python做大数据的框架_Python+大数据计算平台,PyODPS架构手把手教你搭建
原文链接:http://click.aliyun.com/m/13965/
在2016年10月的云栖社区在线培训上,来自阿里云大数据事业部的秦续业分享了《双剑合壁——Python和大数据计算平台的结合实战》。他主要介绍了数据分析和机器学习的方法、DataFrame整体架构以及基础API、前端、后端、机器学习的具体实现方法。
本次视频直播的整理文章整理完毕,如下内容。
数据分析和机器学习
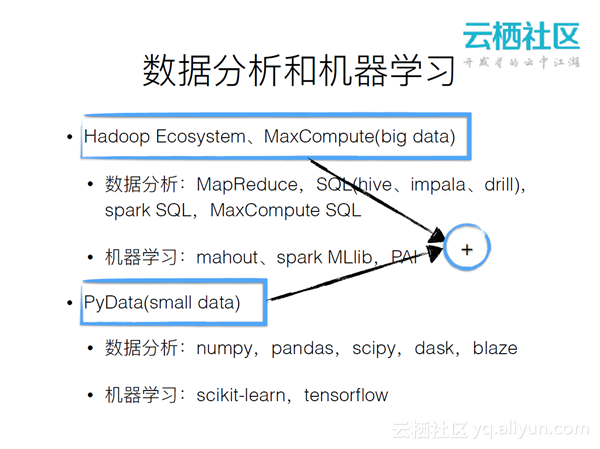
大数据基本都是建立在Hadoop系统的生态上的,其实一个Java的环境。很多人喜欢用Python和R来进行数据分析,但是这往往对应一些小数据的问题,或者本地数据处理的问题。如何将二者进行结合使其具有更大的价值?Hadoop现有的生态系统和现有的Python环境如上图所示。
MaxCompute
MaxCompute是面向离线计算的大数据平台,提供TB/PB级的数据处理,多租户、开箱即用、隔离机制确保安全。MaxCompute上主要分析的工具就是SQL,SQL非常简单、容易上手,属于描述型。Tunnel提供数据上传下载通道,不需要经过SQL引擎的调度。
Pandas
Pandas是基于numpy的数据分析的工具,里面最重要的结构是DataFrame,提供一系列绘图的API,背后是matplotlib的操作,非常容易和Python第三方库交互。
PyODPS架构
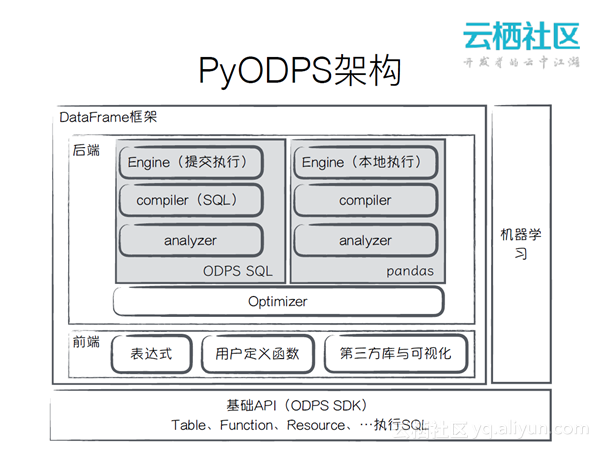
PyODPS即利用Python进行大数据分析,其架构如上图所示。底层是基础API,可以利用其操作MaxCompute上的表、函数或者资源。再上面是DataFrame框架,DataFrame包括两部分,一部分是前端,定义了一套表达式的操作,用户写的代码会转化成表达式树,这与普通的语言是一样的。用户可以自定义函数,也可以进行可视化,与第三方库进行交互。后端最下面是Optimizer,其作用是对表达式树进行优化。ODPS和pandas都是通过compiler和analyzer提交到Engine来执行。
背景
为什么要做DataFrame框架?
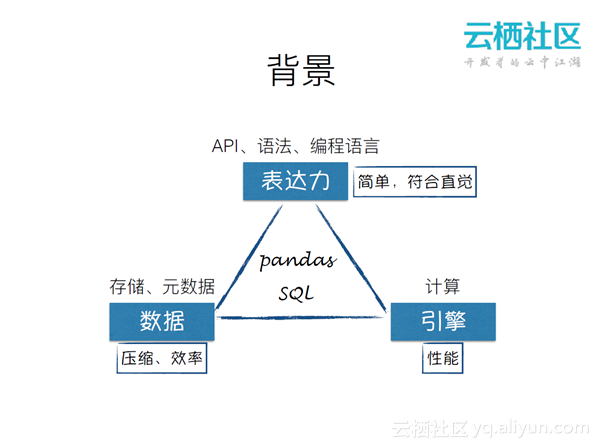
对于任何一个大数据分析工具,都会面临三个维度上的问题:表达力,API、语法、编程语言是否简单、符合直觉?数据,存储、元数据是否能压缩、有效?引擎,计算的性能是否足够?所以就会面临pandas和SQL两个选择。
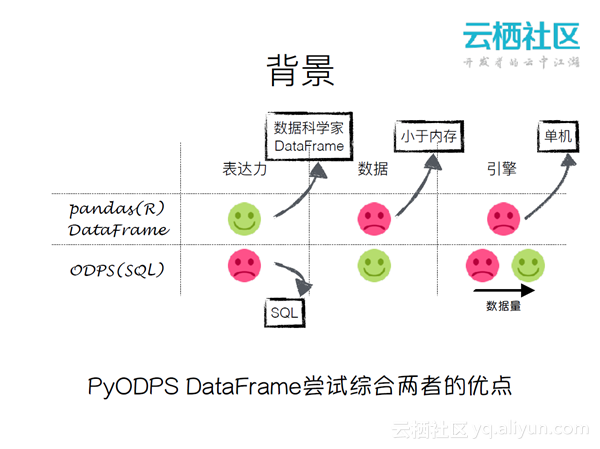
如上图所示,pandas的表达力非常好,但是其数据只能放在内存中,引擎是单机的,受限于本机的性能。SQL的表达力有限,但是可以用于大量的数据,数据量小的时候没有引擎的优势,数据量大的时候引擎会变得很有优势。ODPS的目标是综合这两者的优点。
PyODPS DataFrame
PyODPS DataFrame是使用Python语言写的,可以使用Python的变量、条件判断、循环。可以使用pandas类似的语法,定义了自己的一套前端,有了更好的表达力。后端可以根据数据来源来决定具体执行的引擎,是visitor的设计模式,可扩展。整个执行是延迟执行,除非用户调用立即执行的方法,否则是不会直接执行的。

从上图中可以看出,语法非常类似于pandas。
表达式和抽象语法树
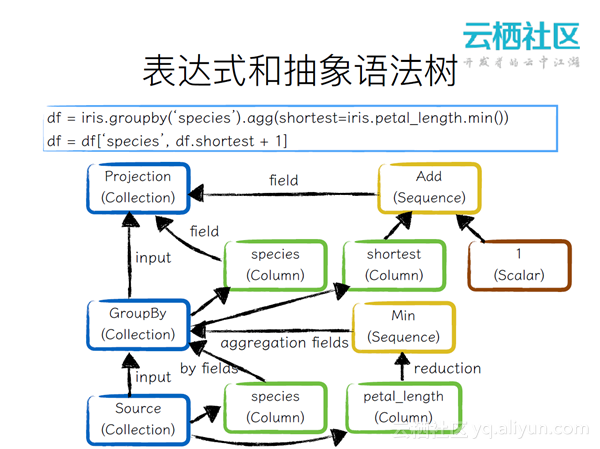
从上图可以看出,用户从一个原始的Collection来进行GroupBy操作,再进行列选择的操作,最下面是Source的Collection。取了两个字段species,这两个字段是做By操作的,pental_length是进行聚合的操作取聚合值。Species字段是直接取出来,shortest字段是进行加一的操作。
Optimizer(操作合并)
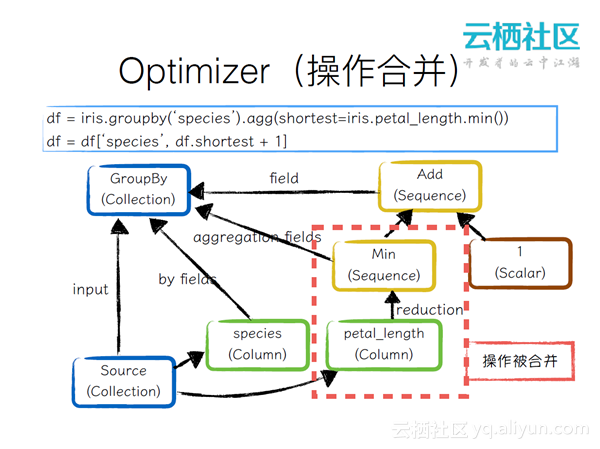
后端首先会使用Optimizer对表达式树进行优化,先做GroupBy,然后在上面做列选择,通过操作合并可以去除petal_length做聚合操作,再加一,最终形成了GroupBy的Collection。
Optimizer(列剪枝)
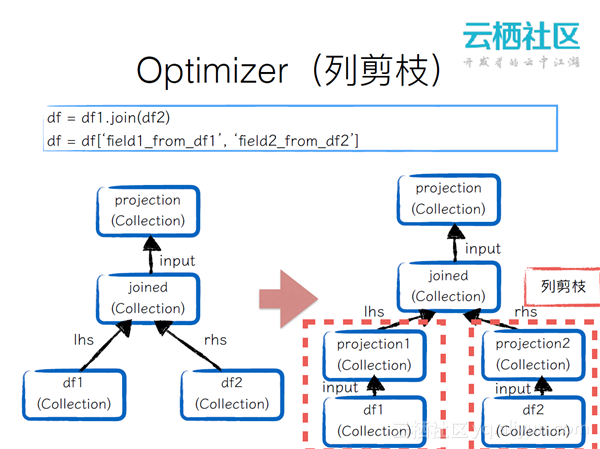
用户join了两个data frame,再取来自data frame 的两个列的时候,如果提交到一个大数据的环境,这样一个过程是非常低下的,因为不是每个列都用到了。所以要对joined下的列进行剪枝操作。比如,data frame1我们只用到了其中的一个字段,我们只需要将字段截取出来做一个projection来形成新的Collection,data frame2也类似。这样,对这两部分进行校验操作的时候就能极大的减少数据的输出量。
Optimizer(谓词下推)
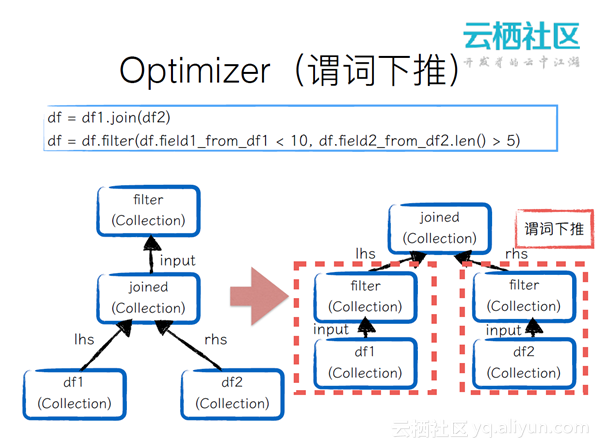
如果对两个data frame进行joined然后再分别进行过滤的话,这个过滤操作是应该下推到下面来执行的,这样就能减少joined 的输入的量。
可视化
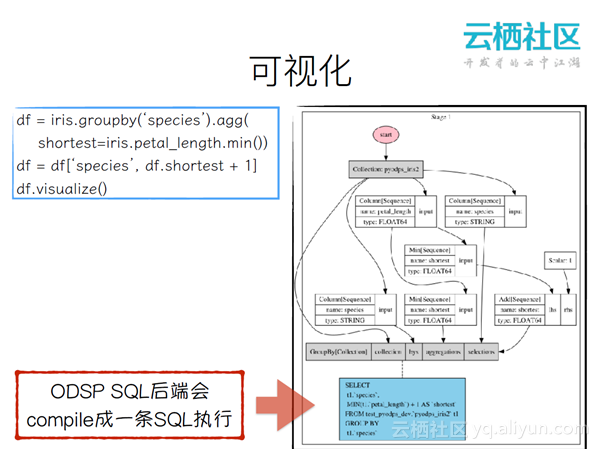
提供了visualize()来方便用户进行可视化。在右边的例子中可以看到,ODSP SQL后端会compile成一条SQL执行。
后端
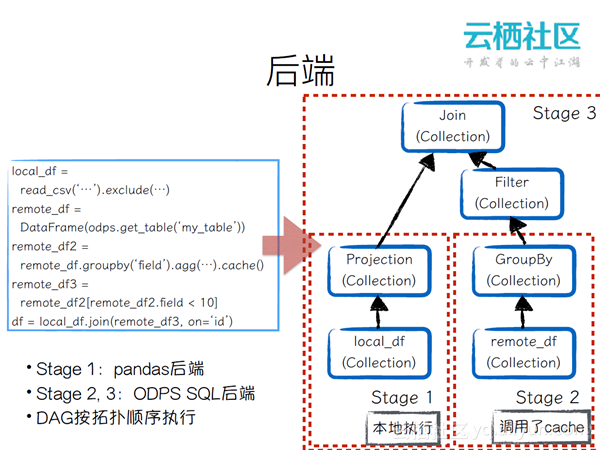
从上图中可以看出,计算后端是非常灵活的。用户甚至可以joined一个pandas的data frame和maxcompute上一个表的数据。
Analyzer
Analyzer的作用是针对具体的后端,将一些操作进行转化。比如:
有些操作比如value_counts,pandas本身支持,因此对于pandas后端,无需处理;对于ODPS SQL后端,没有一个直接的操作来执行,所以在analyzer执行的时候,会被改写成groupby + sort的操作;
还有一些算子,在compile到ODPS SQL时,没有内建函数能完成,会被改写成自定义函数。
ODPS SQL后端
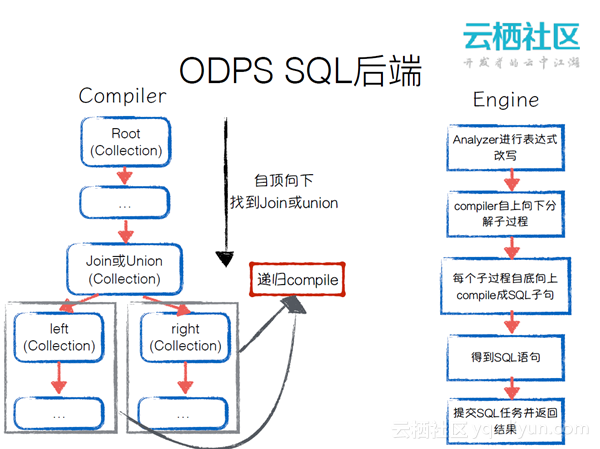
ODPS SQL后端怎么进行SQL编译再执行的操作?编译器可以从上到下遍历表达式树,找到Join或者Union。对于子过程,进行递归compile。再到Engine来具体执行时,会使用Analyzer对表达式树进行改写,compile自上而下的子过程,自底向上compile成SQL子句,最终得到完整的SQL语句,提交SQL并返回任务。
pandas后端
首先访问这个表达式树,然后对每个表达式树节点对应到pandas操作,整个表达式树遍历完之后就会形成DAG。Engine执行按DAG拓扑顺序执行,不断地把它应用到pandas操作,最终得到一个结果。对于大数据环境来说,pandas后端的作用是做本地DEBUG;当数据量很小时,我们可以使用pandas进行计算。
难点+坑
后端编译出错容易丢失上下文,多次optimize和analyze,导致难以查出是之前哪处visit node导致。解决:保证每个模块独立性、测试完备;
bytecode兼容问题,maxcompute只支持Python2.7的自定义函数的执行;
SQL的执行顺序。
ML机器学习
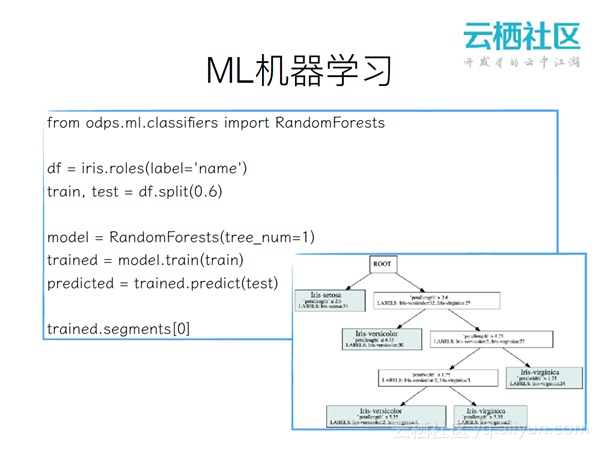
机器学习是输入输出一个data frame。比如,有一个iris的data frame,先用name字段来做一个分类字段,调用split方法将其分成60%的训练数据和40%的测试数据。然后初始化一个RandomForests,其里面有一棵决策树,调用train方法训练训练数据,调用predict方法形成一个预测数据,调用segments[0]就可以看到可视化结果。
未来计划
分布式numpy,DataFrame基于分布式numpy的后端;
内存计算,提升交互式体验;
Tensorflow。
python做大数据的框架_Python+大数据计算平台,PyODPS架构手把手教你搭建相关推荐
- python大数据论坛_干货 | Python+大数据计算平台,PyODPS架构手把手教你搭建
数据分析和机器学习 大数据基本都是建立在Hadoop系统的生态上的,其实一个Java的环境.很多人喜欢用Python和R来进行数据分析,但是这往往对应一些小数据的问题,或者本地数据处理的问题.如何将二 ...
- 大数据江湖之即席查询与分析(下篇)--手把手教你搭建即席查询与分析Demo
上篇小弟分享了几个"即席查询与分析"的典型案例,引起了不少共鸣,好多小伙伴迫不及待地追问我们:说好的"手把手教你搭建即席查询与分析Demo"啥时候能出?说到就得 ...
- python做疫情数据分析的框架_Python制作新冠疫情世界地图
目录 pyecharts模块 简介 Echarts 是一个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可.而 Python 是一门富有表达力的语言,很适合用于数据处 ...
- 手把手教你搭建SSH框架(Eclipse版)
作者: C you again,从事软件开发 努力在IT搬砖路上的技术小白 公众号: [C you again],分享计算机类毕业设计源码.IT技术文章.游戏源码.网页模板.程序人生等等.公众号回复 ...
- python 做个创越火线挂_一日一技:用Python做个能挂墙上的大钟表
今天给大家分享 1 个非常实用的 python 技能--用 Python 做个能挂墙上的大钟表,先上成果视频: 本项目用到的库主要有 pygame . math . datetime 等,另外还用到一 ...
- python什么框架写游戏好_免root修改器框架,免root框架大全,游戏框架免root:《游戏框架》 用python做游戏用什么框架-南开游戏网...
<游戏框架> 用python做游戏用什么框架 2020-11-25 17:37:36 广告 游戏作为一种分类框架 一个好的网计作品就必然有一个号的网页,那么我们来分析一下,在网页设计过程中 ...
- 手把手教你搭建实时大数据引擎FLINK
手把手教你搭建实时大数据引擎FLINK 服务器规划 Standalone高可用HA模式 架构图 下载并上传tar包 具体安装步骤 yarm 集群环境搭建 服务器规划 服务器规划 服务名称 职能 zhe ...
- Python学习教程:手把手教你搭建自己的量化分析数据库
Python学习教程:手把手教你搭建自己的量化分析数据库 引言: 数据是金融量化分析的重要基础,包括股票历史交易数据.上市公司基本面数据.宏观和行业数据等.随着信息流量的日益膨胀,学会获取.查询和加工 ...
- 手把手教你搭建SSM框架(Eclipse版)
作者: C you again,从事软件开发 努力在IT搬砖路上的技术小白 公众号: [C you again],分享计算机类毕业设计源码.IT技术文章.游戏源码.网页模板.程序人生等等.公众号回复 ...
最新文章
- html 乱码_html小坑:网页变成乱码
- Apache Kafka之设计
- Git修改分支名称(local remote)
- cocos2dx中关于Action动作的相关API的详细介绍
- Tomcat 申请证书配置https
- Flink Weekly | 每周社区动态更新-12/24
- PC 先驱克拉克逝世 曾参与开发首款晶体管 PC
- 树模型(一):预备知识
- winpe 能否修复服务器系统盘,U盘启动盘winpe修复系统的技巧
- openwrite Test
- 稻城亚丁神州租车自驾游,一生一定要去一次的地方
- Hotkeycontrol录制宏
- 8个实用、强大、超厉害的软件推荐,快收藏吧!
- jdk的exe安装版和zip压缩版有什么区别
- 7.熟练掌握ES Java API基于upsert实现汽车最新价格的调整
- Vue项目原本原本http请求变成了https
- 卖座项目需要注意的点
- Android-MPChart:PieChart使用小记
- 【稳定性day0】稳定性治理的三种思想—亚马逊、Netflix与蚂蚁金服
- 金星(Venus)——预祝银河证券金星1号成功