多分类学习(OvO、OVR、MVM 原理区别)
多分类问题解决思路,一般来说,用二分类学习器解决多分类问题,基本思想是先拆分后集成,也就是先将数据集进行拆分,然后多个数据集可训练多个模型,然后再对多个模型进行集成。这里所谓集成,指的是使用这多个模型对后续新进来数据的预测方法。
具体来看,依据该思路一般有三种实现策略,分别是“一对一”(One vs Ons,简称OvO)、“一对剩余”(One vs Rest,简称OvR)和“多对多”(Many vs Many,加成MvM)。接下来我们逐个讨论。
1.OvO策略
- 拆分策略
OvO的拆分策略比较简单,基本过程是将每个类别对应数据集单独拆分成一个子数据集,然后令其两两组合,再来进行模型训练。例如,对于上述四分类数据集,根据标签类别可将其拆分成四个数据集,然后再进行两两组合,总共有6种组合,也就是C42C^2_4C42种组合。拆分过程如下所示:
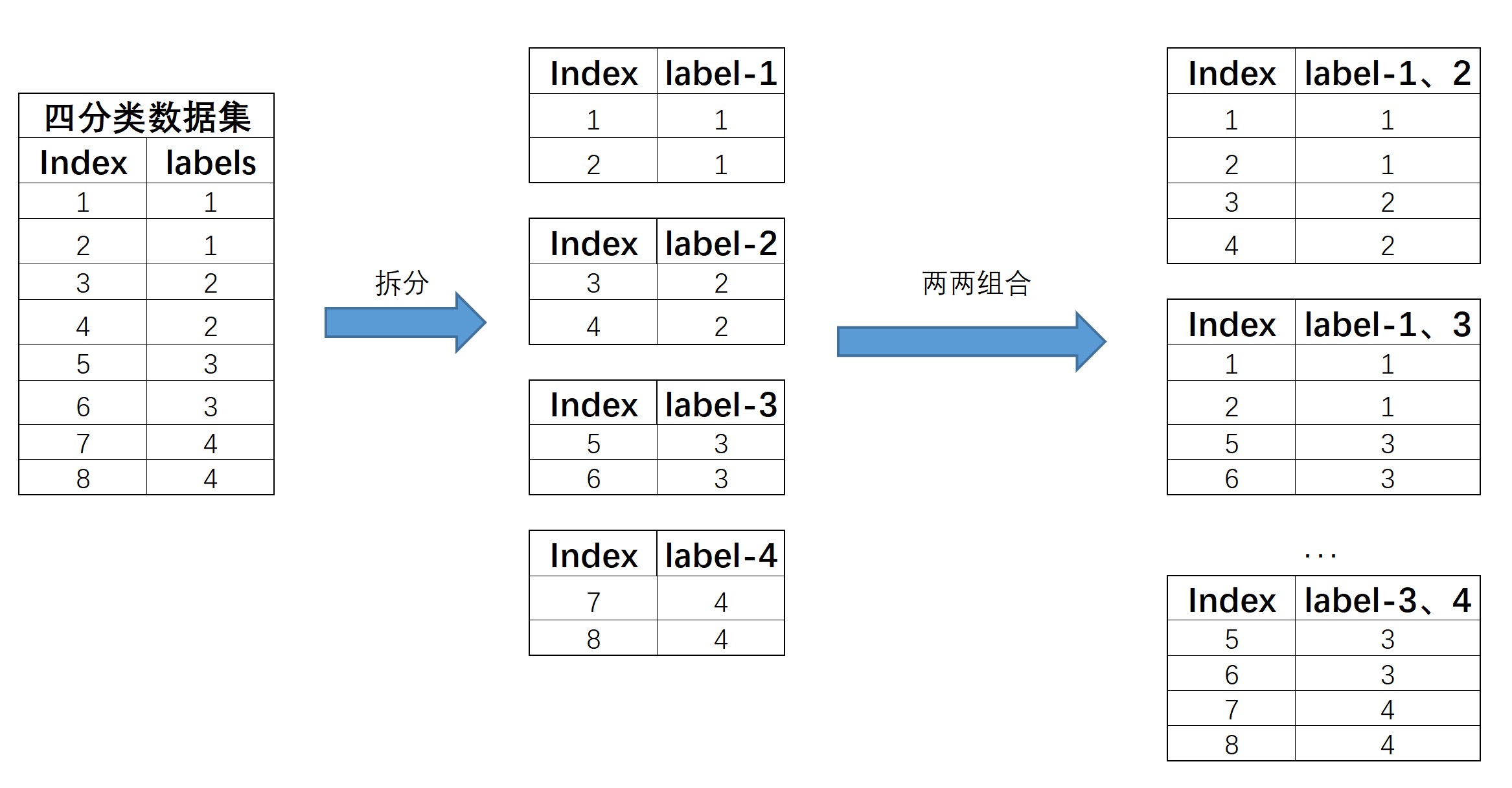
然后在这6个新和成的数据集上,我们就能训练6个分类器。当然,如果是N分类问题,则需要训练CN2=N(N−1)2C^2_N=\frac{N(N-1)}{2}CN2=2N(N−1)个模型。
- 集成策略
当模型训练完成之后,接下来面对新数据集的预测,可以使用投票法从6个分类器的判别结果中挑选最终判别结果。
 根据少数服从多数的投票法能够得出,某条新数据最终应该属于类别1。
根据少数服从多数的投票法能够得出,某条新数据最终应该属于类别1。
2.OvR策略
- 拆分策略
和OvO的两两组合不同,OvR策略则是每次将一类的样例作为正例、其他所有数据作为反例来进行数据集拆分。对于上述四分类数据集,OvR策略最终会将其拆分为4个数据集,基本拆分过程如下:

此4个数据集就将训练4个分类器。注意,在OvR的划分策略种,是将rest无差别全都划分为负类。当然,如果数据集总共有N个类别,则在进行数据集划分时总共将拆分成N个数据集。
- 集成策略
当成,集成策略和划分策略息息相关,对于OvR方法来说,对于新数据的预测,如果仅有一个分类器将其预测为正例,则新数据集属于该类。若有多个分类器将其预测为正例,则根据分类器本身准确率来进行判断,选取准确率更高的那个分类器的判别结果作为新数据的预测结果。

- OvO和OvR的比较
对于这两种策略来说,尽管OvO需要训练更多的基础分类器,但由于OvO中的每个切分出来的数据集都更小,因此基础分类器训练时间也将更短。因此,综合来看在训练时间开销上,OvO往往要小于OvR。而在性能方面,大多数情况下二者性能类似。
3.MvM策略
相比于OvO和OvR,MvM是一种更加复杂的策略。MvM要求同时将若干类化为正类、其他类化为负类,并且要求多次划分,再进行集成。一般来说,通常会采用一种名为“纠错输入码”(Error Correcting Output Codes,简称ECOC)的技术来实现MvM过程。
- 拆分策略
此时对于上述4分类数据集,拆分过程就会变得更加复杂,我们可以任选其中一类作为正类、其余作为负类,也可以任选其中两类作为正类、其余作为负数,以此类推。由此则诞生出了非常多种子数据集,对应也将训练非常多个基础分类器。
当然,将某一类视作正类和将其余三类视作正类的预测结果相同,对调下预测结果即可,此处不用重复划分。
例如,对于上述4分类数据集,则可有如下划分方式:

根据上述划分方式,总共将划分C41+C42=10C_4^1+C_4^2=10C41+C42=10个数据集,对应构建,对应的我们可以构建10个分类器。不过一般来说对于ECOC来说我们不会如此详尽的对数据集进行划分,而是再上述划分结果中挑选部分数据集进行建模,例如就挑选上面显式表示的4个数据集来进行建模,即可 构建4个分类器。
- 集成策略
接下来我们进行模型集成。值得注意的是,如果是以上述方式划分四个数据集,我们可以将每次划分过程中正例或负例的标签所组成的数组视为每一条数据自己的编码。
同时,我们使用训练好的四个基础分类器对新数据进行预测,也将产生四个结果,而这四个结果也可构成一个四位的新数据的编码。接下来,我们可以计算新数据的编码和上述不同类别编码之间的距离,从而判断新生成数据应该属于哪一类。

距离计算有很多种方法:
闵可夫斯基距离计算公式如下:
d(x,y)=∑i=1n(∣xi−yi∣)nnd(x, y) = \sqrt[n]{\sum_{i = 1}^{n}(|x_i-y_i|)^n}d(x,y)=ni=1∑n(∣xi−yi∣)n
当 n =2 时为欧式距离(一般采用);n=1时为曼哈顿距离
def dist(x, y, cat = 2):"""闵可夫斯基距离计算函数"""d1 = np.abs(x - y)if x.ndim > 1 or y.ndim > 1:res1 = np.power(d1, cat).sum(1) # 行相加else:res1 = np.power(d1, cat).sum()res = np.power(res1, 1/cat)return res
进行编码距离计算:
# 原类别编码矩阵
code_mat = np.array([[1, -1, 1, -1],[-1, -1, 1, -1],[-1, -1, -1, 1],[-1, 1, -1, 1]])# 预测数据编码
data_code = np.array([1, -1, 1, 1])
dist(code_mat, data_code)
# 结果 array([2. , 2.82842712, 2.82842712, 3.46410162]) 新样本应该属于第一类
- ECOC方法评估
对于ECOC方法来说,编码越长预测结果越准确,不过编码越长也代表着需要耗费更多的计算资源,并且由于模型本身类别有限,因此数据集划分数量有限,编码长度也会有限。不过一般来说,相比OvR,MvM方法效果会更好。
多分类学习(OvO、OVR、MVM 原理区别)相关推荐
- 多分类问题OvO,OvR,MvM
- 多分类学习:OvO、OvR、ECOC
OvO OvR MvM
- 最通俗易懂---多分类学习之OvO、OvR、MvM
多分类学习之OvO.OvR.MvM 基本思路 OvO(一对一) OvR(一对其余) MvM(多对多) 基本思路 多分类学习的基本思路是"拆解法",即将多分类任务拆分成若干个二分 ...
- 多分类任务ovo、ovr及softmax回归
多分类任务OVO.OVR及softmax回归 – 潘登同学的Machine Learning笔记 文章目录 多分类任务OVO.OVR及softmax回归 -- 潘登同学的Machine Learnin ...
- sklearn中实现多分类任务(OVR和OVO)
sklearn中实现多分类任务(OVR和OVO) 1.OVR和OVO是针对一些二分类算法(比如典型的逻辑回归算法)来实现多分类任务的两种最为常用的方式,sklearn中专门有其调用的函数,其调用过程如 ...
- 多分类学习、多标签学习、多任务学习的区别
Multi-class. Multi-label . Multi-task 三者之间的区别与相同之处 1.直观解释 多分类学习(Multi-class) 一个分类器,但分的类别是包含多个的.例如:分类 ...
- 【机器学习】多分类学习的拆分策略
[机器学习]多分类学习 现实中常遇到多分类学习任务.有些二分类学习方法可直接推广到多分类,但在更多情形下,我们是基于一些基本策略,利用二分类学习器来解决多分类问题.所以多分类问题的根本方法依然是二分类 ...
- 机器学习6-多分类学习器拆分策略
文章目录 1.一对一(One vs. One,简称OvO) 2.一对其余(One vs. Rest,简称OVR) 3.多对多(Many vs. Many,简称MvM) 参考文章: 多分类问题学习器 ...
- 多分类学习与类别不均衡
将二分类扩展为 N N N分类在某些情况下可以直接推广二分类学习算法,但更多时候是对数据集下手的方法: OvO (one),一个数据集产生 N ( N − 1 ) 2 \frac{N(N-1)}{2} ...
最新文章
- python创建对象的格式为_Python入门基础学习(面向对象)
- 【高并发】高并发分布式锁架构解密,不是所有的锁都是分布式锁!!
- automaticallyAdjustsScrollViewInsets
- 王孟源:中国要崛起,基础科研需要“讲实话
- 音乐游戏 简单模拟,字符串,cin.get,getchar,流同步(女赛)
- 技术重塑未来工作方式
- 主机路由在计算机中的应用
- 第二步_安装samba服务器
- Elasticsearch7 mapping和setting简介
- LSL学习笔记(3)
- Codeforces Round #521 (Div. 3) B - Disturbed People (贪心)
- 任天堂 Wii 模拟器 Dolphin 已原生支持苹果 M1 Mac 电脑
- 小程序实战—答题类小程序
- linux jpg图片缩放,ImageMagick之图片缩放
- 英语语法汇总(3.代词)
- Fortran七七八八
- 10.25软件测试学习总结
- 打开谷歌浏览器提示输入密钥环
- js将图片转base64两种方法
- 自动驾驶 常用的汽车连接器