form表单提交数据编码方式和tomcat接受数据解码方式
2019独角兽企业重金招聘Python工程师标准>>> 
简单介绍乱码和http请求
1) 乱码问题是web开发过程中经常遇到的问题,主要原因就是URL中使用了非ASCII码造成服务器后台程序解析出现乱码的问题。
2) URL中最容易出现中文的地方就是在QueryString的参数值还有Servletpath中。
3) 简单用一个图来说明一下http请求的流程:
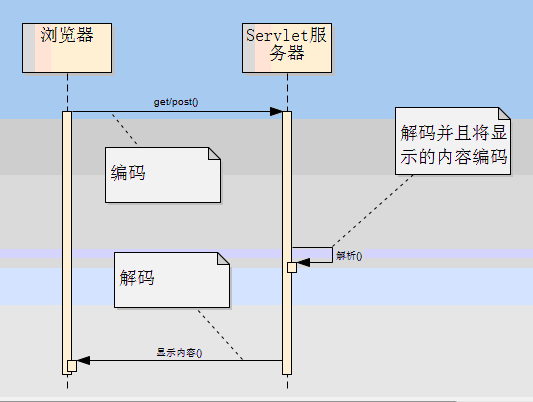
第一步:浏览器把URL经过编码送给服务器;(get请求根据浏览器设置的编码,get默认的是ISO-8859-1; post根据页面设置的编码)
第二步:服务器(tomcat)把这些请求解码处理完毕之后将显示的内容进行编码发送给客户端浏览器;
第三步:浏览器按照指定的编码显示网页
form有2中方法把数据提交给服务器,get和post,分别说下吧。
- get提交
1. 首先说下客户端(浏览器)的form表单用get方法是如何将数据编码后提交给服务器端的吧。
对于get方法来说,都是把数据串联在请求的url后面作为参数,如:http://localhost:8080/servlet?msg=abc
(很常见的一个乱码问题就要出现了,如果url中出现中文或其它特殊字符的话,如:http://localhost:8080/servlet?msg=杭州,服务器端容易得到乱码),url拼接完成后,浏览器会对url进行URL encode,然后发送给服务器,URL encode的过程就是把部分url做为字符,按照某种编码方式(如:utf-8,gbk等)编码成二进制的字节码,然后每个字节用一个包含3个字符的字符串 "%xy" 表示,其中xy为该字节的两位十六进制表示形式。具体介绍可以看下java.net.URLEncoder类的介绍在这里。
了解了URL encode的过程,我们能看到2个很重要的问题,
- 需要URL encode的字符一般都是非ASCII的字符(笼统的讲),再通俗的讲就是除了英文字母以外的文字(如:中文,日文等)都要进行URL encode,所以对于我们来说,都是英文字母的url不会出现服务器得到乱码问题,出现乱码都是url里面带了中文或特殊字符造成的;
- URL encode到底按照那种编码方式对字符编码?这里就是浏览器的事情了,而且不同的浏览器有不同的做法,中文版的浏览器一般会默认的使用GBK,通过设置浏览器也可以使用UTF-8,可能不同的用户就有不同的浏览器设置,也就造成不同的编码方式,所以很多网站的做法都是先把url里面的中文或特殊字符用javascript做URL encode,然后再拼接url提交数据,也就是替浏览器做了URL encode,好处就是网站可以统一get方法提交数据的编码方式。 完成了URL encode,那么现在的url就成了ASCII范围内的字符了,然后以iso-8859-1的编码方式转换成二进制随着请求头一起发送出去。这里想多说几句的是,对于get方法来说,没有请求实体,含有数据的url都在请求头里面。
2. 服务器端(tomcat)是如何将数据获取到进行解码的。
第一步是先把数据用iso-8859-1进行解码,对于get方法来说,tomcat获取数据的是ASCII范围内的请求头字符,其中的请求url里面带有参数数据,如果参数中有中文等特殊字符,那么目前还是URL encode后的%XY状态,先停下,我们先说下开发人员一般获取数据的过程。通常大家都是request.getParameter("name")获取参数数据,我们在request对象或得的数据都是经过解码过的,而解码过程中程序里是无法指定,这里要说下,有很多新手说用request.setCharacterEncoding("字符集")可以指定解码方式,其实是不可以的,看servlet的官方API说明有对此方法的解释:Overrides the name of the character encoding used in the body of this request. This method must be called prior to reading request parameters or reading input using getReader().可以看出对于get方法他是无能为力的,因为get请求的数据在请求头部,而request.setCharacterEncoding作用于请求报文主体。那么到底用什么编码方式解码数据的呢,这是tomcat的事情了,默认缺省用的是iso-8859-1,这样我们就能找到为什么get请求带中文参数为什么在服务器端得到乱码了,原因是在客户端一般都是用UTF-8或GBK对数据URL encode,这里用iso-8859-1方式URL decoder显然不行,在程序里我们可以直接
Java代码
new String(request.getParameter("name").getBytes("iso-8859-1"),"客户端指定的URL encode编码方式") 还原回字节码,然后用正确的方式解码数据。
PS:
网上的文章通常是在tomcat里面做个配置
Xml代码
<Connector port="8080" protocol="HTTP/1.1" maxThreads="150" connectionTimeout="20000"redirectPort="8443" URIEncoding="GBK"/> 这样是让tomcat在获取数据后用指定的方式URL decoder,这样配置以后我们就不需要在代码里解码了。
- post提交
1.客户端(浏览器)的form表单用post方法是如何将数据编码后提交给服务器端的。
在post方法里所要传送的数据也要URL encode,那么他是用什么编码方式的呢? 在form所在的html文件里如果有如下代码,
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>那么post就会用此处指定的编码方式编码。其中pageEncoding用来告诉tomcat此文件所用的字符编码。这个编码应该与eclipse保存文件用的编码一致。Tomcat以此编码方式来读取JSP文件并编译。page标签中的contentType用来设置tomcat往浏览器发送HTML内容所使用的编码。这个编码会在HTTP响应头中指定以通知浏览器。
一般大家都认为这段代码是为了让浏览器知道用什么字符集来对网页解释,所以网站都会把它放在html代码的最前端,尽量不出现乱码,其实它还有个作用就是指定form表单的post方法提交数据的URL encode编码方式。从这里可以看出对于get方法来数,浏览器对数据的URL encode的编码方式是有浏览器设置来决定,(可以用js做统一指定),而post方法,开发人员可以指定。
2。服务器端(tomcat)是如何将数据获取到进行解码的。
如果用tomcat默认缺省设置,也没做过滤器等编码设置,那么他也是用iso-8859-1解码的,但是request.setCharacterEncoding("字符集")可以派上用场。
我发现上面说的tomcat所做的事情前提都是在请求头里没有指定编码方式,如果请求头里指定了编码方式将按照这种方式编码。
- JAVA处理字符的原理
JAVA使用UNICODE来存储字符数据,处理字符时通常有三个步骤:
1、按指定的字符编码形式,从源输入流中读取字符数据
2、以UNICODE编码形式将字符数据存储在内存中
3、按指定的字符编码形式,将字符数据编码并写入目的输出流中
所以JAVA处理字符时总是经过了两次编码转换,一次是从指定编码转换为UNICODE编码,一次是从UNICODE编码转换为指定编码。如果在读入时用错误的形式解码字符,则内存存储的是错误的UNICODE字符。而从最初文件中读出的字符数据,到最终在屏幕终端显示这些字符,期间经过了应用程序的多次转换。如果中间某次字符处理用错误的编码方式解码了从输入流读取的字符数据,或用错误的编码方式将字符写入输出流,则下一个字符数据的接收者就会编解码出错,从而导致最终显示乱码。这一点,是我们分析字符编码问题以及解决问题的指导思想。
一、在JAVA文件中硬编码中文字符,在eclipse中运行,控制台输出了乱码。
例如,我们在JAVA文件中写入以下代码:
String text = "大家好";
System.out.println(text);
如果我们是在eclipse里编译运行,可能看到的结果是类似这样的乱码:????。那么,这是为什么呢?
我们先来看看整个字符的转换过程。
1. 在eclipse窗口中输入中文字符,并保存成UTF-8的JAVA文件。这里发生了多次字符编码转换。不过因为我们相信eclipse的正确性,所以我们不用分析其中的过程,只需要相信保存下的JAVA文件确实是UTF-8格式。
2. 在eclipse中编译运行此JAVA文件。这里有必要详细分析一下编译和运行时的字符编码转换。
编译:我们用javac编译JAVA文件时,javac不会智能到猜出你所要编译的文件是什么编码类型的,所以它需要指定读取文件所用的编码类型。默认javac使用平台缺省的字符编码类型来解析JAVA文件。平台缺省编码是操作系统决定的,我们使用的是中文操作系统,语言区域设置通常都是中国大陆,所以平台缺省编码类型通常是GBK。这个编码类型我们可以在JAVA中使用System.getProperty("file.encoding")来查看。所以javac会默认使用GBK来解析JAVA文件。如果我们要改变javac所用的编码类型,就要加上-encoding参数,如javac -encoding utf-8 Test.java。
这里要另外提一下的是eclipse使用的是内置的编译器,并不能添加参数,如果要为javac添加参数则建议使用ANT来编译。不过这并非出现乱码的原因,因为eclipse可以为每个JAVA文件设置字符编码类型,而内置编译器会根据此设置来编译JAVA文件。
运行:编译后字符数据会以UNICODE格式存入字节码文件中。然后eclipse会调用java命令来运行此字节码文件。因为字节码中的字符总是UNICODE格式,所以java读取字节码文件并没有编码转换过程。虚拟机读取文件后,字符数据便以UNICODE格式存储在内存中了。
3. 调用System.out.println来输出字符。这里又发生了字符编码转换。
System.out.println使用了PrintStream类来输出字符数据至控制台。PrintStream会使用平台缺省的编码方式来输出字符。我们的中文系统上缺省方式为GBK,所以内存中的UNICODE字符被转码成了GBK格式,并送到了操作系统的输出服务中。因为我们操作系统是中文系统,所以往终端显示设备上打印字符时使用的也是GBK编码。如果到这一步,我们的字符其实不再是GBK编码的话,终端就会显示出乱码。那么,在eclipse运行带中文字符的JAVA文件,控制台显示了乱码,是在哪一步转换错误呢?我们一步步来分析。
保存JAVA文件成UTF-8后,如果再次打开你没有看到乱码,说明这步是正确的。
用eclipse本身来编译运行JAVA文件,应该没有问题。
System.out.println会把内存中正确的UNICODE字符编码成GBK,然后发到eclipse的控制台去。
等等,我们看到在Run Configuration对话框的Common标签里,控制台的字符编码被设置成了UTF-8!问题就在这里。 System.out.println已经把字符编码成了GBK,而控制台仍然以UTF-8的格式读取字符,自然会出现乱码。将控制台的字符编码设置为GBK,乱码问题解决。(这里补充一点:eclipse的控制台编码是继承了workspace的设置的,通常控制台编码里没有GBK的选项而且不能输入。我们可以先在 workspace的编码设置中输入GBK,然后在控制台的设置中就可以看到GBK的选项了,设置好后再把workspace的字符编码设置改回utf- 8就是。)
二、JSP文件中硬编码中文字符,在浏览器上显示乱码。
我们用eclipse编写一个JSP页面,使用tomcat浏览这个页面时,整个页面的中文字符都是乱码。这是什么原因呢?
JSP页面从编写到在浏览器上浏览,总共有四次字符编解码。
1. 以某种字符编码保存JSP文件
2. Tomcat以指定编码来读取JSP文件并编译
3. Tomcat向浏览器以指定编码来发送HTML内容
4. 浏览器以指定编码解析HTML内容
这里的四次字符编解码,有一次发生错误最终显示的就会是乱码。我们依次来分析各次的字符编码是如何设置的。
保存JSP文件,这是在编辑器中设置的,比如eclipse中,设置文件字符类型为utf-8。
JSP文件开头的<%@ page language="java" contentType="text/html; charset=utf-8" pageEncoding="utf-8"%>,其中pageEncoding用来告诉tomcat此文件所用的字符编码。这个编码应该与eclipse保存文件用的编码一致。Tomcat以此编码方式来读取JSP文件并编译。
page标签中的contentType用来设置tomcat往浏览器发送HTML内容所使用的编码。这个编码会在HTTP响应头中指定以通知浏览器。
浏览器根据HTTP响应头中指定的字符编码来解析HTML内容。如:
HTTP/1.1 200 OKDate: Mon, 01 Sep 2008 23:13:31 GMTServer: Apache/2.2.4 (Win32) mod_jk/1.2.26Vary: Host,Accept-EncodingSet-Cookie: JAVA2000_STYLE_ID=1;Domain=www.java2000.net;Expires=Thu, 03-Nov-2011 09:00:10 GMT;Path=/Content-Encoding: gzipTransfer-Encoding: chunkedContent-Type: text/html;charset=UTF-8另外,HTML中有个标签<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">中也指定了charset。不过这个字符编码只有在当网页保存在本地作为静态网页时有效,因为没有HTTP头,所以浏览器根据此标签来识别HTML内容的编码方式。
现在在JSP文件中硬编码出现乱码的机会比较小了,因为大家都用了如eclipse的编辑器,基本上可以自动保证这几个编码设置的正确性。现在更多碰到的是在JSP文件中从其他数据源中读取中文字符所产生的乱码问题。
三、在JSP文件中读取字符文件并在页面中显示,中文字符显示为乱码。
比如,我们在JSP文件中使用以下代码:
<%
BufferedReader reader = new BufferedReader(new FileReader("D://test.txt"));
String content = reader.readLine();
reader.close();
%>
<%=content%>
test.txt里保存的是中文字符,但在浏览器上看到的乱码。这是个经常见到的问题。我们继续用之前的方法一步步来分析输入和输出流
1. test.txt是以某种编码方式保存中文字符,比如UTF-8。
2. BufferedReader直接读取test.txt的字节内容并以默认方式构造字符串。分析BufferedReader的代码,我们可以看到 BufferedReader调用了FileReader的read方法,而FileReader又调用了FileInputStream的native 的read方法。所谓native的方法,就是操作系统底层方法。那么我们操作系统是中文系统,所以FileInputStream默认用GBK方式读取文件。因为我们保存test.txt用的是UTF-8,所以在这里读取文件内容使用GBK是错误的编码。
3. <%=content%>其实就是out.print(content),这里又用到了HTTP的输出流JspWriter,于是字符串content又被以JSP的page标签中指定的UTF-8方式编码成字节数组被发送到浏览器端。
4. 浏览器以HTTP头中指定的方式解码字符,这时无论是用GBK还是UTF-8解码,显示的都是乱码。
可见,我们字符编码转换在第二步时出错了,UTF-8的字符串被当做GBK读入了内存中。
解决这个乱码问题有两种方法,一是把test.txt用GBK保存,则FileInputStream能正确读入中文字符;二是使用InputStreamReader来转换字符编码,如:
InputStreamReader sr = new InputStreamReader(new FileInputStream("D://test.txt"),"utf-8");
BufferedReader reader = new BufferedReader(sr);
这样,JAVA就会用utf-8的方式来从文件中读取字符数据。
另外,我们可以通过在java命令后带上Dfile.encoding参数来指定虚拟机读取文件使用的默认字符编码,例如java -Dfile.encoding=utf-8 Test,
这样,我们在JAVA代码里用System.getProperty("file.encoding")取到的值为utf-8。
四、JSP读取request.getParameter里的中文参数后,在页面显示为乱码。
在JAVA的WEB应用中,对request对象里的parameters的中文处理一直是常见也最难搞的一只大怪兽。经常是刚搞定了这边,那边又出了乱码。而导致这种复杂性的,主要是此过程中字符编解码次数非常多,而且无论是浏览器还是WEB服务器特别是TOMCAT总是不能给我们一个比较满意的支持。
首先我们来分析用GET方式上传参数的乱码情况。
例如我们在浏览器地址栏输入以下URL:http://localhost:8080/test/test.jsp?param=大家好
我们的JSP代码如此处理param这个参数:
<% String text = request.getParameter("param"); %>
<%=text%>
而就这么简单的两句代码,我们很有可能在页面上看到这样的乱码:?ó????
网上对处理request.getParamter中的乱码有很多文章和方法,也都是正确的,只是方法太多让人一直不明白到底是为什么。这里给大家分析一下到底是怎么一回事。
首先,我们来看看与request对象有哪些相关的编码设置:
1. JSP文件的字符编码
2. 请求这个带参数URL的源页面的字符编码
3. IE的高级设置中的选项“总以utf-8方式发送URL地址”
4. TOMCAT的server.xml中配置URIEncoding
5. 函数request.setCharacterEncoding()
6. JS的encodeURIComponent函数与JAVA的URLDecoder类
这么多条相关编码设置,也难怪大家被搞得头晕了。这里给大家根据各种情况给大家一一分析一下。见下表:
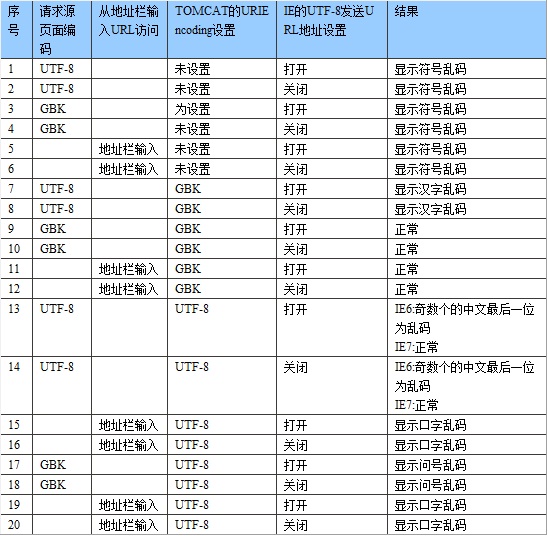
以上表格里的现象,除了指名在IE7上,其他全是在IE6上测试的结果。
由这个表我们可以看到,IE的“总以utf-8方式发送URL地址”设置并不影响对parameter的解析,而从页面请求URL和从地址栏输入URL居然也有不同的表现。
根据这个表列出的现象,大家只要用smartSniff抓几个网络包,并稍稍调查一下TOMCAT的源代码,就可以得出以下结论:
1. IE设置中的“总以utf-8方式发送URL地址”只对URL的PATH部分起作用,对查询字符串是不起作用的。也就是说,如果勾选了这个选项,那么类似http://localhost:8080/test/大家好.jsp?param=大家好这种URL,前一个“大家好”将被转化成utf-8形式,而后一个并没有变化。这里所说的utf-8形式,其实应该叫utf-8+escape形式。
那么,查询字符串中的中文字符,到底是用什么编码传送到服务器的呢?是系统默认编码,即GBK。也就是说,在我们中文操作系统上,传送给WEB服务器的查询字符串,总是以GBK来编码的。
2. 在页面中通过链接或location重定向或open新窗口的方式来请求一个URL,这个URL里面的中文字符是用什么编码的?是用该页面的编码类型。也就是说,如果我们从某个源JSP页面上的链接来访问http://localhost:8080/test/test.jsp?param=大家好这个URL,如果源JSP页面的编码是UTF-8,则大家好这几个字的编码就是UTF-8。
而在地址栏上直接输入URL地址,或者从系统剪贴板粘贴到地址栏上,这个输入并非从页面中发起的,而是由操作系统发起的,所以这个编码只可能是系统的默认 编码,与任何页面无关。我们还发现,在不同的浏览器上,用链接方式打开的页面,如果在地址栏上再敲个回车,显示的结果也会不同。IE上敲回车后显示不变 化,而傲游上可能就会有乱码或乱码消失的变化。说明IE上敲回车,实际发送的是之前记忆下来的内存中的URL,而傲游上发送的从当前地址栏重新获取的 URL。
3. TOMCAT的URIEncoding如果不加以设置,则默认使用ISO-8859-1来解码URL,设置后便用设置了的编码方式来解码。这个解码同时包 括PATH部分和查询字符串部分。可见,这个参数是对用GET方式传递的中文参数最关键的设置。不过,这个参数只对GET方式传递的参数有效,对POST 的无效。分析TOMCAT的源代码我们可以看到,在请求一个页面时,TOMCAT会尝试构造一个Request对象,在这个对象里,会从 Server.xml里读取URIEncoding的值,并赋值给Parameters类的queryStringEncoding变量,而这个变量将在 解析request.getParameter中的GET参数时用来指导字符解码。
4. request.setCharacterEncoding函数只对POST的参数有效,对GET的参数无效。且这个函数必须是在第一次调用 request.getParameter之前使用。这是因为Parameters类有两个字符编码参数,一个是encoding,另一个是 queryStringEncoding,而setCharacterEncoding设置的是encoding,这个是在解析POST的参数是才用到 的。
所以,这就导致了我们通常都要分开处理POST和GET的字符编码,用TOMCAT自带的filter只能处理POST的,另外要设置URIEncoding来设置GET的。这样很麻烦而且URIEncoding无法根据内容来动态区分编码,总还是一个问题。
在调查TOMCAT的代码时发现了另一个在server.xml里的参数useBodyEncodingForURI,可以解决这个问题。这个参数设成 true后,TOMCAT就会用request.setCharacterEncoding所设置的字符编码来同样解析GET参数了。这样,那个 SetCharacterEncodingFilter就可以同时处理GET和POST参数了。
知道了以上知识后,我们再来分析一下前面表格中列出的几个典型现象。
第一条,请求源页面的编码为UTF-8,而TOMCAT的URIEncoding未指定,则TOMCAT用ISO8859-1方式来解码参数,所以从request中读出来后,内存中存储的为错误的UNICODE数据,导致之后到屏幕显示的所有转换全部出错。
第九条,请求源页面编码为GBK,而TOMCAT的URIEncoding也为GBK,TOMCAT用GBK方式去解码原本用GBK编码的字符,解码正确,内存中的UNICODE值正确,最终显示正确的中文。
第十三条,请求源页面编码为UTF-8,TOMCAT的URIEncoding也为UTF-8,而在IE6中最终显示的中文字符,如果是奇数个数,则最后一个会显示为乱码。这是为什么呢?
我的猜测是,这是因为IE6将URL地址发送时,对查询字符串是直接对UTF-8格式的字符使用GBK来编码,而不是对UNICODE的字符来用GBK编 码,所以UTF-8的数据没有经过UNICODE而直接编码成了GBK。而到了TOMCAT这边,GBK的编码又被当成UTF-8做了解码。所以这个过程 中经过了UTF-8转换成GBK,然后又从GBK转换成UTF-8的过程,而这种转换,恰好就会出现奇数个中文字符串的最后一位为乱码的现象。而在IE7 中,估计把这种现象当做BUG已经被解决了,即在发送地址时会先转成UNICODE再编码成GBK。那么估计在IE7的浏览器+中文操作系统环境下,如果 我们把TOMCAT的URIEncoding设置成GBK,无论JSP编码成什么格式,都不会出现乱码。这个没测试,请大家自己验证。
其他几条就不再做分析了,有兴趣的大家自己分析。
参考:
http://blog.csdn.net/lfsf802/article/details/7232834
http://blog.sina.com.cn/s/blog_95c8f1ac010198j2.html
转载于:https://my.oschina.net/trydaydayup/blog/1503817
form表单提交数据编码方式和tomcat接受数据解码方式相关推荐
- Form表单提交前进行JS验证的3种方式
1. 提交按钮的onclick事件中验证 <script type="text/javascript"> function check(form) { ...
- ajax form表单提交_开发日志:金数据表单自动提交脚本
最近学校要求我们每天通过一个在线表单打卡自己在家做的体育课项目,在提交的时候我突然想了下如果能有一个自动的系统每天帮我自动打卡岂不是能省很多时间?而且我一直很想学Python的网络爬虫以及服务器后端的 ...
- html 提交form表单提交数据格式,form表单提交数据
form表单提交的几种方法 HTML表单提交的几种方式方式一:通过submit按钮提交方式二:通过一般按钮button提交1/3javascript">functionsubmit1( ...
- 传统form表单提交方式的文件上传与文件存储
引言 时隔一天,上一篇文章<文件存储>刚一停笔,今天上午就解决了困扰我已久的文件上传问题. 站在一个已实现功能的角度来重新看待这个文件上传的业务:编辑页面选择jar包,然后通过form表单 ...
- form表单提交带参数的两种方式
#第一种方式# action写明了LoginServlet,通过submit按钮直接提交到后台 <form action="LoginServlet" method=&quo ...
- 常见的Form表单提交方式
Form表单提交方式探究 在进行项目编程的时候,我们难免会去编写一些简单的前端页面. 而编写前端页面就力不开 form表单的支持. 下面就form表单的提交方式进行如下探寻 1.常规写法 在form表 ...
- SSM框架下实现form表单提交的方式
实现form表单的提交有多种方式,这里我们主要讲两种常用的. 注:此Demo是在SSM框架下完成的,数据库采用MySQL,关于ssm整合的相关知识,这里不做过多赘述.主要展示表单提交方式,暂不考虑代码 ...
- php form表单提交方式,form表单提交数据的几种方式
一.submit提交 一般表单提交通过type=submit实现,input type="submit",浏览器显示为button按钮,通过点击这个按钮提交表单数据跳转到/url. ...
- form表单提交数据到后台的方式
form表单提交方式 1.无刷新页面提交表单 表单可实现无刷新页面提交,无需页面跳转,如下,通过一个隐藏的iframe实现,form表单的target设置为iframe的name名称, form提交目 ...
最新文章
- Python Tricks 若干
- Linux内核网络设备驱动
- viewGroup 项目中使用
- 反手发力动作--乒在民间
- Java后台获取前端传递的日期解析不了
- android进程调试(ro.debuggable=1或android:debuggable=true)----JDWP线程
- linux tcp连接计算机,计算机基础知识——linux socket套接字tcp连接分析
- kernel php segfault,php不停报错segfault,求高手帮忙
- Python+OpenCV:对极几何(Epipolar Geometry)
- AcWing 1738. 蹄球(特殊基环树)
- 中秋佳节,献上笔试题一道,祝各位事业蒸蒸日上!
- html5中的web worker用法
- HTML 实现扫雷游戏
- 189邮箱smpt服务器,189邮箱登录(常用邮箱客户端设置指南)
- (没有ignore选项时)安装MongoDB4.0以上版本出现 Verify that you have sufficient privileges to start system services
- 软件测试人员的简历是什么样子的?
- 【笔记】HEFT——面向异构计算的高性能、低复杂度任务调度
- android 双击返回键退出 拦截menu键
- AURIX TC397 ASCLIN UART
- android 手机短信恢复,安卓手机短信删除了怎么恢复?简单恢复的方法
热门文章
- 如何判断数组所有数都不等于一个数_【每日算法Day 91】求解数组中出现次数超过1/3的那个数
- 怎样通过vb设置透视表多项选择_数据透视表有多强大?
- 计算机丢失ac1st.dll怎么找回,CAD提示ac1st16.dll丢失修复步骤
- ua获取手机型号_取证人员为什么很难从移动设备上获取电子数据证据?
- 跳一跳python源码下载_微信跳一跳python代码实现
- 【CV夏季划】告别入门,提升眼界,从掌握最有价值的那些CV方向开始
- 【直播回放】100分钟全面剖析图像分割任务,学习CV必知
- 全球及中国本质安全校准器行业销售前景与竞争规模预测报告2022-2027年
- 中国第三代半导体行业应用动态与十四五发展格局展望报告2022版
- 2019 Multi-University Training Contest 1 - 1004 - Vacation - 二分 - 思维