WKmeans一种基于特征权重的聚类算法
1 引例
在前面两篇文章中,我们首先介绍了KmeansKmeansKmeans聚类算法的原理;然后又介绍了一种基于KmeansKmeansKmeans进行改进的Kmeans++Kmeans++Kmeans++聚类算法,该算法的改进点在于依次初始化KKK个簇中心,最大程度上使得不同的簇中心彼此之间相距较远。而在本篇文章中,我们将继续介绍另外一种基于KmeansKmeansKmeans改进的聚类算法——WKmeansWKmeansWKmeans。那它的改进点又在哪儿呢?
跟我一起机器学习系列文章将首发于公众号:月来客栈,欢迎文末扫码关注!
想象一下这样一个场景,假设现在你手中有一个数据集,里面包含有三个特征维度。但是,对于簇结构起决定性作用的只有其中两个维度,也就是说其中有一个维度是噪音维度。在这种情况下采用KmeansKmeansKmeans聚类算法进行聚类会产生什么样的结果呢?
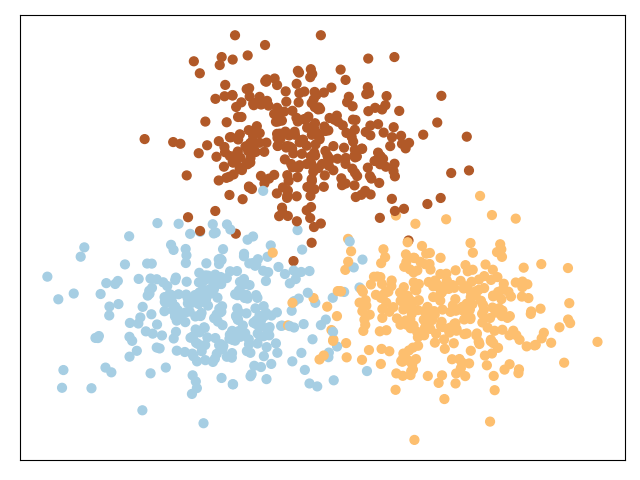
如图所示为正常情况下的一个包含两个特征维度的数据集,从可视化的结果可以看出其有明显的三个簇结构。我们通过Kmeans++Kmeans++Kmeans++算法对其聚类后的NMI结果为0.86(见示例代码)。
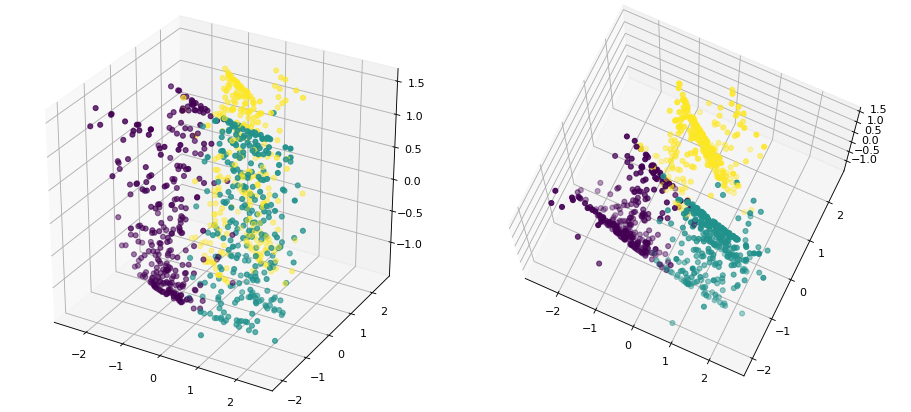
如图所示为上面的数据集加入一个噪音维度后的可视化结果(左右两边为不同视角下的结果)。此时,我们人眼几乎已经无法分辨其中所存在的簇结构了,那通过聚类后的结果如何呢?在我们通过Kmeans++Kmeans++Kmeans++算法对其聚类后发现,其NMI结果已经骤然的下降到了0.66。现在我们想一想为什么混入噪音维度后KmeansKmeansKmeans聚类算法就不怎么管用了呢?
假如现在有两个簇中心c1=[2,3],c2=[3,5]c_1=[2,3],c_2=[3,5]c1=[2,3],c2=[3,5],样本点x=[4,4]x=[4,4]x=[4,4];在这种情况下dxc1=5d_{xc_1}=5dxc1=5大于dxc2=2d_{xc_2}=2dxc2=2,因此样本点xxx应该被划入到簇c2c_2c2中。但如果此时加入一列噪音维度,变成c1=[2,3,2],c2=[3,5,9]c_1=[2,3,2],c_2=[3,5,9]c1=[2,3,2],c2=[3,5,9],样本点变成x=[4,4,1]x=[4,4,1]x=[4,4,1]。那么在这样的情况下dxc1=6d_{xc_1}=6dxc1=6就会小于dxc2=66d_{xc_2}=66dxc2=66,此时xxx就会被错误的划分到簇c1c_1c1中。
我们可以发现,正是由于噪音维度的出现,使得KmeansKmeansKmeans聚类算法在计算样本间的距离时把噪音维度所在的距离也一并的考虑到了结果中,最终导致聚类精度下降。那又没有什么好的办法能够解决这个问题,使得在聚类过程中尽量忽略噪音维度的影响呢?当然有,答案就是给每个特征维度赋予一个权重。
2 加权KMeans聚类算法
加权KmeansKmeansKmeans聚类算法简称为WKmeansWKmeansWKmeans,它出自于2005年的一篇论文,题目是 Automated Variable Weighting in k-Means Type Clustering(公众号回复“论文”)即可获得下载链接[1]。这篇论文的核心思想就是给每个特征维度初始化一个权重值,等到目标函数收敛时,噪音维度所对应的权重就会趋于0,从而使得在计算样本间的距离时能够尽可能的忽略噪音维度的影响。
在上面的例子中,如果上帝给与我们这样一个特征权重W=[w1,w2,w3]=[0.49,0.49,0.02]W=[w_1,w_2,w_3]=[0.49,0.49,0.02]W=[w1,w2,w3]=[0.49,0.49,0.02],并且在计算样本间距离的时候考虑的是加权距离,那么:
dxc1=0.49×(4−2)2+0.49×(4−3)2+0.02×(1−2)2=2.47dxc2=0.49×(4−3)2+0.49×(4−5)2+0.02×(1−9)2=2.26(1)\begin{aligned} d_{xc_1}=0.49\times(4-2)^2+0.49\times(4-3)^2+0.02\times(1-2)^2=2.47\\[2ex] d_{xc_2}=0.49\times(4-3)^2+0.49\times(4-5)^2+0.02\times(1-9)^2=2.26 \end{aligned}\tag{1} dxc1=0.49×(4−2)2+0.49×(4−3)2+0.02×(1−2)2=2.47dxc2=0.49×(4−3)2+0.49×(4−5)2+0.02×(1−9)2=2.26(1)
此时我们发现,在特征权重的作用下,加权后的距离dxc1d_{xc_1}dxc1仍旧大于dxc2d_{xc_2}dxc2,那么xxx依然会被划分到簇c2c_2c2中。因此也就避免了被划分错误的情况。
2.1 WKmeans原理
说了这么久,那么WKmeansWKmeansWKmeans聚类算法是如何实现这么一个想法的呢?如下公式(2)(2)(2)所示便为WKmeansWKmeansWKmeans聚类算法的目标函数:
P(U,Z,W)=∑p=1k∑i=1nuip∑j=1mwjβ(xij−zpj)2(2)P(U,Z,W)=\sum_{p=1}^k\sum_{i=1}^nu_{ip}\sum_{j=1}^mw^{\beta}_j(x_{ij}-z{pj})^2\tag{2} P(U,Z,W)=p=1∑ki=1∑nuipj=1∑mwjβ(xij−zpj)2(2)
服从于约束条件:
∑j=1mwj=1(3)\sum_{j=1}^mw_j=1\tag{3} j=1∑mwj=1(3)
从目标函数(2)(2)(2)可以发现,相较于原始的KmeansKmeansKmeans聚类算法,WKmeansWKmeansWKmeans仅仅只是在目标函数中增加了一个权重参数wjβw^{\beta}_jwjβ。它的作用在于,在最小化整个簇内距离时计算的是每个维度的加权距离和,即通过不同的权重值来调节每个维度对聚类结果的影响。并且,当β=0\beta=0β=0时,目标函数(2)(2)(2)也就退化到了KmeansKmeansKmeans聚类算法的目标函数。
2.2 WKmeans迭代公式
根据目标函数(2)(2)(2)可知,其一共包含有3个需要求解的参数U,Z,WU,Z,WU,Z,W。在这里,我们先直接给出每个参数的一个迭代计算公式,其具体的求解过程在后文再介绍。
簇分配矩阵UUU
uip={1,wjβ∑j=1m(xij−zpj)2≤wjβ∑j=1m(xij−ztj)2,for 1≤t≤k0,otherwise(4)u_{ip}= \begin{cases} 1, & w^{\beta}_j\sum\limits_{j=1}^m(x_{ij}-z_{pj})^2\leq w^{\beta}_j\sum\limits_{j=1}^m(x_{ij}-z_{tj})^2,\;\text{for }1\leq t \leq k\\[1ex] 0, & \text{otherwise} \end{cases}\tag{4} uip=⎩⎨⎧1,0,wjβj=1∑m(xij−zpj)2≤wjβj=1∑m(xij−ztj)2,for 1≤t≤kotherwise(4)簇中心矩阵ZZZ
zpj=∑i=1nuipxij∑i=1nuip(5)z_{pj}=\frac{\sum\limits_{i=1}^nu_{ip}x_{ij}}{\sum\limits_{i=1}^nu_{ip}} \tag{5} zpj=i=1∑nuipi=1∑nuipxij(5)权重矩阵WWW
wj=1∑t=1m[DjDt]1β−1,β>1or β≤0(6)w_j=\frac{1}{\sum\limits_{t=1}^m\left[\frac{D_j}{D_t}\right]^{\frac{1}{\beta-1}}},\;\;\beta>1 \text{ or }\beta\leq0\tag{6} wj=t=1∑m[DtDj]β−111,β>1 or β≤0(6)
其中
Dj=∑p=1k∑i=1nuip(xij−zpj)2(7)D_j=\sum_{p=1}^k\sum_{i=1}^nu_{ip}(x_{ij}-z_{pj})^2\tag{7} Dj=p=1∑ki=1∑nuip(xij−zpj)2(7)
可以看出,DjD_jDj其实就是所有样本点在第jjj个维度上的距离和。
2.3 动手实现
根据前面两篇文章的介绍我们可以发现,对于一个类KmeansKmeansKmeans算法的实现,其实只需实现其对应的迭代更新公式,然后再将其以KmeansKmeansKmeans聚类算法的流程进行调用即可。由于篇幅有限,这里只稍微说一下对于公式(7)(7)(7)的实现,其余部分参见示例代码[2]即可。
def computeWeight(X, centroid, idx, K, belta):n, m = X.shapeweight = np.zeros((1, m), dtype=float)D = np.zeros((1, m), dtype=float)for k in range(K):index = np.where(idx == k)[0]temp = X[index, :] # 取第k个簇的所有样本distance2 = np.power((temp - centroid[k, :]), 2) # ? by mD = D + np.sum(distance2, axis=0)e = 1 / float(belta - 1)for j in range(m):temp = D[0][j] / D[0]weight[0][j] = 1 / np.sum((np.power(temp, e)), axis=0)return weight
我们在编码实现的时候,都是以向量的形式进行的。例如导入第三行代码中,D[0]为一个向量,其中的每个值分别表示对应维度的距离和;np.power(temp,e)计算的就是公式(6)(6)(6)中分母在每个维度的值,然后再通过np.sum()进行累加求和。
下面我们再通过WKmeansWKmeansWKmeans来对包含有噪音维度的数据集进行聚类:
if __name__ == '__main__':x, y, x_noise = make_data()y_pred = wkmeans(x, 3, belta=3)nmi = normalized_mutual_info_score(y, y_pred)print("NMI without noise: ", nmi)y_pred = wkmeans(x_noise, 3,belta=3)nmi = normalized_mutual_info_score(y, y_pred)print("NMI with noise by ours: ", nmi)
#结果
NMI without noise: 0.867939056164429
NMI with noise: 0.852210021893048
从最后的结果来看,WKmeansWKmeansWKmeans在不含有噪音维度以及含有噪音维度的数据集上的NMI指标分别为0.86和0.85,可以发现两者在结果上几乎相差无几。同时,对比于KmeansKmeansKmeans聚类得到的结果,WKmeansWKmeansWKmeans在处理这类包含有噪音维度的数据集中,有着明显的优势。另外值得一说的是,数据集iris的前两个特征维度基本上也算得上是噪音维度,经WKmeansWKmeansWKmeans和KmeansKmeansKmeans聚类后[3],其NMI指标分别为0.81和0.75,也有着明显的提升。
2.4 参数求解
在这一小节中,我们再来稍微介绍一下参数WWW的求解过程,其余部分参见原论文即可。通常,对于KmeansKmeansKmeans框架下的聚类算法,其参数哦求解过程都是依赖于拉格朗日乘数法。因此,根据式子(2)(3)(7)(2)(3)(7)(2)(3)(7)我们便能得到如下拉格朗日函数:
Φ(W,α)=∑j=1mwjβDj+α(∑j=1mwj−1)(8)\Phi(W,\alpha)=\sum_{j=1}^mw^{\beta}_jD_j+\alpha\left(\sum_{j=1}^mw_j-1\right) \tag{8} Φ(W,α)=j=1∑mwjβDj+α(j=1∑mwj−1)(8)
接着分别对W,αW,\alphaW,α求导并令其为0可得:
∂Φ∂wj=βwjβ−1Dj+α=0(9)\frac{\partial \Phi}{\partial w_j}=\beta w^{\beta-1}_jD_j+\alpha=0\\ \tag{9} ∂wj∂Φ=βwjβ−1Dj+α=0(9)
∂Φ∂α=∑j=1mwj−1=0(10)\frac{\partial \Phi}{\partial \alpha}=\sum_{j=1}^mw_j-1=0\tag{10} ∂α∂Φ=j=1∑mwj−1=0(10)
根据式子(9)(9)(9)可得:
wj=(−αβDj)1β−1(11)w_j=\left(\frac{-\alpha}{\beta D_j}\right)^{\frac{1}{\beta-1}}\tag{11} wj=(βDj−α)β−11(11)
将(11)(11)(11)代入(10)(10)(10)得:
∑j=1m(−αβDj)1β−1=1(12)\sum_{j=1}^m\left(\frac{-\alpha}{\beta D_j}\right)^{\frac{1}{\beta-1}}=1\tag{12} j=1∑m(βDj−α)β−11=1(12)
根据(12)(12)(12)有:
(−α)1β−1=1/[∑t=1m(1βDt)1β−1](13)(-\alpha)^{\frac{1}{\beta-1}}=1/\left[\sum_{t=1}^m\left(\frac{1}{\beta D_t}\right)^{\frac{1}{\beta-1}}\right]\tag{13} (−α)β−11=1/[t=1∑m(βDt1)β−11](13)
将(13)(13)(13)代入(11)(11)(11)即可得到:
wj=1(βDj)1β−1∑t=1m(1βDt)1β−1=1(Dj)1β−1∑t=1m(1Dt)1β−1=1∑t=1m(DjDt)1β−1(14)\begin{aligned} w_j=&\frac{1}{(\beta D_j)^{\frac{1}{\beta-1}}\sum\limits_{t=1}^m\left(\frac{1}{\beta D_t}\right)^{\frac{1}{\beta-1}}}\\[2ex] =&\frac{1}{(D_j)^{\frac{1}{\beta-1}}\sum\limits_{t=1}^m\left(\frac{1}{D_t}\right)^{\frac{1}{\beta-1}}}\\[2ex] =&\frac{1}{\sum\limits_{t=1}^m\left(\frac{D_j}{D_t}\right)^{\frac{1}{\beta-1}}} \end{aligned}\tag{14} wj===(βDj)β−11t=1∑m(βDt1)β−111(Dj)β−11t=1∑m(Dt1)β−111t=1∑m(DtDj)β−111(14)
由此我们便得到了WWW的迭代计算公式,同时对于β\betaβ的取值研究直接参数原论文即可,在这里就不再叙述。
3 总结
在本篇文章中,笔者首先通过一个引例来介绍了什么是含有噪音维度的数据集;然后介绍了为什么加入噪音维度后KMeansKMeansKMeans聚类算法的精度就会下降,由此引入了基于权重的WKmeansWKmeansWKmeans聚类算法;最后介绍了WKmeansWKmeansWKmeans聚类算法的原理、实现以及权重WWW的求解过程。本次内容就到此结束,感谢阅读!
若有任何疑问与见解,请发邮件至moon-hotel@hotmail.com并附上文章链接,青山不改,绿水长流,月来客栈见!
引用
[1]Automated Variable Weighting in k-Means Type Clustering 公众号回复“论文”即可获得下载链接
[2]示例代码 : https://github.com/moon-hotel/MachineLearningWithMe
[3]WKmeans: https://github.com/moon-hotel/WKmeans
推荐阅读
[1]Kmeans聚类算法
[2]Kmeans++聚类算法
[3]聚类评估指标

WKmeans一种基于特征权重的聚类算法相关推荐
- fcm算法c语言实现,基于特征权重的FCM算法研究及应用
摘要: 模糊C-均值(FCM)聚类算法是非监督模式识别中应用范围最广泛的算法之一.但是传统的FCM算法中,设定样本的各维特征对分类效果的贡献水平是相同的.在实际中,由于特征提取不够完善,使得特征矢量中 ...
- 基于改进层次凝聚聚类算法的垃圾收运跨区域调度策略
1引言: 垃圾收运的各个环节是控制垃圾回收成本的关键,当前分区域运营模式存在以下问题: 运营成本高:分区域运营模式限制了城市生活垃圾收集和运输的各个环节.从一个区域的特定街道收集的垃圾只能在该区域街道 ...
- 基于GPU的K-Means聚类算法
聚类是信息检索.数据挖掘中的一类重要技术,是分析数据并从中发现有用信息的一种有效手段.它将数据对象分组成为多个类或簇,使得在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别很大.作为统计学的 ...
- [Python从零到壹] 六十一.图像识别及经典案例篇之基于纹理背景和聚类算法的图像分割
祝大家新年快乐,阖家幸福,健康快乐! 欢迎大家来到"Python从零到壹",在这里我将分享约200篇Python系列文章,带大家一起去学习和玩耍,看看Python这个有趣的世界.所 ...
- 一种基于傅里叶变换的相位配准算法phase correlation approach,利用互功率谱得到时空的平移。
一种基于傅里叶变换的相位配准算法phase correlation approach Reddy BS, Chatterji BN. An FFT-based technique for transl ...
- Java实现的基于欧式距离的聚类算法的Kmeans作业
Kmeans作业 环境配置 java环境,使用原生的Java UI组件JPanel和JFrame 算法原理 基于欧式距离的聚类算法,其认为两个目标的距离越近,相似度越大. 该实验产生的点为二维空间中的 ...
- faiss之特征检索与聚类算法
特征检索与聚类算法 核心逻辑: 如何得到数字特征 如何对目标进行召回和排序 相关算法 Tree-based FLANN Annoy Quantization-based Faiss Graph-bas ...
- 聚类——基于距离阈值的聚类算法
基于距离阈值的聚类算法 1.最大最小距离算法 算法思想 对待分类模式样本集以最大距离选取新的聚类中心,以最小距离原则进行模式归类. 算法步骤 从N个样本集中的任选取一个样本,作为第一个聚类中心 z 1 ...
- Structural Deep Clustering Network 基于GNN的深度聚类算法 WWW2020
论文链接:https://arxiv.org/abs/2002.01633 代码与数据集链接:https://github.com/lxk-yb/SDCN 摘要 聚类是数据分析中一个基础任务.最近,深 ...
最新文章
- 最高奖金5万|带打目标检测大赛!还给匹配神助攻队友!
- ubuntu 12.04 配置vsftpd 服务,添加虚拟用户,ssl加密
- sql 除法_七天学会SQL-04SQL复杂查询
- Java 包装类 自动装箱和拆箱
- 【BZOJ4008】亚瑟王,概率DP
- Zookeeper(三)——选举机制
- Linux stat命令和AIX istat命令 (查看文件修改时间)
- Visual Studio 单元测试之六---UI界面测试
- 转:libatk-bridge.so错误解决
- String或Integer补0操作
- (xsinx)/(1+(cosx)^2)在0到π上的定积分
- 音视频技术开发周刊 | 243
- LSD算法与LBD描述子的关系
- 深圳盛世光影简述影视后期制作包括哪些工作?
- SSD(Single Shot MultiBox Detector)不得不说的那些事
- openstack上传镜像
- 计算多个不同鞋码对应的脚长——C语言
- buu刷题记录 [PWNHUB 公开赛 2018]傻 fufu 的工作日
- 【12c】扩展数据类型(Extended Data Types)-- MAX_STRING_SIZE
- uni-app 二维码扫描识别功能
热门文章
- O365 Multi-Geo测试报告
- 进化计算(十)——MFEA算法详解Ⅰ
- java计算机毕业设计vue校园菜鸟驿站管理系统源码+数据库+系统+lw文档
- 基于javaweb+mysql的网上图书商城网上书店(java+SSM+Jsp+MySQL+Redis+JWT+Shiro+RabbitMQ+EasyUI)
- 照做的话,发不了SCI论文你来找我
- net.sf.jasperreports.engine.util.JRFontNotFoundException: Font 华文宋体 is not available to the JVM. S
- 前端学PHP之会话Session
- 2020/第十一届蓝桥杯国赛/Java-A
- 光学相控阵技术能否用于生物雷达
- 2021-12-20 WPF上位机 121-三菱PLC协议读写代码的封装