各种树:trie树、B树、B-树、B+树、B*树
红黑树rbtree 二叉排序树
map 就是采用红黑树存储的,红黑树(RB Tree)是平衡二叉树,其优点就是树到叶子节点深度一致,查找的效率也就一样,为logN.在实行查找,插入,删除的效率都一致,而当是全部静态数据时,没有太多优势,可能采用hash表各合适。
hash_map是一个hash table占用内存更多,查找效率高一些,但是hash的时间比较费时。
总 体来说,hash_map 查找速度会比map快,而且查找速度基本和数据数据量大小,属于常数级别;而map的查找速度是log(n)级别。并不一定常数就比log(n)小, hash还有hash函数的耗时,明白了吧,如果你考虑效率,特别是在元素达到一定数量级时,考虑考虑hash_map。但若你对内存使用特别严格,希望 程序尽可能少消耗内存,那么一定要小心,hash_map可能会让你陷入尴尬,特别是当你的hash_map对象特别多时,你就更无法控制了,而且 hash_map的构造速度较慢。
现在知道如何选择了吗?权衡三个因素: 查找速度, 数据量, 内存使用。
trie树Double Array 字典查找树
Trie树既可用于一般的字典搜索,也可用于索引查找。
每个节点相当于DFA的一个状态,终止状态为查找结束。有序查找的过程相当于状态的不断转换
对于给定的一个字符串a1,a2,a3,...,an.则
采用TRIE树搜索经过n次搜索即可完成一次查找。不过好像还是没有B树的搜索效率高,B树搜索算法复杂度为logt(n+1/2).当t趋向大,搜索效率变得高效。怪不得DB2的访问内存设置为虚拟内存的一个PAGE大小,而且帧切换频率降低,无需经常的PAGE切换。
B树
即二叉搜索树:
1.所有非叶子结点至多拥有两个儿子(Left和Right);
2.所有结点存储一个关键字;
3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
如:
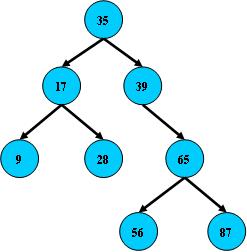
B树的搜索,从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中;否则,如果查询关键字比结点关键字小,就进入左儿子;如果比结点关键字大,就进入右儿子;如果左儿子或右儿子的指针为空,则报告找不到相应的关键字;
如果B树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么B树的搜索性能逼近二分查找;但它比连续内存空间的二分查找的优点是,改变B树结构(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销;
如:
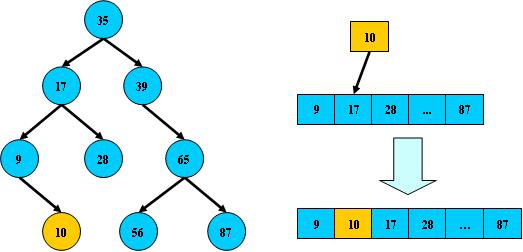
但B树在经过多次插入与删除后,有可能导致不同的结构:
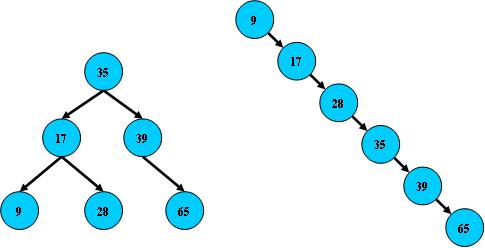
右边也是一个B树,但它的搜索性能已经是线性的了;同样的关键字集合有可能导致不同的树结构索引;所以,使用B树还要考虑尽可能让B树保持左图的结构,和避免右图的结构,也就是所谓的“平衡”问题;
实际使用的B树都是在原B树的基础上加上平衡算法,即“平衡二叉树”;如何保持B树结点分布均匀的平衡算法是平衡二叉树的关键;平衡算法是一种在B树中插入和删除结点的策略;
B-树
是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
如:(M=3)
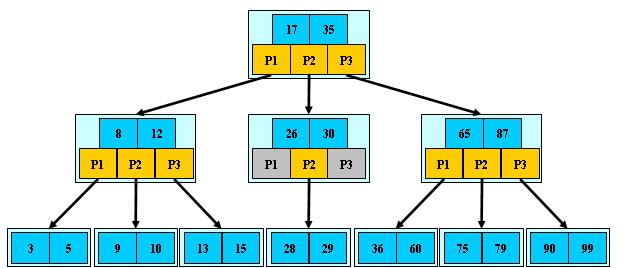
B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少利用率,其最底搜索性能为:
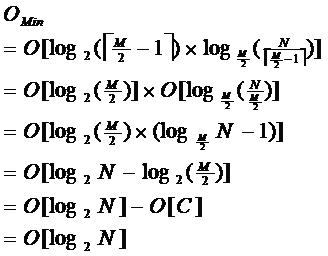
其中,M为设定的非叶子结点最多子树个数,N为关键字总数;
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题;
由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
B+树
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
如:(M=3)
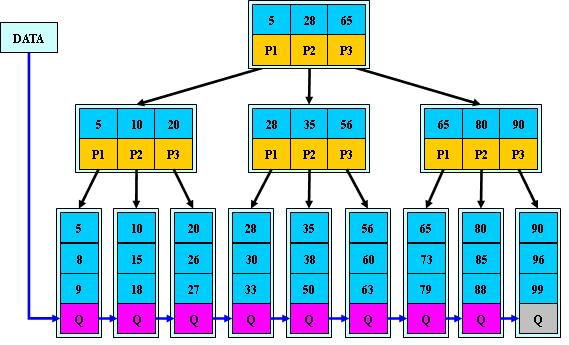
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.更适合文件索引系统;
B*树
是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;
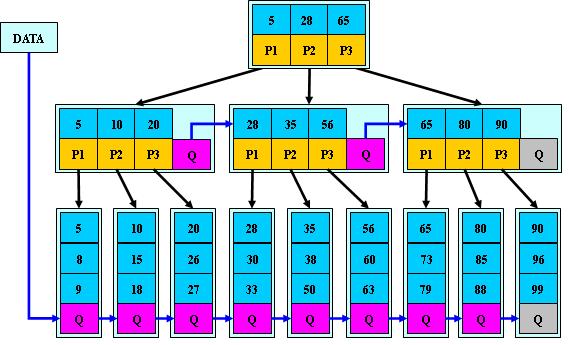
B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2);
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
小结
B树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于走右结点;
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;
所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3;
from:http://hi.baidu.com/shichen/blog/item/961b9e510dcd0e2343a75b73.html
各种树:trie树、B树、B-树、B+树、B*树相关推荐
- 种树:二叉树、二叉搜索树、AVL树、红黑树、哈夫曼树、B树、树与森林
虽然今天不是植树节,但是我今天想种树. 文章目录 树,什么是树? 二叉树 定义 二叉树的创建 二叉树的前中后序遍历 前序遍历: 中序遍历 后序遍历 已知前序.中序遍历结果,还原二叉树 已知后序.中序遍 ...
- 心中有“树”!图文并茂介绍数据结构中常见的树(一)
提到数据结构中的树(Tree) ,大家应该都不陌生,相关书籍中都有大段篇幅的介绍,刷 Leetcode 的时候会遇到很多相关问题.很多人往往会用 "手写红黑树" 来形容面试难度很高 ...
- 心中有“树”!图文并茂介绍数据结构中常见的树(二)
计算机科学家尼古拉斯·沃斯(Niklaus Wirth)曾说过:编程=数据结构+算法 ,可见数据结构在编程中的重要性. 50 年过去了,计算机行业日新月异,大佬的这句名言是否还适用于当下?使用成熟且丰 ...
- R语言构建xgboost模型:使用xgboost的第一颗树(前N颗树)进行预测推理或者使用全部树进行预测推理、比较误分类率指标
R语言构建xgboost模型:使用xgboost的第一颗树(前N颗树)进行预测推理或者使用全部树进行预测推理.比较误分类率指标 目录
- KD树是什么? 为什么要用KD树? KD树怎么用? KD树和KNN的关联是什么?
KD树是什么? 为什么要用KD树? KD树怎么用? KD树和KNN的关联是什么? sklearn中如何配置? 为了提高KNN的搜索效率,这里介绍一种可以减少计算距离次数的方法---KD树方法. KD树 ...
- b树与b+树的区别_一篇文章理清B树、B-树、B+树、B*树索引之间的区别与联系
概述 相信对于B树.B-树.B+树.B*树索引这几个大家都很容易混淆,下面单独对这几个索引做下分类总结. B树 即二叉搜索树: 1.所有非叶子结点至多拥有两个儿子(Left和Right): 2.所有结 ...
- b树与b+树的区别_Linux内核-数据结构系列(B树、B-树、B+树)的区别
一.B树 (二叉搜索树) B 树可以看作是对2-3查找树的一种扩展,即他允许每个节点有M-1个子节点. 根节点至少有两个子节点 每个节点有M-1个key,并且以升序排列 位于M-1和M key的子节点 ...
- 平衡查找树C语言程序,树4. Root of AVL Tree-平衡查找树AVL树的实现
对于一棵普通的二叉查找树而言,在进行多次的插入或删除后,容易让树失去平衡,导致树的深度不是O(logN),而接近O(N),这样将大大减少对树的查找效率.一种解决办法就是要有一个称为平衡的附加的结构条件 ...
- 树剖+线段树||树链剖分||BZOJ1984||Luogu4315||月下“毛景树”
题面:月下"毛景树" 题解:是道很裸的树剖,但处理的细节有点多(其实是自己线段树没学好).用一个Dfs把边权下移到点权,用E数组记录哪些边被用到了:前三个更新的操作都可以合并起来, ...
- java磁盘读写b 树_原来你是这样的B+树
前言 B+树是目前最常用的一种索引数据结构,通常用于数据库和操作系统的文件系统中,本文就网上的知识点与个人理解结合分享,如有错误,欢迎探讨及指正. 定义 B+树是B树的一种变形形式,B+树上的叶子结点 ...
最新文章
- JUC并发编程五 并发架构--Monitor工作原理
- ML之Validation:机器学习中模型验证方法的简介、代码实现、案例应用之详细攻略
- 【机器视觉】 dev_open_tool算子
- 初识Microsoft Hyper-v Server
- 使用 dotnet-outdated 维护项目 nuget 包版本
- 设计模式(一)单例模式的七种写法
- Struts中s:checkboxlist的用法
- LVM扩容之xfs文件系统
- 基于单片机的数字电子钟简单
- 泰迪杯数据挖掘挑战赛—数据预处理(一)
- HttpCanary使用指南——静态注入器
- Linux Ubuntu16挂载新硬盘并格式化硬盘方法教程笔记
- 一种很强的对联,看了让我想起高中时期那会儿对中文的崇拜!
- FPGA音频录音,WM8731音频采集存储DDR3,基于米联客FDMA实现
- 土库曼人纳德沙为什么选择波斯一方与奥斯曼人作战?
- 关于Johnson-Trotter和字典序排列在《算法设计与分析基础》中的论述
- 链家java开发,杭州链家房产信息分析
- leetcode290. 单词规律
- 那些C++程序让你笑三天的奇葩名字
- java毕业设计 ssm公寓宿舍后勤管理系统(含源码+论文)