逻辑回归(Logistic Regression, LR)简介
逻辑回归(Logistic Regression, LR)简介
标签(空格分隔): 机器学习
**机器学习最通俗的解释就是让机器学会决策。**对于我们人来说,比如去菜市场里挑选芒果,从一堆芒果中拿出一个,根据果皮颜色、大小、软硬等属性或叫做特征,我们就会知道它甜还是不甜。类似的,机器学习就是把这些属性信息量化后输入计算机模型,从而让机器自动判断一个芒果是甜是酸,这实际上就是一个分类问题。
分类和回归是机器学习可以解决两大主要问题,从预测值的类型上看,连续变量预测的定量输出称为回归;离散变量预测的定性输出称为分类。例如:预测明天多少度,是一个回归任务;预测明天阴、晴、雨,就是一个分类任务。
线性回归(Linear Regression)
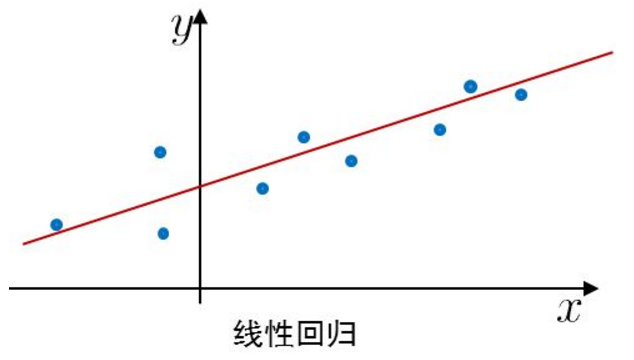
预测函数
在一维特征空间,线性回归是通过学习一条直线hθ(x)=θ0+θ1x1h_\theta(x)=\theta_0+\theta_1x_{1}hθ(x)=θ0+θ1x1,使得这条直线尽可能拟合所有已有的看到的点yyy(观测数据),并希望未看到的数据(测试数据)也尽可能落在这条线上(泛化性能),hθh_\thetahθ是预测值,yyy是实际值。
在多维空间,线性回归表示为hθ(x)=θ0+θ1x1+θ2x2+⋯+θnxnh_\theta(x)=\theta_0+\theta_1x_{1}+\theta_2x_{2}+\cdots+\theta_nx_nhθ(x)=θ0+θ1x1+θ2x2+⋯+θnxn,简化形式为hθ(x)=∑i=0nθixi=θTxh_\theta(x)=\sum^{n}_{i=0}\theta_ix_i=\theta^Txhθ(x)=∑i=0nθixi=θTx,我们的目的,是要找到一个参数θ\thetaθ令hθ(x)h_\theta(x)hθ(x)对数据拟合得最好。
损失函数
那么怎样评价它对于观测到的数据点拟合得好坏呢?所以需要对我们做出的假设hhh进行评估,一般这个函数成为损失函数(loss function)

很直观的想法是希望预测值与实际值尽可能接近,即看预测值与实际值之间的均方误差是否最小,定义线性回归损失函数为
J(θ)=12m∑i=1m(hθ(x(i))−y(i))2J(\theta)=\frac{1}{2m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})^2 J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2
所以现在变成了一个优化问题,即找到要找到令损失函数J(θ)J(\theta)J(θ)最小的θ\thetaθ。定义均方误差有着非常好的几何含义,对应常用的欧式距离(Euclidean distance),基于均方误差最小化进行模型求解的方法称为“最小二乘法”(least square method)。
问:均方误差函数作为损失函数的概率学解释?为什么不用点到直线的距离?
答:这主要是与样本噪声所服从的分布有关。由于假定样本的噪声服从的分布是高斯分布且独立同分布,计算联合概率分布,根据最大似然法则,能推导出要令[(x−μ1)2+(x−μ2)2+⋯][(x-\mu_1)^2+(x-\mu_2)^2+\cdots][(x−μ1)2+(x−μ2)2+⋯]最小,其中xxx表示实际点,μ\muμ表示直线上的理想预测结果,即最小二乘形式,对应实际值到预测值的距离平方。不用点到直线的距离,个人感觉主要还是为了方便计算,因为点到直线距离公式时参数会出现在分母上,不利于求解。
推导细节可参考:在进行线性回归时,为什么最小二乘法是最优方法?
最小二乘法
最小二乘法是一种完全数学描述的方法,用矩阵表示J(θ)=12(Xθ−Y)2J(\theta)=\frac{1}{2}(X\theta-Y)^2J(θ)=21(Xθ−Y)2,展开并对其求偏导,令偏导∂∂θJ(θ)=0\frac{\partial}{\partial\theta}J(\theta)=0∂θ∂J(θ)=0即可得到所求的θ\thetaθθ=(XTX)−1XTY\theta=(X^TX)^{-1}X^TYθ=(XTX)−1XTY
然而现实任务中当特征数量大于样本数时,XTXX^TXXTX不满秩,此时θ\thetaθ有多个解;而且当数据量大时,求矩阵的逆非常耗时;对于不可逆矩阵(特征之间不相互独立),这种正规方程方法是不能用的。所以,还可以采用梯度下降法,利用迭代的方式求解θ\thetaθ。
梯度下降法
梯度下降法是按下面的流程进行的:
1)首先对θ\thetaθ赋值,这个值可以是随机的,也可以让θ\thetaθ是一个全零的向量。
2)改变θ\thetaθ的值,使得θ\thetaθ按梯度下降的方向进行减少。
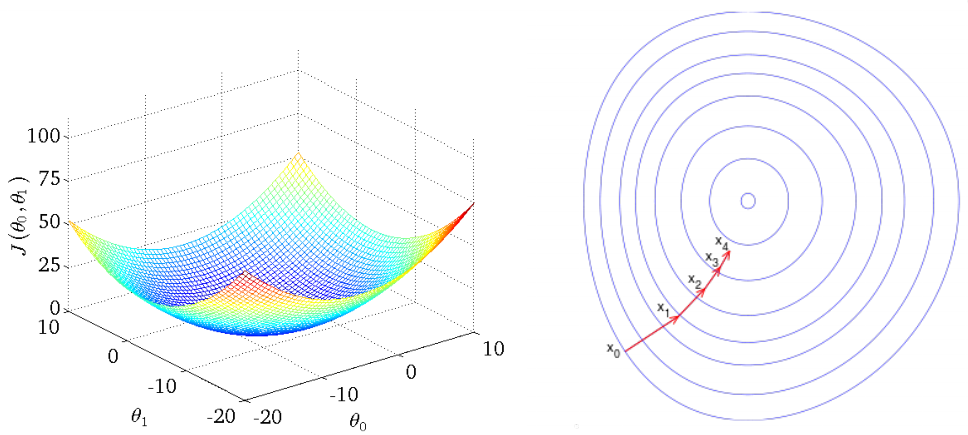
对于只有两维属性的样本,J(θ)J(\theta)J(θ)即J(θ0,θ1)J(\theta_0,\theta_1)J(θ0,θ1)的等高线图
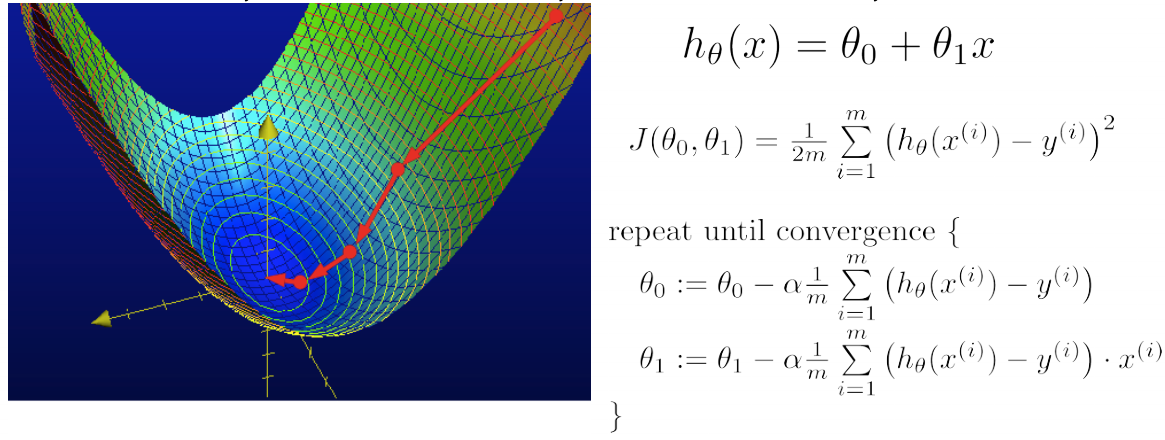
利用梯度下降法,逐步最小化损失函数,找准梯度下降方向,即偏导数的反方向,每次前进一小步,直到收敛
θj:=θj−α∂∂θjJ(θ)=θj−α1m∑i=1m(hθ(x(i))−y(i))xj(i)\theta_j:=\theta_j-\alpha\frac{\partial}{\partial\theta_j}J(\theta)=\theta_j-\alpha\frac{1}{m}\sum^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})x^{(i)}_jθj:=θj−α∂θj∂J(θ)=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i)
迭代更新的方式有多种
- 批量梯度下降(batch gradient descent),也就是是梯度下降法最原始的形式,对全部的训练数据求得误差后再对θ\thetaθ进行更新,优点是每步都趋向全局最优解;缺点是对于大量数据,由于每步要计算整体数据,训练过程慢;
- 随机梯度下降(stochastic gradient descent),每一步随机选择一个样本对θ\thetaθ进行更新,优点是训练速度快;缺点是每次的前进方向不好确定,容易陷入局部最优;
- 微型批量梯度下降(mini-batch gradient descent),每步选择一小批数据进行批量梯度下降更新θ\thetaθ,属于批量梯度下降和随机梯度下降的一种折中,非常适合并行处理。
逻辑回归(Logistic Regression)
逻辑回归由于存在易于实现、解释性好以及容易扩展等优点,被广泛应用于点击率预估(CTR)、计算广告(CA)以及推荐系统(RS)等任务中。逻辑回归虽然名字叫做回归,但实际上却是一种分类学习方法。
线性回归完成的是回归拟合任务,而对于分类任务,我们同样需要一条线,但不是去拟合每个数据点,而是把不同类别的样本区分开来。
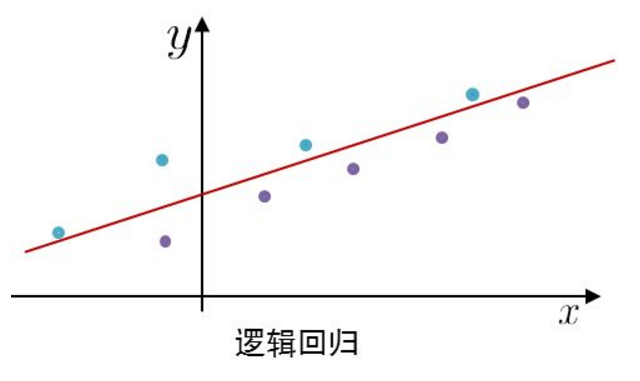
预测函数
对于二分类问题,y∈{0,1}y\in{\{0,1\}}y∈{0,1},1表示正例,0表示负例。逻辑回归是在线性函数θTx\theta^TxθTx输出预测实际值的基础上,寻找一个假设函数函数hθ(x)=g(θTx)h_\theta(x)=g(\theta^Tx)hθ(x)=g(θTx),将实际值映射到到0,1之间,如果hθ(x)>=0.5h_\theta(x)>=0.5hθ(x)>=0.5,则预测y=1y=1y=1,及yyy属于正例;如果hθ(x)<0.5h_\theta(x)<0.5hθ(x)<0.5,则预测y=0y=0y=0,即yyy属于负例。
逻辑回归中选择对数几率函数(logistic function)作为激活函数,对数几率函数是Sigmoid函数(形状为S的函数)的重要代表g(z)=11+e−zg(z)=\frac{1}{1+e^{-z}}g(z)=1+e−z1
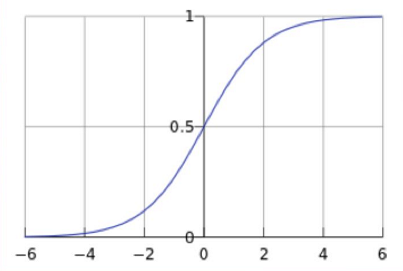
则逻辑回归输出的预测函数数学表达式为
hθ(x)=g(θTx)=11+e−θTxh_\theta(x)=g(\theta^Tx)=\frac{1}{1+e^{-\theta^Tx}}hθ(x)=g(θTx)=1+e−θTx1
其中θ\thetaθ是参数向量。对于hθ(x)h_\theta(x)hθ(x)的直观解释是:对于给定的输入xxx,hθ(x)h_\theta(x)hθ(x)表示其对应类标y=1y=1y=1即属于正例的概率。
问:为什么逻辑回归又叫对数几率回归?
答:上式可以变化为lnhθ(x)1−hθ(x)=θTx\ln\frac{h_\theta(x)}{1-h_\theta(x)}=\theta^Tx\quadln1−hθ(x)hθ(x)=θTx
hθ(x)h_\theta(x)hθ(x)是xxx属于正例的概率,1−hθ(x)1-h_\theta(x)1−hθ(x)是xxx属于反例的概率,两者比值hθ(x)1−hθ(x)\frac{h_\theta(x)}{1-h_\theta(x)}1−hθ(x)hθ(x)叫做几率(odds),表示了xxx作为正例的相对可能性。取对数就叫做对数几率(log odds,或logit)lnhθ(x)1−hθ(x)\ln\frac{h_\theta(x)}{1-h_\theta(x)}ln1−hθ(x)hθ(x)。
如果说线性回归是对于特征的线性组合来拟合真实标记的话(y=wx+by=wx+by=wx+b),那么逻辑回归是对于特征的线性组合来拟合真实标记为正例的概率的对数几率(lny1−y=wx+b\ln{\frac{y}{1-y}}=wx+bln1−yy=wx+b)
对于输入xxx分类结果为类别1和类别0的概率分别为:P(y=1∣x;θ)=hθ(x)P(y=1|x;\theta)=h_\theta(x)P(y=1∣x;θ)=hθ(x)P(y=0∣x;θ)=1−hθ(x).P(y=0|x;\theta)=1-h_\theta(x).P(y=0∣x;θ)=1−hθ(x).
例如,如果对于给定的xxx,通过已经确定的参数计算得出hθ(x)=0.7h_\theta(x)=0.7hθ(x)=0.7,则表示有70%的几率yyy为正例,相应的yyy为负例的几率为0.30.30.3。
决策面
在逻辑回归中,我们预测:
- 当hθh_\thetahθ大于等于0.5时,预测y=1y=1y=1;
- 当hθh_\thetahθ小于0.5时,预测y=0y=0y=0。
根据上面绘制出的S形函数图像,我们知道:
- z=0z=0z=0时g(z)=0.5g(z)=0.5g(z)=0.5,
- z>0z>0z>0时g(z)>0.5g(z)>0.5g(z)>0.5,
- z<0z<0z<0时g(z)<0.5g(z)<0.5g(z)<0.5。
又z=θTxz=\theta^Txz=θTx,所以
- θTx\theta^TxθTx大于等于0时,预测y=1y=1y=1;
- θTx\theta^TxθTx小于0时,预测y=0y=0y=0。
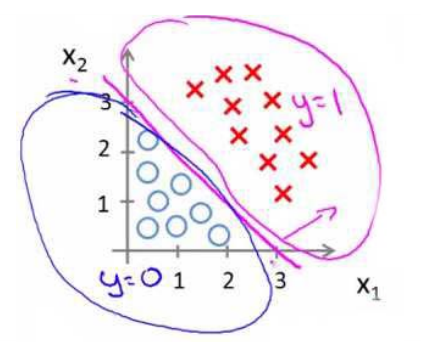
假设我们有一个模型:hθ(x)=g(θ0+θ1x1+θ2x2h_\theta(x)=g(\theta_0+\theta_1x_1+\theta_2x_2hθ(x)=g(θ0+θ1x1+θ2x2并且参数θ\thetaθ是向量[-3 1 1]。
则当−3+x1+x2-3+x_1+x_2−3+x1+x2大于等于0,即x1+x2x_1+x_2x1+x2大于等于3时,模型将预测y=1y=1y=1。
绘制直线x1+x2=3x_1+x_2=3x1+x2=3,便是我们模型的分界线,将预测为1的区域和预测为0的区域分隔开。
损失函数
如何求分类任务的最优解呢?第一个直接的想法是仍然沿用上述的均方误差来表示真实样本与预测值之间的差距$ J(\theta)=\frac{1}{2m}\sum_{i=1}{m}(h_\theta(x{(i)})-y{(i)})2=\frac{1}{2m}\sum_{i=1}{m}(\frac{1}{1+e{-\thetaTx{(i)}-b}}-y{(i)})2$
但这个函数不是凸函数,很难进行优化。
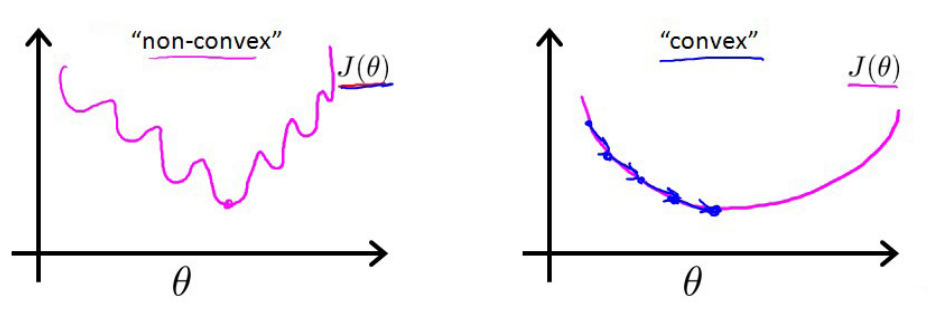
于是我们接着转换思路,既然是分类任务,那么我们可以对于每个类别分别取计算它们各自的损失呀。对于真实标记是1的样本,我们希望预测值越接近于1,损失越小;对于真实标记是0的样本,我们希望预测值越接近于0时损失越小,-log函数正好满足以上情况
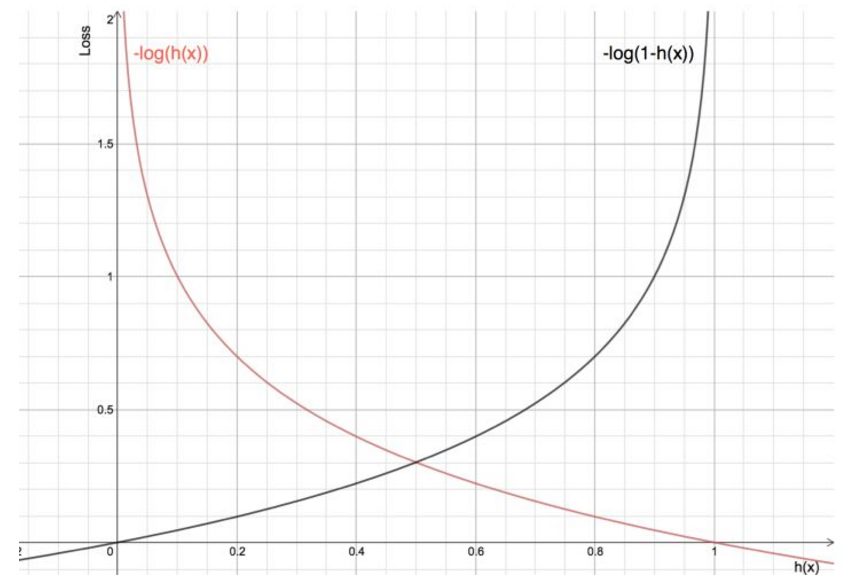
Andrew Ng在课程中直接给出了交叉熵损失CostCostCost函数及数据集全部损失J(θ)J(θ)J(θ)函数,但是并没有给出具体的解释,只是说明了这个函数来衡量hθ(x)h_\theta(x)hθ(x)函数预测的好坏是合理的。
Cost(hθ(x),y)={−log(hθ(x)),if y=1−log(1−hθ(x)),if y=0Cost(h_\theta(x),y)= \begin{cases} -\log(h_\theta(x)), & \text {if $y=1$} \\ -\log(1-h_\theta(x)), & \text {if $y=0$} \end{cases} Cost(hθ(x),y)={−log(hθ(x)),−log(1−hθ(x)),if y=1if y=0
KaTeX parse error: No such environment: split at position 8: \begin{̲s̲p̲l̲i̲t̲}̲ J(\theta) &= \…
问:为什么定义这样的损失函数?
答:实际上J(θ)J(\theta)J(θ)是通过极大似然估计推导得到的
由于yyy只能取0或1,服从伯努利分布,hθ(x)h_\theta(x)hθ(x)是y=1y=1y=1即事件发生概率,则概率质量函数为
p(y∣x;θ)=(hθ(x))y(1−hθ(x))1−yp(y|x;\theta)=(h_\theta(x))^y(1-h_\theta(x))^{1-y}p(y∣x;θ)=(hθ(x))y(1−hθ(x))1−y
对于mmm个独立同分布的训练样本xxx,其似然函数写作L(θ)=∏i=1mp(y∣x;θ)=∏i=1mhθ(xi)yi(1−hθ(xi))1−yiL(\theta)=\prod^{m}_{i=1}p(y|x;\theta)=\prod^{m}_{i=1}h_\theta(x_i)^{y_i}(1-h_\theta(x_i))^{1-y_i}L(θ)=i=1∏mp(y∣x;θ)=i=1∏mhθ(xi)yi(1−hθ(xi))1−yi
为了方便操作,取对数,则对数似然函数为l(θ)=logL(θ)=∑i=1myiloghθ(xi)+(1−yi)log(1−hθ(xi))l(\theta)=\log L(\theta)=\sum^{m}_{i=1}y_i\log{h_\theta(x_i)}+(1-y_i)\log{(1-h_\theta(x_i))}l(θ)=logL(θ)=i=1∑myiloghθ(xi)+(1−yi)log(1−hθ(xi))
根据“最大似然估计”,求l(θ)l(\theta)l(θ)取最大值时的θ\thetaθ,定义损失函数J(θ)J(\theta)J(θ)为J(θ)=−1ml(θ)J(\theta)=-\frac{1}{m}l(\theta)J(θ)=−m1l(θ)
所以最后目标变成取J(θ)J(\theta)J(θ)最小值时的θ\thetaθ为最佳参数。
与线性回归类似,利用梯度下降法更新θ\thetaθ
θj:=θj−α∂∂θjJ(θ)=θj−α1m∑i=1m(hθ(x(i)−y(i))xj(i)\theta_j:=\theta_j-\alpha\frac{\partial}{\partial_{\theta_j}}J(\theta)=\theta_j-\alpha\frac{1}{m}\sum^m_{i=1}(h_\theta(x^{(i)}-y^{(i)})x^{(i)}_jθj:=θj−α∂θj∂J(θ)=θj−αm1i=1∑m(hθ(x(i)−y(i))xj(i)
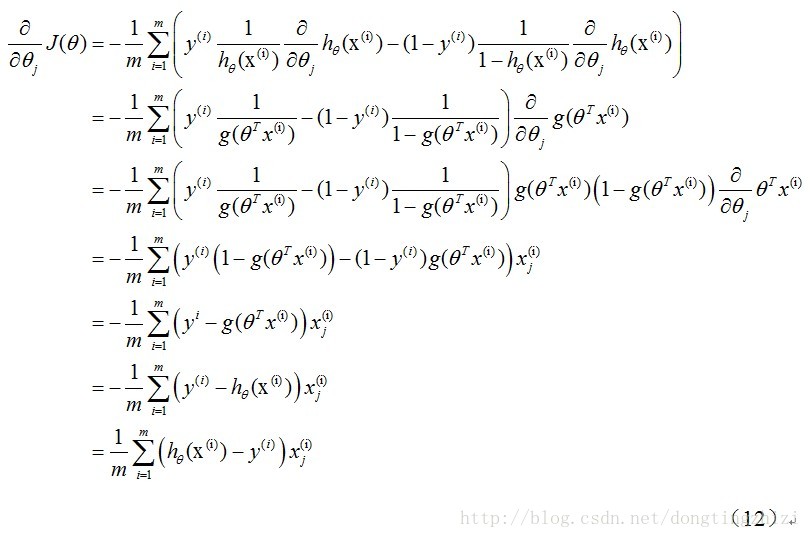
虽然得到的梯度下降更新迭代公式看上去与线性回归的梯度下降算法一样,但是这里的hθ(x)=g(θTx)h_\theta(x)=g(\theta^Tx)hθ(x)=g(θTx)与线性回归不同,所以实际上是不一样的。除了梯度下降法,还有其他的一些用来求代价函数最小时参数θ\thetaθ的方法,如牛顿法、共轭梯度法(Conjugate Gradietn)、局部优化法(BFGS)和有限内存局部优化法(LBFGS)等。
正则化(Regularization)
欠拟合和过拟合
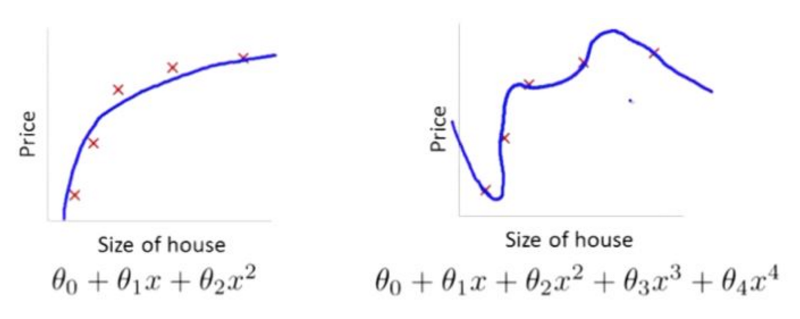
以线性回归预测房价为例
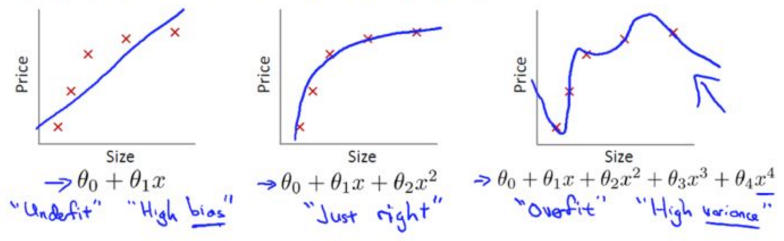
欠拟合(unerfitting),高偏差(bias),没有很好地拟合训练数据,存在较大偏差,不是一个好模型;
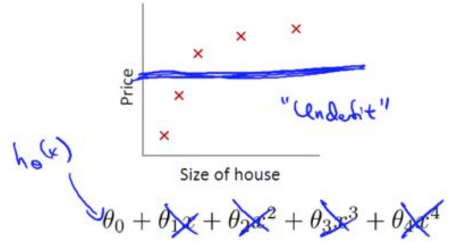
过拟合(overfitting),高方差(variance),对训练数据拟合过于好,泛化性能差,上下波动厉害,也不是一个好模型。
上述情况对于LR也存在
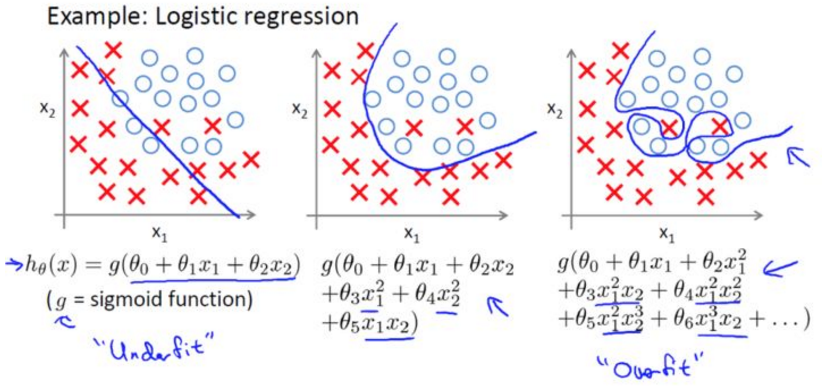
过拟合问题通常发生在变量(特征)过多的时候。这种情况下训练出的方程总是能很好的拟合训练数据,也就是说,我们的代价函数可能非常接近于0或者就为0,使其拟合只局限于训练样本中,无法很好预测其他新的样本。
解决过拟合问题的方法主要有两种:
- 减少特征数量,通过人工或者算法选择哪些特征有用保留,哪些特征没用删除,但会丢失信息。
- 正则化,保留特征,但减少特征对应参数的大小,让每个特征都对预测产生一点影响。
假设我们在损失函数上加上一些项,对θ3\theta_3θ3和θ4\theta_4θ4进行惩罚,变成
minθ12m∑i=1m(hθ(x(i))−y(i))2+1000θ32+1000θ42\min_\theta\frac{1}{2m}\sum^{m}_{i=1}(h_\theta(x^{(i)})-y^{(i)})^2+1000\theta_3^2+1000\theta_4^2 θmin2m1i=1∑m(hθ(x(i))−y(i))2+1000θ32+1000θ42
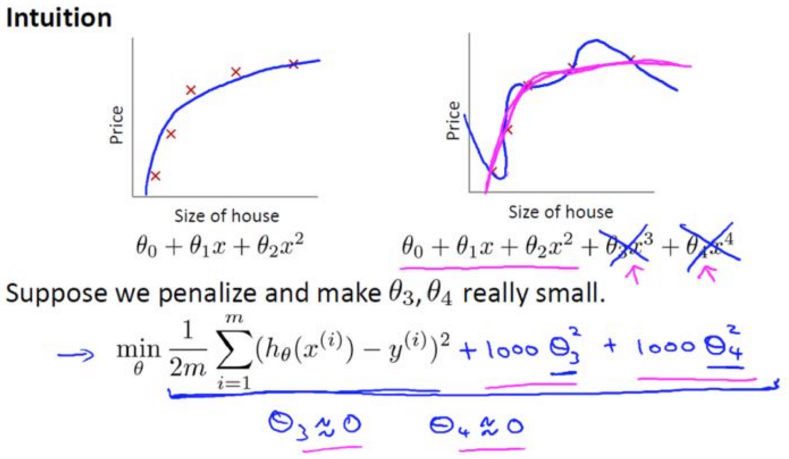
这样求出的θ3\theta_3θ3和θ4\theta_4θ4就会非常小,接近0,得到一个近似的二次函数。
一般来说,正规化背后的思路就是,如果我们的参数值对应一个较小值的话(参数值比较小),那么往往我们会得到一个形式更简单的假设。
但更一般地说,如果我们像惩罚θ3\theta_3θ3和θ4\theta_4θ4这样惩罚其它参数,那么我们往往可以得到一个相对较为简单的假设。
实际上,这些参数的值越小,通常对应于越光滑的函数,也就是更加简单的函数。因此就不易发生过拟合的问题。
假如我们有非常多的特征,我们并不知道其中哪些特征我们要惩罚,我们将对所有的特征进行惩罚,并且让代价函数最优化算法来选择这些惩罚的程度。我们需要修改代价函数,在后面添加一个正则项,收缩每个参数。
正则化线性回归
对于正则化线性回归,损失函数变成
J(θ)=12m[∑i=1m(hθ(x(i))−y(i))2+λ∑j=1nθj2]J(\theta)=\frac{1}{2m}\left[\sum^{m}_{i=1}(h_\theta(x^{(i)})-y^{(i)})^2+\lambda\sum^n_{j=1}\theta^2_j\right] J(θ)=2m1[i=1∑m(hθ(x(i))−y(i))2+λj=1∑nθj2]
注:根据惯例,不对θ0\theta_0θ0进行惩罚。
其中λ\lambdaλ叫做正则化参数,用于平衡拟合训练数据和保持参数值较小避免过拟合之间的关系。
如果λ\lambdaλ过大,则
用梯度下降法迭代求θ\thetaθ,由于不对θ0\theta_0θ0进行惩罚,所以重复下面计算直到收敛:
KaTeX parse error: No such environment: split at position 8: \begin{̲s̲p̲l̲i̲t̲}̲ \theta_0&:=\th…
对上面算法中j=1,2,…,nj=1,2,\ldots,nj=1,2,…,n时的式子进行调整得:
θj:=θj(1−αλm)−α1m∑i=1m((hθ(x(i))−y(i))xj(i)\theta_j:=\theta_j(1-\alpha\frac{\lambda}{m})-\alpha\frac{1}{m}\sum^m_{i=1}((h_\theta(x^{(i)})-y^{(i)})x^{(i)}_j θj:=θj(1−αmλ)−αm1i=1∑m((hθ(x(i))−y(i))xj(i)
正则化逻辑回归
对于逻辑回归损失函数加入正则项得:
J(θ)=−1m∑i=1m[y(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]+λ2m∑j=1nθj2J(\theta)=-\frac{1}{m}\sum^m_{i=1}\left[y^{(i)}\log{h_\theta(x^{(i)})}+(1-y^{(i)})\log({1-h_\theta(x^{(i)})})\right]+\frac{\lambda}{2m}\sum^n_{j=1}\theta^2_j J(θ)=−m1i=1∑m[y(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]+2mλj=1∑nθj2
通过求导用梯度下降法更新θ\thetaθ
KaTeX parse error: No such environment: split at position 8: \begin{̲s̲p̲l̲i̲t̲}̲ \theta_0&:=\th…
看上去形式跟正则化线性回归一样,但其中hθ(x)=g(θTx)h_\theta(x)=g(\theta^Tx)hθ(x)=g(θTx),所以与正则化线性回归不同。
多类分类
LR是一个传统的二分类模型,它也可以用于多分类任务,其基本思想是:将多分类任务拆分成若干个二分类任务,然后对每个二分类任务训练一个模型,最后将多个模型的结果进行集成以获得最终的分类结果。一般来说,可以采取的拆分策略有:
one vs one策略
假设我们有N个类别,该策略基本思想就是不同类别两两之间训练一个分类器,这时我们一共会训练出CN2C^2_NCN2种不同的分类器。在预测时,我们将样本提交给所有的分类器,一共会获得N(N−1)N(N-1)N(N−1)个结果,最终结果通过投票产生。
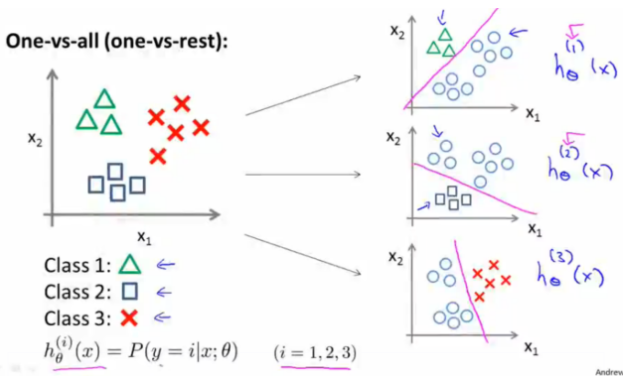
one vs all策略
该策略基本思想就是将第iii种类型的所有样本作为正例,将剩下的所有样本作为负例,进行训练得到一个分类器。这样我们就一共可以得到NNN个分类器。在预测时,我们将样本提交给所有的分类器,一共会获得NNN个结果,我们选择其中概率值最大的那个作为最终分类结果。
LR特点以及适用场景
LR实现简单高效易解释,计算速度快,易并行,在大规模数据情况下非常适用,更适合于应对数值型和标称型数据,主要适合解决线性可分的问题,但容易欠拟合,大多数情况下需要手动进行特征工程,构建组合特征,分类精度不高。
- LR直接对分类可能性进行建模,无需事先假设数据分布,这样就避免了假设分布不准确所带来的问题
- LR能以概率的形式输出,而非知识0,1判定,对许多利用概率辅助决策的任务很有用
- 对率函数任意阶可导,具有很好的数学性质,许多现有的数值优化算法都可以用来求最优解,训练速度快
适用情景:LR是很多分类算法的基础组件,它的好处是输出值自然地落在0到1之间,并且有概率意义。因为它本质上是一个线性的分类器,所以处理不好特征之间相关的情况。虽然效果一般,却胜在模型清晰,背后的概率学经得住推敲。它拟合出来的参数就代表了每一个特征(feature)对结果的影响。也是一个理解数据的好工具。
应用上:
- CTR预估,推荐系统的learning to rank,各种分类场景
- 某搜索引擎厂的广告CTR预估基线版是LR
- 某电商搜索排序基线版是LR
- 某新闻app排序基线版是LR
大规模工业实时数据,需要可解释性的金融数据,需要快速部署低耗时数据
LR就是简单,可解释,速度快,消耗资源少,分布式性能好
ADMM-LR:用ADMM求解LogisticRegression的优化方法称作ADMM_LR。ADMM算法是一种求解约束问题的最优化方法,它适用广泛。相比于SGD,ADMM在精度要求不高的情况下,在少数迭代轮数时就达到一个合理的精度,但是收敛到很精确的解则需要很多次迭代。
逻辑回归(Logistic Regression, LR)简介相关推荐
- 逻辑回归(Logistic Regression, LR)又称为逻辑回归分析,是分类和预测算法中的一种。通过历史数据的表现对未来结果发生的概率进行预测。例如,我们可以将购买的概率设置为因变量,将用户的
逻辑回归(Logistic Regression, LR)又称为逻辑回归分析,是分类和预测算法中的一种.通过历史数据的表现对未来结果发生的概率进行预测.例如,我们可以将购买的概率设置为因变量,将用户的 ...
- 逻辑回归Logistic Regression 模型简介
逻辑回归(Logistic Regression)是机器学习中的一种分类模型,由于算法的简单和高效,在实际中应用非常广泛.本文作为美团机器学习InAction系列中的一篇,主要关注逻辑回归算法的数学模 ...
- 逻辑回归(Logistic Regression)简介及C++实现
逻辑回归(Logistic Regression):该模型用于分类而非回归,可以使用logistic sigmoid函数( 可参考:http://blog.csdn.net/fengbingchun/ ...
- OpenCV3.3中逻辑回归(Logistic Regression)使用举例
OpenCV3.3中给出了逻辑回归(logistic regression)的实现,即cv::ml::LogisticRegression类,类的声明在include/opencv2/ml.hpp文件 ...
- Coursera公开课笔记: 斯坦福大学机器学习第六课“逻辑回归(Logistic Regression)”
Coursera公开课笔记: 斯坦福大学机器学习第六课"逻辑回归(Logistic Regression)" 斯坦福大学机器学习第六课"逻辑回归"学习笔记,本次 ...
- OpenCV逻辑回归Logistic Regression的实例(附完整代码)
OpenCV逻辑回归Logistic Regression的实例 OpenCV逻辑回归Logistic Regression的实例 OpenCV逻辑回归Logistic Regression的实例 # ...
- 斯坦福大学机器学习第四课“逻辑回归(Logistic Regression)”
斯坦福大学机器学习第四课"逻辑回归(Logistic Regression)" 本次课程主要包括7部分: 1) Classification(分类) 2) Hypothesis R ...
- 逻辑回归(logistic regression)的本质——极大似然估计
文章目录 1 前言 2 什么是逻辑回归 3 逻辑回归的代价函数 4 利用梯度下降法求参数 5 结束语 6 参考文献 1 前言 逻辑回归是分类当中极为常用的手段,因此,掌握其内在原理是非常必要的.我会争 ...
- CS229学习笔记(3)逻辑回归(Logistic Regression)
1.分类问题 你要预测的变量yyy是离散的值,我们将学习一种叫做逻辑回归 (Logistic Regression) 的算法,这是目前最流行使用最广泛的一种学习算法. 从二元的分类问题开始讨论. 我们 ...
- 机器学习笔记04:逻辑回归(Logistic regression)、分类(Classification)
之前我们已经大概学习了用线性回归(Linear Regression)来解决一些预测问题,详见: 1.<机器学习笔记01:线性回归(Linear Regression)和梯度下降(Gradien ...
最新文章
- 人工智能基础-算法工程师为什么要懂线性代数?
- 『数学』你确定你学会了勾股弦定理!真的吗?看完这个篇文章再回答我!
- 中国碳纤维复合加热元件行业市场供需与战略研究报告
- matlab imagesc clims,imagesc
- html中script标签的使用方法
- jmeter导出测试报告
- WSL自定义安装路径
- 一次使用针式打印机打印异常问题的处理
- 明尼苏达大学研究者为bug事件致歉
- win10安装 vmware10
- Testbench的激励添加和书写技巧
- Android 打开系统文件管理器选择文件
- 回顾2022,展望2023,一个普通程序员的自述和分享
- 山村屠杀源与公共知识的运用
- QGridLayout(表格布局)详细使用说明
- 麻进:这次不烧作品!
- mybatis动态sql及分页
- Nginx 学习总结
- ROS入门WIKI学习记录
- AJ 组件库之通用数据字典 DataDict