【sklearn第二十讲】聚类
机器学习训练营——机器学习爱好者的自由交流空间(入群联系qq:2279055353)
sklearn.cluster模块用来作聚类分析。每一个聚类算法包括两部分结果:一个执行fit方法的类,它在训练数据上学习类;一个函数,即,给定训练数据,它返回一个整数标签的数组,标签对应每个数据点的聚类结果,保存在labels_属性里。
输入数据
值得注意的是,sklearn.cluster模块执行的聚类算法能够取不同类型的矩阵作为输入。所有的算法都接受[n_samples, n_features]标准矩阵输入。
聚类方法概述
scikit-learn聚类算法比较 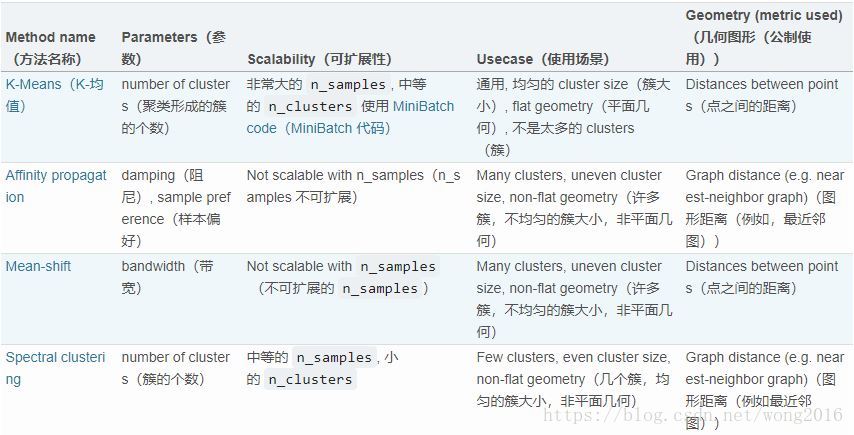 
K-means
KMeans算法通过最小化类内平方和,将样本分隔进等方差的组。该算法要求聚类前指定类的个数。
K-means算法要将 NNN 个样本的数据集 XXX 分割成 KKK 个互不相交的类 C1,C2,…,CKC_1, C_2, \dots, C_KC1,C2,…,CK, 每个类里的样本均值记为 μk,k=1,2,…,K\mu_k, k=1, 2, \dots, Kμk,k=1,2,…,K. 这些均值称为类中心,注意,它们通常不是 XXX 里的数据点。k-means算法选择使得类内平方和最小的类中心。即,
minC∑k=1K∑x∈Ck∣∣x−μk∣∣2\mathop{\min}_{C}\sum\limits_{k=1}^K \sum\limits_{x\in C_k}||x-\mu_k||^2minCk=1∑Kx∈Ck∑∣∣x−μk∣∣2
该准则是度量类内一致程度的测度。一般认为,它存在下列缺点:
它假设类是凸且等方性的(convex and isotropic), 即向所有方向是均匀的,但实际情况并不总是这样。对于延向或不规则向的类,它的聚类结果并不好。
它并不是一个标准的测度。我们只知道它的值越小聚类效果越好,达到0是最好的。但是在高维空间,欧氏距离倾向于更大。因此,在k-means聚类前,使用主成分等降维策略,能够减轻这个问题,并且加速计算。

假如有充足的时间,k-means的准则将总是收敛的,但可能收敛到局部最小值,它高度依赖中心的初始化。解决这个问题的办法之一是**“k-mean++初始化方案”**。该方案初始化的中心彼此距离较远,结果优于随机初始化。在scikit-learn里,使用参数init='k-means++'实现。
Hierarchical clustering
层次聚类(Hierarchical clustering)是一个通用的聚类算法族,这类算法通过连续地合并或分割类,创建嵌套类别。类的层次由一棵树表示,称系统树图(dendrogram). 树根是包括所有样本在内的唯一的类,树叶是仅包括一个样本的类。
AgglomerativeClustering对象使用自下而上法作层次聚类:每个观测初始自成一类,然后连续地合并类。连接准则确定合并类的测度。
Ward 最小化所有类内差的平方和。
Maximum or complete linkage 最小化类的成对观测的最大距离
Average linkage 最小化类的所有成对观测的平均距离
FeatureAgglomeration
FeatureAgglomeration使用自下而上的层次聚类对特征做聚类,这样降低了特征数,因此,可以把它当作一个维数降低的工具。
聚类效果评价
Adjusted Rand index
假设已知真实的类标签分派labels_true, 样本的预测类标签分派labels_pred, adjusted Rand index(ARI)是一个测量两个分派相似性的度量函数。
from sklearn import metrics
labels_true = [0, 0, 0, 1, 1, 1]
labels_pred = [0, 0, 1, 1, 2, 2]
metrics.adjusted_rand_score(labels_true, labels_pred)
你可以在预测的标签里置换0和1,重新命名为2和3,得到的分数相同。
labels_pred = [1, 1, 0, 0, 3, 3]
metrics.adjusted_rand_score(labels_true, labels_pred)
而且,adjusted_rand_score能被用来作为一致性测度(consensus measure), 交换参数不会改变分数值。
metrics.adjusted_rand_score(labels_pred, labels_true)
完美的标签,分值是1.
labels_pred = labels_true[:]
metrics.adjusted_rand_score(labels_true, labels_pred)
坏的预测,分值是负的或接近0.
labels_true = [0, 1, 2, 0, 3, 4, 5, 1]
labels_pred = [1, 1, 0, 0, 2, 2, 2, 2]
metrics.adjusted_rand_score(labels_true, labels_pred)
优势
随机标签分派的ARI分数接近0.
有界范围[-1, 1]: 负值是非常差的,类似的聚类结果有正的ARI, 完美匹配的分值是1.
不假定类结构
不足
ARI需要知道样本的真实类标签,这在实际情况里几乎是不可能的。然而,在完全的无监督学习环境下,ARI可以作为聚类模型选择的一致性指标。
互信息分数
给定真实的类标签labels_true和预测标签labels_pred, 互信息(Mutual Information)是一个度量忽略置换情况下,两种分派一致性的函数。这个函数有两个不同的归一化版本,Normalized Mutual Information(NMI) and Adjusted Mutual Information(AMI). NMI经常在文献里使用,而AMI用于反机会归一化(normalized against chance). 互信息分数在[0, 1]内,优势与不足和ARI类似。
from sklearn import metrics
labels_true = [0, 0, 0, 1, 1, 1]
labels_pred = [0, 0, 1, 1, 2, 2]
metrics.adjusted_mutual_info_score(labels_true, labels_pred)
Homogeneity, completeness and V-measure
给定样本的真实类标签,可以根据条件熵理论定义直观的测度。
homogeneity: 每个类只包括同类成员
completeness: 一个给定类的所有成员被分派到相同的类里
在scikit-learn里,使用homogeneity_score and completeness_score把上面的两个概念变成分数。这两个分数值都在[0, 1]内,值越高聚类效果越好。
from sklearn import metrics
labels_true = [0, 0, 0, 1, 1, 1]
labels_pred = [0, 0, 1, 1, 2, 2]
metrics.homogeneity_score(labels_true, labels_pred)
metrics.completeness_score(labels_true, labels_pred)
它们的调和平均称V-meature, 由v_meature_score计算。
metrics.v_measure_score(labels_true, labels_pred)
使用homogeneity_completeness_v_measure, 可以同时计算这三种分数。
metrics.homogeneity_completeness_v_measure(labels_true, labels_pred)
精彩内容,请关注微信公众号:统计学习与大数据
【sklearn第二十讲】聚类相关推荐
- 初识二维码 第二十讲 二维码解码程序的组件之一 摄像头拍照功能
初识二维码 第二十讲 二维码解码程序的组件之一 摄像头拍照功能 解码程序的第一个环节是通过摄像头这个硬件,得到二维码的图片. 对摄像头的工作原理来说,简单的描述如下:1是从摄像头得到模拟信号, ...
- ev3编程变量模块_英文视频教学翻译-机器人ev3编程学习的第二十讲:举例讲解数据变量模块编...
机器人ev3编程学习的第二十讲:举例讲解数据变量模块编- Rob Widger (为了容易理解,在原文的翻译时做了修改 by EV3-TOM) 这一节我给大家讲解使用变量模块的编程,这些我喜欢的例子也 ...
- java applet编程_第二十讲 Java Applet程序设计
第二十讲Java Applet程序设计 主要内容 初识Java Applet Java Applet的生命周期 Graphics类和图像图形绘制 Applet中播放声音媒体 初识Java Applet ...
- 第十九讲:爱情:如何让爱情天长地久 第二十讲:幽默 第二十一讲:爱情自尊
(注:此为课程第十九课,更新于2017年7月16日) 大家好! 今天我们继续谈论爱情,讲之前先说一下,一位叫Nadia的同学,你的钥匙链落在这教室了,就在我这里,课后请来我这里取. 那我们来讲讲爱情吧 ...
- 深聊全链路压测之:第二十讲 | 如何落地日志隔离方案。
日志隔离落地方案 1.引言 2.Demo预演 2.1 技术方案选型 2.2 Demo系统预演 2.3 扩展知识-日志分离 3.总结 1.引言 这节课,我们来学习如何基于微服务技术落地日志隔离. 从第1 ...
- 王佩丰excel2010基础教程学习笔记(第十六讲到第二十讲)
简单文本函数:left,right,mid,find left()函数有两个参数,参数一是字符串所在单元格,参数二是从字符串左边开始取几位. 从字符串左边开始取三位. right()函数一样,不过是从 ...
- 第二十讲 拉普拉斯变换求解线性ODE
一,拉氏变换公式: , 二,保证的拉氏变换存在的条件: 只有在收敛的情况下,拉氏变换才存在 增长条件:保证拉氏变换存在的前提是的增长速度不能超过的收敛速度, 指数型表达法:,,, 正例: 反例: ,因 ...
- Python实战从入门到精通第二十讲——调用父类方法
在子类中调用父类的某个已经被覆盖的方法. 为了调用父类(超类)的一个方法,可以使用 super() 函数,比如: class A:def spam(self):print('A.spam')class ...
- 第二十讲、迭代器模式
1.定义 Iterator模式也叫迭代模式,是行为模式之一,它把对容器中包含的内部对象的访问委让给外部类,使用Iterator(遍历)按顺序进行遍历访问的设计模式. 2. 转载于:https://ww ...
- 第二十讲 DES算法简介
1 美国制定数据加密标准简况 目的:通信与计算机相结合是人类步入信息社会的一个阶梯, 它始于六十年代末,完成于90年代初.计算机通信网的形成与发 展,要求信息作业标准化,安全保密亦不例外.只有标准化, ...
最新文章
- 2021年7月份学习总结,多套WebFuture的系统部署(简易版)
- LeetCode 13. Roman to Integer
- 使用wireshark抓取3G包
- 动态规划 1.背包问题
- java stream 取不同的数据_基础篇:JAVA.Stream函数,优雅的数据流操作
- 领导:“请在今晚进行网络系统升级”
- python glob用法
- 借Google Guava学习发现和开发通用功能模块
- bash脚本之case语句应用,while、until和select循环应用及其示例
- 今日芯声 | 连发五个“感恩”,余承东庆祝与鸿蒙OS同一天生日
- NLP算法-情绪分析-snowNLP算法库
- Sallen-Key 低通滤波器设计过程
- 【矩阵论总结(5)】常用计算及方法
- 如何让laravel框架下出现vender文件夹
- cocos2dx 特效 3D特效
- Quartz定时任务-@DisallowConcurrentExecution注解
- PLX PCIe Switch使用
- 苹果用什么蓝牙耳机好?适合苹果的音乐蓝牙耳机推荐
- 第九城市CEO朱骏:一个人的掘金游戏
- 吐槽大会,加个好友,分享资源