人脸识别,结构光名词记录
人脸识别步骤包括
- Face detection, 对图像中的人脸进行检测,并将结果用矩形框框出来。Haar+Adaboost FacenessNet
- Face alignment,对检测到的人脸进行姿态的校正,使其人脸尽可能的”正”,通过校正可以提高人脸识别的精度。校正的方法有2D校正、3D校正的方法,3D校正的方法可以使侧脸得到较好的识别。 在进行人脸校正的时候,会有检测特征点的位置这一步,这些特征点位置主要是诸如鼻子左侧,鼻孔下侧,瞳孔位置,上嘴唇下侧等等位置,知道了这些特征点的位置后,做一下位置驱动的变形,脸即可被校”正”了。
- Face verification,人脸校验是基于pair matching的方式,所以它得到的答案是“是”或者“不是”。在具体操作的时候,给定一张测试图片,然后挨个进行pair matching,matching上了则说明测试图像与该张匹配上的人脸为同一个人的人脸。中间包括Feature extraction及verification。 DEEPID PCA
- Face identification或Face recognition:解决who am I?
DEEPID
http://mmlab.ie.cuhk.edu.hk/pdf/YiSun_CVPR14.pdf
https://www.cnblogs.com/jesse123/p/5687069.html
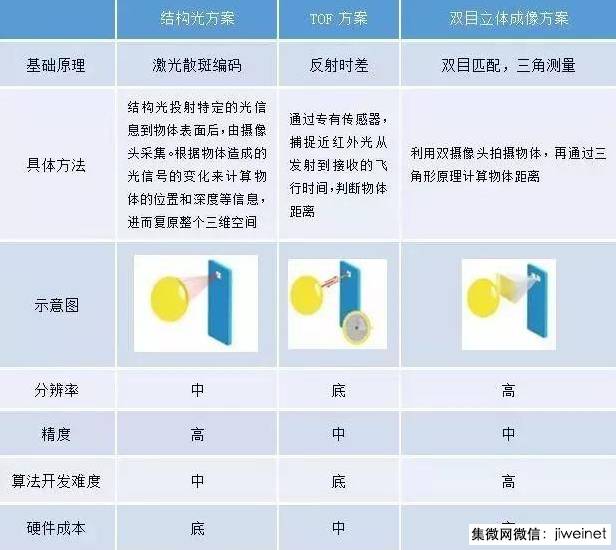
- 点结构光法
点结构光法是简单的三角法。点结构光法的接收方向是不可变的。当实现光栅式平面扫描时,光源和探测是同步移动的。单束激光打在物体表面,由摄像机摄取其反射光点。每次只能处理一点,测量速度慢。 - 线结构光法
通过投射源投射出平面狭缝光,每次投射一个结构光条纹,每幅图像可得到一个截面的深度,通过改变投射狭缝光的角度,获得更多截面的深度,进而获得物体的深度。 - 多线结构光法
以线结构光为基础,为了提高图像处理效率,在一幅图像内处理多条光条纹。 编码结构光法
在多线结构光基础上,为解决多条纹图像中,不同条纹的定位和匹配问题。编码法分为时间编码法、空间编码法、直接编码法、彩色编码法

深度学习用于识别面部DeepFace:Closing the Gap to Human-Level Performance in Face Verification
最早将深度学习用于人脸验证的开创性工作。Facebook AI实验室出品。动用了百万级的大规模数据库。典型的识别信号提特征+验证信号refine的两步走,对DeepID等后人的工作影响很大。
技术概括
关注了人脸验证流程中的人脸对齐步,采用了比较复杂的3D人脸建模技术和逐块的仿射变换进行人脸对齐。可以解决non-planarity对齐问题。 提出了一个9层(其实是8层)的CNN进行特征提取。提出了一种针对对齐后人脸的的locally connected layers,无权值共享。 用CNN提取的特征继续进行metric learning,包括卡方距离学习和siamese network两种方法。
一些值得反思的细节
CNN的结构:conv–>pooling–>conv–>3 locally connected layers–>2 fc。由于最后5层都没有权值共享,所以会造成参数膨胀,共有超过1.2亿个参数,其中95%都来源于最后5层。但locally connected layers相比原始的conv计算速度是一样的。因为动用了目前看来也是惊人的4000人的400百万幅图像,所以没有出现明显的过拟合。 单个CNN最后提取的特征维数是4096。 3D对齐的步骤是:找6个landmarks–>进行2D对齐–>重找6个landmarks–>重进行2D对齐……直到收敛–>找67个landmarks–>3D-2D映射建模–>逐块仿射变换变成正脸。此处水很深,实现起来较复杂,而且后续的论文都没有再用如此复杂的对齐手段也能得到非常好的结果,不建议复现。但对比实验表明3D对齐的作用还是很大的,可能是和采用的算法有关系吧,比如针对3D对齐定制的locally connected layers。 pooling只使用一次,担心信息损失太多。 只对第一个fc layer采用了dropout。 CNN提取完的特征还要进行两次归一化。第一次是每个分量除以训练集中的最大值,第二次是l2归一化。此步似乎多余,也没有足够的理论和实验支撑,又回到了人工特征的老路。归一化本身是一种降低特征之间差异的手段,不一定就可以增强discriminative ability,应该慎重使用。 CNN学习出特征后,还需要用某种相似度来做验证。文中采用了两种比较简单的相似度:加权卡方距离和加权L1距离。权重分别通过SVM和siamese network学习到。这一步一般是进行迁移学习。 相似度量学习到后,还要训练一个SVM对两两距离做2分类,判断是否是同一个人。 数据库:4030个人,每人800-1200幅图像,4百40万幅图像。 10种网络的距离结果ensemble,累加kernel matrix,再用SVM对距离做分类,判断是否是同一个人。 通过牛逼的工程优化,在2.2GHz单CPU上可做到CNN0.18秒,对齐0.05秒,全部0.33秒。
2. Deep LearningFace Representation from Predicting 10,000 Classes
汤晓鸥团队DeepID系列的开创之作。也是典型的两步走策略。
技术概括
训练一个9层CNN对约10000个人(其实是8700个人)做人脸识别,中间有跨层连接和 locally connected layer。倒数第二层的输出作为特征。 多个人脸区域的特征进行连接作为总特征。 用CNN学习出的特征再训练一个joint bayesian进行人脸验证。
一些值得反思的细节
单个CNN训练出的特征是160维,维度非常小,具有极强的压缩性质。 明确提出识别信号的作用,强于只使用验证信号。 CNN的结构:conv1–>pooling1–>conv2–>pooling2–>conv3–>pooling3–>conv4–>fc–>softmax。其中conv3只在每个2*2局部区域权值共享,conv4是locally connected layer,权值不共享。fc同时与pooling3与conv4全连接,是一种多分辨率策略。 CNN输入会根据patch的不同而改变,后续的feature maps都会跟着改变。 人脸对齐采用3个landmarks。根据5个landmarks采样patches。一共10 regions*3 scales*1 RGB*1 gray=60 patches。每个patch还要取flip。所以,最后要训练60*2=120个CNN!最后把每个CNN的160维特征连接成160*2*60=19200维特征。工作量有点大。 用CNN学习出的特征训练了joint bayesian和一个验证用的神经网络。验证用神经网络只是一个三层的浅层网络,输入是成对的图像patches,19200*2维,输出层是2分类结果输出。对比结果显示这种神经网络没有joint bayesian效果好。 训练joint bayesian前用PCA把19200维特征降维到150。 数据库包括10177个人,共202599幅图像。
3. Deep LearningFace Representation by Joint Identification-Verification
超越人类水平(97.53%)。不过同是晓鸥团队的gaussian face是第一次超越人类。
技术概括
明确采用两种监督信号:识别信号用于增加类间距离,验证信号用于减少类内距离(肯定也是有利于增加类间距离的)。 相比于DeepID,loss层除了用于分类的softmax loss,还加入了contrastive loss。两种loss同时反向传播。 相比于DeepID,从众多patches中挑选出了25个最佳pathes,减少计算负担和信息冗余。 验证采用joint bayesian或直接用L2距离。
一些值得反思的细节
CNN结构除了最后的loss层外与DeepID一样。输出是8192个人的分类结果。 从400个patches中挑选了 25个。训练25个CNN,最后连接成的特征向量是25*160=4000维。在训练joint bayesian之前,要通过PCA进一步降维到180维。 因为加入了contrasitive loss,CNN学习出的特征可以直接用于计算L2距离进行人脸验证,效果不会比joint bayesian差很多。 最后通过选择不同的patches,训练了7个分类器做ensemble。
4. Deeply learnedface representations are sparse, selective, and robust
一半内容是理论分析。总体上两步走策略没变,只是CNN结构做了较大改变。
技术概括
增加隐含层的宽度,即feature maps个数。 监督信息跨层连接。 理论分析DeepID2+的特征是sparsity\selectiveness\robustness。sparsity是指特征向量中有许多分量为0,因此具有压缩能力。selectiveness是指某个分量对某个人的图像或某种属性的图像的激活响应程度和其他人或属性的程度不一样,因此具有判别能力。robustness是指图像特征在遮挡前后具有一定的不变性。 利用sparsity进行特征二值化,可用于大规模图像检索。
一些值得反思的细节
训练集中没有特意加入遮挡样本,但学习出的特征也具有遮挡的鲁棒性。 相比于DeepID2,feature maps的个数由20、40、60、80变为128、128、128、128。输出的特征维数由160变为512。 相比于DeepID2,25个patches还要再取一次flip,训练50个CNN,特征维数共50*512=25600维。 数据库:12000个人,290000幅图像。 fc和loss层连接到之前的每一个pooling层后面,也就是类似googlenet的策略,让监督信息直接作用到每一层。但fc层应该权值不共享。 通过对人脸属性方面的分析,说明通过人脸识别与验证信号学习到某个神经元是对某种属性有更强的激活响应。所有这些神经元的组合代表了各种属性的特征组合,说明通过这些中层属性特征可以对高层的身份特征进行差别,与kumar的工作有异曲同工之妙。
5. DeepID3: FaceRecognition with Very Deep Neural Networks
针对CNN的结构做了较大改进,采用图像识别方面的最新网络结构,且层数加深。其他方面较前作没有变化。
技术概括
实现了两种更深层的CNN网络,一种是参考VGG对conv层的不断堆积,一种是参考googlenet对inception结构的不断堆积。 继续采用DeepID2+中的监督信号跨层连接策略。 继续采用DeepID2+中的25个patches(加flip)特征组合策略。其中VGG和googlenet各训练一半。 继续采用DeepID2+中的joint bayesian用于验证的策略。
一些值得反思的细节
VGG类CNN结构: conv1\2–>pooling1–>conv3\4–>pooling2–>conv5\6–>pooling3–>conv7\8–>pooling4–>lc9\10,fc和loss连接到之前每一个pooling层后面。 googlenet类CNN结构:conv1\2–>pooling1–>conv3\4–>pooling2–>inception5\6\7–>pooling3–>inception8\9–>pooling4,fc和loss连接到之前每一个pooling层后面。 relu用于除了pooling层之外的所有层。 dropout用于最后的特征提取层。 特征总长度大约30000维。 PCA降维到300维。 与DeepID2+比起来,精度几乎没有提高。可能还是网络过浅,训练数据过少,没有完全发挥VGG和googlenet的效果。
6. FaceNet: AUnified Embedding for Face Recognition and Clustering
非两步式方法,end-to-end方法。在LFW的精度基本上到极限了,虽然后面还有百度等99.77%以上的精度,但从原理上没有创新,也是用了triplet loss等本文得出的技术。
技术概括
提出了一种end-to-end的网络结构,最后连接的是triplet loss。这样提取的特征可以直接用欧氏距离算相似度。 提出了样本选择技术,找hard triplets。这一步至关重要,选不好可能会不收敛。
一些值得反思的细节
特征维度:128。可以二值化,效果也不错。 triplet loss为什么比contrastive loss好没有解释得太清楚。两者都有margin的概念,而不是像本文所说的是其独有。 triplets选择有两种方法。1.线下选择。用训练中途的网络去找一个样本集中的hard triplets。2.线上选择。也是本文最终所采用的方式。从当前mini-batch中选择。每个mini-batch取几千个(1800个)样本,其中保证每人至少40个样本。负样本随机采样即可。所有正样本对都用,只选择负样本对。 实际选择hard negtives的时候,松弛条件,只选择semi-hard,也就是负样本对的距离比正样本对的距离大,但距离小于margin即可。 margin:0.2。 设计了两种CNN结构。1.VGG类中加入了1*1 kernel。共22层。1.4亿个参数。16亿FLOPS。2.googlenet类基于Inception模型,其中两个小模型NNS1:26M参数,220M FLOPS;NNS2:4.3M参数,20M FLOPS。三个大模型NN3与NN4和NN2结构一样,但输入变小了。 NN2输入:224×224,NN3输入:160×160,NN4输入:96×96。采用了l2 pooling,没有用常规的max pooling,不知原委。 数据库规模超大。800万人,共2亿幅图像。 无需对齐。
7. Deep FaceRecognition
精度上并没有超越前人,但网络结构较易实现,而且提出了一些有很强实践性的工作流程。
技术概括
提出了一个低成本的图像标注流程。 用最朴素的conv层不断堆积建造了一个38层(另外还有40层、43层)的CNN做2622个人的分类,学习识别信号,最后用triplet loss学习验证信号,将特征映射到一个欧氏距离空间用L2距离作为相似度。
一些值得反思的细节
数据库:2600人,260万幅图像。大约每人1000幅。 标注团队:200人。 图像标注流程如下。1.建立人名列表和初步爬图。主要集中于名人,便于从网上获取大量样本,共5000人,男女各半。再进行过滤,过滤掉样本太少的、与lfw有重合的、按人名爬取的图像不准确的。最后剩下2622人,每人200幅。2.收集更多的图像。从其他搜索引擎、关键词加“演员”等附加词,扩充到每人2000幅。3.用分类器自动过滤。训练样本采用搜索引擎rank最高的50幅,用Fisher Vector训练1对多SVM。最后保留每人2000幅中分数最高的1000幅。要训练2622个SVM,工作量巨大。4.去重。5.人工审核加分类器自动过滤。训练一个CNN,每个人分数低的样本就丢弃。最后剩982803幅图像。前4步只花了4天,整个流程花了14天。 特征维度:1024。 CNN结构中不包括LRN。 输入减去了平均脸。没有进行颜色扰动。 mini-batch size= 64。这个设得有点太小了。 dropout用于两个fc层。 triplet loss用于fine-tune。前面几层的参数都固定不变,只变新加的fc层。 triplet中的负样本只选与anchor距离超过margin的。 3scales*10patches = 30 patches。最后这30个特征取平均(原文如此,感觉特征取平均会乱套的,一般都是分类结果取平均或voting)
借鉴之处
人脸对齐是必要的,但没必要做精准对齐。训练时不太用准,测试时可以精准。 跨层连接有利于信息流的反馈传播,有利于效果提升。 识别与验证信号都有用,缺一不可。 多个patches结合效果明显,但增加了计算负担。 多个model结合效果明显,但增加了计算负担。 大规模训练数据量。人数和图像总数都是越多越好。 joint bayesian、直接用相似度距离均可,关键是学习出的特征是否有效。 可以先用一般类型的图像学习N路识别CNN,再用测试图像类型迁移学习验证信号。 也可以直接end-to-end。特征二值化,有利于哈希检索。
人脸识别,结构光名词记录相关推荐
- L.G.Hassebrook团队结构光论文记录
团队文章: 1,Yalla 2005 Very High Resolution 3-D Surface Scanning Using Multi-frequency Phase Measuring ...
- 【陈工笔记】# 人脸识别的实际操作记录 #
"良好的习惯,才不会让努力白白浪费." 首先,需要down一个OpenCV出来,刚开始练习,可以在Windows上上手,安装包传送门:如果享用Linux,就down一个出来,也可以 ...
- 人脸识别技术大总结——Face Detection Alignment
作者:sciencefans 搞了一年人脸识别,寻思着记录点什么,于是想写这么个系列,介绍人脸识别的四大块:Face detection, alignment, verification and id ...
- 人脸识别技术大总结(1):Face Detection Alignment
原文出处: sciencefans 的博客 搞了一年人脸识别,寻思着记录点什么,于是想写这么个系列,介绍人脸识别的四大块:Face detection, alignment, verificat ...
- 人脸识别技术大总结—Face Detection Alignment
人脸识别技术大总结-Face Detection & Alignment 2015-4-8 14:33| 发布者: 炼数成金_小数| 查看: 23912| 评论: 0|来自: cnblo ...
- 像素测量工具_结构光测量—工程质量管理的潜力股
计算机视觉技术与图像处理技术的发展促进了三维测量技术的进步,基于计算机视觉的三维信息获取技术已成为了当前三维测量的主流技术方案,光学测量迅速成为了三维测量技术的热门研究内容.本文将介绍工程应用上三维测 ...
- 人脸服务器如何与门禁系统对接,人脸识别门禁系统终端设备接口说明
1.上传识别结果 人脸识别门禁系统设备识别后把识别结果上传到服务器(单包数据数量小于5条) (一) 人脸识别门禁系统请求(设备->服务器): 1. 人脸识别门禁系统请求命令: 0x19 2. 人 ...
- 人脸识别迁移学习的应用
https://github.com/jindongwang/transferlearning 关于迁移学习的一些资料 这个仓库包含关于迁移学习一些资料,包括:介绍,综述文章,代表工作及其代码,常用数 ...
- python人脸识别、语音合成、智能签到系统(2)
基于python+face_recognition+opencv+pyqt5+百度AI实现的人脸识别.语音播报.语音合成.模拟签到系统(2) 人脸识别效果图 简单介绍以及需要的配置在 python人脸 ...
- Unity调用Face++ 人脸识别 Detect API
Face++提供的 人脸识别 SDK 和 公开的API 可以实现精确的人脸识别,返回多达106个识别点,是目前市面上非常理想的人脸识别产品.这里记录一下 通过Unity 使用c# 调用Face++的d ...
最新文章
- 一个在raw里面放着数据库文件的网上例子
- 技术人的不惑之路...... | 每日趣闻
- JavaScript内置函数及API
- blob转file对象_C++核心准则C.41:构造函数生成的对象应该被完全初始化
- .net WCF简单实例
- BaiDu校招2016计算机视觉笔试试题
- HDU Problem - 3763 CD(二分)
- oracle函数中bitand,Oracle bitand()函数使用方法
- pythonyaml参数_使用python检查yaml配置文件是否符合要求
- python 中m op n运算_Python数字类型、数值运算操作符、数值运算函数
- python中for循环的用法_Python中ifelse判断语句、while循环语句以及for循环语句的使用...
- fgui的ui管理框架_DCET: Unity3D客户端和.Net Core服务器双端框架,支持代码全热更(包括FGUI和双端行为树)...
- html5接收表单,HTML5表单的新功能
- 索尼电视总出现Android,索尼BRAVIA电视推送更新:升级安卓8.0,修复众多问题
- 金山打字测试一分钟软件,金山打字2006——一款打字练习及测试软件.doc
- Java 利用RXTX串口工具使用短信猫
- 【算法复习】迭代改进
- 氛围感新年头像如何制作?教你简单的制作好看头像的办法
- 迪士尼机器人芭蕾舞_迪士尼公园只有卡通公主?内含大量惊人科技感机器人
- 【Unity开发小技巧】Unity打包IOS端APP