大数据交互平台Hue的优势
本文系统地讲解了Hue作为大数据分析交互平台的优势!欢迎批评指正!
Hue Web应用的架构
Hue 是一个Web应用,用来简化用户和Hadoop集群的交互。Hue技术架构,如下图所示,从总体上来讲,Hue应用采用的是B/S架构,该web应用的后台采用python编程语言别写的。大体上可以分为三层,分别是前端view层、Web服务层和Backend服务层。Web服务层和Backend服务层之间使用RPC的方式调用。
![]()
Hue整合大数据技术栈架构
由于大数据框架很多,为了解决某个问题,一般来说会用到多个框架,但是每个框架又都有自己的web UI监控界面,对应着不同的端口号。比如HDFS(50070)、YARN(8088)、MapReduce(19888)等。这个时候有一个统一的web UI界面去管理各个大数据常用框架是非常方便的。这就使得对大数据的开发、监控和运维更加的方便。

从上图可以看出,Hue几乎可以支持所有大数据框架,包含有HDFS文件系统对的页面(调用HDFS API,进行增删改查的操作),有HIVE UI界面(使用HiveServer2,JDBC方式连接,可以在页面上编写HQL语句,进行数据分析查询),YARN监控及Oozie工作流任务调度页面等等。Hue通过把这些大数据技术栈整合在一起,通过统一的Web UI来访问和管理,极大地提高了大数据用户和管理员的工作效率。这里总结一下Hue支持哪些功能:
- 默认基于轻量级sqlite数据库管理会话数据,用户认证和授权,可以自定义为MySQL、Postgresql,以及Oracle
- 基于文件浏览器(File Browser)访问HDFS
- 基于Hive编辑器来开发和运行Hive查询
- 支持基于Solr进行搜索的应用,并提供可视化的数据视图,以及仪表板(Dashboard)
- 支持基于Impala的应用进行交互式查询
- 支持Spark编辑器和仪表板(Dashboard)
- 支持Pig编辑器,并能够提交脚本任务
- 支持Oozie编辑器,可以通过仪表板提交和监控Workflow、Coordinator和Bundle
- 支持HBase浏览器,能够可视化数据、查询数据、修改HBase表
- 支持Metastore浏览器,可以访问Hive的元数据,以及HCatalog
- 支持Job浏览器,能够访问MapReduce Job(MR1/MR2-YARN)
- 支持Job设计器,能够创建MapReduce/Streaming/Java Job
- 支持Sqoop 2编辑器和仪表板(Dashboard)
- 支持ZooKeeper浏览器和编辑器
- 支持MySql、PostGresql、Sqlite和Oracle数据库查询编辑器
- 使用sentry基于角色的授权以及多租户的管理.(Hue 2.x or 3.x)
Hue操作数据
- 使用Hue可以以图形界面的形式创建solr集合,导入数据到Solr中,并建立数据查找索引。
- 提供了人性化的UI页面把数据从文件系统(比如Linux文件系统、HDFS)导入Hive中,导入的时候可以把数据转换成相应的Hive表,导入完成之后就可以直接使用Hive SQL查询刚刚导入的数据了。[^import-hive]
- 使用Hue以图形界面的形式操作HDFS,包括导入、移动、重命名、删除、复制、修改、下载、排序、查看其中的数据等等操作。
- Hue集成了Sqoop组件,这样就可以通过Hue把数据从其他文件系统批量导入到Hadoop中,或者从Hadoop中导出。[^http://blog.cloudera.com/blog/2013/11/sqooping-data-with-hue/]
- 可以通过图形界面的方式操作HBase,可以导入数据到HBase中,可以通过UI界面进行相关的增加、删除和查询操作。[^http://blog.cloudera.com/blog/2013/09/how-to-manage-hbase-data-via-hue/]
Hue数据查询分析
- 通过Hue使用Hive进行数据分析
Hue提供了非常人性化的Hive SQL编辑界面,编辑好SQL语句之后就可以直接查询数据仓库中的数据,还可以保存SQL语句、查看和删除历史SQL语句。对于所查询出来的数据,可以下载以及以多种图表的形式展示它们。通过Hue,用户还可以通过自定义函数然后在Hue中通过SQL引用执行。
![]()
通过Hue使用Impala进行数据分析
和Hive一样,Hue提供了类似的图形界面用来使用Impala进行数据查询分析。形式和Hive的类似。如下图所示:

使用Hue使用Pig进行数据分析
类似于Hive和Impala在Hue中编辑器,Pig的功能和表达式可以直接在Hue中进行编辑和执行等操作。用户可以自定义函数和参数,编辑器能够自动补全Pig关键字、别名和HDFS路径,还支持语法高亮,编写好脚本之后点击一下就可以提交执行。用户可以查看到执行的进度、执行的结果和日志。
Hue数据可视化
Hue使用Web图形界面的可视化的形式展示所查询出来的数据,展示的形式有表格、柱状图、折线图、饼状图、地图等等。这些可视化功能的使用非常简单。比如,使用Hive SQL查询出相关的数据出来之后,我想以柱状图的形式展示它们,我只需要勾选横坐标和纵坐标的字段就可以显示出我想要的柱状图。
Hue提供了可视化的HDFS文件系统,使得对HDFS中的数据的操作完全能够通过UI界面完成,包括查看文件中的内容。
类似地,Hue提供了可视化的UI界面操作HBase中的数据。包含了数据展示,各个版本的数据的查看和其他编辑操作的UI界面,提供了展示数据的排序方式等等。
下图表示,编辑HBase数据的可视化界面
![]()
Hue提供了用户自定义仪表盘(Dashboard)展示数据的功能。数据的来源是Solr这个搜索引擎。通过拖拽的方式设置仪表盘(也就是数据展示的方式),有文本框、时间表、饼状图、线、地图、HTML等组件。图表支持实时动态更新。设置仪表盘的全部操作都是通过图形界面完成的,对于不同的展示方式,用户可以选择相应的字段,整个过程非常简单方便。保存好刚刚配置好的仪表盘之后,我们可以选择分享给相应权限的用户,拥有不同的权限的用户将看到不同的内容。[^http://gethue.com/hadoop-search-dynamic-search-dashboards-with-solr/]
上图表示表盘设置中的以地图的方式展示国家码。
上图表示:多种展示方式的表盘。
Hue对任务调度的可视化
Hue以可视化的方式向用户展示任务的执行情况,具体包括任务的执行进度、任务的执行状态(正在运行、执行成功、执行失败、被killed),任务的执行时间,还能够显示该任务的标准输出信息、错误日志、系统日志等等信息。还可以查看该任务的元数据、向用户展示了正在运行或者已经结束的任务的详细的执行情况。除此之外,Hue还提供了关键字查找和按照任务执行状态分类查找的功能。
![]()
上图表示:任务执行情况和相关信息显示
![]()
上图表示:任务的日志显示。
Hue权限控制
Hue在HueServer2中使用了Sentry进行细粒度的、基于角色的权限控制。这里的细粒度是指,Sentry不仅仅可以给某一个用户组或者某一个角色授予权限,还可以为某一个数据库或者一个数据库表授予权限,甚至还可以为某一个角色授予只能执行某一类型的SQL查询的权限。Sentry不仅仅有用户组的概念,还引入了角色(role)的概念,使得企业能够轻松灵活的管理大量用户和数据对象的权限,即使这些用户和数据对象在频繁变化。除此之外,Sentry还是“统一授权”的。具体来讲,就是访问控制规则一旦定义好之后,这些规则就统一作用于多个框架(比如Hive、Impala、Pig)。举一个例子:我们为某一个角色或者用户组授权只能进行Hive查询,我们可以让这个权限不仅仅作用于Hive,还可以是Impala、MapReduce、Pig和HCatalog。
Sentry的优势还体现在它本身对Hadoop生态组件的集成。如下图所示,我们可以使用Sentry为Hadoop中的多个框架进行权限控制。
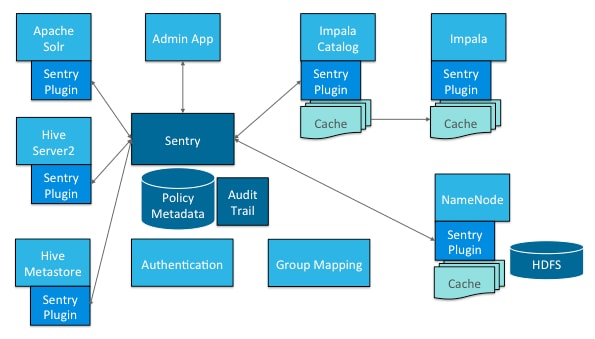
管理员使用浏览器就能修改相关权限。
Airflow工作流
工作流就是一系列相互衔接、自动进行的业务活动或任务。一个工作流包括一组任务(或活动)及它们的相互顺序关系,还包括流程及任务(或活动)的启动和终止条件,以及对每个任务(或活动)的描述。
Airflow目前正在Apache孵化器中[^airflow-incubator],但是已经被包括雅虎在内的很多公司使用[^github-airflow]。
这个平台拥有和 Hive、Presto、MySQL、HDFS、Postgres和S3交互的能力,并且提供了钩子使得系统拥有很好的扩展性。
Airflow的优势
- 动态的:Airflow通过代码(python)来配置管道(pipeline)而不是通过xml配置文件,这使得用户可以编写代码来实例化动态管道。使用代码定义任务(DAG)在执行一个特定的可重复的任务时非常管用。用代码来定义工作流是这个系统最强大之处。这在没有人工干预的情况下自动接入新的数据源的时候非常有用。
- 可伸缩的:可以很容易地编辑、运行和扩展相关的库文件,
- 优雅的:Airflow的管道(pipeline)是精炼直接的,Airflow的核心使用了参数化的脚本,还使用了强大的Jinja模板引擎。
- 可拓展的:Airflow具有模块化结构,使用消息队列来整合任意数量的worker。[^apache-airflow]
- 任务隔离:在一个分布式环境中,宕机是时有发生的。Airflow通过自动重启任务来适应这一变化。到目前为止一切安好。当我们有一系列你想去重置状态的任务时,你就会发现这个功能简直是救世主。为了解决这个问题,我们的策略是建立子DAG。这个子DAG任务将自动重试自己的那一部分,因此,如果你以子DAG设置任务为永不重试,那么凭借子DAG操作你就可以得到整个DAG成败的结果。如果这个重置是DAG的第一个任务设置子DAG的策略就会非常有效,对于有一个相对复杂的依赖关系结构设置子DAG是非常棒的做法。注意到子DAG操作任务不会正确地标记失败任务,除非你从GitHub用了最新版本的Airflow。解决这个问题的另外一个策略是使用重试柄,这样你的重试柄就可以将任务隔离,每次执行某个特定的任务。
- 人性化的:Airflow提供了非常人性化的Web UI,用户可以使用浏览器编辑、查看等操作工作流,提供了人性化的任务监控UI。
![]()
上图表示:Airflow的web UI.
Airflow其他有趣的特点
服务级别协议:用户能够通过设置某一个任务或者DAG(在一定时间内)必须要成功执行,如果一个或多个任务在规定时间内没有成功完成,就会有邮件提醒用户。
XCom:XCom使得任务(task)之间能够交换信息,从而实现更微妙的控制和状态共享。
变量:这可以让用户在Airflow中自定义任意key-value形式的变量。用户可以通过web UI或者代码对变量进行增删改查操作。把这些变量当作系统的配置项是非常有用的。[^http://bytepawn.com/airflow.html]
使用Airflow
- 下载安装Airflow是一件很简单的事情,使用pip就可以了。
- 编写DAG(有向无环图),使用python语言编写。Airflow提供了和Hive、Presto、MySQL、HDFS、Postgres和S3等交互的接口。
- 导入DAG到Airflow中,开始执行。
- 使用Airflow提供的web UI查看BAG执行情况,运行结束之后还可以通过Web UI查看各个任务的执行状况,比如执行时间,便于进一步优化。[^https://www.pandastrike.com/posts/20150914-airflow]
^import-hive
^http://blog.cloudera.com/blog/2013/11/sqooping-data-with-hue/
^http://blog.cloudera.com/blog/2013/09/how-to-manage-hbase-data-via-hue/
^http://bytepawn.com/airflow.html
^https://www.pandastrike.com/posts/20150914-airflow
^http://gethue.com/hadoop-search-dynamic-search-dashboards-with-solr/
大数据交互平台Hue的优势相关推荐
- 大数据可视化平台有什么优势
大数据可视化通过利用视觉效果,通过地理空间.时间序列.逻辑关系等不同维度,把不同类型的数据呈现出来,以便理解数据背后蕴藏的价值.规律.趋势和关系.目前,在公安.政府.零售.生产.交通.地产.汽车等领域 ...
- 【阿里内部应用】基于Blink为新商业调控打造实时大数据交互查询服务
基于Blink为新商业调控打造实时大数据交互查询服务 案例与解决方案汇总页: 阿里云实时计算产品案例&解决方案汇总 从IT到DT.从电商到新商业,阿里巴巴的每个细胞都存在大数据的DNA,如何挖 ...
- python做大数据的框架_Python+大数据计算平台,PyODPS架构手把手教你搭建
原文链接:http://click.aliyun.com/m/13965/ 在2016年10月的云栖社区在线培训上,来自阿里云大数据事业部的秦续业分享了<双剑合壁--Python和大数据计算平台 ...
- 【2017年第2期】应用驱动的大数据融合平台建设
孟祥飞, 冯景华, 赵洋, 夏梓峻 国家超级计算天津中心,天津 300457 摘要:论述了大数据在信息社会发展中的核心地位和对信息技术创新的全方位驱动:重点阐述了应用驱动的大数据和超级计算.云计算融合 ...
- 集成开发环境-大数据开发平台的门户
什么是集成开发环境 这一篇,来谈一下大数据开发平台的门面,集成开发环境.什么是集成开发环境?顾名思义,就是IDE,哪个码农不知道IDE的,有胆你站出来! 不过IDE这个词也太普通了,在那些大厂玩大数据 ...
- 海关外贸企业大数据风控平台
背景 金融行业 金融行业是经营风险的行业,风险控制能力是金融机构的核心竞争力.通常而言,金融机构一般是通过给客户的信用状况评分来计量贷款违约的可能性,并通过客户的风险水平进行利率定价. 传统信用评测方 ...
- 大数据开发平台-数据同步服务
什么是数据同步服务?顾名思义,就是在不同的系统之间同步数据.根据具体业务目的和应用场景的不同,各种数据同步服务框架的功能侧重点往往不尽相同,因而大家也会用各种大同小异的名称来称呼这类服务,比如数据传输 ...
- 从 Airflow 到 Apache DolphinScheduler,有赞大数据开发平台的调度系统演进
点击上方 蓝字关注我们 作者 | 宋哲琦 ✎ 编 者 按 在不久前的 Apache DolphinScheduler Meetup 2021 上,有赞大数据开发平台负责人 宋哲琦 带来了平台调度系统 ...
- 如何用开源组件“攒”出一个大数据建模平台?
写在前面:博主是一只经过实战开发历练后投身培训事业的"小山猪",昵称取自动画片<狮子王>中的"彭彭",总是以乐观.积极的心态对待周边的事物.本人的技 ...
最新文章
- 2018年08月19日发烧诸事记
- 一秒钟世界上会发生多少事_1秒钟世界上会发生多少事?答案超乎你的想象……...
- 三维重建 几何方法 深度学习_基于深度学习的三维重建算法:MVSNet、RMVSNet、PointMVSNet、Cascade系列...
- 全面介绍Windows内存管理机制及C++内存分配实例(六):堆栈
- Groovy语言之SpringBoot整合JDBC案例
- C语言的变量怎样重启后不变,求解释,怎么能让程序里的变量在关闭后依然保存呢?...
- 实物贴图风格拟物图标素材,高逼格即显
- js 设置password placeholder样式_150+ 个优质的 Node.js 包和资源
- Win10远程桌面 出现 身份验证错误,要求的函数不受支持,这可能是由于CredSSP加密Oracle修正 解决方法
- C# 数据库访问类源代码
- 埃夫特机器人离线编程软件_工业机器人离线编程与虚拟仿真软件
- 很多人问中国网络安全行业怎么样?这篇文看完让你彻底了解中国网络安全行业的全景
- 详解:Java的重载方法与示例
- 【Android】EasyClient与EasyCamera的移植学习
- ISO/IEC JTC 1/SC 42人工智能分技术委员会第一次全会在京召开
- 史上最全Java学习路线
- 基于知识图谱的知识泛化让AI学会“举一反三”
- P4231 三步必杀
- 百家号不推荐的文章如何解决呢?
- 论文笔记(八):360 VR Based Robot Teleoperation Interface for Virtual Tour