【阿里内部应用】基于Blink为新商业调控打造实时大数据交互查询服务
基于Blink为新商业调控打造实时大数据交互查询服务
案例与解决方案汇总页:
阿里云实时计算产品案例&解决方案汇总
从IT到DT、从电商到新商业,阿里巴巴的每个细胞都存在大数据的DNA,如何挖掘大数据的价值成为抢占未来先机的金钥匙!传统的大数据开发主要基于离线计算平台MaxCompute(ODPS)进行天级别、小时级别的批量数据分析,但近些年随着618、99、双11、双12等大促活动的常态化,传统的离线数据分析已经无法满足大促当天的需求,以双11实时交易数据为例,试想如果我们只能看到前一小时或者前一天的成交数据,对于公司高层的决策制定、对于行业/运营/商家/商品的行动指导、对于算法的预测调控将大大折扣,可以说大数据实时化已经成为通向新商业体系必须拥有的诺亚船票。
从2017年8月开始,一群有激情有干劲的小伙伴历经三个月打造出一套实时大数据交互查询服务,完美的支撑了珠峰、闪电、通天塔、优惠券、凑单等业务的实时需求,并经过了双11、双12等大促活动的实战考验!!
一、背景介绍
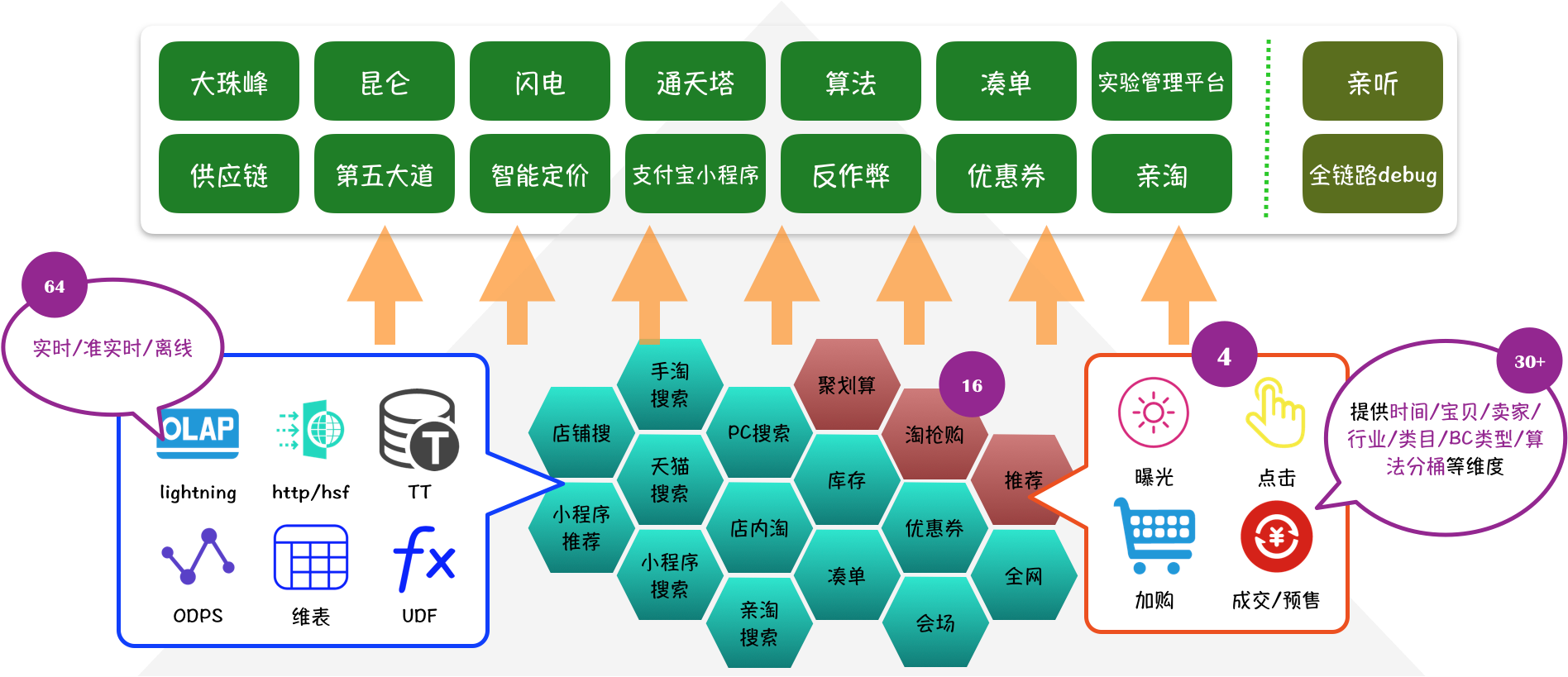
珠峰调控的典型应用场景如下图所示:
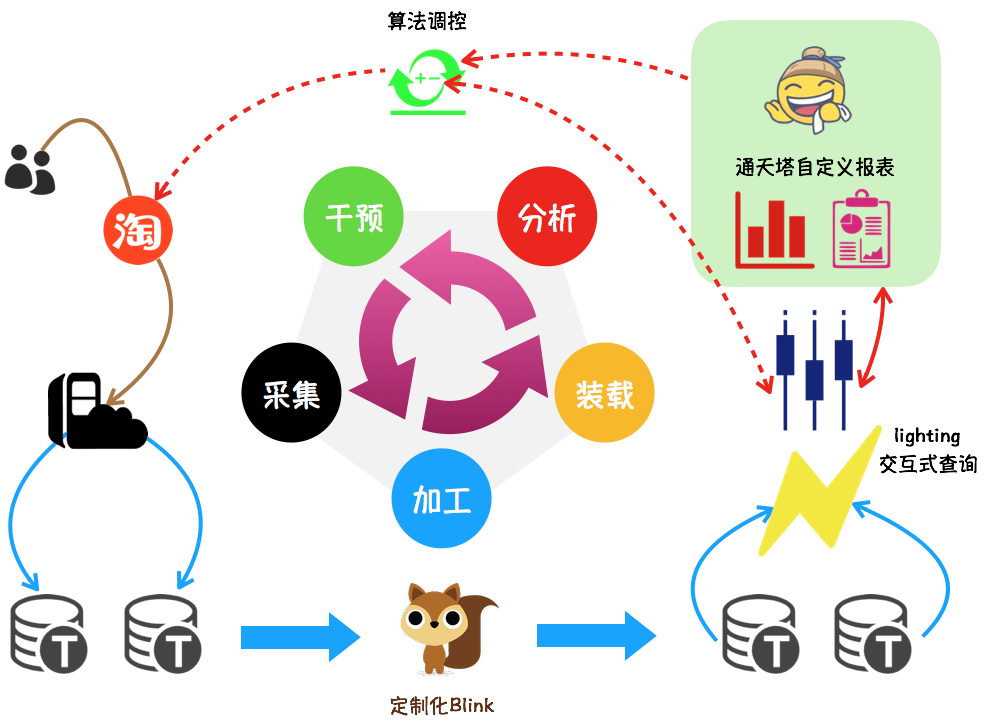
- 采集:用户在淘宝的每一次浏览/点击/加购/成交等行为都被记录在日志中,并实时传送到TimeTunnel,该部分工作由业务团队或数据团队完成
- 加工:基于集团的明星产品Blink,对所需业务渠道的日志进行加工处理,产出业务所需要的各种维度/各种指标
- 装载:将加工好的格式化数据装载到lightning交互式查询引擎,方便后续快速查询
- 分析:通过定制化报表可以实时动态展示行业/类目/商家/宝贝/分桶等多维实时指标,方便小二分析决策,更多业务报表详见珠峰、闪电
- 干预:在搜索/推荐等产品中,算法自动获取指标、并根据实时分析的结果更改线上参数,影响线上效果
- 干预后的结果又进入下一个数据轮回,直到业务目标完成
二、解决方案
2.1 确立目标
改造后的实时数据既要满足功能,还要可兼容、可扩展:
- 数据的正确性和稳定性是一切的前提,实时数据统计口径必须和离线一致
- 资源有限,必须打造统一的解决方案满足已有需求,以及未来可能的需求
- 建立标准化,拉更多人一起参与数据共建
- 数据的生产和消费都要统一管理,消灭一切不合理
2.2 梳理需求
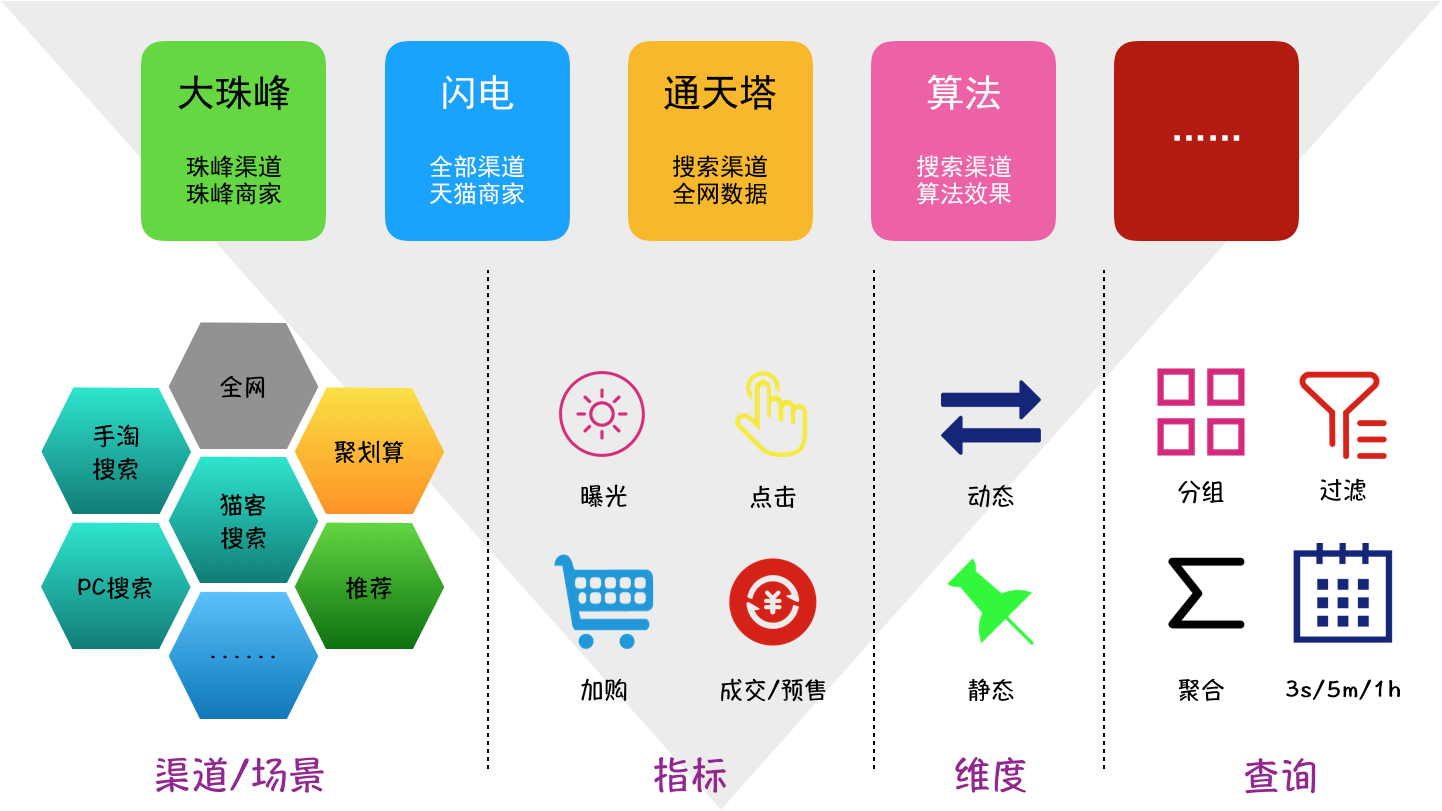
将各平台的业务需求进行挨个梳理,针对数据自身特点进行抽象,确定数据分层:
- 全网数据:独立的数据表,如全网加购、全网成交等
- 渠道数据:根据业务独立性划分为手淘搜索、推荐、营销平台等渠道,各渠道包括数据指标:曝光(宝贝曝光/搜索曝光)、点击、引导加购、引导成交等,各数据指标是独立的数据表
- 子业务场景:含在渠道数据表中,存储在固定字段并用关键字区分,例如手淘搜索全部分页/天猫分页、推荐的猜你喜欢/购后等
- 数据维度:含在渠道数据表中,存储在固定字段(如时间、宝贝、卖家、类目、行业等)和多值字段(如分桶、BC类型等)
梳理各业务方关注的数据场景,梳理出双11的数据需求和查询需求:
数据要求:
- 宝贝量从去年的20w到5kw,增长250倍
- 卖家量从去年的1500到16w,增长100倍
- 单表最大数据量 > 600亿
实时性:
- 单表写入最大QPS > 200w/s
- 数据延迟时间(日志落地到查询可见) < 5s
查询需求:
- 查询频率:3s、1min、5min、1h
- 查询范围:当天、当前小时、前5min、前10min
- 查询响应时间 < 3s
- 单表查询QPS < 100/s
2.3 架构选型
目前可以满足上诉性能要求,并且相对成熟的实时大数据架构方案有两种:

- blink + kv存储:在blink层进行数据预聚合并将聚合后的计算值写入kv存储,用户按照事先约定好的key进行查询即可拿到实时结果,常用的kv存储比如hbase、redis、tair等。该方案的优势是查询毫秒级响应并支持查询高并发,但不足之处是可扩展性较差,增加维度或改变查询条件需要改动整条链路。比如双11媒体交易大屏,提供00:00到当前时刻的交易总额,但如果想查看10:00-10:20的交易总额改造成本就会很高甚至无法进行
- blink + olap/oltp:在blink层进行数据明细加工并补充数据标签,加工后的数据装载到olap/oltp,用户带着自定义条件进行查询。该方案最大的优势就是交互式查询,用户可以根据自己需要进行各种维度的查询组合,但不足之处就是无法支持高并发高QPS查询,而且查询之间会互相干扰,偶尔一个大的聚合查询会导致其它查询失败
两套方案各有优劣各有适应的业务场景,考虑到我们打造的实时数据支持的业务场景较多而且需求各不相同,综合比较之后我们选择了第二套方案,至于不支持高QPS的问题我们通过优化查询Query解决。实践证明我们的选择是很明智的,用户对实时数据的查询需求随着大促逐渐临近呈爆发性的增长,甚至双11当天决策层还对我们提出若干新的数据需求,不过我们都轻松应对,合理的架构让一切不可能成为了可能
2.4 最终架构
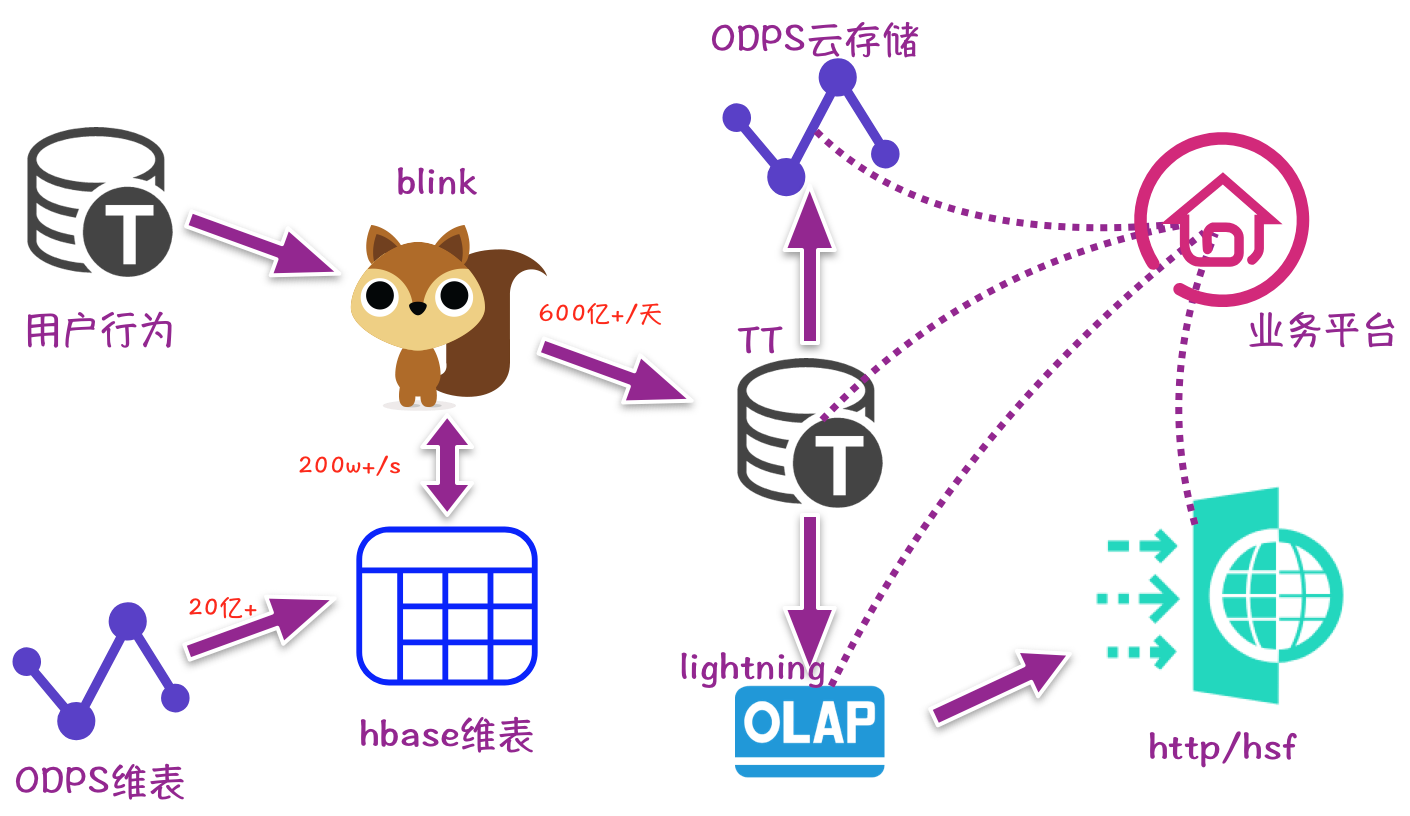
2.5 规范标准
统一接口定义
- 全网数据接口定义
- 渠道搜索数据接口定义
- 渠道宝贝数据接口定义
规范实时处理逻辑的分析方法
- 找日志生产者掌握字段含义,并结合业务需求进行初步设计
- 以BI使用的ODPS表为基础,梳理离线处理逻辑
- 订阅实时日志,使用离线处理逻辑进行日志详细分析
- 实现实时任务代码
- 实时离线对比验证,分别从全部、卖家、宝贝三个维度验证,要求数据差异均小于3%
制定Blink代码开发规范
- 主流程使用Table API,Scala开发
- 日志处理以及字段处理使用UDF,Java开发
- UDF设计尽量只专注一件事,如多值字段中n个字段最好提供n个UDF分别处理
- 过滤逻辑和处理逻辑要求代码层面隔离,不能耦合
- 严格遵守集团开发规约
让合适的人做合适的事
- 搜索数据属于我们擅长的,我们负责开发维护
- 其它数据推动相应业务方按照标准开发,我们提供技术支持和资源支持
2.6 重构
实时任务
实时任务重构过程中做了很多细节优化:
- ID值存储:实时数据均存储各维度ID值,将冗余字段Name剔除,大大减少查询引擎的存储查询压力
- 辅表为主:当数据在辅表和日志都存在时,优先透出辅表数据
- 数据打标:提供全网用户/全网卖家/全网宝贝的数据打标,方便业务方按照数据标一次查询获得结果
- 数据分区:产出到TT中的实时数据按照宝贝ID进行Partition,可以减少查询引擎的单次消耗
- 异步读写:写TT以及读写HBase均采用异步操作,既提高读写QPS又保证实时任务受集群环境影响最小化
- 离线备份:所有的实时数据表每15min同步到相应的云存储ODPS表,以防不时之需
- ……
封装查询接口
为了约束规范业务方使用实时数据,我们封装了统一的数据查询接口:
- 采用租户分配QPS配额的方式,控制访问频率
- 对常用查询方法进行封装,减少用户学习成本
- 每次查询都进行实时监控并记录追踪日志,方便出现问题时快速排查
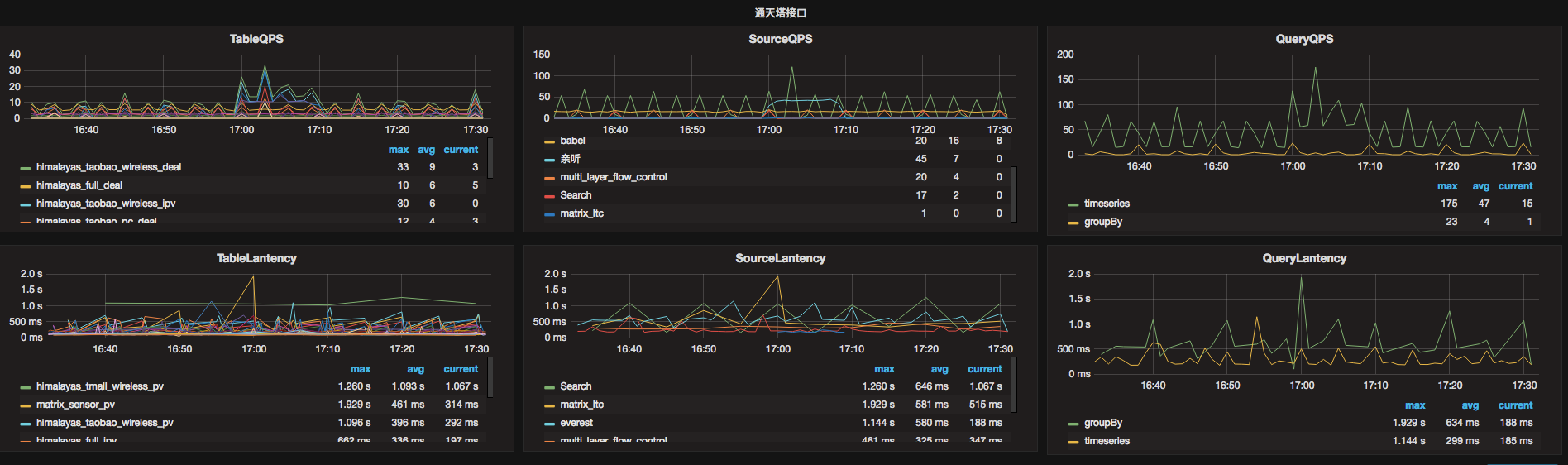
另外我们对业务方每条Query进行了分析,推动业务方优化不合理的Query,对于查询Query较大较慢的业务搭建独立的查询引擎,通过以上措施减少了业务间互相干扰,大大的提高了系统稳定性,业务效率也得到了极大提升
数据校验
邀请BI作为裁判对重构的实时数据进行了一致性校验,__校验结果:90%以上的场景数据差异在1%以内__,实时数据准确性得到了大家的一致认可!
线上运维
- 使用烽火台监控延迟报警、无数据报警
- 在KMonitor建立各级监控:全景监控、单任务监控、全链路大盘
- 通过多轮压测保证任务资源占用既不浪费又能满足大促需要
三、成果总结
3.1 实战效果
2017年双11活动期间,实时大数据共运行Blink任务40+,产生实时数据表40+,占用资源约近5000vcore、近20T mem
双11当天处理日志量数百T,数据峰值TPS约7000w+,产出纯净业务数据数十T,总条数1500亿+,其中单表全天近700亿,数据处理峰值200w+;支持了全网数据的辅表信息透出,实时数据延迟在秒级别;查询服务全天请求近200w,QPS峰值约700次,平均响应时间1.5s
3.2 建立生态
随着实时大数据取得的成功,越来越多平台希望引入实时数据,截止到18年1月底实时大数据服务情况如下图所示,目前业务平台、数据渠道、数据指标仍在不断扩充中,实时大数据生态已经初具规模,这对参与实时数据建设的所有小伙伴们来说是莫大的认可
四、作者简介
花名:言柏,来自搜索事业部-工程效率&技术质量-算法工程平台-实时大数据平台
14年加入阿里,主要从事电商体系实时数据研发以及实时交互式查询赋能于新商业

【阿里内部应用】基于Blink为新商业调控打造实时大数据交互查询服务相关推荐
- 实时计算框架 Flink 新方向:打造「大数据+AI」 未来更多可能
2019-12-20 17:57 导语:如何将大数据与 AI 结合...... 自 Flink 开源以来,越来越多的开发者加入了 Flink 社区.仅仅 2019 年,Flink 在 GitHub 上 ...
- 争分夺秒:阿里实时大数据技术全力助战双11
摘要: 12月13-14日,由云栖社区与阿里巴巴技术协会共同主办的<2017阿里巴巴双11技术十二讲>顺利结束,集中为大家分享了2017双11背后的黑科技.本文是<争分夺秒:阿里实时 ...
- 三大运营商新战场:与BAT争夺大数据金矿
"发展大数据,扩大影响力",这是今年世界电信日的主题. 大数据一词,早已在众多行业开始渗透,但距离规模应用尚有一定距离.通信行业作为目前数据量最大.覆盖面最广的行业之一,拥有大量具 ...
- 新工科背景下的大数据体系建设探析
新工科背景下的大数据体系建设探析 王元卓,于建业 中国科学院计算技术研究所,北京 100190 北京物资学院信息学院,北京 101149 摘要:大数据产业迅猛发展,对大数据人才培养提出了巨大挑战. ...
- 第七章 得数据者得天下,商业竞争中的大数据
商业领域无疑是大数据时代的领头羊,它们最先发现了大数据在商业竞争中的价值.数据化的进程推动了商业数据的可量化变革,同时也更新了对客户形象的描述.信息化的商业竞争已经打响,谁掌握大数据谁就会是未来的赢家 ...
- 大数据带来新机遇:如何利用大数据技术优化跨境电商运营?
互联网和电商的不断发展,跨境电商已经成为一种全新的商业模式.然而,跨境电商的运营需要面对很多挑战,如物流.支付.语言文化等.如何利用大数据技术优化跨境电商运营成为一个重要的课题. 一.大数据技术在跨境 ...
- 专题导读:新工科背景下的大数据人才培养及课程体系设计
专题:新工科背景下的大数据人才培养及课程体系设计 导读: 当今社会已进入大数据时代,为了顺应时代发展的潮流,国内外各类高校陆续开始聚焦大数据,布局新学科,加快人才培养的步伐.目前教育部已经正式批 准2 ...
- 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)...
不多说,直接上干货! 这个很简单,在集群机器里,选择就是了,本来自带就有Impala的. 扩展博客 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解) 欢迎大 ...
- SQL Server 2019 新特性之 SQL Server大数据群集 介绍(一)
SQL Server 2019 新特性之 SQL Server大数据群集 介绍(一) 从开始SQL Server 2019 预览,SQL Server 大数据群集允许你部署的 Kubernetes 上 ...
最新文章
- iMeta期刊推特官方帐号@iMetaJournal上线
- oracle SQL 命令行(二.视图(2))
- 收藏 不显示删除回复显示所有回复显示星级回复显示得分回复 有损脑健康的七种坏习惯...
- SET IDENTITY_INSERT [Table] [ON|OFF]
- mysql范式与反范式_给女同事讲解MySQL数据库设计范式与反范式,她夸我“技术好”...
- 【转】反病毒攻防研究第003篇:添加节区实现代码的植入
- java rmi 超时_java RMI服务超时
- 微软在Skype推出LGBT骄傲月表情与贴纸
- 苹果cmsv10精仿迅播影院2tu风格主题模板
- 黑莓手机将停售;三大运营商:疫情防控期间用户欠费不停机;Chrome 测试移除搜索结果页网址 | 极客头条...
- 超 8 亿人收发微信春节红包;苹果自研 iPhone 芯片;暴雪或将大裁员 | 极客头条...
- java es scroll,Elasticsearch Scroll分页检索案例分享
- 新手怎么入门电子电路设计?
- 第四课曲面与曲线方程
- matlab仿真电子秤,基于51单片机电子秤的代码
- ubuntu16.04安装及卸载anaconda3
- STM32 GD32脱机烧写器制作
- SVN冲突的原因和解决
- puppet kick 报错返回值code3 求解答(finished with exit code 3)
- 7月11号,大连小雨