熊猫数据集_为数据科学拆箱熊猫
熊猫数据集
If you are already familiar with NumPy, Pandas is just a package build on top of it. Pandas provide more flexibility than NumPy to work with data. While in NumPy we can only store values of single data type(dtype) Pandas has the flexibility to store values of multiple data type. Hence, we say Pandas is heterogeneous. We will unpack several more advantages of Pandas today.
如果您已经熟悉NumPy,Pandas只是基于它的一个软件包。 与NumPy相比,熊猫提供了更大的灵活性来处理数据。 在NumPy中,我们只能存储单个数据类型(dtype)的值。Pandas可以灵活地存储多个数据类型的值。 因此,我们说熊猫是异质的 。 今天我们将介绍熊猫的更多优点。
Since we will be referring to NumPy in every section, I’m assuming you have knowledge of NumPy if not I will be dropping links to resources at the end of the article.
由于我们将在每个部分中都引用NumPy,因此假设您已经了解NumPy,否则我将在本文结尾处删除指向资源的链接。
I’m considering the very popular Titanic datset to unpack the abilities of Pandas. You don’t have to worry because I will still be introducing the concepts of Pandas step-by-step keeping in mind you are a newbie to Pandas package.
我正在考虑非常受欢迎的泰坦尼克号daset,以解开熊猫的能力。 您不必担心,因为我仍然会逐步介绍Pandas的概念,请记住您是Pandas软件包的新手。
Let’s just quickly import Pandas, Numpy, and load the Titanic dataset.
让我们快速导入Pandas,Numpy并加载Titanic数据集。
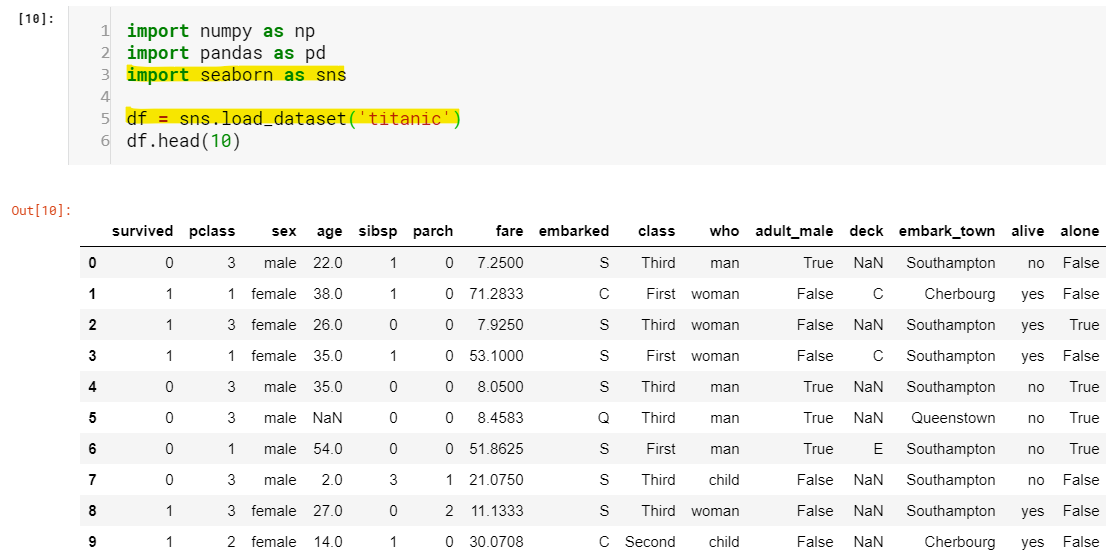
I know, a lot to digest at once but we will break it down at the course of time. For now, don’t worry about line 3 and line 5(highlighted). Just understand that the seaborn package has the dataset in it and we loaded it, that’s all. You might have already figured out that ‘df’ holds our entire dataset but wait, what is the data type of 'df’? and what on Earth is ‘df.head(10)’. This brings us to our first topic Pandas objects: Series and DataFrame.
我知道,有很多东西需要立即消化,但随着时间的流逝我们会分解。 现在,不必担心第3行和第5行(突出显示)。 只需了解seaborn软件包中就有数据集,然后我们就将其加载即可。 您可能已经发现'df'拥有我们的整个数据集,但是等等,'df'的数据类型是什么? 到底是什么'df.head(10)' 。 这将我们带入第一个主题Pandas对象:Series和DataFrame。
熊猫系列对象 (Pandas Series object)
Series is a fundamental data structure of Pandas. We can think of it as a one-dimensional array of indexed data.
系列是熊猫的基本数据结构。 我们可以将其视为索引数据的一维数组。
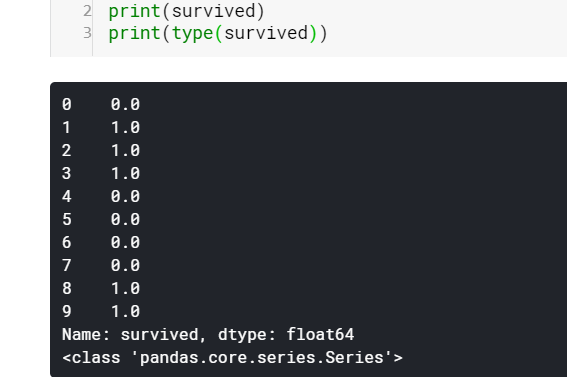
I have grabbed the ‘survived’ column from our dataset which is of type Series. I have converted the values of survived to float-point to differentiate between index and value. We can see it has a sequence of both index and value. Also, Series belongs to the class ‘pandas.core.series.Series’. We can access index and values separately with attribute index and values. Values are simply of type NumPy array and index is an array-like object of type pd.Index.
我从我们的数据集中获取了“生存”列,其类型为Series。 我已经将生存的值转换为浮点数,以区分索引和值。 我们可以看到它同时具有index和value的序列。 而且,Series属于类'pandas.core.series.Series'。 我们可以使用属性索引和值分别访问索引和值。 值只是NumPy数组类型,而index是pd.Index类型的类似数组的对象。

Just as NumPy we can access values of Series with it’s associated index by using square bracket notation.
就像NumPy一样,我们可以使用方括号表示法来访问Series的值及其关联的索引。
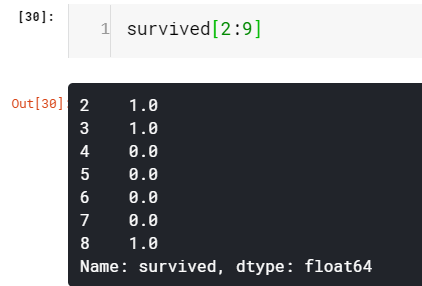
The essential difference between array and Series is that array have only an implicit index to access value while the series has an explicit index as well. The explicit indexing capability of Series gives an advantage, we can have an index of any type, the default is integer values as we have seen. Let’s see how we can change the integer index of our survived Series to string. Additionally, we will also learn how to create a Series object from scratch using an array(values of ‘survived’ which is of type array).
数组和序列之间的本质区别在于,数组仅具有用于访问值的隐式索引,而序列也具有显式索引。 Series的显式索引功能提供了一个优势,我们可以拥有任何类型的索引,如我们所见,默认值为整数值。 让我们看看如何将生存系列的整数索引更改为字符串。 此外,我们还将学习如何使用数组(值为array的'survived'值)从头创建Series对象。
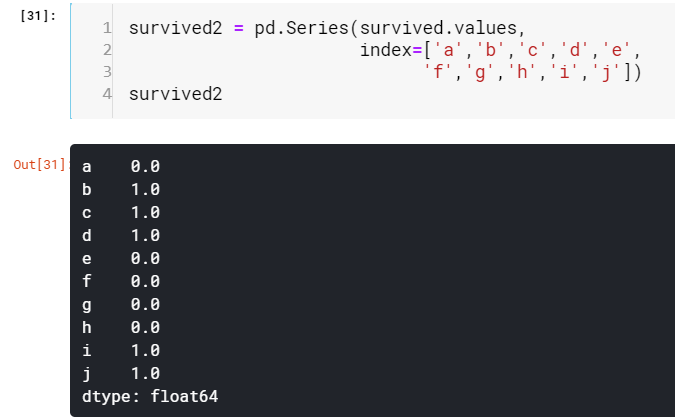
This also gives us scope to think series as an upgraded version on the Python dictionary.
这也使我们可以将系列视为Python词典的升级版本。
熊猫DataFrame对象 (Pandas DataFrame object)
Remember we raised a question in Figure-0 “what is the data type of 'df’?” You got it, ‘df’ is of type DataFrame. DataFrame is another fundamental data structure of Pandas. As we analogically said Series is a one-dimensional array with flexible indices, here, Pandas is a two-dimensional array with both flexible row and column indices. As multiple one-dimensional arrays gave birth to a two-dimensional array, multiple Series gave birth to DataFrame. Now scrolling back to Figure-0, we can see our entire dataset is of type DataFrame which has multiple Series commonly referred as columns of DataFrame.
记得我们在图0中提出了一个问题 :“ df”的数据类型是什么? 知道了,“ df”的类型为DataFrame。 DataFrame是Pandas的另一个基本数据结构。 正如我们以类推的方式说,Series是具有灵活索引的一维数组,在这里,Pandas是具有灵活行和列索引的二维数组。 随着多个一维数组产生一个二维数组, 多个Series产生了DataFrame 。 现在返回到图0,我们可以看到我们的整个数据集都是DataFrame类型,它具有多个Series,通常称为DataFrame的列。
Like Series, DataFrame has an index attribute and column attribute.
与Series一样,DataFrame具有索引属性和列属性。
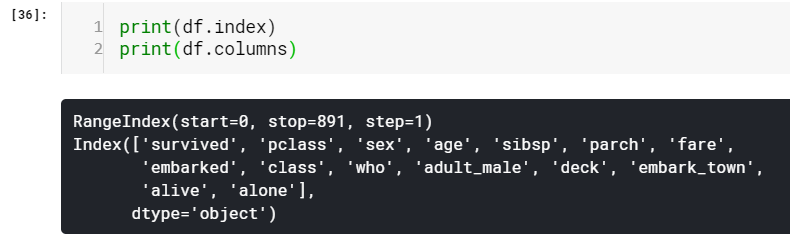
You can notice that columns are also of type pd.Index. Which means, we can access values using the column name just like any other Series or array. Exciting isn’t it! This is the power of DataFrame. Indeed, this is how I grabbed the values of column ‘survived’ in the Pandas Series object section.
您会注意到,列的类型也为pd.Index。 这意味着,我们可以像使用任何其他Series或数组一样使用列名访问值 。 令人兴奋的不是! 这就是DataFrame的强大功能。 确实,这就是我在Pandas Series对象部分中获取“幸存”列的值的方式。

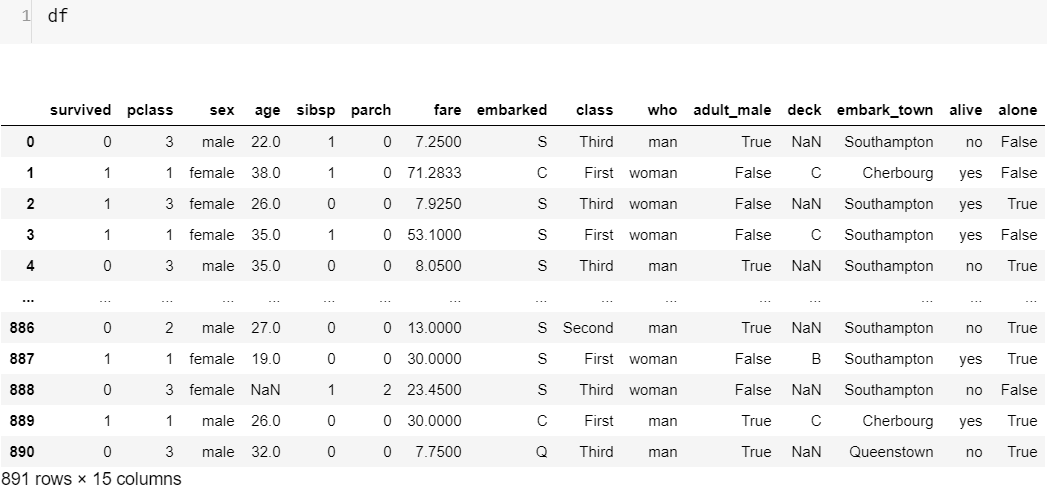
Let me reveal another secret, neither the Series ‘survived’ nor the DataFrame 'df' have 10 rows. Actually, they have 891 rows. This brings us back to our question from Figure-0 “and what on Earth is ‘df.head(10)’ ”. With the magic of the Pandas method head() we can display only the number of rows we pass as a parameter starting from the 1st row and the default value is 5. This is why all the way down we saw only 10 rows. The opposite is the method tail(). Our entire dataset looks like this:
让我透露另一个秘密,无论是“生存”系列还是DataFrame“ df”都没有10行。 实际上,它们有891行。 这使我们回到图-0中的问题 “以及'df.head(10)'在地球上是什么”。 借助Pandas方法head()的魔力,我们可以仅显示从第1行开始作为参数传递的行数,默认值为5。这就是为什么一路向下只能看到10行的原因。 相反的是方法tail()。 我们的整个数据集如下所示:
Although we can create a DataFrame from scratch we are not going to discuss because as a data scientist we rarely have to create any dataset.
尽管我们可以从头开始创建DataFrame,但我们不会讨论,因为作为数据科学家,我们几乎不必创建任何数据集。
数据选择 (Data selection)
While we can use the Python style square-brackets notation to index and select values from our DataFrame, Pandas provides a more powerful attribute called Indexers: loc and iloc. Pandas indexers have an advantage over the regular square-bracket style. They provide us the flexibility to index a DataFrame like any other NumPy array.
虽然我们可以使用Python样式的方括号符号来索引并从DataFrame中选择值,但Pandas提供了一个更强大的属性,称为Indexers:loc和iloc。 熊猫索引器比常规方括号样式具有优势。 它们使我们可以像其他任何NumPy数组一样灵活地为DataFrame编制索引。
iloc[ <row>, <column> ]
iloc [ < 行 >,<列>]
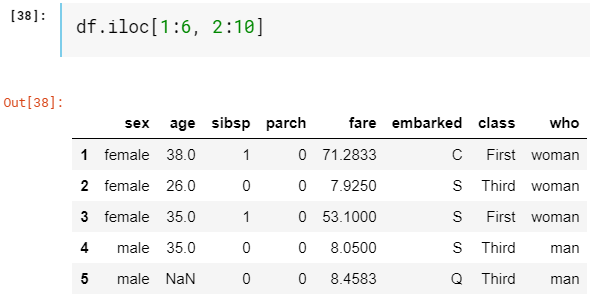
All DataFrames are indexed in two styles: explicit and implicit. We already know that we have column names survived, pclass, sex,… which act as explicit index but they are also indexed internally with integers starting from 0 just like any other Python list acting as an implicit index. Indexer iloc always refers to implicit indices. Although we have columns names we can slice them using integer indices. Let’s extract rows from 1–6 and columns from ‘sex’ to ‘who’.
所有DataFrame都有两种样式索引:显式和隐式。 我们已经知道我们有幸存的列名,pclass,sex等,它们充当显式索引,但它们也从内部以0开头的整数建立索引,就像其他Python列表充当隐式索引一样。 索引器iloc始终引用隐式索引。 尽管我们有列名,但我们可以使用整数索引对其进行切片。 让我们从1–6提取行,从'sex'到'who'提取列。
loc[ <row>, <column> ]
loc [<行>,<列>]
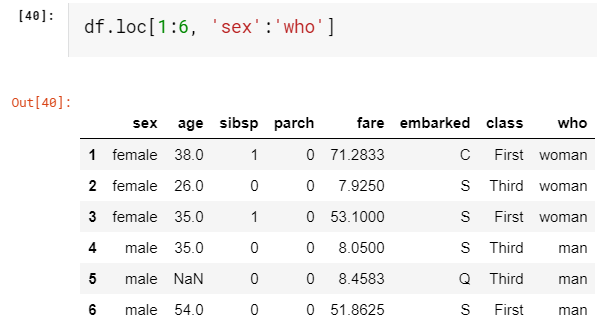
Same way, loc always refers to explicit indices. Let’s do the same thing as above with loc.
同样,loc始终引用显式索引。 让我们使用loc进行与上述相同的操作。
If you provide a column name for iloc or integer indices for loc it will throw an error.
如果提供iloc的列名或loc的整数索引,则会抛出错误。
We can perform many useful and complex operations using iloc and loc. Suppose we need to know the total number of kids and teenagers aged less than 20 who survived the disaster and were alone on the Titanic.
我们可以使用iloc和loc执行许多有用和复杂的操作。 假设我们需要知道在灾难中幸存下来且独自一人在泰坦尼克号上的未满20岁的儿童和青少年的总数。

处理缺失值/数据 (Handling missing values/data)
In real-world datasets, we can always find many missing values. This happens because not everyone provides all the information we need for our analysis or prediction, like a personal phone number. We also cannot discard the entire dataset or the column phone number from the dataset. In such cases, Pandas represents it as a NaN( not a number) and provides several methods for deleting, removing, and replacing them.
在实际数据集中,我们总是可以找到许多缺失值。 发生这种情况是因为并非每个人都提供我们进行分析或预测所需的所有信息,例如个人电话号码。 我们也不能丢弃整个数据集或该数据集中的列电话号码。 在这种情况下,Pandas将其表示为NaN(而不是数字),并提供了几种删除,删除和替换它们的方法。
- isnull()一片空白()
- notnull()notnull()
- dropna()dropna()
- fillna()fillna()
isnull()
一片空白()
Method isnull() returns us a boolean mask of the entire dataset in just one line of code. True if the value is missing and False otherwise.
方法nonull()仅用一行代码就向我们返回了整个数据集的布尔掩码。 如果该值丢失,则为True,否则为False 。

More insightful is to perform aggregation on it such as to see the total number of missing values in each column.
更有见地的是对它执行聚合,例如查看每列中缺失值的总数。

notnull()
notnull()
Method notnull() works the exact opposite of isnull(). False if the value is missing and True otherwise.
方法notnull()与isull()完全相反。 如果缺少该值,则为False;否则为True 。
dropna()
dropna()
Method dropna() is used to drop the missing values. The catch here is we cannot drop only the missing value, either we have to drop the column or row having the missing values. Axis parameters is used to mention if we wish to drop row(axis=0) or column(axis=1).
方法dropna()用于删除缺少的值。 这里的要点是我们不能只删除丢失的值,要么我们必须删除具有丢失值的列或行 。 如果要删除行(轴= 0)或列(轴= 1),则使用轴参数来提及。
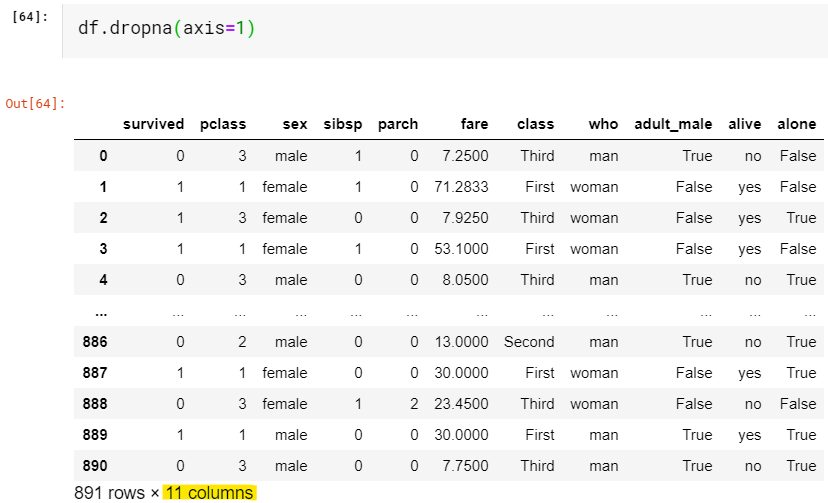
We just dropped all the columns having NaN values that are, ‘age’, ‘embarked’, ‘deck’, and ‘embark_town’. We can note the number of columns reduced from 15 to 11.
我们只删除了所有NaN值为“年龄”,“进站”,“甲板”和“ embark_town”的列。 我们可以注意到列数从15减少到11。
fillna()
fillna()
We just lost four critical features of our data ‘age’, ‘embarked’, ‘deck’, and ‘embark_town’. We cannot afford to lose such features just like that. So here comes the lifesaver method fillna(). With fillna() we can replace the NaN value with our desired value.
我们只是丢失了数据“年龄”,“进站”,“甲板”和“ embark_town”的四个关键特征。 我们不能像那样失去这些功能。 因此,出现了救生方法fillna()。 使用fillna()可以将NaN值替换为所需的值。
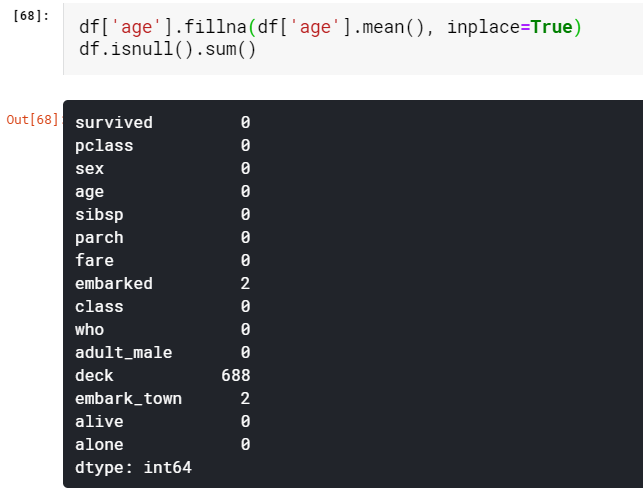
Here the critical decision will be to decide with what values we have to fill the missing values. In our case, the most sensible approach will be to fill the NaN values of age with a mean value of all the ages. Now we don’t have any missing values in our age column. The ability to decide what value to replace with will come with practice.
在这里,关键的决定将是决定用什么值来填补缺失的值。 在我们的案例中,最明智的方法是用所有年龄段的平均值填充年龄的NaN值。 现在,我们的“年龄”列中没有任何缺失的值。 决定替换为什么值的能力将随实践而定。
排序 (Sorting)
Sorting is another powerful tool by Pandas. Unlike list and array, DataFrames are sometimes not sorted by index as well. Hence, there are two types of sorting.
排序是熊猫提供的另一个强大工具。 与列表和数组不同,DataFrame有时也不会按索引排序。 因此,有两种类型的排序。
- Sort by index - sort_index()按索引排序-sort_index()
- Sort by value - sort_values()按值排序-sort_values()
Let us take a small section of data from our Titanic dataset with the help of indexing we learned to demonstrate sorting. I’m going to introduce another way of indexing called vector indexing where we can specify row and column name we want in any order as a list.
让我们借助我们学习来演示排序的索引,从Titanic数据集中获取一小部分数据。 我将介绍另一种索引方式,称为向量索引 ,其中我们可以以任意顺序将所需的行和列名称指定为列表。
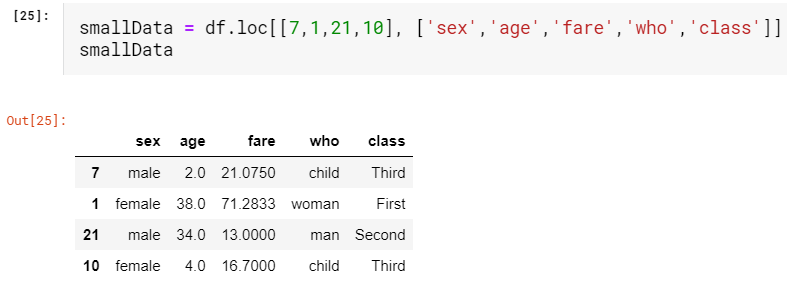
We notice that both our row index and column index are unsorted. Let’s try to sort them both. As we already know we use axis=0 for the row which is the default value and axis=1 for the column.
我们注意到我们的行索引和列索引都是未排序的。 让我们尝试对它们进行排序。 众所周知,我们对默认值的行使用axis = 0,对列使用axis = 1。

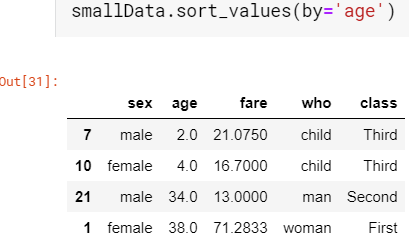
Sort by values is pretty self-explanatory, we just have to decide on which column values we need the sort which can be done with the help of ‘by’ parameter.
按值排序很容易解释,我们只需要确定哪些列值需要排序,就可以借助'by'参数来完成。
In case of conflicting values for example if two persons have the same age then who has to be on top can be decided by adding another level of sorting which can be accomplished by passing a list of column names in the ‘by’ parameter (Ex. smallData.sort_values(by=[‘age’, ‘fare’]). We can also specify the order of sorting using parameter ‘ascending=True’ and ‘ascending=Flase’.
在值冲突的情况下,例如,如果两个人的年龄相同,则可以通过添加另一级别的排序来确定必须位于最上面的人,这可以通过在'by'参数中传递列名列表来实现(例如smallData.sort_values(by = ['age','fare'])。我们还可以使用参数' ascending = True'和'ascending = Flase'指定排序顺序 。
排行 (Ranking)
We are seeing ranking since our 1st grade. We are always being ranked be it by our marks or our quarterly performance. Since ranking is widely used Pandas provide rank() method to ease our work. There exist few standard methods to rank like minimum, maximum, dense, and average. Let’s explore them.
自一年级以来,我们正在看到排名。 无论是我们的成绩还是季度业绩,我们始终被评为排名第一。 由于排名被广泛使用,熊猫提供了rank()方法来简化我们的工作。 很少有标准方法可以对最小值,最大值,密集和平均值进行排名。 让我们探索它们。
Suppose I wish to rank people who board the Titanic based on the fare they paid. For the ease of understanding, we will only look at the ‘survived’ and ‘fare’ column of our data and all methods of ranking next to it.
假设我希望根据他们所支付的票价对登上《泰坦尼克号》的人进行排名。 为了便于理解,我们将仅查看数据的“幸存”和“票价”列以及其旁边的所有排名方法。
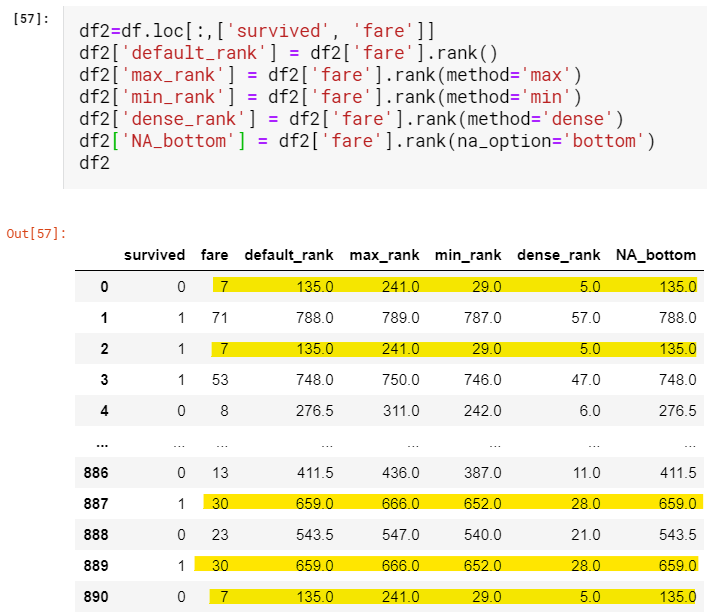
By default, ranking is done in ascending order. Method plays its part only when repeated values occur.
默认情况下,排名是按升序进行的。 仅当出现重复值时,方法才发挥作用。
- The default method is average. When values repeat the average of the positions is taken. In our case value 7 is repeated thrice and is ranked 135: (134+135+136)/3默认方法是平均值。 当值重复时,将获得位置的平均值。 在我们的情况下,值7重复三次,并且排名135:(134 + 135 + 136)/ 3
- In the max method the highest possible position is ranked. Since 7 is repeated thrice there is a competition between ranks 239,240 and 241, finally, 241 is assigned. Rank 239 and 240 are given to nobody.在最大方法中,对最高可能排名进行排名。 由于重复7次,所以在239,240和241之间存在竞争,最后分配了241。 等级239和240被给予任何人。
- The exact opposite is method min. For value 7 there is a competition between ranks 29,30 and 31 finally, 29 is assigned and the positions 30 and 31 are given to nobody.完全相反的是方法min。 对于值7,最终在等级29,30和31之间存在竞争,分配29,并且将排名30和31给予任何人。
- In the dense method, there is no competition between positions. It is exactly as min method but succeeding positions are not skipped, unlike min method.在密集方法中,职位之间没有竞争。 与min方法完全相同,但不跳过后续位置。
If you are reading this sentence, congratulations! You have learned more than the basics of Pandas. There are many more concepts to be covered which will be done in Unpacking Pandas for Data Science: Part 2. I will try my best to make it available as soon as possible.
如果您正在阅读这句话,那么恭喜! 您不仅学到了熊猫的基础知识。 在数据科学的熊猫解压缩:第2部分中 ,将涉及更多概念。我将尽我所能,尽快使它可用。
NumPy资源 (NumPy resources)
Let’s connect
让我们连接
翻译自: https://medium.com/swlh/unpacking-pandas-for-data-science-part-1-32e480ca1688
熊猫数据集
http://www.taodudu.cc/news/show-997491.html
相关文章:
- matplotlib可视化_使用Matplotlib改善可视化设计的5个魔术技巧
- 感知器 机器学习_机器学习感知器实现
- 快速排序简便记_建立和测试股票交易策略的快速简便方法
- 美剧迷失_迷失(机器)翻译
- 我如何预测10场英超联赛的确切结果
- 深度学习数据自动编码器_如何学习数据科学编码
- 图深度学习-第1部分
- 项目经济规模的估算方法_估算英国退欧的经济影响
- 机器学习 量子_量子机器学习:神经网络学习
- 爬虫神经网络_股市筛选和分析:在投资中使用网络爬虫,神经网络和回归分析...
- 双城记s001_双城记! (使用数据讲故事)
- rfm模型分析与客户细分_如何使用基于RFM的细分来确定最佳客户
- 数据仓库项目分析_数据分析项目:仓库库存
- 有没有改期末考试成绩的软件_如果考试成绩没有正常分配怎么办?
- 探索性数据分析(EDA):Python
- 写作工具_4种加快数据科学写作速度的工具
- 大数据(big data)_如何使用Big Query&Data Studio处理和可视化Google Cloud上的财务数据...
- 多元时间序列回归模型_多元时间序列分析和预测:将向量自回归(VAR)模型应用于实际的多元数据集...
- 数据分析和大数据哪个更吃香_处理数据,大数据甚至更大数据的17种策略
- 批梯度下降 随机梯度下降_梯度下降及其变体快速指南
- 生存分析简介:Kaplan-Meier估计器
- 使用r语言做garch模型_使用GARCH估计货币波动率
- 方差偏差权衡_偏差偏差权衡:快速介绍
- 分节符缩写p_p值的缩写是什么?
- 机器学习 预测模型_使用机器学习模型预测心力衰竭的生存时间-第一部分
- Diffie Hellman密钥交换
- linkedin爬虫_您应该在LinkedIn上关注的8个人
- 前置交换机数据交换_我们的数据科学交换所
- 量子相干与量子纠缠_量子分类
- 知识力量_网络分析的力量
熊猫数据集_为数据科学拆箱熊猫相关推荐
- 熊猫数据集_大熊猫数据框的5个基本操作
熊猫数据集 Tips and Tricks for Data Science 数据科学技巧与窍门 Pandas is a powerful and easy-to-use software libra ...
- 熊猫数据集_在日常生活中使用熊猫数据框
熊猫数据集 Before getting started let us do a quick revision, Pandas is a python library that gives elite ...
- 数据科学学习心得_学习数据科学时如何保持动力
数据科学学习心得 When trying to learn anything all by yourself, it is easy to lose motivation and get thrown ...
- 熊猫数据集_熊猫迈向数据科学的第一步
熊猫数据集 I started learning Data Science like everyone else by creating my first model using some machi ...
- 熊猫数据集_用熊猫掌握数据聚合
熊猫数据集 Data aggregation is the process of gathering data and expressing it in a summary form. This ty ...
- 熊猫数据集_处理熊猫数据框中的列表值
熊猫数据集 Have you ever dealt with a dataset that required you to work with list values? If so, you will ...
- 熊猫数据集_对熊猫数据框使用逻辑比较
熊猫数据集 P (tPYTHON) Logical comparisons are used everywhere. 逻辑比较随处可见 . The Pandas library gives you a ...
- 数据科学学习心得_学习数据科学
数据科学学习心得 苹果 | GOOGLE | 现货 | 其他 (APPLE | GOOGLE | SPOTIFY | OTHERS) Editor's note: The Towards Data S ...
- 熊猫数据集_熊猫迈向数据科学的第三部分
熊猫数据集 Data is almost never perfect. Data Scientist spend more time in preprocessing dataset than in ...
最新文章
- ruby中DBI连接MySQL数据库步骤详解
- 判断一个点是否在指定三角形内(1)
- C++计算实时输入数据的统计信息实现算法(附完整源码)
- Mysql(6)——数据库中表相关操作(2)
- 在linux上使用ASP
- [导入]从函数RND的使用想到的!
- 在windows Console 平台下面 用glut编写 opengl程序 注意
- 【编程题目】对于一个整数矩阵,存在一种运算,对矩阵中任意元素加一时,需要其相邻(上下左右)某一个元素也加一...
- 投资为什么很难进步——越不懂 越自信︱投资道
- [2018.10.13 T2] 工作计划
- 必看CSDN积分获取方法
- 【经验分享】PC端免费高效的同声翻译
- 怎么在win7上安装AIR780E的USB驱动
- 大学计算机实践教程在线阅读,计算机基础实践教程.pdf
- ClickHouse遇见RoaringBitmap
- android和ios手机换行,ios label中文与数字混合导致换行解决
- 04-小键盘字母u输出为4的问题
- oracle 查询字符代码dump,字符集问题(Linux、oracle、终端等,导入导出数据)
- 【动网论坛7.1 sp1 修改】-修改搜一搜为其他搜索的方法
- 银河麒麟V10 SP2 搭建tftp服务