无监督学习 | DBSCAN 原理及Sklearn实现
文章目录
- 1. 密度聚类
- 2. DBSCAN
- 2.1 算法原理
- 3. DBSCAN 优缺点
- 3.1 优点
- 3.2 缺点
- 3.3 与 KMeans 比较
- 4. SKlearn 实现
- 5. 在线可视化 DBSCAN
- 参考文献
相关文章:
机器学习 | 目录
机器学习 | 聚类评估指标
机器学习 | 距离计算
无监督学习 | KMeans 与 KMeans++ 原理
无监督学习 | GMM 高斯混合聚类原理及Sklearn实现
1. 密度聚类
密度聚类亦称“基于密度的聚类”(Density-Based Clustering),此类算法假设聚类结构能通过样本分布的紧密程度确定。通常情况下,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇以获得最终的聚类结果[1]。这类算法可以克服 KMeans、BIRCH等只适用于凸样本集的情况。
常用的密度聚类算法:DBSCAN、MDCA、OPTICS、DENCLUE等。[2]
密度聚类的主要特点是:
(1)发现任意形状的簇
(2)对噪声数据不敏感
(3)一次扫描
(4)需要密度参数作为停止条件
(5)计算量大、复杂度高
2. DBSCAN
DBSCAN(具有噪声的基于密度的空间聚类,Density-Based Spatial Clustering of Applications with Noise)是一种著名的密度聚类算法,它基于一组“邻域”(neighborhood)参数(ε,MinPts\varepsilon, MinPtsε,MinPts)来刻画样本分布的紧密程度。
首先我们通过一个简单的例子来介绍 DBSCAN,对于以下数据,我们任意选取一个点,定义一个以 ϵ\epsilonϵ 为半径的邻域,若邻域内没有其他点,则这个点定义为噪声或异常点。
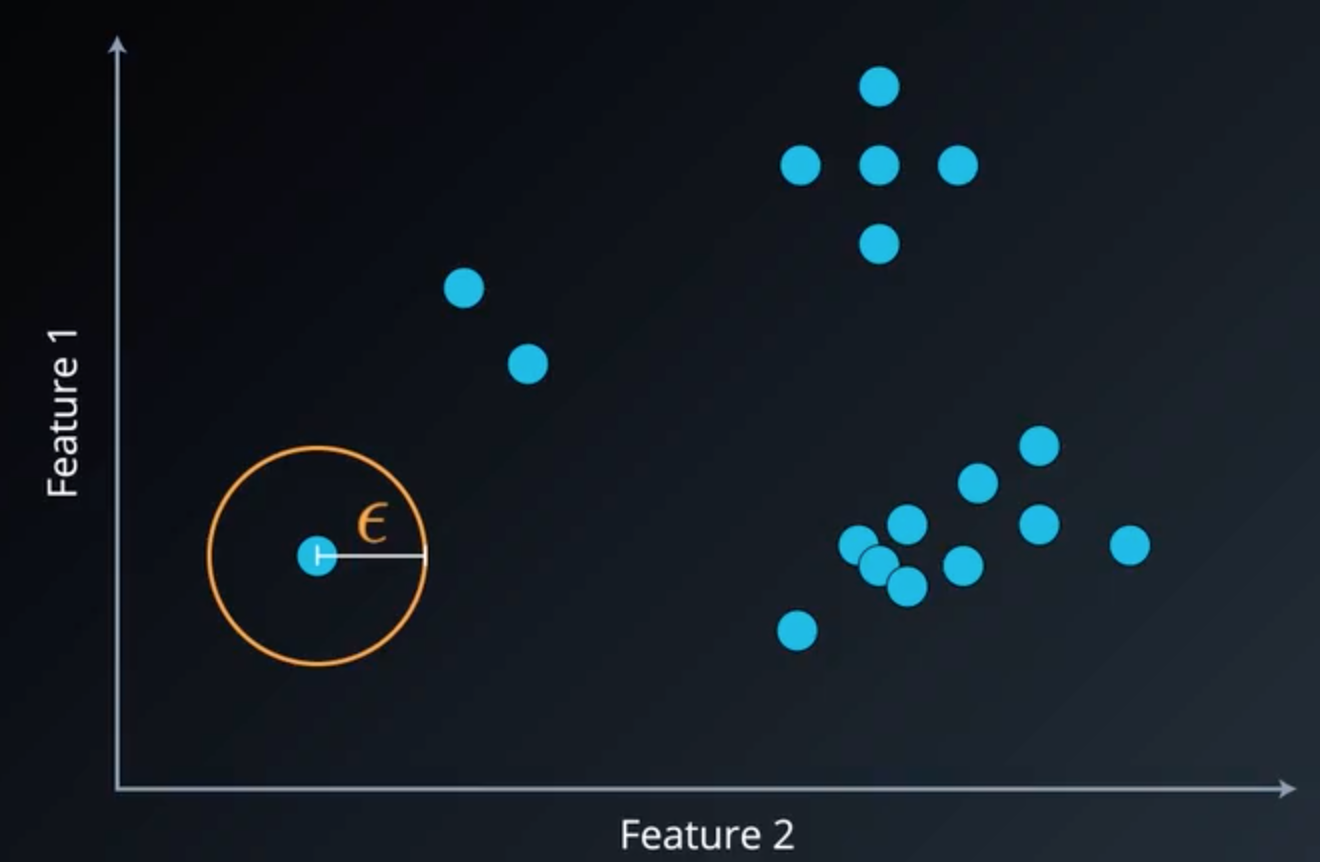 图1 邻域半径及噪声点
图1 邻域半径及噪声点
若这个点不是噪声,则考虑第二个参数:邻域内最少样本个数 MinPtsMinPtsMinPts,若某点邻域内最少样本个数不少于 MinPtsMinPtsMinPts,则这个点定义为核心点。对于该邻域内的非核心对象,定义为边界点,假设 MinPtsMinPtsMinPts=5 ,则聚类过程如下图所示:
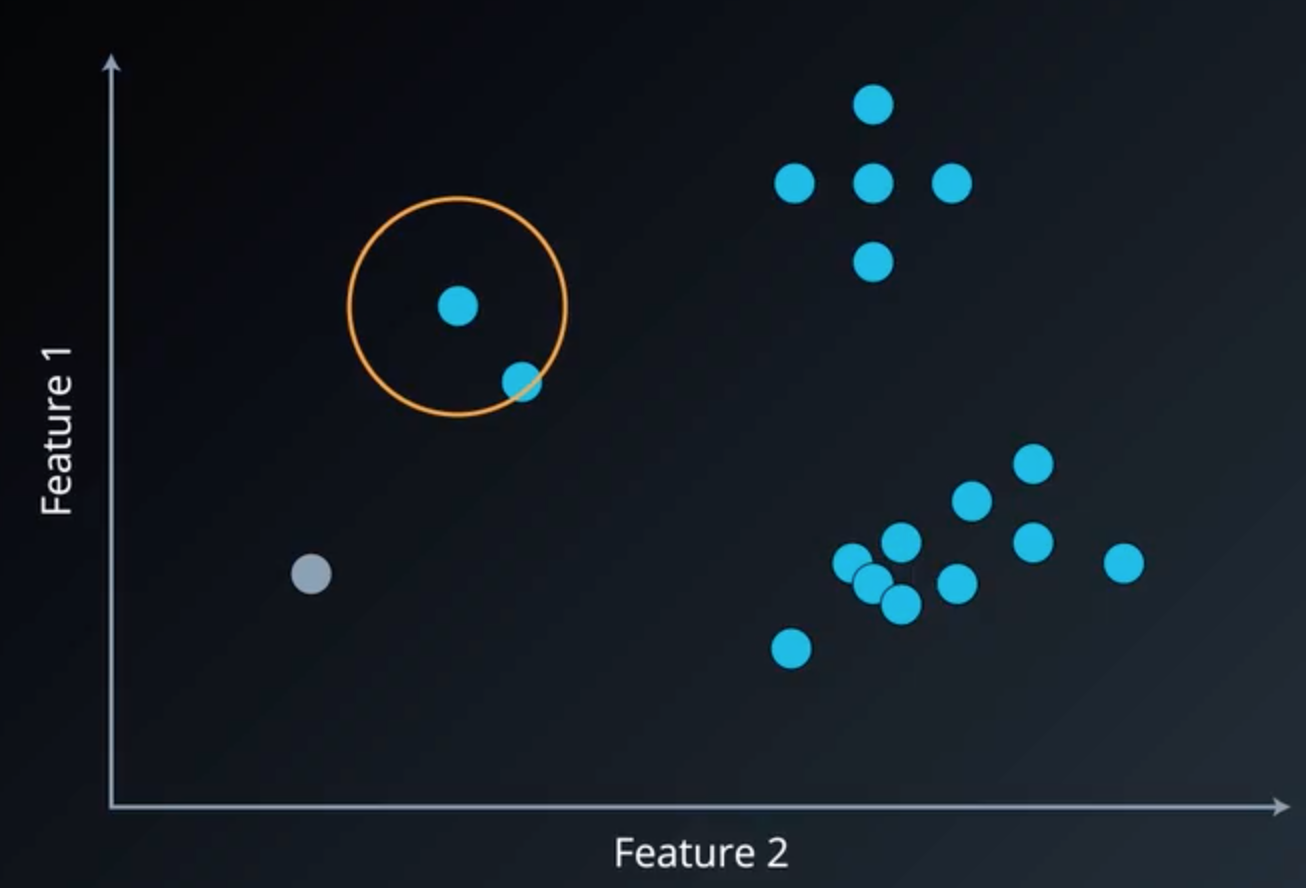 图2 邻域内样本个数少于最少个数
图2 邻域内样本个数少于最少个数 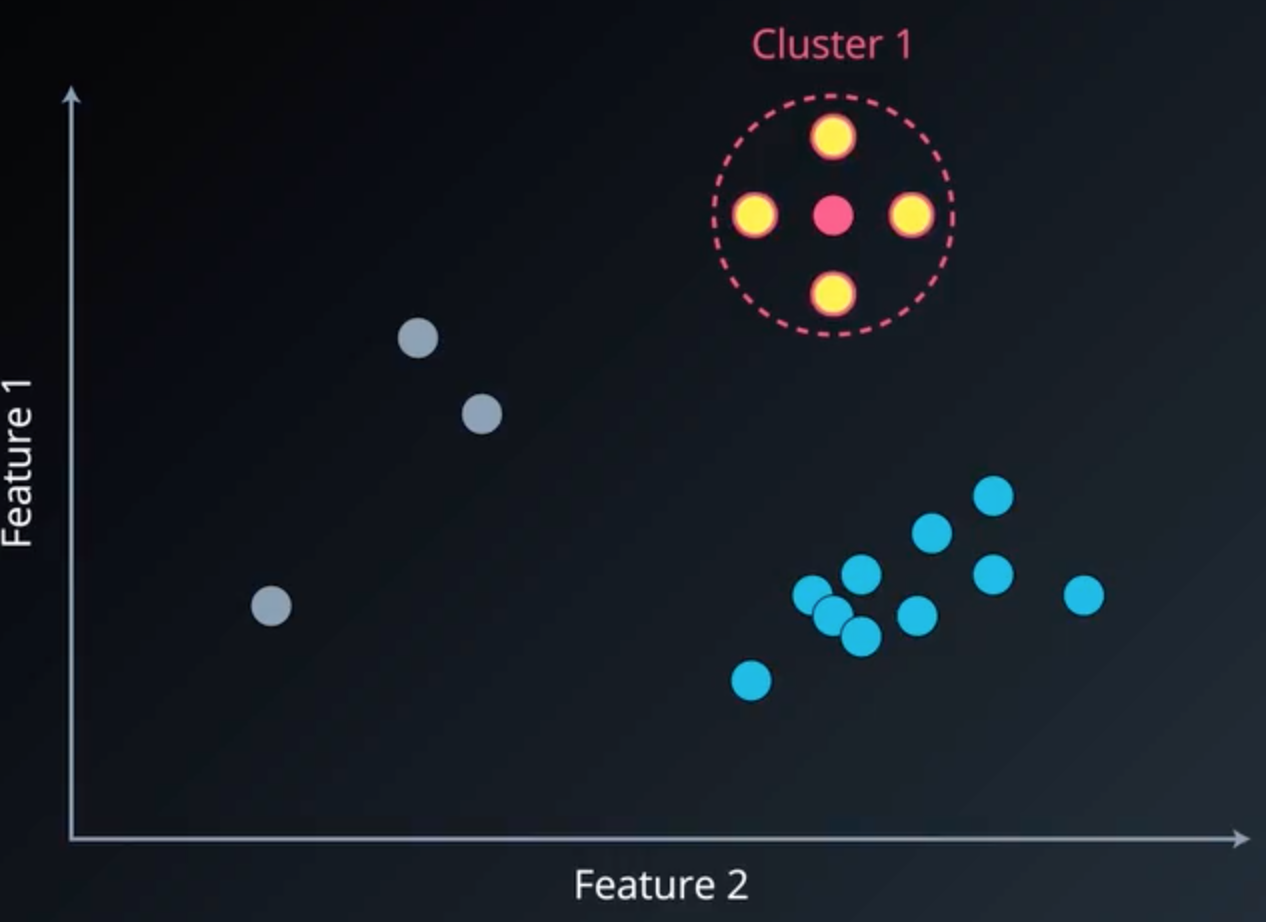 图3 核心点与边界点
图3 核心点与边界点
同理,继续扫描其余的点,可得其他簇:
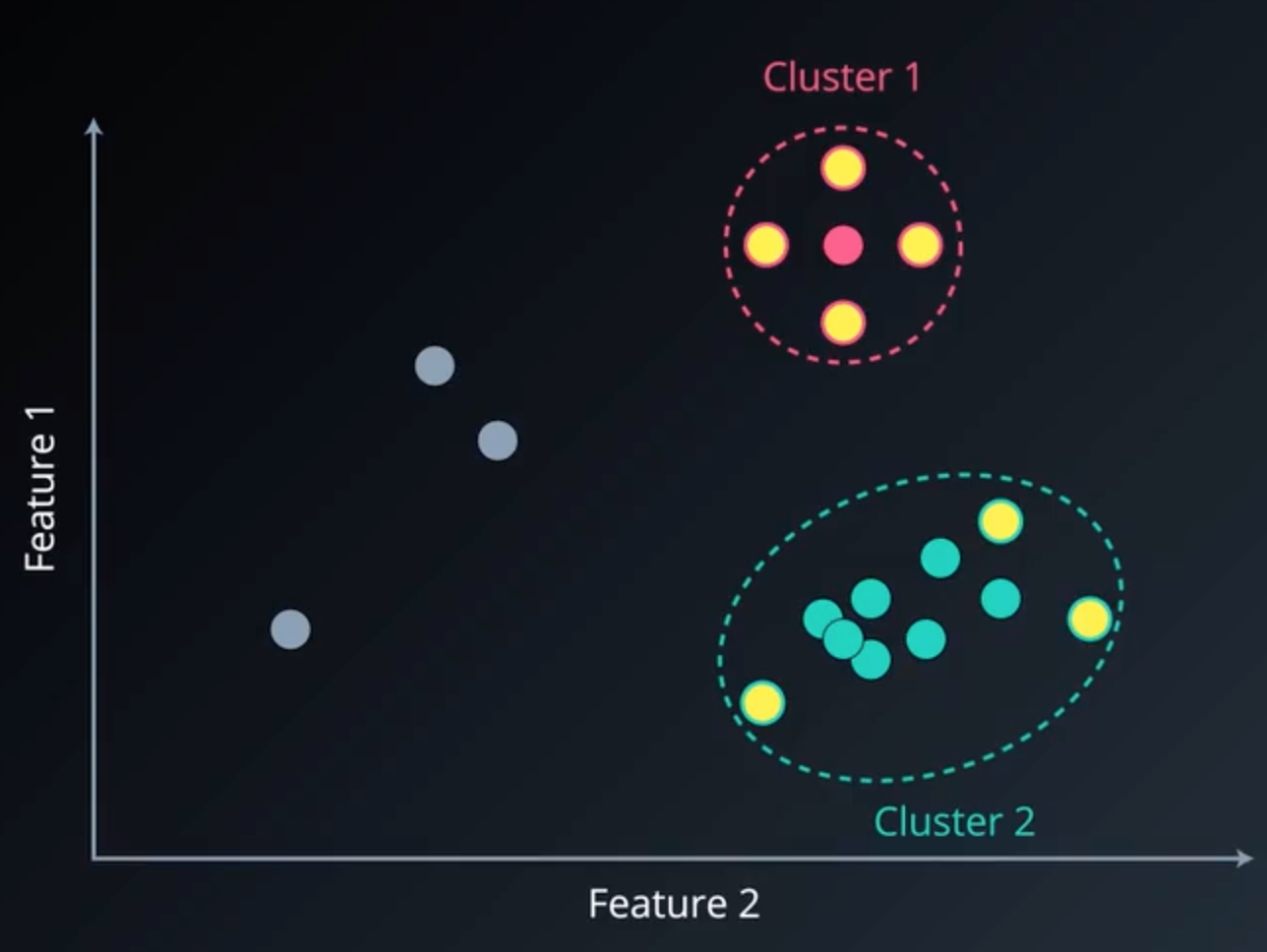 图4 两个不同的聚类簇
图4 两个不同的聚类簇
下面,我们将通过严格的数学定义,来描述 DBSCAN 聚类算法。
2.1 算法原理
首先,给定数据集 D={x1,x2,...,xm}D=\{x_1,x_2,...,x_m\}D={x1,x2,...,xm},我们定义下面几个概念:
ϵ\epsilonϵ 邻域:对 xj∈Dx_j \in Dxj∈D,其 ϵ\epsilonϵ 邻域包含数据集 DDD 中与 xjx_jxj 的距离不大于 ϵ\epsilonϵ 的样本,即 Nϵ={xo∈D∣dist(xi,xj≤ϵ)}N_{\epsilon}=\{x_o \in D| dist(x_i,x_j \leq \epsilon) \}Nϵ={xo∈D∣dist(xi,xj≤ϵ)};
核心对象(core object):若 xjx_jxj 的 ε\varepsilonε 邻域至少包含 MinPtsMinPtsMinPts 个样本,即 ∣Nϵ(xj)≥MinPts∣|N_{\epsilon}(x_j) \geq MinPts|∣Nϵ(xj)≥MinPts∣,则 xjx_jxj 是一个核心对象;
密度直达(directly density-reachable):若 xjx_jxj 位于 xix_ixi 的 ϵ\epsilonϵ 邻域中,且 xix_ixi 是核心对象,则称 xjx_jxj 由 xix_ixi 密度直达;
密度可达(density-reachable):对 xix_ixi 与 xjx_jxj,若存在样本序列 p1,p2,...,pnp_1,p_2,...,p_np1,p2,...,pn,其中 p1=xi,pn=xjp_1 = x_i,p_n=x_jp1=xi,pn=xj 且 pi+1p_{i+1}pi+1 由 pip_ipi 密度直达,则称 xix_ixi 由 xjx_jxj 可达;
密度相连(density-connected):对 xix_ixi 与 xjx_jxj,若存在 xkx_kxk 使得 xix_ixi 与 xjx_jxj 均由 xkx_kxk 密度可达,则称 xix_ixi 与 xjx_jxj 密度相连。
对于邻域中的距离函数 dist(⋅,⋅),在默认情形下设为欧式距离。
下图给出了上述概念的直观显示,假设 MinPts=3MinPts=3MinPts=3:虚线显示出 ϵ\epsilonϵ 邻域,x1x_1x1 是核心对象, x2x_2x2 由 x1x_1x1 密度直达,x3x_3x3 由 x1x_1x1 密度可达,x3x_3x3 与 x4x_4x4 密度相连。
 图4 样本点划分示意图
图4 样本点划分示意图
基于这些概念,DBSCAN 将“簇”定义为:密度可达关系导出的最大的密度相连样本集合。形式化地说,给定邻域参数(ϵ,MinPts\epsilon,MinPtsϵ,MinPts),簇 C⊆DC \subseteq DC⊆D 是满足以下性质的非空样本子集:
连接性(connectivity):xi∈C,xj∈C⇒xi与xj密度相连(1)连接性(connectivity):x_i \in C,x_j \in C \Rightarrow x_i 与 x_j 密度相连 \tag{1} 连接性(connectivity):xi∈C,xj∈C⇒xi与xj密度相连(1)
最大性(maximality):xi∈C,xj由xi密度可达⇒xj∈C(2)最大性(maximality):x_i \in C,x_j 由 x_i 密度可达 \Rightarrow x_j \in C \tag{2}最大性(maximality):xi∈C,xj由xi密度可达⇒xj∈C(2)
若 xxx 为核心对象,则 xxx 密度可达的所有样本组成的集合记为 X={x′∈D∣x′由x密度可达}X=\{x' \in D| x' 由 x 密度可达\}X={x′∈D∣x′由x密度可达},其中 XXX 为满足连接性和最大性的簇。
于是,DBSCAN 算法先任选数据集中的一个核心对象为“种子”(seed),再由此出发确定相应的聚类簇。
算法描述如下图所示,
在第 1-7 行中,算法先根据给定的邻域参数(ϵ,MinPts\epsilon,MinPtsϵ,MinPts)找出所有核心对象;
在第 10-24 行中,以任一核心对象为出发点,找出由密度可达的样本以生成聚类簇,知道所有核心对象均被访问过为止。
 图5 DBSCAN 算法
图5 DBSCAN 算法
3. DBSCAN 优缺点
3.1 优点
(1)不用指明类别数量;
(2)能灵活找到并分离各种形状和大小的类;
(3)能很好地处理噪声和离群点。
3.2 缺点
(1)对于从两个类均可达的边界点,由于各个点是被随机访问的,因此 DBSCAN 不能保证每次都返回相同聚类;
(2)在不同密度的类方面有一定难度。
3.3 与 KMeans 比较
从下面的图中可以看出,DBSCAN 在不规则的数据上,能更好地分类。
 图6 DBCASAN 与 KMeans 聚类效果比较
图6 DBCASAN 与 KMeans 聚类效果比较
4. SKlearn 实现
sklearn.cluster.DBSCAN(eps=0.5, min_samples=5, metric=’euclidean’, metric_params=None, algorithm=’auto’, leaf_size=30, p=None, n_jobs=None)
eps : float, optional 【ϵ\epsilonϵ】
The maximum distance between two samples for one to be considered as in the neighborhood of the other. This is not a maximum bound on the distances of points within a cluster. This is the most important DBSCAN parameter to choose appropriately for your data set and distance function.
min_samples : int, optional 【MinPtsMinPtsMinPts】
The number of samples (or total weight) in a neighborhood for a point to be considered as a core point. This includes the point itself.
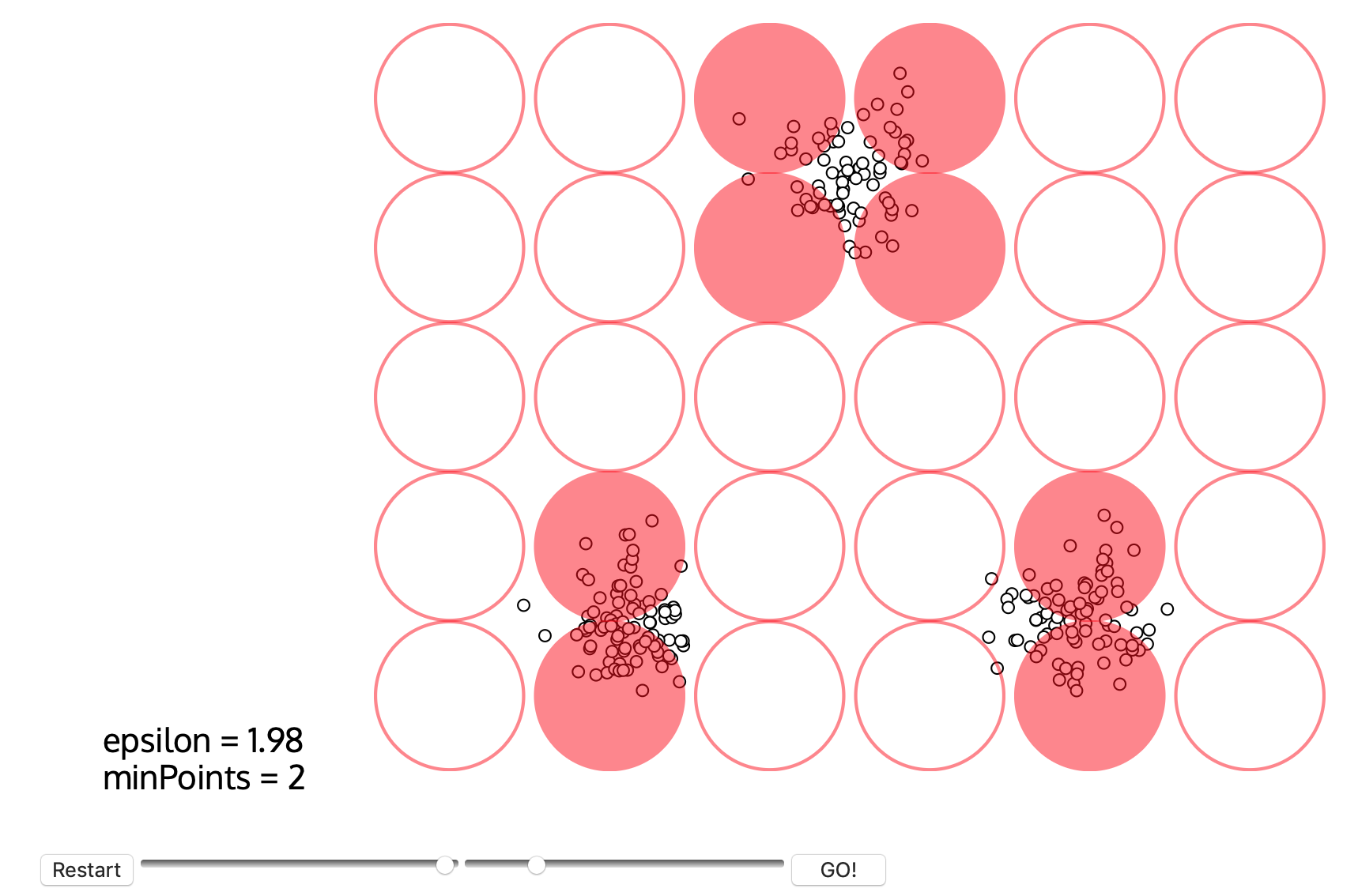
5. 在线可视化 DBSCAN
你可以通过这个网站选择样本分布和参数,并在线可视化 DBSCAN 聚类的过程。
参考文献
[1] 周志华. 机器学习[M]. 北京: 清华大学出版社, 2016: 211.
[2] liuy9803.机器学习之密度聚类算法[EB/OL].https://blog.csdn.net/liuy9803/article/details/80812489, 2018-06-26 .
无监督学习 | DBSCAN 原理及Sklearn实现相关推荐
- [Python人工智能] 十五.无监督学习Autoencoder原理及聚类可视化案例详解
从本专栏开始,作者正式研究Python深度学习.神经网络及人工智能相关知识.前一篇文章详细讲解了循环神经网络LSTM RNN如何实现回归预测,通过sin曲线拟合实现如下图所示效果.本篇文章将分享无监督 ...
- 无监督学习 | 层次聚类 之凝聚聚类原理及Sklearn实现
文章目录 1. 层次聚类 1.1 凝聚聚类 1.2 层次图 1.3 不同凝聚算法比较 2. Sklearn 实现 2.1 层次图可视化 参考文献 相关文章: 机器学习 | 目录 机器学习 | 聚类评估 ...
- 无监督学习 | GMM 高斯混合聚类原理及Sklearn实现
文章目录 1. 高斯混合聚类 1.1 高斯混合分布 1.2 参数求解 1.3 EM 算法 2. Sklearn 实现 参考文献 相关文章: 机器学习 | 目录 机器学习 | 聚类评估指标 机器学习 | ...
- 无监督学习 | KMeans与KMeans++原理
文章目录 1. 原型聚类 1.1 KMeans 1.1.1 最小化成本函数 1.1.2 实例 1.2 KMeans++ 1.2.1 KMeans++ 初始化实例 2. 在线可视化 KMeans 参考资 ...
- 技术+案例详解无监督学习Autoencoder
摘要:本篇文章将分享无监督学习Autoencoder的原理知识,然后用MNIST手写数字案例进行对比实验及聚类分析. 本文分享自华为云社区<[Python人工智能] 十五.无监督学习Autoen ...
- 无监督学习 | KMeans之Sklearn实现:电影评分聚类
文章目录 1. KMeans in Sklearn 2. Sklearn 实例:电影评分的 k 均值聚类 2.1 数据集概述 2.2 二维 KMeans 聚类 3. 肘部法选取最优 K 值 4. 多维 ...
- 监督学习 | 线性分类 之Logistic回归原理及Sklearn实现
文章目录 1. Logistic 回归 1.1 Logistic 函数 1.2 Logistic 回归模型 1.2.1 模型参数估计 2. Sklearn 实现 参考资料 相关文章: 机器学习 | 目 ...
- 监督学习 | 线性回归 之正则线性模型原理及Sklearn实现
文章目录 1. 正则线性模型 1.1 Ridge Regression(L2) 1.1.1 Sklearn 实现 1.1.2 Ridge + SDG 1.1.2.1 Sklearn 实现 1.2 La ...
- 监督学习 | 非线性回归 之多项式回归原理及Sklearn实现
文章目录 1. 多项式回归 2. Sklearn 实现 参考资料 相关文章: 机器学习 | 目录 机器学习 | 回归评估指标 监督学习 | 线性回归 之多元线性回归原理及Sklearn实现 监督学习 ...
最新文章
- 区块链应用和法律规范
- Dubbo的总体架构
- python做ui自动化_[python]RobotFramework自定义库实现UI自动化
- busmaster 使用教程_Busmaster使用.pdf
- mongodb简单的函数
- SqlServer 时间格式化
- linux-centos7 关机命令、系统目录结构介绍
- ES6 import export
- authentication method mysql 8.0查询_mysql 索引整理
- 前端清单之Vue.js篇
- 冬日暖阳,侯捷畅谈技术人生与读书感悟
- Java web ch02_3
- 自媒体运营,你要的小工具来了
- 深圳大学移动互联网应用期末大作业——垃圾分类app
- 华硕Y450拆机清灰、拆下光驱助散热、卸载无用软件
- ubuntu更新源出现错误
- 欢迎莅临HPX华南理工大学——产品经理职业规划讲座
- 吉林大学微型计算机试卷,吉林大学全真预测试卷及答案
- Kubernetes(k8s)基础之二:容器编排介绍及概念
- X版Dr.COM校园网使用路由器上网