《Python自然语言处理》——第1章 语言处理与Python 1.1 语言计算:文本和词汇...
本节书摘来自异步社区《Python自然语言处理》一书中的第1章,第1.1节,作者[美]Steven Bird,Ewan Klein,Edward Loper, 陈涛,张旭,崔杨,刘海平 译,更多章节内容可以访问云栖社区“异步社区”公众号查看。
第1章 语言处理与Python
我们能够很容易地得到数百万数量级的文本。假设我们会写一些简单的程序,那可以用它来做些什么?本章将解决以下几个问题。
(1)通过将技术性较简单的程序与大规模文本结合起来,我们能实现什么?
(2)如何自动地提取出关键字和词组,用来总结文本的风格和内容?
(3)Python编程语言为上述工作提供了哪些工具和技术?
(4)自然语言处理中有哪些有趣的挑战呢?
本章分为风格完全不同的两部分。在1.1节,我们将进行一些与语言相关的编程练习而不去解释它们是如何实现的。在1.2节,我们将系统地回顾关键的编程概念。我们使用章节标题来区分这两种风格,而后面几章则不像前面一样,是将两种风格混合在一起,不作明显的区分。我们希望这种介绍风格能使你对将要出现的内容有一个真实的体会,与此同时,介绍中还涵盖了语言学与计算机科学的基本概念。如果你对这两个方面已经有了基本的了解,可以直接从1.5节开始学习。我们将在后续的章节中重复所有要点,如果错过了什么,你可以很容易地在http://www.nltk.org/ 上查询在线参考材料。如果这些材料对你而言是全新的,那么本章所提出的问题比它还要多,这些问题将在本书的其余部分中进行讨论。
1.1 语言计算:文本和词汇
我们都对文本非常熟悉,因为我们每天都在进行阅读和写作。在本书中,把文本视为编写程序的原始数据,并通过很多有趣的编程方式来处理和分析文本。但在能写这些程序之前,必须得从了解Python解释器开始。
Python入门
Python与用户友好交互的方式之一包括你可以在交互式解释器直接输入代码——解释器将运行你的Python代码的程序。你可以通过一个叫做交互式开发环境(Interactive Development Environment,IDLE)的简单图形接口来访问Python解释器。在Mac上,你可以在“Applications→MacPython”中找到;在Windows中,你可以在“程序→Python”中找到。在UNIX下,你可以在shell输入“idle”来运行Python(如果没有安装,尝试输入python)。解释器将会输入关于你的Python的版本简介,请检查你是否运行在Python 2.4或2.5(这里是2.5.1)。
Python 2.5.1 (r251:54863, Apr 15 2008, 22:57:26)
[GCC 4.0.1 (Apple Inc. build 5465)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>提示如果你无法运行Python解释器,可能是由于没有正确安装Python。请访问http://python.org/查阅详细操作说明。
提示符>>>表示Python解释器正在等待输入。复制这本书的例子时,自己不要键入>>>。现在,把Python当作计算器使用。
>>> 1 + 5 * 2 - 3
8
>>>一旦解释器完成计算并显示出答案,提示符就会重新出现。这表示Python解释器在等待另一个指令。
提示 轮到你来输入几个自己的表达式。可以使用星号(*)表示乘法,左斜线表示除法,可以用括号括起表达式。请注意:除法并不总是像你期望的那样。当输入1/3时,是整数除法(小数会被四舍五入),当输入1.0/3.0时,是“浮点数”(或十进制)除法。要想获得通常平时期望的除法(在Python3.0中的标准),需要输入:from __future__import division。
前面的例子展示了如何使用Python交互式解释器,体验Python语言中各种表达式,看看它们能做些什么。现在让我们尝试一个无意义的表达式,看看解释器将如何处理。
>>> 1 + File "<stdin>", line 11 +^SyntaxError: invalid syntax>>>结果产生了一个语法错误。在Python中,指令以加号结尾是没有意义的。Python解释器会指出发生错误的行(的第1行,表示“标准输入”)。
现在我们学会使用Python解释器了,已经准备好开始处理语言数据了。
NLTK入门
首先应该安装NLTK,可以从http://www.nltk.org/ 上免费下载。按照说明下载适合你的操作系统的版本。
一旦安装完成,便可像前面那样启动Python解释器。在Python提示符后面输入下面两行命令来安装本书所需的数据,然后选择book,如图1-1所示。
>>> import nltk
>>> nltk.download()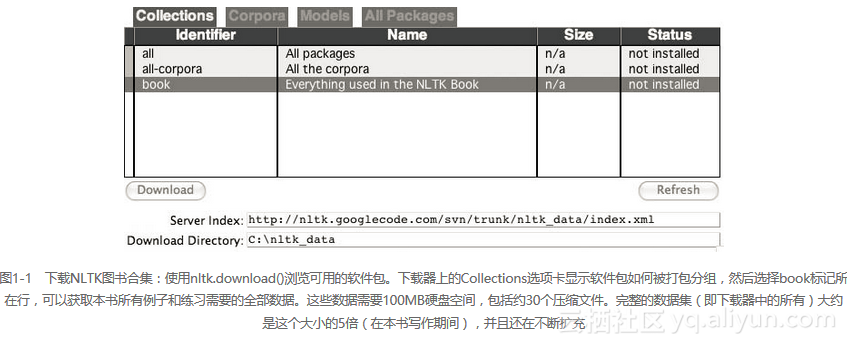
一旦数据被下载到你的机器,你就可以使用Python解释器加载其中的一些了。第一步是在Python提示符后输入一个特殊的命令,告诉解释器去加载一些我们要用的文本:from nltk.book import * 。这条语句是说“从NLTK的book模块中加载所有的条目”。book模块包含你阅读本章时所需的所有数据。在输出欢迎信息之后,将会加载一些书的文本(这将需要几秒钟)。下面就是你需要输入的命令及输出的结果,注意拼写和标点符号的正确性,记住不要输入>>>。
>>> from nltk.book import *
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908
>>>无论什么时候想要找到这些文本,只需要在Python提示符后输入它们的名字即可。
>>> text1
<Text: Moby Dick by Herman Melville 1851>
>>> text2
<Text: Sense and Sensibility by Jane Austen 1811>
>>>现在我们可以使用Python解释器和这些数据,准备开始了。
搜索文本
除了简单地阅读文本之外,还有很多方法可以用来查看文本内容。词语索引视图可以显示指定单词的出现情况,同时还可以显示一些上下文。下面我们输入text1并在后面跟一个点,再输入函数名concordance,然后将monstrous放在括号里,用来查找《白鲸记》中的词monstrous。
>>> text1.concordance("monstrous")
Building index...
Displaying 11 of 11 matches:
ong the former , one was of a most monstrous size . ...This came towards us ,
ON OF THE PSALMS . " Touching that monstrous bulk of the whale or ork we have r
ll over with a heathenish array of monstrous clubs and spears . Some were thick
d as you gazed , and wondered what monstrous cannibal and savage could ever hav
that has survived the flood ; most monstrous and most mountainous ! That Himm
they might scout at Moby Dick as a monstrous fable , or still worse and more de
h of Radney .'" CHAPTER 55 Of the monstrous Pictures of Whales . I shall ere l
ing Scenes . In connexion with the monstrous pictures of whales , I am strongly
ere to enter upon those still more monstrous stories of them which are to be fo
ght have been rummaged out of this monstrous cabinet there is no telling . But
of Whale - Bones ; for Whales of a monstrous size are oftentimes cast up dead u
>>>提示 轮到你来尝试搜索其他词。为了方便重复输入,你也许会用到上箭头、Ctrl-↑或者Alt-p以获取之前输入的命令,然后修改要搜索的词。你也可以尝试搜索已经列入的其他文本。例如:使用text2.concordance("affection")搜索《理智与情感》中的词affection;使用text3.concordance("lived")搜索《创世纪》找出某人活了多久;你也可以看看text4,《就职演说语料》,回到1789年去看看那时英语使用的例子,并且搜索如nation, terror, god这样的词,看看随着时间的推移这些词的使用有何不同;同样还有text5,《NPS聊天语料库》,你可以在里面搜索一些网络用语,如im, ur, lol。(注意这个语料库是未经审查的!)
通过一段时间对这些文本的研究,我们希望你能对语言的丰富性和多样性有一个新的认识。在下一章中,你将学习如何获取更广泛的文本,包括英语以外其他语言的文本。
关键词索引让我们可以看到上下文中的词。例如:我们看到monstrous出现在文章中,如the___pictures和the____ size。还有哪些词出现在相似的上下文中?我们可以通过在被查询的文本名后添加函数名similar,然后在括号中插入相关词的方法来查找到。
>>> text1.similar("monstrous")
Building word-context index...
subtly impalpable pitiable curious imperial perilous trustworthy
abundant untoward singular lamentable few maddens horrible loving lazy
mystifying christian exasperate puzzled
>>> text2.similar("monstrous")
Building word-context index...
very exceedingly so heartily a great good amazingly as sweet
remarkably extremely vast
>>>可以发现从不同的文本中能够得到不同的结果。Austen(奥斯丁,英国女小说家)在词汇的使用上与Melville完全不同。对于她来说,monstrous是正面的意思,有时它的功能像词very一样用作强调成分。
我们可以使用函数common_contexts研究共用两个或两个以上词汇的上下文,如monstrous和very。使用方括号和圆括号将这些词括起来,中间用逗号分割。
>>> text2.common_contexts(["monstrous", "very"])
be_glad am_glad a_pretty is_pretty a_lucky
>>>>提示 轮到你来:挑选另一对词,使用similar()和common_contexts()函数比较它们在两个不同文本中的用法。
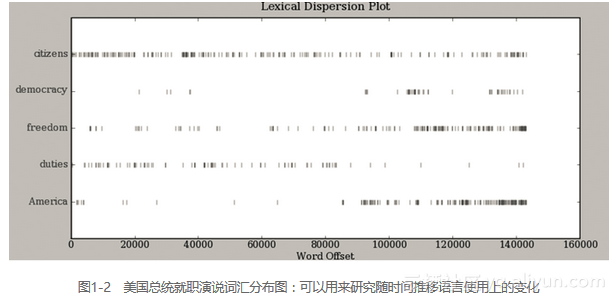
自动检测出现在文本中的特定的词,并显示同一上下文中出现的其他词。我们也可以判断词在文本中的位置:从文本开头算起有多少词出现。这个位置信息可以用离散图表示。每一列代表一个单词,每一行代表整个文本。在图1-2中,我们看到在过去220年中的一些显著的词语用法模式(在一个由就职演说语料首尾相连组合的人工文本中)。可以利用下面的方法画出离散图。你也许会想尝试更多的单词(如:liberty,constitution)和不同的文本。你能在看到这幅图之前预测一个单词的分布吗?如前所述,保证引号、逗号、中括号及小括号的使用完全正确。
>>> text4.dispersion_plot(["citizens", "democracy", "freedom", "duties", "America"])
>>>
提示 重要事项:为了画出本书中用到的图形,你需要安装Python的NumPy和Matplotlib程序包。请参阅http://www.nltk.org/上的安装说明。
现在轻松一下,尝试以上述不同风格产生一些随机文本。要做到这一点,我们需要输入后面跟着函数名generate的文本名称。(需要带括号,但括号里什么也没有。)
>>> text3.generate()
In the beginning of his brother is a hairy man , whose top may reach
unto heaven ; and ye shall sow the land of Egypt there was no bread in
all that he was taken out of the month , upon the earth . So shall thy
wages be ? And they made their father ; and Isaac was old , and kissed
him : and Laban with his cattle in the midst of the hands of Esau thy
first born , and Phichol the chief butler unto his son Isaac , she
>>>请注意,第一次运行此命令时,由于要搜集单词序列的统计信息,因而执行速度比较慢。每次运行后,输出的文本都会不同。现在尝试产生就职演说风格或互联网聊天室风格的随机文本。虽然文本是随机的,但它重复使用了源文本中常见的单词和短语,从而使我们能感觉到它的风格和内容。
提示在generate产生输出时,标点符号与前面的单词分开。虽然这不是正确的英文格式,但我们之所以这么做是为了确保文字和标点符号是彼此独立的。更多关于这方面的内容将在第3章学习。
计数词汇
在前面例子中出现的文本中,最明显的地方在于它们所使用的词汇不同。在本节中,我们将看到如何使用计算机并以各种有用的方式来计数词汇。像以前一样,你可以马上开始使用Python解释器进行试验,即使你可能还没有系统地研究过Python。修改这些例子并测试一下你对它们的理解程度,尝试一下本章结尾的练习题。
首先,让以文本中出现的单词和标点符号为单位算出文本从头到尾的长度。使用函数len获取长度,参考《创世纪》中使用的例子。
>>> len(text3)
44764
>>>《创世纪》有44764个单词和标点符号,也被称作“标识符”。标识符是表示一组字符序列——如:hairy、his或者:)——的术语。当计算文本中标识符的个数时,如to be or not to be这句话,我们计算的是这些序列出现的次数。因此,例句中出现了to和be各两次,or和not各一次。然而在例句中只有4个不同的单词。《创世纪》中有多少不同的单词?如果要用Python来回答这个问题,就不得不稍微改变一下提出的问题。因为一个文本词汇表只是它用到的标识符的集合,在集合中所有重复的元素都只算一个。在Python中可以使用命令:set(text3)来获得text3的词汇表。这样做之后,屏幕上的很多词就会被掠过。现在尝试以下操作。
>>> sorted(set(text3)) ①
['!', "'", '(', ')', ',', ',)', '.', '.)', ':', ';', ';)', '?', '?)',
'A', 'Abel', 'Abelmizraim', 'Abidah', 'Abide', 'Abimael', 'Abimelech',
'Abr', 'Abrah', 'Abraham', 'Abram', 'Accad', 'Achbor', 'Adah', ...]
>>> len(set(text3)) ②
2789
>>>用sorted()包裹Python表达式set(text3)①,得到一个词汇条目的排序表,这个表以各种标点符号开始,然后接着是以A开头的词汇。大写单词排在小写单词前面。通过求集合中项目的个数,可以间接地获得词汇表的大小。再次使用命令len来获得这个数值②。尽管书中有44764个标识符,但只有2789个不同的词汇或“词类型”。词类型是指一个词在一个文本中独一无二的出现或拼写形式。也就是说,这个单词在词汇表中是唯一的。计数的2789个项目中包括标点符号,所以把它们称作唯一项目类型而不是词类型。
现在,开始对文本词汇丰富度进行测量。下面的例子展示的结果含义为每个词平均被使用了16次(应该确保Python使用的是浮点除法)。
>>> from __future__ import division
>>> len(text3) / len(set(text3))
16.05 0197203298673
>>>接下来,专注于特定的词。计数一个单词在文本中出现的次数,再计算一个特定词在文本中占据的百分比。
>>> text3.count("smote")
5
>>> 100 * text4.count('a') / len(text4)
1.46 43016433938312
>>>提示 轮到你来:text5中lol出现了多少次?它占文本全部词数的百分比是多少?
也许你想要对几个文本重复进行这些计算,但重新输入公式是很乏味的。方法是可以自己命名一个任务,如“lexical_diversity”或“percentage”,然后用一个代码块关联它。这样,你只需输入一个很短的名字就可以代替一行或多行Python代码,而且想用多少次就用多少次。执行一个任务的代码段叫做函数。使用关键字def给函数定义一个简短的名字。下面的例子演示的是如何定义两个新的函数,lexical_diversity()和percentage()。
>>> def lexical_diversity(text): 1
... return len(text) / len(set(text)) 2
...
>>> def percentage(count, total): 3
... return 100 * count / total
...注意!当遇到第一行末尾的冒号时,Python解释器提示符由>>>变为...。...提示符表示Python期望的是在后面出现一个缩进代码块。缩进由你决定只需输入4个空格或是敲击Tab键。要结束一个缩进代码段,只需输入一个空行。
在lexical_diversity()1的定义中,指定了一个text参数。这个参数是计算文本词汇多样性时的一个“占位符”,并在使用函数时,重现在运行的代码段中2。类似地,percentage()3定义了两个参数:count和total。
只要Python知道了lexical_diversity()和percentage()是指定代码段的名字,我们就可以继续使用这些函数了。
>>> lexical_diversity(text3)
16.05 0197203298673
>>> lexical_diversity(text5)
7.42 00461589185629
>>> percentage(4, 5)
80.0
>>> percentage(text4.count('a'), len(text4))
1.46 43016433938312
>>>简要重述一下,使用或者说是调用一个如lexical_diversity()这样的函数时,只要输入它的名字并在后面跟一个左括号,再输入文本名字,然后是右括号即可。这些括号经常出现,它们的作用是将任务名——如:lexical_diversity()——与任务将要处理的数据——如:text3分割开。调用函数时放在参数位置的数据值叫做函数的实参。
在本章中,你已经遇到了一些函数,如:len(),set()和sorted()。通常会在函数名后面加一对空括号,例如len(),这只是为了表明这是一个函数而不是其他的Python表达式。函数是编程中的一个重要概念,我们只是在一开始提到了它们,为了是让新手体会到编程的强大和它的创造力。如果你现在觉得有点混乱,请不要担心。
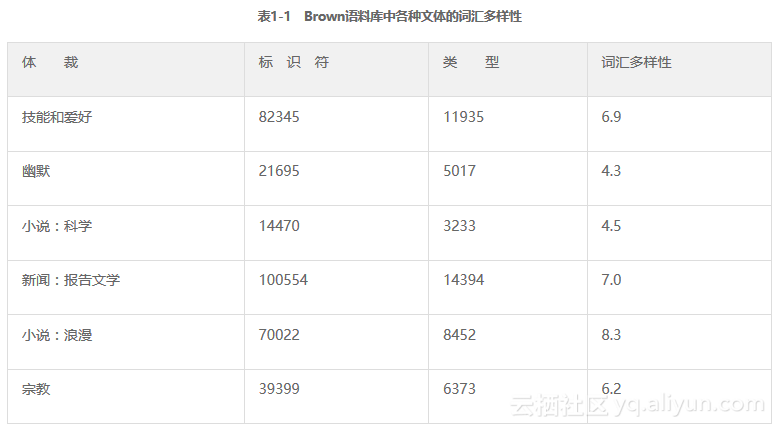
稍后将学习如何使用函数列表显示数据,见表1-1。表中每一行包含了不同数据相同的计算,将使用函数进行这种重复性的工作。
《Python自然语言处理》——第1章 语言处理与Python 1.1 语言计算:文本和词汇...相关推荐
- Python是什么?Python能干什么?一篇文章让你对Python了如指掌!!
Python作为当下最热门的编程语言,在2020年世界脚本语言排行榜中位列榜首,已经成为了多个领域的首选语言. 能用到Python 的地方非常多.从入门级小白到专业级的大佬,数据挖掘.科学计算.图像处 ...
- python网络爬虫_一篇文章教会你利用Python网络爬虫获取穷游攻略
点击上方"IT共享之家",进行关注 回复"资料"可获赠Python学习福利 [一.项目背景] 穷游网提供原创实用的出境游旅行指南.攻略,旅行社区和问答交流平台, ...
- 《Python分布式计算》 第5章 云平台部署Python (Distributed Computing with Python)
序言 第1章 并行和分布式计算介绍 第2章 异步编程 第3章 Python的并行计算 第4章 Celery分布式应用 第5章 云平台部署Python 第6章 超级计算机群使用Python 第7章 测试 ...
- python自然语言分析 何翠仪_如何用 Python 中的 NLTK 对中文进行分析和处理?
最近正在用nltk 对中文网络商品评论进行褒贬情感分类,计算评论的信息熵(entropy).互信息(point mutual information)和困惑值(perplexity)等(不过这些概念我 ...
- 《Python自然语言处理》第二章 习题解答 练习6
问题描述:在比较词表的讨论中,创建一个对象叫做translate,通过它你可以使用德语和意大利语词汇查找对应的英语词汇.这种方法可能会出现什么问题,你能提出一个办法来避免这个问题吗? 书上的做法是通过 ...
- 《Python自然语言处理》第一章学习笔记
#安装nltk等包直接用pip #>>> 表示Python解释器正在等待输入 #Python IDLE Python本身计算器使用 #导入包和模块 from nltk.book im ...
- python基础课程第12章_流畅的python学习笔记-第12章
第12章-类继承 super函数 Py 2.x 和 Py 3.x 中有一个很大的区别就是类,无论是类的定义还是类的继承. Py 3.x 中类的继承可以直接使用 super() 关键字代替原来的 sup ...
- 萌新向Python数据分析及数据挖掘 第二章 pandas 第二节 Python Language Basics, IPython, and Jupyter Notebooks...
Python Language Basics, IPython, and Jupyter Notebooks In [5]: import numpy as np #导入numpy np.random ...
- Python金融数据挖掘 第7章 第3节 (7) 案例:基于股评文本的情绪分析
1.特征词 表示一篇文本,矩阵数据,聚类.分类.预测 2.情绪.情感分析 情感值.舆论文本.文本数据,来源管,新闻.情感倾向:存在误差,不准确 3.基于股评文本的情绪分析 #网络舆情,判断指数走向 3 ...
- python字节流处理_一篇文章带你剖析Python 字节流处理神器struct
点击上方"Python爬虫与数据挖掘",进行关注 回复"书籍"即可获赠Python从入门到进阶共10本电子书 今 日 鸡 汤 仰天大笑出门去,我辈岂是蓬蒿人. ...
最新文章
- 注册报名丨2021 SLT CSRC 研讨会开幕在即,有哪些看点值得关注?
- 成功人士具备的20个习惯(转载)
- spring学习(47):bean的作用域
- CSS3新增-属性(长度颜色背景)选择器-盒子模型
- java 端口转发_用Java快速实现端口转发
- 【Unity】制作简易三维场景
- php本地打开pdf文件_用PHP在web浏览器中打开PDF文件的方法
- 左耳朵谈个人成长:做正确的事,等着被开除
- 教程 |「川言川语」:用神经网络RNN模仿特朗普的语言风格
- bios 刷 灵耀14_华硕灵耀Deluxe14笔记本装win10及bios设置教程(uefi+gpt)
- matlab 之 图中/坐标的线型、颜色、线宽
- 百度地图电子围栏判断
- 2016年8月9日 星期二 --出埃及记 Exodus 16:9
- IP Camera采集方案
- 怎样煮鸡蛋才能让鸡蛋熟且不破
- Windowns 离线安装WSL2
- 广州市博士后研究员系列职称评审及认定
- 基于kvn虚拟化服务器实现drbd高可用方案
- RIFD 的三大标准协议
- ADS6445开发笔记(1)---- 芯片介绍