深度学习:Neural Network Layers Understanding
我想做又应该做的事,都会做到;我想做却不应做的事,都会戒掉。
Inner Product Layer
Inner Product Layer即全连接层,对于IP层的理解,可以简单的将其视为矩阵1*N和矩阵N*M相乘后得到1*M的维度向量。
举个简单的例子,比如输入全连接层的是一个3*56*56维度的数据,假设未知的权重维度为N*M,假设全连接层的输出为num_ouput = 4096,为了计算全连接层的输出,全连接层会将输入的数据3*56*56 reshape 成为1*N的形式,即1x(56x56x3) = 1x9408,所以:
N = 9408
M = num_ouput = 4096
由此,我们做了一个(1x9408)矩阵和(9408x4096)矩阵的乘法。如果num_output的值改变成为100,则做的是一个(1x9408)矩阵和(9408x100)矩阵的乘法。Inner Product layer(常被称为全连接层)将输入视为一个vector,输出也是一个vector(height和width被设为1)。下面是IP层的示意图
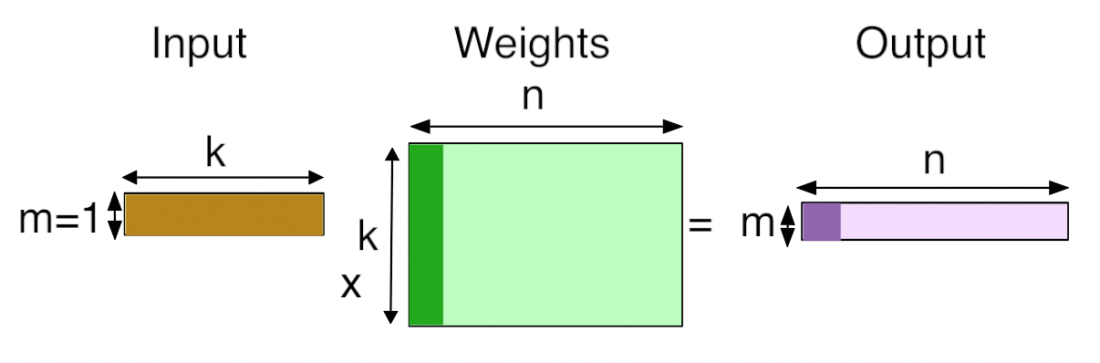
图片摘自Why GEMM is at the heart of deep learning
增大num_output会使得模型需要学习的权重参数增加。IP层一个典型的例子:
layer {name: "ip1"type: "InnerProduct"bottom: "pool2"top: "ip1"# learning rate and decay multipliers for the weightsparam {lr_mult: 1}# learning rate and decay multipliers for the biasesparam {lr_mult: 2}inner_product_param {num_output: 500weight_filler {type: "xavier"}bias_filler {type: "constant"}}
}
有了上面对IP层的理解,对caffe inner_product_layer.cpp中Forward的理解就比较自然了。下面是Caffe的IP层在CPU上的实现:
template <typename Dtype>
void InnerProductLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,const vector<Blob<Dtype>*>& top) {const Dtype* bottom_data = bottom[0]->cpu_data();Dtype* top_data = top[0]->mutable_cpu_data();const Dtype* weight = this->blobs_[0]->cpu_data();caffe_cpu_gemm<Dtype>(CblasNoTrans, transpose_ ? CblasNoTrans : CblasTrans,M_, N_, K_, (Dtype)1.,bottom_data, weight, (Dtype)0., top_data);if (bias_term_) {caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, N_, 1, (Dtype)1.,bias_multiplier_.cpu_data(),this->blobs_[1]->cpu_data(), (Dtype)1., top_data);}
}
上面完成矩阵与矩阵相乘的函数是caffe_cpu_gemm<Dtype>(见math_functions.cpp),caffe_cpu_gemm函数矩阵相乘的具体数学表示形式为:
C=alpha∗TransA(A)∗TransB(B)+beta∗CC=alpha∗TransA(A)∗TransB(B)+beta∗C
上式中TransX是对X做的一种矩阵变换,比如转置、共轭等,具体是cblas.h中定义的为枚举类型。在math_functions.cpp中,除了定义矩阵与矩阵相乘的caffe_cpu_gemm外,还定义了矩阵与向量的相乘,具体的函数为caffe_cpu_gemv,其数学表示形式为:
C=alpha∗TransA(A)∗y+beta∗yC=alpha∗TransA(A)∗y+beta∗y
上面表达式中,y是向量,不是标量。
参考
- Why GEMM is at the heart of deep learning
- What is the output of fully connected layer in CNN?
- caffe_cpu_gemm函数
- Caffe学习:Layers
- Caffe Layers
GEMM
在上面的IP层中,我们已经涉及到了GEMM的知识,在这一小节里面,不妨对该知识点做一个延伸。
GEMM是BLAS (Basic Linear Algebra Subprograms)库的一部分,该库在1979年首次创建。为什么GEMM在深度学习中如此重要呢?我们可以先来看一个图:
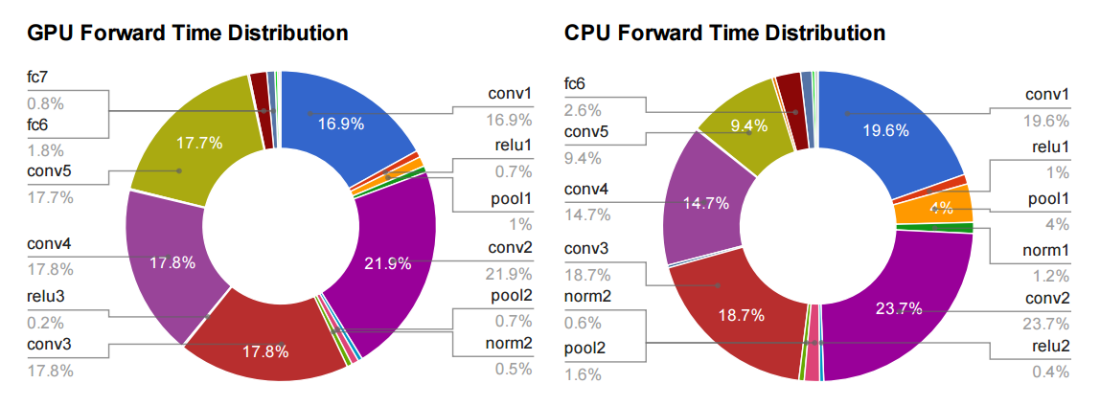
图片摘自Yangqing Jia的thesis
上图是采用AlexNet对CNN网络中不同layer GPU和CPU的时间消耗,从更底层的实现可以看到CNN网络的主要时间消耗用在了FC (for fully-connected)和Conv (for convolution),而FC和Conv在实现上都将其转为了矩阵相乘的形式。举个例子:
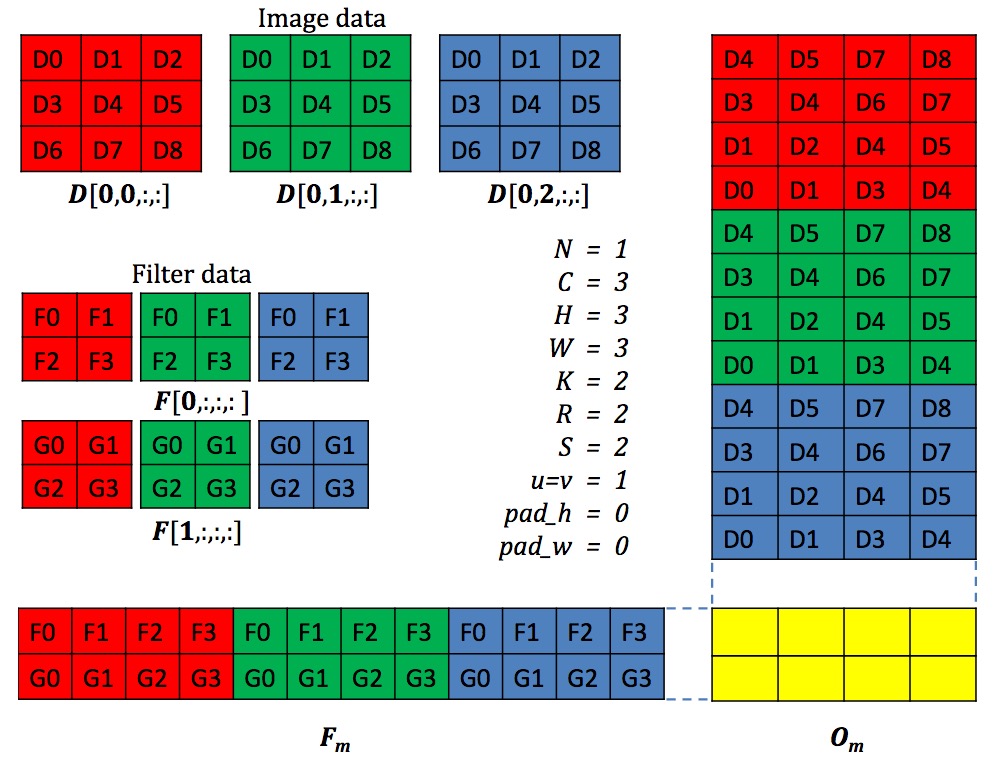
图片摘自cuDNN: Efficient Primitives for Deep Learning
上面Conv在Caffe中具体实现的时候,会将每一个小的patch拉成一个向量,很多patch构成的向量会构成一个大的矩阵,同样的对于多个卷积核展成一个矩阵形式,从而将图像的卷积转成了矩阵与矩阵的相乘(更形象化的解释参阅在 Caffe 中如何计算卷积?)。上面可以看到在FC和Conv上消耗的时间GPU占95%,CPU上占89%。因而GEMM的实现高效与否对于整个网络的效率有很大的影响。
那么什么是GEMM呢?GEMM的全称是GEneral Matrix to Matrix Multiplication,正如其字面意思所表达的,GEMM即表示两个输入矩阵进行相乘,得到一个输出的矩阵。两个矩阵在进行相乘的时候,通常会进行百万次的浮点运算。对于一个典型网络中的某一层,比如一个256 row1152 column的矩阵和一个1152 row192 column的矩阵,二者相乘57 million (256 x 1152 x 192)的浮点运算。因而,通常我们看到的情形是,一个网络在处理一帧的时候,需要几十亿的FLOPs(Floating-point operations per second,每秒浮点计算)。
既然知道了GEMM是限制整个网络时间消耗的主要部分,那么我们是不是可以对GEMM做优化调整呢?答案是否定的,GEMM采用Fortran编程语言实现,经过了科学计算编程人员几十年的优化,性能已经极致,所以很难再去进一步的优化,在Nvidia的论文cuDNN: Efficient Primitives for Deep Learning中指出了还存在着其他的一些方法,但是他们最后采用的还是改进的GEMM版本实现。GEMM可匹敌的对手是傅里叶变换,将卷积转为频域的相乘,但是由于在图像的卷积中存在strides,使得傅里叶变换方式很难保持高效。
from: http://yongyuan.name/blog/neural-network-layers-understanding.html
深度学习:Neural Network Layers Understanding相关推荐
- 第一门课 神经网络和深度学习(Neural Networks and Deep Learning)
第一门课 神经网络和深度学习(Neural Networks and Deep Learning) 文章目录 第一门课 神经网络和深度学习(Neural Networks and Deep Learn ...
- 深度学习 Neural Style 之TensorFlow实践
Neural Style原理 CnnCnnC_{nn} 是一个预先训练好的深度卷积神经网络, XXX 是输入图片. Cnn(X)" role="presentation" ...
- 深度学习-TF函数-layers.concatenate用法 numpy数组维度
环境: tensorfow 2.* def concatenate(inputs, axis=-1, **kwargs): axis=n表示从第n个维度进行拼接,对于一个三维矩阵,axis的取值可以为 ...
- 吴恩达:神经网络和深度学习(Neural Networks and Deep Learning)
文章目录 1.1欢迎 1.2 什么是神经网络 1.3 用神经网络进行监督学习 1.4 为什么深度学习会兴起? 2.1 二分分类 2.2 logistic回归 2.3 logistic回归损失函数 lo ...
- 深度学习 tensorflow tf.layers.conv2d_transpose 反卷积 上采样
参数 conv2d_transpose( inputs, filters, kernel_size, strides=(1, 1), padding='valid', data_format='cha ...
- 深度学习-TF函数-layers.concatenate用法
环境: tensorfow 2.* def concatenate(inputs, axis=-1, **kwargs): axis=n表示从第n个维度进行拼接,对于一个三维矩阵,axis的取值可以为 ...
- 深度学习:tensorflow Layers的实现,numpy实现深度学习(二)
文章目录 基类Layer的实现: 激活层的实现: CostLayer的实现: 基类Layer的实现: 前面已经提到过一个layer的包含:shape,激活函数,梯度的处理以及输出层的处理. impor ...
- 深度学习吴恩达老师(一):神经网络和深度学习(Neural Networks and Deep Learning):内容整理 + 习题分享
- 下载量过百万的吴恩达机器学习和深度学习笔记更新了!(附PDF下载)
今天,我把吴恩达机器学习和深度学习课程笔记都更新了,并提供下载,这两本笔记非常适合机器学习和深度学习入门.(作者:黄海广) 0.导语 我和同学将吴恩达老师机器学习和深度学习课程笔记做成了打印版,放在g ...
最新文章
- Windows Caffe中MNIST数据格式转换实现
- Maven3路程(三)用Maven创建第一个web项目(1)
- 多线程并发:每个开发人员都应了解的内容
- 3维旋转的3种表示方法之间的关系
- 工作project里的Verilog记录
- 深度学习(6)TensorFlow基础操作二: 创建Tensor
- linux 安装svn客户端
- 【hibernate criteria】hibernate中criteria的完整用法 转
- 点在多边形内 java_判断点在多边形内部的方法(Java版)
- c语言CRC16校验(8005)
- rest framework 权限
- android中简单视频播放器demo(附githup下载源码)
- Pseudo Labelling
- flink Flink在监控流计算中的应用
- Skype、MSN/Live Messenger、Lync全面整合
- 【地图导航】3D地图软件是如何做路径规划的?为什么准确率这么高
- flex布局遇到white-space失效问题
- 水晶报表制作6*4cm的打印纸标签,预览时数据是一页,打印出来却多了一页空白?
- 笔记本无法连接WiFi
- 如何接3D模型外包?外包如何报价?高手才能接外包?
热门文章
- 【联邦学习】FATE 集群部署 step3
- 如何在时间紧迫情况下进行机器学习:构建标记的新闻 数据 库 开发 标记 网站 阅读1629 原文:How we built Tagger News: machine learning on a
- 深度研究 | 区块链在征信业的应用探讨:切中了痛点,但也面临四大挑战
- 孙剑亲自撰文:我在 Face++ 的这半年
- Java Review - Queue和Stack 源码解读
- jvm性能调优 - 06线上应用部署JVM实战_堆内存预估与设置
- jvm性能调优 - 02JVM中内存区域
- Linux 文件基本属性
- mysql 编码分层_【平台开发】— 5.后端:代码分层
- linux里hba状态_在Linux/Unix平台查看HBA卡的WWN号 和状态