DeepLearningToolBox学习——NN(neural network)
经典的DeepLearningToolBox,将里面的模型和Andrew Ng的UFLDL tutorial 对应学习,收获不小。
下载地址:DeepLearningToolBox
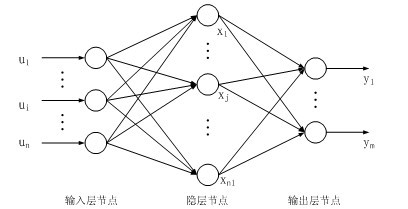
神经网络模型,层与层之间全连接。
1. test_example_NN
%% ex1 vanilla neural net
rand('state',0)
nn = nnsetup([784 100 10]);
opts.numepochs = 1; % Number of full sweeps through data
opts.batchsize = 100; % Take a mean gradient step over this many samples
[nn, L] = nntrain(nn, train_x, train_y, opts);[er, bad] = nntest(nn, test_x, test_y);batchsize 是指每个batch的大小,比如有60000张图片,这里把100个图片作为一个整体(batch)进行训练(或者测试),则有600个batch,需要训练600次。这个概念在DL中是常见的。
这里面出现了3个关键函数:nnsetup,nntrain,nntest
2. nnsetup
function nn = nnsetup(architecture)
% NNSETUP creates a Feedforward Backpropagate Neural Network
% nn = nnsetup(architecture) returns an neural network structure with n=numel(architecture)
% layers, architecture being a n x 1 vector of layer sizes e.g. [784 100 10]nn.size = architecture;nn.n = numel(nn.size);nn.activation_function = 'tanh_opt'; % Activation functions of hidden layers: 'sigm' (sigmoid) or 'tanh_opt' (optimal tanh).nn.learningRate = 2; % learning rate Note: typically needs to be lower when using 'sigm' activation function and non-normalized inputs.nn.momentum = 0.5; % Momentumnn.scaling_learningRate = 1; % Scaling factor for the learning rate (each epoch)nn.weightPenaltyL2 = 0; % L2 regularizationnn.nonSparsityPenalty = 0; % Non sparsity penaltynn.sparsityTarget = 0.05; % Sparsity targetnn.inputZeroMaskedFraction = 0; % Used for Denoising AutoEncodersnn.dropoutFraction = 0; % Dropout level (http://www.cs.toronto.edu/~hinton/absps/dropout.pdf)nn.testing = 0; % Internal variable. nntest sets this to one.nn.output = 'sigm'; % output unit 'sigm' (=logistic), 'softmax' and 'linear'for i = 2 : nn.n % weights and weight momentumnn.W{i - 1} = (rand(nn.size(i), nn.size(i - 1)+1) - 0.5) * 2 * 4 * sqrt(6 / (nn.size(i) + nn.size(i - 1)));nn.vW{i - 1} = zeros(size(nn.W{i - 1}));% average activations (for use with sparsity)nn.p{i} = zeros(1, nn.size(i)); end
end
for循环的作用是随机初始化网络权重W,vW是临时变量,用于计算W,p是用于计算稀疏使用。在下文代码中出现再讲。
3. nntrain
function [nn, L] = nntrain(nn, train_x, train_y, opts, val_x, val_y)
%NNTRAIN trains a neural net
% [nn, L] = nnff(nn, x, y, opts) trains the neural network nn with input x and
% output y for opts.numepochs epochs, with minibatches of size
% opts.batchsize. Returns a neural network nn with updated activations,
% errors, weights and biases, (nn.a, nn.e, nn.W, nn.b) and L, the sum
% squared error for each training minibatch.assert(isfloat(train_x), 'train_x must be a float');
assert(nargin == 4 || nargin == 6,'number ofinput arguments must be 4 or 6')loss.train.e = [];
loss.train.e_frac = [];
loss.val.e = [];
loss.val.e_frac = [];
opts.validation = 0;
if nargin == 6opts.validation = 1;
endfhandle = [];
if isfield(opts,'plot') && opts.plot == 1fhandle = figure();
endm = size(train_x, 1);batchsize = opts.batchsize;
numepochs = opts.numepochs;numbatches = m / batchsize;assert(rem(numbatches, 1) == 0, 'numbatches must be a integer');L = zeros(numepochs*numbatches,1);
n = 1;
for i = 1 : numepochstic;kk = randperm(m);%打乱顺序for l = 1 : numbatchesbatch_x = train_x(kk((l - 1) * batchsize + 1 : l * batchsize), :);%Add noise to input (for use in denoising autoencoder)%//加入noise,这是denoising autoencoder需要使用到的部分 %//具体加入的方法就是把训练样例中的一些数据调整变为0,inputZeroMaskedFraction表示了调整的比例 if(nn.inputZeroMaskedFraction ~= 0)batch_x = batch_x.*(rand(size(batch_x))>nn.inputZeroMaskedFraction);endbatch_y = train_y(kk((l - 1) * batchsize + 1 : l * batchsize), :);%nnff是进行前向传播,nnbp是后向传播,nnapplygrads是进行梯度下降nn = nnff(nn, batch_x, batch_y);nn = nnbp(nn);nn = nnapplygrads(nn);L(n) = nn.L;n = n + 1;endt = toc;if opts.validation == 1loss = nneval(nn, loss, train_x, train_y, val_x, val_y);str_perf = sprintf('; Full-batch train mse = %f, val mse = %f', loss.train.e(end), loss.val.e(end));elseloss = nneval(nn, loss, train_x, train_y);str_perf = sprintf('; Full-batch train err = %f', loss.train.e(end));endif ishandle(fhandle)nnupdatefigures(nn, fhandle, loss, opts, i);enddisp(['epoch ' num2str(i) '/' num2str(opts.numepochs) '. Took ' num2str(t) ' seconds' '. Mini-batch mean squared error on training set is ' num2str(mean(L((n-numbatches):(n-1)))) str_perf]);nn.learningRate = nn.learningRate * nn.scaling_learningRate;
end
end
首先nntrain的作用是训练神经网络,输出最终的网络参数:updated activations,errors, weights and biases, (nn.a, nn.e, nn.W, nn.b)和训练误差L: the sum squared error for each training minibatch.
4. nnff
function nn = nnff(nn, x, y)
%NNFF performs a feedforward pass
% nn = nnff(nn, x, y) returns an neural network structure with updated
% layer activations, error and loss (nn.a, nn.e and nn.L)n = nn.n;m = size(x, 1);x = [ones(m,1) x];nn.a{1} = x;%feedforward passfor i = 2 : n-1switch nn.activation_function case 'sigm'% Calculate the unit's outputs (including the bias term)nn.a{i} = sigm(nn.a{i - 1} * nn.W{i - 1}');case 'tanh_opt'nn.a{i} = tanh_opt(nn.a{i - 1} * nn.W{i - 1}');end%dropoutif(nn.dropoutFraction > 0)if(nn.testing)nn.a{i} = nn.a{i}.*(1 - nn.dropoutFraction);elsenn.dropOutMask{i} = (rand(size(nn.a{i}))>nn.dropoutFraction);nn.a{i} = nn.a{i}.*nn.dropOutMask{i};endend%calculate running exponential activations for use with sparsity%计算sparsity,nonSparsityPenalty 是对没达到sparsitytarget的参数的惩罚系数 if(nn.nonSparsityPenalty>0)nn.p{i} = 0.99 * nn.p{i} + 0.01 * mean(nn.a{i}, 1);end%Add the bias termnn.a{i} = [ones(m,1) nn.a{i}];endswitch nn.output case 'sigm'nn.a{n} = sigm(nn.a{n - 1} * nn.W{n - 1}');case 'linear'nn.a{n} = nn.a{n - 1} * nn.W{n - 1}';case 'softmax'nn.a{n} = nn.a{n - 1} * nn.W{n - 1}';nn.a{n} = exp(bsxfun(@minus, nn.a{n}, max(nn.a{n},[],2)));nn.a{n} = bsxfun(@rdivide, nn.a{n}, sum(nn.a{n}, 2)); end%error and lossnn.e = y - nn.a{n};switch nn.outputcase {'sigm', 'linear'}nn.L = 1/2 * sum(sum(nn.e .^ 2)) / m; case 'softmax'nn.L = -sum(sum(y .* log(nn.a{n}))) / m;end
end
其中x = [ones(m,1) x];是将输入数据扩大一维,这样更加容易计算偏置。 x*W + b = [x,1]*(W,b)'
nn.a{i} = nn.a{i}.*nn.dropOutMask{i};
5.nnbp
function nn = nnbp(nn)
%NNBP performs backpropagation
% nn = nnbp(nn) returns an neural network structure with updated weights n = nn.n;sparsityError = 0;switch nn.outputcase 'sigm'd{n} = - nn.e .* (nn.a{n} .* (1 - nn.a{n}));case {'softmax','linear'}d{n} = - nn.e;endfor i = (n - 1) : -1 : 2% Derivative of the activation functionswitch nn.activation_function case 'sigm'd_act = nn.a{i} .* (1 - nn.a{i});case 'tanh_opt'd_act = 1.7159 * 2/3 * (1 - 1/(1.7159)^2 * nn.a{i}.^2);endif(nn.nonSparsityPenalty>0)pi = repmat(nn.p{i}, size(nn.a{i}, 1), 1);sparsityError = [zeros(size(nn.a{i},1),1) nn.nonSparsityPenalty * (-nn.sparsityTarget ./ pi + (1 - nn.sparsityTarget) ./ (1 - pi))];end% Backpropagate first derivativesif i+1==n % in this case in d{n} there is not the bias term to be removed d{i} = (d{i + 1} * nn.W{i} + sparsityError) .* d_act; % Bishop (5.56)else % in this case in d{i} the bias term has to be removedd{i} = (d{i + 1}(:,2:end) * nn.W{i} + sparsityError) .* d_act;endif(nn.dropoutFraction>0)d{i} = d{i} .* [ones(size(d{i},1),1) nn.dropOutMask{i}];endendfor i = 1 : (n - 1)if i+1==nnn.dW{i} = (d{i + 1}' * nn.a{i}) / size(d{i + 1}, 1);elsenn.dW{i} = (d{i + 1}(:,2:end)' * nn.a{i}) / size(d{i + 1}, 1); endend
end
注意这里面加入了dropout和sparisty部分。
6. nnapplygrads
function nn = nnapplygrads(nn)
%NNAPPLYGRADS updates weights and biases with calculated gradients
% nn = nnapplygrads(nn) returns an neural network structure with updated
% weights and biasesfor i = 1 : (nn.n - 1)if(nn.weightPenaltyL2>0)dW = nn.dW{i} + nn.weightPenaltyL2 * [zeros(size(nn.W{i},1),1) nn.W{i}(:,2:end)];elsedW = nn.dW{i};enddW = nn.learningRate * dW;if(nn.momentum>0)nn.vW{i} = nn.momentum*nn.vW{i} + dW;dW = nn.vW{i};endnn.W{i} = nn.W{i} - dW;end
end
这里的weightPenaltyL2 就是weight decay项,是对网络权重W稀疏性的惩罚
7. nntest
function [er, bad] = nntest(nn, x, y)labels = nnpredict(nn, x);[dummy, expected] = max(y,[],2);bad = find(labels ~= expected); er = numel(bad) / size(x, 1);
end
调用nnpredict来进行预测,得到预测的lables,与ground truth进行比较,得到erro.
DeepLearningToolBox学习——NN(neural network)相关推荐
- 非常详细的讲解让你深刻理解神经网络NN(neural network)
作者:RayChiu_Labloy 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处 目录 什么是神经网络NN.人工神经网络ANN 神经元(神经网络的基本单元) 概念详解 ...
- 深度学习:Neural Network Layers Understanding
我想做又应该做的事,都会做到:我想做却不应做的事,都会戒掉. Inner Product Layer Inner Product Layer即全连接层,对于IP层的理解,可以简单的将其视为矩阵1*N和 ...
- 论文学习15-Table Filling Multi-Task Recurrent Neural Network(联合实体关系抽取模型)
文章目录 abstract 1 introduction 2.方 法 2.1实体关系表(Figure-2) 2.2 The Table Filling Multi-Task RNN Model 2.3 ...
- GNN金融应用之Classifying and Understanding Financial Data Using Graph Neural Network学习笔记
Classifying and Understanding Financial Data Using Graph Neural Network 摘要 1. 概述 2. 数据表示-加权图 3. GNN利 ...
- 深度学习笔记(四)——循环神经网络(Recurrent Neural Network, RNN)
目录 一.RNN简介 (一).简介 (二).RNN处理任务示例--以NER为例 二.模型提出 (一).基本RNN结构 (二).RNN展开结构 三.RNN的结构变化 (一).N to N结构RNN模型 ...
- 动图+独家思维导图!让你秒懂李宏毅2020深度学习(四)—— CNN(Convolutional Neural network)
动图+独家思维导图!让你秒懂李宏毅2020深度学习(四)-- CNN(Convolutional Neural network) 系列文章传送门: 文章目录 动图+独家思维导图!让你秒懂李宏毅2020 ...
- keras构建前馈神经网络(feedforward neural network)进行多分类模型训练学习
keras构建前馈神经网络(feedforward neural network)进行多分类模型训练学习 前馈神经网络(feedforward neural network)是一种最简单的神经网络,各 ...
- keras构建前馈神经网络(feedforward neural network)进行回归模型构建和学习
keras构建前馈神经网络(feedforward neural network)进行回归模型构建和学习 我们不必在"回归"一词上费太多脑筋.英国著名统计学家弗朗西斯·高尔顿(Fr ...
- 【面向代码】学习 Deep Learning Convolution Neural Network(CNN)
转载自: [面向代码]学习 Deep Learning(三)Convolution Neural Network(CNN) - DarkScope从这里开始 - 博客频道 - CSDN.NET htt ...
最新文章
- 图像迁移风格保存模型_CV之NS:图像风格迁移(Neural Style 图像风格变换)算法简介、关键步骤配图、案例应用...
- 2018 年中国科学院大学生数学夏令营试题
- C# 关于调用微信接口的代码
- javascript之数组操作
- python爬虫数据可视化软件_python爬虫及数据可视化分析
- 国际站 RDS MySQL 5.7 高可用版发布
- 利用输入输出流及文件类编写一个程序,可以实现在屏幕显示文本文件的功能,类似DOS命令中的type命令
- mysql分组查询n条记录
- 在CMakeLists.txt文件中包含Eigen
- ROS采坑日记(3)----在ROS下 编译ORB_SLAM2时遇到问题:[rosbuild] rospack found package ORB_SLAM2 at ........
- %%%%%%%%123564
- 【图像提取】基于matlab形态学矩阵块+线段提取【含Matlab源码 1014期】
- Android源码参考
- iphone申请AppleID后无法登陆App Store
- 其实我(微笑哥)是个正经男人!
- android 表情工厂,表情工厂安卓版
- linux修改默认22端口失败,【原创文章】修改亚马逊AWS EC2 LINUX系统SSH默认22端口失败的原因和解决办法...
- 创建bbs mysql语句怎么写_MySQL常用语句 | 小灰灰博客
- Python学习笔记---------廖雪峰(基础和函数)
- 第11周 oj for循环画三角形