Hadoop HA 深度解剖
精选30+云产品,助力企业轻松上云!>>> 
点击蓝色“大数据每日哔哔”关注我
加个“星标”,第一时间获取大数据架构,实战经验
Hadoop 2.x 架构在 NameNode 上的改变,解决了单点问题和主备切换的问题,元数据信息同步的问题,结合 ZK 来实现的,但是 ZK 是如何把主备的 NameNode 节点进行切换的呢?是如何让保证元数据信息同步的呢?
带着这些疑问,开始今天的文章。
目录:
- 配置
- 主备及切换
- 主备切换每个细节(监控检测,脑裂等)
- JQM 数据同步机制
1.
先来看一下官方提供的配置:Apache 官方的例子,熟悉的同学可以略过...
先是配置 hdfs-site.xml 文件。
hdfs集群服务名字:
<property> <name>dfs.nameservices</name> <value>mycluster</value></property>NameNode 别名
<property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2, nn3</value></property>NameNode 的 PRC 监听端口
<property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>machine1.example.com:8020</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>machine2.example.com:8020</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn3</name><value>machine3.example.com:8020</value></property>NameNode 的 HTTP 监听端口
<property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>machine1.example.com:9870</value></property><property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>machine2.example.com:9870</value></property><property> <name>dfs.namenode.http-address.mycluster.nn3</name> <value>machine3.example.com:9870</value></property>This is where one configures the addresses of the JournalNodes which provide the shared edits storage, written to by the Active nameNode and read by the Standby NameNode to stay up-to-date with all the file system changes the Active NameNode makes.
<property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node1.example.com:8485;node2.example.com:8485;node3.example.com:8485/mycluster</value></property>the Java class that HDFS clients use to contact the Active NameNode.
<property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property>Importantly, when using the Quorum Journal Manager, only one NameNode will ever be allowed to write to the JournalNodes, so there is no potential for corrupting the file system metadata from a split-brain scenario. 只有允许同一时刻有一个 NameNode 往JNS 里面写数据。因为会出现过时的 NameNode 好保持着 Active 状态,或者出现假死状态。
下面配置了 sshfence 用于通过 ssh 连接目标机器,运行 kill 命令。
<property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value></property>
<property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/exampleuser/.ssh/id_rsa</value> </property>JNS 编辑日志的物理磁盘地址:
<property><name>dfs.journalnode.edits.dir</name><value>/path/to/journal/node/local/data</value></property>core-site.xml 文件:
配置 ZK 集群:
<property> <name>ha.zookeeper.quorum</name> <value>node01:2181,node02:2181,node03:2181</value></property>配置 HDFS 集群的服务域名:
<property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value></property>以上都配置了什么呢?
有这几个核心点:
NameNode 主备,ZK 集群,JNS 集群,sshfence 一把利剑。
2.
NameNode 的主备切换主要是由 ZKFailerController,HeathMonitor,ActiveStandbyElector 三个组件协同实现的。
其中,ZKFailerController 在 NameNode 上作为独立的进行启动,(在系统上可以看到 zkfc 这个后台进程)。启动的时候,会创建 HeathMonitor 和 ActiveStandbyElector 这两个内部组件,ZKFailoverController 在创建 HealthMonitor 和 ActiveStandbyElector 的同时,也会向 HealthMonitor 和 ActiveStandbyElector 注册相应的回调方法。
HealthMonitor 初始化完成之后会启动内部的线程来定时调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法,对 NameNode 的健康状态进行检测。HealthMonitor 如果检测到 NameNode 的健康状态发生变化,会回调 ZKFailoverController 注册的相应方法进行处理。
如果 ZKFailoverController 判断需要进行主备切换,会首先使用 ActiveStandbyElector 来进行自动的主备选举。ActiveStandbyElector 与 Zookeeper 进行交互完成自动的主备选举。ActiveStandbyElector 在主备选举完成后,会回调 ZKFailoverController 的相应方法来通知当前的NameNode 成为主 NameNode 或备 NameNode。
ZKFailoverController 调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法将 NameNode 转换为 Active 状态或 Standby 状态。
具体的细节:(重要)
健康检查:HeathMonitor
ZKFailoverController 在初始化的时候会创建 HealthMonitor,HealthMonitor 在内部会启动一个线程来循环调用 NameNode 的 HAServiceProtocol RPC 接口的方法来检测 NameNode 的状态,并将状态的变化通过回调的方式来通知 ZKFailoverController。
HealthMonitor 主要检测 NameNode 的两类状态,分别是 HealthMonitor.State 和 HAServiceStatus。HealthMonitor.State 是通过 HAServiceProtocol RPC 接口的 monitorHealth 方法来获取的,反映了 NameNode 节点的健康状况,主要是磁盘存储资源是否充足。
HealthMonitor.State 包括下面几种状态:
NITIALIZING:HealthMonitor 在初始化过程中,还没有开始进行健康状况检测;SERVICE_HEALTHY:NameNode 状态正常;SERVICE_NOT_RESPONDING:调用 NameNode 的 monitorHealth 方法调用无响应或响应超时;SERVICE_UNHEALTHY:NameNode 还在运行,但是 monitorHealth 方法返回状态不正常,磁盘存储资源不足;HEALTH_MONITOR_FAILED:HealthMonitor 自己在运行过程中发生了异常,不能继续检测 NameNode 的健康状况,会导致 ZKFailoverController 进程退出;HealthMonitor.State 在状态检测之中起主要的作用,在 HealthMonitor.State 发生变化的时候,HealthMonitor 会回调 ZKFailoverController 的相应方法来进行处理,具体处理见后文 ZKFailoverController 部分所述。
而 HAServiceStatus 则是通过 HAServiceProtocol RPC 接口的 getServiceStatus 方法来获取的,主要反映的是 NameNode 的 HA 状态,包括:
INITIALIZING:NameNode 在初始化过程中;ACTIVE:当前 NameNode 为主 NameNode;STANDBY:当前 NameNode 为备 NameNode;STOPPING:当前 NameNode 已停止;HAServiceStatus 在状态检测之中只是起辅助的作用,在 HAServiceStatus 发生变化时,HealthMonitor 也会回调 ZKFailoverController 的相应方法来进行处理,具体处理见后文 ZKFailoverController 部分所述。
主备选举:ActiveStandbyElector
Namenode(包括 YARN ResourceManager) 的主备选举是通过 ActiveStandbyElector 来完成的,ActiveStandbyElector 主要是利用了 Zookeeper 的写一致性和临时节点机制,具体的主备选举实现如下:
创建锁节点 ,如果 HealthMonitor 检测到对应的 NameNode 的状态正常,那么表示这个 NameNode 有资格参加 Zookeeper 的主备选举。如果目前还没有进行过主备选举的话,那么相应的 ActiveStandbyElector 就会发起一次主备选举,尝试在 Zookeeper 上创建一个路径为/hadoop-ha//ActiveStandbyElectorLock 的临时节点,Zookeeper 的写一致性会保证最终只会有一个 ActiveStandbyElector 创建成功,那么创建成功的 ActiveStandbyElector 对应的 NameNode 就会成为主 NameNode,ActiveStandbyElector 会回调 ZKFailoverController 的方法进一步将对应的 NameNode 切换为 Active 状态。而创建失败的 ActiveStandbyElector 对应的 NameNode 成为备 NameNode,ActiveStandbyElector 会回调 ZKFailoverController 的方法进一步将对应的 NameNode 切换为 Standby 状态。
Watcher 监听:
不管创建 /hadoop-ha//ActiveStandbyElectorLock 节点是否成功,ActiveStandbyElector 随后都会向 Zookeeper 注册一个 Watcher 来监听这个节点的状态变化事件,ActiveStandbyElector 主要关注这个节点的 NodeDeleted 事件。(所有的 NameNode 都会有一个 Watcher 监听)。
自动触发主备选举 ,如果 Active NameNode 对应的 HealthMonitor 检测到 NameNode 的状态异常时, ZKFailoverController 会主动删除当前在 Zookeeper 上建立的临时节点/hadoop-ha//ActiveStandbyElectorLock,这样处于 Standby 状态的 NameNode 的 ActiveStandbyElector 注册的监听器就会收到这个节点的 NodeDeleted 事件。收到这个事件之后,会马上再次进入到创建/hadoop-ha//ActiveStandbyElectorLock 节点的流程,如果创建成功,这个本来处于 Standby 状态的 NameNode 就选举为主 NameNode 并随后开始切换为 Active 状态。
当然,如果是 Active 状态的 NameNode 所在的机器整个宕掉的话,那么根据 Zookeeper 的临时节点特性,/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 节点会自动被删除,从而也会自动进行一次主备切换。
脑裂:
Zookeeper 在工程实践的过程中经常会发生的一个现象就是 Zookeeper 客户端“假死”,所谓的“假死”是指如果 Zookeeper 客户端机器负载过高或者正在进行 JVM Full GC,那么可能会导致 Zookeeper 客户端到 Zookeeper 服务端的心跳不能正常发出,一旦这个时间持续较长,超过了配置的 Zookeeper Session Timeout 参数的话,Zookeeper 服务端就会认为客户端的 session 已经过期从而将客户端的 Session 关闭。“假死”有可能引起分布式系统常说的双主或脑裂 (brain-split) 现象。
具体到本文所述的 NameNode,假设 NameNode1 当前为 Active 状态,NameNode2 当前为 Standby 状态。如果某一时刻 NameNode1 对应的 ZKFailoverController 进程发生了“假死”现象,那么 Zookeeper 服务端会认为 NameNode1 挂掉了,根据前面的主备切换逻辑,NameNode2 会替代 NameNode1 进入 Active 状态。但是此时 NameNode1 可能仍然处于 Active 状态正常运行,即使随后 NameNode1 对应的 ZKFailoverController 因为负载下降或者 Full GC 结束而恢复了正常,感知到自己和 Zookeeper 的 Session 已经关闭,但是由于网络的延迟以及 CPU 线程调度的不确定性,仍然有可能会在接下来的一段时间窗口内 NameNode1 认为自己还是处于 Active 状态。这样 NameNode1 和 NameNode2 都处于 Active 状态,都可以对外提供服务。这种情况对于 NameNode 这类对数据一致性要求非常高的系统来说是灾难性的,数据会发生错乱且无法恢复。Zookeeper 社区对这种问题的解决方法叫做 fencing,中文翻译为隔离,也就是想办法把旧的 Active NameNode 隔离起来,使它不能正常对外提供服务。
ActiveStandbyElector 为了实现 fencing,会在成功创建 Zookeeper 节点 hadoop-ha//ActiveStandbyElectorLock 从而成为 Active NameNode 之后,创建另外一个路径为/hadoop-ha//ActiveBreadCrumb 的持久节点,这个节点里面保存了这个 Active NameNode 的地址信息。Active NameNode 的 ActiveStandbyElector 在正常的状态下关闭 Zookeeper Session 的时候 (注意由于/hadoop-ha//ActiveStandbyElectorLock 是临时节点,也会随之删除),会一起删除节点/hadoop-ha//ActiveBreadCrumb。但是如果 ActiveStandbyElector 在异常的状态下 Zookeeper Session 关闭 (比如前述的Zookeeper 假死),那么由于/hadoop-ha//ActiveBreadCrumb 是持久节点,会一直保留下来。后面当另一个 NameNode 选主成功之后,会注意到上一个 Active NameNode 遗留下来的这个节点,从而会回调 ZKFailoverController 的方法对旧的 Active NameNode 进行 fencing!!!!!!
如果 ActiveStandbyElector 选主成功之后,发现了上一个 Active NameNode 遗留下来的/hadoop-ha//ActiveBreadCrumb 节点 ,那么 ActiveStandbyElector 会首先回调 ZKFailoverController 注册的 fenceOldActive 方法,尝试对旧的 Active NameNode 进行 fencing,在进行 fencing 的时候,会执行以下的操作:
首先尝试调用这个旧 Active NameNode 的 HAServiceProtocol RPC 接口的 transitionToStandby 方法,看能不能把它转换为 Standby 状态。 如果 transitionToStandby 方法调用失败,那么就执行 Hadoop 配置文件之中预定义的隔离措施,Hadoop 目前主要提供两种隔离措施,通常会选择 sshfence: sshfence:通过 SSH 登录到目标机器上,执行命令 fuser 将对应的进程杀死;shellfence:执行一个用户自定义的 shell 脚本来将对应的进程隔离;
只有在成功地执行完成 fencing 之后,选主成功的 ActiveStandbyElector 才会回调 ZKFailoverController 的 becomeActive 方法将对应的 NameNode 转换为 Active 状态,开始对外提供服务。
3.
ActiveNameNode和StandbyNameNode使用 JouranlNode 集群来进行数据同步的过程如图所示,Active NameNode 首先把 EditLog 提交到 JournalNode 集群,然后 Standby NameNode 再从 JournalNode 集群定时同步 EditLog:
基于 QJM 的共享存储的数据同步机制
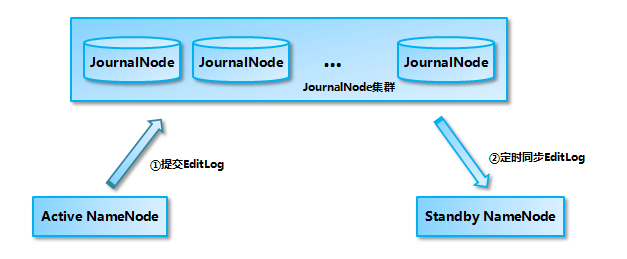
Active NameNode 提交 EditLog 到 JournalNode 集群,当处于 Active 状态的 NameNode 调用 FSEditLog 类的 logSync 方法来提交 EditLog 的时候,会通过 JouranlSet 同时向本地磁盘目录和 JournalNode 集群上的共享存储目录写入 EditLog。写入 JournalNode 集群是通过并行调用每一个 JournalNode 的 QJournalProtocol RPC 接口的 journal 方法实现的,如果对大多数 JournalNode 的 journal 方法调用成功,那么就认为提交 EditLog 成功,否则 NameNode 就会认为这次提交 EditLog 失败。提交 EditLog 失败会导致 Active NameNode 关闭 JournalSet 之后退出进程,留待处于 Standby 状态的 NameNode 接管之后进行数据恢复。
从上面的叙述可以看出,Active NameNode 提交 EditLog 到 JournalNode 集群的过程实际上是同步阻塞的,但是并不需要所有的 JournalNode 都调用成功,只要大多数 JournalNode 调用成功就可以了。如果无法形成大多数,那么就认为提交 EditLog 失败,NameNode 停止服务退出进程。如果对应到分布式系统的 CAP 理论的话,虽然采用了 Paxos 的“大多数”思想对 C(consistency,一致性) 和 A(availability,可用性) 进行了折衷,但还是可以认为 NameNode 选择了 C 而放弃了 A,这也符合 NameNode 对数据一致性的要求。
当 NameNode 进入 Standby 状态之后,会启动一个 EditLogTailer 线程。这个线程会定期调用 EditLogTailer 类的 doTailEdits 方法从 JournalNode 集群上同步 EditLog,然后把同步的 EditLog 回放到内存之中的文件系统镜像上 (并不会同时把 EditLog 写入到本地磁盘上)。
这里需要关注的是:从 JournalNode 集群上同步的 EditLog 都是处于 finalized 状态的 EditLog Segment。“NameNode 的元数据存储概述”一节说过 EditLog Segment 实际上有两种状态,处于 in-progress 状态的 Edit Log 当前正在被写入,被认为是处于不稳定的中间态,有可能会在后续的过程之中发生修改,比如被截断。Active NameNode 在完成一个 EditLog Segment 的写入之后,就会向 JournalNode 集群发送 finalizeLogSegment RPC 请求,将完成写入的 EditLog Segment finalized,然后开始下一个新的 EditLog Segment。一旦 finalizeLogSegment 方法在大多数的 JournalNode 上调用成功,表明这个 EditLog Segment 已经在大多数的 JournalNode 上达成一致。一个 EditLog Segment 处于 finalized 状态之后,可以保证它再也不会变化。
(完)
本文分享自微信公众号 - 大数据每日哔哔(bb-bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Hadoop HA 深度解剖相关推荐
- Hadoop HA 深度解析
社区hadoop2.2.0 release版本开始支持NameNode的HA,本文将详细描述NameNode HA内部的设计与实现. 为什么要Namenode HA? 1. NameNode High ...
- hadoop(ha)hbase(双master)安装
一.软件包准备 CentOS Linux release 7.2 Linux version 3.10.0-327.el7.x86_64 jdk-7u65-linux-x64.tar.gz zook ...
- Hadoop HA+Federation 高可用联邦模式搭建指南
为什么80%的码农都做不了架构师?>>> 简述 Hadoop 集群一共有4种部署模式,详见<Hadoop 生态圈介绍>. HA联邦模式解决了单纯HA模式的性能瓶颈( ...
- Hadoop技术之Hadoop HA 机制学习
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:温球良 导语 最近分享过一次关于Hadoop技术主题的演讲,由于接触时间不长,很多技术细节认识不够,也没讲清楚,作为一个技术人员,本 ...
- 《C语言深度解剖》中的.c/.h 程序模板及函数注释风格
编程规范和变量命令规范对于代码的可阅读性.可维护性有着很大的影响.编程规范有很多,大公司也会制定自己公司的编程规范,如<华为技术有限公司c语言编程规范>等.对于个人编程来说没必要将自己编写 ...
- c语言深度解剖 pdf,c语言深度解剖(解密).pdf.pdf
c语言深度解剖(解密).pdf.pdf 还剩 130页未读, 继续阅读 下载文档到电脑,马上远离加班熬夜! 亲,很抱歉,此页已超出免费预览范围啦! 如果喜欢就下载吧,价低环保! 内容要点: * Str ...
- C语言深度解剖读书笔记(1.关键字的秘密)
开始本节学习笔记之前,先说几句题外话.其实对于C语言深度解剖这本书来说,看完了有一段时间了,一直没有时间来写这篇博客.正巧还刚刚看完了国嵌唐老师的C语言视频,觉得两者是异曲同工,所以就把两者一起记录下 ...
- 图说Hadoop HA
1.hadoopHA 概览 2.hadoop HA 架构图 3.架构 4.运行流程图 5.组件 转载于:https://www.cnblogs.com/dreamofintellegent/p/579 ...
- C语言深度解剖:关键字
第一个C语言程序 内存 定义与声明 变量是什么 为什么要定义变量 定义变量的本质 定义声明 关键字 - auto 局部与全局变量 作用域 vs 生命周期 auto 关键字 - register 寄存器 ...
最新文章
- Excel万年历的制作
- python第三方库有哪些常用的、请列举15个-阿里巴巴Python开发工程师面试题
- UltraEdit 常用快捷方式
- CoreData并发操作模式简介
- js使浏览器窗口最大化(适用于IE的方法)
- python新手难点_汇总初学python时的28个操作难点(新手必看篇)
- sap产品图谱 - road to sap.pdf_蛇胆陈皮胶囊化学成分及指纹图谱研究
- matlab 信号分选 聚类_显示微缩化,对测试分选设备提出了怎样的要求?
- weex入门指南--华岭
- 【PTAL2-001】紧急救援(Dijkstra+最短路径的条数+最短路径中点权之和的最大值)
- 现代通信原理6.1 常规调幅调制(AM)与抑制载波双边带(DSB-SC)调制
- C/C++程序员桌面壁纸---简尚黑
- ofd文件电子签章实现方法
- 适合小孩接触编程起步的几款软件,从游戏中学习编程
- PCL:getCircumcircleRadius ❤️ 计算三角形外接圆半径
- 通信知识宝典1 -- 如何让无线路由网速最快
- 组合排列中重复数问题
- 开源RPC性能比拼测试 : 一不小心我们进了第一梯队
- 值得品读的感悟人生的经典句子 - 格言网(转载)
- pycharm 如何配置主题背景色 墨绿色