作的报告,将通过分析时代的特点, ...
- 《中国人工智能学会通讯》——2.2 智能汽车人机交互与人机协同技术
2.2 智能汽车人机交互与人机协同技术 作为应用最广.保有量最大的现代交通工具,汽车在极大地方便人类生活的同时也带来了大量问题,如交通事故.交通拥堵和环境污染等.每年发生的道路交通事故给人们的生命和财 ...
最新文章
- 如何在HHDI中进行数据质量探查并获取数据剖析报告
- linux shell 变量减法_第四章 shell和环境变量
- boost::serialization模块实现快速二进制归档的测试程序
- GStreamer(二)
- MenuItem创建注意事项
- 实例33:python
- vue基础之样式绑定(class,style)
- 通篇详解-CMMM智能制造能力成熟度
- python 高中信息技术 会考_2019信息技术会考真题
- 如何同时使用双网卡进行两个网络上网
- 使用vbs语言利用SecureCRT批量执行交换机命令
- Wi-Fi 无线网二维码生成 API 接口
- 用旧手机搭建服务器并实现内网穿透不需要root(本人亲测很多次最简单的一个)
- 魔兽对战平台服务器更新维护什么,官方对战平台每天5点维护是个什么梗
- 1000道最新大厂高频Java面试题,覆盖25个技术栈(多线程、JVM、高并发、spring、微服务、kafka,redis、分布式)从底层原理到架构
- ppt编辑图片进阶功能
- Playfair Crack
- 史上非常简单、快速的解决Excel导出遇到Excel导出错误
- 关于Eclipse的基本使用方法
- 介绍|三大前端框架之Vue