Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning阅读笔记
Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning
Alpa阅读笔记
一、论文的研究背景、动机和主要贡献
背景:大模型和分布式训练
深度学习最近的进展直接导致了模型大小的变化,如:GPD3亿万级别的参数,同时在更大数据集上进行修改以支持兼容性。最新的模型上参数的数量以指数的形式增长。
训练这样大的模型是具有挑战性的。因为模型的参数众多,受限于内存大小,无法在一个单一的加速器上进行训练。同时,这会花费几百年去在一个单独的加速器上训练这样的模型。因此分布式训练是必须的。
迄今为止,分布式训练并不是那么容易,为了训练特定的模型人们必须去建立特定的系统。有一些比较流行的技术,比如数据并行(data parallel),张量并行(tensor parallel)和流水线并行(pipeline parallel)。
[细读经典]三种并行知识
三种并行之间有着不同的权衡(trade off),如果要训练一个较大的模型,你必须去找到一个方法去综合运用这三种并行,从而你可以达到一个好的训练吞吐量。以下是专家设计策略的两个例子:
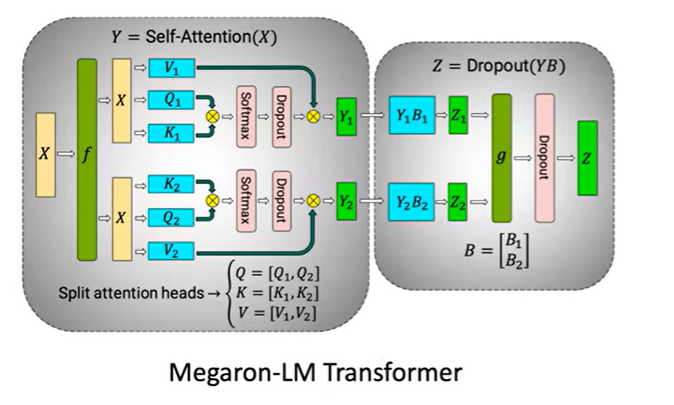
Megatron-LM策略:在transformer层并行化self-attention模型
对于大型的transformer模型,权重的数量非常大,因此不能使用数据并行。所以需要对权重进行分片。在这个模型里面,第一个权重矩阵已经被按列分片,第二个矩阵已经被按行分片,从而减少通信代价。
GShard Mixture-of-Expert
专家层(红色部分)以专家维分片,非专家层以批处理维度分片做数据并行
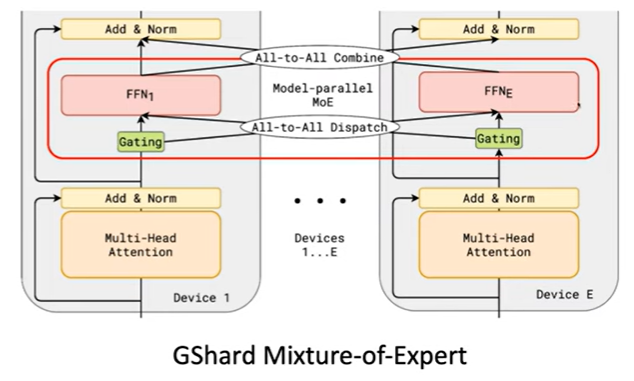
为了应用这样的并行策略,模型开发者不得不去重写他们的模型定义,特定化分片策略,并且插入必要的通信原语,比如这里的all-to-all。这使得开发一个新的模型或者寻找异质模型变得困难。
在我们的论文中,我们的目标是统一所有的这样的并行化策略,并且建立一个编译器去自动产生最优的综合的并行化策略。所以,首先我们总结了现有的并行化策略,把他们分成两种:
Type1:Intra-operator Parallelism

我们利用了单个操作中固有的并行性,所以我们称它为
Intra-operator parallelismType2:Inter-operator Parallelism
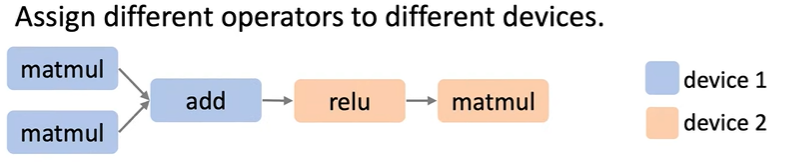
我们利用了在整个图中的更高层次的并行,但由于数据依赖,设备2不得不去等待设备1,等待它的输入数据。所以一些设备可能在一些时间内是空闲的。去解决这样的问题,典型的流水线技术被应用,比如我们可以发送多个微小的批到流水线中去实现并行化。
有了这两种定义,我们可以把传统的并行技术全部归类到这两种分类中,下图展示了一些比较流行的训练两层MLP的并行化技术:
Intra-operator Parallism例子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f6RScEwO-1664632213480)(https://cdn.jsdelivr.net/gh/Holmes233666/blogImage@main/img/2022/08/16/43c8d4416b7ebcaf633ebd318372d1ef-image-20220816114141419-20fbf4.png)]
Inter-operator Parallism例子:
![]()
特别注意的是,在Device Placement的图中,如果不存在多个并行的设备分支,那么会造成时间的空闲;而在Pipeline Parallelism中通过将输入的数据分割为若干的微小的批次,从而解决了这个问题。
在这两种分类之间有着响应的权衡(trade-off):
Intra-operator Parallism需要大量的通信,比如all reduce和all-to-all,故高带宽的设备连接是必要的。Inter-operator Parallism通常需要的是点到点的通信,通信发生在子图的边界内,需要更少的通信。但是为了解决设备的空闲,仔细的调度和分片是需要的。
Prior Auto-Parallelization Work
有效的训练一个大模型通常需要上述的很多技术的综合。如果依赖于人工的设计策略,这需要很大的工程上的努力。所以研究者倾向于去寻找一种基于自动并行。在以前的工作中,有以下几种自动并行化系统:
- Flexflow/Tofu
- Pipedream/Dapple
但是他们都有很多的限制,并且不能训练最先进的模型:
搜索空间有限
由于这些模型仅考虑了有限的并行化技术,并没有对所有的并行化技术予以支持。
搜索算法限制
搜索算法的搜索是基于对模型的随机搜索或者强假设的。
Our Approach
本篇的论文解决方案采取了一个不同的并行化视角,将上述的两种并行化技术分类作为一个两层层次化空间。这个层次化的空间自然地与层次化常见的GPU集群结构映射起来,在GPU内部结点中是高带宽的NVLink链接,而在结点之间是较慢的连接,比如以太网。本篇论文建立了一个两层的层次化搜索空间,然后设计响应的算法去获得每个层次的最优解。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DnZOcJhQ-1664632213482)(https://cdn.jsdelivr.net/gh/Holmes233666/blogImage@main/img/2022/08/16/60da5dacdd31366edbe4f6874485fcea-image-20220816154909651-fac5e3.png)]
接下来是方法的详细说明。
二、Automating Intra and Inter Operator Parallelism
自动并行化(Auto Parallelism)意味着用户不用特意地去修改他们的模型,论文中提到的模型将会将用户的模型从一个单设备的程序转变为一个多设备的程序。Alpa遵循编译器的架构,我们从runtime部分开始说明:
两种并行化的runtime支持
现在的GPU集群中,GPU被典型的组织成为一个两层的拓扑结构,故在结点内有高速的链接,但在结点间有着相对慢速的连接。论文使用了一个二维设备网络去指代这个拓扑结构。以下图为例,在这个设备网络中,我们有2个Worker,每个设备中有4个加速器,并且我们可以假设,在Worker内部,加速器结点之间通信速度较快,而在Worker之间,通信速度较慢。在组织时,设备之间采用Inter-op Parallesim模式,而在设备内部采用Intra-op Parallelism的形式。
![]()
编译器端
对于编译器端,输入是一个计算图和一个特定的设备集群。
我们首先运行一个Inter-op Pass将计算图分片为多个阶段,对于每个阶段我们对其分配一个设备网,故一个设备网负责一个阶段(stage)的计算。对于每个阶段之间,我们运行一个Intra-op Pass去分片所有的操作,即使是在设备网的多个GPU集群之间。
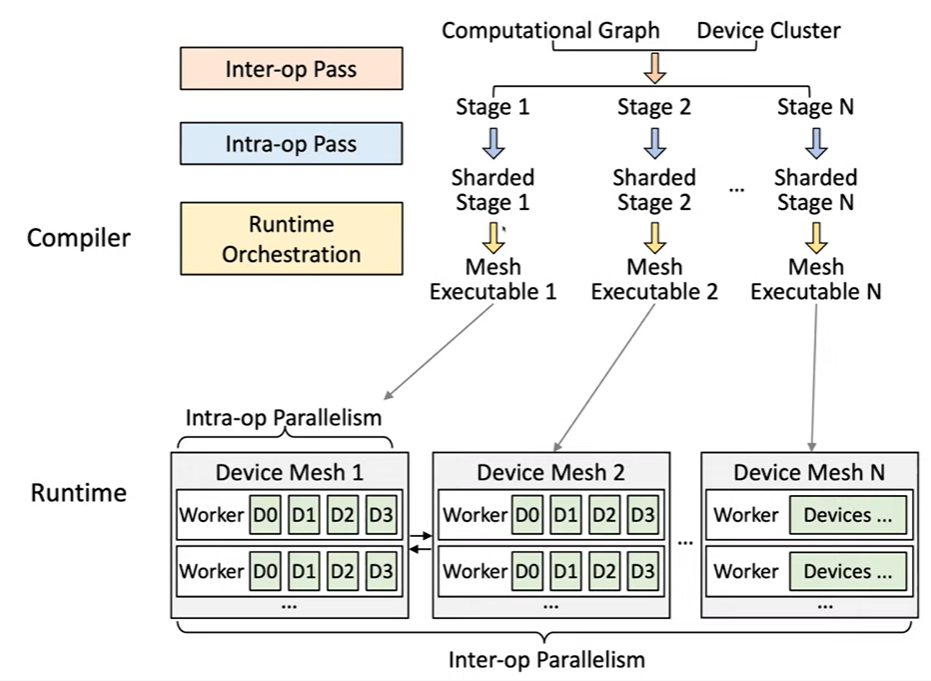
在运行时编排(runtime orchestration)阶段,编译器使用流水线的指令去调度这些阶段,并且所有的指令被静态编译为网络可执行(mesh executable),这个网络可执行被发送到相应的设备网络,然后我们在所有的设备上去执行相应的mesh executable。
故在整个阶段中,最重要的是Inter-op Pass和Intra-op Pass两个部分:
Inter-op Pass可以通过动态规划为Inter-op Parallism提供一个局部的最优解;Intra-op Pass可以通过整数线性规划为Intra-op Parallism提供一个局部最优解
下面对于这两个重要的阶段进行详细的分析:
Intra-op Pass
Intra-op Pass使用的是SPMD风格,这意味着将会对每个操作进行分片,即是是在设备网络中的所有GPU中。SPMD风格简化了许多东西,但是由于其依然可以覆盖很多传统的技术,比如数据并行(Data Prallelism)、操作并行(Operator Parallelism)和零优化器(Zero Optimizer),SPMD是足够强大的。对于Intra-op Pass我们的目标是对于每个操作找到一个分片策略。以下图为例,这是一个两层MLP的向前计算图。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7rds5l4P-1664632213482)(https://cdn.jsdelivr.net/gh/Holmes233666/blogImage@main/img/2022/08/16/1290cdb155db778d4727a55bfbc55caf-image-20220816171138920-dfcf09.png)]
对于张量的权重,它可以被按行分片、按列分片、全复制或者是部分复制,故每个结点的张量都有一个包含多种可能的分片策略的分片策略集(partition strategy set)。比如矩阵乘法有很多种并行计算的方法去解决该问题。不同的算法对输入层有着不同的要求,如某个算法可能要求权重是按列分片的,另一个算法可能要求权重是按行分片的。同时不同的算法也有着不同的输出布局。如果输入不满足算法的输入要求,那么我们需要在边缘做一个布局转化,这会造成相应的通信代价。
总之,去执行计算图,总时间代价公式如下:
Total time cost = node cost(compute cost) + edge-cost(communication cost) \text{Total time cost = node cost(compute cost) + edge-cost(communication cost)} Total time cost = node cost(compute cost) + edge-cost(communication cost)
我们的目标即去对每个操作(operator)选择一个分片的策略,并且最小化总时间代价(Total time cost)。下面给出一个更加具体的例子,分析不同结点可能的分片策略和边缘代价:
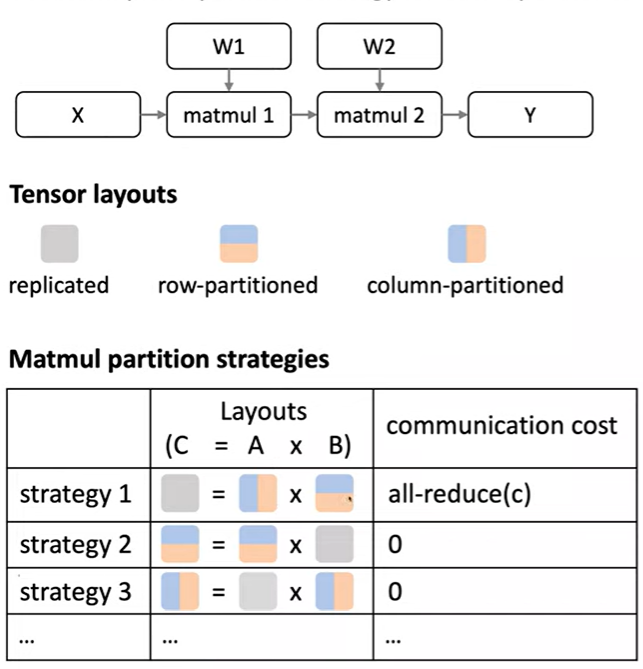
输入矩阵和权重矩阵可以是完整副本、部分副本、列分片或者行分片的形式。矩阵乘法需要三层的循环,我们可以将第一层循环或者第二次循环或者这些循环的结合做并行处理,这样会有多个不同的策略:
- Strategy 1:矩阵A为列分片,矩阵B为行分片,最终产生一个结果的完整副本;同时需要进行
all-reduce(c)去累计部分结果。 - Strategy 2:矩阵A为行分片,矩阵B在两个设备上存有完整的副本,最终产生的结果不需要进行累计,分别存储在两个设备上。
- Strategy 3:矩阵A在两个设备上存有完整副本,矩阵B为列分片,最终产生的结果分别存储在两个设备上。
若布局不匹配,那么需要使用集中式通信原语进行布局转换:
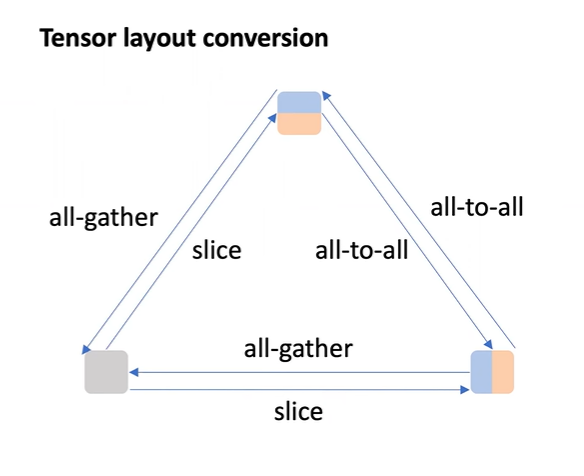
例如:若需得到张量并未列或行分片的副本时,需要使用all-gather原语去进行结果的合并;若进行列分片或者行分片的转换时,需要使用all-to-all原语转换;若将一个完整的副本进行分片,并不需要进行通信,在本地进行分片即可。
上述的优化问题可以使用整数线性规划求解,以下图所示的依赖关系为例:依赖关系只是在两个结点之间存在,这就产生了一个二次目标规划,将其线性化即可得到一个线性规划。
整数规划?如何进行?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y9yt3plv-1664632213483)(https://cdn.jsdelivr.net/gh/Holmes233666/blogImage@main/img/2022/08/16/4a467a2ea41d93e846acd168f43e06a9-image-20220816194215006-2c016a.png)]
为建模此问题,需要枚举所有操作(operator)的所有可能的分片策略,并且计算在所有边上的策略对的通信代价,最后以最小化代价为目标,进行整数线性规划。
与之前的工作对比:
| Comparison | Advantages |
|---|---|
| vs. Tofu |
Support general graphs. Support 2-D device mesh |
| vs. FlexFlow |
Optimality guarantee. Support additional partition strategies. |
Note: 如果考虑通信计算重叠,由于存在复杂的依赖关系,将不再能建模成为一个整数线性规划的问题。实际中,可以先进行整数规划,得到一个较优的解后进行通信计算重叠优化。通信计算重叠(communication computation overlapping)
Inter-op Pass
在这部分将会针对流水线并行进行阐述,目前流水线也是针对于大模型训练的较为有效的方式。Inter-op Pass的目的是分片计算图为多个子图,以下图为例,分片完整的计算图得到了4个子图。同时,还需将输入集群分片为4个子网,将一个阶段与一个子网匹配。最终使用Pipeline的形式将各个子网之间连接,实现Inter-op Pass。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XjMSd9PV-1664632213483)(https://cdn.jsdelivr.net/gh/Holmes233666/blogImage@main/img/2022/08/16/ab10632076efd34d9ac3efaa5158c84a-image-20220816203850209-6b97a5.png)]
Inter-op Pass的目标是最小化流水延迟。流水线延迟由两项组成,首先是预热阶段,后续是稳定阶段,稳定阶段由最长的流水段决定。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VeW2aENx-1664632213484)(https://cdn.jsdelivr.net/gh/Holmes233666/blogImage@main/img/2022/08/16/a43ef5c8e0722d0f80d2002bdc5e7578-image-20220816204358078-d51904.png)]
减少流水线延迟是通过动态规划算法实现的,动态规划的输出将是一个计算图的划分和设备网分片策略的结果,即流水线的各个段。下面是动态规划的细节说明:
M i n i m i z e P i p e l i n e l a t e n c y T = ∑ i S t i + ( B − 1 ) ⋅ max 1 ≤ j ≤ S { t j } Minimize\ Pipeline\ latency\quad T=\sum_{i}^St_i+(B-1)·\max_{1\leq j\leq S}\{t_j\} Minimize Pipeline latencyT=i∑Sti+(B−1)⋅1≤j≤Smax{tj}
Input:
运行intra-op Pass,分析获得每个阶段的用时 t i = t i n t r a ( ( o p , . . . , o q ) , s u b m e s h ( n , m ) ) t_i=t_{intra}((o_p,...,o_q), submesh(n,m)) ti=tintra((op,...,oq),submesh(n,m))。
Constraint:
(1)将同一阶段的向前传递和向后传递分配到相同的子网中。
基于这个约束,我们假设向后传递的部分是对称的,故只需优化图的向前传递部分。
(2)每个子网可以完全覆盖原始的完整网络。
原始的网络是经过分片的,需要仔细选择子网的形状。有些子网的形状可以保证我们 的集群分片策略是始终有效的,并且可以完整覆盖原始的网络。
Solution:
枚举 max { t j } \max\{t_j\} max{tj}并且将其转换为一个传统的动态规划问题——2维背包问题。
Complexity:
O ( k 5 N M ( N + l o g ( M ) ) ) O(k^5NM(N+log(M))) O(k5NM(N+log(M)))
由于时间复杂度中涉及到 k 5 k^5 k5这样的高阶项,故此动态规划的算法不能应用于大规模的图。为了解决这个问题,论文进行了一个预处理的过程——运行图集群算法,以集群相似的图为一个大的层次。故可减少图中的操作的数量。
以上的说明覆盖了我们去构件Alpa的所有核心的技术。
Alpa 实现
实现时使用JAX作为前端,JAX的一些特点使得能够更简单地构建编译器。例如,可跟踪静态的包括向前传递和向后传递的计算图,优化器更新等,图的提供对于论文的优化是非常必要的。
编程API
论文提供了一个One-Line Auto-ParallelizationAPI,JAX程序如下:
# One-line auto-parallelization:
# Put @parallelize decorator on top of the Jax functions
@parallelize
def train_step(state, batch):def loss_func(params):out = state.forward(params, batch["x"])return jax.numpy.mean((out - batch["y"]) ** 2)
grads = grad(loss_func)(state.params)
new_state = state.apply_gradient(grads)
return new_state
# A typical training loop
state = create_train_state() # 模型的创建
for batch in data_loader: # 从data loader中加载批state = train_step(state, batch) # 梯度下降计算
原始的JAX只是在一个加速器上计算,Alpa突破了这一限制,可以在加速器集群上进行计算。
Note: Alpa的并行化是基于Ray加载处理器和分布式集群,并且使用Ray去检测所有的GPU或者是集群中可用的GPU。
实现细节
Inter-op Pass
基于JAX中间层JAX PR实现。由于在此处我们仍然需要一些机器学习的语义,例如向前传递,向后传递,梯度等。
Intra-op Pass
基于XLA HLO实现。在该部分,不对forward pass和backword pass进行区分。在一个通用的计算图上运行ILP算法。然后使用XLA将策略lower为可执行程序。
Pipeline Excecution
流水线在XLA中是不支持的,故实现时使用自设计的流水指令。
![]()
对于运行时的体系架构,实现时使用XLA综合Ray。对于通信部分,使用Nico构建了一个通信库。
三、评估与总结
评估
Cluster: 8 × A W S p 3.13 8\times AWS\ p3.13 8×AWS p3.13个结点。每个结点总共有8 V100 GPUS。
Models:GPT-3(高达39B),GShard MoE(高达70B),Wide-ResNet(高达13B)
Setting:Weak scaling on model sizes
意为可用GPU的数量越多,那么训练的模型越大;但是论文固定了批处理的大小,输入的数据大小是固定的。即,模型并行化的评估与通常的数据并行化的评估是有所不同的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-erTsWO4h-1664632213485)(https://cdn.jsdelivr.net/gh/Holmes233666/blogImage@main/img/2022/08/16/a294f2265cca64a7d95352f342cd72b8-image-20220816232809663-050ce6.png)]
GPT-3
GPT-3被很多的系统进行了相关的优化。Megatron-LM是一个针对GPT-3训练的系统,同时合并了
Intra和Inter的并行。Alpa可以自动找到Megatron的所有的策略并且达到Megatron的性能。同时编译的时间也是可以接受的。MoE
Megatron是针对于GPT-3的,故无法用其训练MoE。对于MoE目前最优且可行的GPU实现是由Deep Speed实现的。Deep Speed针对MoE做了
Intra和Inter的并行,但是他的性能是无法与流水线并行引擎比拟的。W-ResNet
W-ResNet是一个异质模型,因为在卷积神经网络中,活化的速度变得更慢,同时权重的大小变得更大,对于不同的层次,权重也是不同的,所以针对W-ResNet去人工设计一个策略是比较困难的,目前也没有这样的可行的人工策略。但是Alpa仍可以应用在这种类型的模型上,同时达到一个不错的性能。
总结
- Alpa是一个针对自动分布式系统的新的系统设计
- Alpa构建了一个两层的层次化搜索空间并且在每个层次上寻求最优解
- Alpa可以匹配或者超越专门的系统,泛化到新的模型上
Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning阅读笔记相关推荐
- VVC/VTM:帧间预测——Combined inter and intra prediction (CIIP)
Combined inter and intra prediction (CIIP) CIIP,顾名思义,就是说对编码块进行帧间预测Pred_inter和帧内预测Pred_intra,将两个预测块加权 ...
- H.266/VVC帧间预测技术学习:帧间和帧内联合预测(Combined inter and intra prediction, CIIP)
在HEVC中一个CU在预测时要么使用帧内预测要么使用帧间预测,二者只能取其一.而VVC中提出的CIIP技术,是将帧间预测信号与帧内预测信号相结合. 在VVC中,当CU以Merge模式编码时,且CU包含 ...
- AutoField: Automating Feature Selection in Deep Recommender Systems 阅读笔记
AutoField: Automating Feature Selection in Deep Recommender Systems WWW' 22 摘要 特征质量对推荐性能有重要影响.因此,特征选 ...
- 论文阅读笔记 Sparse Representation-Based Intra Prediction for Lossless/Near Lossless Video Coding
摘要 基于稀疏表征的帧内预测SRIP.在HEVC中有35种角度预测模式AIP,用最相似的相邻像素去表示当前待编码像素.为了编码与解码的一致,角度预测模式的参数要传到解码端,为了进一步提高编码效率,再传 ...
- Deep Tone-Mapping Operator UsingImage Quality Assessment InspiredSemi-Supervised Learning
ABSTRACT 色调映射操作符(TMO)旨在将高动态范围(HDR)内容转换为低动态范围,以便其可以在标准动态范围(SDR)设备上显示. HDR内容的色调映射结果通常存储为SDR图像. 对于不同的HD ...
- 美国南加州大学骆沁毅:构建高性能的异构分布式训练算法
计算机体系结构领域国际顶级会议每次往往仅录用几十篇论文,录用率在20%左右,难度极大.国内学者在顶会上开始发表论文,是最近十几年的事情. ASPLOS与HPCA是计算机体系结构领域的旗舰会议.其中AS ...
- 南加州大学钱学海:去中心化分布式训练系统的最新突破
2020 北京智源大会 本文属于2020北京智源大会嘉宾演讲的整理报道系列.北京智源大会是北京智源人工智能研究院主办的年度国际性人工智能高端学术交流活动,以国际性.权威性.专业性和前瞻性的" ...
- vulkan学习_使用vulkan kompute在gpu中进行机器学习和数据处理
vulkan学习 Machine learning, together with many other advanced data processing paradigms, fits incredi ...
- 大规模神经网络的训练优化入门
作者丨立交桥跳水冠军@知乎(已授权) 来源丨https://zhuanlan.zhihu.com/p/269597841 编辑丨极市平台 之前一段时间接触了大规模神经网络训练,看了不少优秀的工作,在这 ...
最新文章
- 32岁!清华大学博导,国家优秀青年科学基金获得者!
- HTML文件类型定义
- 2005-5-29+ 认识httphandler
- oracle 数字处理函数,Oracle函数-单行函数-数字、日期、日期处理函数
- Adobe Flash地图控件AnyMap
- Python 进阶——重访 list (二)
- K8S 使用 SideCar 模式部署 Filebeat 收集容器日志
- Node.js系列——(4)优势及场景
- PHP面向对象6之工具-魔术方法
- 考研数据结构-二叉树
- com口驱动_四足机器人FOC驱动器篇1:Odrive Moco接口板套件介绍
- IP-Guard清除记录
- 【第六届强网杯CTF-Wp】
- Type interface com.aiit.mapper.BrandMapper is not known to the MapperRegistry.解决办法
- 单周期CPU设计【Verilog】
- scratch3.0键盘无法输入文字或修改指令中的数字的快速解决办法
- PBFT -Golang实现详解
- Cortex-M3内核学习(一)
- matlab计算macd_[原创]基于MATLAB的一个简单的交易策略(基于MACD)的Matlab代码-经管之家官网!...
- 【WSN】基于COMPOW协议下的网络连通率和覆盖率附matlab代码