基于TMS320VC5507的语音识别系统实现
1 语音识别片上系统概述
随着数字信号处理技术的发展,语音识别片上系统已成为人们研究的热点。然而,复杂的系统与硬件需求的矛盾,一定程度上限制了它的应用和推广。本文针对上述问题,采用相应的识别策略[1],合理安排算法流程,完成了高性能特定人与非特定人识别系统的片上实现。
2 硬件平台
DSP选型时需综合考虑运算速度、成本、功耗、硬件资源和程序可移植性等因素。本系统采用美国德州仪器(TI)生产的TMS320VC5507定点DSP作为核心处理器[2],并配合使用PLL时钟发生器、JTEG标准测试接口、异步通信串口、DMA控制器、通用输入输出GPIO端口以及多通道缓冲串口(McBSPs)等主要片内外设。系统硬件平台如图1所示。
VC5507 DSP芯片采用先进的多总线结构,内含64 K&TImes;16 bit的片上RAM和64 KB的ROM;片内可屏蔽ROM固化有引导转载程序(Bootloader)和中断向量表等;采用流水线结构提高指令执行的整体速度。与C54x系列DSP不同的是,VC5507DSP的存储空间包括统一的数据、程序空间和I/O空间,寻址空间可达16 MB;片内包含两个算术逻辑单元(ALUs),在最高时钟频率200 MHz下,指令周期可达5 ns,最高速度可达400 MIPS。
存储器采用三菱公司生产的M5M29GB/T320VP系列Flash芯片。全片容量2 MW,分为128个扇区,通过外部存储器接口(EMIF)方式与读写时序接入DSP;采用2.7 V~3.6 V单电源供电。该系列Flash支持块编程操作[3],读写速度要快得多,有利于实时性的改善。
基金项目:国家自然科学基金资助项目60572083
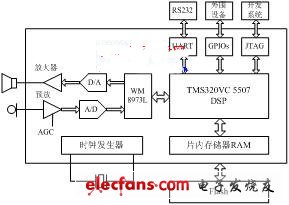
图1 语音识别系统硬件框图
A/D、D/A转换器采用英国Wolfson公司生产的WM8973L芯片。该芯片支持16位A/D、D/A转换,具有可编程输入输出增益控制,可通过软件设置8~96 KHz的多种采样频率[4]。
3 软件结构
3.1 系统概述
特定人识别系统采用12维MFCC参数作为识别引擎的特征参数,训练与识别都是在片上实时实现的,系统框架如图2(a)所示。在训练阶段,由片上实时提取每个词条的特征参数存放到Flash中作为模板库。在识别阶段,将待识别词条实时提取特征参数、端点检测以后,利用动态时间规整(DTW)算法与模板库中的所有模板进行匹配,选择失真度最小的模板作为识别结果。当词表改变时,只需调整Flash存储方式,算法本身无需改动。
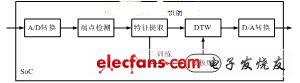
(a) 特定人系统
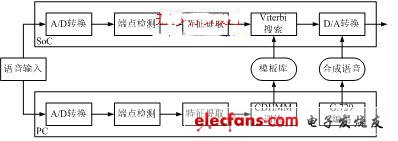
(b) 非特定人系统
图2 识别系统框架
非特定人识别系统的输入特征矢量为27维,包括12维MFCC、12维MFCC一阶差分、一阶对数能量、一阶差分能量以及二阶差分能量。系统以基于因素的CDHMM模型为基本识别框架,采用Viterbi解码的帧同步搜索算法进行识别。HMM模型训练事先在PC机上进行,而Viterbi搜索则在DSP芯片上实时实现,整个系统为双层结构,如图2(b)所示。
训练阶段主要完成如下任务:给定一个HMM模型和一组观察矢量集合,采用迭代算法调整模型参数,使得新模型和给定的观察矢量集合的似然度最大。首先用初始模型估计观察矢量由隐含层所有可能的状态序列输出的后验概率,然后根据前一步的估计结果,利用最大似然准则估计新的HMM模型,所得到的参数用作下一次迭代。识别阶段采用Viterbi搜索,所构建的识别网络包括状态号和状态连接关系等信息。为了减少网络搜索的内存占用量,采用每个词条单独建立网络的方法,使得每个词条的搜索过程可在内存中独立进行[5]。
基于TMS320VC5507的语音识别系统实现相关推荐
- 手把手教你:基于TensorFlow的语音识别系统
系列文章 第十章.手把手教你:基于Django的用户画像可视化系统 第九章.手把手教你:个人信贷违约预测模型 第八章.手把手教你:基于LSTM的股票预测系统 目录 系列文章 一.项目简介 二.语音数据 ...
- 【语音识别】基于GMM-HMM的语音识别系统
基于GMM-HMM的语音识别系统 终极目的:让机器"听懂" . • 对齐:"音频wav" 和"文本txt"的对应关系 • 训练:已知对齐(w ...
- 基于Python的语音识别系统(孤立词)
目录 1 任务介绍 1 2 项目实现 1 2.1 预处理 2 2.2 特征提取 3 2.2.1 归一化 3 2.2.2 预加重 3 2.2.3 分帧 3 2.3 加窗 4 2.3.1 端点检测 6 2 ...
- 语音识别入门第五节:基于GMM-HMM的语音识别系统
目录 基于孤立词的GMM-HMM语音识别系统 训练 解码 基于单音素的GMM-HMM语音识别系统 音素/词典 训练 解码 基于三音素的GMM-HMM语音识别系统 三音素 决策树 基于孤立词的GMM-H ...
- matlab参数是差分的,第13章 基于MATLAB的语音识别系统
对特征参数的要求: 1)提取的特征参数能有效地代表语音特征,具有很好的区分性: 2)各阶参数之间有良好的独立性: 3)特征参数要计算方便,最好有高效的计算方法,以保证语音识别的实时实现. 声带可以有周 ...
- 基于GMM-HMM的语音识别系统
目录 基于孤立词的GMM-HMM语音识别 建模 训练 Viterbi训练 前向后向训练(Baum-Welch训练) 解码 基于单音素的GMM-HMM语音识别系统 基于三音素的GMM-HMM语音识别系统 ...
- 基于python的语音识别系统,Python语音识别技术路线
如何用python调用百度语音识别 1.首先需要打开百度AI语音系统,开始编写代码,如图所示,编写好回车.2.然后接下来再试一下的音频,开始编写成功回车,如图所示的编写. 3.最后,查看音频c的属性, ...
- AI大语音(七)——基于GMM的0-9语音识别系统(深度解析)
本文来自公众号"AI大道理". 这里既有AI,又有生活大道理,无数渺小的思考填满了一生. 1 系统概要 孤立词识别:语音中只包含一个单词的英文识别 识别对象:0-9以及o的英文语音 ...
- 语音识别系统wav2letter++简介
语音识别系统是深度学习生态中发展最成熟的领域之一.当前这一代的语音识别模型基本都是基于递归神经网络(Recurrent Neural Network)对声学和语言模型进行建模,以及用于知识构建的计算密 ...
最新文章
- Linux下通过进程名查询占用的端口
- 从0开始学习 GitHub 系列之「初识 GitHub」
- python pass 占位符 占位语句
- ABAP workbench API的使用方法
- 细粒度权限控制 linux,利用docker插件实现细粒度权限控制
- Ribbon中的负载均衡算法实现
- 第十三节:易学又实用的新特性:for...of
- 无法搜索到电脑模拟热点的可以尝试一下(adhoc补丁)
- 二维数组的最大联通子数组和
- 17、SpringBoot------整合dubbo
- 如何从C快速过渡到C++
- 光学软件市场现状研究分析报告-
- 服务器工作站显示器,HP Z25n超窄边框显示器【深度测评】
- Dropbox使用问题
- [译]第一章:什么是管理
- Vue3和Vue2组件单元素的过渡
- 招聘渠道超全汇总,最适合你的是哪一类?
- db2 SEQUENCE
- 标签语义化以及使用好处
- ASCII,ISO8859-1,GBK,GB18030,Unicode,UTF-8详解