熊猫数据集_对熊猫数据框使用逻辑比较
熊猫数据集
P (tPYTHON)
Logical comparisons are used everywhere.
逻辑比较随处可见 。
The Pandas library gives you a lot of different ways that you can compare a DataFrame or Series to other Pandas objects, lists, scalar values, and more. The traditional comparison operators (<, >, <=, >=, ==, !=) can be used to compare a DataFrame to another set of values.
Pandas库为您提供了许多不同的方式,您可以将DataFrame或Series与其他Pandas对象,列表,标量值等进行比较。 传统的比较运算符( <, >, <=, >=, ==, != )可用于将DataFrame与另一组值进行比较。
However, you can also use wrappers for more flexibility in your logical comparison operations. These wrappers allow you to specify the axis for comparison, so you can choose to perform the comparison at the row or column level. Also, if you are working with a MultiIndex, you may specify which index you want to work with.
但是,还可以使用包装器在逻辑比较操作中提供更大的灵活性。 这些包装器允许您指定要进行比较的轴 ,因此您可以选择在行或列级别执行比较。 另外,如果您使用的是MultiIndex,则可以指定要使用的索引 。
In this piece, we’ll first take a quick look at logical comparisons with the standard operators. After that, we’ll go through five different examples of how you can use these logical comparison wrappers to process and better understand your data.
在本文中,我们将首先快速了解与标准运算符的逻辑比较。 之后,我们将介绍五个不同的示例,说明如何使用这些逻辑比较包装器来处理和更好地理解您的数据。
The data used in this piece is sourced from Yahoo Finance. We’ll be using a subset of Tesla stock price data. Run the code below if you want to follow along. (And if you’re curious as to the function I used to get the data scroll to the very bottom and click on the first link.)
本文中使用的数据来自Yahoo Finance。 我们将使用特斯拉股价数据的子集。 如果要继续,请运行下面的代码。 (如果您对我用来使数据滚动到最底部并单击第一个链接的功能感到好奇)。
import pandas as pd# fixed data so sample data will stay the samedf = pd.read_html("https://finance.yahoo.com/quote/TSLA/history?period1=1277942400&period2=1594857600&interval=1d&filter=history&frequency=1d")[0]df = df.head(10) # only work with the first 10 points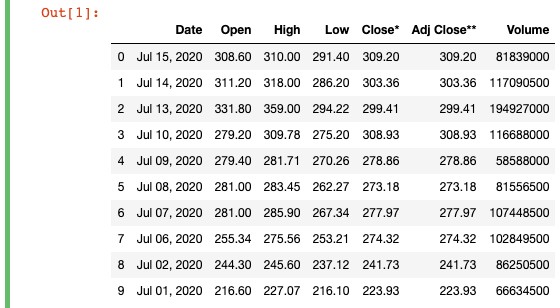
与熊猫的逻辑比较 (Logical Comparisons With Pandas)
The wrappers available for use are:
可用的包装器有:
eq(equivalent to==) — equals toeq(等于==)—等于ne(equivalent to!=) — not equals tone(等于!=)-不等于le(equivalent to<=) — less than or equals tole(等于<=)-小于或等于lt(equivalent to<) — less thanlt(等于<)-小于ge(equivalent to>=) — greater than or equals toge(等于>=)-大于或等于gt(equivalent to>) — greater thangt(等于>)-大于
Before we dive into the wrappers, let’s quickly review how to perform a logical comparison in Pandas.
在深入探讨包装之前,让我们快速回顾一下如何在Pandas中进行逻辑比较。
With the regular comparison operators, a basic example of comparing a DataFrame column to an integer would look like this:
使用常规比较运算符,将DataFrame列与整数进行比较的基本示例如下所示:
old = df['Open'] >= 270Here, we’re looking to see whether each value in the “Open” column is greater than or equal to the fixed integer “270”. However, if you try to run this, at first it won’t work.
在这里,我们正在查看“ Open”列中的每个值是否大于或等于固定整数“ 270”。 但是,如果尝试运行此命令,则一开始它将无法工作。
You’ll most likely see this:
您很可能会看到以下内容:
TypeError: '>=' not supported between instances of 'str' and 'int'
TypeError: '>=' not supported between instances of 'str' and 'int'
This is important to take care of now because when you use both the regular comparison operators and the wrappers, you’ll need to make sure that you are actually able to compare the two elements. Remember to do something like the following in your pre-processing, not just for these exercises, but in general when you’re analyzing data:
这一点现在很重要,因为当您同时使用常规比较运算符和包装器时,需要确保您确实能够比较这两个元素。 请记住,在预处理过程中,不仅要针对这些练习,而且在分析数据时通常要执行以下操作:
df = df.astype({"Open":'float', "High":'float', "Low":'float', "Close*":'float', "Adj Close**":'float', "Volume":'float'})Now, if you run the original comparison again, you’ll get this series back:
现在,如果再次运行原始比较,您将获得以下系列:
You can see that the operation returns a series of Boolean values. If you check the original DataFrame, you’ll see that there should be a corresponding “True” or “False” for each row where the value was greater than or equal to (>=) 270 or not.
您可以看到该操作返回了一系列布尔值。 如果检查原始DataFrame,您会发现值大于或等于( >= )270的每一行都应该有一个对应的“ True”或“ False”。
Now, let’s dive into how you can do the same and more with the wrappers.
现在,让我们深入研究如何使用包装器做同样的事情。
1.比较两列的不平等 (1. Comparing two columns for inequality)
In the data set, you’ll see that there is a “Close*” column and an “Adj Close**” column. The Adjusted Close price is altered to reflect potential dividends and splits, whereas the Close price is only adjusted for splits. To see if these events may have happened, we can do a basic test to see if values in the two columns are not equal.
在数据集中,您将看到有一个“ Close *”列和一个“ Adj Close **”列。 调整后的收盘价被更改以反映潜在的股息和分割,而收盘价仅针对分割进行调整。 要查看是否可能发生了这些事件,我们可以进行基本测试以查看两列中的值是否不相等。
To do so, we run the following:
为此,我们运行以下命令:
# is the adj close different from the close?df['Close Comparison'] = df['Adj Close**'].ne(df['Close*'])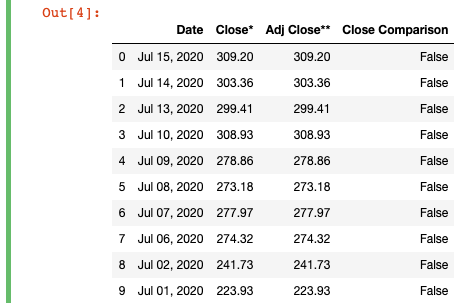
Here, all we did is call the .ne() function on the “Adj Close**” column and pass “Close*”, the column we want to compare, as an argument to the function.
在这里,我们.ne()在“ Adj Close **”列上调用.ne()函数,并传递“ Close *”(我们要比较的列)作为该函数的参数。
If we take a look at the resulting DataFrame, you’ll see that we‘ve created a new column “Close Comparison” that will show “True” if the two original Close columns are different and “False” if they are the same. In this case, you can see that the values for “Close*” and “Adj Close**” on every row are the same, so the “Close Comparison” only has “False” values. Technically, this would mean that we could remove the “Adj Close**” column, at least for this subset of data, since it only contains duplicate values to the “Close*” column.
如果我们看一下生成的DataFrame,您会看到我们创建了一个新列“ Close Compare”,如果两个原始的Close列不同,则显示“ True”,如果相同,则显示“ False”。 在这种情况下,您可以看到每行上“ Close *”和“ Adj Close **”的值相同,因此“ Close Compare”只有“ False”值。 从技术上讲,这意味着我们至少可以删除此数据子集的“ Adj Close **”列,因为它仅包含“ Close *”列的重复值。
2.检查一列是否大于另一列 (2. Checking if one column is greater than another)
We’d often like to see whether a stock’s price increased by the end of the day. One way to do this would be to see a “True” value if the “Close*” price was greater than the “Open” price or “False” otherwise.
我们经常想看看一天结束时股票的价格是否上涨了。 一种方法是,如果“收盘价”大于“开盘价”,则查看“真”值,否则查看“假”价。
To implement this, we run the following:
为了实现这一点,我们运行以下命令:
# is the close greater than the open?df['Bool Price Increase'] = df['Close*'].gt(df['Open'])Here, we see that the “Close*” price at the end of the day was higher than the “Open” price at the beginning of the day 4/10 times in the first two weeks of July 2020. This might not be that informative because it’s such a small sample, but if you were to extend this to months or even years of data, it could indicate the overall trend of the stock (up or down).
在这里,我们看到,在2020年7月的前两周,一天结束时的“收盘价”比一天开始时的“开盘价”高出4/10倍。因为这是一个很小的样本,但是如果您将其扩展到数月甚至数年的数据,则可能表明存量的总体趋势(上升或下降)。
3.检查列是否大于标量值 (3. Checking if a column is greater than a scalar value)
So far, we’ve just been comparing columns to one another. You can also use the logical operators to compare values in a column to a scalar value like an integer. For example, let’s say that if the volume traded per day is greater than or equal to 100 million, we’ll call it a “High Volume” day.
到目前为止,我们只是在相互比较列。 您还可以使用逻辑运算符将列中的值与标量值(例如整数)进行比较。 例如,假设每天的交易量大于或等于1亿,我们将其称为“高交易量”日。
To do so, we run the following:
为此,我们运行以下命令:
# was the volume greater than 100m?df['High Volume'] = df['Volume'].ge(100000000)Instead of passing a column to the logical comparison function, this time we simply have to pass our scalar value “100000000”.
这次我们不必将列传递给逻辑比较函数,而只需传递标量值“ 100000000”。
Now, we can see that on 5/10 days the volume was greater than or equal to 100 million.
现在,我们可以看到5/10天的交易量大于或等于1亿。
4.检查列是否大于自身 (4. Checking if a column is greater than itself)
Earlier, we compared if the “Open” and “Close*” value in each row were different. It would be cool if instead, we compared the value of a column to the preceding value, to track an increase or decrease over time. Doing this means we can check if the “Close*” value for July 15 was greater than the value for July 14.
之前,我们比较了每行中的“打开”和“关闭*”值是否不同。 相反,如果我们将列的值与先前的值进行比较,以跟踪随时间的增加或减少,那将很酷。 这样做意味着我们可以检查7月15日的“ Close *”值是否大于7月14日的值。
To do so, we run the following:
为此,我们运行以下命令:
# was the close greater than yesterday's close?df['Close (t-1)'] = df['Close*'].shift(-1)df['Bool Over Time Increase'] = df['Close*'].gt(df['Close*'].shift(-1))For illustration purposes, I included the “Close (t-1)” column so you can compare each row directly. In practice, you don’t need to add an entirely new column, as all we’re doing is passing the “Close*” column again into the logical operator, but we’re also calling shift(-1) on it to move all the values “up by one”.
为了便于说明,我在“ Close(t-1)”列中添加了一个标题,以便您可以直接比较每一行。 实际上,您不需要添加全新的列,因为我们要做的只是将“ Close *”列再次传递到逻辑运算符中,但是我们还对其调用了shift(-1)来进行移动所有值“加一”。
What’s going on here is basically subtracting one from the index, so the value for July 14 moves “up”, which lets us compare it to the real value on July 15. As a result, you can see that on 7/10 days the “Close*” value was greater than the “Close*” value on the day before.
这里发生的基本上是从索引中减去1,因此7月14日的值“向上”移动,这使我们可以将其与7月15日的实际值进行比较。结果,您可以看到在7/10天“关闭*”值大于前一天的“关闭*”值。
5.比较列与列表 (5. Comparing a column to a list)
As a final exercise, let’s say that we developed a model to predict the stock prices for 10 days. We’ll store those predictions in a list, then compare the both the “Open” and “Close*” values of each day to the list values.
作为最后的练习,假设我们开发了一个模型来预测10天的股价。 我们将这些预测存储在列表中,然后将每天的“打开”和“关闭*”值与列表值进行比较。
To do so, we run the following:
为此,我们运行以下命令:
# did the open and close price match the predictions?predictions = [309.2, 303.36, 300, 489, 391, 445, 402.84, 274.32, 410, 223.93]df2 = df[['Open','Close*']].eq(predictions, axis='index')
Here, we’ve compared our generated list of predictions for the daily stock prices and compared it to the “Close*” column. To do so, we pass “predictions” into the eq() function and set axis='index'. By default, the comparison wrappers have axis='columns', but in this case, we actually want to work with each row in each column.
在这里,我们比较了生成的每日股票价格预测列表,并将其与“收盘价*”列进行了比较。 为此,我们将“预测”传递给eq()函数并设置axis='index' 。 默认情况下,比较包装器具有axis='columns' ,但是在这种情况下,我们实际上要处理每一列中的每一行。
What this means is Pandas will compare “309.2”, which is the first element in the list, to the first values of “Open” and “Close*”. Then it will move on to the second value in the list and the second values of the DataFrame and so on. Remember that the index of a list and a DataFrame both start at 0, so you would look at “308.6” and “309.2” respectively for the first DataFrame column values (scroll back up if you want to double-check the results).
这意味着熊猫将把列表中的第一个元素“ 309.2”与“打开”和“关闭*”的第一个值进行比较。 然后它将移至列表中的第二个值和DataFrame的第二个值,依此类推。 请记住,列表的索引和DataFrame的索引都从0开始,因此对于第一个DataFrame列值,您将分别查看“ 308.6”和“ 309.2”(如果要仔细检查结果,请向上滚动)。
Based on these arbitrary predictions, you can see that there were no matches between the “Open” column values and the list of predictions. There were 4/10 matches between the “Close*” column values and the list of predictions.
根据这些任意的预测,您可以看到“ Open”列值和预测列表之间没有匹配项。 “ Close *”列值和预测列表之间有4/10个匹配项。
I hope you found this very basic introduction to logical comparisons in Pandas using the wrappers useful. Remember to only compare data that can be compared (i.e. don’t try to compare a string to a float) and manually double-check the results to make sure your calculations are producing the intended results.
我希望您发现使用包装程序对熊猫进行逻辑比较非常基础的介绍很有用。 请记住仅比较可以比较的数据(即不要尝试将字符串与浮点数进行比较),并手动仔细检查结果以确保您的计算产生了预期的结果。
Go forth and compare!
继续比较吧!
More by me:- 2 Easy Ways to Get Tables From a Website- Top 4 Repositories on GitHub to Learn Pandas- An Introduction to the Cohort Analysis With Tableau- How to Quickly Create and Unpack Lists with Pandas- Learning to Forecast With Tableau in 5 Minutes Or Less翻译自: https://towardsdatascience.com/using-logical-comparisons-with-pandas-dataframes-3520eb73ae63
熊猫数据集
http://www.taodudu.cc/news/show-995302.html
相关文章:
- 决策树之前要不要处理缺失值_不要使用这样的决策树
- gl3520 gl3510_带有gl gl本机的跨平台地理空间可视化
- 数据库逻辑删除的sql语句_通过数据库的眼睛查询sql的逻辑流程
- 数据挖掘流程_数据流挖掘
- 域嵌套太深_pyspark如何修改嵌套结构域
- spark的流失计算模型_使用spark对sparkify的流失预测
- Jupyter Notebook的15个技巧和窍门,可简化您的编码体验
- bi数据分析师_BI工程师和数据分析师的5个格式塔原则
- 因果推论第六章
- 熊猫数据集_处理熊猫数据框中的列表值
- 数据预处理 泰坦尼克号_了解泰坦尼克号数据集的数据预处理
- vc6.0 绘制散点图_vc有关散点图的一切
- 事件映射 消息映射_映射幻影收费站
- 匿名内部类和匿名类_匿名schanonymous
- ab实验置信度_为什么您的Ab测试需要置信区间
- 支撑阻力指标_使用k表示聚类以创建支撑和阻力
- 均线交易策略的回测 r_使用r创建交易策略并进行回测
- 初创公司怎么做销售数据分析_初创公司与Faang公司的数据科学
- 机器学习股票_使用概率机器学习来改善您的股票交易
- r psm倾向性匹配_南瓜香料指标psm如何规划季节性广告
- 使用机器学习预测天气_如何使用机器学习预测着陆
- 数据多重共线性_多重共线性对您的数据科学项目的影响比您所知道的要多
- 充分利用昂贵的分析
- 如何识别媒体偏见_描述性语言理解,以识别文本中的潜在偏见
- 数据不平衡处理_如何处理多类不平衡数据说不可以
- 糖药病数据集分类_使用optuna和mlflow进行心脏病分类器调整
- mongdb 群集_群集文档的文本摘要
- gdal进行遥感影像读写_如何使用遥感影像进行矿物勘探
- 推荐算法的先验算法的连接_数据挖掘专注于先验算法
- 时间序列模式识别_空气质量传感器数据的时间序列模式识别
熊猫数据集_对熊猫数据框使用逻辑比较相关推荐
- 熊猫数据集_处理熊猫数据框中的列表值
熊猫数据集 Have you ever dealt with a dataset that required you to work with list values? If so, you will ...
- 熊猫数据集_用熊猫掌握数据聚合
熊猫数据集 Data aggregation is the process of gathering data and expressing it in a summary form. This ty ...
- 熊猫数据集_使用大数据的熊猫
熊猫数据集 减少多达90%的内存使用量的提示 (Tips for reducing memory usage by up to 90%) When working using pandas with ...
- 熊猫数据集_大熊猫数据框的5个基本操作
熊猫数据集 Tips and Tricks for Data Science 数据科学技巧与窍门 Pandas is a powerful and easy-to-use software libra ...
- 熊猫数据集_熊猫迈向数据科学的第一步
熊猫数据集 I started learning Data Science like everyone else by creating my first model using some machi ...
- 熊猫数据集_在日常生活中使用熊猫数据框
熊猫数据集 Before getting started let us do a quick revision, Pandas is a python library that gives elite ...
- 熊猫数据集_熊猫迈向数据科学的第三部分
熊猫数据集 Data is almost never perfect. Data Scientist spend more time in preprocessing dataset than in ...
- 熊猫数据集_熊猫迈向数据科学的第二部分
熊猫数据集 If you haven't read the first article then it is advised that you go through that before conti ...
- 熊猫数据集_为数据科学拆箱熊猫
熊猫数据集 If you are already familiar with NumPy, Pandas is just a package build on top of it. Pandas pr ...
最新文章
- AI赌神超进化:德扑六人局击溃世界冠军,诈唬如神,每小时能赢1千刀 | Science...
- Java 10:将流收集到不可修改的集合中
- ci框架 乱码 mysql_mysql容器乱码问题
- 将CSV文件写入到MySQL中(用Pandas库实现MySQL数据库的读写)
- Java Web编程实战1~3章笔记
- 计算机二级黑板板书书写,清华老师们的板书惊艳朋友圈!8个板书技巧让黑板亮起来!...
- Unity3d FPS射击游戏案例 - 消灭病毒
- pycharm新建python的快捷键_Pycharm超级好用的快捷键
- HDU 2243(AC自动机+矩阵快速幂)
- 计算机常年开机,电脑长时间开机的危害
- 《六朝隐逸诗学研究》高智(作者)epub+mobi+azw3格式下载
- 山东新高考604分怎么报计算机专业,山东2017高考604分适合报考哪些211学校
- 计算机网络管理工程师证书考试试题,2016年计算机软件水平考试网络工程师练习题...
- python自动化办公 51cto_用Python开发钉钉群机器人,自动办公神器
- mysql 军规_MySQL数据库军规
- 面试中遇到的一道智力题
- vue 传参 微信_小猿圈web前端之微信小程序页面间跳转传参方式总结
- Android 性能优化之线程优化
- 脑洞全开YY无罪-益智类游戏“脑力大战”引发思考
- NLP下游任务理解以及模型结构改变(上)