redis 命令 数据清理_如何在命令行中清理数据
redis 命令 数据清理
我是兼职数据审计师。 可以将我视为校对员,使用数据表而不是散文页面。 这些表是从关系数据库中导出的,通常大小适中:100,000至1,000,000条记录和50至200个字段。
我从未见过没有错误的数据表。 您可能会想到,混乱并不局限于复制记录,拼写和格式错误以及放置在错误字段中的数据项。 我也发现:
- 坏记录分散在几行中,因为数据项具有嵌入式换行符
- 同一记录中一个字段中的数据项与另一字段中的数据项不同
- 数据项被截断的记录,通常是因为很长的字符串被塞入限制为50个或100个字符的字段中
- 字符编码失败会产生乱码,称为mojibake
- 不可见的控制字符 ,其中一些会导致数据处理错误
- 上一个无法理解数据字符编码的程序插入的替换字符和神秘的问号
清理这些问题并不难,但是找到它们存在非技术性的障碍。 首先是每个人天生都不愿处理数据错误。 在我看到表格之前,数据所有者或管理人员可能已经经历了数据悲伤的所有五个阶段:
- 我们的数据没有错误。
- 好吧,也许有一些错误,但是它们并不是那么重要。
- 好,有很多错误; 我们将请内部人员与他们打交道。
- 我们已经开始修复一些错误,但这很耗时。 我们将在迁移到新的数据库软件时执行此操作。
- 移到新数据库时,我们没有时间清理数据。 我们可以使用一些帮助。
第二种阻碍进度的态度是,人们相信数据清理需要专用的应用程序-昂贵的专有程序或出色的开源程序OpenRefine 。 为了处理专用应用程序无法解决的问题,数据管理器可能会向程序员寻求帮助-擅长使用Python或R的人 。
但是,数据审核和清理通常不需要专用的应用程序。 纯文本数据表已经存在了数十年,文本处理工具也是如此。 打开一个Bash shell,您将在一个工具箱中加载强大的文本处理器,例如grep , cut , paste , sort , uniq , tr和awk 。 它们快速,可靠且易于使用。
我在命令行上进行了所有数据审核,并且将许多数据审核技巧放在了“ cookbook”网站上 。 我经常将操作存储为函数和Shell脚本(请参见下面的示例)。
是的,命令行方法要求从数据库中导出要审核的数据。 是的,审核结果需要稍后在数据库中进行编辑,或者(在数据库允许的情况下)需要导入已清除的数据项以代替杂乱的数据项。
但是优势非常明显。 awk将在消费者级台式机或笔记本电脑上在几秒钟内处理数百万条记录。 简单的正则表达式将找到您可以想象的所有数据错误。 所有这些都将安全地发生在数据库结构之外 :命令行审计不会影响数据库,因为它可以处理从其数据库中释放的数据。
在这一点上,接受过Unix培训的读者会自鸣得意。 他们还记得很多年前通过这些方式在命令行上处理数据。 从那时起发生的事情是处理能力和RAM有了惊人的提高,并且标准命令行工具已经大大提高了效率。 数据审核从未如此快捷或容易。 现在,Microsoft Windows 10可以运行Bash和GNU / Linux程序,Windows用户可以欣赏处理混乱数据的Unix和Linux座右铭:保持冷静并打开终端。

摄影:罗伯特·梅西波夫(CC BY)
一个例子
假设我想在一个大表的特定字段中找到最长的数据项。 这并不是真正的数据审计任务,但是它将显示Shell工具如何工作。 出于演示的目的,我将使用制表符分隔表full0 ,其中有1122023条记录(加上一个标题行)和49场,我会看在外地号码36(我得到的场数与函数解释我食谱网站 。)
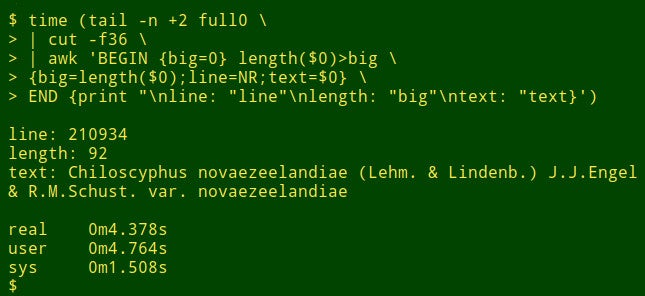
该命令首先使用tail来从full0删除标题行。 结果通过管道传递给cut ,从而提取断头场36。流水线中的下一个是awk 。 此处变量big初始化为0值; 然后awk测试第一条记录中数据项的长度。 如果长度大于0,则awk big重置为新的长度,并将行号(NR)存储在变量line ,并将整个数据项存储在变量text 。 然后, awk依次处理剩余的1,122,022条记录中的每条记录,并在找到更长的数据项时重置这三个变量。 最后,它打印出行号,数据项的长度和最长数据项的全文的整齐分隔的列表。 (在下面的代码中,为了清楚起见,将命令分解为几行。)
<code>tail -n +2 full0 \
> | cut -f36 \
> | awk 'BEGIN {big=0} length($0)>big \
> {big=length($0);line=NR;text=$0} \
> END {print "\nline: "line"\nlength: "big"\ntext: "text}' </code>
这需要多长时间? 在我的台式机(核心i5,8GB RAM)上大约4秒钟:
现在进行整洁的部分:我可以将该长命令弹出到shell函数longest ,该函数将文件名($1)和字段号($2)作为其参数:
然后,我可以将命令作为函数重新运行,在其他字段和其他文件中查找最长的数据项,而无需记住命令的编写方式:
作为最后的调整,我可以将要搜索的编号字段的名称添加到输出中。 为此,我使用head提取表的标题行,将该行通过管道传输到tr以将制表符转换为新行,然后将结果列表通过管道传输到tail和head以在列表上打印$2th字段名称,其中$2是字段编号参数。 字段名称存储在shell变量field并作为内部awk变量fld传递给awk进行打印。
<code>longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
tail -n +2 "$1" \
| cut -f"$2" | \
awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
{big=length($0);line=NR;text=$0}
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }</code>

请注意,如果我要在多个不同字段中寻找最长的数据项,我所要做的就是按向上箭头键以获取最后一个longest命令,然后对字段号进行退格并输入一个新的。
翻译自: https://opensource.com/article/18/5/command-line-data-auditing
redis 命令 数据清理
redis 命令 数据清理_如何在命令行中清理数据相关推荐
- 数据透视表 筛选_筛选列表可见行中的数据透视表
数据透视表 筛选 When you create a pivot table in Excel, it doesn't matter if there are filters applied in t ...
- python向mysql中添加数据标签_用python在MySQL中写入数据和添加数据
在笔者之前的博文中,已介绍了用python连接与mysql数据库的知识.包括如何安装python连接mysql的pymysql包,如何通过cusor语句将python与mysql连接起来,以及如何用p ...
- 数据建模_浅谈数据仓库建设中的数据建模方法
所谓水无定势,兵无常法.不同的行业,有不同行业的特点,因此,从业务角度看,其相应的数据模型是千差万别的.目前业界较为主流的是数据仓库厂商主要是 IBM 和 NCR,这两家公司的除了能够提供较为强大的数 ...
- ug如何导入excel数据点_怎样将dat文件中的数据导入ug中进行操作
怎样将dat文件中的数据导入ug中进行操作 我的问题是,我用了两种方法作一件事情,第一种是直接将cpp 程序的内容粘贴到用一个回调函数中,这样算法生成的数据直接供u g函数使用.这样做的话,感觉很麻烦 ...
- unix和linux命令_Linux vs. Unix,在命令行中清理数据,为儿童准备的15本书,以及更多必读内容
unix和linux命令 上周,关于Linux与Unix的一篇文章是最受欢迎的读物. 查看其他Opensource.com读者对以下内容的了解: Linux与Unix:有什么区别? ,作者:菲尔·埃斯 ...
- xlsx表格怎么做汇总统计_怎样在excel电子表格中对数据进行分类汇总,实例教程...
怎样在 excel 电子表格中对数据进行分类汇 总 , 实例教程 篇一:怎样在 excel 中对数据进行分类汇总 怎样在 Excel 中对数据进行分类汇总 当需要在 Excel 中对数据进行分类计算时 ...
- Python基础_第5章_Python中的数据序列
Python基础_第5章_Python中的数据序列 文章目录 Python基础_第5章_Python中的数据序列 Python中的数据序列 一.字典--Python中的==查询==神器 1.为什么需要 ...
- 删除html表里的数据,如何删除HTML表格行中表格数据之间的空白?
我想弄清楚如何删除HTML表格中的表格数据之间的额外空间.例如,在下面的代码中,在我的Web浏览器IE中查看代码时,"名字"表格数据和"输入名称"表格数据之间会 ...
- easyexcel 读取指定行数据_Excel怎么设置只提取指定行中的数据?
Excel怎么设置只提取指定行中的数据?有些时候我们需要从一个excel文件中的数据库中提取指定的行或列中的数据.例如如图示,是国内所有上市公司的行业统计.但是现在我们只需要其中部分上市公司的行业统计 ...
- pandas使用read_csv函数读取csv数据、sort_index函数基于多层行索引对数据排序(设置ascending参数列表指定不同层行索引的排序方向)
pandas使用read_csv函数读取csv数据.index_col参数指定作为行索引的数据列索引列表形成复合(多层)行索引.sort_index函数基于多层行索引对数据排序(设置ascending ...
最新文章
- 【Qt】Q_PROPERTY():属性系统
- Mac mysql sql_model引起的问题
- matlab神经网络 时间序列,请问吧里有大神做过MATLAB时间序列神经网络(NARX)吗?...
- Beta阶段事后分析
- plsql(轻量版)_流程控制
- 收藏:DPDK内存基本概念
- 关于“收获”啰嗦几句。
- Java虚拟机(十三)——垃圾回收概述
- java中的与或运算
- Android 核心组件 Activity 之上
- linux du命令参数及用法详解---linux统计磁盘空间大小命令
- bat 启动 不弹出对话框_跳过网易启动器用Steam启动逆水寒
- SAS Planet软件使用教程及下载Googlemap地图
- Ipsec phase1 and phase2
- android root大师,安卓Root成难题?ROOT大师帮你一键Root
- 机器学习之利用线性回归预测波士顿房价和可视化分析影响房价因素实战(python实现 附源码 超详细)
- Python-TypeError:takes no arguments
- 堆栈与动态分配内存空间
- AE正确释放打开资源
- 50个直击灵魂的问题_质量管理50个常见问题详解
热门文章
- Nodejs 搭建https服务器(二)
- 139邮箱smtp地址和端口_常用邮箱的服务器(SMTP/POP3)地址和端口总结-阿里云开发者社区...
- 新手入门必备,分享5个自媒体实用工具,效率和收益都翻倍
- python进阶路线 知乎_python进阶书籍知乎怎么用
- Altium Designer 使用技巧
- 隐私计算--23--纵向联邦学习
- 【智能制造】Digital Twin的8种解读! 国际8大主流厂商对digital twin的理解
- 服务器型号sc2312怎么看,HP MSA2312sa实施过程全记录
- 《程序设计综合设计》课程设计--电话号码查询系统
- 深入理解深度学习——注意力机制(Attention Mechanism):注意力评分函数(Attention Scoring Function)