德鲁伊 oltp oltp_内存中OLTP系列–表创建和类型
德鲁伊 oltp oltp
In sequence of the first article of the In-Memory OLTP Series that explained the main pillars, database creation and a briefly overview of the checkpoint files, now we will take a look into the table creation and data types allowed in the In-Memory OLTP feature in SQL Server 2014.
在解释内存OLTP系列的第一篇文章的顺序中,该文章解释了主要Struts,数据库创建以及检查点文件的简要概述,现在我们来看看内存OLTP中允许的表创建和数据类型SQL Server 2014中的功能。
表格创建 ( Table Creation )
Before start to create tables In-Memory is extremely important to understand some key points that will make difference in how you manage these tables in your environment. Remember that the memory-optimized tables resides entirely in memory and there is a limit of 256 GB of RAM.
在开始创建表之前,In-Memory对于了解一些关键点非常重要,这些关键点将在环境中管理这些表的方式上有所不同。 请记住,内存优化表完全位于内存中,并且RAM限制为256 GB。
Rows in the memory-optimized tables are versioned which means that each row can have multiple versions that is maintained in the same table structure, this new capability is called to “multi-version concurrency control (MVCC)”.
内存优化表中的行经过版本控制,这意味着每行可以具有以同一表结构维护的多个版本,此新功能称为“多版本并发控制( MVCC )”。
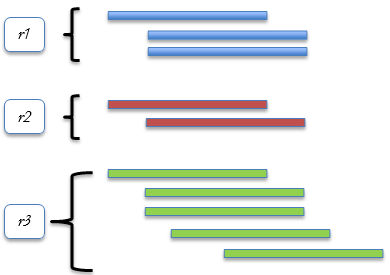
Figure 1. Multi-Version Concurrency Control (MVCC).
图1.多版本并发控制( MVCC )。
The table r1 has 3 versions, r2 has 2 versions & r3 has 5 versions. This versions make the in-memory table structure different than the disk-based tables that is not allowed to storage row version in the same structure of the data pages & extents.
表r1有3个版本,r2有2个版本,r3有5个版本。 此版本使内存中的表结构不同于基于磁盘的表,后者不允许以相同的数据页和扩展区结构存储行版本。
基于磁盘的Vs。 内存表结构 ( Disk-Based Vs. In-Memory Table Structure )
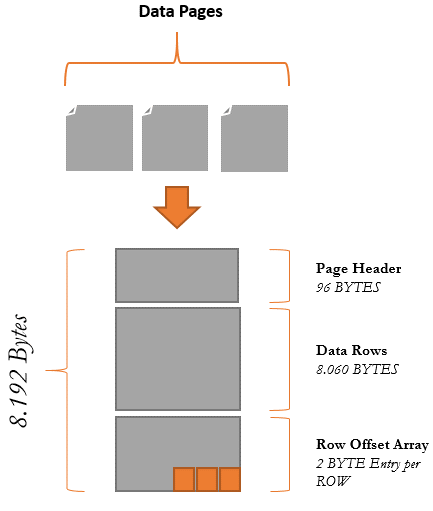
Figure 2. Disk-Based Table Structure.
图2.基于磁盘的表结构。
Page Header
页面标题
The page header occupies 96 BYTES and this piece is responsible to store the header of the data page.
页头占用96个字节 ,该段负责存储数据页的头。
Data Rows
数据行
The data rows occupies 8.060 BYTES and this area is responsible to store the data rows. The number of rows that will be stored in this place depends of the different data types that you have in that table, columns with fixed or non-fixed values will determine the space consumed in the part of the data page.
数据行占8.060个字节 并且该区域负责存储数据行。 将在此位置存储的行数取决于该表中具有的不同数据类型,具有固定值或非固定值的列将确定数据页部分中消耗的空间。
Row Offset Array
行偏移数组
Rows that are added inside of the page has a 2-byte entry in this array. The row offset array have the function to indicate the logical order of the rows in a page that doesn’t means that the rows are ordered conform the physical stored in the disk.
在页面内部添加的行在此数组中有一个2字节的条目。 行偏移量数组具有指示页面中行的逻辑顺序的功能,但这并不意味着行的顺序符合磁盘中存储的物理位置。
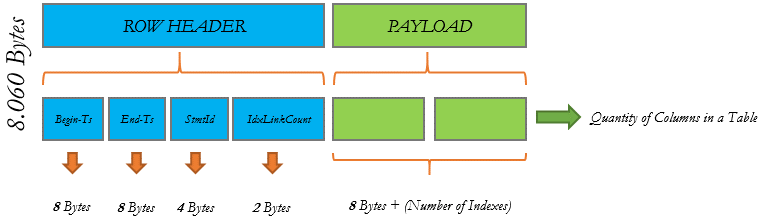
Figure 3. In-Memory Table Structure.
图3.内存中表结构。
Begin-Ts
开始T
Insert timestamp of the row when the COMMIT operation occur.
发生COMMIT操作时,插入行的时间戳。
End-Ts
末端T
Delete timestamp of the row when the COMMIT operation occur.
发生COMMIT操作时,删除行的时间戳。
SmtId
SmtId
Unique number for a transaction used to identify the row that was created.
用于标识已创建行的事务的唯一编号。
IdxLinkCount
IdxLinkCount
Count used to identify the quantity of indexes that are pointing to this row.
用于标识指向该行的索引数量的计数。
比较基于磁盘和内存表的存储方式 ( Comparing Disk-Based & In-Memory Tables Storage Style )
In a Disk-Based Table model, data pages are requested from disk, loaded into the memory and them accessed by the request. The access on disk is one of the most expensive operations that SQLOS (Access Methods Layer) needs to handle because the disk access in the most of the cases are random and also depends of some circumstances to execute the fast read. Statistics, amount of data, fragmentation and disk speed impact directly in how SQL Server will respond and load the data pages into the Buffer Pool area.
在基于磁盘的表模型中,从磁盘请求数据页,将其装入内存,然后由请求访问它们。 磁盘访问是SQLOS(访问方法层)需要处理的最昂贵的操作之一,因为在大多数情况下磁盘访问是随机的,并且还取决于某些情况来执行快速读取。 统计信息,数据量,碎片和磁盘速度直接影响SQL Server如何响应并将数据页加载到“缓冲池”区域。
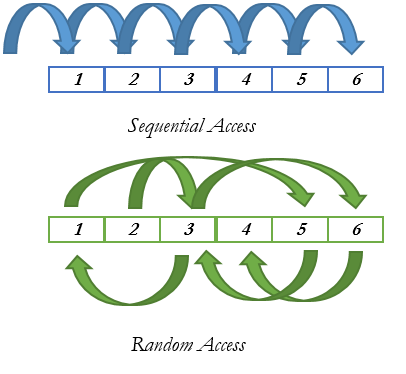
Figure 4. Random & Sequential Access on Disk.
图4.磁盘上的随机和顺序访问。
In an In-Memory Table model, the mindset changes and we start assuming that the data is already loaded into the memory and all the COMMITs operations are written sequentially in the disk in the order of the transaction occurs, this becomes possible because of the Data Files & Delta Files that manages this situation. An INSERT operation safe the transaction in the Data File when a DELETE operation safe the transaction in the Delta Files, this mode all the access on disk becomes sequential making the disk not struggle anymore with the random access. The log record operation had an enhancement too. The in-memory tables save just the COMMIT time phase on the log record and this operation whenever possible tries to group multiple log records into one large I/O accomplishing a faster log insert because the WAL (write-ahead logging) is no longer necessary.
在“内存中表”模型中,思维定式发生了变化,我们开始假设数据已经加载到内存中,并且所有COMMIT操作按照事务发生的顺序顺序写入磁盘中,这可能是由于数据文件和增量文件可以管理这种情况。 INSERT操作使数据文件中的事务安全,而DELETE操作使数据文件中的事务安全,此模式下磁盘上的所有访问都变为顺序访问,从而使磁盘不再为随机访问所困扰。 日志记录操作也有所增强。 内存表仅将COMMIT时间段保存在日志记录上,并且此操作尽可能将多个日志记录分组为一个大型I / O,从而实现了更快的日志插入,因为不再需要WAL(预写日志记录) 。
内存中的表类型 ( Table Types In-Memory )
Creating memory-optimized tables is quiet similar than creating disk-based tables in a database. There are some differences in the index, data types and constraints options that memory-optimized tables can support. To create a memory-optimized table is necessary to add in the table creation phase the MEMORY_OPTIMIZED = ON clause and choose for the durability mode that you desire for memory-optimized table. There are 2 option in the table creation.
创建内存优化表的安静与在数据库中创建基于磁盘的表类似。 内存优化表可以支持的索引,数据类型和约束选项有所不同。 要创建内存优化表,必须在表创建阶段添加MEMORY_OPTIMIZED = ON子句,然后选择所需的持久性模式以进行内存优化表。 表创建中有2个选项。
- SCHEMA_ONLY – Indicates that the schema will be durable but the data is not. These tables do not require any IO operation in the disk subsystem and the data is available only In-Memory, in a SQL Server restart or Server Shutdown the data is lost. SCHEMA_ONLY –指示模式将是持久的,但数据不是持久的。 这些表在磁盘子系统中不需要任何IO操作,并且数据仅在内存中可用,在SQL Server重新启动或服务器关闭中,数据将丢失。
USE inmem_SQLShack goCREATE TABLE [dbo].[inmem_ProductSales] ([ID] [INT] NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 5048),[Name] VARCHAR(50) NOT NULL,[Type] CHAR(2) NOT NULL,[Quantity] INT NOT NULL,[Status] CHAR(2),[UnitPrice] MONEY,[OrderDate] DATETIME) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY) GO - SCHEMA_AND_DATA – Different than the previous model, using this type the schema and the table will be persisted in disk and guarantee that the table will remain available in a SQL Server Restart or Server Shutdown. SCHEMA_AND_DATA –与以前的模型不同,使用此类型,架构和表将保留在磁盘中,并确保该表在SQL Server重新启动或服务器关闭中将保持可用。
USE inmem_SQLShack goCREATE TABLE [dbo].[inmem_InternetSales] ([ID] [INT] NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 5048),[OrderData] DATETIME,[UnitPrice] MONEY,[Discount] MONEY,[UnitPrice] MONEY,[OrderNumber] INT ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA) GO
索引和约束注意事项 ( Indexes & Constraint Considerations )
- All the memory-optimized tables must to have at least one index to connect the rows together because data rows are not stored on pages, this way there is no pages or extents, partitions or allocation units to reference the table.所有内存优化表必须至少具有一个索引才能将各行连接在一起,因为数据行未存储在页面上,因此,没有页面或扩展区,分区或分配单元可以引用该表。
- Together with the memory-optimized tables there is now 2 new index types that will talk more about in the next posts – the hash index and range index.连同内存优化表一起,现在有2种新的索引类型,将在下一篇文章中详细讨论-哈希索引和范围索引。
结论 ( Conclusion )
There are some differences in the models but we can see at this stage that to memory-optimized tables are another way to improve and gain speed. Find the best tables to move is one of the most challenges that you will face as well choose the best indexes in a specific column.
这些模型存在一些差异,但是我们可以在现阶段看到,对内存进行优化的表是提高和提高速度的另一种方法。 找到最佳的表是您将面临的最大挑战之一,并且在特定的列中选择最佳的索引。
In the next article of the series I will explain how to migrate the disk-based tables to memory-optimized tables using the best practices and how to find the best candidates for this process.
在本系列的下一篇文章中,我将解释如何使用最佳实践将基于磁盘的表迁移到内存优化的表,以及如何找到此过程的最佳人选。
翻译自: https://www.sqlshack.com/in-memory-oltp-series-table-creation-types/
德鲁伊 oltp oltp
德鲁伊 oltp oltp_内存中OLTP系列–表创建和类型相关推荐
- 德鲁伊 oltp oltp_内存中OLTP –招待看门狗的三个关键点–检查点文件
德鲁伊 oltp oltp In sequence of the first article about the server memory importance, we will check ano ...
- 德鲁伊 oltp oltp_内存中OLTP –更快变得更简单!
德鲁伊 oltp oltp In-memory OLTP is a revolutionary tool introduced on SQL Server 2014. On SQL Server 20 ...
- 德鲁伊 oltp oltp_内存中OLTP –娱乐看门狗的三个关键点
德鲁伊 oltp oltp With the introduction of the in-memory technology, we need to think about what are the ...
- 德鲁伊 oltp oltp_内存中OLTP系列–简介
德鲁伊 oltp oltp Introduced on SQL Server 2014, the new brand feature In-Memory OLTP a.k.a "Hekato ...
- 德鲁伊 oltp oltp_内存中OLTP –娱乐看门狗的三个关键点–桶数
德鲁伊 oltp oltp When creating a hash index in a memory optimized table we need to define a value for t ...
- sql oltp_内存中的OLTP系列– SQL Server 2014上的数据迁移指南过程
sql oltp In this article we will review migration from disk-based tables to in-memory optimized tabl ...
- sql oltp_SQL Server中的内存中OLTP的快速概述
sql oltp This is in continuation of the previous articles How to monitor internal data structures of ...
- 德鲁伊 oltp oltp_深入研究内存中OLTP表的非聚集索引
德鲁伊 oltp oltp With the introduction of Microsoft's new In-Memory OLTP engine* (code name Hekaton) a ...
- 德鲁伊 oltp oltp_深入研究内存中OLTP表的哈希索引
德鲁伊 oltp oltp With the introduction of Microsoft's new In-Memory OLTP engine (code name Hekaton) the ...
最新文章
- pbewithmd5anddes算法 对应.net_文本相似度算法之-simhash
- 单细胞转录组单飞第二期开课啦!!
- 20145201李子璇 《网络对抗》恶意代码分析
- java:lock锁
- CentOS 7环境安装Docker
- Magento 获取有效属性 Display available options for attributes of Configurable
- 【Big Data - Hadoop - MapReduce】初学Hadoop之图解MapReduce与WordCount示例分析
- 9;XHTML 多媒体
- maya嵌入python_#113 如何给Maya添加一个Python Command Shell ? | 一半君的总结纸
- 对话 “智能+”平台大师,看IBM如何重塑企业数字化
- 三维空间中无人机路径规划的改进型蝙蝠算法
- python+selenium实现QQ空间的登录
- java中的约瑟夫问题_Java 解决约瑟夫问题
- 分式求二阶导数_第12讲 典型例题与练习参考解答:导数的基本运算法则与高阶导数...
- PostScript 打印机打印内存不足错误消息
- 卷积神经网络CNNs详解参考----MNIST
- StringBuffer 拼接字符串时,删除最后一个逗号
- MBT简述:基于模型的测试
- 实时语音通讯的回音消除技术详解
- 长亮科技发布2018年报:营收首破十亿元,直面蚂蚁金服竞争压力