《中国人工智能学会通讯》——12.33 众包知识库补全方法概览
12.33 众包知识库补全方法概览
本章介绍众包知识库补全的方法概览,如图 1所示。其基本思想包含两个部分,其一,利用多种数据源,如现有的多个知识库、Web 结构化数据等,提取知识数据,并将不同数据源的知识数据融合起来,以此补全知识库;其二,在融合的过程中有效地利用众包,通过众包模型细化出具体可供众包完成的任务,利用众包优化算法进行质量和成本的控制,以选择出最优的任务发布到众包平台,如美国亚马逊公司的 Mechanical Turk ( 简称 MTurk) 1 。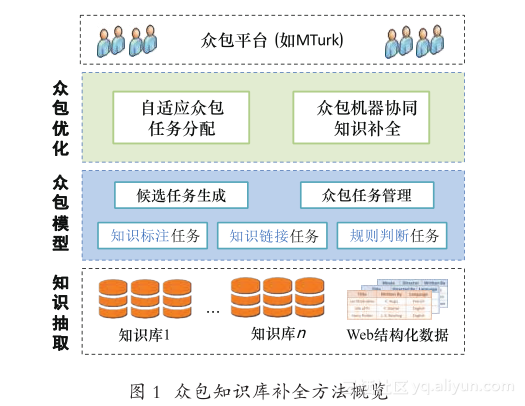
知识抽取:提出利用多类数据源进行抽取,其优势在于使不同源的知识数据互相进行补充,为知识库补全提供数据基础。具体考虑以下数据源:① 多 个 现 有 知 识 库, 如 YAGO [1] 、DBpedia [3] 和Freebase [5] 等,这些知识库构造的方法不尽相同,数据间存在互补;② Web 结构化数据,如 HTML表格[33] ,这些数据规模巨大且具有一定的结构特征,如微软在 2012 年报告存在近 6 亿的 HTML 表格。在此基础上,提取知识元组(主语 - 谓词 - 宾语)。注:由于提出方法的重点在利用众包,因此在知识抽取方面使用了现有的抽取技术。
众包模型:构建利用众包进行知识库补全的基本模型,即将知识库补全这一复杂工作分解成细粒度的众包任务,以分发给大量众包工人进行求解。在此过程中,需要进行候选任务的生成和众包任务的管理工作。具体来讲,提出以下三类基本众包任务。
● 知识标注任务:这类任务要求众包工人直接对知识元组的正确性进行判断,即给定抽取的知识元组 (s, p, o)(符号 s、p 和 o 分别表示主语、谓词和宾语,是一般表示知识的形式),希望众包工人返回 1(表示元组正确)或是 0(表示元组不正确)。
● 知识链接任务:这类任务利用众包对不同数据源的知识元组进行链接。具体而言,给定抽取自不同知识源的两个元组 (s 1 , p 1 , o 1 ) 和 (s 2 , p 2 , o 2 ),这类任务支持以下两种链接:① 实体链接:即判断充当主语或宾语的实体间尽管表示不同,但实际指代同一真实实体,可以链接起来;② 关系链接,即判断关系 p 1 和 p 2 指代的是同一种关系。
● 规则判断任务:这类任务使用众包对知识推理的规则进行判断。知识库中的其他元组对判断某一元组是否存在具有推理作用。具体而言,如要判断元组 (s, p, o) 是否成立,可以参考将主语 s 和宾语 o 关联起来的其他元组,如 (s, p 1 , e) 和 (e, p 2 , o)。这类任务就是判断 (s, p 1 , e) 和 (e, p 2 , o) 如果存在,是否能够推断出 (s, p, o) 就很可能存在。
例如,考虑判断姚明国籍(为了示例,我们假设知识库中姚明的国籍信息缺失)。知识标注任务是让众包直接判断 ( 姚明 , 国籍 , 中国 ) 元组是否正确;知识链接任务是将姚明与某篮球队员 HTML 表格上的姚链接,将关系国籍与如所属国家链接,以此将该表格上的中国填充到国籍的宾语中。规则判断任务是让众包判断 ( 姚明 , 出生地 , 上海 )、( 上海 ,所属国 , 中国 ) 这两个元组是否对判断国籍有帮助。
众包优化:如前所述,众包知识库补全面临着两大挑战:① 质量控制:与传统简单的众包工作(如图片标注、实体识别)不同,知识库补全更为复杂,需要众包工人具有一定的领域背景知识,如做上述判断国籍的题目需要对篮球队员有所了解。为此,本文提出自适应众包任务分配技术,详见第 3 章;② 成本控制:众包并不免费。由于知识库体量巨大,如不能有效地控制成本,众包知识库补全会引入难以承受的金钱开销。为此,本文提出众包机器协同的补全技术,详见第 4 章。
《中国人工智能学会通讯》——12.33 众包知识库补全方法概览相关推荐
- 中国人工智能学会通讯——基于图像认知的心理测评方法及系统
摘要:长久以来心理障碍的诊断和评估通常都是建立在晤谈.观察.量表测验的基础上,交互繁琐困难,主观性比较大,使得人的心理特征难以快速获取和量化.本研究创新性地将心理学和信息科学结合在一起,建立了情绪图像 ...
- 《中国人工智能学会通讯》——12.38 知识库与 HTML 表格的融合
12.38 知识库与 HTML 表格的融合 近年来,HMTL 表格(Web Table)作为万维网上重要的结构化数据,受到了广泛关注.HTML 表格有两个优点,其一是数量巨大,根据微软在 2012年的 ...
- 中国人工智能学会通讯——无智能,不驾驶——面向未来的智能驾驶时代 ( 下 )...
到目前为止似乎比较完美,而实际还 存在着一些问题.我们现在看到很多道 路上面,交通标志牌它的分布非常稀疏, 可能每过一两公里才能够检测出来一个 交通标志牌,因为毕竟这个深度学习算 法是目前最完美的,它 ...
- 中国人工智能学会通讯——基于视频的行为识别技术 1.7 视频的深度分段网络...
1.7 视频的深度分段网络 下面介绍另外一个工作,是我们和 CUHK.ETH 联合开展的,这个工作考 虑视频的分段特性,我们知道视频可以分 成很多段,每一段有不同的内容.我们 开发了一个深度模型,对不 ...
- 中国人工智能学会通讯——智能系统测评:挑战和机遇
上面的四个报告从四个维度讨论了智能系统测评的不同方面--产业.基础.基础和伦理.我受中国人工智能学会的委托,组织这次分论坛,为此对这个领域做了一些调研和思考,从现状和挑战这两个方面做了一些初步总结. ...
- 中国人工智能学会通讯——深蓝、沃森与AlphaGo
在 2016 年 3 月 份,正当李 世石与AlphaGo 进行人机大战的时候,我曾经写过 一 篇< 人 工 智 能 的 里 程 碑: 从 深 蓝 到AlphaGo>,自从 1997 年深 ...
- 中国人工智能学会通讯——后深度学习时代的人工智能
1956 年,在美国达特茅斯学院举行的一次会议上,"人工智能"的研究领域正 式确立.60 年后的今天,人工智能的发展正进入前所未有的大好时期.我今天作的报告,将通过分析时代的特点, ...
- 《中国人工智能学会通讯》——1.28 智能助手背后的技术
1.28 智能助手背后的技术 呈现在人们眼前的智能助手几乎都是"小而美"的,但其背后却是一个十分复杂的系统,需要多种技术的集成和联动.本文将智能助手背后的技术归为四类,分别是需求理 ...
- 中国人工智能学会通讯——智力测试与智能测评的对比思考
因为我的研究方向是心理学,不是特别懂计算机的东西,像陈老师说的,我们2013年很有可能开始一个合作,后来没有进行下来,我们希望来做一下机器人的智能测试.我想跟大家说为什么我对这个研发感兴趣,刚才陈老师 ...
最新文章
- css中.和#的区别 不写时代表什么
- 我的世界java版移除猪灵了吗_我的世界:激怒僵尸猪灵有奖励,用菌光体堆肥,修复126个漏洞!...
- VUE系列-Vue中组件的应用(三)
- Android 进行单元測试难在哪-part3
- php中表单名称未定义,php – zf2,表单集合没有在zf2中创建正确的输入名称
- 08cms php5.6,大型房产门户08cms单城市商业版V8.4(带升级补丁),带手机独家放送,去除后门优化响应...
- 外语学习的真实方法及误区(描述得非常深刻)
- 用python分析股票收益影响因素的方法_Python3对股票的收益和风险进行分析
- 瞄准千亿工业物联网市场,有人物联网为2万企业级用户提供完整可靠方案
- 电脑文件被删除了,找回文件数据的方法有哪些?
- Glide刷新图片闪啊闪
- 关于心理学书籍的一份书目
- 谷歌身份验证器插件以及基于utools的otp快捷使用
- [NOIP2011] 观光公交解题报告
- 相机测试软件,相机篇 软件检测其实意义不大_佳能数码相机_数码影像评测-中关村在线...
- Python免安装环境(Windows)
- STM32F411RE Nucleo笔记-按键控制PWM占空比
- Linux桌面基础:X Window System——Xorg
- 在Eclipse中关联源代码
- 信息碎片化爆炸时代,我们究竟失去的是什么?
热门文章
- arduino机器人设计与制作_百元搭建人工智能自主导航机器人
- 1_文本处理与词嵌入
- hibernate的查询条件lt_鱼与熊掌得兼:Hibernate与Mybatis共存
- python捷联惯导的姿态解算_自动驾驶中高精地图的大规模生产:视觉惯导技术在高德的应用...
- for循环python爬虫_python爬虫 for循环只出来一条
- python 访问网站 json_python爬虫用selenium访问一个网址返回的是个json字符串,怎么获取这个json字符串?...
- python html模板_Python html.format_html方法代码示例
- sqlserver修改链接服务器,sqlserver怎么新建链接服务器
- 在uipath_UiPath狂欢节Day 3——国内超级企业CFO大咖RPA案例分享!
- 修改ubuntu默认的Python版本号