云HBase内核解析
摘要:在2018年1月25号数据库直播大讲堂上云HBase技术团队郭泽晖带来“云HBase内核”演讲,比如先讲对HBase做了简介,接着云HBase内核解析,并重点介绍了GC优化和更适合随机读的编码格式,分享了两个实战优化案例,还对云HBase 2.0进行了展望。
直播视频:https://yq.aliyun.com/video/play/1333
PPT下载:https://yq.aliyun.com/download/2461
以下为精彩视频内容整理:
1. HBase简介
HBase是提供强一致、面向列的结构化键值存储。它使用普通的磁盘,并且支持多种压缩算法,成本相对较低。而且它本身支持横向扩展,满足千万级QPS的需求。其分布式的存储、可以轻松满足从GB到PB的需求。依托Hadoop生态圈,拥有许多分析工具:Phoenix(二级索引),Spark(机器学习的分析),MapReduce等。
2. 云HBase内核解析
2.1 GC优化
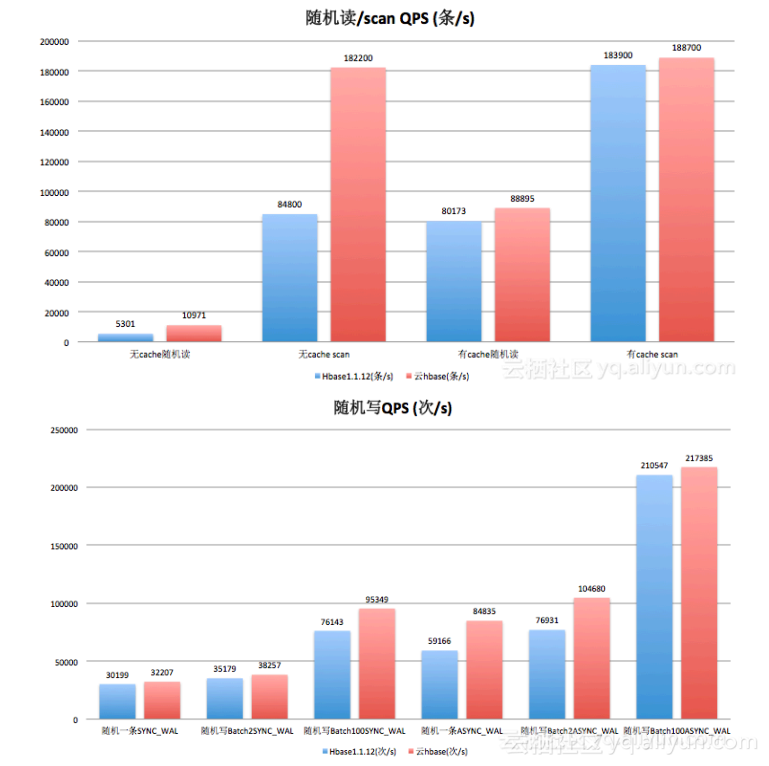
云HBase是基于开源1.1版本发展而来,与阿里内部使用的版本相同,且其经历了双十一严格检验,性能领先开源版本,尤其是在读写方面。
HBase一直以来的存在GC问题。虽然Java简化了编程,提供了内存对象,同时也带来了GC问题,还有延迟问题,但是数据库对延迟高度敏感的。大内存Full GC影响RegionServer服务。情况好时,GC一分钟会或恢复,情况坏时会直接崩溃。针对GC问题,社区已经进行了优化:BucketCache, MemStoreChunkPool。
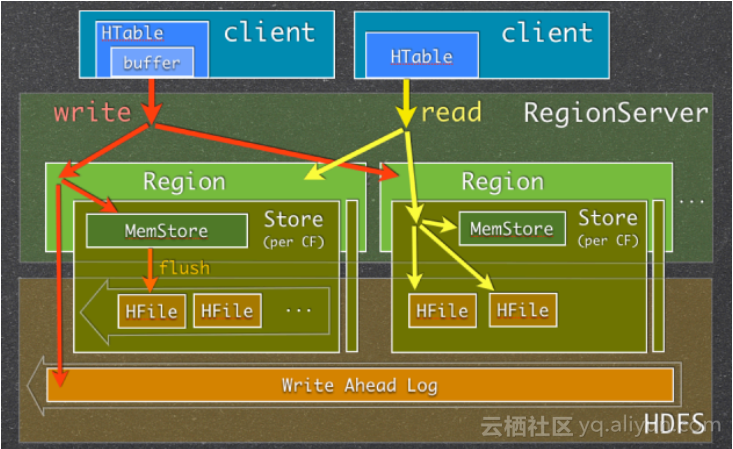
其中MemStoreChunkPool是一个写缓存,当数据写到region里面之后,每个region里面都会有若干个MemStore。当通过客户端把数据写入到region里面时,会先在MemStore写一份。以后在查询的时候,直接从文件中读取,而是先在MemStore读取,这也是HBase保持强一致性的地方。当条件满足的时候,MemStore的数据才会异步写入到磁盘,形成HFile。这就是数据在MemStore的生命周期。
云HBase基于社区已有的BucketCache、 MemStoreChunkPool做了细节的优化,使得云HBase内核优化后:YGC延迟降低50%~70%,吞吐提升20%~30%,几乎不会发生Full GC问题。
MemStoreChunkPool利用了ChunkPool。ChunkPool本质上管理着非常多的Chunk,每个Chunk为2M左右的连续内存。如果不使用ChunkPool,由于数据的本身不规则的,当数据从堆上释放的时候,会产生很多碎片。为了消除这些碎片,写入数据的时候,会申请一个Chunk,数据会写在Chunk,让Chunk来管理这些不规则的数据。MemStoreChunkPool是在ChunkPool上面提出来的,因为在写比较快的时候,会生成很多的Chunk,会给GC造成压力。MemStoreChunkPool在内存中保留一些不释放的Chunk。
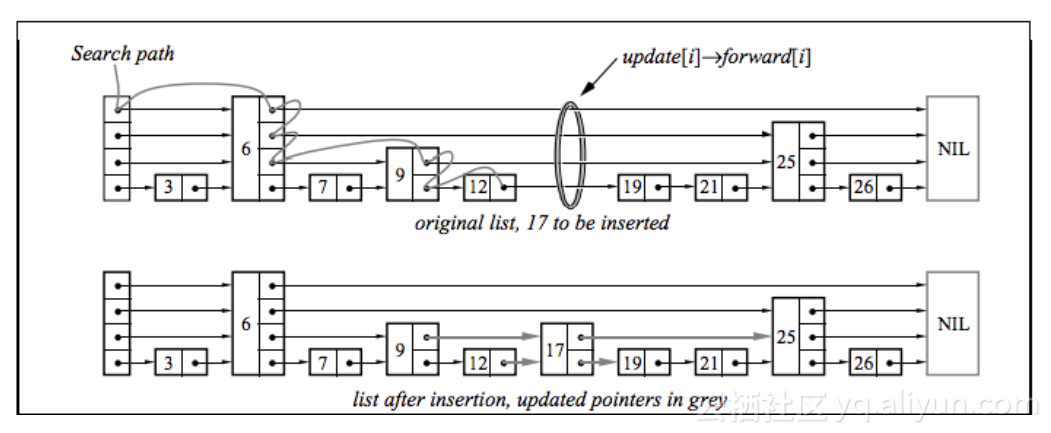
原生的MemStore是用跳跃链表来维护的,其插入复杂度为 O(logn)、查询复杂度为 O(logn)。是基于ConcurrentSkipListMap来实现key-value的维护。选择跳跃链表而不是其他树结构(其复杂度也是O(logn)),是因为从代码上看跳跃链的常数更低,不做插入后做节点的调整和旋转,实际的时间复杂度比其他数据结构要低。
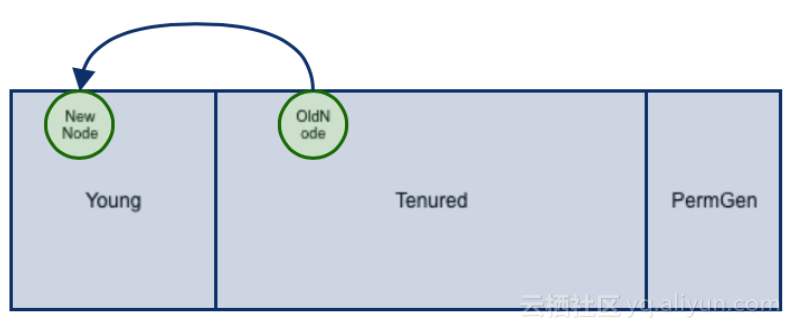
但是基于ConcurrentSkipListMap的MemStore也存在一些问题:数据会在内存中存在一些时间,之前插入的节点会变为年老代,年轻代节点与年老代节点之间存在引用关系,这个引用关系会导致在最年轻代GC的时候,需要扫描年老代。这对年轻代的YGC来说并不友好。而且对象本身占用内存空间以及空间申请过程,都非常零碎。当对象多的时候会产生很多的碎片,当内存过大对内存的开销也非常大。当数据规模不断增大和不断插对象,就会不断产生新索引,要维护的SkipList索引对象就越多,索引数量近O(2n)。
2.2高度聚合的memstore
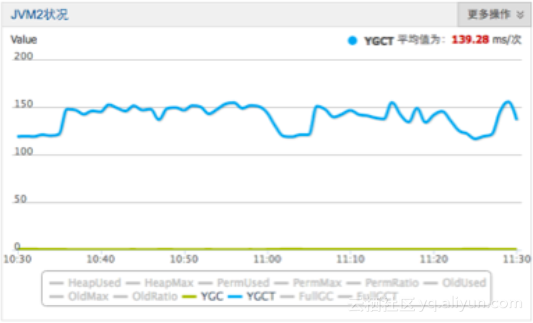
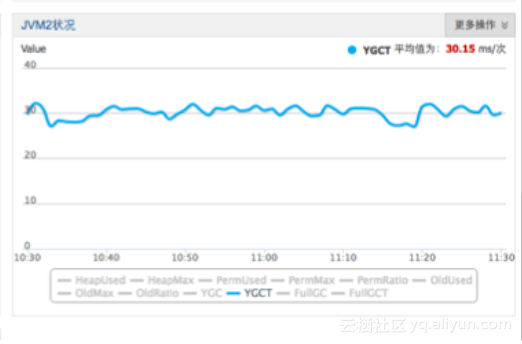
云HBase的MemStore是索引对象和数据内存空间高度聚合,使得CPU缓存效率高,无碎片对GC友好,可以避免Full GC。云HBase比之前的MemStore节约内存近40%,吞吐提升20%~30%,YGC时间减少70%以上。
云HBase的MemStore是基于数组来实现SkipList。每次申请连续的Chunk内存(即1个Chunk默认2M)。云HBase会管理Chunk,本质是字节数组。因为使用JDK的SkipList会产生很多的index对象,这些对象会有对象头的开销,而数组本身是只有一个对象,会大大减少对象的数量,并且将索引和数据是放在连续的Chunk里面,其数据紧凑程度会比JDK的SkipList使用率高,测试的吞吐也比较好
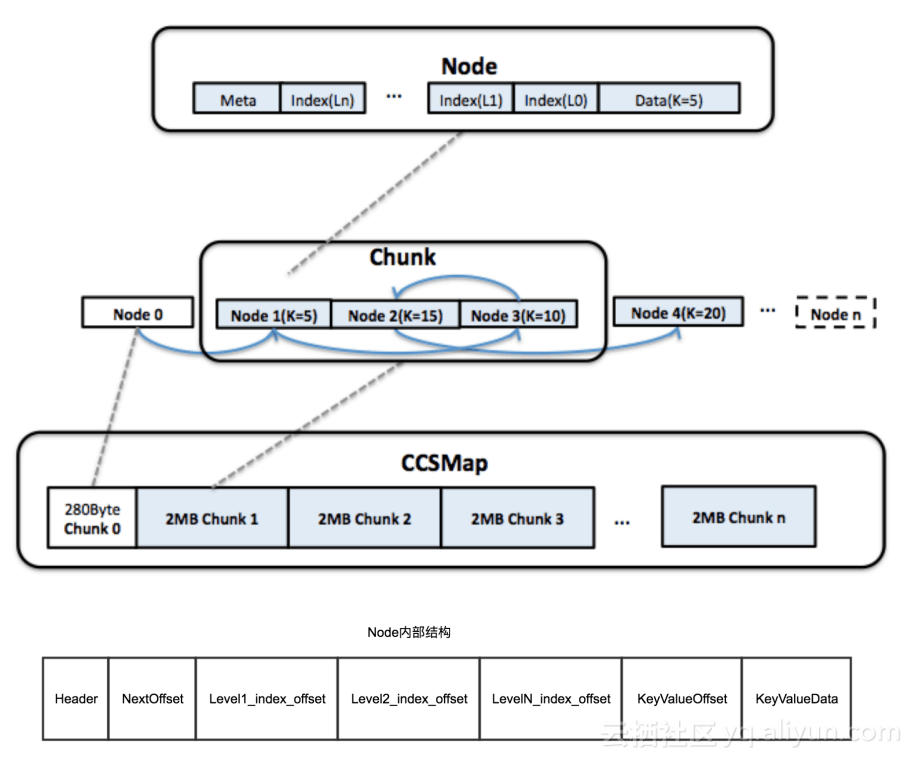
上面是跳跃链表的结构, 其Chunk是连续的。Chunk上面存储着节点信息,指针的信息,key-value的信息、level的信息,这些信息最后相互关联起来,形成了跳跃链表。在实现的时候,为了降低内存和减少GC,一些信息被压缩在若干个bit内,比如Level信息被压缩在5个bit内,存放于header中。其中每个Node内存结构都是相同的,第一个是Header,占用8个字节的数组长度,NextOffet是解析后一个具体的位置,指向下一个Chunk。
跳跃链表使用的链表,其中链表一般有两种选择,arealist和linklist,这取决于元素的数量,如果元素的数量比较大,也知道数量范围,这时候,选择arealist。原理根SkipList一样,Arealist底层只有一个数组,linklist则会产生非常多的节点,这对内存是很大的开销。
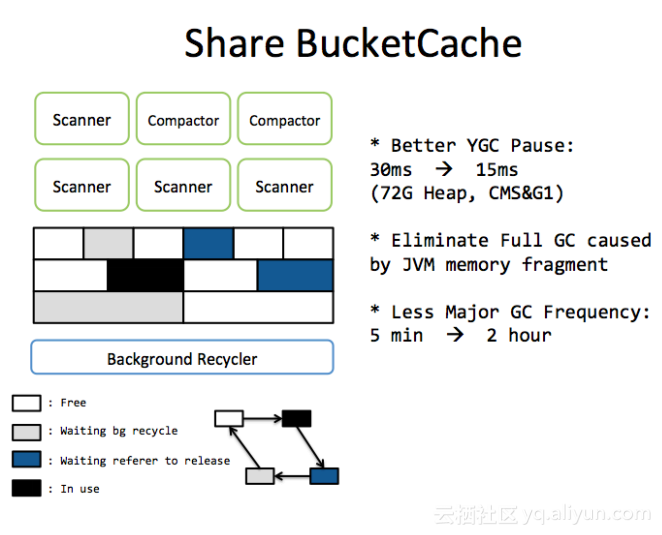
bucket cache是一个读缓存,它跟前面的MemStoreChunkPool非常类似。它先申请bucket(默认为2M),当把Block从文件中读出来的时候,会选择一个合适的bucket进行存放,每个bucket有一个size的标签,决定它能放多大的Block。之前的bucket cache存在一个问题,当有多个线程和有多个用户,访问一个数据块的时候,会把Block从 bucket cache拷贝到栈上面。这样会带来额外的拷贝开销,释放内存的时候,会带来GC的问题。为了解决这个问题,参考C++的智能指针的实现,基于引用计数实现Block的智能指针,实现Block管理。使用bucket cache之后,会减少一半的YGC时间。这也是线上不会出现full GC的重要原因。
2.3更适合随机读的编码格式
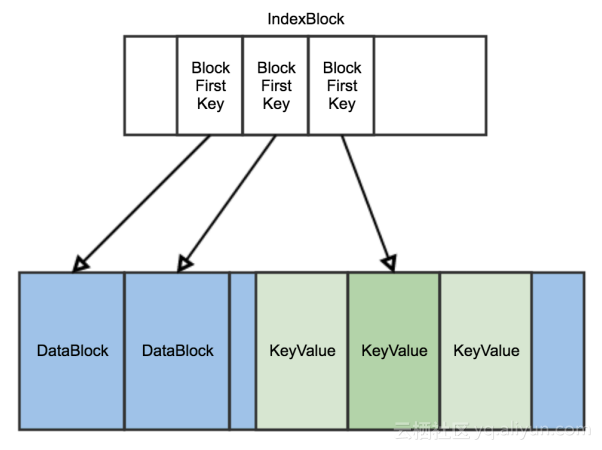
HFile层面数据查询定位过程:根据索引记录nextoffset,通过二分索引可以定位某行某列数据在哪个DataBlock中。seek后读取DataBlock,并对DataBlock进行解码,从头扫描Block获取指KeyValue数据。扫描过程中不断解码。一般使用DataBlock编码格式DIFF来节约空间。
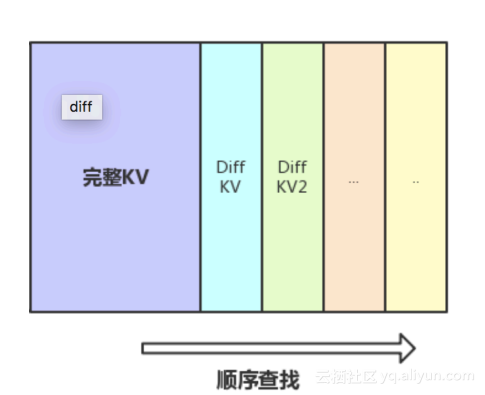
使用DIFF编码的好处是:利用和前一个KeyValue公共前缀压缩空间,利用压缩int节约空间。根据不同场景可以节约2-5倍空间。但是DIFF也存在一些问题:(1)DataBlock需要顺序,不断解码才能找到KeyValue。因为DIFF是利用DataBlock的前一个key-value,公共前缀去压缩空间,也就意味着,如果要在DataBlock查找一个key-value,必须要不断地从头开始扫描。(2)从头开始顺序扫Block会成为随机读瓶颈。
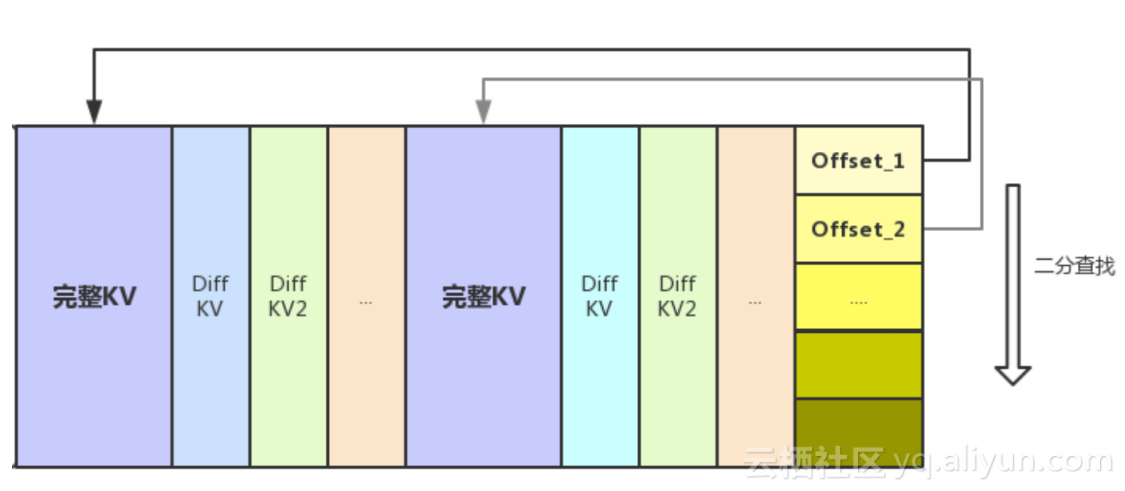
云HBase Indexable Delta编码是基于DIFF编码做出了改进:隔一段距离设置完整的key-value。通过offset信息在完整key-value中二分。从最近的完整key-value开始解码。这样会跳过大量的数据,读延迟减少10%-15%,存储开销仅增加3%-5%。
3. 客户实战优化案例分享
3.1读写分离降延迟
客户为杭州某公司,其嫌99.9%延迟太高,业务不能接受。通过了解发现,客户会定期持续导入数据,对读延迟要求99.9%的延迟要在40ms内。监控显示99.9%延迟很稳定,与客户业务上监控到的99.9%延迟差距较大,且发现请求有排队现象,考虑写入请求阻塞了读请求。
定时的写请求,影响了服务质量。所以建议用户调整一下读写分离。在用户侧业务监控99.9%延迟,发现调整后将时间从90ms降到了40ms,提高了一倍以上。
3.2压缩&编码降低存储成本
客户Soul公司嫌存储成本过高。通过分析发现用户的所有表都没有开启压缩,用的是无编码模式。通过建议用户使用SNAPPY压缩和DIFF编码后(使用DIFF会节省3-5倍的空间)。这两个组合起来编码之后,空间降为原来的1/7,大大节省了使用成本。
4. 云HBase 2.0展望

HBase 2.0提供更稳定更快的分布式数据库服务,对稳定性做了很大的改善,这对云上的场景来说比较重要。因为云上的用户对自动化要求很高,如果代码有1%的问题,那么每100个用户里面就需要处理一个用户的问题,随着客户的增加,那么就会应对不过来。原来的RIT经常会卡住,只能重启才能解决问题,主要因为是region的状态是没有统一管理,比较复杂。HBase 2.0是在master上面管理region,解决了RIT问题。
HBase 2.0只有一个region,这样如果维护region的那台region server挂掉之后,会有一段时间是不可服务。现在提供了region副本,如果一个region挂了,可以从备份中去读。通过牺牲一些可读性,来换取强一致性。
如果对可靠性要求比较高,比如99.99%,那么可以在HBase 2.0上面开启这样的功能,但是这样要耗费更多的资源,因为region会有很多,而且同一个region有多个副本,这样region的数量会非常大。
in memory compaction这个功能是减少写放大,这个功能是在内存中先压缩一部分,避免了把文件从HBase上面拉出来,再压缩,再写回去的过程。
本文由云栖志愿小组王朝阳整理,百见编辑。
云HBase内核解析相关推荐
- hbase 客户端_全网最细致的 HBase 内核解析
最近在网上看到一篇很好的讲 HBase 架构的文章(原文:https://mapr.com/blog/in-depth-look-hbase-architecture/),简洁明了,图文并茂,所以这里 ...
- hbase客户端_好文推荐:全网最细致的 HBase 内核解析
作者:hyuan 文章转自:大数据手稿笔记 最近在网上看到一篇很好的讲 HBase 架构的文章(原文:https://mapr.com/blog/in-depth-look-hbase-archite ...
- 阿里云HBase增强版全文索引功能技术解析
新用户9.9元即可使用6个月云数据库HBase,更有低至1元包年的入门规格供广大HBase爱好者学习研究,更多内容请参考链接 阿里云HBase增强版(Lindorm)简介 阿里云数据库HBase增强版 ...
- 车纷享:基于阿里云HBase构建车联网平台实践
摘要: 1. 业务介绍 车纷享是国内首家进行汽车共享开发和运营的公司.旗下共享汽车平台采用新能源汽车作为运营工具以B2C+C2C汽车共享作为商业运营模式采用车联网技术作为运营管理技术目前已与国内多个城 ...
- 云HBase发布全文索引服务,轻松应对复杂查询
云HBase发布了"全文索引服务"功能,自2019年01月25日后创建的云HBase实例,可以在控制台免费开启此"全文索引服务"功能.使用此功能可以让用户在HB ...
- 阿里云HBase全新发布X-Pack NoSQL数据库再上新台阶
一.八年双十一,造就国内最大最专业HBase技术团队 阿里巴巴集团早在2010开始研究并把HBase投入生产环境使用,从最初的淘宝历史交易记录,到蚂蚁安全风控数据存储.持续8年的投入,历经8年双十一锻 ...
- 赋能云HBase备份恢复 百T级别数据量备份恢复支持
云HBase发布备份恢复功能,为用户数据保驾护航.对大多数公司来说数据的安全性以及可靠性是非常重要的,如何保障数据的安全以及数据的可靠是大多数数据库必须考虑的.2016 IDC的报告表示数据的备份 ...
- 阿里云HBase推出全新X-Pack服务 定义HBase云服务新标准
2018年12月13日,第八届中国云计算标准和应用大会在京召开,会上阿里云HBase宣布推出全新X-Pack服务,支持SQL.时序.时空.图.全文检索能力.复杂分析,从处理到分析全栈式数据库,客户开箱 ...
- 阿里云HBase全新发布X-Pack NoSQL数据库再上新台阶 1
一.八年双十一,造就国内最大最专业HBase技术团队 阿里巴巴集团早在2010开始研究并把HBase投入生产环境使用,从最初的淘宝历史交易记录,到蚂蚁安全风控数据存储.持续8年的投入,历经8年双十一锻 ...
最新文章
- Mysql共享锁实例_mysql共享锁与排他锁用法实例分析
- [NOIP2006] 提高组 洛谷P1066 2^k进制数
- 因为阿里,他们成了“杭漂”
- Windows Server 2008终端服务详解系列5:用ISA 发布SH-TSG
- 如何在Ubuntu上创建桌面快捷方式
- Bootstrap翻页组件
- 6a标准 api_机油最新最高标准来了!SN不再是最高标准!车主不要加错机油了!...
- 又真香了!到底是怎样的软件测试面试文档,拿到这么多大厂offer
- 安川机器人io对照表_安川机器人信号
- 路由器配置vlan桥接
- ssm框架的简要介绍
- 这些你曾深信不疑的大众心理学观点,都是谬论!
- Elasticsearch 如何实现相似推荐功能?
- 使用行列式公式求多边形面积
- 利用区块链技术解决科研问题的前景
- Windows系统 电脑系统重装详细图文教程(绝对够详细,看这一篇就够)
- 【有限马尔科夫链状态分解+Kosaraju 算法】基于Kosaraju 算法和可达矩阵的有限马尔科夫链状态分解
- 压力测试工具tsung
- Aseprite常用快捷键大全
- 【P28】极简全分立耳放(22版)