idea设置实现类生成方法_7种实现位设置的方法
idea设置实现类生成方法
Some data is best modeled as a bit set. For example, the essential information about which students successfully passed a test, out of 3000 students, consists in 3000 bits (375 bytes only).
最好将某些数据建模为一点集 。 例如,关于3000名学生中哪些学生成功通过考试的基本信息包含3000位(仅375字节)。
It turns out that Go doesn’t have a Bitset type in the standard library!
事实证明,Go在标准库中没有Bitset类型!
抽象类型:接口 (Abstract type: interface)
First, let’s say that a Bitset can be any type that implements these 3 methods:
首先,假设Bitset可以是实现以下3种方法的任何类型:
type Bitset interface { GetBit(i int) bool SetBit(i int, value bool) Len() int}It is not necessary in general to start with an interface type. However, it has some advantages and in our case will help comparing different implementations.
通常不必从接口类型开始。 但是,它具有一些优势,在我们的案例中将有助于比较不同的实现。
The Len method returns a number of bits, however its exact semantics is left to the choice of each implementation. We’ll focus more on GetBitand Setbit, and on fixed-sized bitsets.
Len方法返回许多位,但是其确切的语义留给每个实现选择。 我们将更多地关注GetBit和Setbit以及固定大小的位集。
具体实施 (Concrete implementations)
片布尔 (Slice of booleans)
A []boolis a straightforward choice.
[]bool是一个简单的选择。
type BitsetBool []boolfunc (b BitsetBool) GetBit(i int) bool { return b[i]}func (b BitsetBool) SetBit(i int, value bool) { b[i] = value}func (b BitsetBool) Len() int { return len(b)}We create trivial methods in order to satisfy the Bitset interface.
为了满足Bitset接口,我们创建了一些简单的方法。
See the source on GitHub.
请参阅GitHub上的源代码 。
This works well when the size is set at creation and remains fixed:
当在创建时设置大小并保持固定时,这很好用:
bs := make(BitsetBool, M)This implementation is not compact, as it takes up 1 byte per bit in memory, which is an 8x overhead.
此实现并不紧凑,因为它在内存中每位占用1个字节 ,这是8倍的开销。
However, it has advantages:
但是,它具有以下优点:
- very simple to implement
实施起来很简单 - simple to reason about
容易推理 - fast data access
快速数据访问
动态切片的布尔值 (Dynamic slice of booleans)
type BitsetBoolDyn []boolfunc (b *BitsetBoolDyn) SetBit(i int, value bool) { if i >= len(*b) { b.grow(1 + i) } (*b)[i] = value}......See the full source.
参见完整资料 。
The same underlying type []bool can be used to define a bitset type able to automatically grow when needed. To achieve this, the methods have a pointer receiver, as they need to update the slice header when growing. Also, bound checks are added to GetBit and SetBit, as the given index is not expected to always be within current bounds.
可以使用相同的基础类型[]bool定义一个位集类型,该位集类型可以在需要时自动增长。 为此,这些方法具有指针接收器,因为它们需要在增长时更新切片头。 此外,由于不希望给定索引始终位于当前范围之内,因此SetBit边界检查添加到GetBit和SetBit 。
布尔人地图 (Map of booleans)
type BitsetMap map[int]boolSee the full source.
参见完整资料 。
A map of bool is a natural dynamic Bitset. It must be created before adding elements, with an optional size hint:
布尔图是自然的动态位集。 必须在添加元素之前创建它,并带有可选的大小提示:
bs := make(BitsetMap)or
要么
bs := make(BitsetMap, M)An interesting property is that if the Bitset is sparse (lots of false values), then the memory taken up by the map will be proportional to the number of true values, not to the potentially big highest index of a true value.
一个有趣的特点是如果该位集合是稀疏的 (大量假值),然后由地图所占用的内存将正比于真实值的数量,而不是一个真正的价值的潜在的巨大指数最高。
大整数 (Big Integer)
*big.Int implements the basic Bitset functionality, and automatically grows when needed.
* big.Int实现基本的Bitset功能,并在需要时自动增长。
See this source which encapsulates a *big.Int.
请参阅包含*big.Int 此源 。
It is internally backed by a []uint, and its implementation details are more about arithmetic than about storing raw bits.
它在内部由[]uint ,其实现细节更多地是关于算术,而不是存储原始位。
字节片 (Slice of bytes)
type BitsetUint8 []uint8func NewUint8(n int) BitsetUint8 { return make(BitsetUint8, (n+7)/8)}func (b BitsetUint8) GetBit(index int) bool { pos := index / 8 j := index % 8 return (b[pos] & (uint8(1) << j)) != 0}......See the full source. In Go, the types byteand uint8 are strictly equivalent.
参见完整资料 。 在Go中,类型byte和uint8严格等效。
Bytes are the smallest addressable units in Go, so this implementation is compact: each byte is encoding 8 bits, and all bytes are contiguous in memory.
字节是Go中最小的可寻址单元,因此此实现很紧凑:每个字节编码8位,并且所有字节在内存中都是连续的。
Each Get or Set access requires a small computation to locate the correct byte, and access the correct bit inside the byte.
每个“ 获取”或“ 设置”访问都需要进行少量计算才能找到正确的字节,并访问该字节内的正确位。
片64位整数 (Slice of 64-bit integers)
type BitsetUint64 []uint64func NewUint64(n int) BitsetUint64 { return make(BitsetUint64, (n+63)/64)}......See the full source.
参见完整资料 。
Modern computers are often 64-bit platforms, so it makes sense to try to achieve compactness and speed by storing data in 64-bit words (8 bytes).
现代计算机通常是64位平台,因此通过以64位字(8字节)存储数据来尝试实现紧凑性和速度是有意义的。
The implementation logic is the same as for []uint8.
实现逻辑与[]uint8相同。
软件包willf / bitset (Package willf/bitset)
import wb "github.com/willf/bitset"type BitsetWillf struct { wb.BitSet}See the source encapsulating willf’s data structure.
请参见封装willf的数据结构 的源代码 。
This is a popular, ready-to-use bitset package. It has many useful features (popcount, union, etc.).
这是一个流行的,随时可用的位集包。 它具有许多有用的功能(popcount,union等)。
The Bitset is implemented internally as a slice of uint64 plus an exact length in bits.
Bitset在内部以uint64的一部分加上确切的位长度来实现。
基准测试 (Benchmark)
The source of my benchmarks are on GitHub: the 4 filenames containing “bench”.
我的基准测试的源代码在GitHub上 :包含“ bench”的4个文件名。
As always with benchmarks, don’t take the results too seriously. YMMV.
与基准测试一样, 不要过于重视结果 。 YMMV。
写操作的性能 (Perf of write operations)
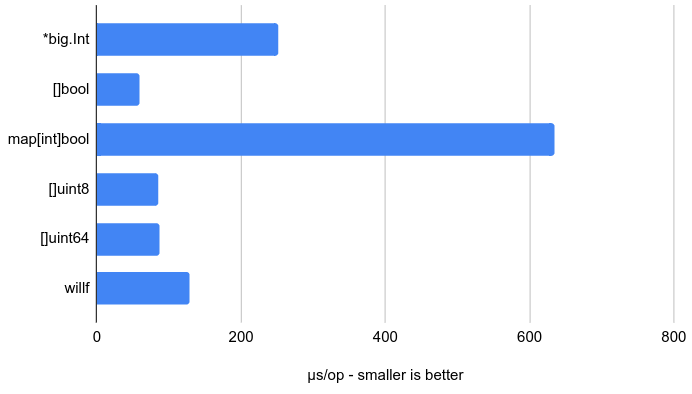
Slice types []bool, []uint8, []uint64 are the fastest structures to write to. They are slightly faster than willf.Bitset, but also less sophisticated (they are fixed-sized, while willf’s embeds some auto-extend code that might not be inlined).
切片类型[] bool,[] uint8和[] uint64是写入速度最快的结构。 它们比willf.Bitset快一点,但是也不太复杂(它们是固定大小的,而willf嵌入了一些可能没有内联的自动扩展代码)。
Big integers and maps of booleans, though nice and easy to use, are slower.
大整数和布尔值映射虽然很容易使用,但速度较慢。
读取操作的性能 (Perf of read operations)
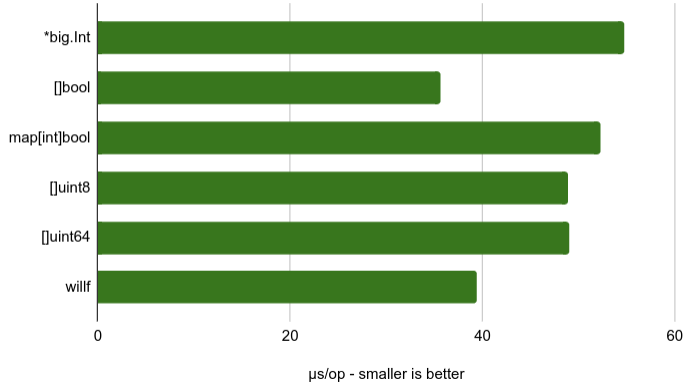
The read operations numbers are more similar to each other. They are faster than write operations.
读取操作编号彼此更相似。 它们比写操作快。
It turns out that []uint8 and []uint64 have the same memory compactness and the same read and write performance numbers. No 64-bit premium gain after all!
事实证明, []uint8和[]uint64具有相同的内存紧凑性和相同的读写性能编号。 毕竟没有64位的溢价收益!
Bitset接口抽象的成本 (Cost of the Bitset interface abstraction)
It may be more efficient to use a specific Bitset’s “raw” concrete type in a tight loop for reading or writing bits, than the Bitset interface type. Consider the difference between BenchmarkUint8IfcWrite and BenchmarkUint8RawWrite:
与Bitset接口类型相比,在紧密循环中使用特定Bitset的“原始”具体类型读取或写入位可能更有效。 考虑BenchmarkUint8 Ifc写和BenchmarkUint8 原始写之间的区别:
var M = 100000func NewUint8(n int) BitsetUint8 { return make(BitsetUint8, (n+7)/8)}func BenchmarkUint8IfcWrite(b *testing.B) { bs := NewUint8(M) benchmarkWrite(bs, b, M)}// Helper benchmark func, compatible with all implementationsfunc benchmarkWrite(bs Bitset, b *testing.B, n int) { for i := 0; i < b.N; i++ { for j := 1; j < n; j += 7 { bs.SetBit(j, true) } for j := 1; j < n; j += 7 { bs.SetBit(j, false) } }}func BenchmarkUint8RawWrite(b *testing.B) { bs := NewUint8(M) for i := 0; i < b.N; i++ { for j := 1; j < M; j += 7 { bs.SetBit(j, true) } for j := 1; j < M; j += 7 { bs.SetBit(j, false) } }}For slices of bytes, the “raw” concrete version is 2x as fast as the “ifc” version.
对于字节片,“原始”具体版本是“ ifc”版本的2倍。
For slices of booleans, the “raw” concrete version is 5x as fast as the “ifc” version!
对于部分布尔值,“原始”具体版本是“ ifc”版本的5倍!
The interface abstraction has a high cost when:
在以下情况下,接口抽象的成本很高:
- each method does a very small amount of work,
每种方法只需要很少的工作, - methods are called on an interface variable in a tight loop, forcing the conversion to the concrete type over and over,
方法在紧密的循环中对接口变量进行调用,从而一再强制转换为具体类型, compiler optimizations such as inlining, constant propagation, bounds check elimination, are not possible at all without knowing the concrete type.
在不了解具体类型的情况下,根本不可能进行编译器优化,例如内联 ,常量传播,边界检查消除。
In the two famous interfaces Reader and Writer from package io:
在io包的两个著名接口Reader和Writer中:
type Reader interface { Read(p []byte) (n int, err error)}type Writer interface { Write(p []byte) (n int, err error)}the methods take a slice as argument, so it’s possible to have them do a large amount of work in a single call. This is not the case with our GetBit, SetBit abstractions which deal with a single bit at a time.
这些方法采用切片作为参数,因此有可能让它们在单个调用中完成大量工作。 我们的GetBit , SetBit抽象不是一次处理单个位的情况。
When benchmarking the “raw” concrete type BitsetUint8,
在对“原始”具体类型BitsetUint8进行基准测试时,
..../bitset_bench_write_raw_test.go:76:13: inlining call to BitsetUint8.SetBit method(BitsetUint8) func(int, bool) { pos := index / 8; j := uint(index % 8); if value { b[pos] |= uint8(1) << j } else { b[pos] &= ^(uint8(1) << j) } }...the short methods GetBit and SetBit are inlined, which saves the cost of a function call. This in turns lets the compiler perform other optimizations, possibly discovering that all slice indices are inferior to M, and eliminating some bound checks.
内联了短方法GetBit和SetBit,这节省了函数调用的成本。 这又使编译器可以执行其他优化,可能会发现所有分片索引均小于M ,并消除了一些绑定检查。
If we want to benchmark each concrete type, we need to write the benchmark code for each of them, as it’s not possible to just call the helper func benchmarkWrite, which would skew the results.
如果要对每种具体类型进行基准测试,则需要为每种具体类型编写基准测试代码,因为不可能仅调用帮助程序func BenchmarkWrite ,这会使结果产生偏差。
This is actually an important lesson: if performance is really important to you, and you’re calling an interface method millions of times in a tight loop, then you should consider working with a concrete type instead.
这实际上是一个重要的教训 :如果性能对您而言确实很重要,并且您在紧密的循环中调用接口方法数百万次,那么您应该考虑使用具体的类型。
Usually though, it’s fine and useful to abstract some behaviors in an interface type.
通常,尽管如此,将接口类型中的某些行为抽象化是很好且有用的。
Fixed size or dynamic growth
固定大小或动态增长
The simple versions of the slice types ([]bool, []uint8, []uint64) are assumed to have fixed size at creation time.
切片类型的简单版本( []bool , []uint8 , []uint64 )在创建时假定具有固定的大小。
All other implementations are dynamic: *big.Int, map[int]bool, willf.Bitset.
所有其他实现都是动态的: *big.Int , map[int]bool , willf.Bitset 。
Turning a “fixed-sized” slice type into a dynamically growing slice type is not very complex: use a pointer receiver in methods, and add explicit bound checks.
将“固定大小”的切片类型转换为动态增长的切片类型不是很复杂:在方法中使用指针接收器,并添加显式绑定检查。
In my benchmark results, I reckon that the overhead of the bound checks is actually very small.
在基准测试结果中,我认为绑定检查的开销实际上很小。
Using the fixed-size version or the dynamic version would depend on the intended use case, as very often a fixed-size bitset is really what we need.
使用固定大小的版本或动态版本将取决于预期的用例,因为通常需要固定大小的位集。
One use case needs special attention, and a trade-off:
一个用例需要特别注意,需要权衡:
either growing for index i is implemented by allocating a new slice to hold (i+1) bits. This is a “compact” way of growing, however if you start with an empty slice, and then flip some n bits incrementally from lower indices to large indices, you will end up with an extremely slow O(n²) runtime complexity. This must be avoided.
通过为分配( i +1)位的新分片来实现为索引i增长的方法。 这是越来越多的“紧凑型”的方式,但如果你开始与一个空的切片,然后从下指数逐步翻转一些n位大的指数,你会落得一个极其缓慢的为O(n²)运行的复杂性。 必须避免这种情况。
or growing for index i is implemented with
append, which “reserves” ~25% of extra unused capacity, in order to achieve a much more sensible cost O(n) when flipping n bits.索引i的增长或增长是通过
append实现的,它“保留”了约25%的未使用容量,以便在翻转n位时获得更合理的成本O( n )。
转到版本 (Go versions)
It’s easy and useful to install several versions of Go on one’s computer (example in bash):
在个人计算机上安装多个版本的Go既简单又有用(例如bash中的示例):
for i in {10..15}; do go get golang.org/dl/go1.$i go1.$i downloaddoneNow I can run the benchmark on 6 major releases of Go, and look for differences.
现在,我可以在Go的6个主要版本上运行基准测试,并寻找差异。
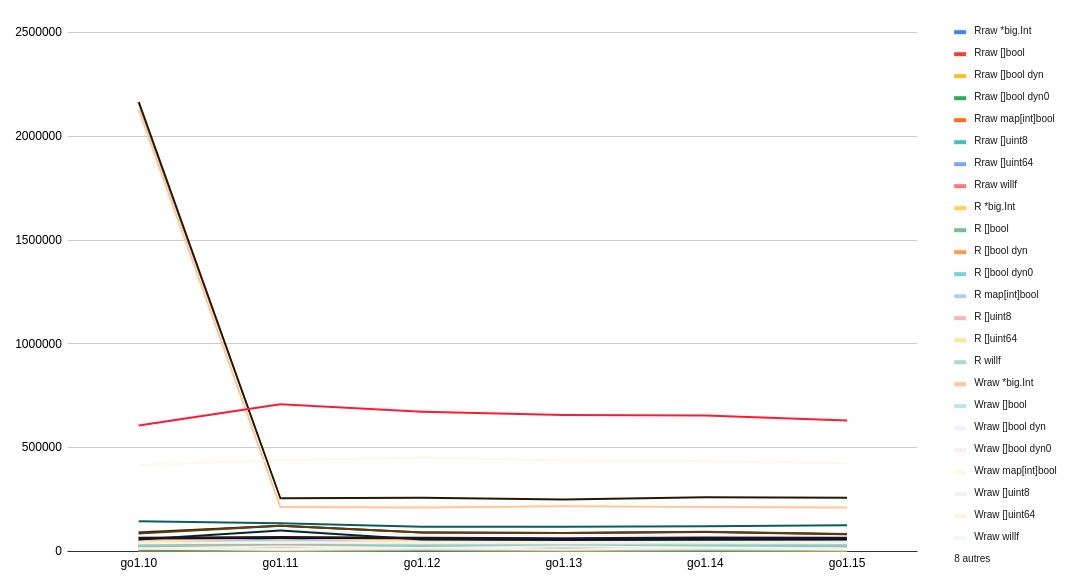
First, most of the lines are dwarfed by 2 outliers, which are “writing bits to *big.Int in Go 1.10”. This part seems to have been tremendously optimized in Go 1.11!
首先,大多数行与2个离群值相比是相形见lier的,它们是“在Go 1.10中将位写入* big.Int”。 这部分在Go 1.11中似乎已经得到了极大的优化 !
Let’s zoom in.
让我们放大。
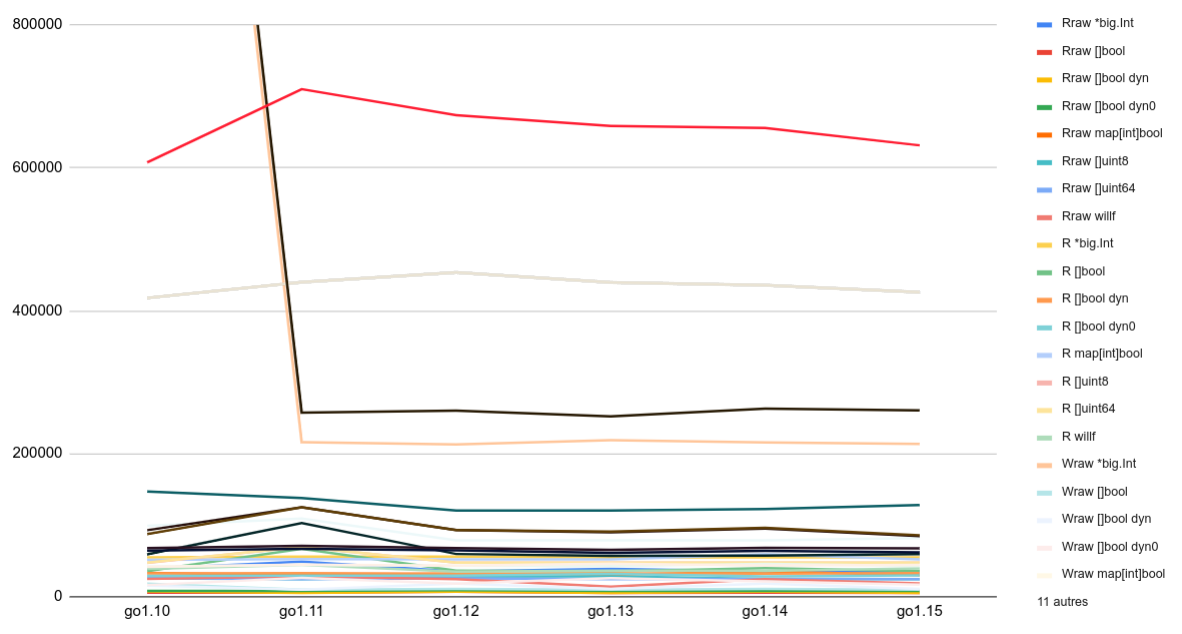
The 2 lines above 400μs/op are “writing bits to map[int]bool”.
高于400μs/ op的2行是“将位写入map [int] bool”。
So far, we know that big ints and maps are not the most efficient for writing.
到目前为止,我们知道大整数和地图并不是最有效的书写方式。
Let’s zoom in further.
让我们进一步放大。
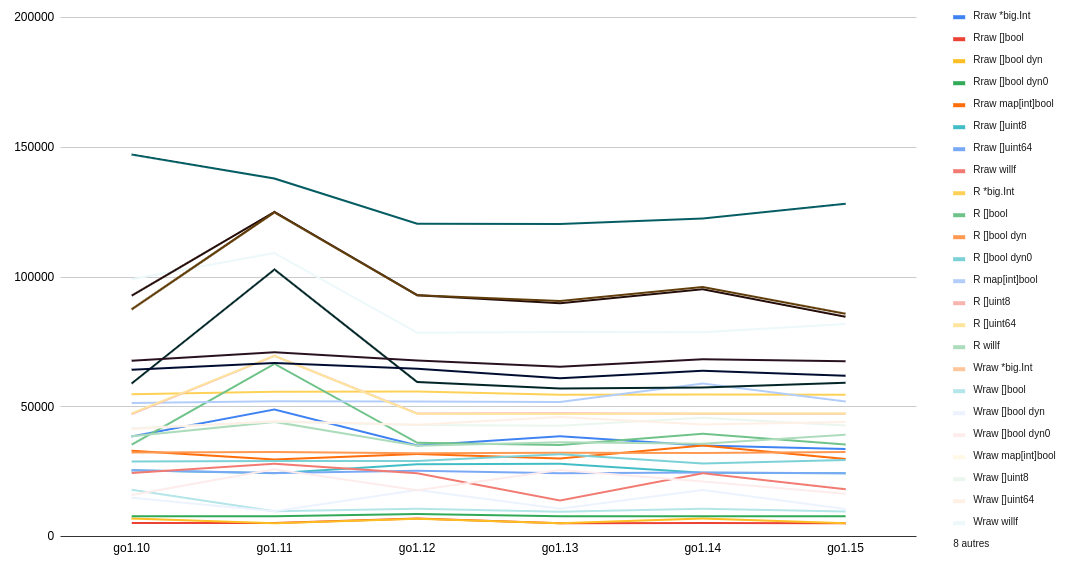
While the chart still looks a bit messy, we can notice many peaks on Go 1.11, as if this specific release was less efficient than the previous ones and than the subsequent ones.
虽然该图表看起来仍然有些混乱,但我们可以在Go 1.11上注意到许多峰值,好像该特定版本的效率不如之前的版本和随后的版本。
If we focus on Go1.12 and above, then we notice less dramatic changes from one Go version to another.
如果我们专注于Go1.12及更高版本,那么我们注意到从一个Go版本到另一个版本的戏剧性变化较小。
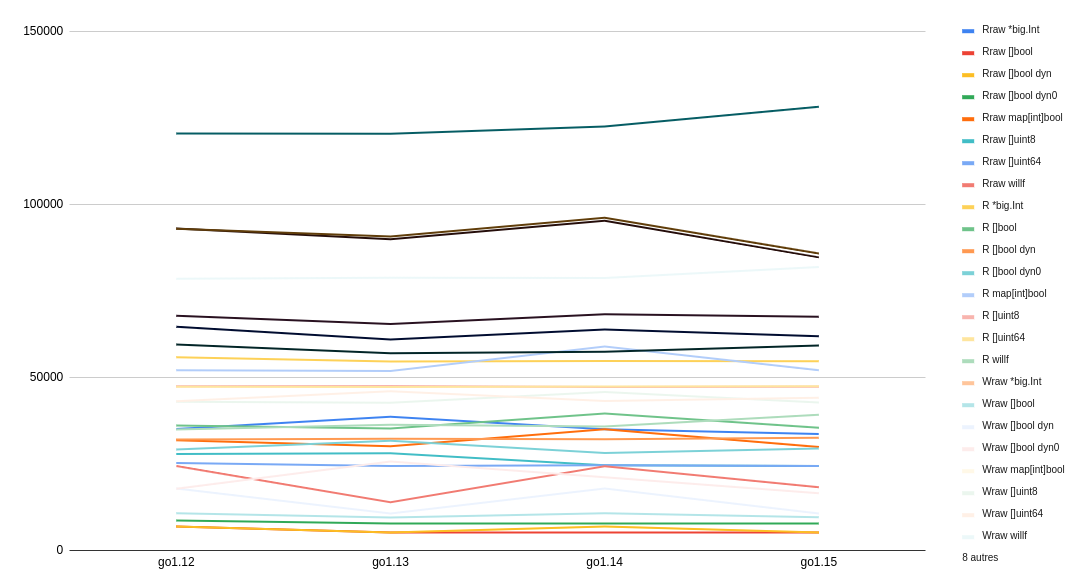
Comparing Go releases with regard to a benchmark is interesting because relying too much on the performance shape of some niche implementation details sometimes lead to “fragile” micro-optimizations, that may no longer hold with the next major release of the compiler.
将Go发行版与基准进行比较很有趣,因为过分依赖某些特定位置实现细节的性能形状有时会导致“脆弱”的微优化,这可能不再适用于编译器的下一个主要发行版。
结论 (Conclusion)
A Bitset is conceptually a simple object, that can be implemented using one of several backing types.
从概念上讲,位集是一个简单的对象,可以使用几种支持类型之一来实现。
Using a fundamental data structure is not always about importing a package, it’s also fine to write one’s own implementation. One important thing is to understand the trade-offs.
使用基本数据结构并不总是要导入包,也可以编写自己的实现。 重要的事情之一是要了解取舍。
Not everything is big data, and not every use case needs peak runtime performance or perfect memory compactness. However, being legible and intelligible is always extremely valuable, so if you need a Bitset, my advice is to choose one that’s simple to use and hard to misuse. I have a preference for the slice of booleans. Your choice may be different :)
并非所有内容都是大数据,也不是每个用例都需要最高的运行时性能或完美的内存紧凑性。 但是,清晰易懂始终是非常有价值的,因此,如果您需要一个Bitset,我的建议是选择一个易于使用且难以滥用的Bitset。 我更喜欢这片布尔值。 您的选择可能有所不同:)
What can we do with a Bitset? Bloom Filters, of course! That would be a story for another post…
我们可以用位集做什么? 布隆过滤器 ,当然! 那将是另一个帖子的故事……
翻译自: https://medium.com/@val_deleplace/7-ways-to-implement-a-bit-set-in-go-91650229b386
idea设置实现类生成方法
相关文章:
- IntelliJ IDEA的安装即使用
- Maven快速入门(IDEA版) - 尚硅谷
- 使用IDEA创建Docker镜像,Docker容器,并发布项目
- 基于SSM实现健康服务中心业务管理系统
- Idea的安装以及相关配置
- IDEA操作技巧与Tomcat集成
- idea下载安装及其运用
- 使用IDEA创建Gradle项目整合SSM框架
- 安装idea
- IDEA操作全解
- IntelliJ IDEA
- [附源码]Python计算机毕业设计SSM基于BS结构的学生交流论坛(程序+LW)
- IDEA开发工具,里面的隐藏功能你知道多少?
- Idea创建Spring Boot项目超时失败的解决方案及Maven改SpringBoot
- JavaWEB四:在IDEA(21.1版本)下部署Tomcat8
- IDEA注册码及快捷键一览
- 英语——平时遇到重要知识点补充【不断更新中】
- 求二叉树b的结点个数、叶子结点个数
- 输出每个叶子结点到根结点的路径
- 遍历二叉树的叶子结点
- 数据结构,计算二叉树叶子结点数 C语言实现
- 叶子结点是什么意思
- 叶子结点和分支节点_一棵深度为5的满二叉树有 个分支结点和 个叶子结点
- 二叉树遍历/先序输出叶子结点
- 求二叉树中从根结点到叶子结点的路径
- 求二叉树的叶子结点个数
- 二叉树叶子结点计数
- 叶子结点和分支节点_二叉树中的度是什么意思,叶子结点是什么?
- 统计二叉树中叶子结点数数据结构C语言,统计二叉树中叶子结点个数的问题,
- 叶子结点和分支节点_统计二叉树分支及叶子结点的个数
idea设置实现类生成方法_7种实现位设置的方法相关推荐
- 属于不安全的http请求方法的是_祛斑方法哪种效果最好,这些方法安全祛斑不反弹...
色斑有很多种,黄褐斑.雀斑.日晒斑.妊辰斑等,斑斑点点在脸上严重影响自信心,甚至会造成自卑心理,不愿和别人交流,那么祛斑方法哪种效果最好呢,今天小编就解读目前最有效的祛斑方法. 祛斑方法哪种效果最好, ...
- cytoscape使用方法_7种方法 ,订制你的专属venn图!-代谢组学/蛋白组学研究
维恩图(Venn diagram),或译Venn图.文氏图.温氏图.范氏图,是用以表示集合(或类)的一种图. 大家对这种图应该不陌生,他们长这样: 或是这样: 以及,这~~样~~~~ 在数据可视化图片 ...
- gdb 扩展 默认参数_默认方法一种扩展旧代码的方法
gdb 扩展 默认参数 如您所知,Java的新版本已于2014年3月18日发布,我将介绍一系列文章来演示其新功能,也许在某些方面,我将谈论我的想法和批评. 我认为重要的第一个功能是"默认方法 ...
- 默认方法一种扩展旧代码的方法
如您所知,Java的新版本于2014年3月18日发布,我将介绍一系列文章来演示其新功能,也许在某些方面,我将谈论我的想法和批评. 我认为重要的第一个功能是"默认方法",在所有Jav ...
- 计算机加解密的主要方法,一种计算机存储器的加密方法和解密方法技术
本发明专利技术公开了一种计算机存储器的加密和解密方法,加密包括步骤:1.将需要加密的数据划分为多个数据块:2.对每个数据小块进行hash运算,对得到的结果做加密运算,得到数据块对应的中间变量(标记为P ...
- 计算机网络安全通信的实现方法,一种计算机网络安全通信的实现方法及系统的制作方法...
专利名称:一种计算机网络安全通信的实现方法及系统的制作方法 技术领域: 本发明涉及计算机网络安全通信领域,具体讲本发明是一种关于计算机网络安全通信的 实现方法及系统. 背景技术: 在许多安全相关的高可 ...
- linux 进程优先级 之设置实时进程 (另一种方式是设置nice值)【转】
转自:https://www.cnblogs.com/jkred369/p/6731353.html Linux内核的三种调度策略: 1,SCHED_OTHER 分时调度策略, 2,SCHED_FIF ...
- 淘宝新开店铺引流方法 5种常用店铺流量获取方法
淘宝流量5中分配方法: 最重要的就是搜索流量 淘宝促销活动流量 广告 大数据推荐流量 达人推荐 淘宝就像一个超市,我们想要提高店铺流量,重点就是要看淘宝这个超市是如何分配的,一切围绕它的分配规则展开, ...
- 提高工作效率的方法_4种提高工作效率的方法
提高工作效率的方法 时间贫困-一种想法,就是没有足够的时间来完成我们需要做的所有工作-是感知还是现实? 事实是,您一天最多不会超过24小时. 长时间工作无济于事. 实际上,您在一天中工作的时间越长,生 ...
最新文章
- 无法在WEB服务器上启动调试,Web 服务器配置不正确
- 青源 LIVE 预告 | 华为诺亚韩凯:视觉 Transformer 综述
- OpenCV捕获视频和摄像头
- VHDL硬件描述语言
- HTML解析利器HtmlAgilityPack
- 16-就业课(2.1)-应用容器-Docker
- 微信朋友圈删除后服务器还有吗,删了的朋友圈还可以找回来吗
- 如何快速在Github找到你想要的东西
- arcgis vue 添加图层优化_行业 | ArcGIS制图技巧(超全)
- (6) 如何用Apache POI操作Excel文件-----POI-3.10的一个和注解(comment)相关的另外一个bug...
- Python案例:计算softmax函数值
- wpf之DependencyProperty
- 蜗牛星际安装U-NAS
- PCR概述及前沿技术
- 使用命令行修复windows系统
- Postman中文版 !!!!傻瓜教程
- python怎么判断质数和合数_用java如何写代码去判断质数和合数
- arp: 查看,为主机添加一个arp 表项
- nltk英文词性分析
- css 背景渐变 图像_交叉渐变背景图像