0x10基本数据结构
0x11 栈
栈是一种后进先出的线性数据结构
AcWing 41.包含min函数的栈
维护两个栈,一个记录栈的值,另一个单调栈,记录下当前的最小值即可
coding
AcWing 128. 编辑器
开两个栈维护,类似对顶堆的操作,我们把他叫做对顶栈好了
令\(P\)为光标位置,分别开两个栈\(a,b\)
栈\(a\)存\(P\)之前的数,栈\(b存\)P$之后的数
\(sum\)是前缀和,\(f\)是前缀和的最大值
对于操作\(L\),把\(x\)压入栈\(a\)并更新\(sum\)和\(f\)
对于操作\(D\) ,栈\(a\)栈顶弹出
对于操作\(L\),把栈顶\(a\)弹出并压入栈\(b\)
对于操作\(R\),把栈顶\(b\)弹出并压入栈\(a\)同时更新\(sum\)和\(f\)
对于操作\(Q\),返回\(f[x]\)
#include <bits/stdc++.h>
using namespace std;const int N = 1e6 + 5 , INF = 0x7ffffff;
int T , opt , a[N] , b[N] , sum[N] , f[N] , ta = 0 , tb = 0;inline int read( bool _ )
{register int x = 0 , f_ = 1;register char ch = getchar();if( _ ){while( ch < '0' || ch > '9' ){if( ch == '-' ) f_ = -1;ch = getchar();}while( ch >= '0' && ch <= '9'){x = ( x << 3 ) + ( x << 1 ) + ch - '0';ch = getchar();}return x * f_;}else{while( ch != 'L' && ch != 'R' && ch != 'I' && ch != 'D' && ch != 'Q' ) ch = getchar();return int(ch);}
}inline void work_1()
{a[ ++ ta ] = read(1);sum[ta] = sum[ ta - 1 ] + a[ta];f[ta] = max( sum[ta] , f[ ta - 1] );return ;
}inline void work_2()
{if( ta > 0 ) ta --;return ;
}inline void work_3()
{if( ta > 0 )b[ ++ tb] = a[ ta ] , ta --;return ;
}inline void work_4()
{if( !tb ) return ;a[ ++ ta ] = b[tb];tb --;sum[ta] = sum[ta - 1] + a[ta];f[ta] = max( sum[ta] , f[ ta - 1] );return ;
}inline void work_5()
{printf("%d\n",f[ read(1) ] );return ;
}int main()
{f[0] = -INF;T = read(1);while( T -- ){opt = read(0);if(opt == 'I' ) work_1();else if(opt == 'D' ) work_2();else if(opt == 'L' ) work_3();else if(opt == 'R' ) work_4();else work_5();}return 0;
}AcWing 131. 直方图中最大的矩形
画图手玩样例就能发现规律
单调栈的经典应用,不过我比较懒,STL+O2直接水过去
#include <bits/stdc++.h>
#pragma GCC optimize(2)
#define LL long long
using namespace std;const int N = 100005;
int n , now , width ;
LL res;
struct node
{int w , h;
}_;
stack< node > s;inline int read()
{register int x = 0;register char ch = getchar();while( ch < '0' || ch > '9' ) ch = getchar();while( ch >= '0' && ch <= '9' ){x = ( x << 3 ) + ( x << 1 ) + ch - '0';ch = getchar();}return x;
}inline node make( int x , int y )
{_.h = x , _.w = y;return _;
}int main()
{while( 1 ){n = read();if( !n ) return 0;res = 0;for( register int i = 1; i <= n ; i ++ ){now = read();if( s.empty() || now > s.top().h ) s.push( make( now , 1 ) );else{width = 0;while( !s.empty() && s.top().h > now ){width += s.top().w;res = max( res , (LL)width * s.top().h );s.pop();}s.push( make( now , width + 1 ) );}}width = 0;while( !s.empty() ){width += s.top().w;res = max( res , (LL)width * s.top().h );s.pop();}printf( "%lld\n" , res );}return 0;
}
0x12 队列
队列是一种“先进先出”的线性数据结构,手写队列时可以用循环队列来优化空间
队列还有一些变形体,优先队列,单调队列,双端队列,这些在\(STL\)中都是有的,不过常数比较大普通队列手写即可
另外优先队列在pbds中也有
AcWing 132. 小组队
这道题本身并不难,只是数据的处理比较恶心
首先开一个队列为维护小组,再开\(n\)个队列维护每个小组的成员
每次压入一个元素,就把这个元素加入这个小组的队列,如果这个小组的队列是空的就把他加入总的队列
每次弹出一个元素,就把总队列队头的小组弹出一个,如果队头小组的队列此时为空,就把队头小组从总队列总弹出
这道题并不是十分的卡常数,不开\(O2\)貌似能过,
另外插队不是好习惯,小心被打
#include <bits/stdc++.h>
#pragma GCC optimize(2)
using namespace std;const int N = 1e6 + 5 , M = 1005;
int n , t , m , num , cub[N];
string opt;
map< int , queue<int> > member;
queue< int > team;inline int read()
{register int x = 0;register char ch = getchar();while( ch < '0' || ch > '9' ) ch = getchar();while( ch >= '0' && ch <= '9' ){x = ( x << 1 ) + ( x << 3 ) + ch - '0';ch = getchar();}return x;
}inline void push()
{num = read();if( member[ cub[num] ].empty() ) team.push( cub[num] );member[ cub[num] ].push( num );return ;
}inline void pop()
{num = team.front();printf( "%d\n" , member[ num ].front() );member[ num ].pop();if( member[ num ].empty() ) team.pop();
}inline void work( int k )
{n = read();if( !n ) exit(0);printf( "Scenario #%d\n" , k );while( !team.empty() ){num = team.front();while( !member[ num ].empty() ) member[ num ].pop();team.pop();}memset( cub , 0 , sizeof(cub) );for( register int i = 1 ; i <= n ; i ++ ){t = read();while( t -- ) cub[ read() ] = i;}while( 1 ){cin >> opt;if( opt == "ENQUEUE" ) push();else if( opt == "DEQUEUE" ) pop();else break;}puts("");return ;
}int main()
{for( register int k = 1 ; 1 ; k ++ ) work(k);return 0;
}AcWing 135. 最大子序和
单调队列的基操
首先对于区间和的问题一般情况下都是转发乘前缀和数组,做差即可
然后就是找左右端点的问题
令前缀和数组为\(s\)
已经枚举的右端点\(i\)和当前的左端点\(j\)
此时再任意一个\(k\)如果满足\(k<j<i\)且\(s[k]>s[j]\),着\(k\)无论如何也不可能成为最有解,因为对于任意的\(i\)如果可以选\(j\)则\(j\)一定\(k\)更优
所以我们发现需要维护一个单调递增的序列,并且随着\(i\)的有移,将会有部分的\(j\)不能使用
符合单调队列的性质所以用单调队列来维护,队列储存的元素是前缀和数组的下标,队头为\(l\),队尾为\(r\)
对于每次枚举的\(i\)有以下几个操作
- 如果\(q[l] < i - m\)将队头出对
- 此时的\(l\)就是最有的\(j\)更新答案
- 维护单调队列性质并把\(i\)放入队列
#include <bits/stdc++.h>
using namespace std;const int N = 300000;
int n , m , s[N] , q[N] , l = 1 , r = 1 , res ;inline int read()
{register int x = 0 , f = 1;register char ch = getchar();while( ch < '0' || ch > '9' ){if( ch == '-' ) f = -1;ch = getchar();}while( ch >= '0' && ch <= '9' ){x = ( x << 3 ) + ( x << 1 ) + ch - '0';ch = getchar();}return x * f;
}int main()
{n = read() , m = read();for( register int i = 1 ; i <= n ; i ++ ) s[i] = s[i-1] + read();for( register int i = 1 ; i <= n ; i ++ ){while( l <= r && q[l] < i - m ) l ++;res = max( res , s[i] - s[ q[l] ] );while( l <= r && s[ q[r] ] >= s[i] ) r --;q[ ++ r ] = i;}cout << res << endl;return 0;
}0x13链表与邻接表
数组是一种支持随机访问,但不支持在任意位置插入或删除元素的数据结构
链表支持在任意位置插入或删除,但只能按顺序访问其中的元素
链表的正规形式一般是通过动态分配内存、指针实现,为了避免内存泄漏、方便调试使用数组模拟链表、下标模拟指针也是常见的做法
指针版
struct Node {int value; // dataNode *prev, *next; // pointers
};
Node *head, *tail;void initialize() { // create an empty listhead = new Node();tail = new Node();head->next = tail;tail->prev = head;
}void insert(Node *p, int value) { // insert data after pq = new Node();q->value = value;p->next->prev = q; q->next = p->next;p->next = q; q->prev = p;
}void remove(Node *p) { // remove pp->prev->next = p->next;p->next->prev = p->prev;delete p;
}void recycle() { // release memorywhile (head != tail) {head = head->next;delete head->prev;}delete tail;
}数组模拟
struct Node {int value;int prev, next;
} node[SIZE];
int head, tail, tot;int initialize() {tot = 2;head = 1, tail = 2;node[head].next = tail;node[tail].prev = head;
}int insert(int p, int value) {q = ++tot;node[q].value = value;node[node[p].next].prev = q;node[q].next = node[p].next;node[p].next = q; node[q].prev = p;
}void remove(int p) {node[node[p].prev].next = node[p].next;node[node[p].next].prev = node[p].prev;
}// 邻接表:加入有向边(x, y),权值为z
void add(int x, int y, int z) {ver[++tot] = y, edge[tot] = z; // 真实数据next[tot] = head[x], head[x] = tot; // 在表头x处插入
}// 邻接表:访问从x出发的所有边
for (int i = head[x]; i; i = next[i]) {int y = ver[i], z = edge[i];// 一条有向边(x, y),权值为z
}AcWing 136. 邻值查找
首先我们开一个pair记录\(A_i\)和对应的\(i\)
然后排序,并用一个链表维护这个序列,链表的值是每个数字排序后的位置
所以每个链表的前驱就是小于等于这个数中最大的,后继就是大于等于这个数中最小的
然后我们倒着访问从\(n\)开始,因为这样不管是前驱还是后继在原序列中的位置一定比当前数在原序列中的位置跟靠前
做差比较、记录结果
然后删掉当前这个数字,因为剩下的数字在原序列中都比他靠前,所以这个数字一定不会是其他数字的结果
#include <bits/stdc++.h>
#define LL long long
using namespace std;const int N = 1e5 + 5 , INF = 0x7f7f7f7f;
int n , l[N] , r[N] , p[N];
pair< int ,int > a[N] , res[N];inline int read()
{register int x = 0,f = 1;register char ch = getchar();while(ch < '0' || ch > '9'){if( ch == '-' ) f = -1;ch = getchar();}while( ch >= '0' && ch <= '9' ){x = ( x << 3 ) + ( x << 1 ) + ch - '0';ch = getchar();}return x * f;
}int main()
{n = read();for( register int i = 1 ; i <= n ; i ++ ){a[i].first = read();a[i].second = i;}sort( a + 1 , a + 1 + n );a[0].first = -INF , a[ n + 1 ].first = INF;for( register int i = 1 ; i <= n ; i ++ ) l[i] = i - 1 , r[i] = i + 1 , p[ a[i].second ] = i;for( register int i = n ; i > 1 ; i -- ){register int j = p[i] , L = l[j] , R = r[j] ;register LL l_val = abs( a[L].first - a[j].first ) , r_val = abs( a[R].first - a[j].first );if( l_val <= r_val ) res[i].first = l_val , res[i].second = a[L].second;else res[i].first = r_val , res[i].second = a[R].second;l[R] = L , r[L] = R;}for( register int i = 2 ; i <= n ; i ++ ) printf( "%d %d\n" , res[i].first , res[i].second );return 0;
}0x14 Hash
Hash 表
Hash表 又称散列表,一般有Hash函数与链表结构共同构成
Hash表主要包括两个基本操作
- 计算Hash函数的值
- 定位到对应的链表中依次遍历、比较
常用的的Hash函数是\(H(x) = (x\mod \ p)+ 1\)
这样显然可以把所有的数分成\(p\)个,如果遇到冲突情况,用链表维护即可
AcWing 137. 雪花雪花雪花
设计Hash函数为\(H(a_1,a_2,\cdots,a_6) = (\sum^{6}_{i=1}a_i + \Pi^{6}_{i=1}a_i)\ mod\ p\),其中\(p\)是一个我们自己选择的一个大质数
然后我们依次把每个雪花插入Hash表中,在对应的链表中查找是否已经有相同的雪花
判断是否有相同雪花的方式就是直接暴力枚举就好
#include <bits/stdc++.h>
using namespace std;const int N = 100010,p = 9991;
int n ,head[N] , nxt[N] ,snow[N][6], tot;inline int H( int *a )
{int sum = 0 , mul = 1 ;for( register int i = 0 ; i < 6 ; i ++ ) sum = ( sum + a[i] ) % p , mul = ( ( long long )mul * a[i] ) % p;return ( sum + mul ) % p;
}inline int read()
{register int x = 0;register char ch = getchar();while( ch < '0' || ch > '9' ) ch = getchar();while( ch >= '0' && ch <= '9' ){x = ( x << 3 ) + ( x << 1 ) + ch - '0';ch = getchar();}return x;
}inline bool equal( int *a, int *b)
{for( register int i = 0 ; i < 6 ; i ++ ){for( register int j = 0 ; j < 6 ; j ++ ){bool eq = 1;for( register int k = 0 ; k < 6 && eq; k ++ ){if( a[ ( i + k ) % 6 ] != b[ ( j + k ) % 6 ] ) eq = 0; }if( eq ) return 1;eq = 1;for( register int k = 0 ; k < 6 && eq; k ++ ){if( a[ ( i + k ) % 6 ] != b[ ( j - k + 6 ) % 6 ] ) eq = 0;}if ( eq ) return 1;}}return 0;
} inline bool insert( int *a )
{register int val = H( a );for( register int i = head[val] ; i ; i = nxt[i] ){if(equal(snow[i] , a ) ) return 1;}++ tot;memcpy( snow[tot] , a , 6 * sizeof( int ) );nxt[ tot ] = head[val];head[val] = tot;return 0;
}int main()
{n = read();int a[10];for( register int j = 1 ; j <= n ; j ++ ){for( register int i = 0 ; i < 6 ; i ++ ) a[i] = read();if( !insert( a ) ) continue;puts( "Twin snowflakes found." );exit(0); }puts( "No two snowflakes are alike." );return 0;
}字符串Hash
下面介绍的字符串\(Hash\)函数把任意一个长度的支付串映射成一个非负整数,并且冲突的概率近乎为\(0\)
取一固定值\(P\),把字符串看成是\(P\)进制数并且分配一个大于\(0\)的数值,代表每种字符。一般说,我们分配的数值都远小于\(P\)。例如,对于小写字母构成的字符串,可以令\(a=1,b=2,\dots ,z = 26\)。取一固定值M,求出该P进制数对M取的余数,作为该字符的\(Hash\)值。
一般来说,我们取\(P=131\)或\(P=13331\),此时\(Hash\)值产生的冲突概率极低,通常我们取\(M=2^{26}\),即直接使用\(unsigned\ long\ long\)的自然溢出来代替低效率的取模运算。
但是在极端构造的数据中取模会导致\(Hash\)冲突,所以可以采用链表来存下每个字符串,也可以通过多次\(Hash\)来解决
AcWing 140. 后缀数组
这道题是字符串Hash,首先把原字符串的前缀进行Hash
然后用一个数组来代表后缀,通过\(O(1)\)计算得到后缀的Hash
然后在比较时,我们通过二分,二分出两个后缀的最大公共前缀,我们只需比较公共前缀的下一位就可以比较两个后缀的字典序
#include <bits/stdc++.h>
#define ULL unsigned long long
#define H( l , r ) ( h[r] - h[ l - 1 ] * p[ r - l + 1 ] )
using namespace std;const int N = 300010 , base = 131;
int n ,sa[N];
ULL h[N] , p[N];
char str[N];inline ULL get_max_common_prefix( int a , int b )
{int l = 0 , r = min( n - a + 1 , n - b + 1 );while( l < r ){int mid = l + r + 1 >> 1;if( H( a , a + mid - 1 ) != H( b , b + mid - 1 ) ) r = mid - 1;else l = mid;}return l;
}inline bool cmp( int a , int b)
{register int l = get_max_common_prefix( a , b );register int av = a + l > n ? INT_MIN : str[ a + l ];register int bv = b + l > n ? INT_MIN : str[ b + l ]; return av < bv;
}int main()
{scanf( "%s" , str + 1 );n = strlen( str + 1 );p[0] = 1 ;for( register int i = 1 ; i <= n ; i ++ ){p[i] = p[ i - 1 ] * base;h[i] = h[ i - 1 ] * base + str[i] - 'a' + 1 ;sa[i] = i;}sort( sa + 1 , sa + 1 + n , cmp );for( register int i = 1 ;i <= n ; i ++ ) printf("%d " , sa[i] - 1 );puts("");for( register int i = 1; i <= n ;i ++ ){if( i == 1 ) printf( "0 " );else printf( "%d " , get_max_common_prefix( sa[ i - 1 ] , sa[i] ) ); }puts("");return 0;
}
0x15 字符串
KMP模式匹配
\(KMP\)算法,又称模式匹配算法,能够在线性时间内判定字符串\(A[1\dots N]\)是否是字符串\(B[1\dots M]\)的子串,并求出字符串\(A\)在字符串\(B\)中出现的位置
KMP算法分为两步
对字符串A进行自我匹配,求出一个数组\(next\),其中\(next[i]\)表示“\(A\)中以\(i\)结尾的非前缀子串”与“\(A\)的前缀”能够匹配的最长长度,即:
\(next[i] = max\{ j \}\),其中\(j<i\)且\(A[i-j+1\dots i] = A[1\dots j]\)
特别地,当不存在这样的\(j\)时\(next[i] = 0\)
对于字符串\(A\)与\(B\)进行匹配,求出一个数组\(f\),其中\(f[i]\)表示“\(B\)中以\(i\)结尾的子串”与“\(A\)的前缀”能够匹配的最长长度,即:
\(f[i] = max\{ j \}\),其中\(j\le i\)且\(B[i-j+1\dots i] = A[1\dots j]\)
\(KMP\)算法\(next\)数组的求法
next[1] = 0;
for( register int i = 2 , j = 0 ; j <= n ; i ++ )
{while( j && a[i] != a[ j + 1 ] ) j = next[j];if( a[i] == a[ j + 1 ] ) j ++ ;next[i] = j;
}\(KMP\)算法\(f\)数组的求法
for( register int i = 1 , j = 0 ; i <= m ; i ++ )
{while( j && ( j == n || b[i] != a[ j + 1 ] ) ) j = next[j];if( b[i] == a[ j + 1 ] ) j ++;f[i] = j;if( f[i] == n ) //此时就是A在B中间出现一次
}CF1029A
这道题实际上就是一道啊很简单的\(KMP\)模板题,理解下\(KMP\)里\(next\)数组的作用就明白了
先输出原序列,在把\(t[next[n]\cdots n]\)输出\(k-1\)次就好
#include <bits/stdc++.h>
using namespace std;const int N = 60;
int n , k , nxt[N];
char t[N];int main()
{cin >> n >> k;scanf( "%s" , t + 1 );nxt[1] = 0;for( register int i = 2 , j = 0 ;i <= n ; i ++ ){while( j && t[i] != t[ j + 1 ] ) j = nxt[j];if( t[i] == t[j + 1] ) j ++ ;nxt[i] = j ;} printf( "%s" , t + 1 );for( ; k > 1 ; k -- ) {for( register int i = nxt[n] + 1 ; i <= n ; i ++ ) printf( "%c" , t[i] );}puts("");return 0;
}最小表示法
给定一个字符串\(S[1\dots n]\),如果我们不断的把它的最后一个字符放到开头,最终会得到\(n\)个字符串,称这\(n\)个字符串是循环同构的。这些字符串中字典序最小的一个称为字符串\(S\)的最小表示法
算法流程
- 初始化i=1,j=2
- 通过直接先后扫描的方法比较 b[i]与b[j]两个循环同构串。
- 如果扫描了n个字符后仍然相等,说明s有更小的循环元(例如catcat有循环元cat),并且该循环元以扫描完成,B[min(i,j)]即为最小表示,算法结束
- 如果在i+k与j+k处发现不想等:
- 若ss[i+k]>ss[j+k],令i=i+k+1。若此时i=j,再令i=i+1
- 若ss[i+k]<ss[j+k],令j=j+k+1。若此时i=j,再令j=j+1
- 若i>n或j>n,则B[min(i,j)]为最小表示;否则重复第二步
int n = strlen( s + 1 );
for( register int i = 1 ; i <= n ; i ++ ) s[ n + i ] = s[i];
int i = 1 , j = 2 , k;
while( i <= n && j <= n )
{for( k = 0 ; k < n && s[ i + k ] == s[ j + k ] ; k ++ );if( k == n ) break;//s形如 catcat ,它的循环元以扫描完成if( s[ i + k ] > s[ j + k ] ){i += k + 1;if( i == j ) i ++;}else {j += k + 1;if( i == j ) j ++; }
}
ans = min( i , j ); //B[ans]是s的最小表示 Luogu P1368
看题目,简单分析就知道是落得最小表示法
#include <bits/stdc++.h>
#define LL long long
using namespace std;const int N = 300005 * 2 ;
int n , ans;
LL a[N];inline LL read()
{register LL x = 0;register char ch = getchar();while( ch < '0' || ch > '9' ) ch = getchar();while( ch >= '0' && ch <= '9' ){x = ( x << 3 ) + ( x << 1 ) + ch - '0';ch = getchar();}return x;
}inline void mini_notation()
{register int i = 1 , j = 2 , k;while( i <= n && j <= n ){for( k = 0 ; k < n && a[ i + k ] == a[ j + k ] ; k ++ );if( k == n ) break;if( a[ i + k ] <= a[ j + k ] ){j += k + 1;if( i == j ) j ++;}else{i += k + 1;if( i == j ) i ++;}}ans = min( i , j );
}int main()
{n = read();for( register int i = 1 ; i <= n ; i ++ ) a[ i + n ] = a[i] = read();mini_notation();for( register int i = ans , j = 1 ; j <= n ; i ++ , j ++ ) printf( "%lld " , a[i] );puts("");return 0;}0x16 Trie
Trie,又称字典树,是一种用于实现字符串快速检索的多叉树结构。Trie的每个节点都拥有若干个字符指针,若在插入或检索字符串时扫描到一个字符c,就沿着当前节点的这个字符指针,走向该指针指向的节点。
Trie的节点可以使用一个结构体进行储存,如下代码中,trans[i]表示这个节点边上的之父为i的边到达儿子节点的编号,若为0则表示没有这个儿子节点
struct node
{int trans[z];// z为字符集的大小bool bo;// 若bo = true 则表示这个顶点代表的字符串是集合中的元素
}tr[N];现在要对一个字符集的Trie插入一个字符串s
inline void insert(string s)
{register int len = s.size(),u = 1;for(register int i = 0;i < len;i ++){if(!tr[u].trans[s[i] - 'a']) tr[u].trans[s[i] - 'a'] = ++ tot;//若不存在这条边则要建立一个新的节点 tot为总的点数 u = tr[u].trans[s[i] - 'a']; }tr[u].bo = 1; //在结尾表示它代表的字符串是集合中的一个元素 return ;
} 查询一个字符串s是否在集合中某个串的前缀
inline bool search(string s)
{register int len = s.size(),u = 1;for(register int i = 0;i < len; i ++){if(!tr[u].trans[s[i] - 'a']) return 0;u = tr[u].trans[s[i] - 'a'];}return 1;
}查询一个字符串s是否是集合中的一个元素
inline bool query(string s)
{register int len = s.size(),u = 1;for(register int i = 0;i < len; i ++){if(!tr[u].trans[s[i] - 'a']) return 0;u = tr[u].trans[s[i] - 'a'];}return tr[u].bo;
}AcWing 142. 前缀统计
构建一颗\(tire\)树在每个结点存一个\(cn\)t记录以当前节点为结尾的字符串有多少个
然后在遍历\(tire\)树将\(cnt\)求和即可
#include <bits/stdc++.h>
#define I( x ) ( x - 'a' )
using namespace std;const int N = 1e6 + 5 , Z = 30;
int n , m , tot = 1 , len , u , ans ;
string s;struct node
{int cnt , trans[Z];
}tr[N];inline void insert()
{len = s.size() , u = 1;for( register int i = 0 ; i < len ; i ++ ){if( !tr[u].trans[ I( s[i] ) ] ) tr[u].trans[ I( s[i] ) ] = ++ tot;u = tr[u].trans[ I( s[i] ) ];}tr[u].cnt ++;return ;
}inline int search()
{len = s.size() , u = 1 ,ans = 0;for( register int i = 0 ; i < len ; i ++ ){if(!tr[u].trans[ I( s[i] ) ] ) return ans;u = tr[u].trans[ I( s[i] ) ];ans += tr[u].cnt;}return ans;
}int main()
{cin >> n >> m;for( register int i = 1 ; i <= n ; i ++ ) {cin >> s;insert();}for( register int i = 1 ; i <= m ; i ++ ){cin >> s;cout << search() << endl; }return 0;
}AcWing 143.最大异或对
要写这道题首先要了解一些位运算的相关知识
首先我们可以构建一个\(01tire\),把所有的数字转化成二进制插入
然后我们枚举一下每一个数字,然后去\(01tire\)中查找,查找每一位时,首先查找是否有和当前位相反的,如果有就选择
这样查找完后,得到二进制数就是所有数字中和当前数异或值最大的,对所有的最大值取\(max\)即可
观察发现,我们可以一遍建树,一边查找,效果是一样的
#include <bits/stdc++.h>
using namespace std;const int N = 1e5 + 5;
int n , a[N] , tot = 1 , res = -1;struct Trie
{int to[2];
}t[ N * 32 ];inline int read()
{register int x = 0;register char ch = getchar();while( ch < '0' || ch > '9' ) ch = getchar();while( ch >= '0' && ch <= '9' ){x = ( x << 1 ) + ( x << 3 ) + ch - '0';ch = getchar();}return x;
}inline void insert( int x )
{register int u = 1 , s;for( register int i = 30 ; i >= 0 ; i -- ){s = x >> i & 1 ;if( !t[u].to[s] ) t[u].to[s] = ++ tot;u = t[u].to[s];}
}inline int search( int x )
{register int u = 1 , ans = 0 , s;for( register int i = 30 ; i >= 0 ; i -- ){s = x >> i & 1;if( t[u].to[ s ^ 1 ] ) u = t[u].to[ s ^ 1 ] , ans |= 1 << i;else u = t[u].to[s];}return ans;
}int main()
{n = read();for( register int i = 1 ; i <= n ; i ++ ) a[i] = read() , insert( a[i] ) , res = max( res , search( a[i] ) );cout << res << endl;return 0;
}0x17 二叉堆
二叉堆是一种支持插入、删除、查询最值的数据结构。它其实是一颗满足“堆性质”的完全二叉树
二叉树的实现可以手写,当然我自己跟推荐使用STL,当然pbds也可以
priority_queue
构造
priority_queue< int > q;//大根堆
priority_queue< int , vector< int > , greater< int > > q;//小根堆注意priority_queue中储存的元素类型必须定义“小于号”,较大的元素会被放在堆顶。内置的int、string等类型已经定义过“小于号”,若使用结构体则必须重载运算符
由于priority_queue是按照从大到小排序所以重载运算符时也要反过来
struct node
{int value ;friend bool operator < (node a , node b){return a.value > b.value;}
};成员函数
q.top();\\访问堆顶元素
q.empty();\\检查是否为空
q.size();\\返回容纳的元素数
q.push();\\插入元素,并排序
q.pop();\\删除栈顶元素懒惰删除法
如果是手写的堆是支持删除任意一个元素,而\(STL\)却不支持这种操作所以我们可以用懒惰删除法
懒惰删除法又称延迟删除法,是一种应对策略。当遇到删除操作时,仅在优先队列之外做一些特殊的记录,用于辨别是否堆中的元素被删除。当从堆顶取出元素时判断是否已经被删除,若是,我们重新取一个最值。换言之,元素的“删除”推迟到堆顶执行
比如“堆优化的\(Dijkstra\)算法”中当某个元素首次被取出时就达到了最短路,当我们再次取出这个元素时我们不会重新进行扩展,而是使用一个\(bool\)数组判断“是否进行过扩展”,其本质还是懒惰删除法的应用
AcWing 146. 序列
首先这道题目,我们可以先考虑\(m=2\)的这种特殊情况
我们发现,当\(A\)序列和\(B\)序列从小到大排序后,最小和肯定是\(A[1]+B[1]\),而次小和必然是\(min(A[2]+B[1],A[1]+B[2])\),也就是说当我们确定好\(A[i][j]\)为\(K\)小和的话,那么第\(k+1\)小的和,必然是\(min(A[k+1]+B[k],A[k]+B[k+1])\),既然如此的话,我们还要注意一点,\(A[1]+B[2]\)和\(A[2]+B[1]\)都可以推导出\(A[2]+B[2]\),所以说我们要记得,如果说\(j+1\)了,那么i就不要\(+1\)了,避免出现重叠,导致答案错误.至于\(min\)函数,可以使用小根堆来维护当前最小值.
数学的归纳法,我们就可以从\(2\),推到\(N\)的情况,也就是先求出前两个序列的值,然后推出前\(N\)小的和的序列,然后用这个退出来的序列,再和第三个序列求值,然后同理,再得出来的值与第四个序列进行同样的操作
#include <bits/stdc++.h>
using namespace std;const int N = 2010;
int t , n , m , a[N] , b[N] , c[N] , tot;struct node
{int i , j;bool f;friend bool operator < ( node x , node y ){return a[ x.i ] + b[ x.j ] > a[ y.i ] + b[ y.j ];}}cur , temp ;inline int read()
{register int x = 0;register char ch = getchar();while( ch < '0' || ch > '9' ) ch = getchar();while( ch >= '0' && ch <= '9' ){x = ( x << 1 ) + ( x << 3) + ch - '0';ch = getchar();}return x;
}inline node make_node( int i , int j , bool f )
{cur.i = i , cur.j = j , cur.f = f;return cur;
}inline void work()
{sort( b + 1 , b + 1 + m );priority_queue< node > q;tot = 0;q.push( make_node( 1 , 1 , 0 ) );for( register int i = 1 ; i <= m ; i ++){temp = q.top() , q.pop();c[i] = a[ temp.i ] + b[ temp.j ];q.push( make_node( temp.i , temp.j + 1 , 1 ) );if( !temp.f ) q.push( make_node( temp.i + 1 , temp.j , 0 ) );}memcpy( a , c , sizeof( a ) );return ;
}int main()
{t = read();while(t--){n = read() , m = read();for( register int i = 1 ; i <= m ; i ++ ) a[i] = read();sort( a + 1 , a + 1 + m ); for( register int i = 2 ; i <= n ; i ++ ){for( register int j = 1 ; j <= m ; j ++ ) b[j] = read();work();}for( register int i = 1 ; i <= m ; i ++ ) printf( "%d " , a[i] );puts(""); }return 0;
}AcWing 147. 数据备份
Luogo P3620 数据备份
这是一道贪心+链表+堆的题
对于题面其实很好理解,就是有\(n\)个点,\(n-1\)条边,从中选\(k\)个但是每个节点只能选一次,求边权最小和
首先我们求\(k = 1\)时的情况,即所有边中最小的一个
再看\(k=2\)的情况,首先我们选择的所有中最小的一个即为\(i\)
呢么第二条选的不是\(i-1\),或\(i+1\)则无影响
若第二条边选的时\(i-1\)则\(i+1\)必选,也就是放弃\(i\)
因为如果选\(i-1\),不选\(i+1\)选\(j\)的情况下,此时对\(i\)时没有限制的则必有\(v[i]+v[k]\le v[i-1]+v[k]\)
如果\(k=3\),举下面这个例子
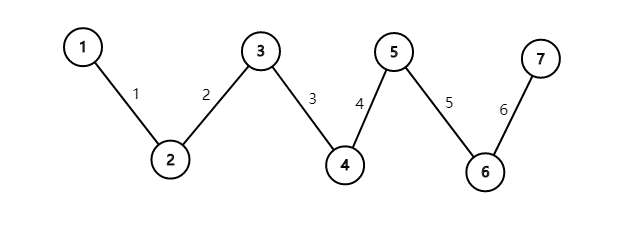
假设已经选择的\(2\)和\(4\)
此时我们要选择\(1\)则必选\(3\)和\(5\)
如果不选\(3,5\),选\(3,6\)的话
则必有\(1,4,6\)比\(1,3,6\)更优
根据数学归纳法我们可以推出,如果我们已经选择一串连续的点构成的边,假如我们因为要选择某一条边来破坏某一条边已经被选择的边,呢么这些连续的点构成的边一定要全部都破坏不然不可能更优
知道这个结论后在结合贪心的策略就可以解决这个问题
首先我们用一个堆来维护所以的边首先取出一个边\(i\),把\(v[i]\)累加的答案中,并且在堆中加入条权值为\(v[i-1]+v[i+1]-v[i]\),左端点为\(i-1\)的左端点,右端点为\(i+1\)的右端点的边,并且删除\(i-1\)和\(i+1\)这两条边
这样当我们选择的到\(i-1\)或\(i+1\)时都会选择到这条新加入边,对位边的信息我们用双向链表来维护即可
对于堆的删除操作可以使用懒惰标记法,这里给出一个\(set\)解决的方法,并会在下一小节给出set的基本用法
#include <bits/stdc++.h>
#define LL long long
#define PLI pair< LL , int >
using namespace std;const int N = 100010;
int n , k , l[N] , r[N];
LL d[N] , res;
set< PLI > s;inline int read()
{register int x = 0;register char ch = getchar();while( ch < '0' || ch > '9' ) ch = getchar();while( ch >= '0' && ch <= '9' ){x = ( x << 3 ) + ( x << 1 ) + ch - '0';ch = getchar();}return x;
}inline void delete_node( int p )
{r[ l[p] ] = r[p] , l[ r[p] ] = l[p];
}int main()
{n = read() , k = read();for( register int i = 1 ; i <= n ; i ++ ) d[i] = read();for( register int i = n ; i > 0 ; i -- ) d[i] -= d[ i - 1 ];d[1] = d[ n + 1 ] = 1e15;for( register int i = 1 ; i <= n ; i ++ ){l[i] = i - 1;r[i] = i + 1;s.insert( { d[i] , i } );}while( k -- ){set< PLI >::iterator it = s.begin();register LL v = it -> first;register int p = it -> second , left = l[p] , right = r[p];s.erase(it) , s.erase( { d[left] , left } ) , s.erase( { d[right] , right } );delete_node(left) , delete_node(right);res += v;d[p] = d[left] + d[right] - d[p];s.insert( { d[p] , p } ) ;}cout << res << endl;return 0;
}set
set< int > s;//构造函数,元素不可重复
multiset<int>s;//构造函数,元素可以重复
s.size();//返回s中有多少元素
s.empty();//返回s是否为空
s.clear();//清空s
s.begin();//返回指向s中第一个元素的迭代器
s.end();//返回指向s中最后一个元素下一个位置的迭代器
s.insert(x);//向s中插入一个元素x
s.find(x);//返回s中指向x的迭代器,如果s中没有x则返回s.end()
s.erase(x);//删除x
s.count(x)//返回s中x元素的个数(这个只适用于multiset) Huffman 树
考虑这样一个问题:构造一颗包含\(n\)个节点的\(k\)叉树,其中第\(i\)个叶子节点的权值为\(w_i\),要求最小化\(\sum w_i \times l_i\)其中\(l_i\)表示第\(i\)个叶子节点到根节点的距离
该问题被称为Huffman树(哈夫曼树)
为了最小化\(\sum w_i \times l_i\),应该让权值打的叶子节点的深度尽量的小。当\(k=2\)时,我们很容易想到用下面这个贪心思路求\(Huffman\)树
- 建立一个小根堆,插入这\(n\)个叶子节点的权值
- 从队列中取出两个最小的权值\(w_1\)和\(w_2\),令\(ans += w_1 + w_2\)
- 建立一个权值为\(w_1 + w_2\)的树节点\(p\),并把\(p\)成为\(w_1\)和\(w_2\)的父亲节点
- 在堆中插入\(p\)节点
- 重复\(2 \cdots 4\),直到堆的大小为\(1\)
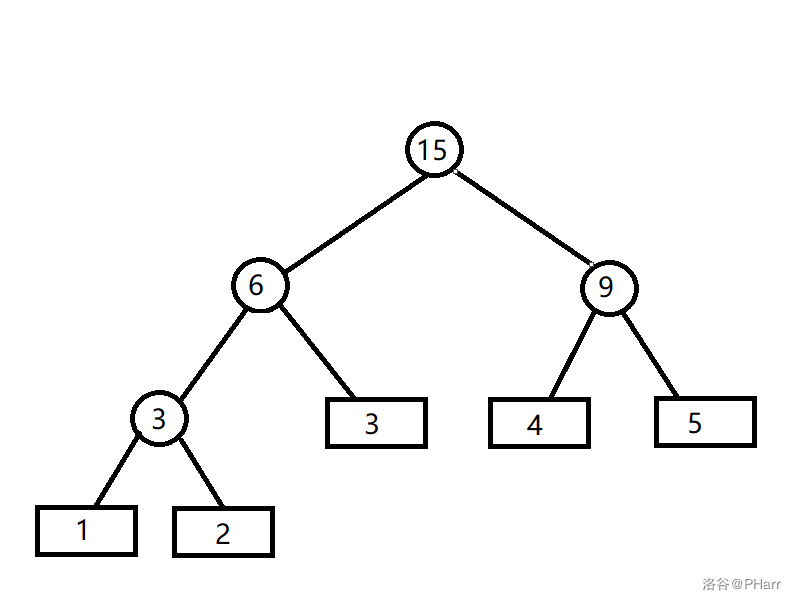
对于\(k>2\)的\(Huffman\)树,正常的想法就是在上述算法上每次取出\(k\)的节点
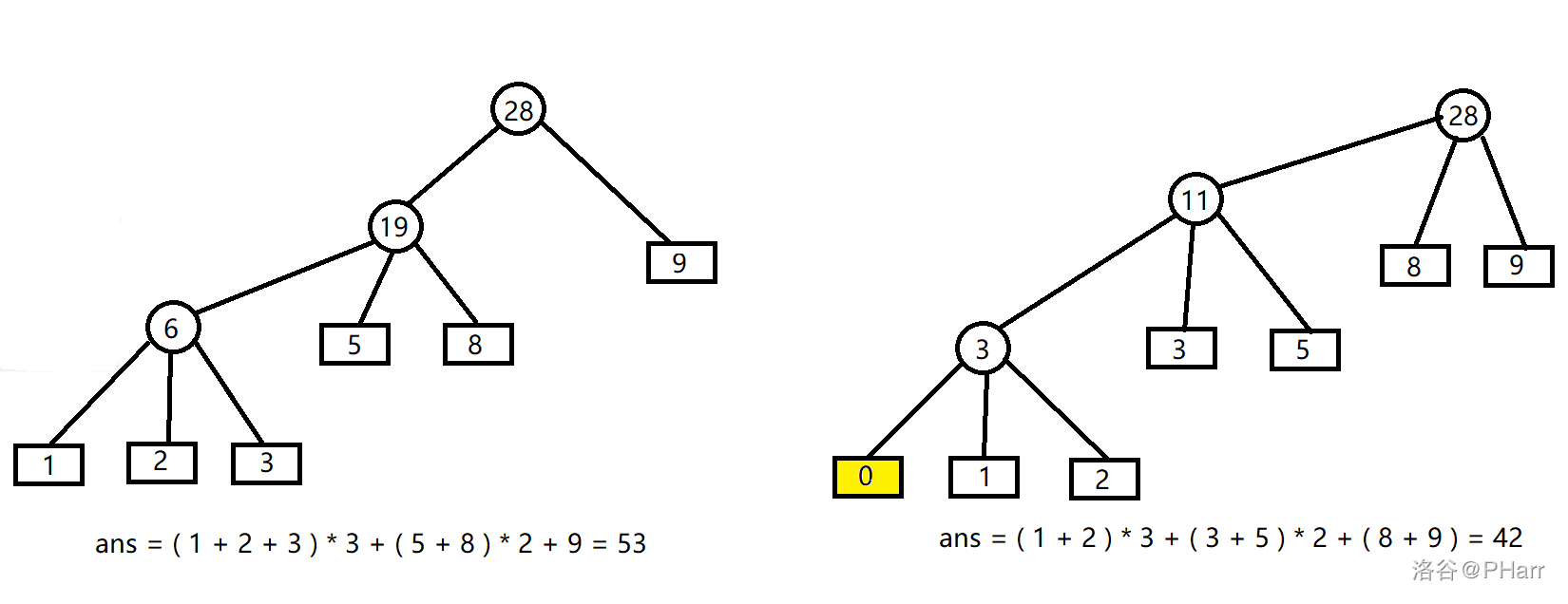
但加入最后一次取不出\(k\)个时,也就是第一层未满,此时从下方任意取出一个子树接在根节点的下面都会更优
所以我们要进行一些操作
我们插入一些额外的权值为\(0\)的叶子节点,满足\((n-1)mod(k-1) = 0\)
这是在根据上述思路做即可,因为补\(0\)后只有最下面的一次是不满的
AcWing 148. 合并果子
\(2\)叉\(Huffman\)树模板题,直接做即可
#include <bits/stdc++.h>
using namespace std;int n , ans , a , b;
priority_queue< int , vector<int> , greater<int> > q; inline int read()
{register int x = 0;register char ch = getchar();while( ch < '0' || ch > '9' ) ch = getchar();while( ch >= '0' && ch <= '9' ){x = ( x << 1 ) + ( x << 3 ) + ch - '0';ch = getchar();}return x;
} int main()
{n = read();for( register int i = 1 ; i <= n ; i ++ ) q.push( read() );while( q.size() > 1 ){a = q.top() , q.pop() , b = q.top() , q.pop();ans += a + b;q.push( a + b );}cout << ans << endl;return 0;
}AcWing 149. 荷马史诗
这道题目背景比多,有考阅读的成分
简化版的提议就是求\(Huffman\)树,并且求出\(Huffman\)树的深度
所以只需稍作更改即可
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
typedef pair< LL, int> PLI;int n , m ;
LL res;
priority_queue< PLI , vector<PLI> , greater<PLI> > heap;inline LL read()
{register LL x = 0 , f = 1;register char ch = getchar();while( ch < '0' || ch > '9' ){if( ch == '-' ) f = -1;ch = getchar();}while( ch >= '0' && ch <= '9' ){x = ( x << 3 ) + ( x << 1 ) + ch - '0';ch = getchar();}return x * f;
}int main()
{n = read() , m = read();for( register int i = 1 ; i <= n ; i ++ ) heap.push( { read() , 0 } );while( ( n - 1 ) % ( m - 1 ) ) heap.push( { 0ll , 0 } ) , n ++;while( heap.size() > 1 ){register LL sum = 0;register int depth = 0;for( register int i = 0 ; i < m ; i ++ ) sum += heap.top().first , depth = max( depth , heap.top().second ) , heap.pop();res += sum;heap.push( { sum , depth + 1 } );}cout << res << '\n' << heap.top().second << '\n';return 0;
}转载于:https://www.cnblogs.com/Mark-X/p/11257423.html
0x10基本数据结构相关推荐
- 【读书笔记】《算法竞赛进阶指南》读书笔记——0x10基本数据结构
to do(perhaps never) CH1401 后缀数组 所有课后题 栈 例题:HDU4699 Editor 维护一个整数序列的编辑器,支持以下五种操作: I x:在当前光标位置处插入一个整数 ...
- 0x10 基本数据结构
0x11 栈 复杂度:这是一种数据结构,依情况而定. 应用:一般配合其它算法一起用,或用作单调栈. 注意:若用STL实现,有些操作会导致Segmentation Fault,如空栈出栈. 0x12 队 ...
- [算法进阶0x10]基本数据结构C作业总结
t1-Supermarket 超市利润 题目大意 给定n个商品,每个商品有利润pi和过期时间di.每天只能卖一个商品,过期商品不能卖.求如何安排每天卖的商品可以使收益最大. 分析 一开始打了一个复杂度 ...
- 电子学会 青少年编程等级考试(C语言)六级(数据结构)试题
6级-2021-12-01-电话号码 3791:电话号码 OpenJudge - 3791:电话号码 4089:电话号码 OpenJudge - 4089:电话号码 6级-2021-12-02-字符串 ...
- 算法竞赛知识合集 目录(博客中转站)
目录 0x00. 基本算法 0x01. 基本算法 - 位运算 0x02. 基本算法 - 递推与递归 0x03. 基本算法 - 前缀和与差分 0x04.基本算法 - 二分和三分 0x05.基本算法 - ...
- 李煜东算法进阶指南打卡题解
算法竞赛进阶指南 一.0x00 基本算法 1)位运算 2)递推与递归 3)前缀和与差分 4)二分 5)排序 6)倍增 7)贪心 8)习题 二.0x10 基本数据结构 1)栈 2)队列 3)链表与邻接表 ...
- 以太坊数据结构MPT
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载. MPT(Merkle Patricia Tries)是以太坊存储数据的核心数据结构,它是由Merkle Tree和Pat ...
- 011 数据结构逆向—二叉树
文章目录 前言 背包数据嵌套结构 背包二叉树 二叉树分析 背包数据结构分析 总结 前言 学习完了链表的数据结构,我们再通过幻想神域了解一下二叉树在游戏中的存储形式. 这一次要逆向的数据是背包中的所有物 ...
- 009 数据结构逆向—数组(困难版)
文章目录 前言 数组逆向 通过人物血量查找人物属性 调call取对象 call内追局部变量 逆向加密数组下标 分析人物属性 总结 前言 通过之前的分析,我们已经对数组结构有了一个简单的了解,这次就用幻 ...
最新文章
- 重磅推荐!机器学习|深度学习|自然语言处理 书籍/课程/资料/资源大分享!
- AGI:走向通用人工智能的【生命学哲学科学】第二篇——思维、生命科学、客观世界
- MySQL查询语种关键字_SQL——SQL语言全部关键字详解
- 【渝粤教育】电大中专电商运营实操12作业 题库
- node.js request get 请求怎么拿到返回的数据_从零开始用nodejs写一个简单的静态服务器
- weiphp 简介--笔记
- 社会网络分析-python_体育社 - 运动让生活更有乐趣 - 俱乐部活动在线管理系统...
- web平台安全测试方案
- c语言中的字符数组和字符串之间的关系
- 新型 EGFR 小分子抑制剂(克服 L858R/T790M 突变)
- python读取桌面上的文件夹怎么加密_python给文件夹加密 怎么样给python文件加密...
- jzoj1794 保镖排队 (树形dp)
- 扫描仪显示计算机繁忙或故障,为什么我的兄弟打印机每次扫描图像文件总是显示连接计算机,但是电脑就没有弹出那个框让我选择?请求高手...
- erp系统的开发工具
- pandas绘图线条颜色大全
- 大恒相机图像采集 linux+python
- AWS如何安全顺利关闭所有的免费服务
- nbu6.5 linux安装,Veritas.Netbackup 6.0 for Linux RedHat AS5.3安装问题
- 请问在 1 到 2020 中,有多少个数既是 4 的整数倍,又是 6 的整数倍。
- 一看就会的Nginx学习教程(千万别告诉其他人),java视频百度云盘