无监督学习 | 层次聚类 之凝聚聚类原理及Sklearn实现
文章目录
- 1. 层次聚类
- 1.1 凝聚聚类
- 1.2 层次图
- 1.3 不同凝聚算法比较
- 2. Sklearn 实现
- 2.1 层次图可视化
- 参考文献
相关文章:
机器学习 | 目录
机器学习 | 聚类评估指标
机器学习 | 距离计算
无监督学习 | KMeans 与 KMeans++ 原理
无监督学习 | DBSCAN 原理及Sklearn实现
无监督学习 | GMM 高斯混合聚类原理及Sklearn实现
1. 层次聚类
层次聚类(hierarchical clustering)试图在不同层次对数据集进行划分,从而形成树形的聚类结构。数据集的划分可采用“自底向上”的聚合策略,也可采用“自顶向下”的分拆策略。[1]
因此其优点是可以层次化聚类,将聚类结构视觉化;而缺点是计算量大,我们将在后面提到这一点。
1.1 凝聚聚类
凝聚聚类(Agglomerative Clustering)是一种采用自底向上聚类策略的层次聚类算法。它先将数据集中的每个样本看作一个初始聚类簇,然后在算法运行的每一步中找出距离最近的两个聚类簇进行合并。该过程不断重复,直到达到预设的聚类簇个数。这里的关键是如何计算聚类簇之间的距离。实际上,每个簇是一个样本集合,因此,只需要采用关于集合的某种距离即可。例如,给定聚类簇 CiC_iCi 与 CjC_jCj,可通过下面的式子来计算距离:
最小距离:dmin(Ci,Cj)=minx∈Ci,z∈Cjdist(x,z)(1)最小距离:d_{\min }\left(C_{i}, C_{j}\right)=\min _{\boldsymbol{x} \in C_{i}, \boldsymbol{z} \in C_{j}} \operatorname{dist}(\boldsymbol{x}, \boldsymbol{z}) \tag{1}最小距离:dmin(Ci,Cj)=x∈Ci,z∈Cjmindist(x,z)(1)
最大距离:dmax(Ci,Cj)=maxx∈Ci,z∈Cjdist(x,z)(2)最大距离:d_{\max }\left(C_{i}, C_{j}\right)=\max _{\boldsymbol{x} \in C_{i}, \boldsymbol{z} \in C_{j}} \operatorname{dist}(\boldsymbol{x}, \boldsymbol{z}) \tag{2}最大距离:dmax(Ci,Cj)=x∈Ci,z∈Cjmaxdist(x,z)(2)
平均距离:davg(Ci,Cj)=1∣Ci∣∣Cj∣∑x∈Ci∑z∈Cjdist(x,z)(3)平均距离:d_{\operatorname{avg}}\left(C_{i}, C_{j}\right)=\frac{1}{\left|C_{i}\right|\left|C_{j}\right|} \sum_{\boldsymbol{x} \in C_{i}} \sum_{\boldsymbol{z} \in C_{j}} \operatorname{dist}(\boldsymbol{x}, \boldsymbol{z}) \tag{3}平均距离:davg(Ci,Cj)=∣Ci∣∣Cj∣1x∈Ci∑z∈Cj∑dist(x,z)(3)
显然,最小距离由两个簇的最近样本决定,最大距离由两个簇的最远样本决定,而平均距离则由两个簇的所有样本共同决定。
此外,也可以使用离差平方和 ESS(Error Sum of Squares)来进行聚类,通过最小化聚类前后的离方平方和之差 Δ(Ci,Cj)\Delta(C_i,C_j)Δ(Ci,Cj),来寻找最近的簇。[2]
离差平方和:ESS=∑i=1nxi2−1n(∑i=1nxi)2(4)离差平方和:ESS=\sum_{i=1}^n x_i^2-\frac{1}{n}\big(\sum_{i=1}^n x_i\big)^2 \tag{4}离差平方和:ESS=i=1∑nxi2−n1(i=1∑nxi)2(4)
Δ(Ci,Cj)=ESS(Ci∪Cj)−ESS(Ci)−ESS(Cj)(5)\Delta(C_i,C_j)=ESS(C_i \cup C_j)-ESS(C_i)-ESS(C_j) \tag{5}Δ(Ci,Cj)=ESS(Ci∪Cj)−ESS(Ci)−ESS(Cj)(5)
当聚类簇距离由 dmind_{min}dmin、dmaxd_{max}dmax、davgd_{avg}davg 或 Δ(Ci,Cj)\Delta(C_i,C_j)Δ(Ci,Cj) 计算时,凝聚聚类算法被相应地称为单链接(single-linkage)、全链接(complete-linkage))、均链接(average-linkage)和 Ward-linkage 算法。
凝聚聚类算法描述如下图所示:
在第 1-9 行,算法先对仅包含一个样本的初始聚类簇和相应的距离矩阵进行初始化;
在第 11-23 行,凝聚算法不断合并距离最近的聚类簇,并对合并得到的聚类簇的距离矩阵进行更新;
上述过程不断重复,直到达到预设的聚类簇数。
 图1 凝聚聚类算法
图1 凝聚聚类算法
1.2 层次图
下面以单链接为例子,介绍层次聚类的层次图(系统图,dendrogram)。假设我们有以下八个点,使用单链接聚为 3 个类。
首先将每个点设为一个单独的簇类,因此此时有 8 个簇,大于预期 3 个簇,故需要继续进行聚类。
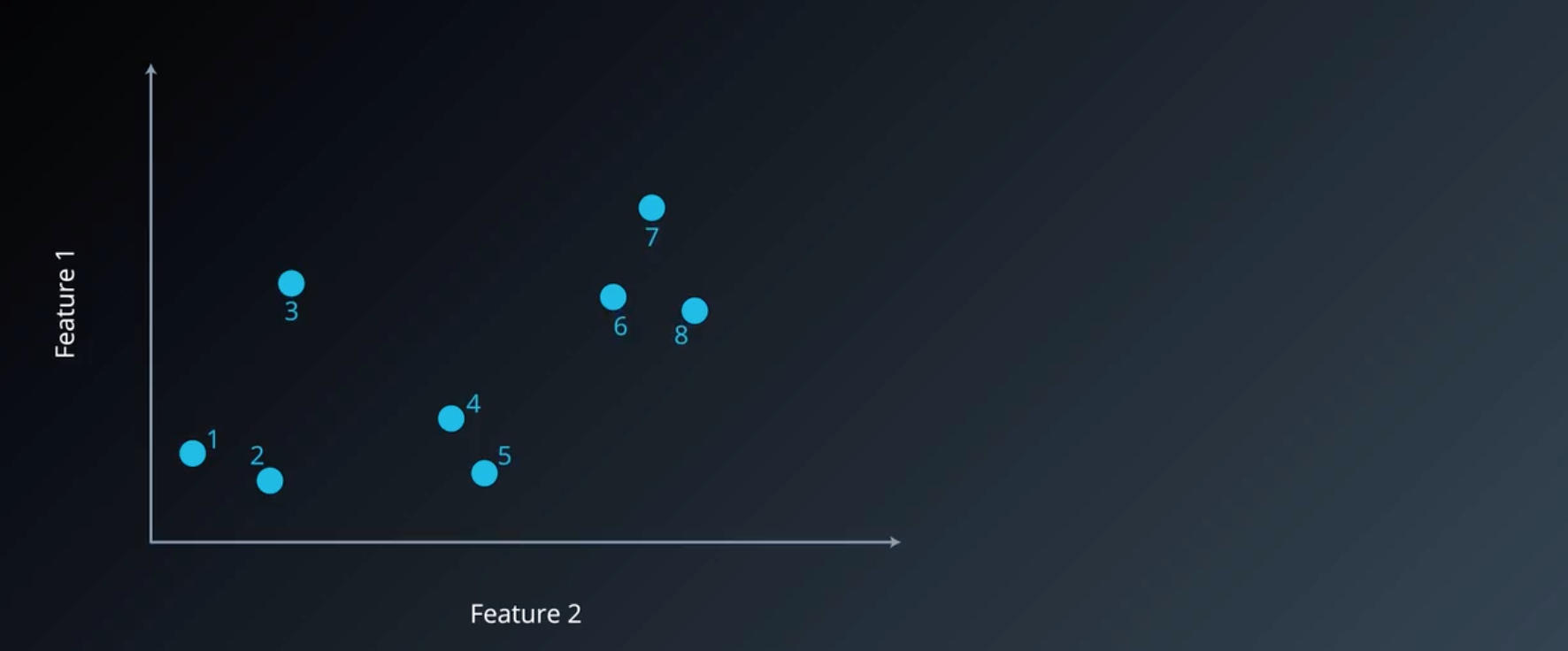 图2 初始化聚类簇
图2 初始化聚类簇
因此我们重复算法 11-23 行 3 次,每次将距离最近的两个样本聚为同一簇,对应右图的层次图。此时仍剩下 5 个簇,因此需要继续进行聚类。
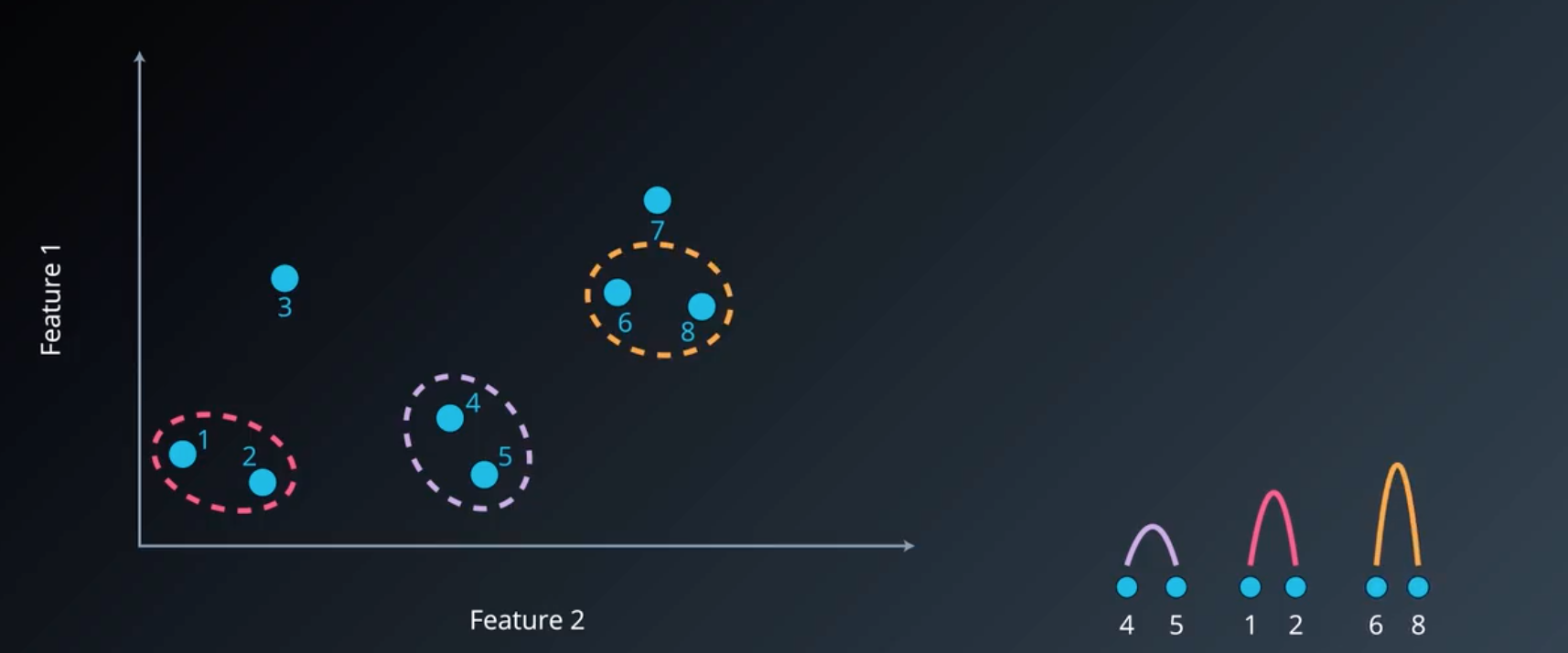 图3 5个聚类簇
图3 5个聚类簇
可以看到,此时样本 7 与簇 {6,8} 的距离(distmin=dist(6,7)dist_{min}=dist(6,7)distmin=dist(6,7))最近,因此可以将他们聚为一簇,如下图所示:
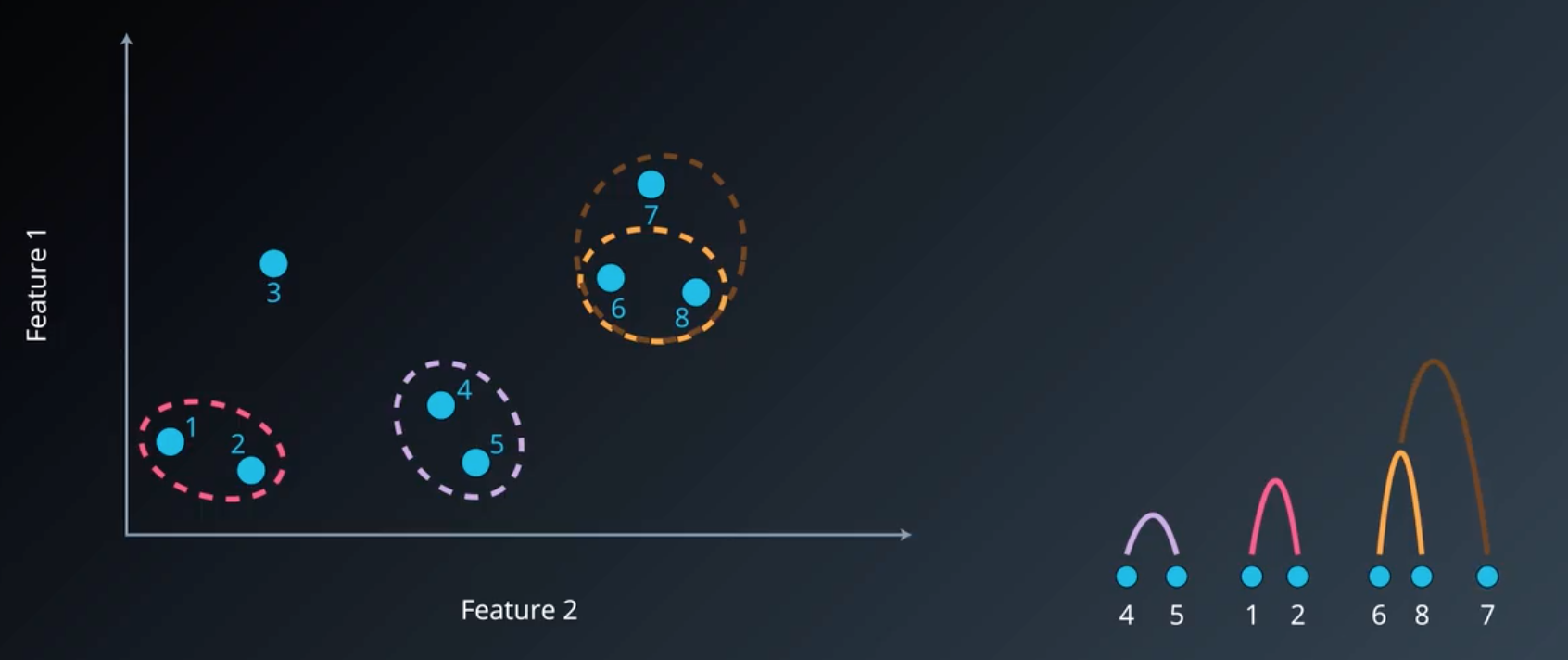 图4 4个聚类簇
图4 4个聚类簇
同理,继续进行聚类,考虑各个簇之间的距离,可以看出,样本 3 与簇 {4,5} 的距离(distmin=dist(3,4)dist_min=dist(3,4)distmin=dist(3,4))最近,因此有:
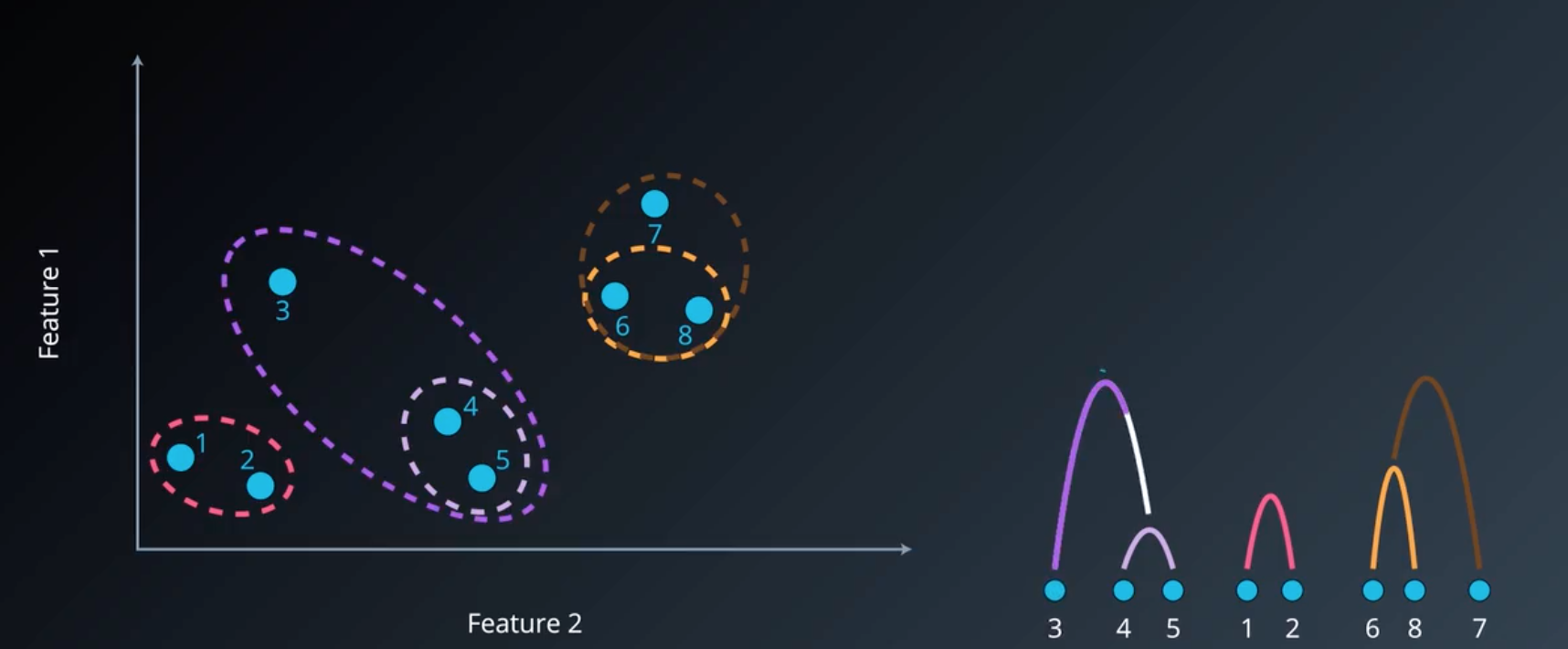 图5 3个聚类簇
图5 3个聚类簇
此时已经达到了我们所要求的聚类簇数,故算法停止,对应的层次图如右方所示。
1.3 不同凝聚算法比较
通过下面图片,我们可以看到各类凝聚算法在不同类型数据上的聚类效果,
需要注意的是,由于单链接和全链接只考虑簇中两个代表性的点,故受噪声和异常点影响大;而单链接容易出现一个簇囊括大多数样本(左下方图),而全链接则比单链接更紧凑些。
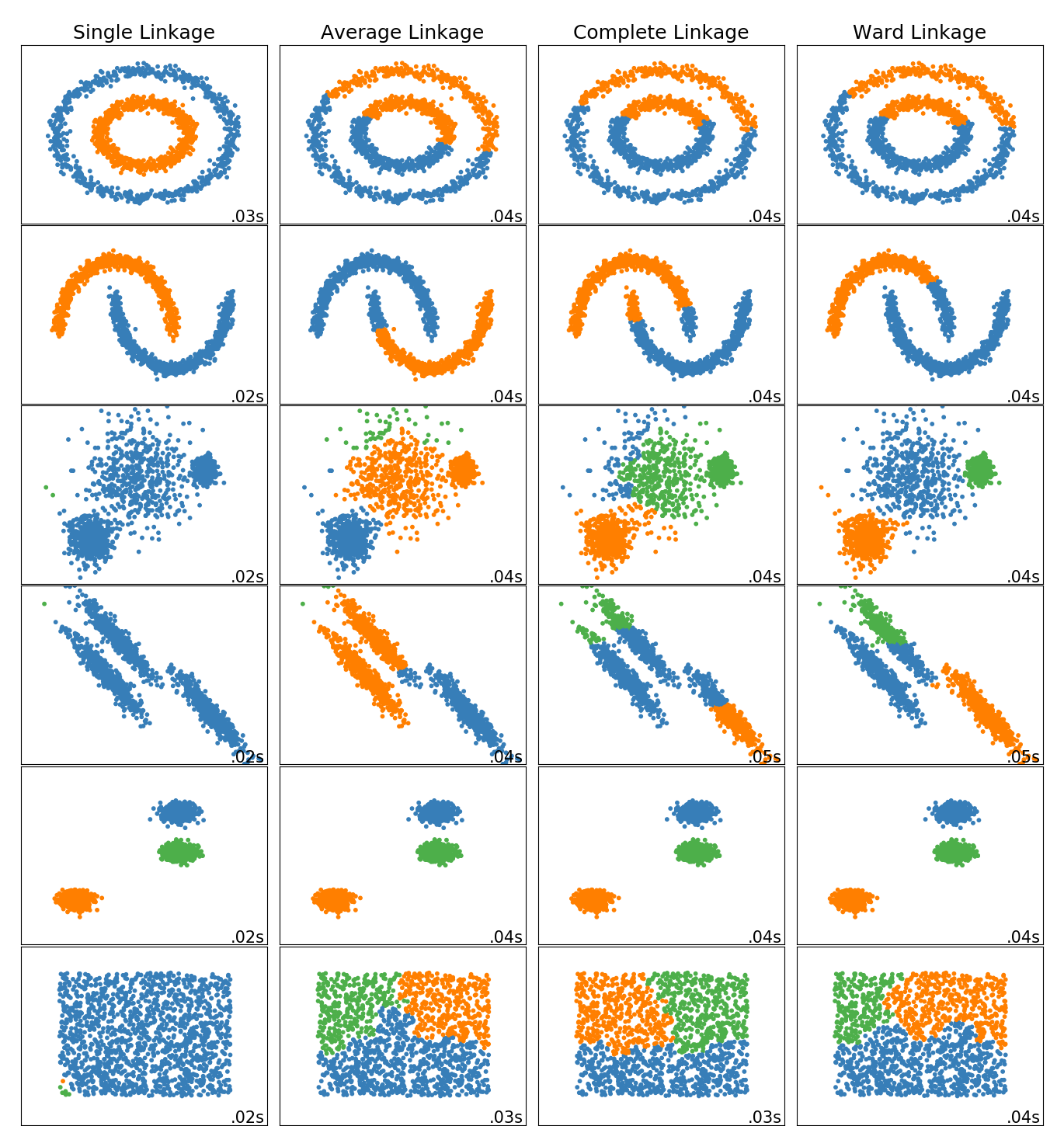 图6 不同凝聚算法比较
图6 不同凝聚算法比较
2. Sklearn 实现
sklearn.cluster.AgglomerativeClustering(n_clusters=2, affinity=‘euclidean’, memory=None, connectivity=None, compute_full_tree=‘auto’, linkage=‘ward’, distance_threshold=None)
n_clusters:聚类簇数
affinity: string or callable, default: “euclidean” 【距离计算参数】
Metric used to compute the linkage. Can be “euclidean”, “l1”, “l2”, “manhattan”, “cosine”, or “precomputed”. If linkage is “ward”, only “euclidean” is accepted. If “precomputed”, a distance matrix (instead of a similarity matrix) is needed as input for the fit method.
linkage: {“ward”, “complete”, “average”, “single”}, optional (default=”ward”)
Which linkage criterion to use. The linkage criterion determines which distance to use between sets of observation. The algorithm will merge the pairs of cluster that minimize this criterion.
ward minimizes the variance of the clusters being merged.
average uses the average of the distances of each observation of the two sets.
complete or maximum linkage uses the maximum distances between all observations of the two sets.
single uses the minimum of the distances between all observations of the two sets.
2.1 层次图可视化
由于 Sklearn 中并不支持可视化层次图,因此我们使用 Scipy:
from scipy.cluster.hierarchy import dendrogram, ward, single
from sklearn.datasets import load_iris
import matplotlib.pyplot as pltX = load_iris().data[:10]linkage_matrix = ward(X)dendrogram(linkage_matrix)plt.show<function matplotlib.pyplot.show(*args, **kw)>
 图7 层次树可视化
图7 层次树可视化
参考文献
[1] 周志华. 机器学习[M]. 北京: 清华大学出版社, 2016: 214.
[2] Ward J H , Jr. Hierarchical Grouping to Optimize an Objective Function[J]. Journal of the American Statistical Association, 1963, 58(301):236-244.
无监督学习 | 层次聚类 之凝聚聚类原理及Sklearn实现相关推荐
- 监督学习 | 线性分类 之Logistic回归原理及Sklearn实现
文章目录 1. Logistic 回归 1.1 Logistic 函数 1.2 Logistic 回归模型 1.2.1 模型参数估计 2. Sklearn 实现 参考资料 相关文章: 机器学习 | 目 ...
- 无监督学习 | GMM 高斯混合聚类原理及Sklearn实现
文章目录 1. 高斯混合聚类 1.1 高斯混合分布 1.2 参数求解 1.3 EM 算法 2. Sklearn 实现 参考文献 相关文章: 机器学习 | 目录 机器学习 | 聚类评估指标 机器学习 | ...
- 无监督学习中的无监督特征学习、聚类和密度估计
无监督学习概述 无监督学习(Unsupervised Learning)是指从无标签的数据中学习出一些有用的模式,无监督学习一般直接从原始数据进行学习,不借助人工标签和反馈等信息.典型的无监督学习问题 ...
- 层次聚类多维度matlab实现_第34集 python机器学习:凝聚聚类
凝聚聚类:凝聚聚类是指许多基于相同原则构建的聚类算法.这一原则是:算法首先声明每个点是自己的簇,然后合并两个最相似的簇,直到满足某种停止条件为止. scikit-learn中实现的停止准则是簇的个数, ...
- 无监督学习 | KMeans与KMeans++原理
文章目录 1. 原型聚类 1.1 KMeans 1.1.1 最小化成本函数 1.1.2 实例 1.2 KMeans++ 1.2.1 KMeans++ 初始化实例 2. 在线可视化 KMeans 参考资 ...
- Python机器学习基础篇三《无监督学习与预处理》
前言 前期回顾: Python机器学习基础篇二<为什么用Python进行机器学习> 上面这篇里面写了文本和序列相关. 我们要讨论的第二种机器学习算法是无监督学习算法.无监督学习包括没有已知 ...
- 机器学习(二)之无监督学习:数据变换、聚类分析
文章目录 0 本文简介 1 无监督学习概述 2 数据集变换 2.1 预处理和缩放 2.2 程序实现 2.3 降维.特征提取与流形学习 2.3.1 主成分分析 2.3.2 非负矩阵分解 2.3.3 用t ...
- Machine Learning Algorithms Study Notes(4)—无监督学习(unsupervised learning)
1 Unsupervised Learning 1.1 k-means clustering algorithm 1.1.1 算法思想 1.1.2 k-means的不足之处 1 ...
- Python 机器学习实战 —— 无监督学习(下)
前言 在上篇< Python 机器学习实战 -- 无监督学习(上)>介绍了数据集变换中最常见的 PCA 主成分分析.NMF 非负矩阵分解等无监督模型,举例说明使用使用非监督模型对多维度特征 ...
最新文章
- 久坐 缺乏运动 消化能力 会减弱
- java前后端分离的实现方式_采用前后端分离的方式进行开发,实现了几种常用的文件上传功能...
- java 如何发提示_消息提醒-如何实现收到待办给QQ发送提醒?
- SysinternalsSuite工具
- Quartz.NET常用方法 01
- Golang包管理工具之govendor的使用
- 关于如何在ASP.NET 2.0中定制Expression Builders
- js实现sqrt开方函数(二分法)
- python常用模块初始
- docker容器启动失败解决办法
- 2016.7.27 VS搜索正则表达式,在UltraEdit中可选用Perl正则引擎,按C#语法搜索
- 求 HCDA认证题库
- 最近发现一个很好的网站-夏泽网,超链接如下:
- Activiti设置流程发起人用户信息
- 奥比中光深度摄像头_苹果收购Primesense后,奥比中光希望用它的深度摄像头填补市场空白...
- Maven中央仓库配置文件
- Excel VBA中的If,Select循环语句
- 【思科源码实例】企业网络搭建项目,带文档和PKT源文件.局域网网络作业.
- java.lang.IllegalStateException异常:简单的分析和简单解决方案
- ssas 数据源mysql_支持的数据源类型(SSAS 多维)
热门文章
- 大规模异构数据并行处理系统的设计、实现与实践
- 作者:夏梓峻(1986-),男,国家超级计算天津中心应用研发部副部长。
- 【2017年第1期】基于征信数据观中国近10年产业间信贷资源的调整路径
- 作者:孙傲冰(1978-),男,博士,东莞中国科学院云计算产业技术创新与育成中心电子政务事业部副研究员...
- 作者:孙卫强,博士,上海交通大学教授、博士生导师。
- Tomcat 申请证书配置https
- 【数据结构与算法】二叉查找树的Java实现
- 来,一起来实现一个符合Promise/A+的Promose(1.0.1版本)
- Android隐藏输入法键盘(hideSoftInputFromInputMethod没有效果)(转)
- vs 编译错误 The name 'InitializeComponent' does not exist in the current context in WPF application...