NLP的ImageNet时代已经到来
摘要: NLP领域即将巨变,你准备好了吗?
自然语言处理(NLP)领域正在发生变化。
作为NLP的核心表现技术——词向量,其统治地位正在被诸多新技术挑战,如:ELMo,ULMFiT及OpenAI变压器。这些方法预示着一个分水岭:它们在 NLP 中拥有的影响,可能和预训练的 ImageNet 模型在计算机视觉中的作用一样广泛。
由浅到深的预训练
预训练的词向量给NLP的发展带来了很好的方向。2013年提出的语言建模近似——word2vec,在硬件速度慢且深度学习模型得不到广泛支持的时候,它的效率和易用性得到了采用。此后,NLP项目的标准方式在很大程度上保持不变:经由算法对大量未标记数据进行预处理的词嵌入被用于初始化神经网络的第一层,其它层随后在特定任务的数据上进行训练。这种方法在大多数训练数据量有限的任务中表现的不错,通过模型都会有两到三个百分点的提升。尽管这些预训练的词嵌入模型具有极大的影响力,但它们有一个主要的局限性:它们只将先验知识纳入模型的第一层,而网络的其余部分仍然需要从头开始训练。
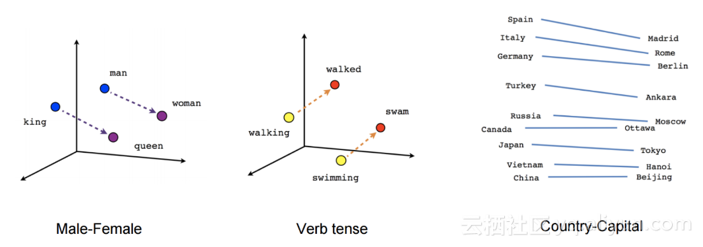
word2vec捕获的关系(来源:TensorFlow教程)
Word2vec及其他相关方法是为了实现效率而牺牲表达性的笨方法。使用词嵌入就像初始化计算机视觉模型一样,只有编码图像边缘的预训练表征:它们对许多任务都有帮助,但是却无法捕获可能更有用的信息。利用词嵌入初始化的模型需要从头开始学习,不仅要消除单词的歧义,还要从单词序列中提取意义,这是语言理解的核心。它需要建模复杂的语言现象:如语义组合、多义性、长期依赖、一致性、否定等等。因此,使用这些浅层表示初始化的NLP模型仍然需要大量示例才能获得良好性能。
ULMFiT、ELMo和OpenAI transformer最新进展的核心是一个关键的范式转变:从初始化我们模型的第一层到分层表示预训练整个模型。如果学习词向量就像学习图像的边一样,那么这些方法就像学习特征的完整层次结构一样,从边到形状再到高级语义概念。
有趣的是,计算机视觉(CV)社区多年来已经做过预训练整个模型以获得低级和高级特征。大多数情况下,这是通过学习在ImageNet数据集上对图像进行分类来完成的。ULMFiT、ELMo和OpenAI transformer现已使NLP社区接近拥有“ ImageNet for language ”的能力,即使模型能够学习语言的更高层次细微差别的任务,类似于ImageNet启用训练的方式学习图像通用功能的CV模型。在本文的其余部分,我们将通过扩展和构建类比的ImageNet来解开为什么这些方法看起来如此有前途。
ImageNet

ImageNet对机器学习研究过程的影响几乎是不可取代的。该数据集最初于2009年发布,并迅速演变为ImageNet大规模视觉识别挑战赛(ILSVRC)。2012年,由Alex Krizhevsky,Ilya Sutskever和Geoffrey Hinton提交的深层神经网络表现比第二竞争对手好41%,这表明深度学习是一种可行的机器学习策略,并可能引发ML研究领域的深度学习的爆发。
ImageNet的成功表明,在深度学习的时代,数据至少与算法同样重要。ImageNet数据集不仅使诞生于2012年的深度学习能力得以展现,而且还在迁移学习中实现了重要性的突破:研究人员很快意识到可以使用最先进的模型从ImageNet中学到任何将权重初始化,这种“微调”方法可以表现出良好的性能。
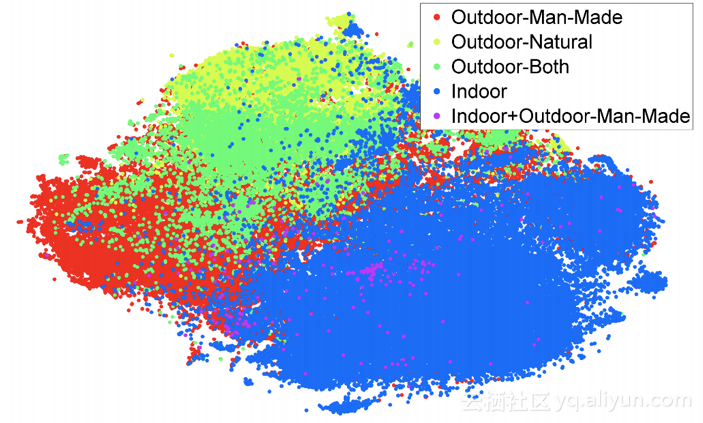
在ILSVRC-2012上接受过训练的特征可归纳为SUN-397数据集
预训练的ImageNet模型已被用于在诸如物体检测之类的任务中如语义分割,人体姿势估计和视频识别,并且表现非常良好。同时,他们已经将CV应用到训练样本数量少且注释昂贵的领域。
ImageNet中有什么?
为了确定ImageNet的语言形式,我们首先必须确定是什么让ImageNet适合迁移学习。之前我们只是对这个问题有所了解:减少每个类的示例数或类的数量只会导致性能下降,而细粒度和更多数据对性能并不总是好的。
与其直接查看数据,更谨慎的做法是探究在数据上训练的模型学到了什么。众所周知,在ImageNet上训练的深层神经网络的特征迁移顺序为从第一层到最后一层、从一般任务到特定任务:较低层学习建模低级特征,如边缘,而较高层学习建模高级概念,如图案和整个部分或对象,如下图所示。重要的是,关于物体边缘、结构和视觉组成的知识与许多 CV 任务相关,这就揭示了为什么这些层会被迁移。因此,类似 ImageNet的数据集的一个关键属性是鼓励模型学习可以泛化到问题域中新任务的特征。

可视化在ImageNet上训练的GoogLeNet中不同层的特征捕获的信息
除此之外,很难进一步概括为什么ImageNet的迁移工作表现的如此好。例如,ImageNet数据集的另一个可能的优点是数据的质量,ImageNet的创建者竭尽全力确保可靠和一致的注释。然而,远程监督的工作是一个对比,这表明大量的弱标签数据可能就足够了。事实上,最近Facebook的研究人员表示,他们可以通过预测数十亿社交媒体图像上的主题标签以及ImageNet上最先进的准确性来预先训练模型。
如果没有更具体的见解,我们必须明白两个关键的需求:
1. 类似ImageNet的数据集应该足够大,即大约数百万个训练样例。
2. 它应该代表该学科的问题空间。
用于语言任务的ImageNet
相比于 CV,NLP 的模型通常浅得多。因此对特征的分析大部分聚焦于第一个嵌入层,很少有人研究迁移学习的高层性质。我们考虑规模足够大的数据集。在当前的 NLP 形势下,有以下几个常见任务,它们都有可能用于 NLP 的预训练模型。
阅读理解是回答关于段落自然语言问题的任务。这项任务最受欢迎的数据集是Stanford Question Answering Dataset(SQuAD),其中包含超过100,000个问答配对,并要求模型通过突出显示段落中的跨度来回答问题,如下所示:

自然语言推理是识别一段文本和一个假设之间的关系(蕴涵、矛盾和中立)的任务。这项任务最受欢迎的数据集是斯坦福自然语言推理(SNLI)语料库,包含570k人性化的英语句子对。数据集的示例如下所示:

机器翻译,将一种语言的文本翻译成另一种语言的文本,是NLP中研究最多的任务之一,多年来人们已经为流行的语言对积累了大量的训练数据,例如40M英语-法语WMT 2014中的法语句子对。请参阅下面的两个示例翻译对:

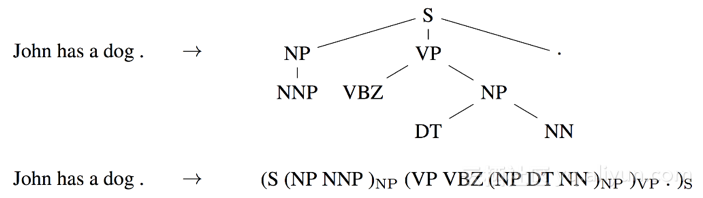
成分文法分析(Constituency parsing)试图以(线性化)分析树的形式提取句子的句法结构,如下所示。目前已经有数以百万计的弱标签解析用于训练此任务的序列到序列模型。
语言建模(LM)旨在预测下一个单词的前一个单词。现有的基准数据集最多包含一亿个单词,但由于任务无监督的,因此可以使用任意数量的单词进行训练。请参阅下面的维基百科文章组成的受欢迎的WikiText-2数据集中的示例:

所有这些任务提供或允许收集足够数量的示例来训练。实际上,以上任务(以及很多其它任务例如情感分析、skip-thoughts 和自编码等)都曾在近几个月被用于预训练表征。
虽然任何的数据都包含某些偏差,人类标注可能无意间引入额外信息,而模型也将会利用这些信息。近期研究表明在诸如阅读理解和自然语言推理这样的任务中的当前最优模型实际上并没有形成深度的自然语言理解,而是注意某些线索以执行粗浅的模式匹配。例如,Gururangan 等人 (2018) 在《Annotation Artifacts in Natural Language Inference Data》中表明,标注者倾向于通过移除性别或数量信息生成蕴涵示例,以及通过引入否定词生成矛盾。只需使用这些线索,模型就可以在未查看前提的情况下在 SNLI 数据集上以 67% 的准确率分类假设。
因此,更难的问题是:哪个任务最能代表NLP问题?换种说法,哪个任务使我们能学到最多关于自然语言理解的知识或关系?
语言建模的案例
为了预测句子中最可能的下一个单词,模型不仅需要能够表达语法(预测单词的语法形式必须与其修饰语或动词匹配),还需要模型语义。更重要的是,最准确的模型必须包含可被视为世界知识或常识的东西。考虑一个不完整的句子“服务很差,但食物是”。为了预测后续的单词,如“美味”或“糟糕”,模型不仅要记住用于描述食物的属性,还要能够识别出“但是”结合引入对比,以便新属性具有“穷人”的反对情绪。
语言建模是上面提到的最后一种方法,它已被证明可以捕获与下游任务相关的语言的许多方面,例如长期依赖性、等级关系和情绪。与相关的无监督任务(例如跳过思考和自动编码)相比,语言建模在语法任务上表现更好,即使训练数据较少。
语言建模的最大好处之一是训练数据可以通过任何文本语料库免费提供,并且可以获得无限量的训练数据。这一点尤其重要,因为NLP不仅涉及英语、目前在全球范围内有大约4,500种语言。作为预训练任务的语言建模为以前没有语言开发模型打开了大门。对于数据资源非常低的语言,即使是未标记的数据也很少,多语言语言模型可以同时在多种相关语言上进行训练,类似于跨语言嵌入的工作。
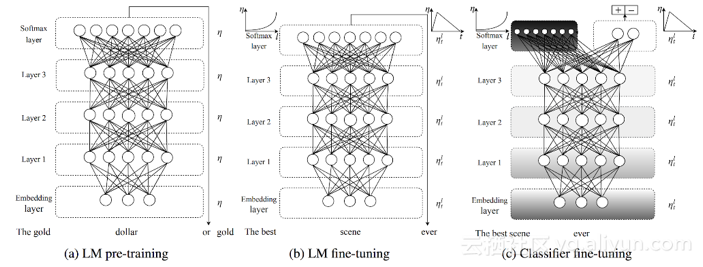
ULMFiT的不同阶段
到目前为止,我们将语言建模作为预训练任务的论点纯粹是概念性的。但最近几个月,我们也获得了经验:语言模型嵌入(ELMo)、通用语言模型微调(ULMFiT)和OpenAI已经凭经验证明了语言建模如何用于预训练,如上所示。所有这三种方法都采用预训练语言模型来实现自然语言处理中各种任务的最新技术,包括文本分类、问答、自然语言推理、序列标记等等。
在如下所示的ELMo等很多情况中,使用预训练语言模型作为核心的算法在广泛研究的基准上,要比当前最优的结果高10%到20%。ELMo同时也获得了 NLP顶级盛会NAACL-HLT 2018 的最佳论文。最后,这些模型表现出非常高的样本效率,达到最优性能只需要数百样本,甚至可以实现zero-shot学习。
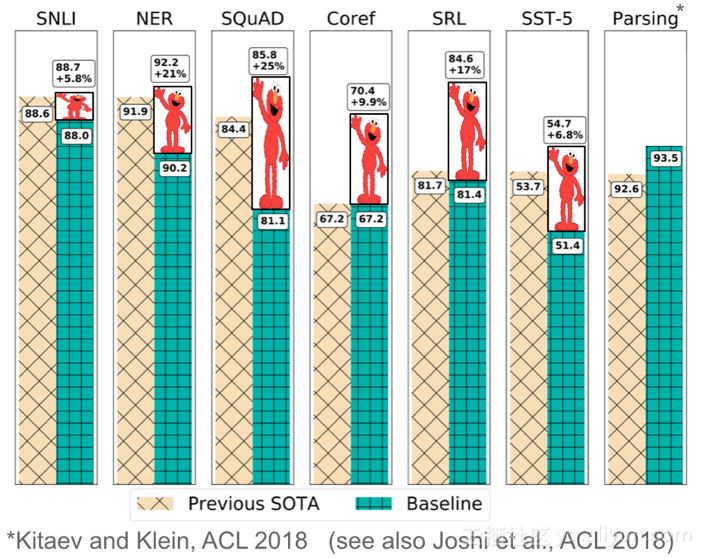
ELMo在各种NLP任务中实现的改进
鉴于这一步取得的变化,NLP 实践者很可能在一年后下载预处理的语言模型,而不是预处理的词嵌入,来用于他们自己的模型中,就像现在大多数 CV 项目的起点是如何预处理 ImageNet 模型一样。
然而,类似于word2vec,语言建模的任务自然有其自身的局限性:它只是作为真正的语言理解的代理,并且单个单体模型没有能力捕获某些下游任务所需的信息。例如,为了回答关于或遵循故事中人物轨迹的问题,模型需要学习执行回指或共同解决。此外,语言模型只能捕获他们所看到的内容。某些类型的特定信息,例如大多数常识知识,很难单独从文本中学习,这就需要整合一部分外部信息。
一个突出的问题是如何从一个预训练语言模型将信息迁移到下游任务中。有两个主要的范式,一是是否将预训练语言模型作为固定的特征提取器,并将其表征作为特征整合到随机初始化的模型(正如ELMo所做的)中;二是是否微调完整的语言模型(如ULMFiT所做的)。后者在计算机视觉中很常用,其中训练时会调整模型的最高层或最高的几层。虽然NLP模型通常更浅,因此相比对应的视觉模型需要不同的微调技术,但近期的的预训练模型变得更深了。我在下一月将展示NLP迁移学习的每个核心组件的作用:包括表达性很强的语言模型编码器(如深度BiLSTM或Transformer),用于预训练的数据的量和本质,以及微调预训练模型使用的方法。
但理论依据在哪里?
到目前为止,我们的分析主要是概念性的和经验性的,因为人们仍然很难理解为什么在ImageNet上训练的模型迁移得如此之好。一种更为正式的、考虑预训练模型泛化能力的方式是基于bias learning模型(Baxter, 2000)。假设我们的问题域覆盖特定学科中任务的所有排列,例如计算机视觉——它构成了环境。我们对此提供了许多数据集,允许我们诱导一系列假设空间 H=H'。我们在偏置学习中的目标是找到偏置,即假设空间 H'∈H,它可以在整个环境中最大化性能。
多任务学习中的经验和理论结果(Caruana,1997; Baxter,2000)表明,在足够多的任务中学习到的偏置或许可以推广到在同样环境中未见过的任务上。通过多任务学习,在ImageNet上训练的模型可以学习大量的二进制分类任务(每个类一个)。这些任务都来自自然、真实世界的图像空间,可能对许多其他 CV 任务也有代表性。同样,语言模型通过学习大量分类任务(每个词一个)可能诱导出有助于自然语言领域许多其他任务的表征。然而,要想从理论上更好地理解为什么语言建模似乎在迁移学习中如此有效,还需要进行更多的研究。
NLP的ImageNet时代
NLP使用迁移学习的时机已经成熟。鉴于ELMo、ULMFiT和OpenAI的实证结果如此令人印象深刻,这种发展似乎只是一个时间问题,预训练的词嵌入模型将逐渐淘汰,取而代之的是每个 NLP 开发者工具箱里的预训练语言模型。这有可能会解决NLP领域标注数据量不足的问题。
数十款阿里云产品限时折扣中,赶紧点击领劵开始云上实践吧!
以上为译文。
本文由阿里云云栖社区组织翻译。
文章原标题《NLP's ImageNet moment has arrived》,
作者:gradient。译者:虎说八道,审校:。
文章为简译,更为详细的内容,请查看原文。
原文链接
NLP的ImageNet时代已经到来相关推荐
- NLP领域的ImageNet时代:词嵌入已死,语言模型当立
NLP领域的ImageNet时代:词嵌入已死,语言模型当立 https://www.toutiao.com/a6742137243487437316/ NLP领域的ImageNet时代:词嵌入已死,语 ...
- ImageNet时代将终结?何恺明新作:Rethinking ImageNet Pre-training
译者 | 刘畅 林椿眄 整理 | Jane 出品 | AI科技大本营 Google 最新的研究成果 BERT 的热度还没褪去,大家都还在讨论是否 ImageNet 带来的预训练模型之风真的要进入 NL ...
- 后ImageNet时代李飞飞视觉基因组重磅计划
后ImageNet时代李飞飞视觉基因组重磅计划 来源: 新智元 作者: 发布时间: 2016年03月23日 浏览量: 2295 [新智元导读]ImageNet已经成为全球最大的图像识别数据库,每 ...
- MAAS 模型即服务:人工智能大模型时代已经到来
MAAS 模型即服务:人工智能大模型时代已经到来 随着人工智能技术的快速发展,越来越多的大型模型被应用于各种领域,如自然语言处理.计算机视觉.语音识别等.这些大型模型通常需要庞大的计算资源和存储空间, ...
- 沈南鹏:一个科技主导的新时代已经到来
来源:500VC 最近,红杉中国的投资战略发生了明显变化.在近期一场公开演讲中,沈南鹏透露:"近年来,人工智能.高端制造等硬科技项目已经超过我们投资组合的80%." 在这个不一样 ...
- “小米造车”终于尘埃落定,网络营销下“造车时代”终将到来
还记得早前就有业内人士消息称"小米即将造车",对此小米集团回复称没有此消息,然而在日前的小米春季新品发布会上,雷军宣称"这是我人生中最后一次重大创业项目,我愿意压上所有战 ...
- 5G( 9)---开发者:你如何迎接5G时代的到来?
开发者:你如何迎接5G时代的到来? 摘要:围绕5G的谈话及其对开发者的影响才刚刚开始.我们预计明年将看到各种5G试点项目,并在2020年全球推出,因此我们鼓励您随时了解最新情况并了解所有最新动态. 随 ...
- 网络分解的时代即将到来,云服务商正在铺路 | 分析师洞察
1. 网络分解的时代即将到来,因为 Google 和 Facebook 这两大巨头已经为未来铺平了道路 多年以来,不少互联网公司都希望通过软件来摆脱硬件网络的束缚,而现在,距离这个颠覆创新变成现实,似 ...
- PC 新时代即将到来,Windows 11 将迎来首次重大更新:终于要支持 Android 应用了
过去两年对我们的生活方式产生了深远而持久的影响,PC 发挥了比以往任何时候都更有意义的作用.最近一位朋友反映,他从来没有想到他八岁的儿子会精通 Teams 和 OneNote,或者他七十二岁的母亲会成 ...
最新文章
- golang中的空slice
- 如何查看自己的Github仓库占据了多少存储空间
- Jquery 实现原理之 Ajax
- ubuntu系统显卡、显卡驱动、CUDA、CUDNN的介绍以及版本匹配问题
- abstract class和interface有什么区别
- 微擎模块安装文件manifest.xml
- 安装arm虚拟机_虚拟机Parallels出手:苹果M1的Mac能运行Win 10 还挺顺畅
- Windows安装pytorch-cpu
- Qt总结:QMessageBox(原生态弹出框及究极超nice封装自定义弹出框)
- 电脑五笔,电脑键盘五笔指法练习表
- 高效的六面体变换算法实现(一) —— 等圆柱映射 与 六面体映射
- 中国银行 网银 控件造成 IE8 崩溃的解决办法
- Eclipse如何调试代码
- smartbi服务器缓存文件,导出资源 - Smartbi V10帮助中心 -
- web课程设计网页规划与设计~在线阅读小说网页共6个页面(HTML+CSS+JavaScript+Bootstrap)...
- 批处理Bat建立微信多开程序
- USB3.0接口防静电及lay out设计
- Python使用 matplotlib的basemap绘图之一--几行代码画世界地图和中国地图
- 浏览器低延时播放监控摄像头RTSP海康大华硬盘录像机NVR视频(EasyNVR播放FLV视频流)
- 如何配置一个极简舒适的终端环境:oh-my-zsh 和iterms配置