SQL Server中并行执行计划的基础
In this article, we will learn the basics of Parallel Execution Plans, and we will also figure out how the query optimizer decides to generate a parallel query plan for the queries.
在本文中,我们将学习并行执行计划的基础知识,并且还将弄清楚查询优化器如何决定为查询生成并行查询计划。
Let’s first look at how a query is executed and the role of the query optimizer in this process. When a query is executed, it proceeds through the following steps.
首先,让我们看一下如何执行查询以及查询优化器在此过程中的作用。 执行查询后,将继续执行以下步骤。
Query Parsing -> Binding (Algebrizer) -> Query Optimization -> Execution
查询解析->绑定(Algebrizer)->查询优化->执行
The query optimizer makes an effort to produce an optimum query plan on the query optimization step. This step is very crucial because the output of the query optimizer directly affects the query performance. Query optimizer analyzes various query plan candidates and chooses the good enough plan from these candidates. Query optimizer makes a decision based on the balance between optimization time and plan quality when deciding on a query plan. Therefore, query optimizer does not work to find the best query plan; otherwise, this process might cause to consume more time, and the execution time will take longer.
查询优化器努力在查询优化步骤上生成最佳查询计划。 此步骤非常关键,因为查询优化器的输出直接影响查询性能。 查询优化器分析各种查询计划候选项,并从这些候选项中选择足够好的计划。 当确定查询计划时,查询优化器将基于优化时间与计划质量之间的平衡做出决策。 因此,查询优化器无法找到最佳查询计划。 否则,此过程可能会消耗更多时间,并且执行时间将更长。
When creating a query plan, the query optimizer is affected by various parameters. For example, the following parameters affect the generated query plans.
创建查询计划时,查询优化器会受到各种参数的影响。 例如,以下参数会影响生成的查询计划。
- Database compatibility level 数据库兼容性级别
- Cardinality Estimation version 基数估计版本
- Query hints 查询提示
In this context, it is clear that the goal of the query optimizer is to produce efficient execution plans that help to reduce the execution time of the queries. In accordance with this purpose, parallel query processing might be a good option to reduce the response time of the query by using the multiple CPU’s power.
在这种情况下,很明显,查询优化器的目标是生成有效的执行计划,以帮助减少查询的执行时间。 根据此目的,并行查询处理可能是通过使用多个CPU的功能来减少查询的响应时间的好选择。
什么是并行处理? (What is parallel processing?)
The parallel processing aims to separate big tasks into more than one small task, and these small tasks will be completed by the discrete threads. In this approach, more than one task will be performed in unit time; thus, the response time will be reduced dramatically. This idea does not change for SQL Server; it tries to process queries that require excessive workload in a parallel manner. The query optimizer in SQL Server takes into account three settings when generating a parallel query plan. These are:
并行处理旨在将大任务分解为多个小任务,这些小任务将由离散线程完成。 在这种方法中,单位时间内将执行多个任务。 因此,响应时间将大大减少。 对于SQL Server,这种想法不会改变。 它尝试以并行方式处理需要大量工作量的查询。 生成并行查询计划时,SQL Server中的查询优化器会考虑三个设置。 这些是:
- Cost Threshold for Parallelism 并行成本阈值
- Max Degree of Parallelism (MAXDOP) 最大并行度(MAXDOP)
- Affinity mask 亲和力面膜
先决条件 (Pre-requisites)
In this article, we will use the AdventureWorks database, and we will also use the Create Enlarged AdventureWorks script to generate an enlarged copy of the SalesOrderHeader and SalesOrderDetail tables.
在本文中,我们将使用AdventureWorks数据库,还将使用“ 创建放大的AdventureWorks”脚本来生成SalesOrderHeader和SalesOrderDetail表的放大副本。
As a second step, we will create a non-clustered index through the following query.
第二步,我们将通过以下查询创建一个非聚集索引。
CREATE NONCLUSTERED INDEX IX_L001
ON [Sales].[SalesOrderHeaderEnlarged] ([PurchaseOrderNumber])
Lastly, we will switch compatibly level to 150 (SQL Server 2019) so that our test database will be ready for all examples of this article.
最后,我们将兼容级别切换到150(SQL Server 2019),以便我们的测试数据库可用于本文的所有示例。
ALTER DATABASE AdventureWorks2008R2 SET COMPATIBILITY_LEVEL = 150
并行成本阈值 (Cost Threshold for Parallelism)
The estimated query cost is a unit that is calculated using the I/O and CPU requirement of a query. This measurement helps the optimizer to evaluate the cost of the query plans and select the optimal plan. Query optimizer calculates the estimated cost of the query by summing the estimated cost of individual operators in the query plan. The Estimated Subtree Cost attribute indicates the estimated cost of the plan in the query plan.
估算查询成本是使用查询的I / O和CPU需求计算得出的单位。 此度量有助于优化器评估查询计划的成本并选择最佳计划。 查询优化器通过将查询计划中各个运算符的估计成本相加来计算查询的估计成本。 估计子树成本属性指示查询计划中计划的估计成本。
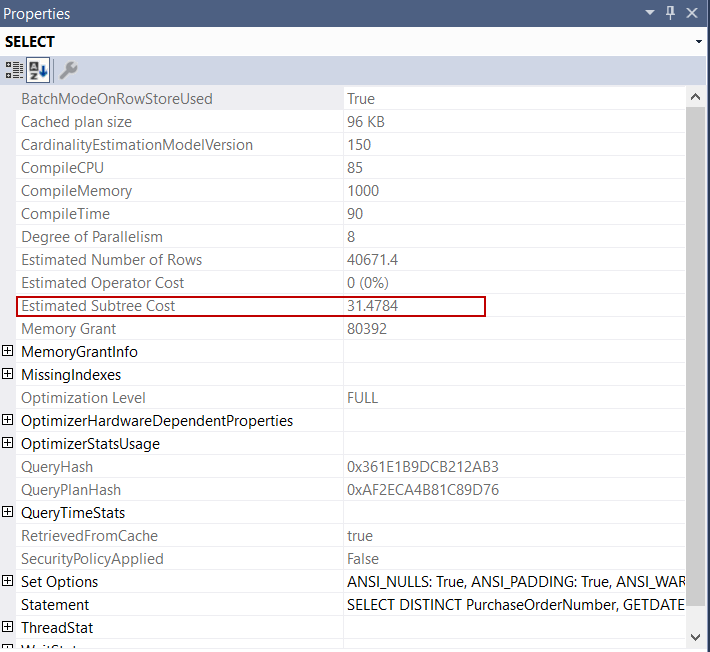
When this value exceeds the Cost Threshold for Parallelism setting, the query optimizer begins to consider creating a parallel query plan alongside the serial plans. The default value of this setting is 5, and it can be changed using SQL Server Management Studio or Transact-SQL.
当该值超过“ 并行性成本阈值”设置时,查询优化器将开始考虑在并行计划旁边创建并行查询计划。 此设置的默认值为5,可以使用SQL Server Management Studio或Transact-SQL进行更改。
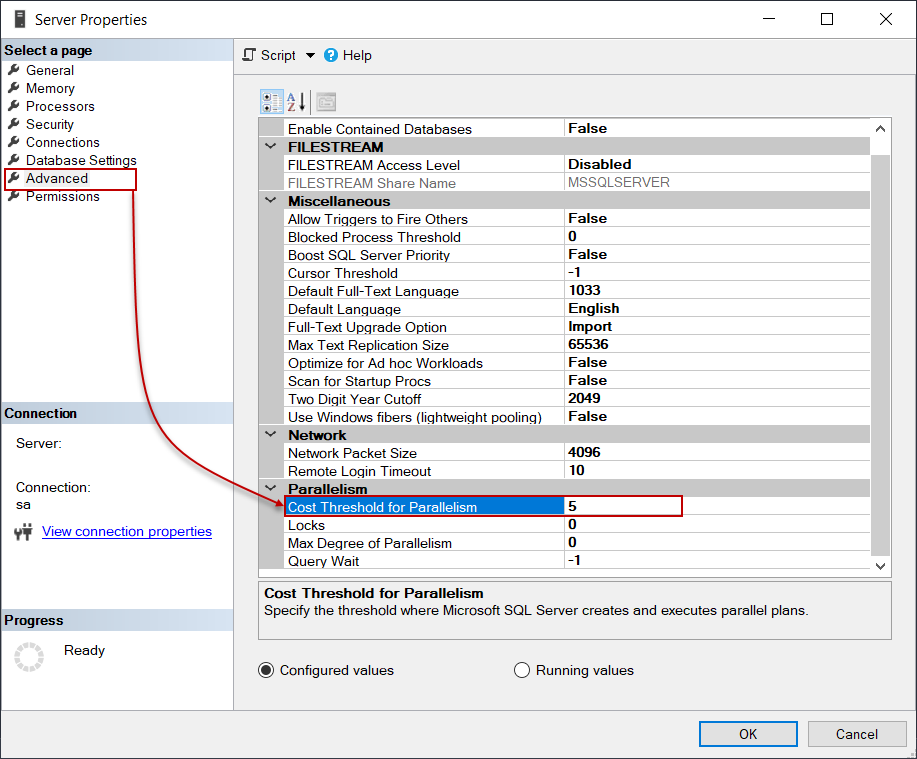
With the help of the following query, we can set the cost threshold for parallelism value as 20.
借助以下查询,我们可以将并行度值的成本阈值设置为20 。
EXEC sp_configure 'show advanced options', 1 ;
GO
RECONFIGURE
GO
EXEC sp_configure 'cost threshold for parallelism', 20 ;
GO
RECONFIGURE
GO
Now we will execute the following query and analyze the actual execution plan.
现在,我们将执行以下查询并分析实际的执行计划。
SELECT ProductID,SUM(LineTotal) AS TotalsOfLine ,
SUM(UnitPrice) AS TotalsOfPrice, SUM(UnitPriceDiscount) AS TotalsOfDiscount FROM
Sales.SalesOrderDetailEnlarged SOrderDet
INNER JOIN Sales.SalesOrderHeaderEnlarged SalesOr
ON SOrderDet.SalesOrderID = SalesOr.SalesOrderID
WHERE PurchaseOrderNumber LIKE 'PO%'
GROUP BY ProductID
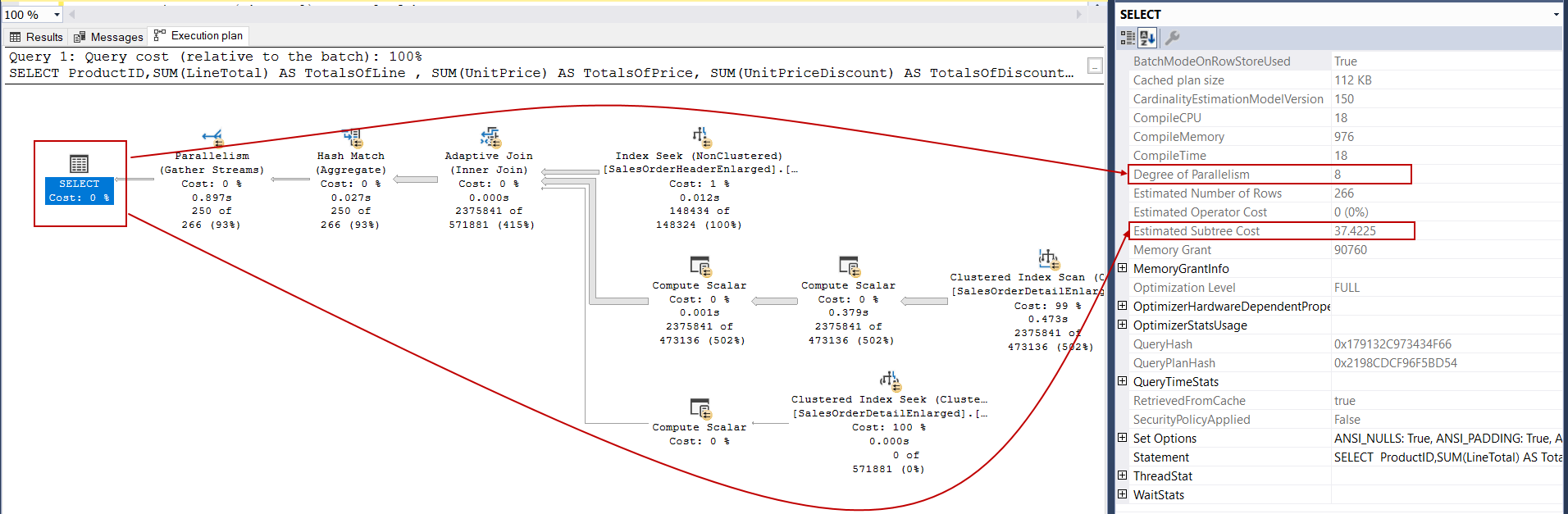
As we can see, the estimated subtree cost is nearly 37.12, and it is greater than the cost threshold for parallelism value so that the query optimizer generates a parallel query plan. The query optimizer considers generating a parallel query plan when the estimated subtree cost exceeds the cost threshold for parallelism value. Otherwise, the query optimizer will only evaluate the serial plans and will decide one of them. The Degree of Parallelism attribute indicates the number of processors that have been used by the query during the execution period.
如我们所见,估计的子树成本 是接近37.12,并且大于并行度的成本阈值,以便查询优化器生成并行查询计划。 当估计的子树成本超过并行度值的成本阈值时,查询优化器考虑生成并行查询计划。 否则,查询优化器将仅评估串行计划并决定其中之一。 并行度属性指示查询在执行期间已使用的处理器数量。
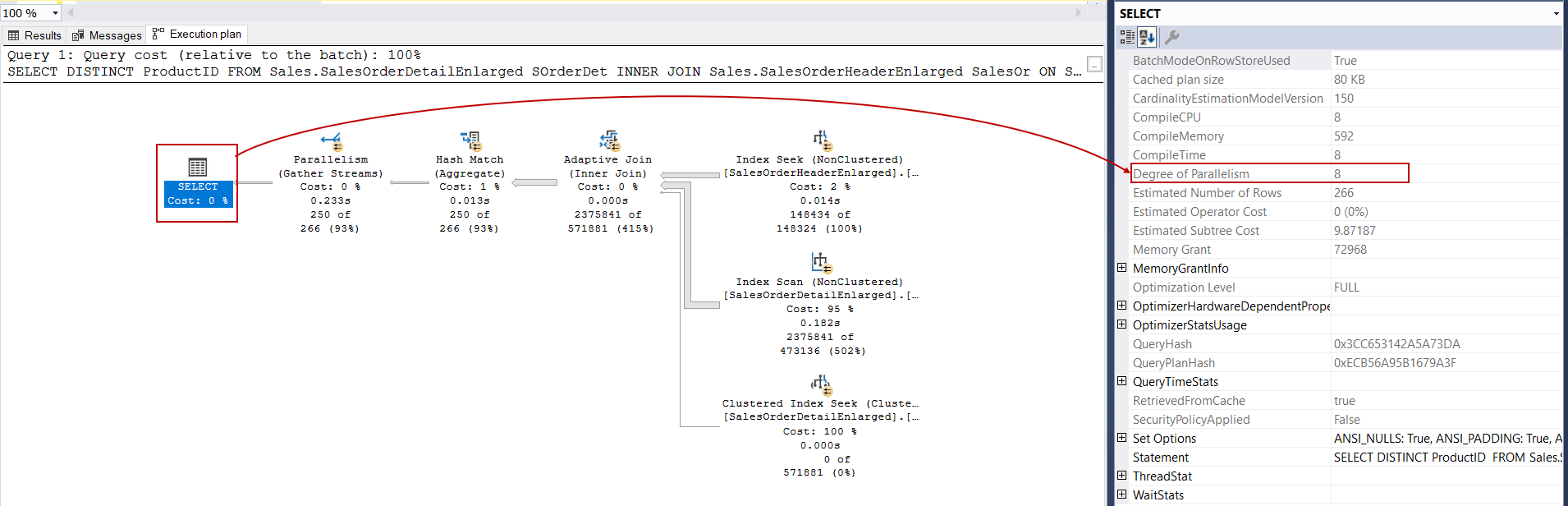
However, the ENABLE_PARALLEL_PLAN_PREFERENCE query hint forces the query optimizer to generate a parallel query plan without thinking about the cost threshold for parallelism. For example, the following query estimated subtree cost is 17.12, and the query optimizer should decide on a serial query plan.
但是, ENABLE_PARALLEL_PLAN_PREFERENCE查询提示会强制查询优化器生成并行查询计划,而无需考虑并行性的成本阈值。 例如,以下查询估计的子树成本为17.12,并且查询优化器应确定串行查询计划。
SELECT DISTINCT ProductID FROM
Sales.SalesOrderDetailEnlarged SOrderDet
INNER JOIN Sales.SalesOrderHeaderEnlarged SalesOr
ON SOrderDet.SalesOrderID = SalesOr.SalesOrderID
WHERE PurchaseOrderNumber LIKE 'PO%'
GROUP BY ProductID
If we add the ENABLE_PARALLEL_PLAN_PREFERENCE query hint at the end of the query, the query optimizer will decide to use a parallel execution plan.
如果我们在查询末尾添加ENABLE_PARALLEL_PLAN_PREFERENCE查询提示,则查询优化器将决定使用并行执行计划。
SELECT DISTINCT ProductID FROM
Sales.SalesOrderDetailEnlarged SOrderDet
INNER JOIN Sales.SalesOrderHeaderEnlarged SalesOr
ON SOrderDet.SalesOrderID = SalesOr.SalesOrderID
WHERE PurchaseOrderNumber LIKE 'PO%'
GROUP BY ProductID
OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'))
最大平行度 (Max Degree of Parallelism)
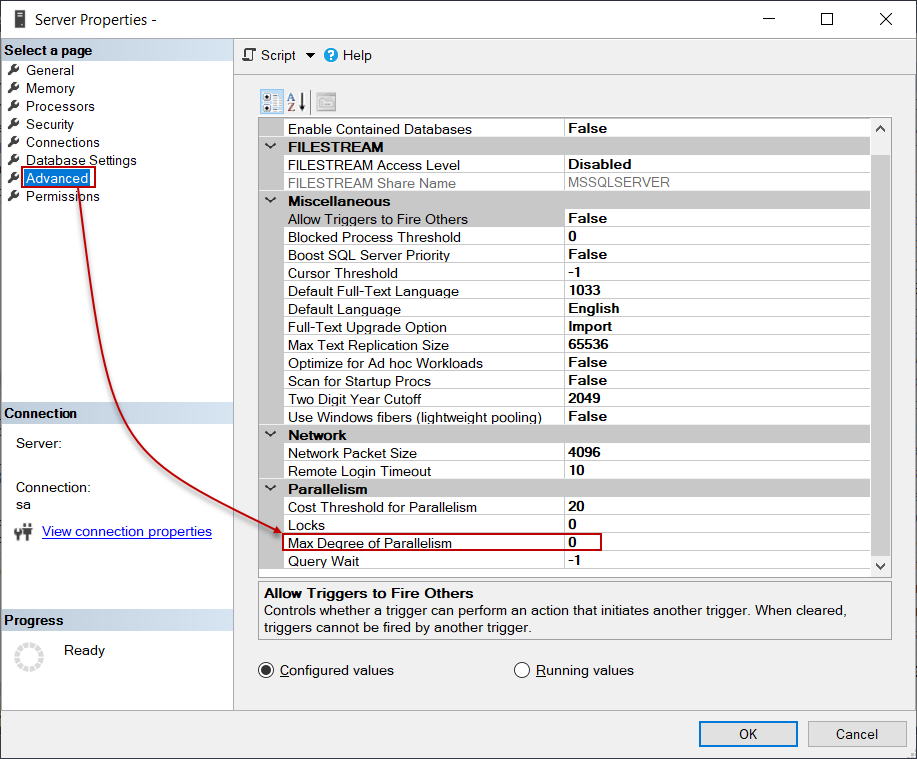
Max Degree of Parallelism, also known as MAXDOP, is a server, database, or query level option that determines the maximum number of logical processors that can be used when a query is executed. By default, this option is set to 0, and it means that the query engine can use all available processors. We can find out this value under the Advanced settings on the Server Properties page.
最大并行度 ,也称为MAXDOP ,是服务器,数据库或查询级别的选项,用于确定执行查询时可以使用的逻辑处理器的最大数量。 默认情况下,此选项设置为0,这意味着查询引擎可以使用所有可用的处理器。 我们可以在“服务器属性”页面上的“ 高级”设置下找到该值。
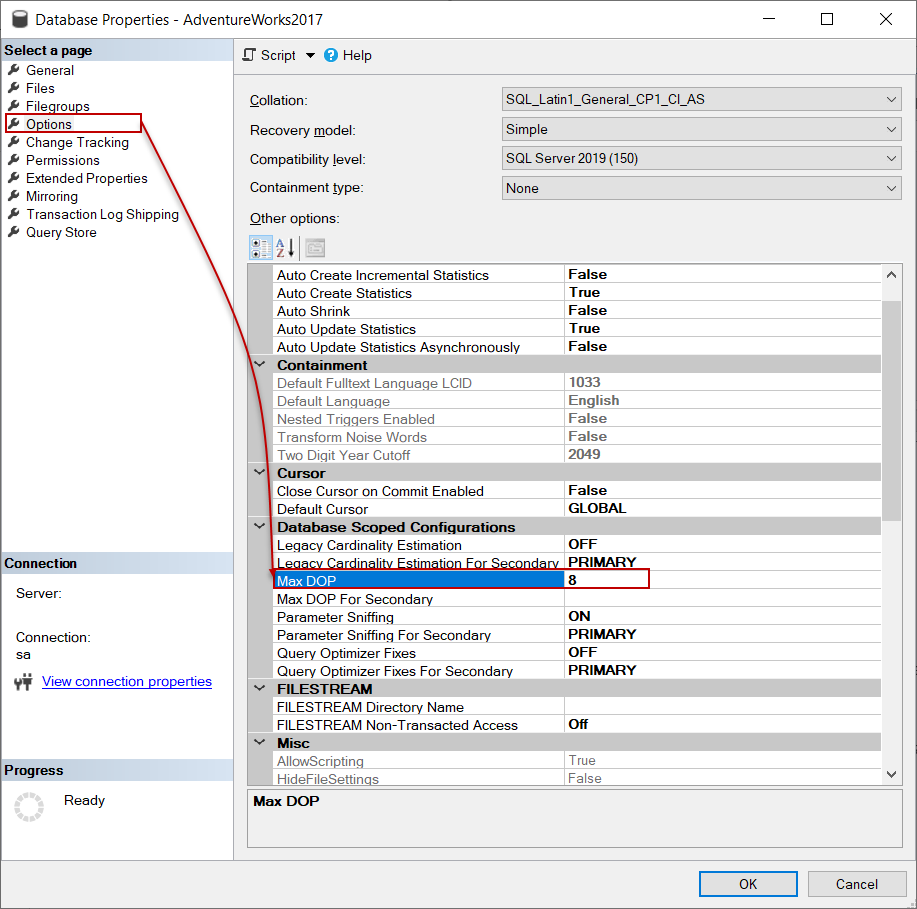
On the other hand, this value can be changed for a particular database and can be seen on the Options tab of the database.
另一方面,可以为特定数据库更改此值,并且可以在数据库的“ 选项”选项卡上看到该值。
The MAXDOP hint can be used to explicitly specify how many processors can be used by a query. For the below query, we will limit the maximum number of CPUs to be used to 2.
MAXDOP提示可用于显式指定查询可使用多少个处理器。 对于以下查询,我们将使用的最大CPU数量限制为2。
SELECT ProductID,SUM(LineTotal) AS TotalsOfLine ,
SUM(UnitPrice) AS TotalsOfPrice, SUM(UnitPriceDiscount) AS TotalsOfDiscount FROM
Sales.SalesOrderDetailEnlarged SOrderDet
INNER JOIN Sales.SalesOrderHeaderEnlarged SalesOr
ON SOrderDet.SalesOrderID = SalesOr.SalesOrderID
WHERE PurchaseOrderNumber LIKE 'PO%'
GROUP BY ProductID
OPTION (MAXDOP 2)
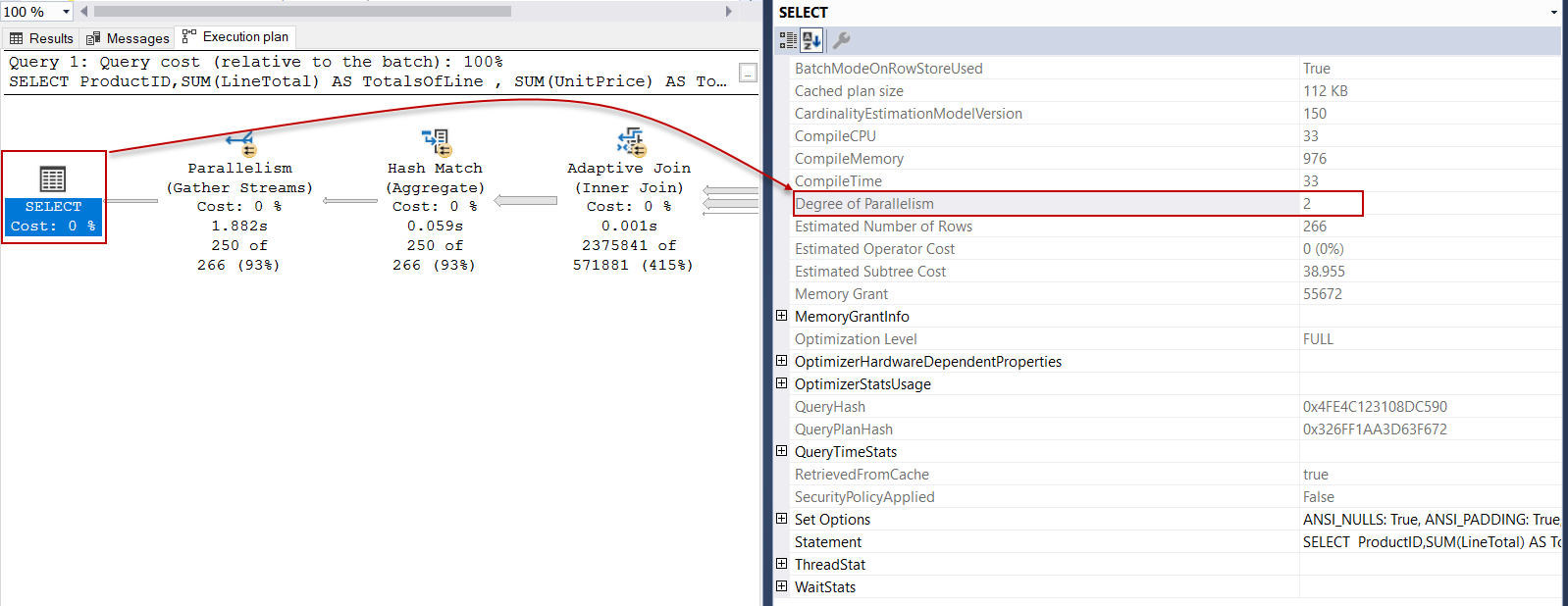
In the above query plan, the degree of parallelism attribute shows how many processors have used when the above query was executed.
在上述查询计划中, 并行度属性显示执行上述查询时使用了多少个处理器。
Also, this option can be used to force query optimizer to generate a serial query plan. In the following query, we will set the MAXDOP option as 1 and the query optimizer will create a serial query plan.
同样,此选项可用于强制查询优化器生成串行查询计划。 在下面的查询中,我们将MAXDOP选项设置为1,查询优化器将创建一个串行查询计划。
SELECT ProductID,SUM(LineTotal) AS TotalsOfLine ,
SUM(UnitPrice) AS TotalsOfPrice, SUM(UnitPriceDiscount) AS TotalsOfDiscount FROM
Sales.SalesOrderDetailEnlarged SOrderDet
INNER JOIN Sales.SalesOrderHeaderEnlarged SalesOr
ON SOrderDet.SalesOrderID = SalesOr.SalesOrderID
WHERE PurchaseOrderNumber LIKE 'PO%'
GROUP BY ProductID
OPTION (MAXDOP 1)
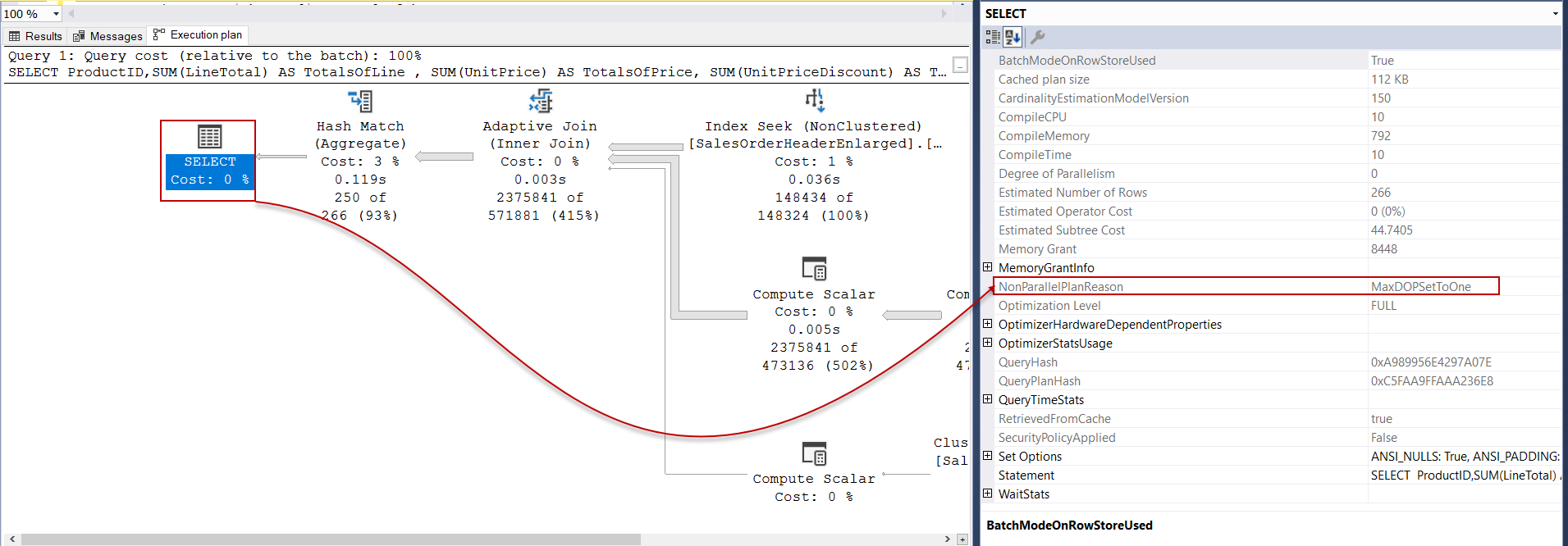
As we can see, the NonParallelPlanReason attribute obviously shows why the query optimizer does not generate a parallel execution plan. For this example, the attribute value shows the MaxDOPSetToOne value because we have set the MAXDOP option as 1.
如我们所见, NonParallelPlanReason属性显然显示了查询优化器为何不生成并行执行计划的原因。 在此示例中,该属性值显示了MaxDOPSetToOne值,因为我们将MAXDOP选项设置为1。
亲和面膜 (Affinity Mask)
In SQL Server, this option helps to restrict specific CPU core usage. So that the SQL Server uses only the dedicated CPU cores. However, about this option, Microsoft warns us with the following note:
在SQL Server中,此选项有助于限制特定的CPU内核使用。 因此,SQL Server仅使用专用的CPU内核。 但是,关于此选项,Microsoft向我们发出以下注意事项 :
“This feature will be removed in a future version of Microsoft SQL Server. Do not use this feature in new development work, and modify applications that currently use this feature as soon as possible.”
“此功能将在将来的Microsoft SQL Server版本中删除。 不要在新的开发工作中使用此功能,而应尽快修改当前使用此功能的应用程序。”
To find this option, you can navigate to the Processors tab on the SQL Server properties page. In the following illustration, we will set the only one CPU core to SQL Server.
要找到此选项,可以导航到“ SQL Server属性”页面上的“ 处理器”选项卡。 在下图中,我们将为SQL Server设置唯一的一个CPU内核。
Now we will execute the following query and interpret the query plan.
现在,我们将执行以下查询并解释查询计划。
SELECT ProductID,SUM(LineTotal) AS TotalsOfLine ,
SUM(UnitPrice) AS TotalsOfPrice, SUM(UnitPriceDiscount) AS TotalsOfDiscount FROM
Sales.SalesOrderDetailEnlarged SOrderDet
INNER JOIN Sales.SalesOrderHeaderEnlarged SalesOr
ON SOrderDet.SalesOrderID = SalesOr.SalesOrderID
WHERE PurchaseOrderNumber LIKE 'PO%'
GROUP BY ProductID
In this execution plan, we can see a new value for the NonParallelPlanReason attribute. EstimatedDOPIsOne specifies that only one CPU core is dedicated to the SQL Server; for this reason, it generates a serial query plan.
在此执行计划中,我们可以看到NonParallelPlanReason属性的新值。 EstimatedDOPIsOne指定仅一个CPU内核专用于SQL Server; 因此,它会生成一个串行查询计划。
Tip: Inserting data into the variable does not allow us to generate parallel query plans. In the following query, we will declare a table variable and then insert some rows to it. Also, we will enable the actual query plan and will analyze it.
提示:将数据插入变量不允许我们生成并行查询计划。 在下面的查询中,我们将声明一个表变量,然后向其中插入一些行。 另外,我们将启用实际的查询计划并进行分析。
DECLARE @Temp AS TABLE (ID INT , TrackingNumber VARCHAR(100), LTotal FLOAT)
INSERT INTO @Temp
SELECT ProductID,CarrierTrackingNumber , LineTotal FROM Sales.SalesOrderDetailEnlarged
WHERE CarrierTrackingNumber = '4911-403C-98'
For this query, we figured out that the query optimizer has created a serial query plan because the NonParallelPlanReason attribute indicates the CouldNotGenerateValidParallelPlan value. On the other hand, temporary tables allow creating parallel query plans when we insert to rows. Now we will execute the same query for a temporary table and interpret the query plan.
对于此查询,我们发现查询优化器已经创建了一个串行查询计划,因为NonParallelPlanReason属性指示CouldNotGenerateValidParallelPlan值。 另一方面,当我们插入行时,临时表允许创建并行查询计划。 现在,我们将对临时表执行相同的查询并解释查询计划。
DROP TABLE IF EXISTS #TempInsert
CREATE TABLE #TempInsert (ID INT , TNumber VARCHAR(100), LTotal FLOAT)
GO
INSERT INTO #TempInsert
SELECT ProductID,CarrierTrackingNumber , LineTotal FROM Sales.SalesOrderDetailEnlarged
WHERE CarrierTrackingNumber = '4911-403C-98'
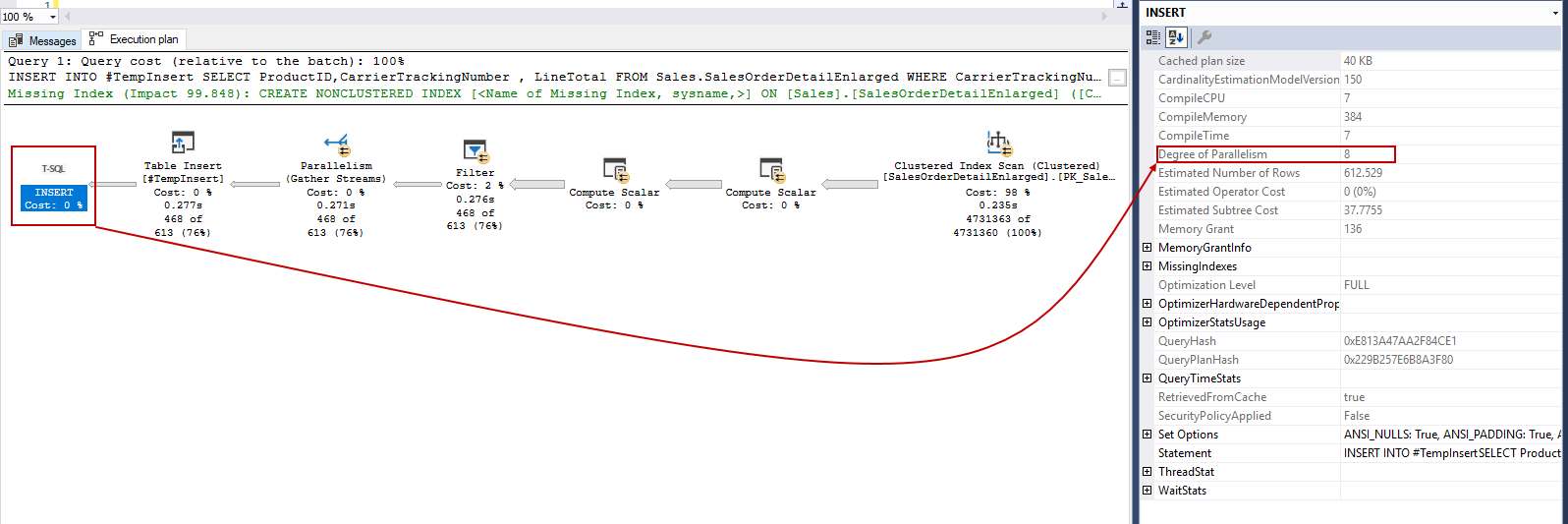
As seen above, inserting data into the temporary table allows creating a parallel query plan. This is the main difference between temporary tables and table variables in terms of parallelism.
如上所示,将数据插入临时表允许创建并行查询计划。 就并行性而言,这是临时表和表变量之间的主要区别。
结论 (Conclusion)
In this article, we learned the factors that help query optimizer to decide when to create Parallel Execution Plans. The query optimizer takes into account three options when generating parallel plans as we have stated them above:
在本文中,我们学习了有助于查询优化器决定何时创建并行执行计划的因素。 如上所述,查询优化器在生成并行计划时会考虑三个选项:
- Cost Threshold for Parallelism 并行成本阈值
- Max Degree of Parallelism (MAXDOP) 最大并行度(MAXDOP)
- Affinity mask 亲和力面膜
翻译自: https://www.sqlshack.com/the-basics-of-parallel-execution-plans-in-sql-server/
SQL Server中并行执行计划的基础相关推荐
- 如何在SQL Server中创建视图
In this article, we will learn the basics of the view concept in SQL Server and then explore methods ...
- SQL Server中的执行计划
介绍 (Introduction) In this article, I'm going to explain what the Execution Plans in SQL Server are a ...
- SQL Server查询执行计划–基础
为什么查询执行对SQL Server性能很重要? (Why is query execution important for SQL Server performance?) SQL Server性能 ...
- sql 闩锁 原因_如何识别和解决SQL Server中的热闩锁
sql 闩锁 原因 描述 (Description) In SQL Server, internal latch architecture protects memory during SQL ope ...
- 十步优化SQL Server中的数据访问
故事开篇:你和你的团队经过不懈努力,终于使网站成功上线,刚开始时,注册用户较少,网站性能表现不错,但随着注册用户的增多,访问速度开始变慢,一些用户开始发来邮件表示抗议,事情变得越来越糟,为了留住用户, ...
- 在SQL Server中分页结果的最佳方法是什么
如果您还希望获得结果总数(在进行分页之前),那么在SQL Server 2000.2005.2008.2012中对结果进行分页的最佳方法是(性能明智的)? #1楼 最终, Microsoft SQL ...
- SQL Server中SCAN 和SEEK的区别
SQL Server中SCAN 和SEEK的区别 SQL SERVER使用扫描(scan)和查找(seek)这两种算法从数据表和索引中读取数据.这两种算法构成了查询的基础,几乎无处不在.Scan会扫描 ...
- cte公用表表达式_CTE SQL删除; 在SQL Server中删除具有公用表表达式的数据时的注意事项
cte公用表表达式 In this article, the latest in our series on Common table expressions, we'll review CTE SQ ...
- 图数据库 graph_通过SQL Server中的自连接了解Graph数据库相对于关系数据库的好处
图数据库 graph Earlier this year, I published several articles on SQLShack with an aim of demonstrating ...
最新文章
- 深度学习 英文 训练阶段_半监督深度学习训练和实现小Tricks
- Windows核心编程的官方网站
- 《scikit-learn》随机森林之深入学习
- 小明利用计算机软件绘制函数,辽宁省大连市2014年高二学业水平模拟考试 信息技术试题(三)...
- 【入门二】格式化输入/输出
- 08.CXF发布WebService(Java项目)
- Vue3 JSON编辑器
- 高人泡MM的QQ聊天记录
- 从excel表格生成ArcGIS Pro样式符号
- python刷抖音_Python刷抖音脚本
- win7系统提示“此windows副本不是正版” 解决方案
- python矩阵教程_Python Numpy Tutorial / Python Numpy 教程 (矩阵和图像操作)
- android模拟器 diy,DIY泡沫黏液模拟器
- CSS 1px边框问题两个解决方案
- 宜宾市放心舒心消费平台-工商GIS一张图
- ECN Trade:全球经济疲软,美国国债成新宠
- 如何用python抓取文献_浅谈Python爬虫技术的网页数据抓取与分析
- 路由 OSPF常见4种网络类型MA、P2P、NBMA、P2MP、OSPF报头字段信息简介。
- Solr与mysql数据同步
- 计算机专业学生u盘32g够用吗,很超值:为什么我的32G USB只有28.8g?