GBDT 算法:原理篇
2019独角兽企业重金招聘Python工程师标准>>> 
本文由云+社区发表
GBDT 是常用的机器学习算法之一,因其出色的特征自动组合能力和高效的运算大受欢迎。 这里简单介绍一下 GBDT 算法的原理,后续再写一个实战篇。
1、决策树的分类
决策树分为两大类,分类树和回归树。
分类树用于分类标签值,如晴天/阴天/雾/雨、用户性别、网页是否是垃圾页面;
回归树用于预测实数值,如明天的温度、用户的年龄、网页的相关程度;
两者的区别:
- 分类树的结果不能进行加减运算,晴天 晴天没有实际意义;
- 回归树的结果是预测一个数值,可以进行加减运算,例如 20 岁 3 岁=23 岁。
- GBDT 中的决策树是回归树,预测结果是一个数值,在点击率预测方面常用 GBDT,例如用户点击某个内容的概率。
2、GBDT 概念
GBDT 的全称是 Gradient Boosting Decision Tree,梯度提升决策树。
要理解 GBDT,首先就要理解这个 B(Boosting)。
Boosting 是一族可将弱学习器提升为强学习器的算法,属于集成学习(ensemble learning)的范畴。Boosting 方法基于这样一种思想:对于一个复杂任务来说,将多个专家的判断进行适当的综合所得出的判断,要比其中任何一个专家单独的判断要好。通俗地说,就是"三个臭皮匠顶个诸葛亮"的道理。
基于梯度提升算法的学习器叫做 GBM(Gradient Boosting Machine)。理论上,GBM 可以选择各种不同的学习算法作为基学习器。GBDT 实际上是 GBM 的一种情况。
为什么梯度提升方法倾向于选择决策树作为基学习器呢?(也就是 GB 为什么要和 DT 结合,形成 GBDT) 决策树可以认为是 if-then 规则的集合,易于理解,可解释性强,预测速度快。同时,决策树算法相比于其他的算法需要更少的特征工程,比如可以不用做特征标准化,可以很好的处理字段缺失的数据,也可以不用关心特征间是否相互依赖等。决策树能够自动组合多个特征。
不过,单独使用决策树算法时,有容易过拟合缺点。所幸的是,通过各种方法,抑制决策树的复杂性,降低单颗决策树的拟合能力,再通过梯度提升的方法集成多个决策树,最终能够很好的解决过拟合的问题。由此可见,梯度提升方法和决策树学习算法可以互相取长补短,是一对完美的搭档。
至于抑制单颗决策树的复杂度的方法有很多,比如限制树的最大深度、限制叶子节点的最少样本数量、限制节点分裂时的最少样本数量、吸收 bagging 的思想对训练样本采样(subsample),在学习单颗决策树时只使用一部分训练样本、借鉴随机森林的思路在学习单颗决策树时只采样一部分特征、在目标函数中添加正则项惩罚复杂的树结构等。
演示例子:
考虑一个简单的例子来演示 GBDT 算法原理。
下面是一个二分类问题,1 表示可以考虑的相亲对象,0 表示不考虑的相亲对象。
特征维度有 3 个维度,分别对象 身高,金钱,颜值
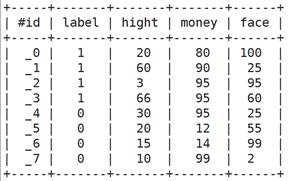
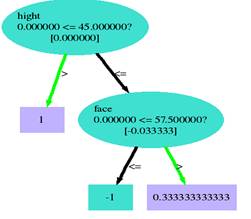
对应这个例子,训练结果是 perfect 的,全部正确, 特征权重可以看出,对应这个例子训练结果颜值的重要度最大,看一下训练得到的树。
Tree 0:
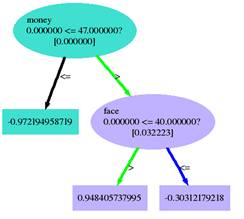
Tree 1:
3、原理推导
3.1 目标函数
监督学习的关键概念:模型(model)、参数(parameters)、目标函数(objective function)
模型就是所要学习的条件概率分布或者决策函数,它决定了在给定特征向量时如何预测出目标。
参数就是我们要从数据中学习得到的内容。模型通常是由一个参数向量决定的函数。
目标函数通常定义为如下形式:
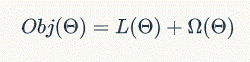
其中,L 是损失函数,用来衡量模型拟合训练数据的好坏程度;Ω称之为正则项,用来衡量学习到的模型的复杂度。
对正则项的优化鼓励算法学习到较简单的模型,简单模型一般在测试样本上的预测结果比较稳定、方差较小(奥坎姆剃刀原则)。也就是说,优化损失函数尽量使模型走出欠拟合的状态,优化正则项尽量使模型避免过拟合。
3.2 加法模型
GBDT 算法可以看成是由 K 棵树组成的加法模型:

如何来学习加法模型呢?
解这一优化问题,可以用前向分布算法(forward stagewise algorithm)。因为学习的是加法模型,如果能够从前往后,每一步只学习一个基函数及其系数(结构),逐步逼近优化目标函数,那么就可以简化复杂度。这一学习过程称之为 Boosting。具体地,我们从一个常量预测开始,每次学习一个新的函数,过程如下:
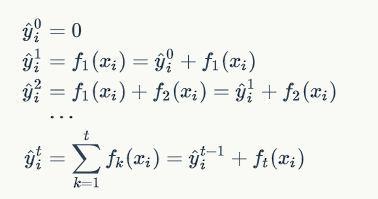
在第 t 步,这个时候目标函数可以写为:
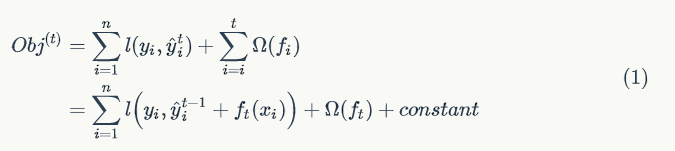
举例说明,假设损失函数为平方损失(square loss),则目标函数为:
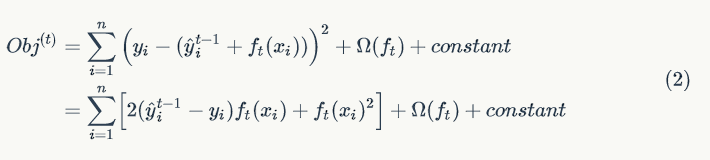
其中,称
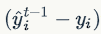
之为残差(residual)。因此,使用平方损失函数时,GBDT 算法的每一步在生成决策树时只需要拟合前面的模型的残差。
3.3 泰勒公式
定义:

泰勒公式简单的理解,就是函数某个点的取值可以用参考点取值和 n+1 阶导数的来表示,而且这个公式是有规律的比较好记。
根据泰勒公式把函数
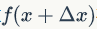
在
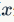
点处二阶展开,可得到如下等式:
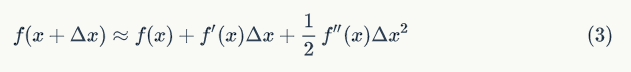
则等式(1) 可转化为:
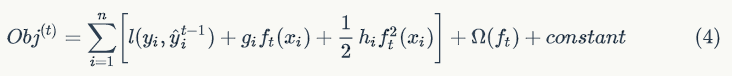
假设损失函数为平方损失函数,把对应的一阶导数和二阶导数代入等式(4) 即得等式(2)。
由于函数中的常量在函数最小化的过程中不起作用,因此我们可以从等式(4) 中移除掉常量项,得:
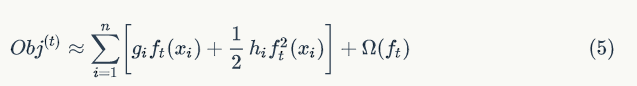
3.4 GBDT 算法
一颗生成好的决策树,假设其叶子节点个数为
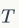
,
决策树的复杂度可以由正则项
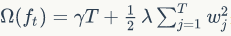
来定义,即决策树模型的复杂度由生成的树的叶子节点数量和叶子节点对应的值向量的 L2 范数决定。
定义集合
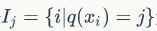
为所有被划分到叶子节点的训练样本的集合。等式(5) 可以根据树的叶子节点重新组织为 T 个独立的二次函数的和:
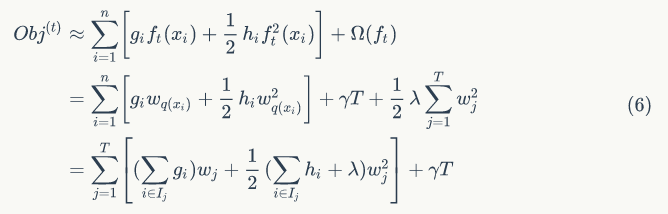
定义
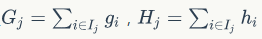
,则等式(6) 可写为:
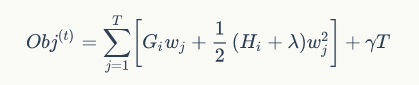
因为一元二次函数最小值处,一阶导数等于 0:

此时,目标函数的值为
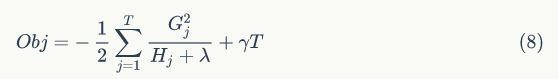
综上,为了便于理解,单颗决策树的学习过程可以大致描述为: 1. 枚举所有可能的树结构 q 2. 用等式(8) 为每个 q 计算其对应的分数 Obj,分数越小说明对应的树结构越好 3. 根据上一步的结果,找到最佳的树结构,用等式(7) 为树的每个叶子节点计算预测值
然而,可能的树结构数量是无穷的,所以实际上我们不可能枚举所有可能的树结构。通常情况下,我们采用贪心策略来生成决策树的每个节点。
\1. 从深度为 0 的树开始,对每个叶节点枚举所有的可用特征 2. 针对每个特征,把属于该节点的训练样本根据该特征值升序排列,通过线性扫描的方式来决定该特征的最佳分裂点,并记录该特征的最大收益(采用最佳分裂点时的收益) 3. 选择收益最大的特征作为分裂特征,用该特征的最佳分裂点作为分裂位置,把该节点生长出左右两个新的叶节点,并为每个新节点关联对应的样本集 4. 回到第 1 步,递归执行到满足特定条件为止
3.5 收益的计算
如何计算每次分裂的收益呢?假设当前节点记为 C,分裂之后左孩子节点记为 L,右孩子节点记为 R,则该分裂获得的收益定义为当前节点的目标函数值减去左右两个孩子节点的目标函数值之和:

根据等式(8) 可得:
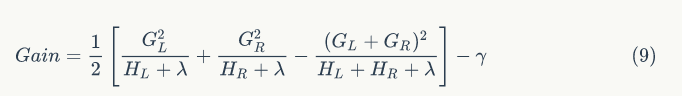
其中,
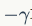
项表示因为增加了树的复杂性(该分裂增加了一个叶子节点)带来的惩罚。
最后,总结一下 GBDT 的学习算法:
- 算法每次迭代生成一颗新的决策树 ;
- 在每次迭代开始之前,计算损失函数在每个训练样本点的一阶导数和二阶导数 ;
- 通过贪心策略生成新的决策树,通过等式(7) 计算每个叶节点对应的预测值
- 把新生成的决策树
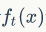
添加到模型中:
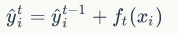
保持简单
易经中说道"易则易知,简则易从",就是越是简易的东西,越是容易被理解和得到执行。很多机器学习模型都会尽量让学习到的模型尽量简单,尽量减少参数,越是简单的模型,通用性越好,也是这个道理。
Xgboost 和 GBDT 的区别:
GBDT:
- GBDT 它的非线性变换比较多,表达能力强,而且不需要做复杂的特征工程和特征变换。
- GBDT 的缺点也很明显,Boost 是一个串行过程,不好并行化,而且计算复杂度高,同时不太适合高维稀疏特征;
- 传统 GBDT 在优化时只用到一阶导数信息。
Xgboost:
它有以下几个优良的特性:
- 显示的把树模型复杂度作为正则项加到优化目标中。
- 公式推导中用到了二阶导数,用了二阶泰勒展开。(GBDT 用牛顿法貌似也是二阶信息)
- 实现了分裂点寻找近似算法。
- 利用了特征的稀疏性。
- 数据事先排序并且以 block 形式存储,有利于并行计算。
- 基于分布式通信框架 rabit,可以运行在 MPI 和 yarn 上。(最新已经不基于 rabit 了)
- 实现做了面向体系结构的优化,针对 cache 和内存做了性能优化。
此文已由作者授权腾讯云+社区在各渠道发布
获取更多新鲜技术干货,可以关注我们腾讯云技术社区-云加社区官方号及知乎机构号
转载于:https://my.oschina.net/qcloudcommunity/blog/2996643
GBDT 算法:原理篇相关推荐
- 通俗易懂理解GBDT算法原理-转
GBDT算法深入解析 https://www.zybuluo.com/yxd/note/611571 通俗易懂理解GBDT算法原理 https://blog.csdn.net/qq_36696494/ ...
- GBDT算法原理深入分析
GBDT算法原理深入分析1 https://www.zybuluo.com/yxd/note/611571 GBDT算法原理深入分析2 https://www.wandouip.com/t5i1874 ...
- 微信技术分享:微信的海量IM聊天消息序列号生成实践(算法原理篇)
1.点评 对于IM系统来说,如何做到IM聊天消息离线差异拉取(差异拉取是为了节省流量).消息多端同步.消息顺序保证等,是典型的IM技术难点. 就像即时通讯网整理的以下IM开发干货系列一样: <I ...
- xgboost算法_xgboost算法原理篇
1, 概述部分 这篇文章,主要来介绍一下xgboost的理论部分,可能会不够详细,由于xgboost算法相比较前三篇文章中提到的算法更加复杂,这里主要讲解一下损失函数正则化,切分点查找算法及其优化,叶 ...
- 决策树与剪枝、bagging与随机森林、极端随机树、Adaboost、GBDT算法原理详解
目录 1.决策树 1.1 ID3 1.2 C4.5 1.3 CART 1.4 预剪枝和后剪枝 2 bagging与随机森林 2.1 bagging 2.2 随机森林 3 极端随机树 4 GBDT 5 ...
- GBDT算法原理个人总结
0.前言 本文仅仅是自己的学习总结,好记性不如烂笔头,相信对你也会有一些启发吧,可能会与其他博客有很多相似的地方,如若侵权,立删. 1.提升树 在讲GBDT之前,首先要讲一下提升树(Boosting ...
- 【算法原理篇】个性化搜索的介绍,推荐和搜索的强强结合
作者:Pavel Kordík 编译:ronghuaiyang 导读 一般来说,搜索是非个性化的,不过如果和推荐系统组合起来,也会有意想不到的效果. 寻找正确的信息总是很困难的.在不久之前,文档还是存 ...
- GBDT算法原理及附有源码实现的 转
https://blog.csdn.net/zpalyq110/article/details/79527653
- gbdt算法_GBDT算法原理及应用
是新朋友吗?记得先点蓝字关注我哦- 作者介绍 知乎@王多鱼 京东的一名推荐算法攻城狮. 主要负责商品推荐的召回和排序模型的优化工作. 一.GBDT算法原理 Gradient Boosting Deci ...
最新文章
- 软件项目管理重点总结
- Javascript深入浅出
- 华为BGP动态路由协议理论
- php usort strcmp,字符串函数演示和usort()进行二维数组排序(0827)
- thinkphp使用问题
- vuejs npm chromedriver 报错
- 安装在电脑上的网络测试软件,iperf3 网络测试工具
- 许家印深夜主持集团营销大会:恒大全国楼盘全线7折!
- 简单明了的普利姆算法
- 双非二本计算机学生是应该考研还是就业
- 详谈SSD硬盘接口: SATA、mSATA 、PCIe、M.2和U.2
- 指定的文件夹没有包含设备的兼容软件驱动程序...请确认它是为用于基于X64的系统的Windows设计的
- HTML DOM属性和方法
- 企业转型升级,务必抓住“企业上云”政策红利
- [论文阅读]PAN++: Towards Efficient and Accurate End-to-End Spotting of Arbitrarily-Shaped Text
- python import变灰_python--pycharm中import导入包呈现灰色问题之解决~很实用
- IOS个人账户转公司账户,TPshop APP提交审核
- VM-CtenOS-8+Linux-8+LANMP环境中安装phpMyAdmin
- org.eclipse.wst.common.component文件位置
- unity3d 禁用脚本