中国人工智能学会通讯——智能系统测评:挑战和机遇

上面的四个报告从四个维度讨论了智能系统测评的不同方面——产业、基础、基础和伦理。我受中国人工智能学会的委托,组织这次分论坛,为此对这个领域做了一些调研和思考,从现状和挑战这两个方面做了一些初步总结。
在现状方面,从三个维度存在着差异和争论。第一,智能系统测评是基于外显行为,还是基于内在机制?第二,基于任务,还是基于标准?第三,基于同类比较,还是基于参照物比照?在挑战方面,存在着用户依赖性、环境相关性和价值渗透性三个方面的挑战。
现状方面:外显行为与内在机制的争论。现代人工智能最初想法的提出是图灵提出了所谓图灵测试,我们看到的这张图。在屋子里有一个智能系统,还有一个人。裁判是人类,在屋子外面,只能通过对话来了解和他对话的两个对象,以分辨哪个是人、哪个是机器。如果裁判不能正确的区分,就认为智能系统具有了人的智能。这样的设计显然是基于智能系统外显行为的,另外也是基于参照物的,和人对比。还有一个特点是只考虑问答,没有考虑环境的影响。对图灵测试是有很多批评的,最有名的是赛尔,美国哲学家,提出了Chinese room作为质疑。假设屋子里有一本手册,根据它从外显行为上可以回答所有的问题,但是不理解人的问题,是不是真的有智能?这种质疑说到底是行为和机制的争论,这个争论是长期的。但是在争论里,大家一致的意见,都很少讨论与环境的关系,主要在争论评价“智能”应该依据行为,还是机制。
我们回顾图灵最初的文章,实际上预测到了几乎所有的批评和质疑,而且他提前对所有预期到的批评和质疑都进行了反驳。实际上,应该测行为还是测机制,这是我们现在仍然很难说得清楚的,因为它是非常深的一个问题。我在这儿只是枚举这些现象。这是第一个方面的现状。
第二个方面存在的一些差异,不一定是争论,主要是差异。测评是基于任务,还是基于某种标准?基于任务的测评是设定一组任务,根据完成情况评分。刚才刘挺教授讲到,自然语言评测也是基于很多任务——广义的任务,当然任务都是系统化地来测。从自然语言领域之外来看,比如考虑测智能系统,很容易想到测智商,其实它也是针对任务来测。还有一个在机器人领域的国际测试,这个和自然语言领域是比较类似的,长期在进行系统性的测试。在服务机器人领域最大的测试是RoboCup@Home,在家庭环境和其他近似真实的环境中,对服务机器人整机性能进行系统化测试。也是基于任务的,每年设计不同的任务,有的任务难一点,基本上像刚才刘挺教授说的,比大家能做到的稍微强一点,也有少数测试很难,大多数队伍都是零分。这个测试一般三年有一次大的变化,变化以后可能任务提得比较难。它是分阶段的。第一阶段,大家都能得分。但是到第二阶段,可能大部分都得零分了。到第三年可能做得好一点。这是基于任务的。基于标准的测试是参照给定的标准打分。典型例子就是产品的评测,今天我们请来的郑军奇总经理,他演讲中介绍了机器人产品的检测、认证,现在有一个完整体系。对于产品来说,当然是有标准的,所以他说首先要制定标准。可能我们在人工智能学会,学术界的关注更多一点。产品测试是针对特定产品、特定功能、特定品质的,问题是比较明确的。假设要测一个服务机器人的样机,它现在还不是产品,预期未来5~10年成为产品,现在定它的标准就有难度,只好不断地提任务,通过完成任务的情况进行测评。这两种思路是有差异的。但是它们之间现在看并没有太多的矛盾,而是可以用到不同的场合,是互补的。
第三类差异是在同类里面比较,还是和参照物进行比较。同类测试的例子,比如对话系统或者同类机器人,得分多少可以比较。智商依年龄段进行对比,同类机器人进行对比。基于参照物的比较也是非常多的,一般会基于人工智能和人做对比,这种例子也很多。后面还有一个嘉宾的发言,北京大学苏彦捷教授。中科大和北大2013年做了一些合作,考虑参考智商测试的标准和方法,来对机器人智能做一些测评。这里面还有很多挑战,一会儿苏教授会作进一步介绍。
其实图灵测试也是和人比较,很明显是和人做对比。还有我们都知道的IBM做的Watson人机大战。本来是人的擂台赛,Watson也去参赛,最后赢了人类两位冠军。一位连续胜了170多场,这是非常厉害的。还有一位胜的场次最多,胜了300多场。最终Watson还是赢了他们两位。我们知道深蓝和Alphago比的是国际象棋和围棋,也是和人对比。两种比较的方法也是存在着差异的。当然,它们之间是不是有多少争论,那倒不一定,倒是给我们提供了不同的检测、测试、评价手段,我们根据情况可以选择需要的。
在这些现状的基础上,智能系统测评存在什么疑难和挑战?我初步总结有三项。
第一项挑战:用户依赖性。其实做人工智能的人很多是做信息出身的,如果不做产品,对用户之间的差异有时可能考虑的相对少一些,因为计算机科学技术是以标准化为基础的。但是到了人工智能领域,对用户的依赖性还是很大的。也就是说,有时不同的用户,对相同智能系统的相同行为会给出矛盾的评价。所以,如果某些智能系统依赖于用户评价,对这样的系统进行测评是有挑战性的。
信息推荐其实就有这种情况,不同的用户对信息的要求不一样,即所谓个性化。还有在机器人领域中的复杂家庭服务,不同的家庭生活习惯是不一样的,所以对于机器人提供服务的要求也是不一样的。这样我们就会发现,对智能系统的测评实际上涉及对智能系统用户的某种测评,或者用户研究。做产品的人对这方面是很清楚的,而做科研的人,可能过去对这方面考虑的比较少。用户需求通常是隐含在产品检测中,但是传统的产品和产品检测往往很少考虑用户的个性化需求。现在大家开始重视个性化,这样就产生了用户依赖性。这里还有一个可能对我们形成挑战的因素——传统的科学评价准则往往要求测试者无关,因为传统的科学标准认为,测试应该是客观的,所以应该和客户无关。现在看来,用户依赖性对智能系统测评提出了挑战。
第二项挑战是环境相关性,这对服务机器人来说是比较明显的,还有其他一些智能系统也会存在类似情况。我们看图灵测试,其实假定了环境无关性。但是也有一些智能系统和应用环境相关度较高,比较典型的例子就是现在做的很多的无人车。一个有一定基础的技术团队,其实做个一两年,最多两三年,就可以在简单的情况下完成无人驾驶的任务。简单的路况情况下并不复杂,比如各种标记物和交通标志容易识别的场景中,很快就能做出可以上路的无人车。但是实际路况变复杂以后,难度就增加很多。高速公路上和市区道路难度是很不一样的。中国和欧美情况也不一样。在中国无人车的挑战非常大,主要挑战是来源于环境复杂性。再比如智能服务机器人,现在提到服务机器人,往往认为就是对话机器人,其实核心的智能服务机器人是具有移动操作功能的。比如将来能当家政服务员、当保姆的,或者餐馆服务员,这两种机器人都在现在的测试里有反映。实际上这些测试的设计是要同时设计环境的,要考虑环境难度的。
我们更深入地考虑一下,这个挑战更进一步的难点是什么?任意给定的真实环境,让机器人适应它是不难的,环境给定以后总有办法。但是让一台设计好的机器人能适应所有可能的真实环境,这是非常难的。说到底,这就是国际人工智能最近十多年一直说的环境的不可预测性。服务机器人进入千家万户,扫地是比较简单的,如果是更复杂的任务,就和环境和用户有关了,存在着不可预测性。设计者不能预测未来会出现什么环境,这样一种不可预测性,对于系统建造和智能评价都是存在的,这也提出了一种挑战。
为了把上面这个深层难点说的更清楚,简单介绍一下智能机器人的结构,见图1。智能机器人作用于环境和人,对环境
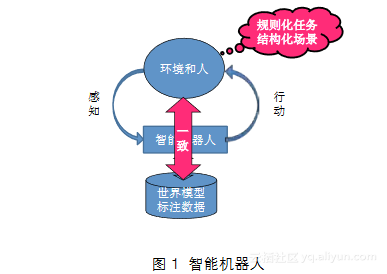
有感知和行动,图中这边是感知,那边是行动。机器人总是依赖于世界模型或大量的标注数据。在规则性任务和结构化环境中,我们可以让世界模型或者标注数据和环境保持一致。但是这种要求其实在现实中通常很难得到满足,所以出现的科学挑战有时是从环境里发生的,见图2。不可预
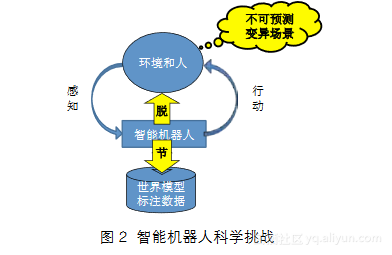
预测的场景,变异的场景,表面上看差不多,有些细节变化,可这些细节变化导致环境对智能系统来说变得非常不一样。在自然语言里也有类似的现象,比如刚才刘教授举例,一句话里少了一个“的”字,两句话的意思就完全不一样了。在环境里也是这样,某些很小的变化对机器人有非常大的影响。主要的挑战在于,这种变异导致世界模型或者标注数据和现实环境发生了脱节,以至于机器人的行动出了问题。这就是环境相关性。
第三项挑战:价值渗透性。智能系统测评测的是性能或者能力,可以测性能,也可以测能力。至于与实用价值有什么关系,作为学者可能不会直接考虑实用价值。当然,最初做研究可能有一个背景和应用需求,但是研究过程中就不太关注实用价值了。图灵测试也没有直接考虑实用价值,智商测试也没有考虑实用价值。我们看IBM的Watson,也不是直接用实用价值评价的。但是,如果我们一直按照这样的思路往下走,可能会有问题。不考虑智能系统的价值渗透性,是不利于智能系统测评发挥作用的。我们看到,智能系统能力的大小和它的实用价值,实际上相互之间可以出现各种各样的关系,比如说有些系统能力很强,未必它的价值就大;还有的系统能力比较弱,也未必价值小。现在中国互联网一些服务,如微信,太好用了。你说它有多强的智能,这个是不好说的,可是它的价值非常大。我觉得能力与价值两者之间的关系可能需要协调,不是只考虑一个侧面,而是要考虑两个侧面。否则我们对能力做了很多评价,而且发现能力很强,但是它的作用不大。这对人工智能的发展可能不是一件好事。
我初步总结了三方面的挑战,那么该如何回答这些挑战?我们需要进一步努力。回答这些挑战,其实还有一些很难的事情,我用图3加以说明。在机器人领域,
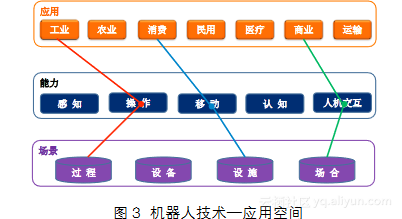
技术和应用的空间是非常大的,比如从能力维度,我们很粗的来划分,有感知、操作、移动、认知、交互;从应用维度来说,可以分类为工业、农业、消费、民用、医疗、商业、运输,这个分类是欧盟对机器人的分类。这些分类看起来分的更细一点,因为其中每一个行业都非常大。从应用场景来说,有过程的,如工业生产;有用到设备上的;有应用于设施的;也有应用于场合的。现在我们在国内看到的机器人产品,常见的例子比如工业机器人,是用于过程的,它的能力就是操作。这是一个例子,在图3中用红线表示。还有对话和提供信息服务的机器人,用于一些场合,交互能力用于商业,这是第二个常见的例子,图3中用绿线表示。第三个例子,扫地机器人,是用于家庭或室内环境,这是用于设施的,它的能力只涉及移动的能力,图3中用蓝线表示。这种机器人按照欧盟的分类叫做消费机器人。其实这三种类型的机器人已经涵盖了现有机器人产品或者机器人研发的相当大的比例,可能超过50%。从图3可以看出,我们还可以连很多别的线,这样就会有很多种其他类型的机器人。而且未必是只用单一的能力去提供服务,可能是多种能力组合起来,这样一组合又形成非常多的可能产品。这张图中,组合起来会出现非常多的智能系统种类,这些情况下怎么做智能系统的测评?这是非常有挑战性的。
下面举一个综合性例子,试图表明未来的人机交互场景是什么样的,进而表明智能系统测评的复杂性,见图4。这个例子是

中科大机器人团队为自己设计的未来目标,我们希望机器人未来几年能够实现这一目标。用户问:“冰箱的用途是什么?”这是典型的问答。我们的机器人叫可佳,她回答用户:“冰箱是用于食品保鲜的。”用户:“怎么保鲜?”这个问题稍微有点深了。可佳:“把买回来的食品放进冰箱,吃的时候再取出来。”到目前为止,人机交互都在对话范围里,再看下面。用户:“太好了,你赶紧从冰箱里拿一点吃的给我。”显然,用户的这个问题已经不是单纯的问答型任务了,而是要提供服务的,包含移动和操作功能,机器人要开冰箱,把食物拿出来,这就不是简单的对话了。如果对话聊天那好办,机器人可以说“你自己去拿,你怎么那么懒”,这个问题就很容易地解决了。但是服务机器人不行,真要把食品从冰箱里拿出来送给用户。我们假想将来会出现这样的情况,可佳说:“你别做梦了,家里的东西都被你吃光了。”这体现出机器人要了解家庭里所有相关信息,以便根据真实的信息了解和执行用户的服务请求。接下来用户说:“那你怎么不买?”这也不是聊天,这是在批评,在指责机器人:你任务没有完成好,东西被我吃光了,你就该买,你怎么不买?可佳说:“昨天就告诉你了,你不给钱。”我们假想,未来钱还是用户自己管的,没有交给机器人。所以机器人的意思是,你不给钱,我买不了,这是在做因果推理,而且是针对现实场景的因果推理,不是局限于抽象概念之间的因果推理。用户说:“给你,你多买一点,然后赶紧给我做午饭”,意味着用户肚子饿了。可佳说:“这就对了,下次早点给。你等着吧。”意思是买完以后给你做午饭。这个例子反映了很多问题,图3里枚举的各种机器人能力,都在这个人机交互过程中有体现。
从这个例子可以看出,像这样的一种机器人,我们怎样对它进行测评?涉及的问题是相当复杂的,非常有挑战性,也非常有科学意义和实用价值。
最后,我发言的结语。测评是人工智能研究的开端,目前正在成为核心内容之一。智能系统测评存在长期争论,隐含重大科学问题、社会需求和技术需求。智能系统测评极具挑战性,涉及人工智能研究与应用的一系列深层课题,孕育着人工智能突破的重大机遇;也涉及伦理方面的问题、社会保障体系的问题,以及其他社会性问题。这些挑战在当前的情况下非常值得我们去思考和努力。
(本报告根据速记整理)
中国人工智能学会通讯——智能系统测评:挑战和机遇相关推荐
- 中国人工智能学会通讯——无智能,不驾驶——面向未来的智能驾驶时代 ( 下 )...
到目前为止似乎比较完美,而实际还 存在着一些问题.我们现在看到很多道 路上面,交通标志牌它的分布非常稀疏, 可能每过一两公里才能够检测出来一个 交通标志牌,因为毕竟这个深度学习算 法是目前最完美的,它 ...
- 中国人工智能学会通讯——基于视频的行为识别技术 1.7 视频的深度分段网络...
1.7 视频的深度分段网络 下面介绍另外一个工作,是我们和 CUHK.ETH 联合开展的,这个工作考 虑视频的分段特性,我们知道视频可以分 成很多段,每一段有不同的内容.我们 开发了一个深度模型,对不 ...
- 中国人工智能学会通讯——深蓝、沃森与AlphaGo
在 2016 年 3 月 份,正当李 世石与AlphaGo 进行人机大战的时候,我曾经写过 一 篇< 人 工 智 能 的 里 程 碑: 从 深 蓝 到AlphaGo>,自从 1997 年深 ...
- 中国人工智能学会通讯——智力测试与智能测评的对比思考
因为我的研究方向是心理学,不是特别懂计算机的东西,像陈老师说的,我们2013年很有可能开始一个合作,后来没有进行下来,我们希望来做一下机器人的智能测试.我想跟大家说为什么我对这个研发感兴趣,刚才陈老师 ...
- 中国人工智能学会通讯——基于图像认知的心理测评方法及系统
摘要:长久以来心理障碍的诊断和评估通常都是建立在晤谈.观察.量表测验的基础上,交互繁琐困难,主观性比较大,使得人的心理特征难以快速获取和量化.本研究创新性地将心理学和信息科学结合在一起,建立了情绪图像 ...
- 中国人工智能学会通讯——智能语音技术与产业应用展望 1.2 智能语音产业应用的现状和挑战...
1.2 智能语音产业应用的现状和挑战 智能语音产业应用,基本上都是从语音控制.语音识别和语音交互作为切入点建立起来的,根据不同的定位和形态,目前主要分为以下4类. (1)APP类纯软语音应用.如App ...
- 中国人工智能学会通讯——人工智能在各医学亚专科的发展现状及趋势 1.3 人工智能在各医学亚专科的发展态势...
1.3 人工智能在各医学亚专科的发展态势 1. 人工智能在眼科领域的应用 2016年11月,Google的研究者Gulshan博士等人在美国医学协会杂志"Journal of the Ame ...
- 中国人工智能学会通讯——机器人组件技术在智能制造系统中的应用
摘要:随着工业4.0时代的到来,如何将传统工厂改造成为个性化.网络化.柔性生产的智能制造系统成为了当前的研究热点.本文从智能制造系统和智能机器人系统的相似性出发,构建了基于机器人组件技术的智能制造系统 ...
- 中国人工智能学会通讯——后深度学习时代的人工智能
1956 年,在美国达特茅斯学院举行的一次会议上,"人工智能"的研究领域正 式确立.60 年后的今天,人工智能的发展正进入前所未有的大好时期.我今天作的报告,将通过分析时代的特点, ...
最新文章
- 网络高可用性解决方案
- 十种MySQL报错注入
- Kubernetes学习笔记(一)
- 【GNN】啥是GNN?GNN咋学?GNN何用?
- ubuntu下adb offline 的解决办法
- 前端学习(715):数组新增元素
- 给一个执行在windows 7和NAT下的VMWARE虚拟机分配固定IP
- 网络基本概念之TCP, UDP, 单播(Unicast), 多播(组播)(Multicast)
- 韩国Hana银行将建立试点验证CBDC技术
- jdk的java和javac命令
- [19/05/06-星期一] JDBC(Java DataBase Connectivity,java数据库连接)_基本知识
- 2018,扬帆起航!
- python所有组合,在python中组合n个列表的所有元素
- 大学生科技立项项目申报书超详细写作规范
- Unity3D 制作绿草地,草坪,模型表面生成草地,草地效果Shader实现 草着色器 Brute Force - Grass Shader
- 国产计算机系统有哪些,国产电脑操作系统有哪些(华为鸿蒙系统笔记本电脑)...
- EditPlus字体放大方法
- ubuntu 14.04开机出现错误“Error found when loading /root/.profile”解决(root用户登录时才会出现)
- 【注入】C# 构造注入的方法
- UE4 自建基础玩家时重力的设置