通过python 爬取网址url 自动提交百度
通过python 爬取网址url 自动提交百度

昨天同事说,可以手动提交百度这样索引量会上去。
然后想了下。是不是应该弄一个py 然后自动提交呢?想了下。还是弄一个把
python 代码如下:
import os
import re
import shutil REJECT_FILETYPE = 'rar,7z,css,js,jpg,jpeg,gif,bmp,png,swf,exe' #定义爬虫过程中不下载的文件类型def getinfo(webaddress): #'#通过用户输入的网址连接上网络协议,得到URL我这里是我自己的域名global REJECT_FILETYPE url = 'http://'+webaddress+'/' #网址的url地址print 'Getting>>>>> '+urlwebsitefilepath = os.path.abspath('.')+'/'+webaddress #通过函数os.path.abspath得到当前程序所在的绝对路径,然后搭配用户所输入的网址得到用于存储下载网页的文件夹 if os.path.exists(websitefilepath): #如果此文件夹已经存在就将其删除,原因是如果它存在,那么爬虫将不成功 shutil.rmtree(websitefilepath) #shutil.rmtree函数用于删除文件夹(其中含有文件) outputfilepath = os.path.abspath('.')+'/'+'output.txt' #在当前文件夹下创建一个过渡性质的文件output.txt fobj = open(outputfilepath,'w+') command = 'wget -r -m -nv --reject='+REJECT_FILETYPE+' -o '+outputfilepath+' '+url #利用wget命令爬取网站tmp0 = os.popen(command).readlines() #函数os.popen执行命令并且将运行结果存储在变量tmp0中print >> fobj,tmp0 #写入output.txt中 allinfo = fobj.read()target_url = re.compile(r'\".*?\"',re.DOTALL).findall(allinfo) #通过正则表达式筛选出得到的网址 print target_urltarget_num = len(target_url) fobj1 = open('result.txt','w') #在本目录下创建一个result.txt文件,里面存储最终得到的内容for i in range(target_num):if len(target_url[i][1:-1])<70: # 这个target_url 是一个字典形式的,如果url 长度大于70 就不会记录到里面print >> fobj1,target_url[i][1:-1] #写入到文件中else: print "NO"fobj.close() fobj1.close() if os.path.exists(outputfilepath): #将过渡文件output.txt删除 os.remove(outputfilepath) #删除if __name__=="__main__": webaddress = raw_input("Input the Website Address(without \"http:\")>") getinfo(webaddress) print "Well Done."执行完之后就会有如下url
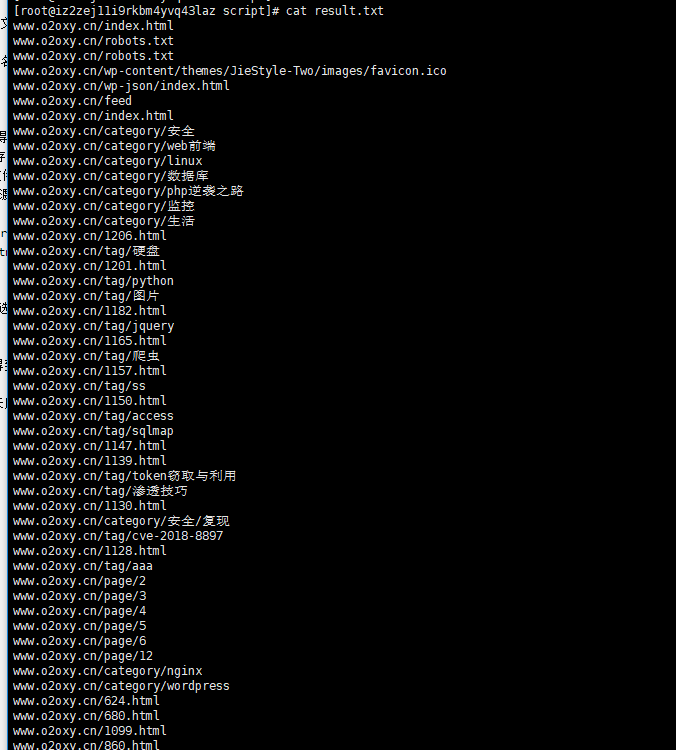
再弄一个主动提交的脚本,我进入百度录入的网址找到自己提交的地址
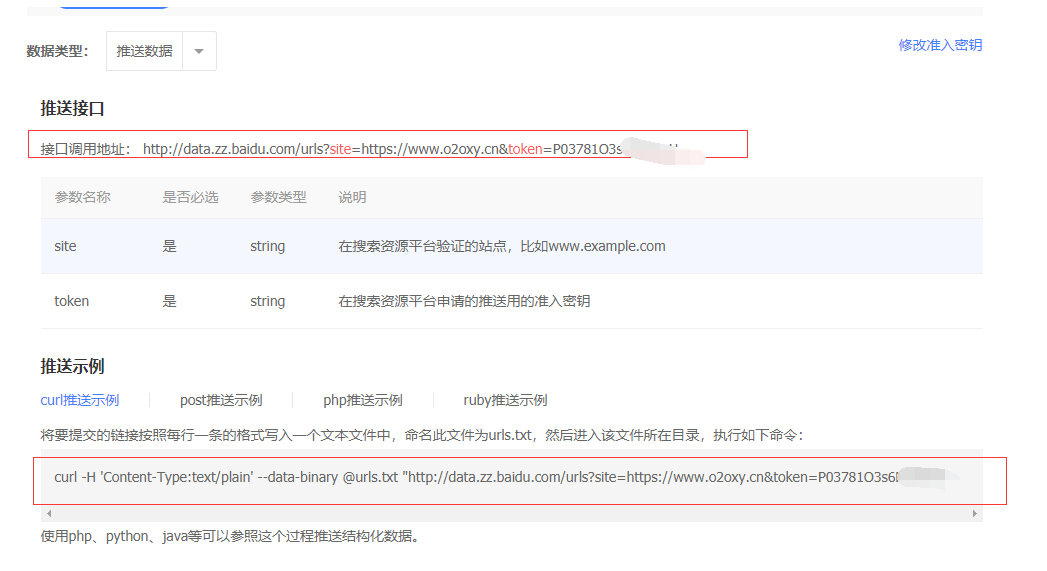
写了一个垃圾脚本,本来想融入到py中。但是想了下,还是别了
[root@iz2zej11i9rkbm4yvq43laz script]# cat baiduurl.sh cd /script && curl -H 'Content-Type:text/plain' --data-binary @result.txt "http://data.zz.baidu.com/urls?site=https://www.o2oxy.cn&token=P03781O3s6Ee"&& curl -H 'Content-Type:text/plain' --data-binary @result.txt "http://data.zz.baidu.com/urls?site=https://www.o2oxy.cn&token=P03781O3s6E"
执行结果如下:
[root@iz2zej11i9rkbm4yvq43laz script]# sh baiduurl.sh
{"remain":4993750,"success":455}{"remain":4993295,"success":455}然后做了一个计划任务

执行一下。获取网址url 比较慢,可能十分钟把
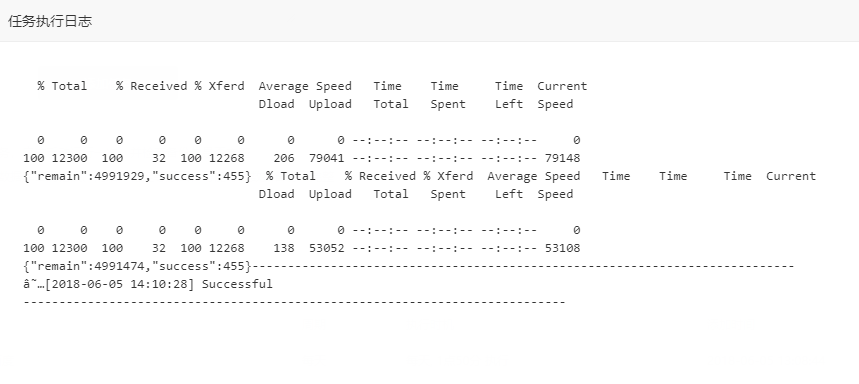
唔。完美!!!!!

转载于:https://www.cnblogs.com/liang2580/p/9142511.html
通过python 爬取网址url 自动提交百度相关推荐
- 使用Python爬取微信群里的百度云资源
需求背景: 最近误入一个免费(daoban)资源的分享群(正经脸),群里每天都在刷资源链接.但是大家都知道,百度云的分享链接是很容易被河蟹的,群里除了分享链接外,就是各种抱怨 "怎么又失效了 ...
- python语言的主网址-Python爬取网址中多个页面的信息
通过上一篇博客了解到爬取数据的操作,但对于存在多个页面的网址来说,使用上一篇博客中的代码爬取下来的资料并不完整.接下来就是讲解该如何爬取之后的页面信息. 一.审查元素 鼠标移至页码处右键,选择检查元素 ...
- 2021最新 python爬取12306列车信息自动抢票并自动识别验证码(三)购票篇
项目前言 tiebanggg又来更新了,项目--[12306-tiebanggg-master]注:本项目仅供学习研究,如若侵犯到贵公司权益请联系我第一时间进行删除:切忌用于一切非法途径,否则后果自行 ...
- 2021最新python爬取12306列车信息自动抢票并自动识别验证码
项目描述 项目前言 tiebanggg又来更新了,项目--[12306-tiebanggg-master]注:本项目仅供学习研究,如若侵犯到贵公司权益请联系我第一时间进行删除:切忌用于一切非法途径,否 ...
- python爬取12306列车信息自动抢票并自动识别验证码(一)列车数据获取篇
项目前言 自学python差不多有一年半载了,这两天利用在甲方公司搬砖空闲之余写了个小项目--[12306-tiebanggg-master].注:本项目仅供学习研究,如若侵犯到贵公司权益请联系我第一 ...
- python爬虫 豆瓣影评的爬取cookies实现自动登录账号
python爬虫 豆瓣影评的爬取cookies实现自动登录账号 频繁的登录网页会让豆瓣锁定你的账号-- 网页请求 使用cookies来实现的自动登录账号,这里的cookies因为涉及到账号我屏蔽了,具 ...
- python爬取天气与微博热搜自动发给微信好友
python爬取天气与微博热搜自动发给微信好友 前言 系统环境 正文 爬取中国天气网 爬取微博热搜 微信自动发送消息 源代码 总结 github地址 前言 忙着毕设与打游戏之余,突然想着写个爬虫练练手 ...
- python爬取某网站高清二次元图片 自动下载
第一章 Python 爬取网站信息 文章目录 一,什么是爬虫? 二.使用步骤 1.引入库 2.伪装header 3.读取信息并过滤,写入文件 总结 前言 本文只做技术讨论,大家不要一直爬这个小网站,记 ...
- python爬取整个网站_python爬取网站全部url链接
御剑自带了字典,主要是分析字典中的网址是否存在,但是可能会漏掉一些关键的网址,于是前几天用python写了一个爬取网站全部链接的爬虫. 实现方法 主要的实现方法是循环,具体步骤看下图: 贴上代码: # ...
最新文章
- 域控制器建立以及一般配置
- 与通用计算机相比 单片机具体有哪些特点,嵌入式系统-复习大纲_彭荣
- Product文本格式说明
- 揭秘阿里云 RTS SDK 是如何实现直播降低延迟和卡顿
- 软件网站安全性的设计与检测与解决方案
- 梯度下降(一)--机器学习
- 服务器硬盘数据备份到nas,群晖NAS教程第五节:如何备份 Synology NAS
- catia快捷键_CATIA的管理员模式和多版本环境变量设置
- PbootCMS制作个性分页条之单页/总页数效果详细介绍教程
- pada aws configuration
- SCHTASKS windows计划任务
- usb接口问题折腾记
- R语言中的函数1:outer(张量积)
- 可以模拟人工操作的软件;如访问网页,在网页中自动获取固定信息等
- 安卓使用http下载文件
- 通过 汇编了解C语言 指针 悬垂指针概念
- 从两道基础二分算法题谈check函数的写法
- Java多线程sleep和wait的区别
- 漏洞挖掘工具-CE(Cheat Engine) 简介
- java ppt转html_c# Office文件转换成Html格式(将PPT转换成HTML)