java爬虫抓取起点小说_爬虫实践-爬取起点中文网小说信息
qidian.py:
import xlwt
import requests
from lxml import etree
import time
all_info_list = []
def get_info(url):
html = requests.get(url)
selector = etree.HTML(html.text)
infos = selector.xpath(‘//ul[@class="all-img-list cf"]/li‘)
for info in infos:
title = info.xpath(‘div[2]/h4/a/text()‘)[0]
author = info.xpath(‘div[2]/p[1]/a[1]/text()‘)[0]
style_1 = info.xpath(‘div[2]/p[1]/a[2]/text()‘)[0]
style_2 = info.xpath(‘div[2]/p[1]/a[3]/text()‘)[0]
style = style_1 + ‘.‘ + style_2
complete = info.xpath(‘div[2]/p[1]/span/text()‘)[0]
introduce = info.xpath(‘div[2]/p[2]/text()‘)[0].strip()
word = info.xpath(‘div[2]/p[3]/span/text()‘)[0].strip(‘万字‘)
info_list = [title, author, style, complete, introduce, word]
all_info_list.append(info_list)
time.sleep(1)
if __name__ == ‘__main__‘:
urls = [‘http://a.qidian.com/?page={}‘.format(str(i)) for i in range(1, 5)]
for url in urls:
get_info(url)
header = [‘title‘, ‘author‘, ‘style‘, ‘complete‘, ‘introduce‘, ‘word‘]
book = xlwt.Workbook(encoding=‘utf-8‘)
sheet = book.add_sheet(‘Sheet1‘)
for h in range(len(header)):
sheet.write(0, h, header[h])
i = 1
for list in all_info_list:
j = 0
for data in list:
sheet.write(i, j, data)
j += 1
i += 1
book.save(‘xiaoshuo.xls‘)
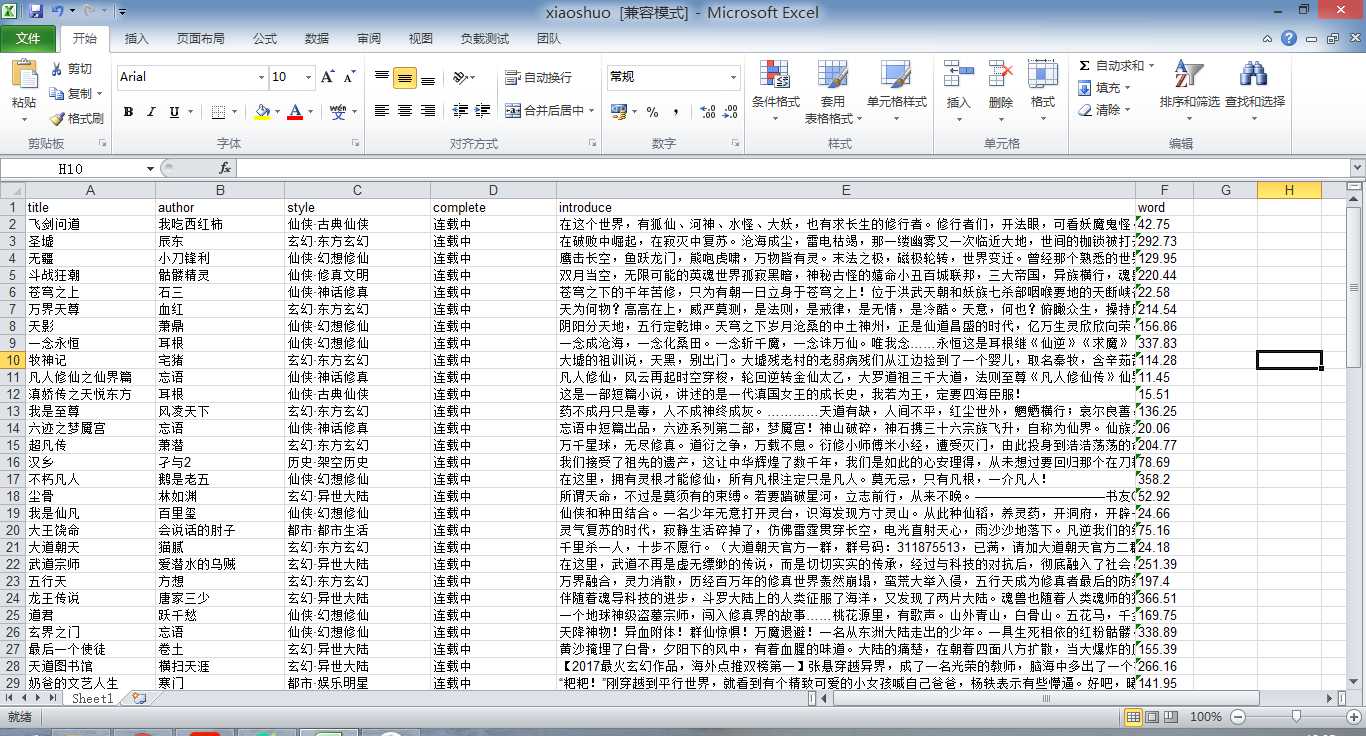
java爬虫抓取起点小说_爬虫实践-爬取起点中文网小说信息相关推荐
- python爬取软件数据_利用Python爬取爬取APP上面的数据
前言 在我们在爬取手机APP上面的数据的时候,都会借助Fidder来爬取.今天就教大家如何爬取手机APP上面的数据. 环境配置 1.Fidder的安装和配置 下载Fidder软件地址:https:// ...
- python爬取qq电话_用Python爬取整个学院MM的电话和QQ,爬虫这也太霸道了!
1. python爬虫可以爬取大规模数据.Python具有丰富和强大的库.它常被昵称为胶水语言,能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起.基本上可以负责任地认为,Pytho ...
- python爬取qq电话_用Python爬取整个学院MM的电话和QQ,爬虫这也太牛了!
文章末尾有python全套学习资料领取 1. python爬虫可以爬取大规模数据.Python具有丰富和强大的库.它常被昵称为胶水语言,能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在 ...
- python爬取电影评分_用Python爬取猫眼上的top100评分电影
代码如下: # 注意encoding = 'utf-8'和ensure_ascii = False,不写的话不能输出汉字 import requests from requests.exception ...
- python爬取bilibili弹幕_用Python爬取B站视频弹幕
原标题:用Python爬取B站视频弹幕 via:菜J学Python 众所周知,弹幕,即在网络上观看视频时弹出的评论性字幕.不知道大家看视频的时候会不会点开弹幕,于我而言,弹幕是视频内容的良好补充,是一 ...
- python正则表达式爬取网页数据_常用正则表达式爬取网页信息及HTML分析总结
Python爬取网页信息时,经常使用的正则表达式及方法. 1.获取 标签之间内容2.获取 超链接之间内容3.获取URL最后一个参数命名图片或传递参数4.爬取网页中所有URL链接5.爬取网页标题titl ...
- python爬取微博评论_用 python 爬取微博评论并手动分词制作词云
最近上海好像有举行个什么维吾尔族的秘密时装秀,很好看的样子,不过我还没时间看.但是微博上已经吵翻了天,原因是 好吧,这不是我们关心的,我的心里只有学习 我爱学习 Python 爬虫 本次爬取的是这条微 ...
- python爬取qq好友_利用Python爬取QQ好友空间数据
程序思路 构造请求链接 先获取所有的好友 获取说说 获取留言 获取个人信息 把数据存到数据库 以上就是整个过程中的大思路,然后在逐步把大思路化解成小的具体的问题去解决.本人对于Python学习创建了一 ...
- python爬取qq数据_用Python爬取QQ好友空间说说进行分析
前言: 本文涉及知识点有数据库的读写,python基础,浏览器开发者工具的使用,适用于有编程基础,了解过python的朋友阅读. 环境:PyCharm+Chrome+MongoDB Window10 ...
- python爬取今日头条_使用python-aiohttp爬取今日头条
原博文 2018-01-24 22:01 − http://blog.csdn.net/u011475134/article/details/70198533 原出处 在上一篇文章<使用pyth ...
最新文章
- 源码阅读:SDWebImage(十九)——UIImage+ForceDecode/UIImage+GIF/UIImage+MultiFormat
- 路由表查找算法概述-哈希/LC-Trie树/256-way-mtrie树
- springmvc学习笔记(10)-springmvc注解开发之商品改动功能
- sql 外连接的写法。
- [SDOI2010]外星千足虫 题解 高斯消元+bitset简介
- webpack基础webpack-dev-server配置
- Nginx笔记-Nginx中进程结构及使用Linux信号量管理
- favicon.ico是什么?
- 告诉家里做饭的人,这些食物一起吃才是大补!
- 全国大学生电子设计竞赛 控制类赛题分析
- win10计算机管理看不见蓝牙,如何解决Win10设备管理器找不到蓝牙?
- 拿php做个日历,分享如何用PHP制作日历(附代码)
- 开源的项目管理软件——OpenProj
- 三款MikroTik家用和小型办公网路由器
- 【2019年5月23日】指数估值排名
- 拟推荐全省文物系统先进_文物系统突出贡献先进个人事迹材料
- 用户流量红利消退的下半场,淘宝如何保持高速增长?
- C语言的函数到底是什么
- 忘记HP服务器ilo密码?如何在不重启服务器的情况下重置ilo登录密码
- 阿里云独享虚拟主机和共享虚拟主机区别对比