【总结向】从CMRC2019头部排名看中文MRC
文章目录
- 0 预备知识
- 数据集
- 中文MRC任务要点(融合CMRC2018-2019)
- 任务类型
- 数据增强与扩充
- 数据处理
- 文本向量化表达
- 特征融合
- 训练方法
- 预训练模型
- 预测目标
- 其他:trick & 问题
- 实用工具
- 应用
- 1 冠军:平安金融
- 纲要
- 策略
- 核心
- 连贯性学习
- SiBert
- 负样本的连贯性
- 非独立性的预测方式
- 文本长度与分词
- 领域迁移
- 消融实验
- 总结
- 2 亚军:顺丰 Mojito System
- 预处理
- 预训练
- 模型
- 预测策略
- 实验结果
- 错误分析
- 3 季军:6Estates
- 数据集分析
- 策略与方法
- 数据集扩充,分布调整
- 预训练
- 单个choice拼接预测
- 多个choice拼接预测
- 多choice vs 单choice
- 集成模型
- 改进
- 4 季军:哈工大
- 模型架构
- 数据增强
- 学习率
- 训练方法
- 数据增强与原始数据的 混合模式 选择
- 排除干扰项
- 实验结果
- 5 季军:CICC
- 实验结果和消融分析
- 反思
- 6 启发
- 7 参考
- 网页
- ppt提到的论文
0 预备知识
数据集
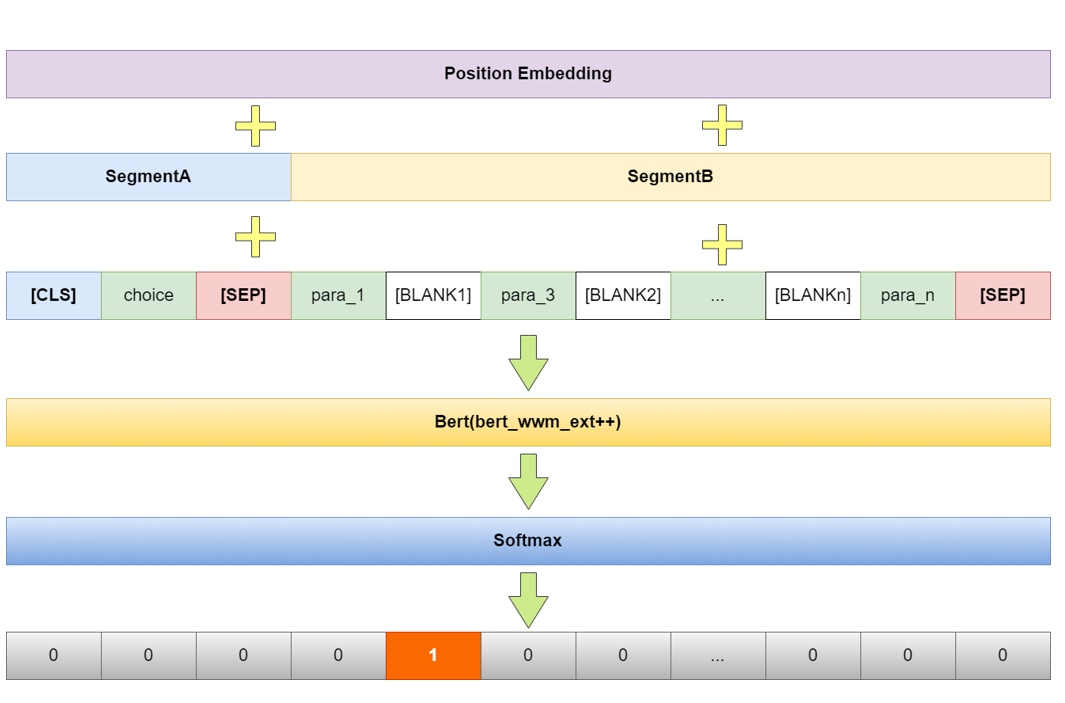
CMRC 2019的任务是句子级填空型阅读理解(Sentence Cloze-Style Machine Reading Comprehension, SC-MRC)。我个人感觉类似7选5 or 5选5的题型。.根据给定的一个叙事篇章以及若干个从篇章中抽取出的句子,参赛者需要建立模型将候选句子精准的填回原篇章中,使之成为完整的一篇文章。SC级的任务提升了MRC难度。
难点:需要根据上下文逻辑关系判断空穴部分;减少干扰项的影响
![]()
数据集样式
| JSON字段 | 介绍 |
|---|---|
| context |
带空缺的篇章,空缺以[BLANK]表示
|
| context_id | 篇章的ID, 唯一 |
| choices | 填入空缺内的候选句子,有序列表 |
| answers | 填入空缺的句子序号顺序(句子序号从0开始计数) |
JSON举例(包含假选项)
{"data": [{"context": "森林里有一棵大树,树上有一个鸟窝。[BLANK1],还从来没有看到过鸟宝宝长什么样。 小松鼠说:“我爬到树上去看过,鸟宝宝光溜溜的,身上一根羽毛也没有。” “我不相信,”小白兔说,“所有的鸟都是有羽毛的。” “鸟宝宝没有羽毛。”小松鼠说,“你不信自己去看。” 小白兔不会爬树,它没有办法去看。小白兔说:“我请蓝狐狸去看一看,我相信蓝狐狸的话。” 小松鼠说:“蓝狐狸跟你一样,也不会爬树。” 蓝狐狸说:“我有魔法树叶,我能变成一只狐狸鸟。” [BLANK2],一下子飞到了树顶上。 “蓝狐狸,你看到了吗?”小白兔在树下大声喊。 “我看到了,鸟窝里有四只小鸟,他们真是光溜溜的,一根羽毛也没有。”蓝狐狸说。 就在这时候,鸟妈妈和鸟爸爸回来了,[BLANK3],....[BLANK8]....","choices": ["蓝狐狸是第一次变成狐狸鸟","森林里所有的鸟听到喊声","他们看到鸟窝里蹲着一只蓝色的大鸟","蓝狐狸真的变成了一只蓝色的大鸟","小动物们只看到过鸟妈妈和鸟爸爸在鸟窝里飞进飞出","小松鼠变成了一只蓝色的大鸟"],"context_id": "SAMPLE_00002","answers": [4,3,2,1,0]}]
}
CMRC 2018的数据集和SQuAD类型相似,来源于中文维基百科,单文档,给定一篇文档和一个问题;参赛者需要解决的是,如何建立并训练 model,使其能更好地理解 context 与 query,并找到相应答案。
在数据方面,主要工作集中在数据的归一化和去噪音。CMRC 比赛训练集包含大约一万条数据,总体数据量偏少,这种情况下数据的标注一致性尤为重要。(标注不一致的问题会使模型的最终预测 EM 指标降低)
相关资讯
- CMRC官网介绍:https://hfl-rc.github.io/cmrc2019/task/
中文MRC任务要点(融合CMRC2018-2019)
任务类型
完形填空
多选
考虑输入拼接方式,比如是单个choice预测 还是 多个choice预测(6estates的启发)
抽取式
数据增强与扩充
数据量少
back translatin:比如zh->en->zh(哈工大),过程中保持[blank]位置不变,然后最强增强倍数N=1
用类似领域的数据作为补充;
人工标注(成本花费大)
数据增强方式
比如多选类型,对答案不属于文章任何一个choice的情况(unknow choice),做简单DA
又或者动态数据增强(平安)?
又如增加假答案(从原文中随机选取一定数量句子作为候选答案(增加假答案)参与训练。(顺丰,CICC是每篇文章会从上一篇文章抽一个句子作为假例子)
sample2paras:将所有原文中的 [BLANK] 用 choices 填充,重新随机生成新的 [BLANK] 位置与对应的 choices,新 [BLANK] 位置的原文长度分布与原始训练集一致
生成数据也要考虑去重,比如达到一个阈值或者尝试生成次数上限
设置增强倍数,即每个样本生成N个增强数据
抓取数据
如从故事网等网站上抓取相关文本作为数据集的扩充,并删去相似文本
扩充数据集的时候要注意分布(6estates),从而生成新数据集
调整问题或者context长度的分布,也要研究一下(6estates和哈工大都有这思想),分布也会涉及重复的样本
增强数据与原始数据的混合模式选择
- 增强数据与目标数据领域完全一致
- 增强数据与目标数据领域有差异(适合迁移 or stage-wise)
数据处理
文本归一化处理(如:如繁简转换、中英文标点转换、去除拼音标注 、长度限制、分布调整 等)
增加假答案(从原文中随机选取一定数量句子作为候选答案(假答案)参与训练),CICC是每篇文章会从上一篇文章抽一个句子作为假例子
context norm
filter query is None or answer is None
Answer和Context长度限制
data augment
干扰项(CMRC2019)
重复干扰项,排除重复干扰项能明显提高推理效果
随机干扰项
文本向量化表达
如用预训练语言模型,如中文ELMo(英文ELMo是基于字符集的编码),可采用的粒度有:
- 中文词级
- 笔划级
字模型
优点:embedding参数少,unk少,语料中字出现的次数相对均匀;
缺点:中文字模型分词后文本可能过长,有些任务分段后性能下降,没有分词的先验信息。
Token level的分类任务(阅读理解,NER等),字模型>>词模型。 虽然字模型整体表现更好,但是词模型能够有效降低文本长度使得attention视野更远,部分数据集会有奇效。
词模型
优点:有分词的先验信息。有预训练词向量,能够降低文本长度,节约显存。
缺点:Embedding参数巨大,UNK多,词频分布不均带来部分词的优化过于稀疏;week domain transfer ability;目前的分词工具表现还不是很好,会导致下游任务的bias
对于Transformer而言,受限于显存压力。模型大多长度受限,而长距离的attention在很多任务上非常关键,此时词模型对text level的分类任务上可能会有奇效。
sub-word 了解一下咯!
pos embedding
query type embedding
word match
长文档处理(比如结合tramsformer-xl, xlnet的自回归方式处理长文本)
特征融合
问题类型的one-hot特征
如:who, where, when, how, num, why, how long等类型,转为one-hot向量
POS信息
词共现特征
句子连贯性
- 候选答案回填(顺丰)
- SI,SSI方法(平安)
训练方法
蒸馏(distill)
自我蒸馏,self-distill。
自我蒸馏就是不改变模型大小,循环进行 teacher-student 的训练,直到效果不再改进
知识蒸馏
如student采用和teacher同样的网络结构(重生网络)
蒸馏通常用在模型压缩方面,即采用预训练好的复杂模型(teacher model)输出作为监督信号去训练另一个简单模型(student model),从而将 teacher 学习到的知识迁移到 student。
Post-process(要了解)
无监督数据预训练LM -> 特定任务数据上精调LM -> 任务标注数据精调模型(LM初始化)
打破模型训练消耗大对想法尝试的束缚:(CICC)
使用相同原理的tiny模型做benchmark,在其基础上做对比实验,最后应用到大模型上。
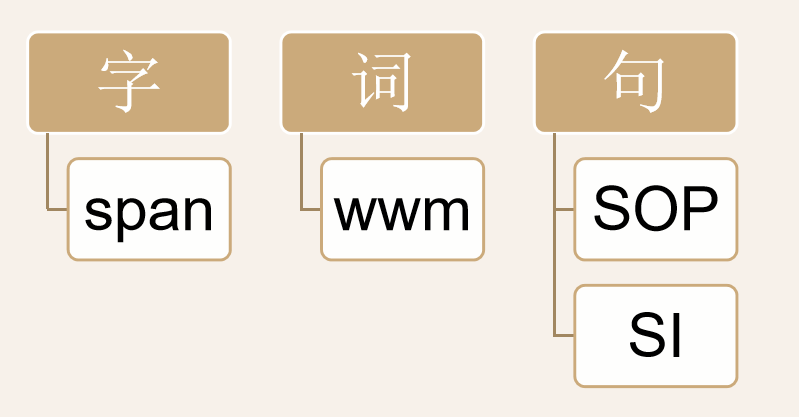
多层级任务的pretrain——字、词、句(cicc)
预训练模型
- 中文预训练BERT-wwm
预测目标
- level:character level, word level, sentence level
- NSP, MSP(6esetates)
- 这些训练目标和组合,比如同时预测character-level 和mask和mask sentence prediction,不知道能不能看做多任务学习
- 全词掩码 wwm, 快去了解
目标类型
语言模型
分类问题
合理性排序问题(顺丰),目标决定损失函数
其他:trick & 问题
Gate机制(关注核心单词)
如extra gated-dropout for query
答案抽取用PointerNetwork来预测答案起始与终止位置
prob = start * end
多任务
- 预测词是不是在答案的范围里,二分类,当做辅助任务去训练
- 预测答案是否在这个句子里
多任务其实是比较 trick 的东西,不同任务设置的权重不一样,需要不断去尝试。
显存优化方法
- blocksparse
- 避免对大tensor进行dropout
中文文档复杂性
当数据集是文本时,文档可能长至几百页,这时,机器就需要搭配文章分类和段落索引这样的技术来提升速度和准确性。
另外,文档中的一级标题、二级标题以及表格和图片等都是需要处理的问题。
学习率
- 学习率自适应,也就是每层组设置不同的学习率(哈工大)
- 三角周期学习率,学习率按照三角规律周期性变化(与固定学习率的指数衰减方式相比,有明显提升)
模型集成, 模型融合
损失函数
marginLoss, CrossEntropyLoss
实用工具
- 了解一下SMRC,搜狗的机器阅读理解工具集合,https://github.com/sogou/SMRCToolkit ,它提供了CMRC2018的模块
- blocksparse,一个用于块稀疏矩阵乘法和卷积的高效GPU内核, https://github.com/openai/blocksparse
- SentencePiece(spm),字词混合模型。作为一个高性能的无监督文本词条化工具,可以通过EM算法为预训练提供基于统计的高效分词。事实上xlnet即是用这个来进行分词的。 https://github.com/google/sentencepiece
- 中文bert预训练:https://github.com/ymcui/Chinese-BERT-wwm
应用
搜索引擎
客服
金融教育领域,有大量非结构化的文本
比如金融有很多公告类型的数据,纯靠人工提取知识点,并且由于长尾效应,难以覆盖到用户需要的所有点。依托阅读理解,机器可以直接从非结构化数据中提取到用户所需要的信息点。
CMRC2019对⾦融⻛控领域, 针对企业年报中关键⾦融要素, 抽取原因语句和相关段落的任务起到帮助
1 冠军:平安金融
纲要
如何更好地学习到句子之间的连贯性?——SI(Sentence Insertion)
非独立性条件下,合理的预测方式
中文NLP任务是否还需要分词? ——SentencePiece
预训练模型中连贯性知识的进一步强化 —— SDRP
预训练模型的领域迁徙 ——SSI
策略
看来这也是单choice预测策略
![]()
核心
优化
针对BERT占用显存的地方优化
- 使用blocksparse
- 避免对大tensor进行dropout
预训练语料
使用多源数据重训练bert,在官方中文BERT使用中文wiki基础上,采集了百科、新闻、知乎等多源数据
连贯性学习
主题相同的情况下,学习句子的连贯性,并且还要学会拒绝不连贯的句子。
SiBert
Sentence Insertion(SI代替NSP)
NSP学到的更多是主题信息而不是连贯性信息(根据ALBert研究),因此这里替换NSP为SI;而cmrc2019句子位置预测本身就是一个可用于预训练的自监督方法,能够有效补充语言模型对连贯性 和 顺序学习 的需求。
SI能学习到在判断 主题相同的情况下,句子放在哪里最连贯。
![]()
其中,sentence2是其他文档的句子,sentence1-3等是该篇文章,
SiBert结果与动态mask
在SiBert基础上基于 全词MASK继续fine-tune
全词mask[1] 与 英文中的ngram-mask相对应,在**spanBert[2]**中表示该方法对MRC提升显著
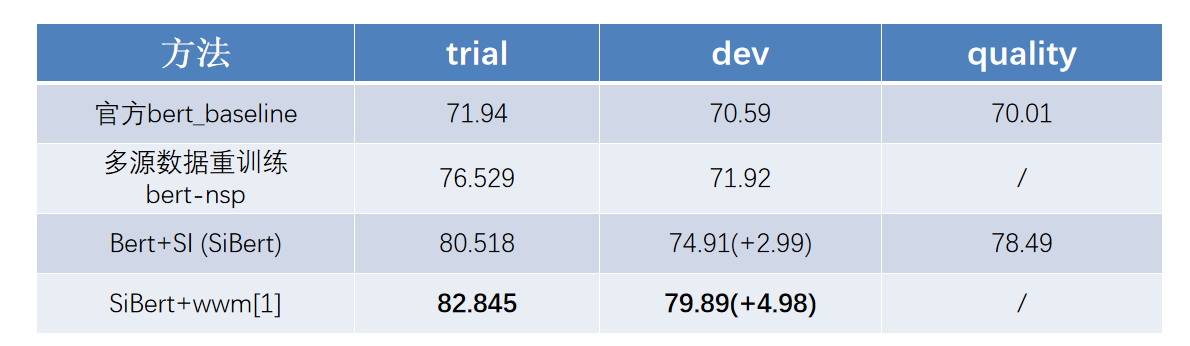
Sibert vs 2Sibert结论:
- 基于sentencepiece统计得到的字词混合模型能够基本解决词模型UNK的问题,在预训练中远优于传统分词+统计得到的词模型。
- Token level的分类任务(阅读理解,NER等),字模型>>词模型。
负样本的连贯性
受到ERNIE2.0[3]的启发,我们为模型新增了Sentence-Document Relation Prediction(SDRP)任务。使得模型针对负样本不仅仅专注于主题,更能判别它们的连贯性。下图结果称为3SiBert(2SiBert见下文)。
![]()
非独立性的预测方式
因为多个choice之间也会提示信息(比如顺序关系,会有对比信息,6estates也有用到这个启发),从而在推断过程中相互提供有效信息得到答案,因此每个choice之间的预测不应该是独立的。
原始的独立的预测目标:
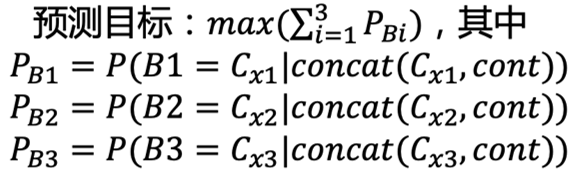
动态预测
在推断的阶段,逐渐还原文本,增加先验信息。
![]()
文本长度与分词
问题
文本长度过长(>512),限制模型性能,因此要探索如何 无损缩减长度, 可以用到 SentencePiece[spm]分词工具来降低context文本长度,并得到字词混合模型,能够基本解决词模型unk的问题。
SentencePiece
高性能的无监督文本词条化工具,可以通过EM算法为预训练提供基于统计的高效分词,并得到字词混合模型,能够基本解决词模型unk的问题。下图里,分词后context长度明显降低。(2SiBert)
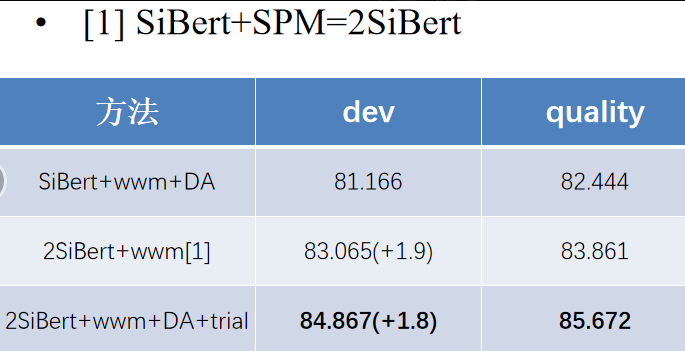
领域迁移
为了使得预训练模型更贴近cmrc2019的任务,在之前预训练模型的基础上把Sentence Insertion任务替换为短句抽取(Short Sentence Insertion, SSI),进一步训练了500k步。
![]()
消融实验
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BsugYJvs-1586241113301)(https://i.loli.net/2020/04/05/38HFotdpklg7Ky5.png)]
总结
预训练
BERT模型优化,预训练语料丰富化;Sentence Insertion 和 全词mask任务;句子篇章关系预测任务;预训练模型的领域迁移
数据增强
简单负样本增强;动态数据增强(配合SDRP)
数据处理
SentencePiece字词混合模型; 动态预测
2 亚军:顺丰 Mojito System
预处理
- 数据清理
- 增加假答案
- 候选答案回填(判断句子 合理性、连贯性)
- 多**[mask]填充**(与掩码语言模型保持一致性、一定程度上还原候选答案与上下文的相对距离)
![]()
区分mask和blank哦
预训练
![]()
模型
![]()
![]()
Margin Loss
候选答案是一个 合理性排序问题! 而不是分类问题

知识蒸馏,重生网络,对应的loss
![]()
预测策略
关键是构造这个候选答案的得分矩阵(下文6estates的是choice-unused矩阵,反正关键是构建矩阵),在这个基础上采用 差值排序。
有图知,答案的选择策略有两种,一种的方案A直接取最高分,还有一种是方案B采用差值排序选择。
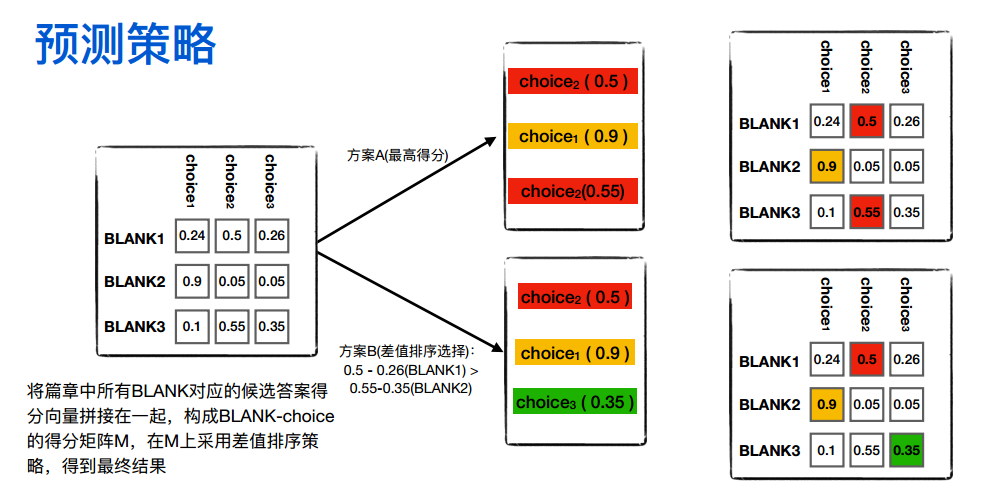
实验结果
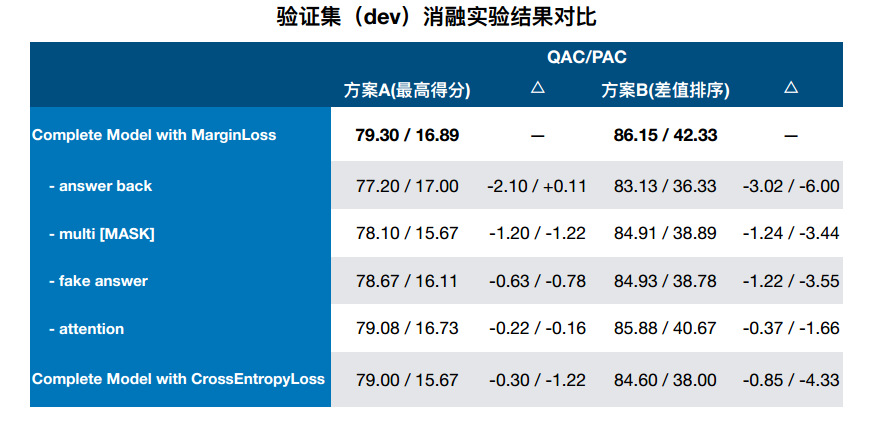
总之有和其他模型的对比;自己的消融分析;采用不同预训练语言模型的对比;采用集成模型的对比
错误分析
对于需要一些推理的blank(好像不同的方法叫法不同,在6esetate里不知道是不是又处理了,叫作unsed),观察出缺乏一定知识推理能力;候选答案无法区分,答案都合理;预测方案不同导致不同的预测答案;关键上下文缺失的情况下,已有信息无法得到真正的答案;语序方面的问题;
3 季军:6Estates
数据集分析
问题
- 数据不充分;
- TTD数据问题数量分布差异; (结合1,所以可以考虑自己增加一些数据集)
- TTD 文本长度分布也有差异;
- 相似文本值得答案有所泄露或者互相干扰

![]()

策略与方法
策略
- 改进bert
- 增加数据量,并调整数据分布(研究一下)
- 尝试不同预训练任务
- 问题转化为针对context构建 choice-unused 概率矩阵
- 分别以choice 和 unused 为中心构建不同模型进行预测
矩阵如图:
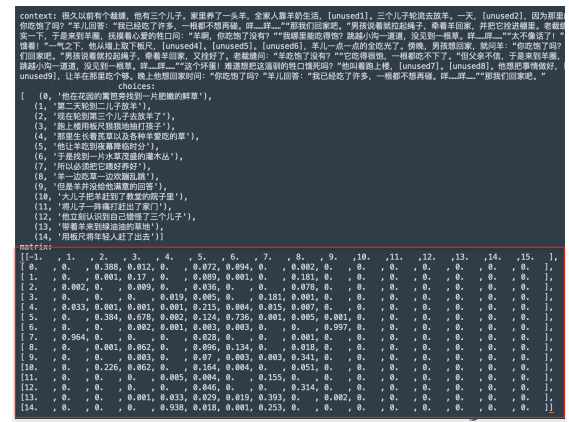
数据集扩充,分布调整
- 从故事网等网站抓取更多相关文本;删去trail/dev/qualify中的相似文本;
- 问题可以包含符号,字符长度15-30,问题数量5-15;不允许采样时出现相似文本,从而生成新的数据集
预训练
预训练的几种objective,这就涉及多任务学习的范畴
- 在新数据上⽣成了⼤约600W预训练数据
- Mask Prediction 1(character level)
- Mask Prediction 2 (word level)
- Next Sentence Prediction
- Mask Sentence Prediction

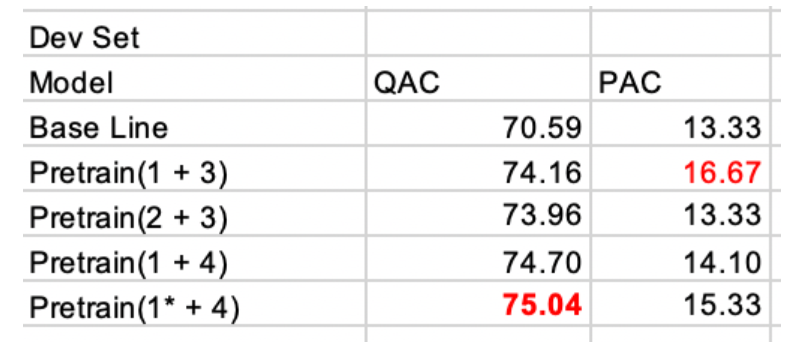
单个choice拼接预测
将单个choice放入一个example中,从而训练新的预训练模型。
由此产生发方法有:
- model1 : 新的预训练模型
- model2 : 新的与训练模型 + 更大训练集
- model3 : 加⼊更多中间层, 在最终输出层之前增加更⾼概率的Dropout
- model4 : 增加单独的输出和Attention⽤来检测是否为假的Choice
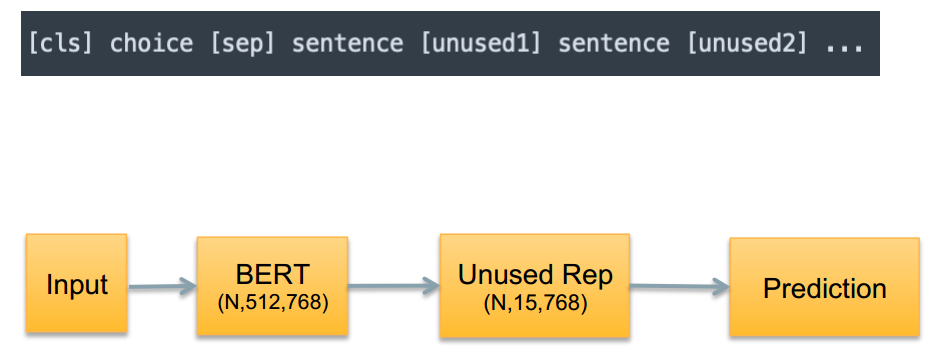
多个choice拼接预测
所有choice都放入一个example中,从而建模的时候做choice rep和unused rep的text pooling
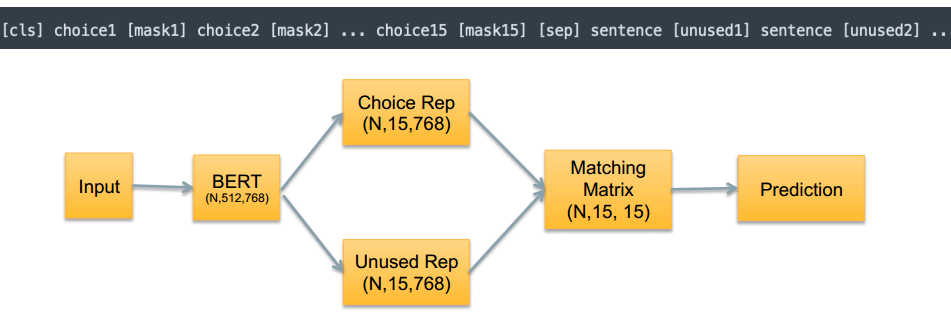
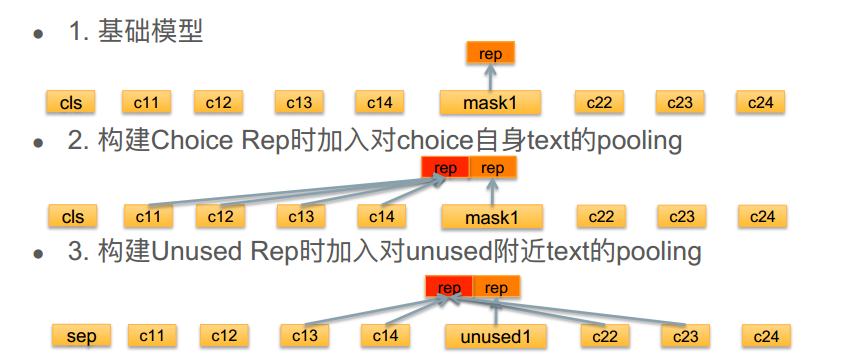
多choice vs 单choice
- 当需要⻓⽂本上下⽂来辅助判断时,同样max_seq_len情况下多 choice模型能够建模的context⻓度⼤⼤减少 (可以结合xlnet的自回归建模方式处理长文档)
- 当存在有多个空位距离较近时, 需要更多的choice之间的对⽐信息(顺丰也考虑到这个,就是choice之间的关系)才能辅助确定空位应该填⼊的choice
集成模型
- 单choice和多choice模型预测概率线性回归
- 根据choice预测概率和choice部分⽂本在context中的出现情况判断是否直接排除该choice
- 将置信度较⾼的choice填⼊context中, 构建新的case, 迭代式预测
改进
- 长文档,xlnet的自回归思想建模方式,处理更长文本
- 多choice模型中增加更合适的pairwise loss,使得模型能在choice选取中更有区分度
4 季军:哈工大
模型架构
创新点:
个人感觉主要是在数据、训练方式上做加法,模型架构没有什么创新
提出了一种填空型阅读理解任务的通用数据增强方法
在特定任务数据上精调 LM 明显地提升了语言模型对该任务的表达能力
学习率的领域自适应与三角周期性学习
数据增强与原始数据的混合模式选择
优点
- 单模型,训练及推理效率高
- 通用数据增强方法可使用其他领域数据做迁移或者从任意领域无监督数据直接生成训练集
改进
- 模型结构上有待进一步改进,如加入更能表征句子位置的结构
- 对每个样本的多个 choice 位置的损失加入整体性约束
数据增强
重排填空位置

Back Translate
- zh->en->zh:保持 [BLANK] 位置不变
- 最佳增强倍数 N=1:使用重排对每个样本生成1个增强数据
学习率
学习率领域自适应
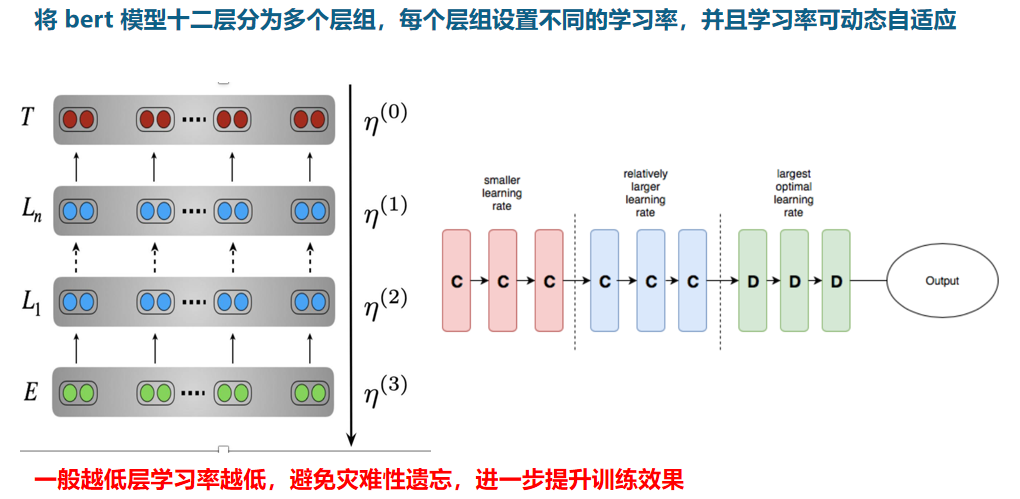
三角周期学习率:学习率按照三角规律周期性变化
训练方法

数据增强与原始数据的 混合模式 选择
增强数据与目标数据领域完全一致

增强数据与目标数据领域有差异
- 适合迁移:增强数据模型->目标数据模型
- stage_wise: 从距离最远的优先训练,依次迁移到距离较近的增强数据,最后迁移到目标数据,这样有效利用其它领域信息并减少遗忘
该句子填空任务的增强数据与目标数据领域完全一致

排除干扰项

实验结果
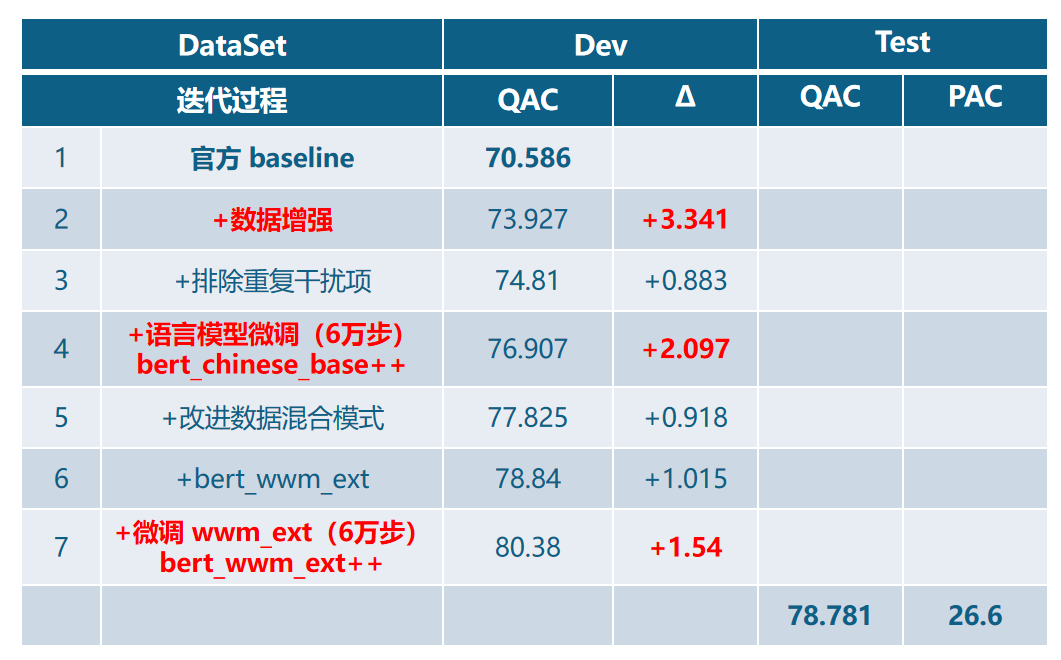
5 季军:CICC
实验结果和消融分析
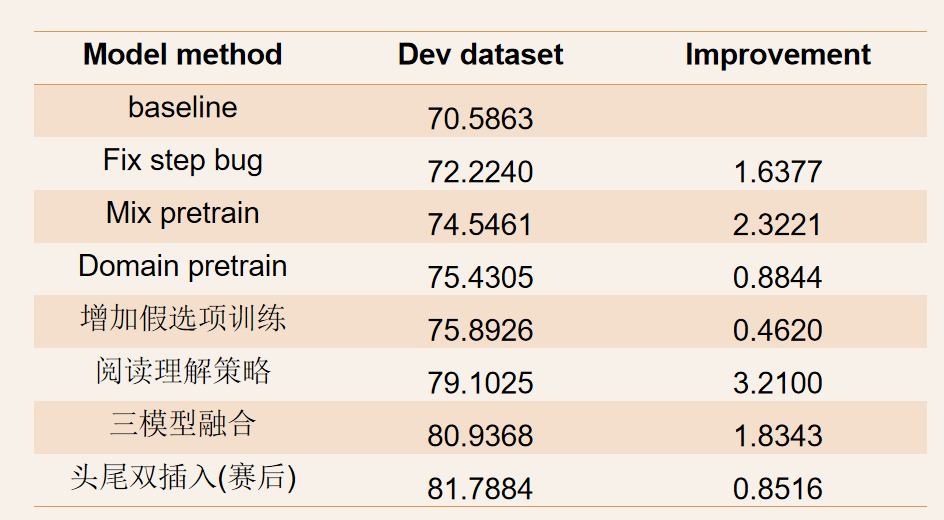
由上图知:
增加假例子:每篇文章会从上一篇文章抽一个句子作为假例子
domain pretrain

mix pretrain
阅读理解策略
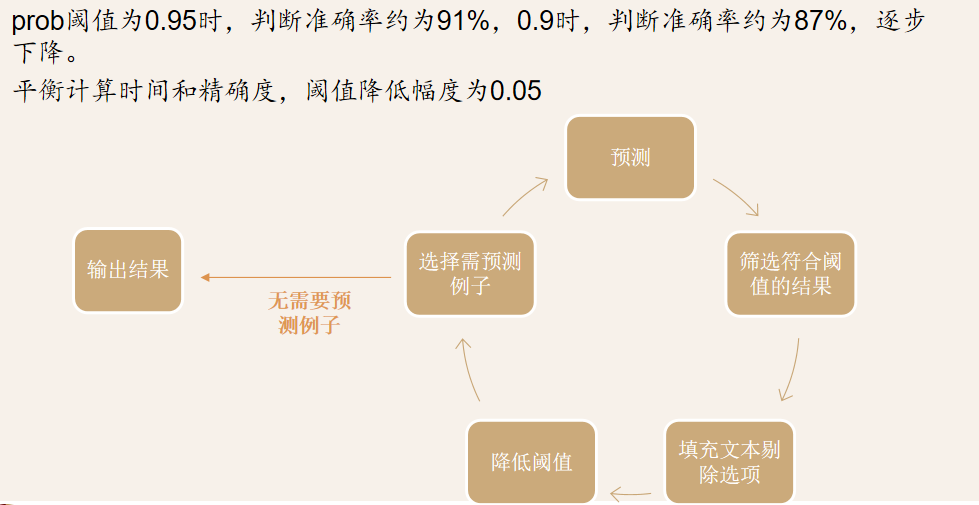
三模型融合
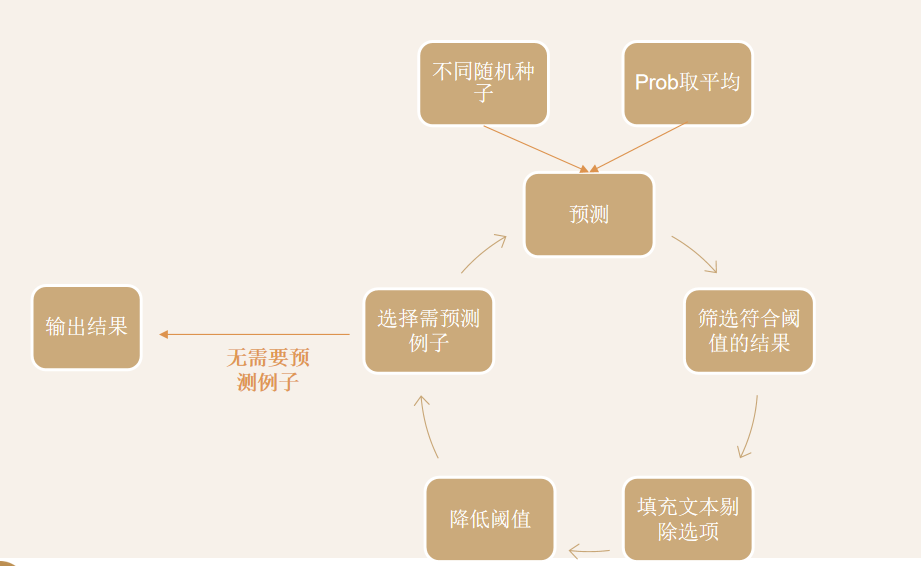
反思
如何打破模型训练消耗大对想法尝试的束缚:
使用相同原理的tiny模型做benchmark,在其基础上做对比实验,最后应用到大模型上。
多层级任务的pretrain——字、词、句
6 启发
动机出发,比如探索更好的MRC落地应用,或者探索PTM的新的任务。通过改进不同模型的缺点来找到创新点和推动发展。
根据具体数据集任务分析数据集好像是个之前被我很忽略的一个点,这里好几个队伍都进行了数据集的分析,从而观察数据集的分布、选项、长度、数据数量、重复项,判断选项之间的顺序性或者独立性影响,选项与上下文之间的影响作用,这都是我之前没有考虑到的!分析任务是个首当其冲的大事啊!分析任务还包括分析任务的难点,比如这个任务的难点就包括句子连贯性的学习,因此针对连贯性,冠军也亚军团队都有自己的连贯性学习方案,具体见上文因为这里我突然想不起来了(记性真的好差,因此要多回顾呀)。
每个模型基本都使用了数据增强来拓展数据集,其中包括领域迁移、back translate、生成假数据、假答案、简单粗暴抓取数据等不同的拓展数据的方式与数据混合方式,并且对原始的数据与生成的数据也要做进一步的处理比如分布调整、去重等,但我对这些方面的认识还是十分模糊!如果要做中文MRC任务,这方面我还要多下点功夫研究和归纳一下,数据的扩充和处理是个大任务!
适合中文任务的预训练模型也要了解哦,比如常用的bert-wwm,这是个啥玩意?快去搞!
spanBert似乎是2019的实用方法,在mask词上有所帮助;总之在语言模型的 mask 上面要看些论文了,估计其中一部分论文还要从预训练模型里面找。
采用Post-training的multi-task方法再次在顺丰的模型上证明,多任务学习的损失loss的设计,涉及数学知识的部分如何把握?还有有点担心计算量,又预训练又post training的,我们学校的服务器能跑多少?还是只能跑fine-tune?也许这需要一个很轻便的预训练模型吧?这点要找学长问问,以及问问学长做过哪些训练实验,如果能发现能直接拿来用的实验结果就更好了。看到CICC那边对于到模型消耗大的反思,我也要有所启发,比如如何构建一个相同原理的tiny模型来组benmark?
上面也设计到训练方式,训练方式里的各种蒸馏也可以了解一下呢,知识蒸馏是啥?快去看呐。
中文MRC的训练单位,及词、字作为输入单位的不同特点,中文还是需要分词的;而在cicc看到多层级的任务的预训练:字、词、句,这方面学习到的知识如何抽取和融合利用,也要探索。
大部分模型的输入,好像还是单个choice拼接context的,学习打分的矩阵很关键,即得到一个交融的矩阵还是很重要的;模型的预测目标设计上,要针对数据集的特点,思考要让模型学到什么。并且预测的类型也可以不一样,比如多选题的目标可以是分类,而又可以是一个排序问题(多个选项中找最高可能);
最后还要拥有一种 分析思想,要总结经典套路的消融分析、错误分析方式,还要结合模型特点和创新点来设置分析对比实验,并且还可以从任务特点来做分析,比如CICC的对不同位置的结果也可以做分析,总之能找出问题的话,就可以找出可改进的地方。在消融分析上做减法或者做加法都可,涉及的组件比如预训练组件、语言模型差异、数据的增强方法(比如领域迁移、假答案等)、训练方式的不同(比如融合模型)。总之这里的分析思想也和上面的任务分析思想对应,要多分析,多思考,想不出来抱大腿(不是。
看论文的时候不仅要学会找能用的东西,还要思考自己能不能创新?就是既要思考模型的优点,更要找到模型的缺点,但是目前我好像还是只在汲取知识的阶段,缺点根本看不出来好伐。。因为要看的太多了,找到一些可用的素材就已经很难,找到关系更是难上加难,如果要创新的话,怎么站在巨人的肩膀上?更如何在错综复杂的关系里选择合适的轮子?如果专注于造轮子的话如何稳住心态不会崩?
7 参考
网页
https://www.leiphone.com/news/201811/3KC2OSaNQDzhTDDJ.html
雷锋网的RC进阶:https://www.leiphone.com/news/201811/wr62uxvN0dJDbLwF.html ,2018
从字到词,大词典中文BERT模型的探索之旅,https://www.jiqizhixin.com/articles/2019-06-27-17?from=synced&keyword=%E8%AF%8D%E5%90%91%E9%87%8FBERT
ppt提到的论文
[1] Cui, Yiming, et al. “Pre-Training with Whole Word Masking for Chinese BERT.” arXiv preprint arXiv:1906.08101 (2019)
[2] Joshi M, Chen D, Liu Y, et al. Spanbert: Improving pre-training by representing and predicting spans[J]. arXiv preprint arXiv:1907.10529, 2019. 【 平安、顺丰,动态mask和spanmask】
[3] Sun, Yu, et al. “Ernie 2.0: A continual pre-training framework for language understanding.” arXiv preprint arXiv:1907.12412 (2019).
[4] Li, Xiaoya, et al. “Is word segmentation necessary for deep learning of Chinese representations?.” Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019.
[5] Furlanello T, Lipton Z C, Tschannen M, et al. Born again neural networks. International Conference on Machine Learning (ICML), 2018 【重生网络】
[6] Clark K, Luong M T, Khandelwal U, et al. Bam! born-again multi-task networks for natural language understanding. Association for Computational Linguistics (ACL), 2019. 【重生网络的一种策略】
【总结向】从CMRC2019头部排名看中文MRC相关推荐
- 外部依赖项很多未定义标识符_从日本编程书籍《我的第一本编程书》中译版看中文例程如何扬长避短——标识符(一)
日本作者平山尚在前言归结了本书的三点独特之处: 从始至终只编写一个程序(俄罗斯方块游戏) 使用专门的工具 绝对面向首次接触程序的人群 第一点,优势是一个项目主体贯穿全书,但同时很考验编排顺序,以及技术 ...
- sql排名名次分页mysql_mysql 实现排名及中文排序实例[分页累加行号]
/*排名相同情况下,优先按姓名排序*/ SELECT t.`name`, t.company_name, @rownum:=@rownum+1 as rankNum, t.ss from ( SELE ...
- 从排名看主流半导体厂商在3G市场的策略与心态
从排名看主流半导体厂商在3G市场的策略与心态 上网时间:2006年07月01日 作者:孙昌旭 最新出炉的2005年全球WCDMA基带处理器厂商排名与中国手机厂商所看到和感受到的似乎相差甚远. 作为GS ...
- CCF 等级会议排名 / CORE Ranking排名 / CCF 中文期刊排名
CCF 等级会议排名/ 国际计算机CORE Ranking 排名 / CCF中文期刊排名 <中国计算机学会推荐国际学术会议和期刊目录> 此目录官网地址(含详细学科分类): https:// ...
- 2018-03-28 从人机交互角度看中文编程:#39;打开微信#39;
前文通用型的中文编程语言探讨之一: 高考是基于现有英文编程语言的一个技术思路. 在这个回答以及下面的讨论中, 又提到了编程其实是人机交互的一种形式. 不禁试着跳出程序员视角看这个问题. 几年前才发现M ...
- 看中文域名 谈国际域名
在发现我国 CNNIC ROOT 根证书已经悄无声息混进微软 Windows 操作系统受信任的根证书颁发机构和 Firefox 火狐浏览器受信任证书列表中的事实之后(敏感话题,不再过多谈及,只是希望某 ...
- 数据可视化之中国足球队在国际足联及亚洲的历史排名看这儿
最近最热的体育盛事莫过于世界杯了,四年一届的足球盛事,正在卡塔尔激战正酣.这时候可能会有球迷疑问:怎么没看到中国队呢?也有网友调侃说中国队被分到工程队去了. 泱泱大国,难道中国十几亿人口,一个足球队都 ...
- 设计师必看中文字体排版法则
在中国的商业设计里面是离不开汉字的,可是很多设计师在做所谓的私人创作时往往就回避汉字,全是清一色的英文字母.汉字的编排其实很能见一个设计师的功力,大一点说作品里面文字的编排与设计就能看出这个设计师够不 ...
- 中国有超级计算机的大学,计算机专业排名看超算实力,ASC竞赛五大高校排名,中山大学第一...
ASC竞赛五大高校 计算机专业的实力主要体现在算法与编程的逻辑运算上,因此计算机专业必须掌握大量基础数学知识,甚至很多是离散数学.模糊数学等人工智能逻辑数学,简单的程序软件应用和O2O程序实现其实都不 ...
最新文章
- 《JavaScript启示录》——1.21 JavaScript对象和Object()对象
- 报名丨图神经网络前沿学术研讨会:清北高校vs企业,9位学者联袂分享
- [Linux]搜索文件是否包含指定内容并返回文件名
- 了解电商优惠券的一生,看完这篇就足够了!
- WPF入门教程系列三——Application介绍(续)
- 扩展方法的定义及使用
- resource busy and acquire with nowait specified解决方法
- 对当今社会的某些现象的感想
- 歌德语言证书c1考什么,Goethe-Zertifikat C1 (歌德中级证书C1)考试细则 2010.2.1版.pdf...
- android常用网址
- Pytorch专题实战——激活函数(Activation Functions)
- 后序非递归遍历二叉树的应用
- 自动把动态的jsp页面(或静态html)生成PDF文档,并且上传至服务器
- 数据库程序设计复习资料
- 网口压线顺序_水晶头压线顺序
- 从球域采样分布分析360质量评估
- 华三交换机配置vrrp_VRRP原理与配置 华为、华三交换机,路由器
- 墙面有几种装修方法_墙面怎么装?四种装修方式总有一款适合你
- c3p0连接池拿不到连接导致系统崩溃的问题解决
- imx6d overlay视频应用程序-mxc_v4l2_overlay分析
热门文章
- java开发工程师英文_java工程师英文简历范文
- 学习的目的:建立世界观、学以致用、知行合一
- 小程序使用小白接口上传图片方法1
- 二进制/八进制转换器
- 【加密锁】Virbox对Unity3D打包程序加密流程
- OmniPeek tools install and setting
- EasyNVR网页摄像机直播方案H5前端构建之:如何播放HLS
- 压缩pdf大小的方法?怎样压缩pdf大小?pdf文档怎么压缩?pdf文件太大怎么压缩?pdf文件太大怎么压缩成小内存?如何降低pdf文件大小?怎么把pdf文件压缩到指定大小?压缩pdf的简单方法
- 软件黑盒测试心得与经验
- 3000字/16张炫酷动态图,推荐一款好用到爆的Python可视化利器