基础数据结构(二):字典树、并查集、堆、哈希表、字符串的哈希方式、STL的常见容器及其接口
文章目录
- 一、字典树Trie
- 1 原理
- 2 Trie字符串统计
- 3 [LeetCode 208. 实现 Trie (前缀树)](https://leetcode-cn.com/problems/implement-trie-prefix-tree/)
- 4 Trie例题:[最大异或对](https://www.acwing.com/problem/content/145/)
- 5 Trie与dfs结合
- 二、并查集
- 1 最基础的并查集
- 2 并查集扩展1—记录每个集合元素个数
- 3 并查集拓展2—记录每个结点到根节点的距离
- 三、堆
- 1 堆操作的原理
- 2 堆排序
- 3 模拟堆
- 四、哈希表
- 1 哈希表的原理
- 2 模拟散列表
- I 拉链法
- II 开放寻址法
- 3 字符串的哈希方式
- I 原理
- II 模板题
- 五、STL简介
- 1 vector
- 2 pair
- 3 tuple—C++11
- 3 string
- 4 queue, priority_queue
- 5 stack
- 6 deque
- 7 set map multiset multimap
- 8 unordered_set unordered_map unordered_multiset unordered_multimap
- 9 bitset
一、字典树Trie
1 原理
Trie是一个用来高效存储和查找字符串集合的数据结构。
使用到Trie树时,字符一般都是小写字母或者都是大写字母或者都是0和1,字符范围不会很大。

储存方式:先创建一个根节点,然后从根节点开始,同时遍历字符串,若遍历位置的字符存在与当前结点的子结点,则进入子结点,否则创建子结点,然后进入子结点,循环往复这个过程。
并且在每个单词结尾的节点会进行标记,表示以这个字母结尾是存在一个单词的。
以Trie树结构存储的字符串集合可以快速的查找次集合中是否有对应字符串,查找原理如图
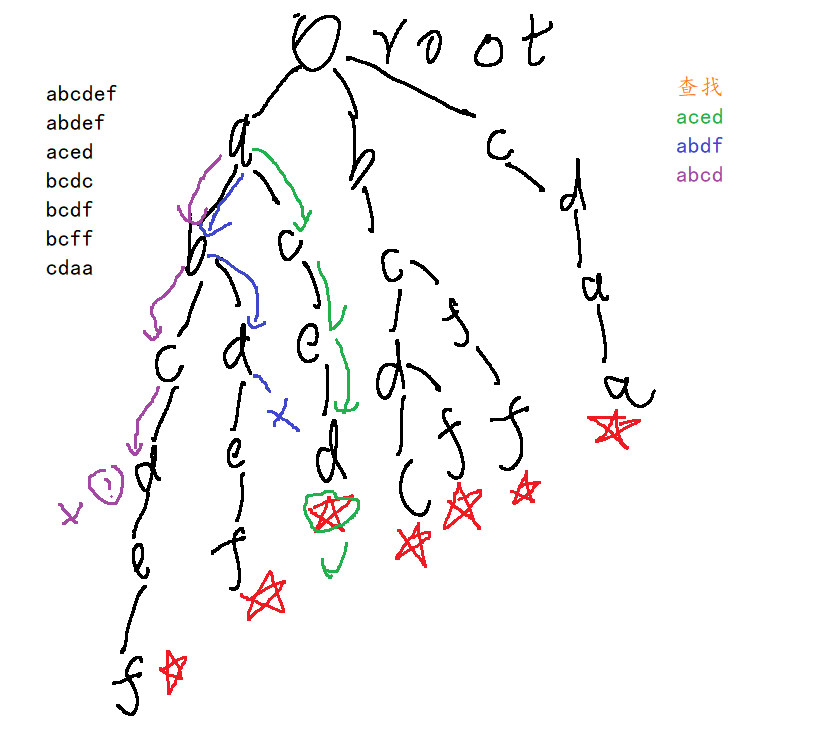
2 Trie字符串统计
模板题:

代码:
#include <iostream>
#include <string>
using namespace std;const int N = 1e5 + 10;int son[N][26];// 只有小写字母 所以每个结点最多有26个分叉
// son[i]存储的是下标为i的结点的孩子
int cnt[N];// 存储以i结点结尾的单词的出现次数
int idx = 0;// 0既代表根节点又代表空结点 idx表示当前第一个可用的结点的前一个结点void insert(const string& str)
{int p = 0; // 从根节点开始for (char ch : str){int u = ch - 'a';// 看看当前结点是否有ch的孩子 没有的话创建一个if (son[p][u] == 0){son[p][u] = ++idx;}// 进入孩子结点p = son[p][u];}// p走到结尾 ++cnt[p]表示以p结点结尾的单词数量 + 1++cnt[p];
}// 查询单词出现了多少次
int query(const string& str)
{// 从根节点开始int p = 0;for (char ch : str){// 得到字符映射到的编号int u = ch - 'a';// 看看当前结点是否有对应的孩子// 如果没有 则说明当前单词不存在 返回0if (son[p][u] == 0) return 0;//否则进入孩子结点接着往下找p = son[p][u];}// 走到这里返回单词出现次数return cnt[p];
}int main()
{int n;cin >> n;string s;char op;while (n--){cin >> op;if (op == 'I'){cin >> s;insert(s);}else{cin >> s;cout << query(s) << endl;}}return 0;
}
3 LeetCode 208. 实现 Trie (前缀树)

// 数组前缀树
class Trie {public:Trie() {idx = 0;}void insert(string word) {int p = 0;for (char ch : word){int u = ch - 'a';if (son[p][u] == 0) son[p][u] = ++idx;p = son[p][u];}++cnt[p];}bool search(string word) {int p = 0;for (char ch : word){int u = ch - 'a';if (son[p][u] == 0) return false;p = son[p][u];}return cnt[p] != 0;}bool startsWith(string prefix) {int p = 0;for (char ch : prefix){int u = ch - 'a';if (son[p][u] == 0) return false;p = son[p][u];}return true;}
private:static const int N = 1e5 + 10;int son[N][26] = {0};int idx;int cnt[N] = {0};
};// 链式前缀树
class Trie {public:Trie() : children(26), isend(false){}void insert(string word) {// 根节点Trie* pNode = this;for (char ch : word){int u = ch - 'a';if (pNode->children[u] == nullptr){pNode->children[u] = new Trie();}pNode = pNode->children[u];}pNode->isend = true;}bool search(string word) {Trie* pNode = this;for (char ch : word){int u = ch - 'a';if (pNode->children[u] == nullptr) return false;pNode = pNode->children[u];}return pNode->isend;}bool startsWith(string prefix) {Trie* pNode = this;for (char ch : prefix){int u = ch - 'a';if (pNode->children[u] == nullptr) return false;pNode = pNode->children[u];}return true;}
private:// 孩子结点数组vector<Trie*> children;// 当前结点是否为单词bool isend;
};
4 Trie例题:最大异或对
暴力算法:两重循环枚举每个数。
int res = 0;
for (int i = 0; i < n; ++i)
{// 由于异或的交换律 不必同时枚举a[i]和a[j]// 每次都找在i之前的数即可for (int j = 0; j < i; ++j){res = max(res, a[i] ^ a[j]);}
}
使用Trie树优化,每次都在Trie树中查找与a[i]异或最大的元素。
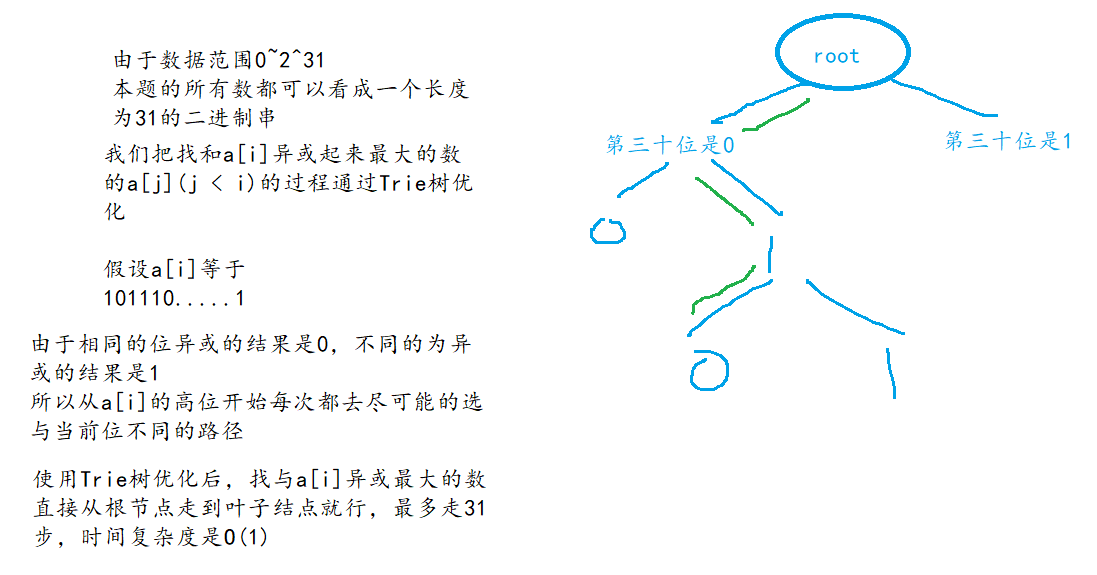
我们这里也可以先插入再查找,先插入再查找的优势是不用特判空树的情况。
本题的目的意在表达所有的Trie树不仅可以存储字符串,还可以存储任何以二进制序列表达的数据,因此,Trie树可以存储所有的计算机的数据。
#include <iostream>
#define read(x) scanf("%d", &(x))
#define print(x) printf("%d\n", (x))
using namespace std;const int N = 1e5 + 10;
// 总共有N个数 每个数是31位
// 最多有31 * N个结点
const int M = 31 * N;int son[M][2];
int idx = 0;
int a[N];void insert(int x)
{// 从第30位(从0开始记)开始插入int p = 0;for (int i = 30; i >= 0; --i){// 得到x的第i位int u = x >> i & 1;if (son[p][u] == 0) son[p][u] = ++idx;p = son[p][u];}
}int query(int x)
{int p = 0;int ret = 0;for (int i = 30; i >= 0; --i){int u = x >> i & 1;// 先看看能否走和第i位不相等的位置if (son[p][!u] != 0){// 能走的话 先把值记录上然后再进去// 怎么记录呢 就是让ret整体往右移动一位然后加上当前位ret = (ret * 2) + !u;p = son[p][!u];}else{ret = (ret * 2) + u;p = son[p][u];}}return ret;
}int main()
{int n;read(n);for (int i = 0; i < n; ++i) read(a[i]);int ret = 0;for (int i = 0; i < n; ++i){// 先把当前数字插入Trie树insert(a[i]);ret = max(ret, a[i] ^ query(a[i]));}print(ret);return 0;
}
5 Trie与dfs结合

class WordDictionary {public:WordDictionary() : isend(false), children(26){}void addWord(string word) {auto* p = this;for (char ch : word){int u = ch - 'a';if (p->children[u] == nullptr){p->children[u] = new WordDictionary();}p = p->children[u];}p->isend = true;}bool dfs(const string& word, WordDictionary* p, int index){// 处理终点 查找到尾了就看看此时的isend是否为trueif (index == word.size()) return p->isend;char ch = word[index];// 若当前结点是字母 正确的条件就是含有当前字母的孩子结点存在// 且进入下一层和下一个字符的dfs最终返回的是trueif (ch >= 'a' && ch <= 'z'){if (p->children[ch - 'a'] != nullptr && dfs(word, p->children[ch - 'a'], index + 1))return true;}// 如果是. 就把.枚举为不同字母 若存在字母 满足这个字母的孩子存在// 且进入下一层和下一个字符的dfs返回true 则返回trueelse{for (int i = 0; i < 26; ++i){if (p->children[i] != nullptr && dfs(word, p->children[i], index + 1))return true;}}// 走到这里说明不存在 返回false即可return false;}bool search(string word) {return dfs(word, this, 0);}
private:bool isend;vector<WordDictionary*> children;
};二、并查集
1 最基础的并查集
并查集是用来干嘛的呢?
并查集支持的操作:
- 将两个集合合并
- 询问两个元素是否在同一个集合当中
不妨假设我们使用暴力做法,假设有一个数组belong,belong[x] = a表示x元素属于标号是a的集合.
暴力做法下,询问两个元素是否在同一个集合当中,belong[x] == belong[y]复杂度不是很高;把两个集合合并就要修改所有属于集合a的集合标号改为b或修改所有属于集合b的集合标号改为集合a的标号,这个复杂度是很高的。
并查集可以在近乎O(1)的时间之内完成这两个操作。
原理:
每个树就是一个集合,树根的编号即为集合的编号,每个结点存储其父节点的编号,p[x]表示x的父节点。
如何判断树根,我们把树根的p[x]定义为x,即
p[x] = x,判断p[x] == x即可;如何求x的集合编号:
while(p[x] != x) x = p[x];如何合并两个集合?假设
px是x的集合编号,py是y的集合编号,直接让p[px] = py或p[py] = px即可。对应到几何图像上就是把x集合树的根节点插入到y树随便一个位置或者把y集合树的根节点插入到x树随便一个位置。
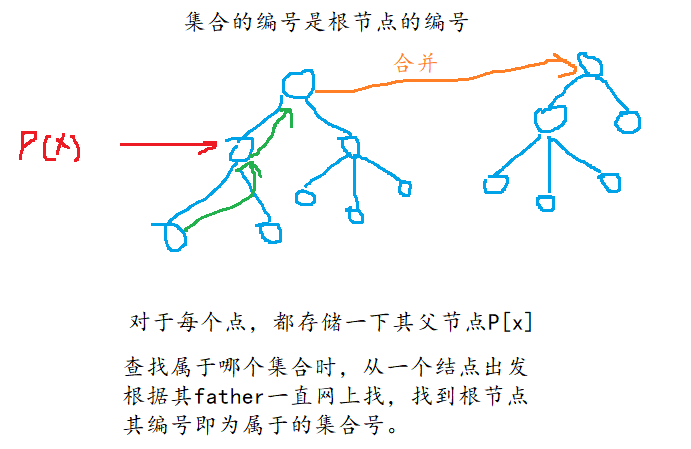
如果仅仅是这样,并查集的时间复杂度还是很高的,就是在查找x的集合编号时,每次都要循环树的高度次,这里有个很牛逼的优化。
![]()
这种优化方式叫做路径压缩,并查集还有一种称为按秩合并的优化,但是优化效果不明显,建议使用路径压缩。
并查集查找并路径优化的代码:
int find(int x)
{if (p[x] != x) p[x] = find(p[x]);return p[x];
}
原理图:
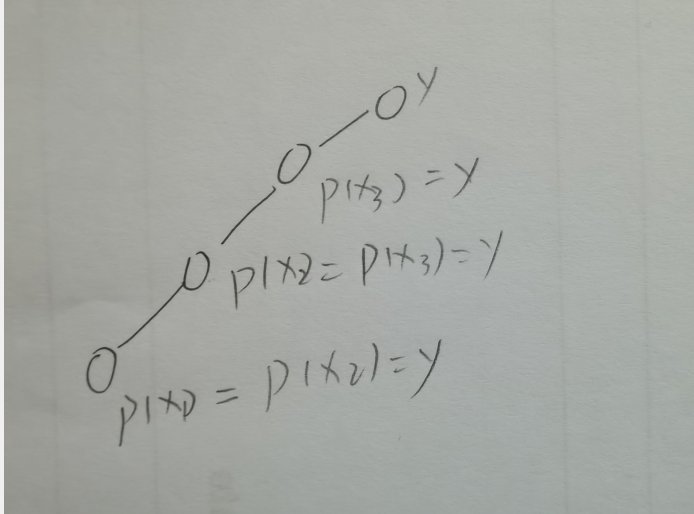
模板题:
#include <iostream>
#define read(x) scanf("%d", &(x))using namespace std;const int N = 1e5 + 10;
int p[N];// 储存每个节点的父节点int find(int x)
{if (p[x] != x) p[x] = find(p[x]);return p[x];
}int main()
{int n, m;read(n);read(m);char op;int a, b;for (int i = 1; i <= n; ++i) p[i] = i;// 一开始都在各自的集合中while (m--){cin >> op;// 或char op[2]; scanf("%s", op);// 因为scanf这个函数如果读%c就会读进一些空格和回车之类的东西。if (op == 'M'){read(a);read(b);// 把a的祖宗接到b的祖宗上p[find(a)] = find(b);}else{read(a);read(b);if (find(a) == find(b)) printf("Yes\n");else printf("No\n");}}return 0;
}
2 并查集扩展1—记录每个集合元素个数
如何动态的维护一个集合中元素的个数呢?看一个例题。

可以发现本题的前两个操作和上一题的前两个操作一样。不难发现同一个连通块中的点就是在同一个集合中的,如果在两个连通块中增加一条边,会把两个连通块连通,也就是会把两个集合合并。
至于查询集合元素数量函数,可以考虑定义一个size数组,我们认为仅有根节点的size是有意义的。
在合并集合的时候,假设集合a的根节点是x,集合b的根节点是y,则p[find(a)] = find(b)同时让size[y] += size[x]即可,注意这里要特判a和b不在同一个集合,否则相当于让集合元素数量翻倍。
#include <iostream>
#define read(x) scanf("%d", &(x))
const int N = 1e5 + 10;int p[N];
int cnt[N];// 合并时更新集合内元素数量int find(int x)
{if (p[x] != x) p[x] = find(p[x]);return p[x];
}int main()
{int n, m;read(n);read(m);char op[4];int a, b;for (int i = 1; i <= n; ++i){p[i] = i;cnt[i] = 1;// 一开始完全不连通 每个结点一个集合 集合内元素数量为1}while (m--){scanf("%s", op);if (op[0] == 'C'){read(a);read(b);// 加一条边等价于合并a b所在的集合int x = find(a);int y = find(b);// 若a和b已经在同一个集合中 则无需合并集合 直接continueif (x == y) continue;p[x] = y;cnt[y] += cnt[x];}else if (op[1] == '1'){read(a);read(b);if (find(a) == find(b)) printf("Yes\n");else printf("No\n");}else{read(a);printf("%d\n", cnt[find(a)]);}}return 0;
}
并查集求解LeetCode1020.飞岛的数量

class DSU
{public:DSU(int n): p(n){for (int i = 0; i < n; ++i){p[i] = i;}}// 查找并合并路径int find(int x){if (p[x] != x) p[x] = find(p[x]);return p[x];}void Union(int x, int y){p[find(x)] = find(y);}bool isSameSet(int x, int y){return find(x) == find(y);}
private:vector<int> p;// 存储它的当前结点父辈结点
};
class Solution {public:int dx[4] = {1, -1, 0, 0};int dy[4] = {0, 0, -1, 1};int numEnclaves(vector<vector<int>>& grid) {//(i, j)结点映射到 i * n + j这个数int m = grid.size();int n = grid[0].size();// 四个边界上的岛屿点都和 m * n 点相连DSU dsu(m * n + 10);for (int i = 0; i < m; ++i){// (i, 0)和(i, n - 1)if (grid[i][0] == 1) dsu.Union(i * n, m * n);if (grid[i][n - 1] == 1) dsu.Union(i * n + n - 1, m * n);}for (int j = 0; j < n; ++j){if (grid[0][j] == 1) dsu.Union(j, m * n);if (grid[m - 1][j] == 1) dsu.Union((m - 1) * n + j , m * n);}for (int i = 0; i < m; ++i){for (int j = 0; j < n; ++j){if (grid[i][j] == 1){for (int k = 0; k < 4; ++k){int nx = i + dx[k];int ny = j + dy[k];if (nx < 0 || nx >= m || ny < 0 || ny >= n || grid[nx][ny] == 0)continue;// 否则设定它们彼此连通dsu.Union(nx * n + ny, i * n + j);}}}}// 经过这样一弄 所有与边上相连的岛屿点都连通到了m * n上// 检查和m * n不连通的即可int ret = 0;for (int i = 1; i < m - 1; ++i){for (int j = 1; j < n - 1; ++j){if (grid[i][j] == 1 && !dsu.isSameSet(i * n + j, m * n))++ret;}}return ret;}
};
3 并查集拓展2—记录每个结点到根节点的距离

根据循环关系,我们发现如果已知x和y的关系(不管是吃还是被吃还是同类)和y和z的关系(不管是吃还是被吃还是同类)立即可推出x和z的关系。
假设若一个结点A的元素可以吃B结点的元素,则A是B的孩子,那么在同一条链上,可以观察到:
假设当前结点与根节点的距离是d:
- d % 3 == 0->当前结点和根节点是同类
- d % 3 == 1->当前结点可以吃根节点
- d % 3 == 2->当前结点可以被根节点吃
- 余0的可以吃余2的,余2的可以吃余1的,余1的可以吃余0的。
存储时,我们存储的是当前结点到父节点的距离,每进行一次find也就是路径压缩时,会把这个距离更新为到根节点的距离。
#include <iostream>
#define read(a, b) scanf("%d%d", &a, &b)
#define Read(t, l, m) scanf("%d%d%d", &t, &l, &m)
using namespace std;const int N = 5e4 + 10;int p[N];// 父辈
int d[N];// 记录到父辈结点的距离 每次find后会更新为到根节点的距离// 该并查集储存具有关系(捕食或者同类)
int find(int x)
{if (p[x] != x){// p[x]find回来以后会被更新为根结点的距离/*int t = p[x];p[x] = find(p[x]);// 把距离更新为到根节点的距离// 距离就是到父节点的距离d[x]和父辈结点到根节点的距离// 因为p[x]已经改变了 所以用原本那个保存好的t d[t]表示父节点到根节点的距离d[x] = d[x] + d[t];*/int t = find(p[x]);d[x] += d[p[x]];p[x] = t;}return p[x];
}int main()
{int n, k;int t, x, y;read(n, k);for (int i = 1; i <= n; ++i){p[i] = i;}int cnt = 0;while (k--){Read(t, x, y);if (x > n || y > n){++cnt;continue;}if (t == 1){int px = find(x);int py = find(y);// 看看它们是否在同一类里面 如果在 这说明已经建立过了关系(同类或捕食)// 同类的话它们到根的距离模3都相等// 不等则说明说的假话if (px == py && (d[x] - d[y]) % 3){++cnt;}// 如果它们不在同一个集合中 说明它们还未建立关系else if (px != py){// 给它们建立同类关系p[px] = py;// 让px成为py的孩子// 为了保证它们是同类 x到根px的距离加上一个数应该和d[y]同余3// 即 (d[x] + ? - d[y]) % 3 == 0// ? = d[y] - d[x] ?就是px到py的距离d[px]d[px] = d[y] - d[x];}}else{int px = find(x);int py = find(y);// 如果它们在同一个集合中 说明它们已经建立了关系// x捕食y 则x到根节点的距离d[x]%3应该等于y节点到根的距离d[y] % 3 + 1// 不等则说明说的假话if (px == py && (d[x] - d[y] - 1) % 3) ++cnt;// 尚未建立关系else if (px != py){// px连到py上p[px] = py;// 建立捕食关系 (d[x] + d[px] - d[y] - 1) % 3 == 0// 求得d[px] = d[y] - d[x] + 1d[px] = d[y] + 1 - d[x];}}}printf("%d\n", cnt);return 0;
}
三、堆
1 堆操作的原理
手写一个堆。
堆是维护一个数据集合,提供操作:
- 向集合中加入一个数
- 求集合中的最小值
- 删除最小值
- 删除集合中任意一个元素
- 修改集合中任意一个元素
STL中的优先级队列无法直接通过接口实现后两个操作。
堆是一颗完全二叉树,以小根堆为例,满足一个性质:每个点都是小于其左右孩子的。
所以根节点就是集合中的最小值。
堆的存储:完全二叉树都用一个数组来存储。
若1号点是根节点,则下标为x的节点的左孩子的下标是2x,右孩子的下标是2x + 1,父节点的下标是x / 2
若0号下标的点是根节点,则下标为x的点的左孩子下标为2x + 1,右孩子的下标为2x + 2,父节点的下标为(x - 1) / 2.
堆有两个基本操作:down(x)向下调整;up(x)把一个结点向上调整
小根堆向下调整down(x)的原理:若孩子中的较小值小于根,则让根的值与此孩子交换,然后接着往下比对,直到不能交换为止。如果把一个值变大了,就是用down(x)操作往下压。
up(x)操作的原理:把一个数变小了,要把数往上移动。
- 插入一个数x:
heap[++size] = x; up(size); - 求集合中的最小值:
heap[1]; - 移除集合中的最小元素:
heap[1] = heap[size]; size--; down(1);因为删除头结点很困难,但是删除尾结点很简单,所以进行了转化。 - 删除任意一个元素:同移除集合中的最小元素:
heap[k] = heap[size]; size--; up(k); down(k);,因为删除元素后,若当前值比原来的值大,则应该执行down(k),若当前值比原来的值小,则应该执行up(k),并且down(k)和up(k)只会执行一个(因为只有变大了才会使得down(k)往下移动,只有变小了才会使得up(k)往上移动。 - 修改任意一个元素:同删除任意一个元素一个道理:
heap[k] = x; up(k); down(k);
2 堆排序
// 解法1 建立一个标准的堆
#include <iostream>
using namespace std;
const int N = 1e5 + 10;// 小跟堆
// 堆顶下标是1 下标为x的结点 父亲是x/2 左孩子是2x 右孩子是2x + 1
class Heap
{public:Heap(){_size = 0;}Heap(const vector<int>& vec){_size = 0;for (auto l : vec){a[++_size] = l;}for (int i = _size / 2; i > 0; --i){down(i);}}int size(){return _size;}void down(int k){int t = k;if (k * 2 <= _size && a[k * 2] < a[t]) t = k * 2;if (k * 2 + 1 <= _size && a[k * 2 + 1] < a[t]) t = k * 2 + 1;// 走到这里t就是k和它左右孩子中的较小者// t不等于k则要调if (t != k){swap(a[t], a[k]);down(t);}}/*void up(int k){// 找到父节点int t = k / 2;// 如果没出界且父节点更大 则要调if (t != 0 && a[t] > a[k]){swap(a[t], a[k]);up(t);}}*/void up(int k){while (k / 2 && a[k / 2] > a[k]){swap(a[k], a[k / 2]);k /= 2;}}void insert(int x){// 插入等价于在尾部插入然后往上调a[++_size] = x;up(_size);}int top(){// 堆顶下标是1return a[1];}void pop_top(){// 先把1的值改为尾巴的值 然后size--,然后down(1)a[1] = a[_size];_size--;down(1);}void pop(int k){// 移除下标为k的元素 先让a[k] = a[size] 然后size--// 然后不管变大了还是变小了执行up(k)和down(k)即可a[k] = a[_size];_size--;up(k);down(k);}void change(int k, int x){a[k] = x;up(k);down(k);}
private:int a[N];int _size;
};int main()
{int n, m;cin >> n >> m;Heap hp;int x;for (int i = 0; i < n; ++i){cin >> x;hp.insert(x);}while (m--){cout << hp.top() << ' ';hp.pop_top();}return 0;
}// 从第一个有孩子的节点开始向下调整建堆
#include <iostream>
#define read(x) scanf("%d", &(x))
#define print(x) printf("%d ", (x))
using namespace std;const int N = 1e5 + 10;int h[N];
int _size;void down(int k)
{int t = k;if (k * 2 <= _size && h[t] > h[k * 2]) t = k * 2;if (k * 2 + 1 <= _size && h[t] > h[k * 2 + 1]) t = k * 2 + 1;if (t != k){swap(h[t], h[k]);down(t);}
}int main()
{int n, m;read(n);read(m);_size = n;for (int i = 1; i <= n; ++i) { read(h[i]);}// 建堆 从第一个有孩子结点的位置开始downfor (int i = _size / 2; i > 0; --i){down(i);}while (m--){print(h[1]);h[1] = h[_size--];down(1);}return 0;
}
3 模拟堆

本题需要改动的是第k个插入,所以我们需要维护两个数组ph[N] hp[N],ph[k] = x表示第k个插入的点在堆中的下标为x;hp[x] = k表明堆里下标为x的点是第k个插入。
// 所以在做交换的时候 需要完成这样的交换
void heap_swap(int i, int j)
{// 先交换两个点的插入下标swap(ph[hp[i]], ph[hp[j]]);// 再交换两个点是第几个插入swap(hp[i], hp[j]);// 最后交换值swap(h[i], h[j]);
}
总体代码如下:
#include <iostream>
#include <string>
using namespace std;const int N = 1e5 + 10;int h[N];
int hp[N];// hp[i] = k 当前堆内下标为i的元素是第k个插入堆的元素
int ph[N];// ph[k] = i 第k个插入堆的元素当前下标为i
int _size;void heap_swap(int i, int j)
{swap(ph[hp[i]], ph[hp[j]]);swap(hp[i], hp[j]);swap(h[i], h[j]);
}void up(int x)
{while (x / 2 && h[x / 2] > h[x]){heap_swap(x, x / 2);x /= 2;}
}void down(int x)
{int t = x;if (2 * x <= _size && h[t] > h[2 * x]) t = 2 * x;if (2 * x + 1 <= _size && h[t] > h[2 * x + 1]) t = 2 * x + 1;if (t != x){heap_swap(t, x);down(t);}
}int main()
{int n, m = 0;cin >> n;string op;int k, x;while (n--){cin >> op;if (op == "I"){cin >> x;_size++;m++;ph[m] = _size;hp[_size] = m;h[_size] = x;up(_size);}else if (op == "PM"){printf("%d\n", h[1]);}else if (op == "DM"){heap_swap(1, _size);_size--;down(1);}else if (op == "D"){cin >> k;k = ph[k];// 找到第k个插入的下标heap_swap(k, _size);_size--;down(k);up(k);}else {cin >> k >> x;k = ph[k];h[k] = x;up(k);down(k);}}return 0;
}
四、哈希表
主要介绍两部分内容:哈希表的存储结构和字符串的哈希方法。
1 哈希表的原理
哈希表的主要功能是把一个庞大的值域映射到从0~N的数,N一般比较小,如1e5~1e6,从这个角度上来看,离散化是一种保序的哈希方式。
2 模拟散列表

对本题来说,直接对109范围的数据取mod105可以设定为我们的哈希函数。
这样设计的函数可能会有冲突,因为两个不相同的数取模也可能得到相同的值。
这种时候我们就要处理冲突,常见的两种处理冲突的方法:开放寻址法和拉链法。
I 拉链法
先开一个映射范围大小的数组,如本题开一个1e5大小的数组,代表每个链的头结点指针。
拉链法处理冲突的方式就是如果需要插入的元素映射后的位置已经有元素了,就挂上一个像桶一样的东西:
![]()
数学期望下,每个链的长度都是常数,哈希表的查找效率就是O(1).
插入x:先求h(x)看看在哪个槽上,然后插入单链表的节点一样插入这个值为x的结点即可;
查询x:先求h(x)找到对应槽,然后遍历这个单链表;
删除:一般就是给每个点增加一个bool变量,如果要删除就给这个点标记一下就行,而非真正的删除。
设计哈希时,膜的数最好取成质数,并且离2的整次幂稍微远点,在数学上可以证明,这样取冲突的几率最小。
如本题,数据个数是105个,大于105的第一个质数是10003.
注意到数据范围存在负数情况,虽然数学上任何整数的取模都是非负数,但是C++取模后可能为负数,所以可以这样取(x % N + N) % N,这样保障哈希值是正数。
// 拉链法
#include <iostream>
#include <cstring>
#define readnum(x) scanf("%d", &(x))
#define readstr(x) scanf("%s", (x))
using namespace std;const int N = 100003;int h[N];// 哈希表的桶头 头结点 只存储指向下一结点的指针
int ne[N];// 单链表的ne数组 -1代表空指针
int e[N];// 单链表的值数组
int idx = 0;void insert(int x)
{int k = (x % N + N) % N;e[idx] = x;ne[idx] = h[k];h[k] = idx;idx++;
}bool find(int x)
{int k = (x % N + N) % N;for (int i = h[k]; i != -1; i = ne[i]){if (e[i] == x) return true;}return false;
}int main()
{memset(h, -1, sizeof(h));int x, n;char op[2];readnum(n);while (n--){readstr(op);readnum(x);if (op[0] == 'I'){insert(x);}else{if (find(x)) printf("Yes\n");else printf("No\n");}}return 0;
}
II 开放寻址法
开放寻址法一般会开数据个数范围的2~3倍大小的数组
![]()
删除也是找到这个元素后打一个flag标记。
#include <iostream>
#include <cstring>
const int N = 2e5 + 3;
const int null = 0x3f3f3f3f;
using namespace std;class hashtable
{public:hashtable(){// memset是按字节来赋值的memset(h, 0x3f, sizeof(h));}int find(int x){int k = (x % N + N) % N;while (h[k] != null && h[k] != x){k++;if (k == N) k = 0;}return k;}bool query(int x){return h[find(x)] == x;}void insert(int x){h[find(x)] = x;}
private:int h[N];
};int main()
{int n, x;cin >> n;hashtable hash;char op[2];while (n--){cin >> op >> x;if (op[0] == 'I'){hash.insert(x);}else {if (hash.query(x)) cout << "Yes" << endl;else cout << "No" << endl;}}return 0;
}
3 字符串的哈希方式
I 原理
我们介绍的是字符串前缀哈希法。
如str = "acwing"`,h[1]是"a"的哈希值, h[2]是“ac"的哈希值,h[3]是"abc"``的哈希值…h[0]定义为0,因为没有字符就没有值。
字符串的哈希方法就是把字符串看成一个p进制的数。
![]()
由于字符串通常比较强,所以对应的数字可能很大,所以再膜上一个比较小的数Q比较好。这样就能把任何一个字符串映射到一个0~Q-1的数了。
- 注意:不能把任何字符映射到0,否则A是0,AA也是0,就会出现大量的冲突;
- 这里的字符串哈希方法是假设我们RP足够好,不存在冲突;
- 经验值:当p取131或13331,Q取2^64次方时,我们可以假定不存在冲突
好处是什么呢?我们可以通过一个公式从一个串前缀的哈希值得到任意一个子串[L,R]的哈希值。
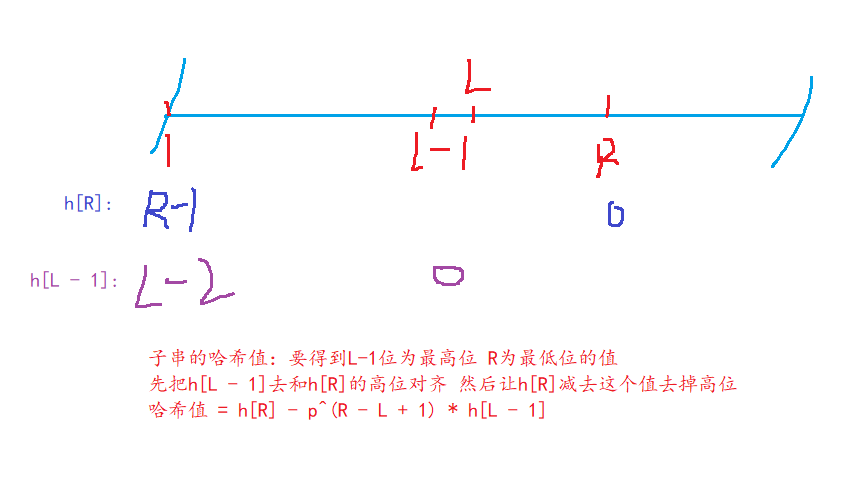
因为我们的Q取的值是2^64,所以用一个unsigned long long来储存每个哈希值,当溢出时相当于自动取模了。
h[i]的递推公式:
h[i]=p∗h[i−1]+str[i]h[i] = p * h[i - 1] + str[i] h[i]=p∗h[i−1]+str[i]
II 模板题
#include <iostream>
using namespace std;
typedef unsigned long long ULL;
const int N = 1e5 + 10;ULL h[N];// 每个[1~i]位置的哈希值
ULL p[N];// 预处理p^i的值为p[i]
const int P = 131;
char str[N];ULL get(int l, int r)
{// 利用获得子串哈希值的公式 h[L~R] = h[R] - h[L - 1] * P[R - L + 1]return h[r] - h[l - 1] * p[r - l + 1];
}int main()
{int n, m;scanf("%d%d%s", &n, &m, str + 1);p[0] = 1;for (int i = 1; i <= n; ++i){// 提前预处理P^ip[i] = p[i - 1] * P;// 利用h的递推公式求1~i的串的哈希值h[i] = h[i - 1] * P + str[i];}int l1, r1, l2, r2;while (m--){scanf("%d%d%d%d", &l1, &r1, &l2, &r2);if (get(l1, r1) == get(l2, r2)) cout << "Yes" << endl;else cout << "No" << endl;}return 0;
}
我写的一个模板:
#include <iostream>
#include <cstdio>
#include <string>
using namespace std;const int N = 1e5 + 10;
const int P = 131;typedef unsigned long long ULL;class strhash
{public:strhash(const string& s,int n){int sz = s.size();for (int i = 0; i < sz; ++i){str[i + 1] = s[i];}p[0] = 1;for (int i = 1; i <= n; ++i){p[i] = p[i - 1] * P;h[i] = h[i - 1] * P + str[i];}}ULL getval(int l, int r){return h[r] - h[l - 1] * p[r - l + 1]; }bool isSamestr(int l1, int r1, int l2, int r2){return getval(l1, r1) == getval(l2, r2);}
private:ULL h[N] = {0};ULL p[N];char str[N];
};int main()
{string s;int n, m, l1, r1, l2, r2;cin >> n >> m;cin >> s;strhash sh(s, n);while (m--){cin >> l1 >> r1 >> l2 >> r2;if (sh.isSamestr(l1, r1, l2, r2)) cout << "Yes" << endl;else cout << "No" << endl;}return 0;
}
所有判断字符串是否相等的都可以使用这个方法试试。
五、STL简介
1 vector
变长数组,长度倍增。
头文件<vector>.构造函数用法:vector<int> a(n, val);
vector数组:vector<int> a[10];
size()容器元素个数,empty()容器是否为空,所有容器都有
clear():清空容器
长度倍增主要好处体现在:每次向os申请一个长度为1的数组和一个长度为n的数组其实时间是差不多的,时间只和申请次数有关,和申请长度无关,正是因为有这样的特点,变长数组要尽量减少申请的次数,浪费空间问题并不大。
因为倍增思想出于效率的考虑,每次拷贝最多扩容的次数是O(logn)的,次数并不多,我们可以认为vector容器尾插一个元素平均效率是O(1)的
front()、back()、push_back()、pop_back();
迭代器begin():第0个数的迭代器,end():最后一个数后面一个数的迭代器.
迭代器遍历vector:
for (vector<int>::iterator i = a.begin(); i != a.end(); ++i)
{cout << *i << ' ';
}
vector<int>::iterator通常写为auto
vector支持比较运算,是按字典序比较大小的:
2 pair
存储一个二元组,头文件<utility>.
pair<type1, type2> p;
p.first()第一个元素,p.second()第二个元素。
支持比较运算,以first为第一关键字,以second为第二关键字比较,其实也是字典序,使用sort默认排升序。
构造pair:auto p = make_pair( , );,在C++11中,可以直接用大括号构造:pair<int, string> p = {1, "abc"};.
如果一个食物有两个属性,并且我们想按第一个属性排序,放到pair然后排序里头就可以了。
3 tuple—C++11
与pair类似,支持多元组构造,头文件<tuple>
构造:
tuple<int, const char*> p = make_tuple(1, "abc");
tuple<int, const char*> p1 = {1, "sssss"};
取值:
tie(x, str) = p1;
auto [l, k] = p1;
cout << std::get<1>(p) << endl;// 获得元素中下标为1的元素
修改值:
auto& [l, k] = p1;
k = "char";
get<1>(p) = "hahahahaha";
它的排序同pair,也是按字典序排的,使用sort默认排升序。
3 string
头文件<string>
字符串,substr:子串,c_str():返回串的头指针。
size() empty() clear().
operator+=:字符串后连上一个字符串;
s.substr(子串起始位置, 子串长度);,第二个参数超过数组长度时,就会输出到最后一个字符位置,省略第二个参数也是这个效果。
printf打印string:printf("%s", s.c_str());,返回char数组的起始地址。
4 queue, priority_queue
头文件<queue>
queue:push(),pop(),front(),back(),但是queue没有clear()函数。

如果要清空使用重新构造一个空的队列就行:q = queue<int>();
priority_queue:优先队列,就是个堆:push()入堆,top()返回堆顶元素,pop()把堆顶弹出,它也没有clear()函数
默认定义的堆是大根堆。
要获得小根堆有两种方式
- 直接往堆里大根堆中插入x的相反数;
q.push(-x); - 直接定义小跟堆:
priority_queue<int, vector<int>, greater<int>> q;
5 stack
头文件````
push:栈顶增加元素,top():返回栈顶元素,pop():弹出栈顶元素,同样没有clear()函数
6 deque
头文件<deque>
双向队列,队头队尾都可以插入删除,支持随机访问,是一个加强版的vector.
支持size()、emty()、clear().
对于插入删除,支持:push_back()\push_front()和pop_front()\pop_back().
支持operator[]、begin()、end().
缺点是速度比较慢,比一般的容器慢好几倍。
7 set map multiset multimap
基于平衡二叉树(红黑树)实现,动态的维护一个有序的序列。
头文件<set>,里头包含了set和multiset.
都支持size(),clear(),empty().
set/multiset:
begin()和end(),支持++,--返回后继和前驱的元素的迭代器,时间复杂度O(logn)
s.insert(x):O(logn)
s.find(x):x不存在返回end()迭代器,存在返回指向x的迭代器。O(logn)
s.count(x):返回某一个数出现的次数O(logn).
s.erase():输入是一个数x,则删除所有x,O(k + logn);输入是一个迭代器i,删除这个迭代器,O(logn),这里主要是multiset的删除问题,如果用erase(x)就会删掉所有的值为x的结点,这时可以输入一个迭代器来删除。
s.lower_bound(x):大于等于x的最小的数的迭代器,不存在返回end()
s.upper_bound(x):大于x的最小的数的迭代器,不存在返回end().
map/multimap:
头文件<map>
m.insert(x),x是一个pair
m.erase(x),x是pair或迭代器。
m.find(x),x是第一个关键字,和set的find效果一样。

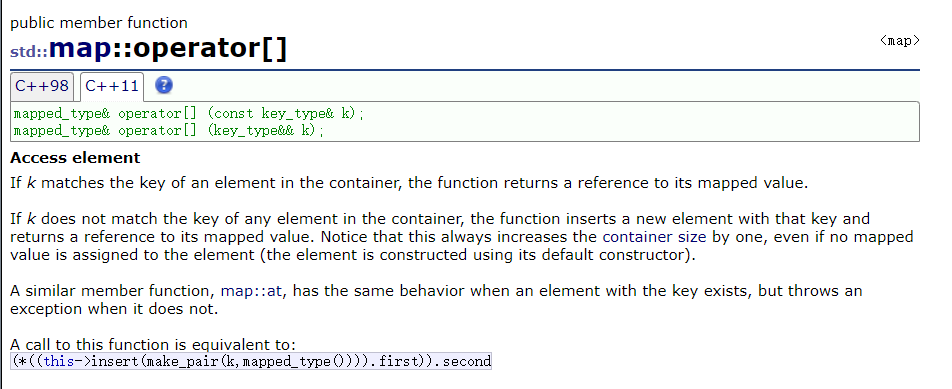
operator[]:根据key返回值,并且由于返回的是引用可以取代插入a["lyq"] = 1;时间复杂度O(logn).
m.lower_bound(k)和m.upper_bound(k),k是关键字,和set效果一样:大于等于x的最小
8 unordered_set unordered_map unordered_multiset unordered_multimap
头文件<unordered_set>和<unordered_map>.
基于哈希表来实现的,内部元素是无序的,接口和上面类似,因为哈希表的原因增删查改的时间复杂度都是O(1),但是不支持lower_bound()和upper_bound()函数,迭代器的++和--也不支持。
9 bitset
压位,状态压缩,存储二进制位。
C++中的bool的大小是1个字节,如果开1024个布尔类型元素的数组,需要1kb的内存。
但是实际上bool值用一个位就能表示,如果能压位的话,1024的布尔类型的元素数组只要128字节就可以了。
比如有的题需要开一个10^8的布尔数组,如果用bool,那么大概是100MB的空间,但是题目限制一般是64MB,这时用bitset就可以省8位空间。
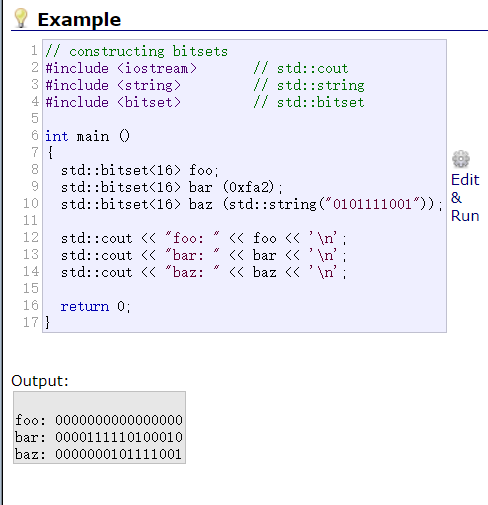
构造函数:bitset<个数> bit;
支持所有位运算~ ^ & | << >>.
支持比较== !=.
支持|= ^= <<= >>= &=
支持operator[],返回某一位的位:

count()返回有多少个1.
any():返回是否至少有一个1
none():返回是否全为0,与any()相反
set():把所有位置成1;set(k, v)将第k位变成v
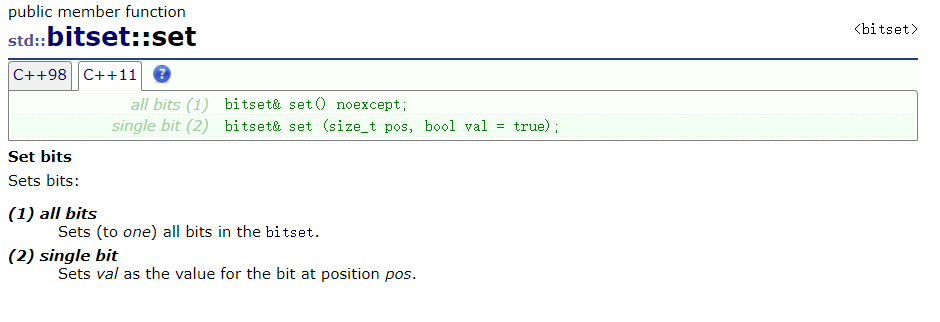
reset():把所有位变成0.
flip():把所有位取反
flip(k):把第k位取反
基础数据结构(二):字典树、并查集、堆、哈希表、字符串的哈希方式、STL的常见容器及其接口相关推荐
- POJ - 2513 Colored Sticks(字典树+并查集+欧拉回路)
题目链接:点击查看 题目大意:给出n个木棍,问若两两相连,最终能否构成一根长直木棍,相连的规则是两个木棍的相接端点的颜色需要保持相同 题目分析:关于这个题目,我们可以将每个木棍视为一条边,每个木棍的两 ...
- HDU 1512 Monkey King 左偏树 + 并查集
题目:http://acm.hdu.edu.cn/showproblem.php?pid=1512 题意:有n个猴子,一开始每个猴子只认识自己.每个猴子有一个力量值,力量值越大表示这个猴子打架越厉害. ...
- 可持久化线段树【主席树】可持久化并查集【主席树+并查集】
笼统的主席树原理 众所周知, 主席树是可以持久化的, 换言之你能知道你所维护信息的所有历史状态. 主席树是这样做的: 1. 首先建一颗朴素的线段树,代表初始状态 (下图黑色) , 也就是第0次操作后的 ...
- 数据结构之哈希表以及常用哈希的算法表达(含全部代码)
目录 为什么要有哈希 哈希表 含义 创建哈希表需要注意的点 算法的选择 哈希冲突的处理 线性探测法 再哈希法 链表法 哈希表的实现(代码部分) 确定结构体(节点) 准备一个哈希算法 创建一个哈希表(即 ...
- 分门别类刷leetcode——高级数据结构(字典树,前缀树,trie树,并查集,线段树)
目录 Trie树(字典树.前缀树)的基础知识 字典树的节点表示 字典树构造的例子 字典树的前序遍历 获取字典树中全部单词 字典树的整体功能 字典树的插入操作 字典树的搜索操作 字典树的前缀查询 字典树 ...
- 最优雅的数据结构之一——字典树Trie(Java)
什么是Trie? 又称单词查找树: 又叫前缀树(prefix tree): Trie树,是一种树形结构,是一种哈希树的变种. 作用: 用以较快速地进行单词或前缀查询: 用于快速检索.统计,排序和保存大 ...
- 【数据结构】字典树TrieTree图文详解
问题引入 现在,我给你n个单词,然后进行q次询问,每一次询问一个单词b,问你b是否出现在n个单词中,你会如何去求呢? 暴力搜索?但是我们如果这么做的话时间复杂度一下就高上去了.大家都是成熟的ACMer ...
- 0x17.基础数据结构 - 二叉堆
目录 一.二叉堆 二.例题 0.AcWing 145. 超市 AcWing 146. 序列(POJ 2442) 三.HuffmanHuffmanHuffman树 1.AcWing 148. 合并果子 ...
- 数据结构之字典树Trie
文章目录 Trie 字典树 前缀树 什么是Trie 基本概念 基本性质 应用场景 优点 手写一个trie Trie字典树的前缀查询 实现Trie(前缀树) LeetCode208 添加与搜索单词 - ...
最新文章
- 关于组织参加2020年全国大学生智能汽车竞赛山东赛区比赛的通知
- windows扫描域内端口
- 抽象类与接口的一个程序实现
- 推荐Mongodb GUI 可视化管理工具-NoSQLBooster
- fjblog佛教博客不错
- Hibernate框架ORM的实现原理-不是技术的技术
- 中国替扎尼定行业市场供需与战略研究报告
- 【UOJ#177】欧拉回路
- AR的那些有用的工具
- 《Oracle 11g SQL 和PL SQL从入门到精通》 学习笔记
- 联合查询(union)——MySQL
- ElK STACK的简要分析
- ERP系统之结存功能
- 北京人工智能产业联盟成立,百度CTO王海峰出任联盟理事长
- 3ds Max 实验十五 UV展开综合运用
- 数据分析入门学习指南,零基础小白都能轻松看懂
- 对微机用户来说 为了防止计算机意外故障,对于微机用户来说,为了防止计算机意外故障而丢失重要数据,对重要数据应定期进行备份。下列移动存储器中,最不常用的一种是...
- Prolific USB-to-Serial Comm Port在win8.1下
- oracle 连接 双网卡,Oracle Linux 6.4(BOND)双网卡绑定实战—附加说明
- 阿联酋和沙特阿拉伯就加密货币展开合作