python应用中调用spark_在python中使用pyspark读写Hive数据操作
1、读Hive表数据
pyspark读取hive数据非常简单,因为它有专门的接口来读取,完全不需要像hbase那样,需要做很多配置,pyspark提供的操作hive的接口,使得程序可以直接使用SQL语句从hive里面查询需要的数据,代码如下:
from pyspark.sql import HiveContext,SparkSession
_SPARK_HOST = "spark://spark-master:7077"
_APP_NAME = "test"
spark_session = SparkSession.builder.master(_SPARK_HOST).appName(_APP_NAME).getOrCreate()
hive_context= HiveContext(spark_session )
# 生成查询的SQL语句,这个跟hive的查询语句一样,所以也可以加where等条件语句
hive_database = "database1"
hive_table = "test"
hive_read = "select * from {}.{}".format(hive_database, hive_table)
# 通过SQL语句在hive中查询的数据直接是dataframe的形式
read_df = hive_context.sql(hive_read)
2 、将数据写入hive表
pyspark写hive表有两种方式:
(1)通过SQL语句生成表
from pyspark.sql import SparkSession, HiveContext
_SPARK_HOST = "spark://spark-master:7077"
_APP_NAME = "test"
spark = SparkSession.builder.master(_SPARK_HOST).appName(_APP_NAME).getOrCreate()
data = [
(1,"3","145"),
(1,"4","146"),
(1,"5","25"),
(1,"6","26"),
(2,"32","32"),
(2,"8","134"),
(2,"8","134"),
(2,"9","137")
]
df = spark.createDataFrame(data, ['id', "test_id", 'camera_id'])
# method one,default是默认数据库的名字,write_test 是要写到default中数据表的名字
df.registerTempTable('test_hive')
sqlContext.sql("create table default.write_test select * from test_hive")
(2)saveastable的方式
# method two
# "overwrite"是重写表的模式,如果表存在,就覆盖掉原始数据,如果不存在就重新生成一张表
# mode("append")是在原有表的基础上进行添加数据
df.write.format("hive").mode("overwrite").saveAsTable('default.write_test')
tips:
spark用上面几种方式读写hive时,需要在提交任务时加上相应的配置,不然会报错:
spark-submit --conf spark.sql.catalogImplementation=hive test.py
补充知识:PySpark基于SHC框架读取HBase数据并转成DataFrame
一、首先需要将HBase目录lib下的jar包以及SHC的jar包复制到所有节点的Spark目录lib下
二、修改spark-defaults.conf 在spark.driver.extraClassPath和spark.executor.extraClassPath把上述jar包所在路径加进去
三、重启集群
四、代码
#/usr/bin/python
#-*- coding:utf-8 –*-
from pyspark import SparkContext
from pyspark.sql import SQLContext,HiveContext,SparkSession
from pyspark.sql.types import Row,StringType,StructField,StringType,IntegerType
from pyspark.sql.dataframe import DataFrame
sc = SparkContext(appName="pyspark_hbase")
sql_sc = SQLContext(sc)
dep = "org.apache.spark.sql.execution.datasources.hbase"
#定义schema
catalog = """{
"table":{"namespace":"default", "name":"teacher"},
"rowkey":"key",
"columns":{
"id":{"cf":"rowkey", "col":"key", "type":"string"},
"name":{"cf":"teacherInfo", "col":"name", "type":"string"},
"age":{"cf":"teacherInfo", "col":"age", "type":"string"},
"gender":{"cf":"teacherInfo", "col":"gender","type":"string"},
"cat":{"cf":"teacherInfo", "col":"cat","type":"string"},
"tag":{"cf":"teacherInfo", "col":"tag", "type":"string"},
"level":{"cf":"teacherInfo", "col":"level","type":"string"} }
}"""
df = sql_sc.read.options(catalog = catalog).format(dep).load()
print ('***************************************************************')
print ('***************************************************************')
print ('***************************************************************')
df.show()
print ('***************************************************************')
print ('***************************************************************')
print ('***************************************************************')
sc.stop()
五、解释
数据来源参考请本人之前的文章,在此不做赘述
schema定义参考如图:
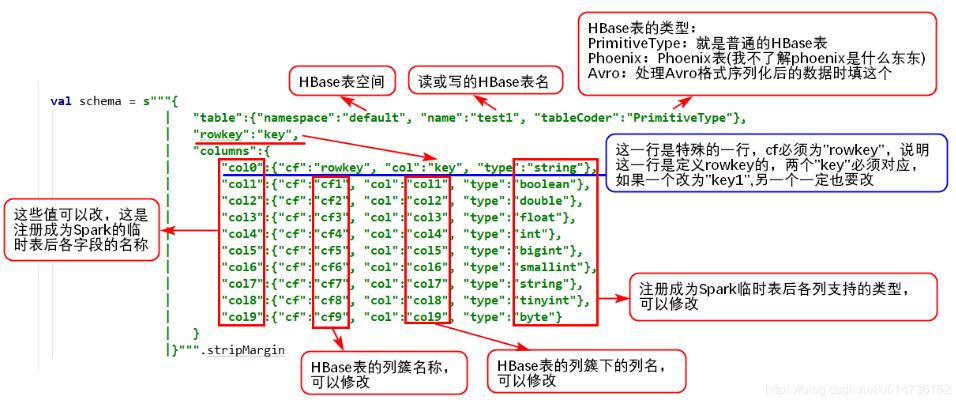
六、结果
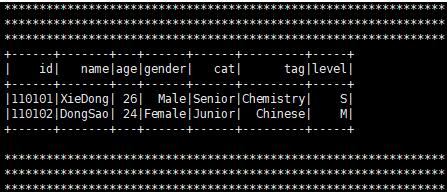
以上这篇在python中使用pyspark读写Hive数据操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。
python应用中调用spark_在python中使用pyspark读写Hive数据操作相关推荐
- 如何在MATLAB中调用(运行)“用Python写成的函数或脚本”
如何在MATLAB中调用"用Python写成的函数或脚本",首先要确保MATLAB知道咱们的Python解释器的位置在哪里. 如果安装了Python的时候把Python加入了系统环 ...
- c语言实现爬虫功能,用C/C 扩展Python语言_python 调用c语言 python实现简单爬虫功能_python实现简单爬虫...
用C/C 扩展Python语言 Python是一门功能强大的脚本语言,它的强大不仅表现在功能上,还表现在其扩展性上.她提供大量的API以方便程序员利用C/C++对Python进行扩展.因为执行速度慢几 ...
- 【Groovy】Groovy 脚本调用 ( Linux 中调用 Groovy 脚本 | Windows 中调用 Groovy 脚本 )
文章目录 前言 一.Linux 中调用 Groovy 脚本 二.Windows 中调用 Groovy 脚本 前言 在 命令行 , Groovy 脚本 , Groovy 类 , Java 类中 , 可以 ...
- Python语言学习:利用python语言实现调用内部命令(python调用Shell脚本)—命令提示符cmd的几种方法
Python语言学习:利用python语言实现调用内部命令(python调用Shell脚本)-命令提示符cmd的几种方法 目录 利用python语言实现调用内部命令-命令提示符cmd的几种方法 T1. ...
- C标准函数库中获取时间与日期、对时间与日期数据操作及格式化
表示时间的三种数据类型[编辑] 日历时间(calendar time),是从一个标准时间点(epoch)到现在的时间经过的秒数,不包括插入闰秒对时间的调整.开始计时的标准时间点,各种编译器一般使用19 ...
- python 类函数调用外部函数_python类中调用外部函数,python 函数中 定义类
Q1:python函数里的数组如何在函数外调用出来 使用返回值的方法有两种: 可以直接把调用的函数作为变量使用 可以用调用函数给一个变量赋值 第一种情况见如下例子: l = [1,2,3,4,5] d ...
- matlab中调用java代码_Matlab中调用第三方Java代码
在Java中采用Matlab JA Builder可以实现调用m文件,采用这样的方式,可在Matlab的M文件中,直接调用Java类.这种方式可以表示为Java--> Matlab( m, Ja ...
- java中调用数组参数_java中如何调用带有数组类型参数的存储过程
java中如何调用带有数组类型参数的存储过程 关注:95 答案:3 mip版 解决时间 2021-01-28 00:39 提问者万丈深渊 2021-01-27 14:00 不知道java中java ...
- mysql在触发器中调用存储过程_mysql 触发器中调用存储过程
想要在MYSQL的触发器中调用存储过程,但是IDE提示: 0A000 Not allowed to return a result set from a trigger 触发器代码如下: DELIMI ...
最新文章
- HSRP多组基础配置实验
- Tensorflow【实战Google深度学习框架】—TensorBoard
- 一眼定位问题,函数计算发布日志关键词秒检索功能
- python matplotlib.pyplot如何绘制实时图表?(实时绘制、更新图表、实时更新、动态窗口)plt.ion() plt.clf() plt.pause() plt.ioff()
- python下载后是黑的_python下载文件记录黑名单的实现代码
- Linux中设置vim自动在运算符号两边加上空格
- 使用Swashbuckle构建RESTful风格文档
- 【DP】【递归】分离与合体
- 51单片机怎么显示当前时间_51单片机玩转物联网基础篇06-LCD1602液晶显示器
- MATLAB教程(1) MATLAB 基础知识(4)
- 这让全场的chinaakd
- NBU客户端安装(linux和windows)
- gtp文件服务器,GTP中文网吉它谱吉他谱guitar网站
- web渗透测试思路浅谈-----漏洞发现及利用
- Rational Rose :从用例图开始
- html5动画测试题,Html5+js测试题
- HyperX旋火游戏鼠标推荐——轻量化鼠标设计界的艺术品
- 铲雪车(snow) UVA10203 Snow Clearing 题解
- 编程之美--数组中的最长递增子序列(LIS longest increasement sequence)
- position:relative的用法
热门文章
- 神经网络与中心场近似
- [Machine Learning]--无监督学习
- python idle编辑的代码文件拓展名是_Python IDLE编辑器打开后缀名为.py的文件
- 大学生计算机专业英语,《计算机专业英语》习题含答案(大学期末复习资料).doc...
- python数据处理高斯滤波_十大点云数据处理技术梳理
- 【STM32】位操作、按位与、按位或、按位异或、取反、左移、右移等基础 C 语言知识补充
- 【Matlab】解个微分方程
- 利用SIMULINK搭建一个16QAM调制解调收发系统
- AgileEAS.NET平台视频会议培训第二辑-简单插件开发应用演练(速度下载)
- O029、教你看懂OpenStack日志