机器学习之算法部分(算法篇1)
目录
0.Introduction
1.K近邻算法--【分类算法】
1.1 K-近邻算法简介
1.1.1 K-近邻算法(KNN)概念
1.1.2 举例-电影类型分析
1.2 k近邻算法api初步使用
1.2.1 Scikit-learn工具介绍
1.2.2 K-近邻算法API
1.2.3 案例
1.2.4 问题
1.3 距离度量
1.3.1 欧式距离(Euclidean Distance)
1.3.2 曼哈顿距离(Manhattan Distance)
1.3.3 切比雪夫距离(Chebyshev Distance)
1.3.4 闵可夫斯基距离(Minkowski Distance)
1.3.5 标准化欧氏距离(Standardized EuclideanDistance)
1.3.6 余弦距离(Cosine Distance)
1.3.7 汉明距离(Hamming Distance)【了解】
1.3.8 杰卡德距离(Jaccard Distance)【了解】
1.3.9 马氏距离(Mahalanobis Distance)【了解】
1.4 k值的选择
1.5 kd树
1.5.1 kd树简介
1.5.2 构造方法
1.5.3 步骤
1.6 案例:鸢尾花种类预测--数据集介绍
1.6.1 案例:鸢尾花种类预测
1.6.2 scikit-learn中数据集介绍
1.7 特征工程-特征预处理
1.7.1 什么是特征预处理
1.7.2 归一化
1.7.3 标准化
1.8 案例:鸢尾花种类预测―流程实现
1.9 knn算法总结
1.10 交叉验证,网格搜索
1.10.1 交叉验证
1.10.2 网格搜索
1.10.3 交叉验证,网格搜索(模型选择与调优)API
1.10.4 鸢尾花案例增加K值调优
1.11 案例2:预测facebook签到位置
1.11.1 数据集介绍及下载
1.11.2 代码分析
1.11.3 总结
2.线性回归--【预测问题】
2.1 线性回归简介
2.1.1 线性回归应用场景
2.1.2 什么是线性回归
2.2 线性回归api初步使用
2.2.1 线性回归API
2.2.2 举例
2.3 数学:求导
2.3.1 常见函数的导数
2.3.2 导数的四则运算
2.3.3 练习
2.3.4 矩阵(向量)求导【了解]
2.4 线性回归的损失和优化
2.4.1 损失函数
2.4.2 优化算法
2.5 梯度下降法方法介绍
2.5.1 全梯度下降算法(FG)
2.5.2 随机梯度下降算法(SG)
2.5.3 小批量梯度下降算法(mini-batch)
2.5.4 随机平均梯度下降算法(SAG)
2.5.5 算法比较
2.5.6 梯度下降优化算法(拓展)
2.6 线性回归api再介绍
2.7 案例:波士顿房价预测
2.8 欠拟合和过拟合
2.8.1 定义
2.8.2 原因以及解决方法
2.8.3 正则化
2.8.4 维灾难【拓展知识】
2.9 正则化线性模型
2.9.1 Ridge Regression(岭回归,又名Tikhonovregularization)
2.9.2 Lasso Regression(Lasso回归)
2.9.3 Elastic Net(弹性网络)
2.9.4 Early Stopping[了解]
2.10 线性回归的改进-岭回归
2.10.1 API
2.10.2 观察正则化程度的变化,对结果的影响?
2.10.3 波士顿房价预测
2.11 模型的保存和加载
2.11.1 sklearn模型的保存和加载API
2.11.2 线性回归的模型保存加载案例
3.逻辑回归--【分类问题】
3.1 逻辑回归介绍
3.1.1 逻辑回归的应用场景
3.1.2 逻辑回归的原理
3.1.3 损失以及优化
3.2 逻辑回归api介绍
3.3 案例:癌症分类预测-良/恶性乳腺癌肿瘤预测
3.4 分类评估方法
3.4.1 分类评估方法
3.4.2 ROC曲线与AUC指标
3.5 ROC曲线的绘制
3.5.1 曲线绘制
3.5.2 意义
3.6 分类中解决类别不平衡问题
3.6.1 类别不平衡数据集基本介绍
3.6.2 解决类别不平衡数据方法介绍
4.决策树算法——>分类算法
4.1 决策树算法简介
4.2 决策树分类原理
4.2.1 熵
4.2.2 决策树的划分依据——信息增益
4.2.3 决策树的划分依据二——信息增益率
4.2.4 决策树的划分依据三----基尼值和基尼指数
4.2.5 小结
4.3 cart剪枝
4.3.1 为什么要剪枝
4.3.2 常用的减枝方法
4.4 特征工程-特征提取
4.4.1 特征提取
4.4.2 字典特征提取
4.4.3 文本提取
4.5 决策树算法api
4.6 案例:泰坦尼克号乘客生存预测
4.7 回归决策树
4.7.1 原理描述
4.7.2 算法描述
4.7.3 简单实例
4.7.4 小结
5.集成学习——预测、分类问题
5.1 集成学习算法简介
5.1.1 什么是集成学习
5.1.2 复习:机器学习的两个核心任务
5.1.3 集成学习中boosting和Bagging
5.1.4 小结
5.2 Bagging和随机森林
5.2.1 Bagging集成原理
5.2.2 随机森林构造过程
5.2.3 包外估计(Out-of-Bag Estimate)
5.2.4 随机森林api介绍
5.2.4 随机森林预测案例
5.2.5 bagging集成优点
5.2.6 小结
5.3 otto案例介绍 – Otto Group Product Classification Challenge
5.3.1 背景介绍
5.3.2 数据集介绍
5.3.3 评分标准
5.3.4 实现过程
5.4 Boosting
5.4.1 什么是Boosting
5.4.2 实现过程
5.4.3 bagging集成与boosting集成的区别
5.5 AdaBoost介绍
5.5.1 构造过程细节
5.5.2 关键点剖析
5.5.3 案例
5.5.4 api介绍
5.5.5 小结
5.6 GBDT介绍
5.6.1 Decision Tree: CART回归树
5.6.2 Gradient Boosting:拟合负梯度
5.6.3 GBDT算法原理
5.6.4 实例介绍
5.6.5 小结
6.聚类算法
6.1 认识聚类算法
6.1.1 聚类算法在现实中的应用
6.1.2 聚类算法的概念
6.1.3 聚类算法与分类算法最大的区别
6.1.4 小结
6.2 聚类算法api初步使用
6.2.1 api介绍
6.2.2 案例
6.2.3 小结
6.3 聚类算法实现流程
6.3.1 K-Means聚类步骤
6.3.2 案例练习
6.3.3 小结
6.4 模型评估
6.4.1 误差平方和(SSE \The sum of squares due to error)
6.4.2 “肘”方法 (Elbow method) — K值确定
6.4.3 轮廓系数法(Silhouette Coefficient)
6.4.4 CH系数(Calinski-Harabasz Index)
6.4.5 小结
6.5 算法优化
6.5.1 Canopy算法配合初始聚类
6.5.2 K-means++
6.5.3 二分k-means
6.5.4 k-medoids(k-中心聚类算法)
6.5.5 Kernel k-means(了解)
6.5.6 ISODATA
6.5.7 Mini Batch K-Means
6.5.8 小结
6.6 特征工程-特征降维
6.6.1 降维
6.6.2 特征选择
6.6.3 主成分分析
6.6.4 小结
6.7 案例:探究用户对物品类别的喜好细分
6.7.1 需求
6.7.2 分析
6.7.3 完整代码
0.Introduction
![]()
1.K近邻算法--【分类算法】
![]()
1.1 K-近邻算法简介
![]()
1.1.1 K-近邻算法(KNN)概念
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法,总体来说KNN算法是相对比较容易理解的算法。
- 定义:
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也鹿于这个类别。- 来源:
KNN算法最早是由Cover和Hart提出的一种分类算法。- 距离公式:
两个样本的距离可以通过如下公式计算,又叫欧式距离,关于距离公式会在后面进行讨论。
1.1.2 举例-电影类型分析
假设我们现在有几部电影:
![]()
其中?号电影不知道类别,如何去预测?我们可以利用KNN算法的思想:
![]()
分别计算每个电影和被预测电影的距离,然后求解:
![]()
一般K值取奇数,也不会选1个,具有偶然性。
1.2 k近邻算法api初步使用
机器学习流程复习:
1.获取数据集
2.数据基本处理
3.特征工程
4.机器学习
5.模型评估
1.2.1 Scikit-learn工具介绍
- Python语言的机器学习工具
- Scikit-learn包括许多知名的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API
- 目前稳定版本0.19.1
1.2.2 K-近邻算法API
- sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)
-n_neighbors:int,可选(默认=5) , k_neighbors查询默认使用的邻居数
1.2.3 案例
(1)步骤分析
1.获取数据集
2.数据基本处理(该案例中省略)
3.特征工程(该案例中省略)
4.机器学习
5.模型评估(该案例中省略)
(2)代码过程
![]()
1.2.4 问题
1.距离公式,除了欧式距离,还有哪些距离公式可以使用?
2.取K值的大小?
3.api中其他参数的具体含义?
1.3 距离度量
![]()
1.3.1 欧式距离(Euclidean Distance)
欧氏距离是最容易直观理解的距离度量方法我们小学、初中和高中接触到的两个点在空间中的距离一般都是指欧氏距离。
1.3.2 曼哈顿距离(Manhattan Distance)
在曼哈顿街区要从一个十字路口开车到另一个十字路口,驾驶距离显然不是两点间的直线距离。这个实际驾驶距离就是“曼哈顿距离”。曼哈顿距离也称为“城市街区距离"(City Block distance)。
1.3.3 切比雪夫距离(Chebyshev Distance)
国际象棋中,国王可以直行、横行、斜行,所以国王走一步可以移动到相邻8个方格中的任意一个。国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?这个距离就叫切比雪夫距离。
1.3.4 闵可夫斯基距离(Minkowski Distance)
闵氏距离不是一种距离,而是一组距离的定义,是对多个距离度量公式的概括性的表述。
小结:
![]()
1.3.5 标准化欧氏距离(Standardized EuclideanDistance)
标准化欧氏距离是针对欧氏距离的缺点而作的一种改进。
思路:既然数据各维分量的分布不一样,那先将各个分量都“标准化"到均值、方差相等。假设样本集X的均值(mean)为m,标准差(standard deviation)为s,X的“标准化变量”表示为:
如果将方差的倒数看成一个权重,也可称之为加权欧氏距离(Weighted Euclidean distance)。
1.3.6 余弦距离(Cosine Distance)
几何中,夹角余弦可用来衡量两个向量方向的差异;机器学习中,借用这一概念来衡量样本向量之间的差异。
- 二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式:
- 两个n维样本点a(x11,x12,...,x1n)和b(x21,x22,.. .,x2n)的夹角余弦为:
夹角余弦取值范围为[-1,1]。余弦越大表示两个向量的夹角越小,余弦越小表示两向量的夹角越大。当两个向量的方向重合时余弦取最大值1,当两个向量的方向完全相反余弦取最小值-1。
1.3.7 汉明距离(Hamming Distance)【了解】
两个等长字符串s1与s2的汉明距离为:将其中一个变为另外一个所需要作的最小字符替换次数。
汉明重量:是字符串相对于同群长度的零字符串的汉明距离,也就是说,它是字符串中非零的元素个数;对于二进制字符串来说,就是1的个数,所以11101的汉明重量是4。因此,如果向量空间中的元素a和b之间的汉明距离等于它们汉明重量的差a-b。
应用:汉明重量分析在包括信息论、编码理论、密码学等领域都有应用。比如在信息编码过程中,为了增强容错性,应使得编码间的最小汉明距离尽可能大。但是,如果要比较两个不同长度的字符串,不仅要进行替换,而且要进行插入与删除的运算,在这种场合下,通常使用更加复杂的编辑距离等算法。
1.3.8 杰卡德距离(Jaccard Distance)【了解】
杰卡德相似系数(Jaccard similarity coefficient):两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示:
杰卡德距离(Jaccard Distance):与杰卡德相似系数相反,用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度:
1.3.9 马氏距离(Mahalanobis Distance)【了解】
下图有两个正态分布图,它们的均值分别为a和b,但方差不一样,则图中的A点离哪个总体更近?或者说A有更大的概率属于谁?显然,A离左边的更近,A属于左边总体的概率更大,尽管A与a的欧式距离远一些。这就是马氏距离的直观解释。
马氏距离是基于样本分布的一种距离。
马氏距离是由印度统计学家马哈拉诺比斯提出的,表示数据的协方差距离。它是一种有效的计算两个位置样本集的相似度的方法。
与欧式距离不同的是,它考虑到各种特性之间的联系,即独立于测量尺度。
1.4 k值的选择
K值过小:容易受到异常点的。 ==> 过拟合
K值过大:受到样本均衡的问题 ==> 欠拟合
近似误差:对现有训练集的训练误差,关注训练集,如果近似误差过小可能会出现过拟合的现象,对现有的训练集能有很好的预测,但是对未知的测试样本将会出现较大偏差的预测。模型本身不是最接近最佳模型。
估计误差:可以理解为对测试集的测试误差,关注测试集,估计误差小说明对未知数据的预测能力好,模型本身最接近最佳模型。【估计误差好才是真的好】
1.5 kd树
问题导入:
实现k近邻法时,主要考虑的问题是如何对训练数据进行快速k近邻搜索。
这在特征空间的维数大及训练数据容量大时尤其必要。
k近邻法最简单的实现是线性扫描(穷举搜索),即要计算输入实例与每一个训练实例的距离。计算并存储好以后,再查找K近邻。当训练集很大时,计算非常耗时。
为了提高KNN搜索的效率,可以考虑使用特殊的结构存储训练数据,以减小计算距离的次数。
1.5.1 kd树简介
(1)什么是kd树
根据KNN每次需要预测一个点时,我们都需要计算训练数据集里每个点到这个点的距离,然后选出距离最近的k个点进行投票。当数据集很大时,这个计算成本非常高,针对N个样本,D个特征的数据集,其算法复杂度为O (DN^2)。
kd树:为了避免每次都重新计算一遍距离,算法会把距离信息保存在一棵树里,这样在计算之前从树里查询距离信息,尽量避免重新计算。其基本原理是,如果A和B距离很远,B和C距离很近,那么A和C的距离也很远。有了这个信息,就可以在合进约时候跳过距离远的点。
这样优化后的算法复杂度可降低到O(DNlog (N))。感兴趣的读者可参阅论文∶Bentley,J.L.,Communications of the ACM (1975)。
1989年,另外一种称为Ball Tree的算法,在kd Tree的基础上对性能进一步进行了优化。感兴趣的读者可以搜索Five balltree construction algorithms来了解详细的算法信息。
(2)原理
黄色的点作为根节点,上面的点归左子树,下面的点归右子树,接下来再不断地划分,分割的那条线叫做分割超平面(splitting hyperplane) ,在一维中是一个点,二维中是线,三维的是面。
黄色节点就是Root节点,下一层是红色,再下一层是绿色,再下一层是蓝色。
1.5.2 构造方法
(1)构造根结点,使根结点对应于K维空间中包含所有实例点的超矩形区域;
(2)通过递归的方法,不断地对k维空间进行切分,生成子结点。在超矩形区域上选择一个坐标轴和在此坐标轴上的一个切分点,确定一个超平面,这个超平面通过选定的切分点并垂直于选定的坐标轴,将当前超矩形区域切分为左右两个子区域(子结点);这时,实例被分到两个子区域。
(3)上述过程直到子区域内没有实例时终止(终止时的结点为叶结点)。在此过程中,将实例保存在相应的结点上。
(4)通常,循环的选择坐标轴对空间切分,选择训练实例点在坐标轴上的中位数为切分点,这样得到的kd树是平衡的(平衡二叉:它是一棵空树,或其左子树和右子树的深度之差的绝对值不超过1,且它的左子树和右子树都是平衡二叉树)。KD树中每个节点是一个向量,和二叉树按照数的大小划分不同的是,KD树每层需要选定向量中的某一维,然后根据这一维按左小右大的方式划分数据。在构建KD树时,关键需要解决2个问题:
-选择向量的哪一维进行划分;-如何划分数据;
第一个问题简单的解决方法可以是随机选择某一维或按顺序选择,但是更好的方法应该是在数据比较分散的那一维进行划分(分散的程度可以根据方差来衡量)。好的划分方法可以使构建的树比较平衡,可以每次选择中位数来进行划分,这样问题2也得到了解决。
1.5.3 步骤
样本集{(2,3),(5,4), (9,6),(4,7),(8,1),(7,2)}
1.6 案例:鸢尾花种类预测--数据集介绍
本实验介绍了使用Python进行机器学习的一些基本概念。在本案例中,将使用K-NearestNeighbor (KNN)算法对鸢尾花的种类进行分类,并测量花的特征。
本案例目的:
1.遵循并理解完整的机器学习过程。
2.对机器学习原理和相关术语有基本的了解。3.了解评估机器学习模型的基本过程。
![]()
1.6.1 案例:鸢尾花种类预测
lris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。lris也称鸢尾花卉数据集,是一类多重变量分析的数据集。关于数据集的具体介绍:
该虹膜数据集包含150行数据,包括来自每个的三个相关鸢尾种类50个样品:山鸢尾,虹膜锦葵,和变色鸢尾。
1.6.2 scikit-learn中数据集介绍
(1)scikit-learn数据集API介绍
- sklearn.datasets
-加载获取流行数据集
-datasets.load_*()
-获取小规模数据集,数据包含在datasets里
-datasets.fetch_*(data_home=None)
-获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数
据集下载的目录,默认是~/scikit _learn_data/
sklearn小数据集:
- datasets.load_lris()
加载并返回鸢尾花数据集
sklearn大数据集:
- sklearn.datasets.fetch_20newsgroups(data_home=None,subset='train')
-subset:'train' 或者'test','all',可选,选择要加载的数据集。
-训练集的“训练”,测试集的“测试”,两者的“全部”
#导入数据集
from sklearn.datasets import load_iris,fetch_20newsgroups#1.数据集获取
#1.1 小数据集
iris=load_iris()
print(iris)#1.2 大数据集
news=fetch_20newsgroups()
print(news)(2)sklearn数据集返回值介绍
- load和fetch返回的数据类型datasets.base.Bunch(字典格式)
-data:特征数据数组,是[n_samples ' n_features]的二维numpy.ndarray数组
-target:标签数组,是n_samples 的一维numpy.ndarray 数组
-DESCR:数据描述
-feature_names:特征名,新闻数据,手写数字、回归数据集没有
-target_names:标签名
#导入数据集
from sklearn.datasets import load_iris,fetch_20newsgroups#获取鸢尾花数据集
iris=load_iris()
print('鸢尾花数据集返回值:\n',iris)
#返回值是一个继承自字典的Bench
print('鸢尾花的特征值:\n',iris['data'])#或者iris.data
print('鸢尾花的目标值:\n',iris.target)
print('鸢尾花特征的名字:\n',iris.feature_names)
print('鸢尾花目标值的名字:\n',iris.target_names)
print('鸢尾花数据集的描述:\n',iris.DESCR)![]()
(3)查看数据分布
通过创建一些图,以查看不同类别是如何通过特征来区分的。在理想情况下,标签类将由一个或多个特征对完美分隔。在现实世界中,这种理想情况很少会发生。
seaborn介绍:
- Seaborn 是基于Matplotlib核心库进行了更高级的API封装,可以让你轻松地画出更漂亮的图形。而Seaborn的漂亮主要体现在配色更加舒服、以及图形元素的样式更加细腻。
- 安装pip3 install seaborn
- seaborn.lmplot()是一个非常有用的方法,它会在绘制二维散点图时,自动完成回归拟合--sns.Implot()里的x, y分别代表横纵坐标的列名
-data= 是关联到数据集,
-hue=* 代表按照species即花的类别分类显示
-fit_reg=是否进行线性拟合。
#导入数据集
from sklearn.datasets import load_iris,fetch_20newsgroups
#
#获取鸢尾花数据集
iris=load_iris()import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd#把数据转换成dataframe的格式
iris_data=pd.DataFrame(iris['data'],columns=['Sepal_Length','Sepal_Width','Petal_Length','Petal_Width'])
iris_data['Species']=iris.target
print(iris_data)
def plot_iris(iris,col1,col2):sns.lmplot(x=col1,y=col2,data=iris,hue='Species',fit_reg=False)#fit_reg:取消线plt.xlabel(col1)plt.ylabel(col2)plt.title('鸢尾花种类分布图')plt.show()plot_iris(iris_data,'Petal_Width','Sepal_Length')(4)数据集的划分
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集:70%80%75%
- 测试集:30%20%25%
数据集划分api:
- sklearn.model_selection.train_test_split(arrays,*options)
-x:数据集的特征值
-y:数据集的标签值
-test_size:测试集的大小,一般为float,百分比
-random_state:随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
-return:测试集特征训练集特征值值,训练标签,测试标签(默认随机取)
from sklearn.datasets import load_iris,fetch_20newsgroups
from sklearn.model_selection import train_test_splitiris=load_iris()x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.2,random_state=22)
print('训练集的特征值是:\n',x_train)
print('训练集的目标值是:\n',x_test)
print('训练集的特征值是:\n',y_train)
print('训练集的目标值是:\n',y_test)
print('训练集的特征值形状:\n',y_train.shape)
print('训练集的目标值形状:\n',y_test.shape)1.7 特征工程-特征预处理
1.7.1 什么是特征预处理
定义:通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程。
为什么我们要进行归一化/标准化?
- 特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其它的特征。
包含内容(数值型数据的无量纲化):
- 归一化
- 标准化
特征预处理API:
- sklearn. preprocessing
1.7.2 归一化
定义:通过对原始数据进行变换把数据映射到(默认为[0,1])之间。
公式:
API:
- sklearn.preprocessing.MinMaxScaler (feature_range=(0,1).….)
-MinMaxScalar.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
-返回值:转换后的形状相同的array
from sklearn.preprocessing import MinMaxScaler
import pandas as pddata=pd.read_csv('./data/dating.txt')#1.归一化
#1.1 实例化一个转换器
transfer=MinMaxScaler(feature_range=(0,1))
#1.2 调用fit_transfrom方法
minmax_data=transfer.fit_transform(data[['milage','Liters','Consumtime']])
注意:最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性(稳定性)较差,只适合传统精确小数据场景。==> 现在基本淘汰了
1.7.3 标准化
定义:通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内。
公式:
from sklearn.preprocessing import StandardScaler
import pandas as pddata=pd.read_csv('./data/dating.txt')#2.标准化
#2.1 实例化一个转换器
transfer=StandardScaler()
#2.2 调用fit_transfrom方法
minmax_data=transfer.fit_transform(data[['milage','Liters','Consumtime']])
- 对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变
- 对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。
1.8 案例:鸢尾花种类预测―流程实现
![]()
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier#1.获取数据
iris=load_iris()
#2.数据基本处理
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.2)
#3.特征工程-标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.fit_transform(x_test)
#4.机器学习(模型训练)
estimator=KNeighborsClassifier(n_neighbors=9)
estimator.fit(x_train,y_train)
#5.模型评估
#方法1:对比真实值和预测值
y_predict=estimator.predict(x_test)
print('对比真实值和预测值:\n',y_predict==y_test)
#方法2:直接计算准确率
score=estimator.score(x_test,y_test)
print('准确率为:\n',score)
![]()
1.9 knn算法总结
优点:
- 简单有效
- 重新训练的代价低
- 适合类域交叉样本
KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。- 适合大样本自动分类
该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。缺点:
- 惰性学习
KNN算法是懒散学习方法(lazy learning,基本上不学习),一些积极学习的算法要快很多- 类别评分不是规格化
不像一些通过概率评分的分类- 输出可解释性不强
例如决策树的输出可解释性就较强- 对不均衡的样本不擅长
当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。- 计算量较大
目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
1.10 交叉验证,网格搜索
1.10.1 交叉验证
交叉验证:将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成4份,其中一份作为验证集。然后经过4次(组)的测试,每次都更换不同的验证集。即得到4组模型的结果,取平均值作为最终结果。又称4折交叉验证。
我们之前知道数据分为训练集和测试集,但是为了让从训练得到模型结果更加准确。做以下处理:
- 训练集:训练集+验证集
- 测试集:测试集
交叉验证目的:为了让被评估的模型更加准确可信。
注意:交叉验证不能提高模型的准确率
问题:那么这个只是对于参数得出更好的结果,那么怎么选择或者调优参数呢?
1.10.2 网格搜索
通常情况下,有很多参数是需要手动指定的〈如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。
1.10.3 交叉验证,网格搜索(模型选择与调优)API
![]()
1.10.4 鸢尾花案例增加K值调优
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier#1.获取数据
iris=load_iris()
#2.数据基本处理
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.2)
#3.特征工程-标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.fit_transform(x_test)#4.机器学习(模型训练)
#4.1 实例化一个估计器
estimator=KNeighborsClassifier(n_neighbors=5)
#4.2 调用交叉验证网格搜索
param_grid={#超参数字典"n_neighbors":[1,3,5,7,9]
}
estimator=GridSearchCV(estimator,param_grid=param_grid,cv=10,n_jobs=-1)
#4.3 模型训练
estimator.fit(x_train,y_train)#5.模型评估
#5.1 输出预测值
y_predict=estimator.predict(x_test)
print('对比真实值和预测值:\n',y_predict==y_test)
#5.2 输出准确率
score=estimator.score(x_test,y_test)
print('准确率为:\n',score)
#5.3 其他评价指标
print('最好的模型:\n',estimator.best_estimator_)
print('最好的结果:\n',estimator.best_score_)
print('整体模型结果:\n',estimator.cv_results_)![]()
1.11 案例2:预测facebook签到位置
Facebook V Results: Predicting Check Ins 是Facebook在Kaggle上的一个机器学习工程竞赛数据集。https://www.kaggle.com
1.11.1 数据集介绍及下载
这项比赛的目的是预测一个人想签到哪个地方。为了实现这一目的,Facebook创建了一个人工世界,由10公里乘10公里的正方形中的100,000多个地方组成。对于给定的一组坐标,程序员的任务是返回最可能的位置的排名列表。数据经过伪造,类似于来自移动设备的位置信号,使您有一种处理真实数据(复杂的数值和嘈杂的值)所需的风味。不一致和错误的位置数据可能会破坏Facebook Check In等服务的体验。
训练和测试数据集是根据时间划分的,测试数据中的公共/私人排行榜是随机划分的。 此数据集中没有人的概念。 所有row_id都是事件,而不是人员。
数据特征:
- row_id:id of the check-in event 标记事件的id
- x y: coordinates 用户的位置
- accuracy: location accuracy 定位准确性
- time: 时间戳
- place_id: id of the business, this is the target you are predicting
数据集下载:百度网盘 请输入提取码
提取码:4h5k
1.11.2 代码分析
![]()
首先我们导入本次实战所要用到的库:
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split,GridSearchCV使用pandas来进行数据的写入,由于数据是以csv的格式存放的。所以我采用了pandas.read_csv函数来进行写入操作:
#1.读取数据
facebook=pd.read_csv('./Datas/train.csv')第一次输入数据时,需要对数据进行处理以提高最后模型的预测的准确率。
由于时间是以时间戳的格式输入的,所以我们将时间转换为年月日的格式方便后续计算。并将日、时、周作为特征值构造新的特征:
#2.处理数据
#2.1 缩小数据
facebook_data=facebook.query('x>1.0 & x<1.25 & y>2.5 & y<2.75')
#2.2 转换时间戳为年月日格式
time=pd.to_timedelta(facebook_data['time'],unit='s')
#把日期格式转换为字典数据
time=pd.DataFrame(time)
#构造特征
facebook_data['day']=time.day
facebook_data['hour']=time.hour
facebook_data['weekday']=time.weekday由于很多地方签到的数量都很少,删除一些签到数量很少的地方可以减少计算负荷,加快效率。
#2.3 去掉签到较少的地方
place_count=facebook_data.groupby('place_id').count()
place_count=place_count[place_count.row_id>3]
facebook_data=facebook_data[facebook_data['place_id'].isin(place_count.index)]
#2.4 确定特征值和目标值
x=facebook_data[['x','y','accuracy','day','hour','weekday']]
y=facebook_data['place_id']
#2.5 分割数据集
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=22)这时,我们将处理好的数据输出可以看到,此时的数据是:
x y place_id day hour weekday
600 1.2214 2.7023 6683426742 1 18 3
957 1.1832 2.6891 6683426742 10 2 5
4345 1.1935 2.6550 6889790653 5 15 0
4735 1.1452 2.6074 6822359752 6 23 1
5580 1.0089 2.7287 1527921905 9 11 4
... ... ... ... ... ... ...
29100203 1.0129 2.6775 3312463746 1 10 3
29108443 1.1474 2.6840 3533177779 7 23 2
29109993 1.0240 2.7238 6424972551 8 15 3
29111539 1.2032 2.6796 3533177779 4 0 6
29112154 1.1070 2.5419 4932578245 8 23 3[16918 rows x 6 columns]
这时,我们要在特征的层面上对数据进一步处理,也就是做特征工程。
K-近邻算法一定要做特征标准化处理,因为K-NN算法在计算时是采用欧氏距离来测量每一个点之间在特征空间的距离。要采用标准化来降低某几个大特征对最后结果的影响。
# 特征工程(标准化)
std = StandardScaler()
# 对训练集和测试集的特征值进行标注化
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
特征工程处理完后,在进行算法建模之前,我们要将数据分割为数据集和测试集。来进行模型评估。
#3.特征工程(标准化)
#3.1 实例化一个转换器
transfer=StandardScaler()
#3.2 调用fit_transform
x_train=transfer.fit_transform(x_train)
x_test=transfer.fit_transform(x_test)最后使用K-NN算法来建立模型,进行预测。
#4.机器学习-knn+cv
#4.1 实例化一个估计器
estimator=KNeighborsClassifier()
#4.2 调用GridSearchCV
param_grid={'n_neighbors':[1,3,5,7,9]}
estimator=GridSearchCV(estimator,param_grid=param_grid,cv=5)
#4.3 模型训练
estimator.fit(x_train,y_train)#5.模型评估
#5.1 基本评估方式
score=estimator.score(x_test,y_test)
print('最后预测的准确率为:\n',score)y_predict=estimator.predict(x_test)
print('最后的预测值为:\n',y_predict)
print('预测值与真实值的对比情况:\n',y_predict==y_test)最后,我们得到的结果为:
准确率: 0.4949408983451537
1.11.3 总结
K-NN算法非常简单,但是K-NN算法的性能有一定的局限。当计算一个点时,要计算该点与特征空间其他所有点的距离才能找到几个距离最近的点,所以K-NN算法的时间复杂度是非常大的。
虽然我们还可以通过一些调参的手段又优化模型,提高准确率。但那都是治标不治本。在Kaggle上,榜单前十的大神选手的准确率也不过60-62这个程度,再难得以提升。
2.线性回归--【预测问题】
![]()
2.1 线性回归简介
2.1.1 线性回归应用场景
- 房价预测
- 销售额度预测
- 贷款额度预测
2.1.2 什么是线性回归
(1)定义与公式
线性回归(Linear regression)是利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式。
特点:只有一个自变量的情况称为单变量回归,多于一个自变量情况的叫做多元回归。
(2)线性回归的特征与目标的关系分析
线性回归当中主要有两种模型,一种是线性关系,另一种是非线性关系。在这里我们只能画一个平面更好去理解,所以都用单个特征或两个特征举例子。
- 线性关系
- 非线性关系
2.2 线性回归api初步使用
2.2.1 线性回归API
- sklearn.linear_model.LinearRegression()
LinearRegression.coef_:回归系数
2.2.2 举例
![]()
(1)步骤分析
![]()
(2)代码过程
#导入模块
from sklearn.linear_model import LinearRegression#构造数据集
x=[[80,86],[82,80],[85,78],[90,90],[86,82],[82,90],[78,80],[92,94]
]
y=[84.2,80.6,80.1,90,83.2,87.6,79.4,93.4]#机器学习-模型训练
#实例化api
estimator=LinearRegression()
#使用fit方法训练
estimator.fit(x,y)
#查看系数值
coef=estimator.coef_
print('系数是:',coef)#预测
result=estimator.predict([[100,80]])
print('预测结果是:\n',result)
![]()
2.3 数学:求导
2.3.1 常见函数的导数
![]()
2.3.2 导数的四则运算
![]()
2.3.3 练习
![]()
2.3.4 矩阵(向量)求导【了解]
![]()
2.4 线性回归的损失和优化
2.4.1 损失函数
![]()
如何去减少这个损失,使我们预测的更加准确些?既然存在了这个损失,我们一直说机器学习有自动学习的功能,在线性回归这里更是能够体现。这里可以通过一些优化方法去优化(其实是数学当中的求导功能)回归的总损失!!!
2.4.2 优化算法
如何去求模型当中的W,使得损失最小?(目的是找到最小损失对应的W值)线性回归经常使用的两种优化算法:
- 正规方程
- 梯度下降
(1)正规方程
- 理解:x为特征值矩阵,y为目标值矩阵,w是权重系数。直接求到最好的结果
- 缺点:当特征过多过复杂时,求解速度太慢并且得不到结果
正规方程求解步骤:
正则方程的推导过程:
(为什么结果不是
,因为方阵才有逆矩阵,特征矩阵未必是方阵,所以乘以逆矩阵变为方阵矩阵)
方法二:
https://www.jianshu.com/p/2b6633bd4d47
(2)梯度下降法
梯度下降法的基本思想可以类比为一个下山的过程。
假设这样一个场景:一个人被困在山上,需要从山上下来(i.e.找到山的最低点,也就是山谷)。但此时山上的浓雾很大,导致可视度很低。因此,下山的路径就无法确定,他必须利用自己周围的信息去找到下山的路径。这个时候,他就可以利用梯度下降算法来帮助自己下山。具体来说就是,以他当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着山的高度下降的地方走,(同理,如果我们的目标是上山,也就是爬到山顶,那么此时应该是朝着最陡峭的方向往上走)。然后每走一段距离,都反复采用同一个方法,最后就能成功的抵达山谷。
梯度下降的基本过程就和下山的场景很类似。
首先,我们有一个可微分的函数。这个函数就代表着一座山。我们的目标就臧找到这个函数的最小值,也就是山底。
根据之前的场景假设,最快的下山的方式就是找到当前位置最陡峭的方向,然后沿着此方向向下走,对应到函数中,就是找到给定点的梯度,然后朝着梯度相反的方向,就能让函数值下降的最快!因为梯度的方向就是函数之变化最快的方向。所以,我们重复利用这个方法,反复求取梯度,最后就能到达局部的最小值,这就类似于我们下山的过程。而求取梯度就确定了最陡峭的方向,也就是场景中测量方向的手段。
梯度的概念:
梯度是微积分中一个很重要的概念
- 在单变量的函数中,梯度其实就是函数的微分,代表着函数在某个给定点的切线的斜率。
- 在多变量函数中,梯度是一个向量,向量有方向,梯度的方向就指出了函数在给定点的上升最快的方向,所以反方向就是梯度下降最快的方向。
这也就说明了为什么我们需要千方百计的求取梯度!我们需要到达山底,就需要在每一步观测到此时最陡峭的地方,梯度就恰巧告诉了我们这个方向。梯度的方向是函数在给定点上升最快的方向,那么梯度的反方向就是函数在给定点下降最快的方向,这正是我们所需要的。所以我们只要沿着梯度的反方向一直走,就能走到局部的最低点!
梯度下降举例:
如图,经过四次的运算,也就是走了四步,基本就抵达了函数的最低点,也就是山底。
公式:
的含义:
a在梯度下降算法中被称作为学习率或者步长,意味着我们可以通过α来控制每一步走的距离,以保证不要步子跨的太大扯着蛋,哈哈,其实就是不要走太快,错过了最低点。同时也要保证不要走的太慢,导致太阳下山了,还没有走到山下。所以a的选择在梯度下降法中往往是很重要的! a不能太大也不能太小,太小的话,可能导致迟迟走不到最低点,太大的话,会导致错过最低点!
- 为什么梯度要乘以一个负号?
梯度前加一个负号,就意味着朝着梯度相反的方向前进!我们在前文提到,梯度的方向实际就是函数在此点上升最快的朽向!而我们需要朝着下降最快的方向走,自然就是负的梯度的方向,所以此处需要加上负号。
(3)正规方程和梯度下降的对比
![]()
选择:
- 小规模数据:
-LinearRegression(不能解决拟合问题)
-岭回归- 大规模数据:-SGDRegressor
2.5 梯度下降法方法介绍
上一节中给大家介绍了最基本的梯度下降法实现流程,常见的梯度下降算法有:
- 全梯度下降算法(Full gradient descent)
- 随机梯度下降算法(Stochastic gradient descent)
- 随机平均梯度下降算法(Stochastic average gradient descent)
- 小批量梯度下降算法(Mini-batch gradient descent) ,
它们都是为了正确地调节权重向量,通过为每个权重计算一个梯度,从而更新权值,使目标函数尽可能最小化。其差别在于样本的使用方式不同。
![]()
2.5.1 全梯度下降算法(FG)
计算训练集所有样本误差,对其求和再取平均值作为目标函数。
权重向量沿其梯度相反的方向移动,从而使当前目标函数减少得最多。
因为在执行每次更新时,我们需要在整个数据集上计算所有的梯度,所以批梯度下降法的速度会很慢,同时,批梯度下降法无法处理超出内存容量限制的数据集。
批梯度下降法同样也不能在线更新模型,即在运行的过程中,不能增加新的样本。
其是在整个训练数据集上计算损失函数关于参数0的梯度:
2.5.2 随机梯度下降算法(SG)
由于FG每迭代更新一次权重都需要计算所有样本误差,而实际问题中经常有上亿的训练样本,故效率偏低,且容易陷入局部最优解,因此提出了随机梯度下降算法。
其每轮计算的目标函数不禹是全体样本误差,而仅是单个样本误差,即每次只代入计算一个样本目标函数的梯度来更新权重,再取下一个样本重复此过程,直到损失函数值停止下降或损失函数值小于某个可以容忍的阈值。
此过程简单,高效,通常可以较好地避免更新迭代收敛到局部最优解。其迭代形式为
2.5.3 小批量梯度下降算法(mini-batch)
小批量梯度下降算法是FG和SG的折中方案,在一定程度上兼顾了以上两种方法的优点。每次从训练样本集上随机抽取一个小样本集(部分),在抽出来的小样本集上采用FG迭代更新权重。
被抽出的小样本集所含样本点的个数称为batch_size,通常设置为2的幂次方,更有利于GPU加速处理。
特别的,若batch_size=1,则变成了SG;若batch_size=n,则变成了FG.其迭代形式为
2.5.4 随机平均梯度下降算法(SAG)
在SG方法中,虽然避开了运算成本大的问题,但对于大数据训练而言,SG效果常不尽如人意,因为每一轮梯度更新都完全与上一轮的数据和梯度无关。
随机平均梯度算法克服了这个问题,在内存中为每一个样本都维护一个旧的梯度,随机选择第i个样本来更新此样本的梯度,其他样本的梯度保持不变,然后求得所有梯度的平均值,进而更新了参数。
如此,每一轮更新仅需计算一个样本的梯度,计算成本等同于SG,但收敛速度快得多。
2.5.5 算法比较
为了比对四种基本梯度下降算法的性能,我们通过一个逻辑二分类实验来说明。本文所用的Adult数据集来自UCI公共数据库〈http://archive.ics.uci.edu/ml/datasets/Adult)。数据集共有15081条记录,包括“性别""年龄""受教育情况""每周工作时常"等14个特征,数据标记列显示“年薪是否大于50000美元”。我们将数据集的80%作为训练集,剩下的20%作为测试集,使用逻辑回归建立预测模型,根据数据点的14个特征预测其数据标记(收入情况)。
以下6幅图反映了模型优化过程中四种梯度算法的性能差异。
结论:
- FG方法由于它每轮更新都要使用全体数据集,故花费的时间成本最多,内存存储最大。
- SAG在训练初期表现不佳,优化速度较慢。这是因为我们常将初始梯度设为0,而SAG每轮梯度更新都结合了上一轮梯度值。
- 综合考虑迭代次数和运行时间,SG表现性能都很好,能在训练初期快速摆脱初始梯度值,快速将平均损失函数降到很低。但要注意,在使用SG方法时要慎重选择步长,否则容易错过最优解。
- mini-batch结合了SG的“胆大”和FG的“心细”,从6幅图像来看,它的表现也正好居于SG和FG二者之间。在目前的机器学习领域,mini-batch是使用最多的梯度下降算法,正是因为它避开了FG运算效率低成本大和SG收敛效果不稳定的缺点。
- SAG>mini-batch,FG和SG一般不会使用
2.5.6 梯度下降优化算法(拓展)
以下这些算法主要用于深度学习优化:
动量法:
- 其实动量法(SGD with monentum)就是SAG的姐妹版。
- SAG是对过去K次的梯度求平均值
- SGD with monentum是对过去所有的梯度求加权平均
Nesterov加速梯度下降法:
- 类似于一个智能球,在重新遇到斜率上升时候,能够知道减速
Adagrad:
- 让4句率使用参数
- 对于出现次数较少的特征,我们对其采用更大的学习率,对于出现次数较多的特征,我们对其采用较小的学习率。
Adadelta:
- Adadelta是Adagrad的一种扩展算法,以处理Adagrad学习速率单调递减的问题。·
RMSProp:
- 其结合了梯度平方的指数移动平均数来调节学习率的变化。
- 能够在不稳定(Non-Stationary)的目标函数情况下进行很好地收敛。
Adam:
- 结合AdaGrad和RMSProp两种优化算法的优点。
- 是一种自适应的学习率算法
参考链接:https://blog.csdn.net/google19890102/article/details/69942970
2.6 线性回归api再介绍
sklearn.linear_model.LinearRegression(fit_intercept=True)
- 通过正规方程优化
- fit_intercept:是否计算偏置
- LinearRegression.coef_:回归系数
- LinearRegression.intercept_:偏置
sklearn.linear_model.SGDRegressor(loss= squared_loss" , fit_intercept=True, learning_rate='invscaling', eta0=0.01)
- SGDRegressor类实现了随机梯度下降学习,它支持不同的loss函数和正则化惩罚项来拟合线性回归模型。
- loss:损失类型
loss=”squared_loss”:普通最小二乘法- fit_intercept:是否计算偏置
- learning_rate:string, optional
-学习率填充
-'constant':eta = eta0 【不推荐】
-'optimal': eta = 1.0/ (alpha * (t+ t0)) [default]
-"invscaling" : eta = eta0 / pow(t,power_t)
-power_t=0.25:存在父类当中
-对于一个常数值的学习率来说,可以使用learning_rate='constant',并使用eta0来指定学习率。- SGDRegressor.coef_:回归系数。
- SGDRegressor.intercept_:偏置
![]()
2.7 案例:波士顿房价预测
1.活动背景:
波士顿房地产市场竞争激烈,而你想成为该地区最好的房地产经纪人。为了更好地与同行竞争,你决定运用机器学习的一些基本概念,帮助客户为自己的房产定下最佳售价。幸运的是,你找到了波士顿房价的数据集,里面聚合了波士顿郊区包含多个特征维度的房价数据。你的任务是用可用的工具进行统计分析,并基于分析建立优化模型。这个模型将用来为你的客户评估房产的最佳售价。
2.数据介绍:
给定的这些特征,是专家们得出的影响房价的结果属性。我们此阶段不需要自己去探究特征是否有用,只需要使用这些特征。到后面量化很多特征需要我们自己去寻找
3.分析:
回归当中的数据大小不一致,是否会导致结果影响较大。所以需要做标准化处理。
- 数据分割与标准化处理
- 回归预测
- 线性回归的算法效果评估
4.回归性能评估:
均方误差(Mean Squared Error)MSE)评价机制:
sklearn.metrics.mean_squared_error(y_true, y_pred)
- 均方误差回归损失
- y_true:真实值
- y_pred:预测值
- return:浮点数结果
5.代码1-正规方程预测:
from sklearn.datasets import load_boston#数据 from sklearn.model_selection import train_test_split#数据集划分 from sklearn.preprocessing import StandardScaler#标准化数据 from sklearn.linear_model import LinearRegression#模型建立 from sklearn.metrics import mean_squared_error#模型评估def linear_model1():'''正规方程:return:None'''#1.获取数据boston=load_boston()#2.数据基本处理#2.1 数据集划分x_train,x_test,y_train,y_test=train_test_split(boston.data,boston.target,test_size=0.2)#3.特征工程标准化transfer=StandardScaler()x_train=transfer.fit_transform(x_train)x_test=transfer.fit_transform(x_test)#4.机器学习(线性规划)estimator=LinearRegression()estimator.fit(x_train,y_train)#5.模型评估#5.1 预测值和准确率y_pre=estimator.predict(x_test)print('预测值为:\n',y_pre)score=estimator.score(x_test,y_test)print('准确率:\n',score)#5.2 均方误差ret=mean_squared_error(y_test,y_pre)print('均方误差是:\n',ret)if __name__ == '__main__':linear_model1()
6.代码2-梯度下降法预测:
from sklearn.datasets import load_boston#数据 from sklearn.model_selection import train_test_split#数据集划分 from sklearn.preprocessing import StandardScaler#标准化 from sklearn.linear_model import SGDRegressor#模型训练 from sklearn.metrics import mean_squared_error#评估def linear_model2():'''梯度下降法预测波士顿房价:return:None'''# 1.获取数据boston = load_boston()# 2.数据基本处理# 2.1 数据集划分x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, test_size=0.2)# 3.特征工程标准化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.fit_transform(x_test)# 4.机器学习(线性回归)estimator = SGDRegressor(max_iter=1000,learning_rate='constant',eta0=0.0001)#学习率为固定值【不推荐】estimator.fit(x_train, y_train)print('这个模型的偏置为:\n',estimator.intercept_)# 5.模型评估# 5.1 预测值和准确率y_pre = estimator.predict(x_test)print('预测值为:\n', y_pre)score = estimator.score(x_test, y_test)print('准确率:\n', score)# 5.2 均方误差ret = mean_squared_error(y_test, y_pre)print('均方误差是:\n', ret)if __name__ == '__main__':linear_model2()
2.8 欠拟合和过拟合
![]()
2.8.1 定义
过拟合:一个假设在训练数据上能够获得比其他假设更好的拟合,但是在测试数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。(模型过于复杂)
欠拟合:一个假设在训练数据上不能获得更好的拟合,并且在测试数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)
那么是什么原因导致模型复杂?线性回归进行训练学习的时候变成模型会变得复杂,这里就对应前面再说的线性回归的两种关系,非线性关系的数据,也就是存在很多无用的特征或者现实中的事物特征跟目标值的关系并不是简单的线性关系。
2.8.2 原因以及解决方法
1.欠拟合原因以及解决办法:
原因:学习到数据的特征过少解决办法:
添加其他特征项,有时候我们模型出现欠拟合的时候是因为特征项不够导致的,可以添加其他特征项来很好地解决。例如,“组合”、“泛化”、“相关性”三类特征是特征添加的重要手段,无论在什么场景,都可以照葫芦画瓢,总会得到意想不到的效果。除上面的特征之外,“上下文特征”、“平台特征"等等,都可以作为特征添加的首选项。
- 添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强。
2.过拟合原因以及解决办法:
原因:原始特征过多,存在一些嘈杂特征,模型过于复杂是因为模型尝试去兼顾各个测试数据点。解决办法:
- 重新清洗数据,导致过拟合的一个原因也有可能是数据不纯导致的,如果出现了过拟合就需要我们重新清洗数据。
- 增大数据的训练量,还有一个原因就是我们用于训练的数据量太小导致的,训练数据占总数据的比例过小。
- 正则化
- 减少特征维度,防止维灾难
2.8.3 正则化
1.正则化定义:
在解决回归过拟合中,我们选择正则化。但是对于其他机器学习算法如分类算法来说也会出现这样的问题,除了一些算法本身作用之外(决策树、神经网络),我们更多的也是去自己做特征选择,包括之前说的删除、合并一些特征。
如何解决:
在学习的时候,数据提供的特征有些影响模型复杂度或者这个特征的数据点异常较多,所以算法在学习的时候尽量减少这个特征的影响(甚至删除某个特征的影响),这就是正则化。
注:调整时候,算法并不知道某个特征影响,而是去调整参数得出优化的结果。
2.正则化类别:
L2正则化:
- 作用:可以使得其中一些W的都很小,都接近于0,削弱某个特征的影响。
- 特点:越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象
- Ridge回归
L1正则化:
- 作用:可以使得其中一些W的值直接为0,删除这个特征的影响
- LASSO回归
2.8.4 维灾难【拓展知识】
1.维灾难概念:
随着维度的增加,分类器性能逐步上升,到达某点之后,其性能便逐渐下降。
有一系列的图片,每张图片的内容可能是猫也可能是狗;我们需要构造一个分类器能够对猫、狗自动的分类。首先,要寻找到一些能够描述猫和狗的特征,这样我们的分类算法就可以利用这些特征去识别物体。猫和狗的皮毛颜色可能是一个很好的特征,考虑到红绿蓝构成图像的三基色,因此用图片三基色各自的平均值称得上方便直观。这样就有了一个简单的Fisher分类器:
if 0.5*red + 0.3*green + 0.2*blue > 0.6: return "cat" else:return "dog"使用颜色特征可能无法得到一个足够准确的分类器,如果是这样的话,我们不妨加入一些诸如图像纹理(图像灰度值在其X、Y方向的导数dx、dy),就有5个特征(Red、Blue、Green、dx、dy)来设计我们的分类器:
也许分类器准确率依然无法达到要求,加入更多的特征,比如颜色、纹理的统计信息等等,如此下去,可能会得到上百个特征。那是不是我们的分类器性能会随着特征数量的增加而逐步提高呢?答案也许有些让人沮丧,事实上,当特征数量达到一定规模后,分类器的性能是在下降的。
随着维度(特征数量)的增加,分类器的性能却下降了。
2.维数灾难与过拟合:
我们假设猫和狗图片的数量是有限的(样本数量总是有限的),假设有10张图片,接下来我们就用这仅有的10张图片来训练我们的分类器。
增加一个特征,比如绿色,这样特征维数扩展到了2维:
增加一个特征后,我们依然无法找到一条简单的直线将它们有效分类
再增加一个特征,比如蓝色,扩展到3维特征空间:
在3维特征空间中,我们很容易找到一个分类平面,能够在训练集上有效的将猫和狗进行分类:
在高维空间中,我们似乎能得到更优的分类器性能。
从1维到3维,给我们的感觉是:维数越高,分类性能越优。然而,维数过高将导致一定的问题:在一维特征空间下,我们假设一个维度的宽度为5个单位,这样样本密度为10/5=2;在2维特征空间下,10个样本所分布的空间大小25,这样样本密度为10/25=0.4;在3维特征空间下,10个样本分布的空间大小为125,样本密度就为10/125=0.08.
如果继续增加特征数量,随着维度的增加,样本将变得越来越稀疏,在这种情况下,也更容易找到一个超平面将目标分开。然而,如果我们将高维空间向低维空间投影,高维空间隐藏的问题将会显现出来:
过多的特征导致的过拟合现象:训练集上表现良好,但是对新数据缺乏泛化能力。
高维空间训练形成的线性分类器,相当于在低维空间的一个复杂的非线性分类器,这种分类器过多的强调了训练集的准确率甚至于对一些错误/异常的数据也进行了学习,而正确的数据却无法覆盖整个特征空间。为此,这样得到的分类器在对新数据进行预测时将会出现错误。这种现象称之为过拟合,同时也是维灾难的直接体现。
简单的线性分类器在训练数据上的表现不如非线性分类器,但由于线性分类器的学习过程中对噪声没有对非线性分类器敏感,因此对新数据具备更优的泛化能力。换句话说,通过使用更少的特征,避免了维数灾难的发生(也即避免了高维情况下的过拟合)。
由于高维而带来的数据稀疏性问题:假设有一个特征,它的取值范围D在0到1之间均匀分布,并且对狗和猫来说其值都是唯一的,我们现在利用这个特征来设计分类器。如果我们的训练数据覆盖了取值范围的20%(e.g 0到0.2),那么所使用的训练数据就占总rt量的20%。上升到二维情况下,覆盖二维特征空间20%的面积,则需要在每个维度上取得45%的取值范围。在三维情况下,要覆盖特征空间20%的体积,则需要在每个维度上取得58%的取值范围..在维度接近一定程度时,要取得同样的训练样本数量,则几乎要在每个维度上取得接近100%的取值范围,或者增加总样本数量,但样本数量也总是有限的。
如果一直增加特征维数,由于样本分布越来越稀疏,如果要避免过拟合的出现,就不得不持续增加样本数量。
数据在高维空间的中心比在边缘区域具备更大的稀疏性,数据更倾向于分布在空间的边缘区域:
不属于单位圆的训练样本比搜索空间的中心更接近搜索空间的角点。这些样本很难分类,因为它们的特征值差别很大(例如,单位正方形的对角的样本)。
一个有趣的问题是,当我们增加特征空间的维度时,圆〈超球面)的体积如何相对于正方形(超立方体)的体积发生变化。尺寸d的单位超立方体的体积总是1Md= 1.尺寸d和半径0.5的内切超球体的体积可以计算为:
在高维空间中,大多数训练数据驻留在定义特征空间的超立方体的角落中。如前所述,特征空间角落中的实例比围绕超球体质心的实例难以分类。
在高维空间中,大多数训练数据驻留在定义特征空间的超立方体的角落中。如前所述,特征空间角落中的实例比围绕超球体质心的实例难以分类:
事实证明,许多事物在高维空间中表现得非常不同。例如,如果你选择一个单位平方(1×1平方)的随机点,它将只有大约0.4%的机会位于小于0.001的边界(换句话说,随机点将沿任何维度“极端"这是非常不可能的)。但是在一个10000维单位超立方体(1x1×1立方体,有1万个1)中,这个概率大于99.999999%。高维超立方体中的大部分点都非常靠近边界。更难区分的是:如果你在一个单位正方形中随机抽取两个点,这两个点之间的距离平均约为0.52。如果在单位三维立方体中选取两个随机点,则平均距离将大致为0.66。但是在一个100万维的超立方体中随机抽取两点呢?那么平均距离将是大约408.25(大约1,000,000 /6)!
非常违反直觉:当两个点位于相同的单位超立方体内时,两点如何分离?这个事实意味着高维数据集有可能非常稀疏∶大多数训练实例可能彼此远离。当然,这也意味着一个新实例可能离任何训练实例都很远,这使得预测的可信度表现得比在低维度数据中要来的差。训练集的维度越多,过度拟合的风险就越大。理论上讲,维度灾难的一个解决方案可能是增加训练集的大小以达到足够密度的训练实例,不幸的是,在实践中,达到给定密度所需的训练实例的数量随着维度的数量呈指数增长。如果只有100个特征(比MNIST问题少得多),那么为了使训练实例的平均值在0.1以内,需要比可观察宇宙中的原子更多的训练实例,假设它们在所有维度上均匀分布。
对于8维超立方体,大约98%的数据集中在其256个角上。结果,当特征空间的维度达到无穷大时,从采样点到质心的最小和最大欧几里得距离的差与最小距离本身只比趋于零:
距离测量开始失去其在高维空间中测量的有效性,由于分类器取决于这些距离测量,因此在较低维空间中分类通常更容易,其中较少特征用于描述感兴趣对象。
如果理论无限数量的训练样本可用,则维度的诅咒不适用,我们可以简单地使用无数个特征来获得完美的分类。训练数据的大小越小,应使用的功能就越少。如果N个训练样本足以覆盖单位区间大小的1D特征空间,则需要N^2个样本来覆盖具有相同密度的2D特征空间,并且在3D特征空间中需要N^3个样本。换句话说,所需的训练实例数量随着使用的维度数量呈指数增长。
2.9 正则化线性模型
- Ridge Regression 岭回归 ==> 常用
就是把系数前面添加平方项,然后限制系数值的大小
α值越小,系数值越大,α越大,系数值越小- Lasso 回归
对系数值进行绝对值处理
由于绝对值在顶点处不可导,所以进行计算的过程中产生很多0,最后得到结果为:稀疏矩阵- Elastic Net 弹性网络
是前两个内容的综合
设置了一个r,如果r=0--岭回归;r=1--Lasso回归- Early stopping
通过限制错误率的阈值,进行停止
2.9.1 Ridge Regression(岭回归,又名Tikhonovregularization)
岭回归是线性回归的正则化版本,即在原来的线性回归的cost funtion中添加正则项(regularizationterm):
以达到在拟合数据的同时,使模型权重尽可能小的目的,岭回归代价函数:
2.9.2 Lasso Regression(Lasso回归)
Lasso回归是线性回归的另一种正则化版本,正则项为权值向量的e1范数。
Lasso回归的代价函数:
【注意】
- Lasso Regression的代价函数在0=0处是不可导的.
- 解决方法:在0=0处用一个次梯度向量(subgradient vector)代替梯度,如下式
- Lasso Regression的次梯度向量
Lasso Regression有一个很重要的性质是:倾向于完全消除不重要的权重。
例如:当α取值相对较大时,高阶多项式退化为二次甚至是线性:高阶多项式特征的权重被置为0。
也就是说,Lasso Regression能够自动进行特征选择,并输出一个稀疏模型(只有少数特征的权重是非零的)。
2.9.3 Elastic Net(弹性网络)
弹性网络在岭回归和Lasso回归中进行了折中,通过混合比(mix ratio) r进行控制:
- r=0:弹性网络变为岭回归
- r=1:弹性网络便为Lasso回归
弹性网络的代价函数:
一般来说,我们应避免使用朴素线性回归,而应对模型进行一定的正则化处理,那如何选择正则化方法呢?
小结:
- 常用:岭回归
- 假设只有少部分特征是有用的:
-弹性网络
-Lasso
-一般来说,弹性网络的使用更为广泛。因为在特征维度高于训练样本数,或者特征是强相关的情况下,Lasso回归的表现不太稳定。- api:
from sklearn.linear_model import Ridge,ElasticNet,Lasso
2.9.4 Early Stopping[了解]
Early Stopping也是正则化迭代学习的方法之一。
其做法为:在验证错误率达到最小值的时候停止训练。
2.10 线性回归的改进-岭回归
2.10.1 API
sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True,solver="auto" , normalize=False)
- 具有I2正则化的线性回归
- alpha:正则化力度,也叫
取值:0~1 1~10
- solver:会根据数据自动选择优化方法
sag:如果数据集、特征都比较大,选择该随机梯度下降优化- normalize:数据是否进行标准化
normalize=False:可以在fit之前调用preprocessing.StandardScaler标准化数据
normalize=True:之前就不需要标准化了,这里会自动进行标准化- Ridge.coef_:回归权重
- Ridge.intercept_:回归偏置
Ridge方法相当于SGDRegressor(penalty='l2', loss="squared_loss"),只不过SGDRegressor实现了一个普通的随机梯度下降学习,推荐使用Ridge(实现了SAG)
- 具有l2正则化的线性回归,可以进行交叉验证
- coef_:回归系数
2.10.2 观察正则化程度的变化,对结果的影响?
![]()
- 正则化力度越大,权重系数会越小
- 正则化力度越小,权重系数会越大
2.10.3 波士顿房价预测
from sklearn.datasets import load_boston#数据
from sklearn.model_selection import train_test_split#数据集划分
from sklearn.preprocessing import StandardScaler#标准化
from sklearn.linear_model import Ridge#模型训练
from sklearn.metrics import mean_squared_error#评估def linear_model3():'''梯度下降法预测波士顿房价:return:None'''# 1.获取数据boston = load_boston()# 2.数据基本处理# 2.1 数据集划分x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, test_size=0.2)# 3.特征工程标准化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.fit_transform(x_test)# 4.机器学习-线性回归(岭回归)estimator = Ridge(alpha=1)#estimator = RidgeCV(alphas=(0.1,1,10))estimator.fit(x_train, y_train)# 5.模型评估# 5.1 获取系数等值y_pre = estimator.predict(x_test)print('预测值为:\n', y_pre)score=estimator.score(x_test,y_test)print('预测值是:\n',score)print('模型中的系数为:\n',estimator.coef_)print('模型中的偏置:\n',estimator.intercept_)# 5.2 评价#均方误差error=mean_squared_error(y_test,y_pre)print('均方误差是:\n', error)if __name__ == '__main__':linear_model3()![]()
2.11 模型的保存和加载
![]()
2.11.1 sklearn模型的保存和加载API
import joblib
- 保存:joblib.dump(estimator, 'test.pkl')
- 加载:estimator = joblib.load('test.pkI')
2.11.2 线性回归的模型保存加载案例
关键代码段:
# #4.2 模型保存
# joblib.dump(estimator,'./Datas/波士顿房价预测/model.pkl')
#4.3 模型加载
estimator=joblib.load('./Datas/波士顿房价预测/model.pkl')完整代码:
from sklearn.datasets import load_boston#数据
from sklearn.model_selection import train_test_split#数据集划分
from sklearn.preprocessing import StandardScaler#标准化
from sklearn.linear_model import Ridge,RidgeCV#模型训练
from sklearn.metrics import mean_squared_error#评估
import joblib#模型保存和加载def linear_model3():'''梯度下降法预测波士顿房价 ==> 模型保存和加载:return:None'''# 1.获取数据boston = load_boston()# 2.数据基本处理# 2.1 数据集划分x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22,test_size=0.2)# 3.特征工程标准化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.fit_transform(x_test)# 4.机器学习-线性回归(岭回归)# #4.1 模型训练# estimator = Ridge(alpha=1)# # estimator = RidgeCV(alphas=(0.1,1,10))# estimator.fit(x_train, y_train)# #4.2 模型保存# joblib.dump(estimator,'./Datas/波士顿房价预测/model.pkl')#4.3 模型加载estimator=joblib.load('./Datas/波士顿房价预测/model.pkl')# 5.模型评估# 5.1 获取系数等值y_pre = estimator.predict(x_test)print('预测值为:\n', y_pre)score=estimator.score(x_test,y_test)print('预测值是:\n',score)print('模型中的系数为:\n',estimator.coef_)print('模型中的偏置:\n',estimator.intercept_)# 5.2 评价#均方误差error=mean_squared_error(y_test,y_pre)print('均方误差是:\n', error)if __name__ == '__main__':linear_model3()![]()
3.逻辑回归--【分类问题】
![]()
![]()
3.1 逻辑回归介绍
逻辑回归(Logistic Regression)是机器学习中的一种分类模型,逻辑回归是一种分类算法,虽然名字中带有回归,但是它与回归之间有一定的联系。中于算法的简单和高效,在实际中应用非常广泛。
3.1.1 逻辑回归的应用场景
- 广告点击率
- 是否为垃圾邮件
- 是否患病
- 金融诈骗
- 虚假账号
看到上面的例子,我们可以发现其中的特点,那就是都属于两个类别之间的判断。逻辑回归就是解决二分类问题的利器。
3.1.2 逻辑回归的原理
要想掌握逻辑回归,必须掌握两点:
- 逻辑回归中,其输入值是什么
- 如何判断逻辑回归的输出
1.输入:
逻辑回归的输入就是一个线性回归的输出结果。
2.激活函数:
- sigmoid函数
- 判断标准
回归的结果输入到sigmoid函数当中
输出结果:[0,1]区间中的一个概率值,默认为0.5为阈值
逻辑回归最终的分类是通过属于某个类别的概率值来判断是否属于某个类别,并且这个类别默认标记为1(正例),另外的一个类别会标记为0(反列)。(方便损失计算)
输出结果解释(重要):假设有两个类别A,B,并且假设我们的概率值为属于A(1)这个类别的概率值。现在有一个样本的输入到逻辑回归输出结果0.6,那么这个概率值超过0.5,意味着我们训练或者预测的结果就是A(1)类别。那么反之,如果得出结果为0.3那么,训练或者预测结果就为B(0)类别。
所以接下来我们回忆之前的线性回归预测结果我们用均方误差衡量,那如果对于逻辑回归,我们预测的结果不对该怎么去衡量这个损失呢?我们来看这样一张图
那么如何去衡量逻辑回归的预测结果与真实结果的差异呢?
3.1.3 损失以及优化
1.损失:
逻辑回归的损失,称之为对数似然损失,公式如下:
- 分开类别
怎么理解单个的式子呢?这个要根据log的函数图像来理解:
- 综合完整损失函数
看到这个式子,其实跟我们讲的信息嫡类似。接下来我们呢就带入上面那个例子来计算一遍,就能理解意义了。
2.优化:
同样使用梯度下降优化算法,去减少损失函数的值。这样去更新逻辑回归前面对应算法的权重参数,提升原本属于1类别的概率,降低原本是0类别的概率。
3.2 逻辑回归api介绍
sklearn.linear_model.LogisticRegression(solver='liblinear', penalty='l2',C = 1.0)
- solver可选参数:{"liblinear' , 'sag', 'saga' , 'newton-cg', 'lbfgs'},
-默认: "liblinear';用于优化问题的算法。
-对于小数据集来说,“lilblinear"是个不错的选择,而“sag"和'saga'对于大型数据集会更快。
-对于多类问题,只有'newton-cg','sag','saga'和'lbfgs'可以处理多项损失;"liblinear"仅限于“one-versus-rest"分类。- penalty:正则化的种类
- C:正则化力度
默认将类别数量少的当做正例。
LogisticRegression方法相当于SGDClassifier(loss="log" , penalty=""),SGDClassifier实现了一个普通的随机梯度下降学习。而使用LogisticRegression(实现了SAG)。
3.3 案例:癌症分类预测-良/恶性乳腺癌肿瘤预测
1.学习目标:
通过肿瘤预测案例,学会如何使用逻辑回归对模型进行训练。
2.数据介绍:
原始数据的下载地址: Index of /ml/machine-learning-databases/breast-cancer-wisconsin (uci.edu)
https://archive.ics.uci.edu/ml/machine-learning-databases/
数据描述:
(1)699条样本,共11列数据,第一列用语检索的id,后9列分别是与肿瘤相关的医学特征,最后一列表示肿瘤类型的数值。
(2)包含16个缺失值,用”?”标出。
3.案例分析:
1.获取数据
2.基本数据处理
2.1 缺失值处理
2.2 确定特征值,目标值
2.3 分割数据
3.特征工程(标准化)
4.机器学习(逻辑回归)
5.模型评估
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split#数据分离
from sklearn.preprocessing import StandardScaler#数据标准化
from sklearn.linear_model import LogisticRegression#模型训练# import ssl#证书验证问题
# ssl._create_default_https_context = ssl._create_unverified_context
# 1.获取数据
names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape','Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin','Normal Nucleoli', 'Mitoses', 'Class']
data=pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data",names=names)
# print(data)#2.基本数据处理
#2.1 缺失值处理
data=data.replace(to_replace='?',value=np.NaN)
data=data.dropna()#删除
#2.2 确定特征值,目标值
x=data.iloc[:,1:10]
y=data['Class']
#2.3 分割数据
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=22)#3.特征工程(标准化)
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.fit_transform(x_test)#4.机器学习(逻辑回归)
estimator=LogisticRegression()
estimator.fit(x_train,y_train)#5.模型评估
y_predict=estimator.predict(x_test)
print('预测值是:\n',y_predict)
score=estimator.score(x_test,y_test)
print('准确率为:\n',score)![]()
3.4 分类评估方法
复习:分类评估指标
![]()
3.4.1 分类评估方法
(1)精确率与召回率
混淆矩阵:在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类)。
精确率(Precision)与召回率(Recall):
- 精确率:预测结果为正例样本中真实为正例的比例(了解)
- 召回率:真实为正例的样本中预测结果为正例的比例(查得全,对正样本的区分能力)
(2)F1-score
还有其他的评估标准,F1-score,反映了模型的稳健型。
(3)分类评估报告api
sklearn.metrics.classification_report(y_true,y_pred, labels=[ ], target_names=None )
- y_true:真实目标值入
- y_pred:估计器预测目标值
- labels:指定类别对应的数字
- target_names:目标类别名称
- return:每个类别精确率与召回率
部分代码:
#5.2 其他评估
ret=classification_report(y_test,y_predict,labels=(2,4),target_names=('良性','恶性'))#后两个参数为了可读性
print(ret)![]()
假设这样一个情况,如果99个样本癌症,1个样本非癌症,不管怎年我全都预测正例(默认癌症为正例),准确率就为99%但是这样效果并不好,这就是样本不均衡下的评估问题。
问题:如何衡量样本不均衡下的评估?
3.4.2 ROC曲线与AUC指标
(1)TPR和FPR
- TPR = TP/(TP + FN)
所有真实类别为1的样本中,预测类别为1的比例- FPR = FP/(FP + TN)
所有真实类别为0的样本中,预测类别为1的比例
(2)ROC曲线
- ROC曲线的横轴就是FPRate,纵轴就是TPRate,当二者相等时,表示的意义则是:对于不论真实类别是1还是0的样本,分类器预测为1的概率是相等的,此时AUC为0.5
(3)AUC指标
- AUC的概率意义是随机取一对正负样本,正样本得分大于负样本得分的概率
- AUC的范围在[0,1]之间,并且越接近1越好,越接近0.5属于乱猜
- AUC=1,完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5<AUC<1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
(4)AUC计算API
from sklearn.metrics import roc_auc_score
sklearn.metrics.roc_auc_score(y_true, y_score)
- 计算ROC曲线面积,即AUC值
- y_true:每个样本的真实类别,必须为0(反例),1(正例)标记
- y_score:预测得分,可以是正类的估计概率、置信值或者分类器方法的返回值
关键代码:
from sklearn.metrics import roc_auc_score#模型评估
#5.3 AUC指标计算
y_test=np.where(y_test>3,1,0)#大于3的置为1,否则置为0
auc=roc_auc_score(y_test,y_predict)
print('AUC指标为:\n',auc)![]()
- AUC只能用来评价分类
- AUC非常适合评价样本不平衡中的分类器性能
3.5 ROC曲线的绘制
![]()
关于ROC曲线的绘制过程,通过以下举例进行说明
假设有6次展示记录,有两次被点击了,得到一个展示序列(1:1,2:0,3:1,4:0,5:0,6:0),前面的表示序号,后奭的表示点击(1)或没有点击(0)。
然后在这6次展示的时候都通过model算出了点击的概率序列。
下面看三种情况。
![]()
3.5.1 曲线绘制
3.5.2 意义
如上图的例子,总共6个点,2个正样本,4个负样本,取一个正样本和一个负样本的情况总共有8种。上面的第一种情况,从上往下取,无论怎么取,正样本的概率总在负样本之上,所以分对的概率为1,AUC=1。再看那个ROC曲线,它的积分是什么?也是1,ROC曲线的积分与AUC相等。
上面第二种情况,如果取到了样本2和3,那就分错了,其他情况都分对了﹔所以分对的概率是0.875,AUC=0.875。再看那个ROC曲线,它的积分也是0.875,ROC曲线的积分与AUC相等。
上面的第三种情况,无论怎么取,都是分错的,所以分对的概率是0,AUC=0.0。再看ROC曲线,它的积分也是0.0,ROC曲线的积分与AUC相等。
很牛吧,其实AUC的意思是——Area Under roc Curve,就是ROC曲线的积分,也是ROC曲线下面的面积。绘制ROC曲线的意义很明显,不断地把可能分错的情况扣除掉,从概率最高往下取的点,每有一个是负样本,就会导致分错排在它下面的所有正样本,所以要把它下面的正样本数扣除掉(1-TPR,剩下的正样本的比例)。总的ROC曲线绘制出来了,AUC就定了,分对的概率也能求出来了。
3.6 分类中解决类别不平衡问题
前面我们已经初步认识了,什么是类别不平衡问题。其实,在现实环境中,采集的数据(建模样本)往往是比例失衡的。比如网贷数据,逾期人数的比例是极低的(千分之几的比例)﹔奢侈品消费人群鉴定等。
3.6.1 类别不平衡数据集基本介绍
在这一节中,我们一起看一下,当遇到数据类别不平衡的时候,我们该如何处理。在Python中,有Imblearn包,它就是为处理数据比例失衡而生的。
pip3 install imbalanced-learn
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt#使用make_classification生成样本数据
x,y=make_classification(n_samples=5000,#创建样本点个数n_features=2,#特征个数=n_informative+n_redundant+n_repeatedn_informative=2,#多信息特征的个数n_redundant=0,#冗余信息, informative特征的随机线性组合n_repeated=0,#重复信息,随机提取n_informative和n_redundant特征n_classes=3,#分类类别n_clusters_per_class=1,#某一个类别是由几个cluster构成的weights=[0.01,0.05,0.94],#列表类型,权重比random_state=0)
print(x.shape,x,sep='\n')
print(y.shape,y,sep='\n')#查看各个样本的样本量
from collections import Counter
print(Counter(y))#Counter({2: 4674, 1: 262, 0: 64})
#数据可视化
plt.scatter(x[:,0],x[:,1],c=y)
plt.show()![]()
![]()
可以看出样本的三个标签中,1,2的样本量极少,样本失衡。下面使用imblearn进行过采样。
接下来,我们就要基于以上数据,进行相应的处理。关于类别不平衡的问题,主要有两种处理方式:
- 过采样方法
减少数量较多一类样本的数量,使得正负样本比例均衡。- 欠采样方法
增加数量较少那一类样本的数量,使得正负样本比例均衡。
3.6.2 解决类别不平衡数据方法介绍
(1)过采样方法【常用】
什么是过采样方法:对训练集里的少数类进行“过采样”(oversampling),即增加一些少数类样本使得正、反例数目接近,然后再进行学习。
1.随机过采样方法
关键代码段:
#使用imblearn进行随机过采样 from imblearn.over_sampling import RandomOverSampler ros=RandomOverSampler(random_state=0) x_resampled,y_resampled=ros.fit_resample(x,y) #查看结果 print('处理后的数据:\n',Counter(y_resampled))#Counter({2: 4674, 1: 4674, 0: 4674})#数据可视化 plt.scatter(x_resampled[:,0],x_resampled[:,1],c=y_resampled) plt.show()
缺点︰
- 对于随机过采样,由于需要对少数类样本进行复制来扩大数据集,造成模型训练复杂度加大。
- 另一年面也容易造成模型的过拟合问题,因为随机过采样是简单的对初始样本进行复制采样,这就使得学习器学得的规则过于具体化,不利于学习器的泛化性能,造成过拟合问题。
为了解决随机过采样中造成模型过拟合问题,又能保证实现数据集均衡的目的,出现了过采样法代表性的算法SMOTE算法。
2. 过采样代表性算法-SMOTE
SMOTE算法摒弃了随机过采样复制样本的做法,可以防止随机过采样中容易过拟合的问题,实践证明此方法可以提高分类器的性能。
核心代码段:
#SMOTE算法过采样 from imblearn.over_sampling import SMOTE x_resampled,y_resampled=SMOTE().fit_resample(x,y) print('处理后的数据:\n',Counter(y_resampled))#Counter({2: 4674, 1: 4674, 0: 4674})
(2)欠采样方法【不常使用】
什么是欠采样方法:
直接对训练集中多数类样本进行“欠采样”(undersampling) ,即去除一些多数类中的样本使得正例、反例数目接近,然后再进行学习。
随机欠采样方法:
核心代码段:
#随机欠采样方法 from imblearn.under_sampling import RandomUnderSampler x_resampled,y_resampled=RandomUnderSampler(random_state=0).fit_resample(x,y) print('处理后的数据:\n',Counter(y_resampled))#Counter({0: 64, 1: 64, 2: 64})
缺点︰
- 随机欠来样方法通过改变多数类样本比例以达到修改样本分布的目的,从而使样本分布较为均衡,但是这也存在一些问题。对于随机欠采样,由于采样的样本集合要少于原来的样本集合,因此会造成一些信息缺失,即将多数类样本删除有可能会导致分类器丢失有关多数类的重要信息。
官网链接:https://imbalanced-learn.readthedocs.io/en/stable/ensemble.html
4.决策树算法——>分类算法
![]()
4.1 决策树算法简介
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-else结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法。
决策树:是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果,本质是一颗由多个判断节点组成的树。
此时需要用到信息论中的知识:信息嫡,信息增益。
4.2 决策树分类原理
![]()
4.2.1 熵
1.概念:
物理学上,嫡Entropy是“混乱"程度的量度。
系统越有序,嫡值越低;系统越混乱或者分散,嫡值越高。
1948年含农提出了信息嫡(Entropy)的概念。
2.信息理论:
- 从信息的完整性上进行的描述:
当系统的有序状态一致时,数据越集中的地方嫡值越小,数据越分散的地方嫡值越大。- 从信息的有序性上进行的描述:
当数据量一致时,系统越有序,嫡值越低;系统越混乱或者分散,嫡值越高。
"信息嫡" (information entropy)是度量样本集合纯度最常用的一种指标。
3.案例:
4.2.2 决策树的划分依据——信息增益
1.概念:
信息增益:以某特征划分数据集前后的嫡的差值。嫡可以表示样本集合的不确定性,嫡越大,样本的不确定性就越大。因此可以使用划分前后集合嫡的差值来衡量使用当前特征对于样本集合D划分效果的好坏。信息增益= entroy(前) - entroy(后)
注:信息增益表示得知特征X的信息而使得类Y的信息嫡减少的程度定义与公式:
2.案例:
活跃度的信息增益比性别的信息增益大,也就是说,活跃度对用户流失的影响比性别大。在做特征选择或者数据分析的时候,我们应该重点考察活跃度这个指标。
4.2.3 决策树的划分依据二——信息增益率
1.概念:
在上面的介绍中,我们有意忽略了"编号"这一列.若把"编号"也作为一个候选划分属性,则根据信息增益公式可计算出它的信息增益为0.9182,远大于其他候选划分属性。
计算每个属性的信息嫡过程中,我们发现,该属性的值为0,也就是其信息增益为0.9182,但是很明显这么分类,最后出现的结果不具有泛化效果,无法对新样本进行有效预测。
实际上,信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,著名的C4.5决策树算法【Quinlan,1993】不直接使用信息增益,而是使用"增益率" (gain ratio)来选择最优划分属性。
增益率:增益率是用前面的信息增益Gain(D, a)和属性a对应的"固有值"(intrinsic value) 【Quinlan,1993】的比值来共同定义的。
2.案例一:
3.案例二:
现在我们来总结一下C4.5的算法流程:
4. 为什么使用C4.5要好
4.2.4 决策树的划分依据三----基尼值和基尼指数
1.概念:
2.案例:
总结:
4.2.5 小结
(1)常见决策树的启发函数比较
![]()
1.ID3算法
存在的缺点
- ID3算法在选择根节点和各内部节点中的分支属性时,采用信息增益作为评价标准。信息增益的缺点是倾向于选择取值较多的属性,在有些情况下这类属性可能不会提供太多有价值的信息.
- ID3算法只能对描述属性为离散型属性的数据集构造决策树。
2.C4.5算法
做出的改进(为什么使用C4.5要好)
- 用信息增益率来选择属性
- 可以处理连续数值型属性
- 采用了一种后剪枝方法
- 对于缺失值的处理
C4.5算法的优缺点
- 优点:
产生的分类规则易于理解,准确率较高。- 缺点∶
在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。此外,C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
3.CART算法
CART算法相比C4.5算法的分类方法,采用了简化的二叉树模型,同时特征选择采用了近似的基尼系数来简化计算。
C4.5不一定是二叉树,但CART一定是二叉树。
4.多变量决策树
同时,无论是ID3,C4.5还是CART,在做特征选择的时候都是选择最优的一个特征来做分类决策,但是大多数,分类决策不应该是由某一个特征决定的,而是应该由一组特征决定的。这样决策得到的决策树更加准确。这个决策树叫做多变量决策树(multi-variate decision tree)。在选择最优特征的时候,多变量决策树不是选择某一个最优特征,而是选择最优的一个特征线性组合来做决策。这个算法的代表是OC1,这里不多介绍。
如果样本发生一点点的改动,就会导致树结构的剧烈改变。这个可以通过集成学习里面的随机森林之类的方法解决。
(2)决策树变量的两种类型
- 数字型(Numeric)︰变量类型是整数或浮点数,如前面例子中的“年收入”。用“>=",“>""<"或“<=”作为分割条件(排序后,利用已有的分割情况,可以优化分割算法的时间复杂度)。
- 名称型(Nominal)︰类似编程语言中的枚举类型,变量只能从有限的选项中选取,比如前面例子中的“婚姻情况”,只能是“单身”,“已婚"或“离婚”,使用“=”来分割。
(3)如何评估分割点的好坏?
如果一个分割点可以将当前的所有节点分为两类,使得每一类都很“纯”,也就是同一类的记录较多,那么就是一个好分割点。
比如上面的例子,“拥有房产",可以将记录分成了两类,“是"的节点全部都可以偿还债务,非常“纯";“否”的节点,可以偿还贷款和无法偿还贷款的人都有,不是很“纯",但是两个节点加起来的纯度之和与原始节点的纯度之差最大,所以按照这种方法分割。
构建决策树采用贪心算法,只考虑当前纯度差最大的情况作为分割点。
4.3 cart剪枝
![]()
4.3.1 为什么要剪枝
图形描述:
- 横轴表示在决策树创建过程中树的结点总数,纵轴表示决策树的预测精度。
- 实线显示的是决策树在训练集上的精度,虚线显示的则是在一个独立的测试集上测量出来的精度。
- 随着树的增长,在训练样集上的精度是单调上升的,然而在独立的测试样例上测出的精度先上升后下降。
出现这种情况的原因:
- 原因1:噪声、样本冲突,即错误的样本数据。
- 原因2:特征即属性不能完全作为分类标准。
- 原因3:巧合的规律性,数据量不够大。
剪枝(pruning)是决策树学习算法对付"过拟合"的主要手段。
在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因训练样本学得"太好"了,以致于把训练集自身的一些特点当作所有数据都具有的一般性质而导致过拟合。因此,可通过主动去掉一些分支来降低过拟合的风险。
如何判断决策树泛化性能是否提升呢?接下来,我们一起看一下,如何对这一棵树进行剪枝。
4.3.2 常用的减枝方法
决策树剪枝的基本策略有"预剪枝"(pre-pruning)和"后剪枝"(post- pruning)。
- 预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点;
- 后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
数据集:
其中{1,2,3,6,7,10,14,15,16,17}为测试集,{4,5,8,9,11,12,13}为训练集。
(1)预剪枝
![]()
(2)后剪枝
![]()
(3)总结
![]()
4.4 特征工程-特征提取
![]()
什么是特征提取呢?
1.将文本类型转化为数字
2.将类别类型转化为数字
4.4.1 特征提取
1.定义:即将任意数据(如文本或图像)转换为可用于机器学习的数字特征。
注:特征值化是为了计算机更好的去理解数据
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取(深度学习将介绍)
2.API:sklearn.feature_extraction
4.4.2 字典特征提取
作用:对字典数据进行特征值化
sklearn.feature_extraction.DictVectorizer(sparse=True,...)
- DictVectorizer.fit_transform(X)
-X:字典或者包含字典的迭代器返回值
-返回sparse矩阵- DictVectorizer.get_feature_names():返回类别名称
(1)应用
我们对以下数据进行特征提取:
data = [{'city': '北京', 'value' : 150},{'city': '浙江', 'value': 10},{'city': '上海', 'value': 50}
]
(2)流程分析
- 实例化类
DictVectorizer- 调用
fit_transform方法输入数据并转化 (注意返回格式)
from sklearn.feature_extraction import DictVectorizer#字典特征提取def dict_demo():'''对字典类型进行特征提取:return:None'''data = [{'city': '北京', 'value': 150},{'city': '浙江', 'value': 10},{'city': '上海', 'value': 50}]#1.实例化一个转换器transfer=DictVectorizer(sparse=False)#2.调用fit_transformdata=transfer.fit_transform(data)print('返回的结果是:\n',data)#打印特征名字print('特征名字:\n',transfer.get_feature_names())return Nonedict_demo()sparse=False的运行结果:
![]()
sparse=True的运行结果:
![]()
可以看到没有加上
sparse=False参数的结果为sparse矩阵,sparse稀疏,将非零值 按位置表示出来,可以节省内存,提高加载效果。之前在学习pandas中的离散化的时候,也实现了类似的效果。我们把这个处理数据的技巧叫做”one-hot“编码。
(3)小结
对于特征当中存在类别信息的我们都会做one-hot编妈处理。
4.4.3 文本提取
作用:对文本数据进行特征值化
sklearn.feature_extraction.text.CountVectorizer(stop_words=[])
- 返回词频矩阵
- stop_words 参数表示停用的词
- CountVectorizer.fit_transform(X)
X:文本或者包含文本字符串的可迭代对象
返回值:返回sparse矩阵- CountVectorizer.inverse_transform(X)
X : array数组或者sparse矩阵
返回值:转换之前数据格- CountVectorizer.get_feature_names()
返回值:单词列表sklearn.feature_extraction.text.TfidfVectorizer
流程分析:
- 实例化类
CountVectorizer- 调用
fit_transform方法输入数据并转化 (注意返回格式,利用toarray()进行sparse矩阵转化为array数组)
(1)英文文本特征提取
from sklearn.feature_extraction import DictVectorizer#字典特征提取
from sklearn.feature_extraction.text import CountVectorizer#文本特征提取def text_count_demo():'''对文本进行特征提取:return:None'''data = ["life is short,i is like python","life is too long,i disiike python"]#1.实例化一个转换器transfer=CountVectorizer()#2.调用fit_transferdata=transfer.fit_transform(data)print('文本特征提取结果为:\n',data.toarray())#sparse矩阵转化为array数组print('返回特征名字:\n',transfer.get_feature_names())return Nonedef dict_demo():'''对字典类型进行特征提取:return:None'''data = [{'city': '北京', 'value': 150},{'city': '浙江', 'value': 10},{'city': '上海', 'value': 50}]#1.实例化一个转换器transfer=DictVectorizer(sparse=True)#2.调用fit_transformdata=transfer.fit_transform(data)print('返回的结果是:\n',data)#打印特征名字print('特征名字:\n',transfer.get_feature_names())return Nonetext_count_demo()![]()
注意:单个字母的单词不统计,参数stop_words中也可指定不做统计的单词
![]()
![]()
问题:如果我们将数据替换成中文?
然而,当文本为中文时,由于每个字之间没有空格,所以在面对中文文本的时候,我们需要先进行分词。
(2)英文文本特征提取 ——jieba 分词处理
jieba.cut()
- 返回词语组成的生成器
需要安装
jieba库:pip install jieba
data = ['优美胜于丑陋(Python以编写优美的代码为目标)','明了胜于晦涩(优美的代码应当是明了的,命名规范,风格相似)','简洁胜于复杂(优美的代码应当是简洁的,不要有复杂的内部实现)','复杂胜于凌乱(如果复杂不可避免,那代码间也不能有难懂的关系,要保持接口简洁)','扁平胜于嵌套(优美的代码应当是扁平的,不能有太多的嵌套)','间隔胜于紧凑(优美的代码有适当的间隔,不要奢望一行代码解决问题)','可读性很重要(优美的代码是可读的)','即便假借特例的实用性之名,也不可违背这些规则(这些规则至高无上)','不要包容所有错误,除非你确定需要这样做(精准地捕获异常,不写 except:pass 风格的代码)','当存在多种可能,不要尝试去猜测','而是尽量找一种,最好是唯一一种明显的解决方案(如果不确定,就用穷举法)','做也许好过不做,但不假思索就动手还不如不做(动手之前要细思量)','如果你无法向人描述你的方案,那肯定不是一个好方案;反之亦然(方案测评标准)','命名空间是一种绝妙的理念,我们应当多加利用(倡导与号召)'
]
- 分析
- 准备句子,利用
jieba.cut进行分词- 实例化
CountVectorizer- 将分词结果变成字符串当作
fit_transform的输入值
def cut_word(text):#分词return ' '.join(list(jieba.cut(text)))def Chinese_count_demo():'''中文文本特征提取:return: None'''data = ['优美胜于丑陋(Python以编写优美的代码为目标)','明了胜于晦涩(优美的代码应当是明了的,命名规范,风格相似)','简洁胜于复杂(优美的代码应当是简洁的,不要有复杂的内部实现)','复杂胜于凌乱(如果复杂不可避免,那代码间也不能有难懂的关系,要保持接口简洁)','扁平胜于嵌套(优美的代码应当是扁平的,不能有太多的嵌套)','间隔胜于紧凑(优美的代码有适当的间隔,不要奢望一行代码解决问题)','可读性很重要(优美的代码是可读的)','即便假借特例的实用性之名,也不可违背这些规则(这些规则至高无上)','不要包容所有错误,除非你确定需要这样做(精准地捕获异常,不写 except:pass 风格的代码)','当存在多种可能,不要尝试去猜测','而是尽量找一种,最好是唯一一种明显的解决方案(如果不确定,就用穷举法)','做也许好过不做,但不假思索就动手还不如不做(动手之前要细思量)','如果你无法向人描述你的方案,那肯定不是一个好方案;反之亦然(方案测评标准)','命名空间是一种绝妙的理念,我们应当多加利用(倡导与号召)']data_new=[cut_word(sent) for sent in data]#实例化一个转化器transfer=CountVectorizer(stop_words=['except','pass','(',')'])#调用fit_transform函数data_final=transfer.fit_transform(data_new)print('返回结果:\n',data_final.toarray())print('特征名字为:\n',transfer.get_feature_names())![]()
(3)Tf-idf文本特征提取
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
公式:
- 词频(term frequency,tf)指的是某一个给定的词语在该文件中出现的频率
- 逆向文档频率(inverse document frequency,idf)是一个词语普遍重要性的度量。某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到
- 最终结果可以理解为重要程度
API:
- sklearn.feature_extraction.text.TfidfVectorizer(stop_words=None,...)
返回词的权重矩阵- TfidfVectorizer.fit_transform(X)
X:文本或者包含文本字符串的可迭代对象
返回值:返回sparse矩阵- TfidfVectorizer.inverse_transform(X)
X : array数组或者sparse矩阵
返回值:转换之前数据格式- TfidfVectorizer.get_feature_names()
返回值:单词列表
![]()
import jieba#分词
from sklearn.feature_extraction.text import TfidfVectorizerdef cut_word(text):#分词return ' '.join(list(jieba.cut(text)))def Tfifd_demo():data = ['优美胜于丑陋(Python以编写优美的代码为目标)','明了胜于晦涩(优美的代码应当是明了的,命名规范,风格相似)','简洁胜于复杂(优美的代码应当是简洁的,不要有复杂的内部实现)','复杂胜于凌乱(如果复杂不可避免,那代码间也不能有难懂的关系,要保持接口简洁)','扁平胜于嵌套(优美的代码应当是扁平的,不能有太多的嵌套)','间隔胜于紧凑(优美的代码有适当的间隔,不要奢望一行代码解决问题)','可读性很重要(优美的代码是可读的)','即便假借特例的实用性之名,也不可违背这些规则(这些规则至高无上)','不要包容所有错误,除非你确定需要这样做(精准地捕获异常,不写 except:pass 风格的代码)','当存在多种可能,不要尝试去猜测','而是尽量找一种,最好是唯一一种明显的解决方案(如果不确定,就用穷举法)','做也许好过不做,但不假思索就动手还不如不做(动手之前要细思量)','如果你无法向人描述你的方案,那肯定不是一个好方案;反之亦然(方案测评标准)','命名空间是一种绝妙的理念,我们应当多加利用(倡导与号召)']data_new=[cut_word(sent) for sent in data]#实例化转化器类transfer=TfidfVectorizer(stop_words=['except','pass','(',')'])data_final=transfer.fit_transform(data_new)print('返回结果是:\n',data_final.toarray())print('特征名字为:\n',transfer.get_feature_names())Tfifd_demo()![]()
Tf-idf 的重要性:
分类机器学习算法进行文章分类中前期数据处理方式。
4.5 决策树算法api
![]()
![]()
4.6 案例:泰坦尼克号乘客生存预测
决策树算法案例:泰坦尼克号乘客生存预测_IT之一小佬的博客-CSDN博客
4.7 回归决策树
4.7.1 原理描述
上篇文章已经讲到,关于数据类型,我们主要可以把其分为两类,连续型数据和离散型数据。在面对不同数据时,决策树也 可以分为两大类型: 分类决策树和回归决策树。 前者主要用于处理离散型数据,后者主要用于处理连续型数据。
不管是回归决策树还是分类决策树,都会存在两个核心问题:
- 如何选择划分点?
- 如何决定叶节点的输出值?
⼀个回归树对应着输入空间(即特征空间)的⼀个划分以及在划分单元上的输出值。分类树中,我们采用信息论中的方法,通过计算选择最佳划分点。
而在回归树中,采用的是启发式的方法。假如我们有n个特征,每个特征有si(i ∈ (1, n))个取值,那我们遍历所有特征, 尝试该特征所有取值,对空间进行划分,直到取到特征 j 的取值 s,使得损失函数最小,这样就得到了⼀个划分点。描述该过程的公式如下:
假设将输入空间划分为M个单元:R1, R2, …, Rm 那么每个区域的输出值就是:
cm = avg(yi∣xi ∈ Rm)也就是该区域内所有点y值的平均数。
举例:
如下图,假如我们想要对楼内居⺠的年龄进⾏回归,将楼划分为3个区域R1, R2 , R3(红线),
那么R1的输出就是第⼀列四个居⺠年龄的平均值,
R2的输出就是第⼆列四个居⺠年龄的平均值,
R3的输出就是第三、四列⼋个居⺠年龄的平均值。
4.7.2 算法描述
- 输入:训练数据集D:
输出:回归树f(x).
在训练数据集所在的输入空间中,递归的将每个区域划分为两个子区域并决定每个子区域上的输出值,构建二叉决策树:
(1)选择最优切分特征j与切分点s,求解
编辑
(2)用选定的对(j, s)划分区域并决定相应的输出值:
(3)继续对两个子区域调用步骤(1)和(2),直至满足停止条件。
(4)将输入空间划分为M个区域R , R , …, R , 生成决策树:
4.7.3 简单实例
为了易于理解,接下来通过⼀个简单实例加深对回归决策树的理解。 训练数据见下表,目标是得到⼀棵最小二乘回归树。
![]()
(1)实例计算过程
![]()
(2)回归决策树和线性回归对比
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from sklearn import linear_model# 用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei'] #生成数据
x=np.array(list(range(1,11))).reshape(-1,1)
y=np.array([5.56, 5.70, 5.91, 6.40, 6.80, 7.05, 8.90, 8.70, 9.00, 9.05])#模型训练
model1=DecisionTreeRegressor(max_depth=1)
model2=DecisionTreeRegressor(max_depth=3)
model3=linear_model.LinearRegression()
model1.fit(x,y)
model2.fit(x,y)
model3.fit(x,y)#模型预测
x_test=np.arange(0.0,10.0,0.01).reshape(-1,1)#生成1000个数字用于训练模型
y_1=model1.predict(x_test)
y_2=model2.predict(x_test)
y_3=model3.predict(x_test)#结果可视化
plt.figure(figsize=(10,6),dpi=100)
plt.scatter(x,y,label='data')
plt.scatter(x_test,y_1,label='max_depth=1')
plt.scatter(x_test,y_2,label='max_depth=3')
plt.scatter(x_test,y_3,label='liner regression')plt.xlabel('数据')
plt.ylabel('预测值')
plt.title('Decision Tree Regression')
plt.legend()
plt.show()![]()
4.7.4 小结
![]()
5.集成学习——预测、分类问题
5.1 集成学习算法简介
学习目标:
- 了解什么是集成学习
- 知道机器学习中的两个核心任务
- 了解集成学习中的boosting和bagging
5.1.1 什么是集成学习
![]()
集成学习通过建立几个模型来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。
5.1.2 复习:机器学习的两个核心任务
- 任务一:如何优化训练数据 —> 主要用于解决欠拟合问题
- 任务二:如何提升泛化性能 —> 主要用于解决过拟合问题
5.1.3 集成学习中boosting和Bagging
![]()
只要单分类器的表现不太差,集成学习的结果总是要好于单分类器的。
5.1.4 小结
- 什么是集成学习
- 通过建立几个模型来解决单一预测问题
- 机器学习两个核心任务
- 1.解决欠拟合问题
- 弱弱组合变强
- boosting
- 2.解决过拟合问题
- 互相遏制变壮
- Bagging
5.2 Bagging和随机森林
学习目标
- 知道Bagging集成原理
- 知道随机森林构造过程
- 知道RandomForestClassifier的使用
- 了解baggind集成的优点
5.2.1 Bagging集成原理
目标:把下面的圈和方块进行分类
实现过程:
1.采样不同数据集
2.训练分类器
3.平权投票,获取最终结果
4.主要实现过程小结
5.2.2 随机森林构造过程
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
随机森林 = Bagging + 决策树
例如, 如果你训练了5个树, 其中有4个树的结果是True, 1个树的结果是False, 那么最终投票结果就是True.
随机森林够造过程中的关键步骤(M表示特征数目):
1)一次随机选出一个样本,有放回的抽样,重复N次(有可能出现重复的样本)
2) 随机去选出m个特征, m <<M,建立决策树
思考:
- 为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的- 为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
5.2.3 包外估计(Out-of-Bag Estimate)
在随机森A构造过程中,如果进行有放回的抽样,我们会发现,总是有一部分样本我们选不到。
- 这部分数据,占整体数据的比重有多大呢?
- 这部分数据有什么用呢?
(1)包外估计的定义
随机森林的 Bagging过程,对于每一颗训练出的决策树gt ,与数据集D有如下关系:
对于星号的部分,即是没有选择到的数据,称之为Out-of-bag(OOB)数据,当数据足够多,对于任意一组数据(xn, yn)是包外数据的概率为:
由于基分类器是构建在训练样本的⾃助抽样集上的,只有约 63.2% 原样本集出现在中,⽽剩余的 36.8% 的数据作为包 外数据,可以⽤于基分类器的验证集。
经验证,包外估计是对集成分类器泛化误差的无偏估计.
在随机森林算法中数据集属性的重要性、分类器集强度和分类器间相关性计算都依赖于袋外数据。
(2)包外估计的用途
- 当基学习器是决策树时,可使⽤包外样本来辅助剪枝 ,或用于估计决策树中各结点的后验概率以辅助对零训练样本结点的处理;
- 当基学习器是神经网络时,可使用包外样本来辅助早期停止以减小过拟合 。
5.2.4 随机森林api介绍
![]()
5.2.4 随机森林预测案例
(1)实例化随机森林
from sklearn.ensemble import RandomForestClassifier
# 随机森林去进行预测
rf = RandomForestClassifier()
(2)定义超参数的选择列表
from sklearn.model_selection import GridSearchCV
#超参数调优
param = {"n_estimators": [120,200,300,500,800,1200], "max_depth": [5, 8, 15, 25, 30]}
(3)使用GridSearchCV进行网格搜索
# 超参数调优
gc = GridSearchCV(rf, param_grid=param, cv=2)gc.fit(x_train, y_train)print("随机森林预测的准确率为:", gc.score(x_test, y_test))
注意:
- 随机森林的建立过程
- 树的深度、树的个数等需要进行超参数调优
5.2.5 bagging集成优点
Bagging + 决策树/线性回归/逻辑回归/深度学习… = bagging集成学习方法
经过上面方式组成的集成学习方法:
均可在原有算法上提高约2%左右的泛化正确率
简单, 方便, 通用
5.2.6 小结
![]()
5.3 otto案例介绍 – Otto Group Product Classification Challenge
5.3.1 背景介绍
奥托集团是世界上最⼤的电⼦商务公司之⼀,在20多个国家设有子公司。该公司每天都在世界各地销售数百万种产品, 所以对其产品根据性能合理的分类非常重要。
不过,在实际工作中,工作人员发现,许多相同的产品得到了不同的分类。本案例要求,你对奥拓集团的产品进行正确的分类。尽可能的提供分类的准确性。
链接:Otto Group Product Classification Challenge | Kaggle
https://www.kaggle.com/clotto-group-product-classification-challengeloverview
5.3.2 数据集介绍
- 本案例中,数据集包含大约200,000种产品的93个特征。
- 其目的是建立⼀个能够区分otto公司主要产品类别的预测模型。
- 所有产品共被分成九个类别(例如时装,电子产品等)。
- id - 产品id
- feat_1, feat_2, …, feat_93 - 产品的各个特征
- target - 产品被划分的类别

数据集网盘链接:
链接: https://pan.baidu.com/s/1MHh-RHTX38vqMrE83lAWZg?pwd=tw1q
提取码: tw1q
其中,sampleSubmission.csv是提交格式,(不过deadline已经过了,现在可以拿来做分类练手,提交后可以看到自己的排名,大佬云集!)。
train.csv是训练集,除了特征以外,还有类别用于模型训练。
test.csv是测试集,只有特征,类别得我们拿训练好的模型做预测。
5.3.3 评分标准
本案例中,最后结果使⽤多分类对数损失进行评估。
具体公式:
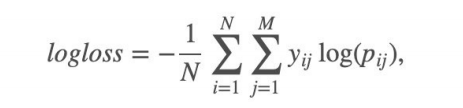
5.3.4 实现过程
(1)流程分析
- 获取数据
- 数据基本处理
- 数据量比较大,尝试是否可以进⾏数据分割
- 转换目标值表示方式
- 模型训练
- 模型基本训练
(2)代码实现
![]()
![]()
![]()
![]()
![]()
![]()
![]()
5.4 Boosting
![]()
5.4.1 什么是Boosting
![]()
随着学习的积累从弱到强
简而言之:每新加入一个弱学习器,整体能力就会得到提升
代表算法:
Adaboost,GBDT,XGBoost,LightGBM
5.4.2 实现过程
1.训练第⼀个学习器
![]()
2.调整数据分布
![]()
3.训练第二个学习器
![]()
4.再次调整数据分布
![]()
5.依次训练学习器,调整数据分布
![]()
6.整体过程实现
![]()
5.4.3 bagging集成与boosting集成的区别
区别⼀:数据方面
Bagging:对数据进行采样训练;
Boosting:根据前⼀轮学习结果调整数据的重要性。
区别二:投票方面
Bagging:所有学习器平权投票;
Boosting:对学习器进行加权投票。
区别三:学习顺序
Bagging的学习是并行的,每个学习器没有依赖关系;
Boosting学习是串行,学习有先后顺序。
区别四:主要作用
Bagging主要用于提高泛化性能(解决过拟合,也可以说降低方差)
Boosting主要用于提高训练精度 (解决欠拟合,也可以说降低偏差)
![]()
5.5 AdaBoost介绍
5.5.1 构造过程细节
![]()
5.5.2 关键点剖析
如何确认投票权重?
如何调整数据分布?
![]()
5.5.3 案例
给定下面这张训练数据表所示的数据,假设弱分类器由xv产⽣,其阈值v使该分类器在训练数据集上的分类误差率最低,试用Adaboost算法学习⼀个强分类器。
![]()
![]()
![]()
5.5.4 api介绍
from sklearn.ensemble import AdaBoostClassifier
api链接:https://scikitlearn.org/stable/modules/generated/sklearn.ensemble.AdaBoostClassifier.html
#sklearn.ensemble.AdaBoost Classifier5.5.5 小结
![]()
5.6 GBDT介绍
![]()
GBDT的全称是 Gradient Boosting Decision Tree,梯度提升树,在传统机器学习算法中,GBDT算的上TOP3的算法。想要理解GBDT的真正意义,那就必须理解GBDT中的Gradient Boosting和Decision Tree分别是什么?
5.6.1 Decision Tree: CART回归树
(1)回归树生成算法(复习)
![]()
5.6.2 Gradient Boosting:拟合负梯度
梯度提升树(Grandient Boosting)是提升树(Boosting Tree)的一种改进算法,所以在讲梯度提升树之前先来说一下提升树。
先来个通俗理解:假如有个人30岁,我们首先用20岁去拟合,发现损失有10岁,这时我们用6岁去拟合剩下的损失,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有一岁了。如果我们的迭代轮数还没有完,可以继续迭代下面,每一轮迭代,拟合的岁数误差都会减小。最后将每次拟合的岁数加起来便是模型输出的结果。
5.6.3 GBDT算法原理
![]()
5.6.4 实例介绍
(1)数据介绍
![]()
(2)模型训练
![]()
![]()
![]()
![]()
![]()
5.6.5 小结
![]()
6.聚类算法
学习目标
- 掌握聚类算法实现过程
- 知道K-means算法原理
- 知道聚类算法中的评估模型
- 说明K-means的优缺点
- 了解聚类中的算法优化方式
- 知道特征降维的实现过程
- 应用Kmeans实现聚类任务
6.1 认识聚类算法
![]()
使用不同的聚类准则,产生的聚类结果不同。
6.1.1 聚类算法在现实中的应用
用户画像,广告推荐,Data Segmentation,搜索引擎的流量推荐,恶意流量识别
基于位置信息的商业推送,新闻聚类,筛选排序
图像分割,降维,识别;离群点检测;信用卡异常消费;发掘相同功能的基因片段
![]()
6.1.2 聚类算法的概念
聚类算法:
一种典型的无监督学习算法,主要用于将相似的样本自动归到一个类别中。
在聚类算法中根据样本之间的相似性,将样本划分到不同的类别中,对于不同的相似度计算方法,会得到不同的聚类结果,常用的相似度计算方法有欧式距离法。
6.1.3 聚类算法与分类算法最大的区别
聚类算法是无监督的学习算法,而分类算法属于监督的学习算法。
6.1.4 小结
- 聚类算法分类
- 粗聚类
- 细聚类
- 聚类的定义
- 一种典型的无监督学习算法,
- 主要用于将相似的样本自动归到一个类别中
- 计算样本和样本之间的相似性,一般使用欧式距离
6.2 聚类算法api初步使用
![]()
6.2.1 api介绍
![]()
6.2.2 案例
随机创建不同二维数据集作为训练集,并结合k-means算法将其聚类,你可以尝试分别聚类不同数量的簇,并观察聚类效果:
聚类参数
n_cluster传值不同,得到的聚类结果不同:
(1)流程分析
![]()
(2)代码实现
1.创建数据集:
import matplotlib.pyplot as plt from sklearn.datasets import make_blobs from sklearn.cluster import KMeans from sklearn.metrics import calinski_harabasz_score# 创建数据集 # X为样本特征,Y为样本簇类别, 共1000个样本,每个样本4个特征,共4个簇, # 簇中心在[-1,-1], [0,0],[1,1], [2,2], 簇方差分别为[0.4, 0.2, 0.2, 0.2] X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],cluster_std=[0.4, 0.2, 0.2, 0.2],random_state=9)# 数据集可视化 plt.scatter(X[:, 0], X[:, 1], marker='o') plt.show()
2.使用k-means进行聚类,并使用CH方法评估
y_pred = KMeans(n_clusters=2, random_state=9).fit_predict(X) # 分别尝试n_cluses=2\3\4,然后查看聚类效果 plt.scatter(X[:, 0], X[:, 1], c=y_pred) plt.show()# 用Calinski-Harabasz Index评估的聚类分数 print(calinski_harabasz_score(X, y_pred))
6.2.3 小结
![]()
6.3 聚类算法实现流程
![]()
6.3.1 K-Means聚类步骤
- 随机设置K个特征空间内的点作为初始的聚类中心
- 对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
- 接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
- 如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程
通过下图解释实现流程:
![]()
6.3.2 案例练习
- 案例
编辑 - 1、随机设置K个特征空间内的点作为初始的聚类中心(本案例中设置p1和p2)
编辑 - 2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
编辑
编辑 - 3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
编辑 - 4、如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程【经过判断,需要重复上述步骤,开始新一轮迭代】
编辑
编辑 - 5、当每次迭代结果不变时,认为算法收敛,聚类完成,K-Means一定会停下,不可能陷入一直选质心的过程。
编辑
6.3.3 小结
![]()
6.4 模型评估
6.4.1 误差平方和(SSE \The sum of squares due to error)
举例:(下图中数据-0.2, 0.4, -0.8, 1.3, -0.7, 均为真实值和预测值的差)
在
K-Means中的应用:
公式各部分内容:
上图中:
K=2
- SSE图最终的结果,对图松散度的衡量.(eg: SSE(左图)<SSE(右图))
- SSE随着聚类迭代,其值会越来越小,直到最后趋于稳定
- 如果质心的初始值选择不好,SSE只会达到一个不怎么好的局部最优解.
6.4.2 “肘”方法 (Elbow method) — K值确定
![]()
- (1)对于n个点的数据集,迭代计算k from 1 to n,每次聚类完成后计算每个点到其所属的簇中心的距离的平方和;
- (2)平方和是会逐渐变小的,直到k==n时平方和为0,因为每个点都是它所在的簇中心本身。
- (3)在这个平方和变化过程中,会出现一个拐点也即“肘”点,下降率突然变缓时即认为是最佳的k值。
在决定什么时候停止训练时,肘形判据同样有效,数据通常有更多的噪音,在增加分类无法带来更多回报时,我们停止增加类别。
6.4.3 轮廓系数法(Silhouette Coefficient)
结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类的效果:
目的:
内部距离最小化,外部距离最大化
案例:
下图是500个样本含有2个feature的数据分布情况,我们对它进行SC系数效果衡量:
k=2的情况:
k=4的情况:
n_clusters = 2时,第0簇的宽度远宽于第1簇;
n_clusters = 4时,所聚的簇宽度相差不大,因此选择K=4,作为最终聚类个数。
6.4.4 CH系数(Calinski-Harabasz Index)
类别内部数据的协方差越小越好,类别之间的协方差越大越好(换句话说:类别内部数据的距离平方和越小越好,类别之间的距离平方和越大越好),
这样的
Calinski-Harabasz分数s会高,分数s高则聚类效果越好。
tr为矩阵的迹, Bk为类别之间的协方差矩阵,Wk为类别内部数据的协方差矩阵;
m为训练集样本数,k为类别数。
使用矩阵的迹进行求解的理解:
矩阵的对角线可以表示一个物体的相似性。
在机器学习里,主要为了获取数据的特征值,那么就是说,在任何一个矩阵计算出来之后,都可以简单化,只要获取矩阵的迹,就可以表示这一块数据的最重要的特征了,这样就可以把很多无关紧要的数据删除掉,达到简化数据,提高处理速度。
CH需要达到的目的:
用尽量少的类别聚类尽量多的样本,同时获得较好的聚类效果。
6.4.5 小结
![]()
6.5 算法优化
![]()
k-means算法小结
优点:
- 原理简单(靠近中心点),实现容易
- 聚类效果中上(依赖K的选择)
- 空间复杂度O(N),时间复杂度O(IKN)
N为样本点个数,K为中心点个数,I为迭代次数缺点:
对离群点,噪声敏感 (中心点易偏移)
很难发现大小差别很大的簇及进行增量计算
结果不一定是全局最优,只能保证局部最优(与K的个数及初值选取有关)
6.5.1 Canopy算法配合初始聚类
(1)Canopy算法配合初始聚类实现流程
![]()
(2)Canopy算法的优缺点
![]()
6.5.2 K-means++
![]()
为方便后面表示,把其记为 A
![]()
Kmeans++目的,让选择的质心尽可能的分散
如下图中,如果第一个质心选择在圆心,那么最优可能选择到的下一个点在P(A)这个区域(根据颜色进行划分)
![]()
6.5.3 二分k-means
实现流程:
1.所有点作为一个簇。
2.将该簇一分为二。
3.选择能最大限度降低聚类代价函数(也就是误差平方和)的簇划分为两个簇。
4.以此进行下去,直到簇的数目等于用户给定的数目k为止。
![]()
隐含的一个原则
因为聚类的误差平方和能够衡量聚类性能,该值越小表示数据点越接近于他们的质心,聚类效果就越好。所以需要对误差平方和最大的簇进行再一次划分,因为误差平方和越大,表示该簇聚类效果越不好,越有可能是多个簇被当成了一个簇,所以我们首先需要对这个簇进行划分。
二分K均值算法可以加速K-means算法的执行速度,因为它的相似度计算少了并且不受初始化问题的影响,因为这里不存在随机点的选取,且每一步都保证了误差最小。
6.5.4 k-medoids(k-中心聚类算法)
K-medoids和K-means是有区别的,不一样的地方在于中心点的选取
- K-means中,将中心点取为当前cluster中所有数据点的平均值,对异常点很敏感!
- K-medoids中,将从当前cluster 中选取到其他所有(当前cluster中的)点的距离之和最小的点作为中心点。
![]()
算法流程:
( 1 )总体n个样本点中任意选取k个点作为medoids
( 2 )按照与medoids最近的原则,将剩余的n-k个点分配到当前最佳的medoids代表的类中
( 3 )对于第i个类中除对应medoids点外的所有其他点,按顺序计算当其为新的medoids时,代价函数的值,遍历所有可能,选取代价函数最小时对应的点作为新的medoids
( 4 )重复2-3的过程,直到所有的medoids点不再发生变化或已达到设定的最大迭代次数
( 5 )产出最终确定的k个类
k-medoids对噪声鲁棒性好。
例:当一个cluster样本点只有少数几个,如(1,1)(1,2)(2,1)(1000,1000)。其中(1000,1000)是噪声。如果按照k-means质心大致会处在(1,1)(1000,1000)中间,这显然不是我们想要的。这时k-medoids就可以避免这种情况,他会在(1,1)(1,2)(2,1)(1000,1000)中选出一个样本点使cluster的绝对误差最小,计算可知一定会在前三个点中选取。
k-medoids只能对小样本起作用,样本大,速度就太慢了,当样本多的时候,少数几个噪音对k-means的质心影响也没有想象中的那么重,所以k-means的应用明显比k-medoids多。
6.5.5 Kernel k-means(了解)
kernel k-means实际上,就是将每个样本进行一个投射到高维空间的处理,然后再将处理后的数据使用普通的k-means算法思想进行聚类。
6.5.6 ISODATA
类别数目随着聚类过程而变化;
对类别数会进行合并,分裂,
“合并”:(当聚类结果某一类中样本数太少,或两个类间的距离太近时)
“分裂”:(当聚类结果中某一类的类内方差太大,将该类进行分裂)
6.5.7 Mini Batch K-Means
适合大数据的聚类算法。
大数据量是什么量级?通常当样本量大于1万做聚类时,就需要考虑选用Mini Batch K-Means算法。
Mini Batch KMeans使用了Mini Batch(分批处理)的方法对数据点之间的距离进行计算。
Mini Batch计算过程中不必使用所有的数据样本,而是从不同类别的样本中抽取一部分样本来代表各自类型进行计算。由于计算样本量少,所以会相应的减少运行时间,但另一方面抽样也必然会带来准确度的下降。
该算法的迭代步骤有两步:
(1)从数据集中随机抽取一些数据形成小批量,把他们分配给最近的质心
(2)更新质心
与Kmeans相比,数据的更新在每一个小的样本集上。对于每一个小批量,通过计算平均值得到更新质心,并把小批量里的数据分配给该质心,随着迭代次数的增加,这些质心的变化是逐渐减小的,直到质心稳定或者达到指定的迭代次数,停止计算。
6.5.8 小结
![]()
6.6 特征工程-特征降维
学习目标
- 了解降维的定义
- 知道通过低方差过滤实现降维过程
- 知道相关系数实现降维的过程
- 知道主成分分析法实现过程
6.6.1 降维
(1)定义
降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程。
- 降低随机变量的个数
- 相关特征(correlated feature)
-相对湿度与降雨量之间的相关
-等等正是因为在进行训练的时候,我们都是使用特征进行学习。如果特征本身存在问题或者特征之间相关性较强,对于算法学习预测会影响较大
(2)降维的两种方式
- 特征选择
- 主成分分析(可以理解一种特征提取的方式)
6.6.2 特征选择
(1)定义
数据中包含冗余或无关变量(或称特征、属性、指标等),旨在从原有特征中找出主要特征。
(2)方法
- Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关联
- 方差选择法:低方差特征过滤
- 相关系数
- Embedded (嵌入式):算法自动选择特征(特征与目标值之间的关联)
- 决策树:信息熵、信息增益
- 正则化:L1、L2
- 深度学习:卷积等
(3)低方差特征过滤
删除低方差的一些特征,前面讲过方差的意义。再结合方差的大小来考虑这个方式的角度。
- 特征方差小:某个特征大多样本的值比较相近
- 特征方差大:某个特征很多样本的值都有差别
1.API:
2.数据计算:
我们对某些股票的指标特征之间进行一个筛选,除去
'index,'date','return'列不考虑(这些类型不匹配,也不是所需要指标)一共这些特征:
pe_ratio,pb_ratio,market_cap,return_on_asset_net_profit,du_return_on_equity,ev,earnings_per_share,revenue,total_expenseindex,pe_ratio,pb_ratio,market_cap,return_on_asset_net_profit,du_return_on_equity,ev,earnings_per_share,revenue,total_expense,date,return 0,000001.XSHE,5.9572,1.1818,85252550922.0,0.8008,14.9403,1211444855670.0,2.01,20701401000.0,10882540000.0,2012-01-31,0.027657228229937388 1,000002.XSHE,7.0289,1.588,84113358168.0,1.6463,7.8656,300252061695.0,0.326,29308369223.2,23783476901.2,2012-01-31,0.08235182370820669 2,000008.XSHE,-262.7461,7.0003,517045520.0,-0.5678,-0.5943,770517752.56,-0.006,11679829.03,12030080.04,2012-01-31,0.09978900335112327 3,000060.XSHE,16.476,3.7146,19680455995.0,5.6036,14.617,28009159184.6,0.35,9189386877.65,7935542726.05,2012-01-31,0.12159482758620697 4,000069.XSHE,12.5878,2.5616,41727214853.0,2.8729,10.9097,81247380359.0,0.271,8951453490.28,7091397989.13,2012-01-31,-0.0026808154146886697
- 分析
1、初始化
VarianceThreshold,指定阀值方差2、调用
fit_transformimport pandas as pd from sklearn.feature_selection import VarianceThresholddef var_thr():"""特征选择:低方差特征过滤:return:None"""data=pd.read_csv(r'D:\各种编译器的代码\pythonProject12\机器学习\Datas\factor_returns.csv')# print(data)#1.实例化一个转换器transfer=VarianceThreshold(threshold=1)#2.调用fit_transformdata=transfer.fit_transform(data.iloc[:,1:10])print("删除低方差特征的结果:\n", data)print("形状:\n", data.shape)if __name__ == '__main__':var_thr()
(4)相关系数
主要实现方式:
- 皮尔逊相关系数
- 斯皮尔曼相关系数
1.皮尔逊相关系数
1.1 作用:反映变量之间相关关系密切程度的统计指标。
1.2 公式计算案例:
举例
1.3 特点:
1.4 api:
1.5 案例:from scipy.stats import pearsonrx1 = [12.5, 15.3, 23.2, 26.4, 33.5, 34.4, 39.4, 45.2, 55.4, 60.9] x2 = [21.2, 23.9, 32.9, 34.1, 42.5, 43.2, 49.0, 52.8, 59.4, 63.5]print(pearsonr(x1, x2)) """ 运行结果:第一个是相关系数 (0.9941983762371884, 4.922089955456964e-09) """
2.斯皮尔曼相关系数【常用】
2.1 作用:反映变量之间相关关系密切程度的统计指标。
2.2 公式计算案例:
2.3 特点:
- 斯皮尔曼相关系数表明 X (自变量) 和 Y (因变量)的相关方向。 如果当X增加时, Y 趋向于增加, 斯皮尔曼相关系数则为正
- 与之前的皮尔逊相关系数大小性质一样,取值 [-1, 1]之间
- 斯皮尔曼相关系数比皮尔逊相关系数应用更加广泛
2.4 api:
from scipy.stats import spearmanr
2.5 举例:from scipy.stats import spearmanrx1 = [12.5, 15.3, 23.2, 26.4, 33.5, 34.4, 39.4, 45.2, 55.4, 60.9] x2 = [21.2, 23.9, 32.9, 34.1, 42.5, 43.2, 49.0, 52.8, 59.4, 63.5]print(spearmanr(x1, x2)) """ 运行结果:第一个是相关性系数 SpearmanrResult(correlation=0.9999999999999999, pvalue=6.646897422032013e-64) """
6.6.3 主成分分析
(1) 什么是主成分分析(PCA)
- 定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量
- 作用:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
- 应用:回归分析或者聚类分析当中
(2)API
![]()
(3)数据计算
from sklearn.decomposition import PCA#主成分分析def pca_demo():"""对数据进行pca降维:return:None"""data=[[2,8,4,5],[6,3,0,8],[5,4,9,1]]#1.实例化PCA,小数——保留多少信息transfer=PCA(n_components=0.9)#2.调用fit_transformdata1=transfer.fit_transform(data)print('保留90%的信息,降维结果是:\n',data1)# 1.实例化PCA,整数——指定降维到的维度transfer2 = PCA(n_components=3)# 2.调用fit_transformdata2 = transfer2.fit_transform(data)print('保留三列数据:\n', data2)return Noneif __name__ == '__main__':pca_demo()运行结果:
保留90%的信息,降维结果是:[[-3.13587302e-16 3.82970843e+00][-5.74456265e+00 -1.91485422e+00][ 5.74456265e+00 -1.91485422e+00]]
保留三列数据:[[-3.13587302e-16 3.82970843e+00 4.59544715e-16][-5.74456265e+00 -1.91485422e+00 4.59544715e-16][ 5.74456265e+00 -1.91485422e+00 4.59544715e-16]]6.6.4 小结
![]()
6.7 案例:探究用户对物品类别的喜好细分
学习目标
- 应用pca和K-means实现用户对物品类别的喜好细分划分
数据是在kaggle中找的:Instacart Market Basket Analysis | Kaggle
![]()
![]()
6.7.1 需求
![]()
6.7.2 分析
![]()
6.7.3 完整代码
![]()
![]()
![]()
机器学习之算法部分(算法篇1)相关推荐
- 轻松看懂机器学习十大常用算法
本文转载自CSDN aliceyangxi1987的博客 通过本篇文章可以对机器学习(machine learning, ML)的常用算法有个常识性的认识,没有代码,没有复杂的理论推导,就是图解一下, ...
- 机器学习中的最优化算法总结
https://www.toutiao.com/a6672189997212238348/ 导言 对于几乎所有机器学习算法,无论是有监督学习.无监督学习,还是强化学习,最后一般都归结为求解最优化问题. ...
- 机器学习系列之EM算法
机器学习系列之EM算法 我讲EM算法的大概流程主要三部分:需要的预备知识.EM算法详解和对EM算法的改进. 一.EM算法的预备知识 1.极大似然估计 (1)举例说明:经典问题--学生身高问题 我们需要 ...
- louvian算法 缺点 优化_机器学习中的优化算法(1)-优化算法重要性,SGD,Momentum(附Python示例)...
本系列文章已转至 机器学习的优化器zhuanlan.zhihu.com 优化算法在机器学习中扮演着至关重要的角色,了解常用的优化算法对于机器学习爱好者和从业者有着重要的意义. 这系列文章先讲述优化算 ...
- 最优化算法python实现篇(4)——无约束多维极值(梯度下降法)
最优化算法python实现篇(4)--无约束多维极值(梯度下降法) 摘要 算法简介 注意事项 算法适用性 python实现 实例运行结果 算法过程可视化 摘要 本文介绍了多维无约束极值优化算法中的梯度 ...
- 轻松看懂机器学习十大常用算法 - 基础知识
通过本篇文章可以对机器学习ML的常用算法有个常识性的认识,没有代码,没有复杂的理论推导,就是图解一下,知道这些算法是什么,它们是怎么应用的,例子主要是分类问题. 算法如下: 决策树 随机森林算法 逻辑 ...
- 机器学习十大经典算法之决策树
机器学习经典十大算法 机器学习/人工智能的子领域在过去几年越来越受欢迎.目前大数据在科技行业已经炙手可热,而基于大量数据来进行预测或者得出建议的机器学习无疑是非常强大的.一些最常见的机器学习例子,比如 ...
- 机器学习中树模型算法总结之 决策树(下)
写在前面 首先回顾一下上一篇的相关内容,主要是理论的介绍了决策树的模型及几种常见的特征选择准则,具体可参见机器学习中树模型算法总结之 决策树(上).今天主要接着学习,包括决策树的生成(依赖于第一篇的三 ...
- GBDT 算法:原理篇
2019独角兽企业重金招聘Python工程师标准>>> 本文由云+社区发表 GBDT 是常用的机器学习算法之一,因其出色的特征自动组合能力和高效的运算大受欢迎. 这里简单介绍一下 G ...
- 机器学习10大经典算法详解
"数据+算法=模型". 面对具体的问题,选择切合问题的模型进行求解十分重要.有经验的数据科学家根据日常算法的积累,往往能在最短时间内选择更适合该问题的算法,因此构建的模型往往更准确 ...
最新文章
- 史上最全SQL优化方案(二)
- 时序分析中的关键术语
- 存储型xss_web安全测试--XSS(跨站脚本)与CSRF
- SQL Server 2008 BIDS组件的安装
- 高质量C++/C编程指南 ver 1.0
- .NET Core IdentityServer4实战 第六章-Consent授权页
- Java,JavaFX的流畅设计风格进度栏
- microsoft office 卸载不了
- UI素材|管理系统数字可视化界面
- android webview打印,javascript - 如何在Android Webview中使网站上的打印按钮工作? - 堆栈内存溢出...
- DRILLNET 2.0------第二十章 高温高压钻井水力计算模型
- 修航片调卫片,不会PS的GISer不是一个好“美工“
- Linux常见命令tar
- Cortex-M3 (NXP LPC1788)之ADC模/数转换器
- Docker 配置国内源加速镜像下载
- 怎样促进计算机专业发展,【计算机教学论文】怎样促进计算机技术应用及改善(共4879字)...
- CSS设置 background-image透明度小技巧
- 谷粒商城-分布式事务
- STM32F103C8T6的高低电平范围
- 查询没有选修java的学生_查询没有考试的学生学号和课程号