守卫解救acm_让作家阻止了它的解救
守卫解救acm
In this post, I’ll show you how Artificial Intelligence (AI) and Machine Learning (ML) can be used to help you get a start on that novel you always wanted to write. I’ll begin with a brief background on how computers process text using AI. Then I’ll describe how I set up an ML model called GPT-2 to generate new plot summaries, and give instructions on how you can create some new story ideas for yourself.
在本文中,我将向您展示如何使用人工智能(AI)和机器学习(ML)来帮助您开始编写自己一直想写的小说。 我将简要介绍计算机如何使用AI处理文本。 然后,我将描述如何建立一个称为GPT-2的ML模型以生成新的情节摘要,并说明如何自己创建一些新的故事创意。
This is the second part of my series of articles on how AI can be used for creative endeavors. The first part is on how to use ML to create abstract art, available here.
这是我的系列文章的第二部分,有关如何将AI用于创新活动。 第一部分是有关如何使用ML创建抽象艺术的信息,请参见此处 。
背景 (Background)
自然语言处理 (Natural Language Processing)
Natural Language Processing (NLP) is a field of Linguistics and Computer Science that studies how machines, with their computer languages like Java and Python, can communicate with humans, with their natural languages like English and Swahili. One of the first proponents of teaching computers to understand human language was Alan Turing. He wrote about it in 1950 [1].
自然语言处理(NLP)是语言学和计算机科学领域的一门学科,研究使用Java和Python等计算机语言的机器如何使用英语和斯瓦希里语等自然语言与人类进行交流。 艾伦·图灵(Alan Turing)是最早教计算机理解人类语言的拥护者之一。 他在1950年撰写了有关它的文章[1]。
We may hope that machines will eventually compete with men in all purely intellectual fields. But which are the best ones to start with? Even this is a difficult decision. Many people think that a very abstract activity, like the playing of chess, would be best. It can also be maintained that it is best to provide the machine with the best sense organs that money can buy, and then teach it to understand and speak English. — Alan Turing, Mathematician and Computer Scientist
我们可能希望机器最终将在所有纯知识领域与男人竞争。 但是,最开始的是哪些呢? 即使这是一个困难的决定。 许多人认为最好是一个非常抽象的活动,例如下棋。 还可以维护的是,最好为机器提供钱可以买到的最好的感觉器官,然后 教它理解和说英语。 —数学家和计算机科学家Alan Turing
文本到令牌 (Text to Tokens)
One of the first steps in processing text is converting words to numbers. This process is called tokenization. One of the simplest ways to tokenize text is to simply assign unique words and punctuation marks a numerical value in the order they appear in the input sequence. For example, consider the first part of the opening line from “Tale of Two Cities”.
处理文本的第一步之一就是将单词转换为数字。 此过程称为令牌化。 标记文本的最简单方法之一是简单地分配唯一的单词,并按其在输入序列中出现的顺序将标点符号标记为数值。 例如,请考虑“两个城市的故事”中开头部分的第一部分。
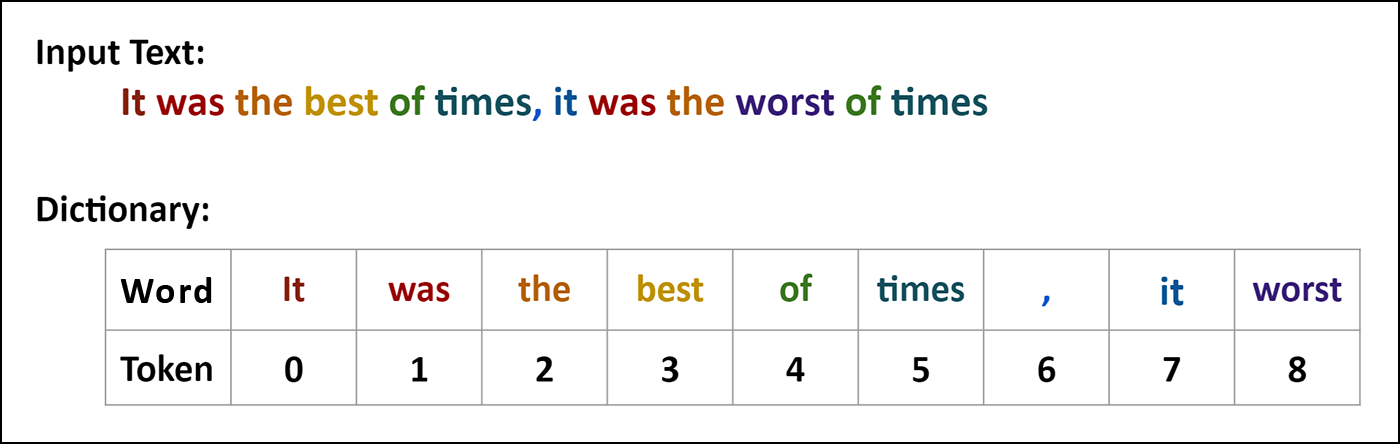
You can see that four of the words, “was”, “the”, “of”, and “times”, appear twice, and they get the same token value in both instances. In this scheme, capitalized words like “It” get a different token than “it” in lower case. Also, punctuation marks, like the comma, get their own token. You can read about various tokenization schemes in Srinivas Chakravarthy’s post here.
您可以看到单词“ was”,“ the”,“ of”和“ times”中的四个出现两次,并且在两种情况下它们都获得相同的标记值。 在此方案中,大写字母(如“ It”)与小写字母“ it”具有不同的标记。 此外,标点符号(如逗号)也获得了自己的令牌。 您可以在此处的 Srinivas Chakravarthy的文章中了解有关各种标记化方案的信息。
变形金刚 (Transformers)
Once the words are tokenized, they can be processed by machine learning systems for various tasks. For example, an ML model can be trained to translate text from one language to another. In the example below a transformer has been trained to translate from English to Spanish.
一旦单词被标记,机器学习系统就可以处理各种任务。 例如,可以训练ML模型将文本从一种语言翻译成另一种语言。 在下面的示例中,一名变压器经过了培训,可以将英语翻译成西班牙语。
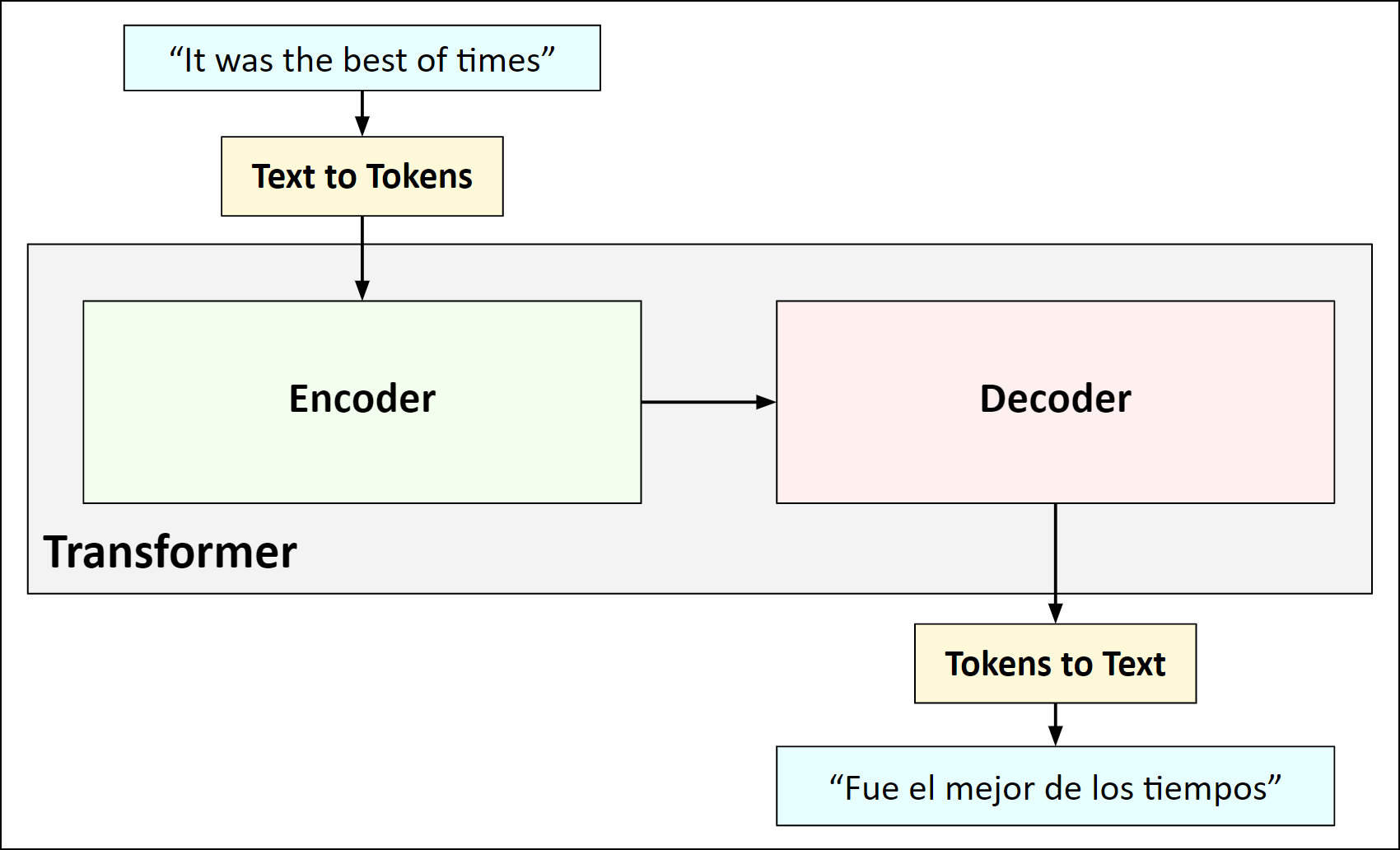
The input English text is converted to tokens before being fed into the transformer. Inside the transformer, the tokens are encoded into an internal “universal” form, then decoded into Spanish tokens, which are converted to Spanish words. For more information about transformers, check out this post by Maxime Allard.
输入的英文文本在输入到转换器之前将转换为令牌。 在转换器内部,将令牌编码为内部“通用”形式,然后解码为西班牙语令牌,然后将其转换为西班牙语单词。 有关变压器的更多信息,请查看Maxime Allard的这篇文章 。
GPT-2 (GPT-2)
In 2018, OpenAI created a system called the Generative Pretrained Transformer (GPT) [2]. They explained that large gains in NLP tasks …
在2018年,OpenAI创建了一个名为“预生成式变压器(GPT)”的系统[2]。 他们解释说,在NLP任务中大有收获...
… can be realized by generative pre-training of a language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task. — Alec Radford and colleagues from OpenAI
……可以通过在各种未标记文本的语料库上对语言模型进行生成式预训练,然后对每个特定任务进行区分性微调来实现。 — OpenAI的Alec Radford及其同事
The team from OpenAI created an improved version of the transformer called GPT-2 in 2019 [3]. In this paper, they said …
OpenAI的团队在2019年创建了改进版的变压器,称为GPT-2 [3]。 他们在本文中说……
… a language model with sufficient capacity will begin to learn to infer and perform the tasks demonstrated in natural language sequences in order to better predict them, regardless of their method of procurement. — Alec Radford and colleagues from OpenAI
…具有足够能力的语言模型将开始学习推断和执行以自然语言顺序演示的任务,以便更好地预测它们,而不论其采购方式如何。 — OpenAI的Alec Radford及其同事
Below is a diagram that shows the major components of GPT-2. Instead of using tokens with single values, GPT-2 uses word embeddings which are arrays of multiple numbers to represent each word. This gives the system the capacity to capture a more complete understanding of the words.
下图显示了GPT-2的主要组成部分。 GPT-2不是使用带有单个值的标记,而是使用单词嵌入,这些单词嵌入是由多个数字组成的数组来表示每个单词。 这使系统能够捕获对单词的更完整理解。
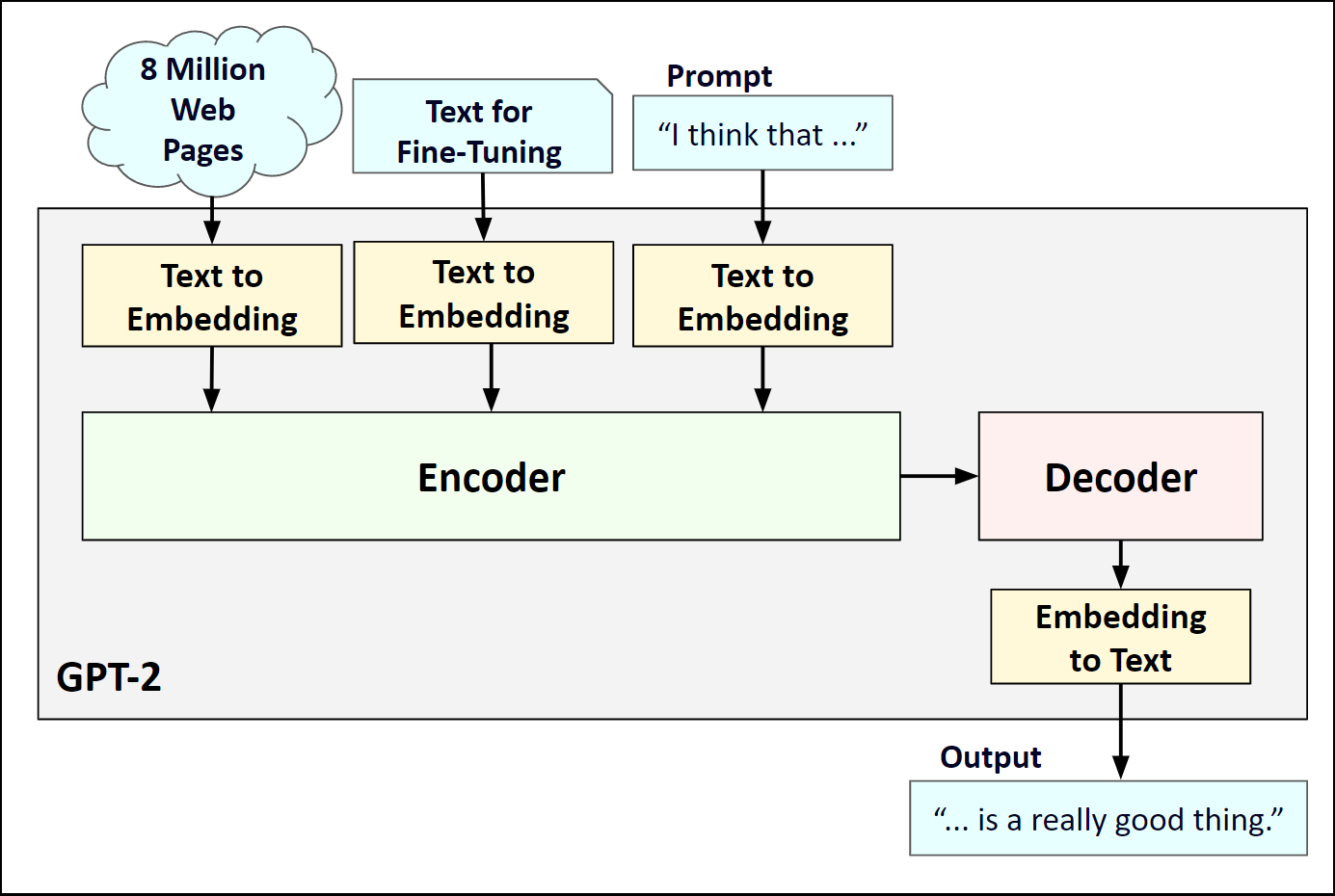
The GPT-2 model works in three phases:
GPT-2模型分为三个阶段:
- Initial training — Learns to understand language in general
初步培训-学习一般语言 - Fine-tuning — Learns to perform a specific task
微调-学习执行特定任务 - Prompt — Primes the system to start generating the output text
提示-启动系统以开始生成输出文本
Note that the model draws on the input from all three phases when generating text. You can read more about how GPT-2 works in Jay Alammar’s post here.
请注意,生成文本时,模型会使用所有三个阶段的输入。 你可以关于GPT-2是如何工作的周杰伦Alammar的帖子在这里 。
情节果酱 (PlotJam)
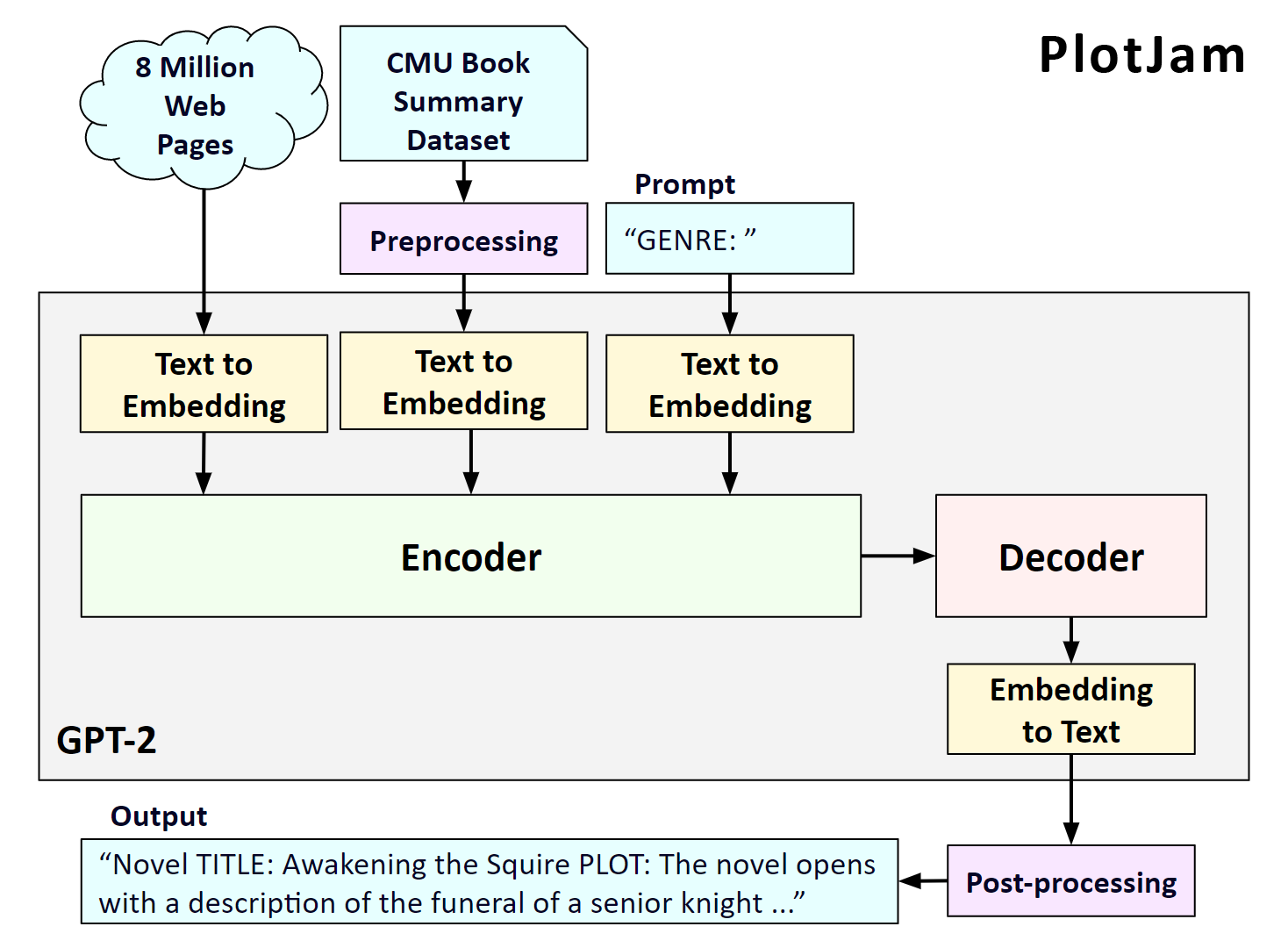
PlotJam is a system I created to help creative writers discover new stories. Using a GPT-2 model that was fine-tuned with titles and plot summaries of over 16 thousand English books, PlotJam creates new stories with titles and brief plot summaries. Here is a diagram that shows the main components.
PlotJam是我创建的一个系统,可以帮助创意作家发现新故事。 PlotJam使用GPT-2模型,该模型已对超过1.6万本英语书籍的书名和情节摘要进行了微调,从而创建了包含书名和情节摘要的新故事。 这是显示主要组件的图。
准备文本以进行微调 (Preparing the Text for Fine-Tuning)
The source of the fine-tuning text is the Book Summary Dataset from Carnegie Mellon University. I prepped the data by isolating just the genre, title, and the first part of the plot summary for each book.
微调文字的来源是卡内基梅隆大学的“书籍摘要”数据集 。 我通过仅隔离每本书的类型,标题和情节摘要的第一部分来准备数据。
Here’s an example of the original data for one of the books:
这是其中一本书的原始数据的示例:
Wikipedia ID 1166383Freebase ID /m/04cvx9Book title White NoiseBook author Don DeLilloPublication date 1985-01-21Genres Novel, Postmodernism, Speculative fiction, FictionPlot summarySet at a bucolic Midwestern college known only as The-College-on-the-Hill, White Noise follows a year in the life of Jack Gladney, a professor who has made his name by pioneering the field of Hitler Studies (though he hasn’t taken German language lessons until this year). He has been married five times to four women and has a brood of children and stepchildren (Heinrich, Denise, Steffie, Wilder) with his current wife, Babette. Jack and Babette are both extremely afraid of death; they frequently wonder which of them will be the first to die. The first part of White Noise, called "Waves and Radiation," is a chronicle of contemporary family. ...Here’s the Python code to preprocess the book summaries.
这是预处理书摘的Python代码。
Here’s one of the entries from the CMU Book Summary Dataset after preprocessing.
预处理后,这是CMU书籍摘要数据集中的条目之一。
GENRE: Novel, Postmodernism, Speculative fiction, Fiction TITLE: White Noise PLOT: Set at a bucolic Midwestern college known only as The-College-on-the-Hill, White Noise follows a year in the life of Jack Gladney, a professor who has made his name by pioneering the field of Hitler Studies (though he hasn't taken German language lessons until this year). He has been married five ...训练模型 (Training the Model)
After the book summary text was preprocessed, I used it to fine-tune the GPT-2 model. I ran the fine-tuning for 10,000 steps, which seems to be enough for the system to generate new plot summaries. Here’s the source code:
在对书籍摘要文本进行预处理之后,我用它来微调GPT-2模型。 我进行了10,000步的微调,这似乎足以使系统生成新的绘图摘要。 这是源代码:
生成图 (Generating Plots)
After the model is fine-tuned, it can be used to create new plots by calling the generate function. I pass in a prompt “GENRE:” which will signal the system to create the titles and plots of a story with a random genre.
对模型进行微调后,可以通过调用generate函数将其用于创建新图。 我输入了提示“ GENRE:”,该信号将向系统发出信号,以创建具有随机体裁的故事的标题和情节。
Here is the output, showing a new plot synthesized by GPT-2:
以下是输出,显示了GPT-2合成的新图:
GENRE: Mystery TITLE: Deadright’s Corner PLOT: The novel’s protagonist is Edward Wells, a young policeman who is given the job of turning around the case of a manslaughter in which a man killed his wife’s valet – the killing was clearly premeditated – after which he is induced to investigate the matter further. It is during this investigation that Wells discovers the terms of a secret contract between the police and a deceased man's ...OK. Here it is. The first new story. It’s in the mystery genre with the title “Deadright’ Corner”. And it seems to be a crime story with a young police officer as the protagonist. Not bad.
好。 这里是。 第一个新故事。 属于“ Deadright” Corner之类的神秘题材。 这似乎是一个犯罪故事,由一名年轻的警察担任主角。 不错。
检查创意 (Checking for Originality)
The GPT-2 system is designed to “just start writing” in the style of the data used for fine-tuning. When prompted with the prefix “GENRE:”, it will choose one of the genres it saw in the fine-tuning and then create a title and a brief plot summary. However, there is no guarantee that it will always create a new title and a unique plot. Sometimes it chooses an existing title and it may or may not come up with a plot similar to the published work.
GPT-2系统旨在“微调”使用的数据样式“刚刚开始写入”。 当出现前缀“ GENRE:”的提示时,它将选择在微调中看到的一种流派,然后创建标题和简短的情节摘要。 但是,不能保证它将始终创建新的标题和唯一的情节。 有时,它选择一个现有的标题,并且可能会或可能不会拿出与已发表作品相似的情节。
I filter out clearly recycled stories by post-processing the results to see if the title is unique or not. I check for previously used titles in the CMU dataset, as well as titles from the book review site Goodreads and the IMDB database which has titles for movies and TV shows. Here is a diagram that shows the number of titles in these three datasets.
我通过对结果进行后期处理来过滤出清晰可回收的故事,以查看标题是否唯一。 我检查了CMU数据集中以前使用的标题,以及书评网站Goodreads和包含电影和电视节目标题的IMDB数据库中的标题。 下图显示了这三个数据集中的标题数量。
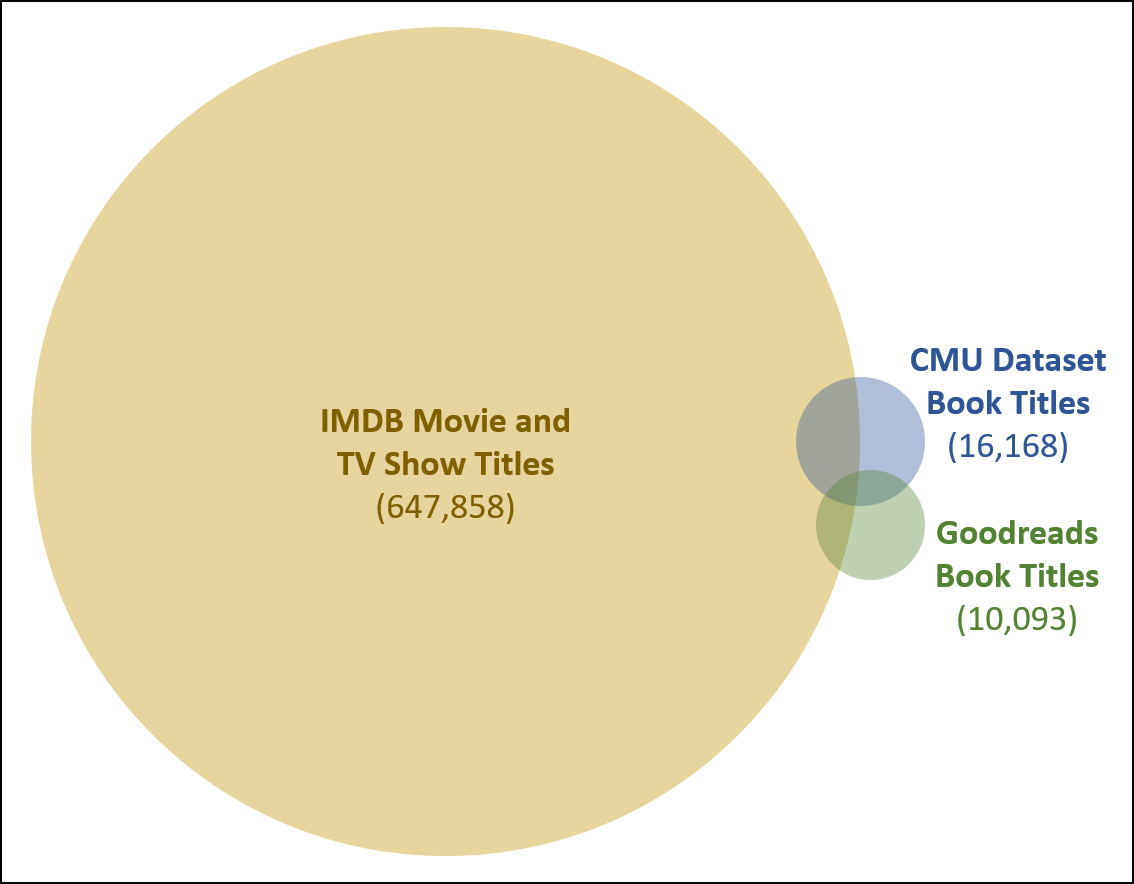
You can see that the IMDB database has a huge list of titles compared to the CMU dataset and Goodreads. Here is a code snippet that shows how I accumulate the list of titles to be used for duplicate checking.
您可以看到,与CMU数据集和Goodreads相比,IMDB数据库具有大量标题。 这是一个代码片段,显示了我如何累积用于重复检查的标题列表。
Note that I remove the articles “The” and “A” from the head of the titles. If GPT-2 comes up with the title “Great Gatsby” we’ll consider it a dupe and filter it out. Also, note that the list of titles is not exhaustive. There are plenty of published books that don’t have Wikipedia pages, reviews on Goodreads, or have been made into movies or TV shows. So if you see a story plot that you like, please do a little research first before writing your masterpiece to make sure it’s truly unique.
请注意,我从标题的开头删除了“ The”和“ A”一词。 如果GPT-2的标题是“ Great Gatsby”,我们将其视为欺骗并过滤掉。 另外,请注意标题列表并不详尽。 有很多已出版的书籍,没有Wikipedia页面,Goodreads上的评论,或者没有做成电影或电视节目。 因此,如果您看到自己喜欢的故事情节,请在编写杰作之前先做一点研究,以确保它真正独特。
不要重复自己。 不要重复自己。 (Don’t repeat yourself. Don’t repeat yourself.)
Sometimes the GPT-2 text generator gets stuck on a particular phrase and repeats it multiple times in a plot summary. You can see some repetition in this example.
有时,GPT-2文本生成器会卡在特定短语上,并在绘图摘要中重复多次。 您可以在此示例中看到一些重复。
GENRE: Science Fiction TITLE: Baseline Behavior PLOT: In the preface, Guy Sager explains his term for the branch of psychology that emphasizes the individual’s sense of themselves vs. the collective and their social relations. He believes that the individual’s sense of themselves can be affected by the environment (via the “environment in which they find themselves”). In other words, the individual’s sense of themselves can be saved by the environment (via their …Notice how the phrase “the individual’s sense of themselves” is repeated three times. I wrote a little function that looks for this artifact to filter out entries that have repetition. Here’s the Python code.
请注意,短语“个人的自我意识”是如何重复三遍的。 我编写了一个小函数来查找该工件,以过滤出具有重复的条目。 这是Python代码。
If the function sees a phrase of a given length in the input one or more times, it gets flagged with repetition. I use the phrase length of five to filter out repetitive plot summaries.
如果函数一次或多次在输入中看到给定长度的短语,则将其标记为重复。 我使用长度为5的短语来过滤出重复的图摘要。
在Google Colab中生成新故事 (Generating new Stories in Google Colab)
Here are instructions to run PlotJam. It runs as a Google Colab, a free service for experimenting with AI using a high-end GPU. Note that having a Google account is required.
这是运行PlotJam的说明。 它作为Google Colab运行,这是一项使用高端GPU进行AI实验的免费服务。 请注意,必须拥有Google帐户。
Click on the PlotJam link above.
单击上方的PlotJam链接。
Log into your Google account, if you’re not logged in already.
如果您尚未登录,请登录您的Google帐户 。
Click the first Run cell button (hover over the [ ] icon and click the play button). A warning will appear indicating that this notebook was not created by Google.
单击第一个“运行”单元格按钮(将鼠标悬停在[]图标上,然后单击“播放”按钮)。 将会出现警告,表明该笔记本不是由Google创建的。
Click Run anyway to initialize the system. It takes about 5 minutes to download the datasets and configure the pre-trained GPT-2 model.
单击“仍然运行”以初始化系统。 下载数据集并配置预训练的GPT-2模型大约需要5分钟。
Choose which genre you would like to try and hit the second Run cell button to generate some new story plots.
选择您想尝试的类型 ,然后单击第二个“运行”单元按钮以生成一些新的故事情节。
Choose a story that you like and hit the third Run cell button to generate five variations of the selected story plot.
选择一个您喜欢的故事,然后单击第三个“运行”单元按钮以生成所选故事情节的五种变体。
You can see that each of the plot variations start with the same genre and title, but are different in how the plot summary unfolds.
您可以看到,每个情节变体都以相同的流派和标题开头,但是情节摘要的显示方式不同。
未来的工作 (Future Work)
The PlotJam system is based on the “large” model of GPT-2. This model, with 774 million parameters, runs on the Google Colab system. Future work would be to use the “extra-large” model with 1.6 billion parameters which may have better results. OpenAI recently released a beta version of their GPT-3 model, which they claim has 175 billion parameters. This would probably do an even better job of creating plot summaries.
PlotJam系统基于GPT-2的“大型”模型。 该模型具有7.74亿个参数,可在Google Colab系统上运行。 未来的工作将是使用具有16亿个参数的“特大”模型,这可能会产生更好的结果。 OpenAI最近发布了其GPT-3模型的测试版,他们声称该模型具有1,750亿个参数。 创建情节摘要可能会做得更好。
致谢 (Acknowledgments)
I would like to thank Jennifer Lim for her help and feedback on this project.
我要感谢Jennifer Lim对这个项目的帮助和反馈。
源代码 (Source Code)
All source code for this project is available on GitHub. The sources are released under the CC BY-NC-SA license.
该项目的所有源代码都可以在GitHub上找到 。 来源根据CC BY-NC-SA许可发布 。

翻译自: https://towardsdatascience.com/got-writers-block-it-s-plotjam-to-the-rescue-e555db9f3272
守卫解救acm
相关文章:
- 【论文分享】ACL 2020 立场检测相关研究
- python工具包--Pandas
- python自动化plc_PYTHON – 让“Monty 语言”进入自动化行业:第 4 部分
- Karma、Jasager与WiFiPineApple之间的关系
- 致Play Framework开发者们的一封信
- 塞格Np7280游戏笔记本概述
- 中国眼部护理产品市场趋势报告、技术动态创新及市场预测
- 《一》注册订阅号并完成基本配置
- 全球与中国滴眼液和润滑剂市场深度研究分析报告
- 25.redux中间件redux-thunk和redux-saga
- ResultSet.TYPE_SCROLL_SENSITIVE到底发生了什么?
- task5b-验证lncRNA只有部分具有polyA尾结构
- 通过物理地址查计算机,别人知道我查电脑的物理地址,怎么处理
- OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading “D:\Anaconda\envs\pytorch-1.4\lib\site-package
- Python与MySQL交互——简易用户注册登录
- 去掉whatsns问答系统页面底部隐藏的官网链接
- 浅谈CURD系统和CRQS系统
- 一、pytorch环境配置
- spring-cloud-oauth2
- DiscuzNT 交易插件设计之商品添加,编辑和删除(CUD)
- 简单webform前端页面布局以及后台代码
- jquery知识点总结(2)--- CSS模块+筛选模块+文档处理(CUD)模块+事件模块
- 项目3-商城-1-注册登录首页
- 【MySQL - 3】数据库可视化工具SQLyog的安装使用及DML操作大全(CUD)
- 微信大全 微信支付 微信登录 小程序 PC 公众号
- React学习笔记—简易信息管理,实现CUD
- 008 使用MyBatis,easyUI实现CRUD操作样例-CUD(CRUD完毕)
- 某享瘦app登录逆向
- CSS模块、筛选模块、文档处理(CUD)模块、事件模块
- Vue——构造内嵌登录二维码
守卫解救acm_让作家阻止了它的解救相关推荐
- 解救人质的android游戏,一枪制敌解救人质游戏
一枪制敌解救人质游戏的画质非常的高清细腻,游戏需要选择不同形象的士兵进行闯关冒险,超多的关卡设计,丰富复杂的地形环境,武器的种类也比较多,发挥自己的战术能力,消灭每一个关卡中的敌人,并且成功的营救更多 ...
- 迷宫问题(解救小哈)
文章目录 解救小哈 完整代码 读入数据 输出数据 总结 解救小哈 迷宫由n行m列的单元格组成(n和m都<=50),每个单元格要么是空地要么是障碍物.小哼要以最快的速度解救小哈,帮助小哼找到一条从 ...
- 考研英语 - word-list-36
每天十个单词,本博客收集整理自<考研英语词汇>,仅供学习和个人积累. 新东方单词在线阅读地址 ,希望这个链接一直都有效 :) 2017年08月23日 07:18:44 ban 词义: vt ...
- 《中华人民共和国刑法》
刑法是规定犯罪.刑事责任和刑罚的法律,是掌握政权的统治阶级为了维护本阶级政治上的统治和各阶级经济上的利益,根据自己的意志,规定哪些行为是犯罪并且应当负何种刑事责任 ,并给予犯罪嫌疑人何种刑事处罚的法律 ...
- 啊哈算法系列(C语言、python、Java )
关于<啊哈!算法>相关资源 关于<啊哈!算法>相关资源 - 欣乐 - 博客园 第1章 一大波数正在靠近--排序 第1节 最快最简单的排序--桶排序 [坐在马桶上看算法]算法1: ...
- 青年在选择的职业时的思考
大学四年即将结束,回望这四年,有很多美好的回忆,但更多的是心有不甘--半路转行,考研失败,四年来一直都是孑然一身.我的前22年如梦似幻,从我有记忆伊始,我遇到了很多人,也别离了很多人,有久别重逢,也有 ...
- Moonlight Shadow
歌词 Moonlight Shadow 月光幽灵 -- Dana Winner 1. The last that ever she saw him 那是她今生最后一次见到他 2. carried aw ...
- 跳动的心c语言源代码,电影丨跳动的心投资份额有吗?怎么投资?什么时间上映...
该楼层疑似违规已被系统折叠 隐藏此楼查看此楼 国家层面对中国电影行业发展的鼓励和重视.从2015年年初到现在,传媒行业在所有分类行业里涨幅最大,表现尤为强劲;中国电影市场的持续火爆是有目共睹的文化现象 ...
- 《青年在选择职业时的考虑》
@<青年在选择职业时的考虑> 马克思 自然本身给动物规定了它应该遵循的活动范围,动物也就安分地在这个范围内活动,不试图越出这个范围,甚至不考虑有其他什么范围的存在.神也给人指定了共同的目标 ...
- vue 通过路由守卫阻止跳转
前提声明 使用的环境是 vue3,其他版本没做测试仅作参考 案例分析 制作一个登陆界面,在点击登录的时候进行匹配账号和密码,成功后再切换组件,如果输错弹出alter. 前提条件:登录是一个嵌套在内部的 ...
最新文章
- 记录一个免费而且好用的SSH登录软件_SecureCRT
- ICRA 2021| 聚焦距离的Camera-IMU-UWB融合定位方法
- python 03 字符串详解
- IPSEC造成网络Destination host unreachable
- string替换_GEE数据类型—String,Number
- TOGAF:从业务架构到业务需求
- 变换例题_用初等变换求逆矩阵的小小解释
- 毕昇 JDK:“传奇再现”华为如何打造 ARM 上最好用的 JDK?
- DDD(领域驱动设计)
- 【辨异】—— 可见 vs. 不可见
- 人脸对齐(十五)--PIFA with a Single CNN
- 深入理解 Javascript 面向对象编程
- java论文word_word 论文 排版 适用于 word2016
- MPB:南农韦中组-根系分泌物调控土壤微生物群落结构和功能的研究方法
- java报错symbol_java 报错cannot resolve symbol问题
- Win10 51仿真器PZTracker驱动安装失败 未知设备
- java:定义一个Shape类,派生出Circle类和Rectangle类,手写模拟GeoArrayList,实现升序(升序以面积大小判断)存入Circle类和Rectangle类
- 该怎么说,爱到最后成了路人甲,陌路天涯
- 【寒假每日一题】分巧克力(个人练习)详细题解+推导证明(第八天)附带转载程序员壁纸
- 微信小程序图片根据屏幕比例缩放