Hadoop之机架感知
在分布式集群下,由于机架的的槽位和交换机网口数量的限制,使得集群上的机器不得不跨越机架,通常一个大型的集群会跨越很多机架。一般情况机架内机器的通讯会快于跨机架机器之间的通讯,并且机架之间机器的网络通信通常受到上层交换机间网络带宽的限制。
通过机架感知,可以带来性能和安全性的提升,例如:HDFS块为了故障容错,采用机架感知按到一定的策略将某些块放置在不同的机架上,这样就算一个机架瘫痪也不会影响集群;运行MapReduce任务时,如果任务数量过多,每个任务运行的节点可能在不同的机架运行,这样任务可以就近获取到所需的HDFS块。
Hadoop守护进程通过获取配置文件中配置的外部脚本或Java类来获取集群slave的机架ID,使用Java类,需要实现org.apache.hadoop.net.DNSToSwitchMapping接口,这个接口期望用一一对应的方式用/myrack/myhost的格式保存网络拓扑结构的信息,“/”拓扑结构的分隔符,“myrack”的机架标识符,"myhost"是主机。例如:‘/192.168.100.0/192.168.100.5’ 作为一个机架-Host的拓扑映射。
额外的配置:mapreduce.jobtracker.taskcache.levels, 该参数定义在mapred-core.xml中,决定MapReduce缓存网络拓扑结构的层级,举例来说,如果它的值是2,则构建2个层级的缓存,一个 hosts (host -> task mapping) 和另一个racks (rack -> task mapping)。
NameNode是以主机为单位来计算集群的负载情况。以节点的话,如果某台主机上启动了多个DataNode节点,会造成这台主机的负载过重。
NameNode启动时,有两种方式存放DataNode:
1,org.apache.hadoop.hdfs.server.blockmanagement.Host2NodesMap
将DataNode和主机的对应关系存放到org.apache.hadoop.hdfs.server.blockmanagement.Host2NodesMap类中,该类主要对集群中的DataNode节点按照主机进行分类管理,包含contains(是否包含),add(添加),remove(删 除),getDatanodeByHost(根据IP地址获取DataNode),getDatanodeByXferAddr方法。
2,org.apache.hadoop.net.NetworkTopology(默认)
NetworkTopology类将整个集群的DataNode节点存储成一个树形的网络拓扑图,但是在NameNode节点把一个DataNode节点交给NetworkTopology时,要将DataNode节点解析成/myrack/myhost格式。
NameNode 节点要把IP地址解析成什么样的路径格式,这个是由用户指定的,用户可以在core-site.xml的 net.topology.node.switch.mapping.impl中设置,默认为 org.apache.hadoop.net.ScriptBasedMapping类。如果用户自己实现,必须必须实现 org.apache.hadoop.net.DNSToSwitchMapping接口。
在默认的情况下,Hadoop是没有机架感知的,如果要开启机架感知也很简单,配置net.topology.script.file.name,参数值通常是一个可执行脚本(支持Python和Shell),脚本接受一个值,输出一 个值,一般都是接受IP地址,输出这个IP地址对应的机架信息。NameNode在启动的时候,DataNode会发送心跳,NameNode获取到心跳 的IP,将IP作为参数传入脚本,获取到输出值,将输出信息存放到上述所讲保存DataNode的对象中。
Python 实例:
#!/usr/bin/python
# this script makes assumptions about the physical environment.
# 1) each rack is its own layer 3 network with a /24 subnet, which
# could be typical where each rack has its own
# switch with uplinks to a central core router.
#
# +-----------+
# |core router|
# +-----------+
# / \
# +-----------+ +-----------+
# |rack switch| |rack switch|
# +-----------+ +-----------+
# | data node | | data node |
# +-----------+ +-----------+
# | data node | | data node |
# +-----------+ +-----------+
#
# 2) topology script gets list of IP's as input, calculates network address, and prints '/network_address/ip'.import netaddr
import sys
sys.argv.pop(0) # discard name of topology script from argv list as we just want IP addressesnetmask = '255.255.255.0' # set netmask to what's being used in your environment. The example uses a /24for ip in sys.argv: # loop over list of datanode IP's
address = '{0}/{1}'.format(ip, netmask) # format address string so it looks like 'ip/netmask' to make netaddr work
try:network_address = netaddr.IPNetwork(address).network # calculate and print network addressprint "/{0}".format(network_address)
except:print "/rack-unknown" # print catch-all value if unable to calculate network addressShell 实例:
#!/bin/bash
# Here's a bash example to show just how simple these scripts can be
# Assuming we have flat network with everything on a single switch, we can fake a rack topology.
# This could occur in a lab environment where we have limited nodes,like 2-8 physical machines on a unmanaged switch.
# This may also apply to multiple virtual machines running on the same physical hardware.
# The number of machines isn't important, but that we are trying to fake a network topology when there isn't one.
#
# +----------+ +--------+
# |jobtracker| |datanode|
# +----------+ +--------+
# \ /
# +--------+ +--------+ +--------+
# |datanode|--| switch |--|datanode|
# +--------+ +--------+ +--------+
# / \
# +--------+ +--------+
# |datanode| |namenode|
# +--------+ +--------+
#
# With this network topology, we are treating each host as a rack. This is being done by taking the last octet
# in the datanode's IP and prepending it with the word '/rack-'. The advantage for doing this is so HDFS
# can create its 'off-rack' block copy.
# 1) 'echo $@' will echo all ARGV values to xargs.
# 2) 'xargs' will enforce that we print a single argv value per line
# 3) 'awk' will split fields on dots and append the last field to the string '/rack-'. If awk
# fails to split on four dots, it will still print '/rack-' last field valueecho $@ | xargs -n 1 | awk -F '.' '{print "/rack-"$NF}'网络拓扑机器之间的距离:
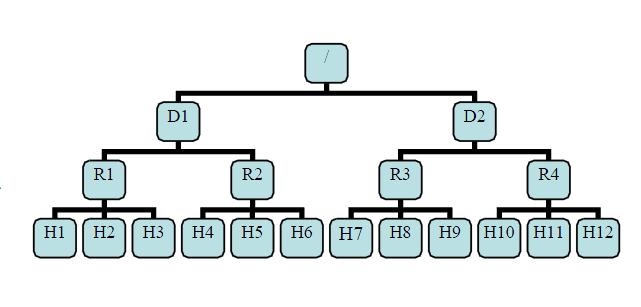
有了机架感知,NameNode就可以画出上图所示的datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的是D1。这些rackid信息可以通过topology.script.file.name配置。有了这些rackid信息就可以计算出任意两台datanode之间的距离。
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R1/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode
副本放置策略
1,client上传文件,第一个block副本放在和client所在的DataNode里(如果client不在集群范围内,则这第一个DataNode是随机选取的,当然系统会尝试不选择哪些太满或者太忙的node)。
2,第二个副本放置在与第一个节点不同的机架中的node中(随机选择)。
3,第三个副本和第二个在同一个机架,随机放在不同的node中。
如果还有更多的副本就随机放在集群的node里。
Hadoop的副本放置策略在可靠性(block在不同的机架)和带宽(一个管道只需要穿越一个网络节点)中做了一个很好的平衡。下图是备份参数是3的情况下一个管道的三个datanode的分布情况。
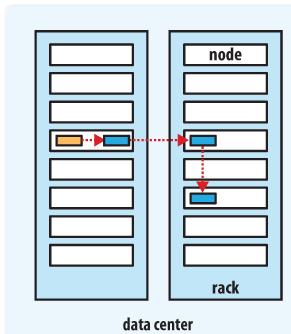
参考:http://blog.csdn.net/fiberlijun/article/details/4820266
机架感知的几个配置:
| 参数 | 值 | 描述 |
|---|---|---|
| net.topology.node.switch.mapping.impl | org.apache.hadoop.net.ScriptBasedMapping | 该配置类调用net.topology.script.file.name参数配置的外部脚本处理节点名称。如果net.topology.script.file.name参数没有设置,则所有节点的名称都返回:"/default-rack" |
| net.topology.impl | org.apache.hadoop.net.NetworkTopology | 默认是一个经典的三层网络拓扑结构。 |
|
net.topology.script.file.name |
外部脚本路径。 | |
net.topology.script.number.args
|
100
|
运行net.topology.script.file.name参数时最大的参数数量,每个参数都是一个IP地址。 |
net.topology.table.file.name
|
在net.topology.script.file.name被设置为 org.apache.hadoop.net.TableMapping时,可以使用此配置。文件格式是一个有两个列的文本文件,使用空白字符分隔。第一列是DNS或IP地址,第二列是机架路径。如无指定,使用默认机架("/default-rack") |
![]()
Hadoop之机架感知相关推荐
- Hadoop之——机架感知配置
转载请注明出处:http://blog.csdn.net/l1028386804/article/details/51935169 1.背景 Hadoop在设计时考虑到数据的安全与高效,数据文件默认在 ...
- Hadoop配置机架感知(python脚本)
昨天QQ群里提了一个hadoop运行效率分配的问题,总结一下,写个文章.集群使用hadoop-1.0.3 有些hadoop集群在运行的时候,不完全是绝对平均的分配,不过需要尽可能平均的分配任务,避免某 ...
- Hadoop配置机架感知
配置机架感知 core-site.xml cat $HADOOP_HOME/etc/hadoop/core-site.xml <property> <name>net.topo ...
- hadoop 配置机架感知
假如设备链接层次分3层,第一层交换机d1下面连多个交换机rk1,rk2,rk3,rk4,-. 每个交换机对应一个机架. d1(rk1(hs11,hs12,-),rk2(hs21,hs22,-), rk ...
- Hadoop机架感知
背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高于跨机架 ...
- hadoop之 hadoop 机架感知
1.背景 Hadoop在设计时考虑到数据的安全与高效,数据文件默认在HDFS上存放三份,存储策略为本地一份,同机架内其它某一节点上一份,不同机架的某一节点上一份.这样如果本地数据损坏,节点可以从同一机 ...
- 【转】hadoop机架感知
原文链接 http://www.cnblogs.com/ggjucheng/archive/2013/01/03/2843015.html 背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交 ...
- 第十三章 hadoop机架感知
背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高于跨机架 ...
- Hadoop机架感知配置及配置问题解决
Hadoop在搭建集群的时候,集群的网络拓扑都是默认在同一个机架下的.以/default-rack为一个机架,如下格式. Rack: /default-rack 192.168.71.100:5001 ...
最新文章
- python里面的pip是什么意思_Python-pip和conda有什么区别?
- centos 程序 mysql数据库文件位置,CentOS 更改MySQL数据库目录位置
- ppp协议pap验证过程状态转移图_电脑网络知识:TCP协议的高级特性,你所不知道的TCP...
- OC----内存管理
- xxx is not mapped 错误 解决方案
- 设计世界上最小的 Arduino!
- UVALive5910 UVA1641 POJ4022 ASCII Area【水题+输入输出】
- 通过keil hex2bin,bin2hex的方法
- PS教程证件照底片更换颜色
- vue 图表组件_基于Vue.js中可用的JUI图表的Vue组件
- html+div+动画效果,CSS3效果:animate实现点点点loading动画效果(一)
- 2023必火的5种服装店装修风格,看看哪种风格适合你家店?
- 有服务器端源码和客户端源码,C# 远程控制软件源码(含服务器端和客户端源码)...
- 好看的网站发布导航页HTML源码
- 【互联网代理方案】——Zookeeper
- 蓝牙核心技术概述: 蓝牙协议规范(射频、基带链路控制、链路管理)
- 【Spring Cloud 2】软件架构设计,Java游戏合集百度云盘
- 解决Pycharm任务栏可见但窗口不显示
- C++程序设计课程中的团队建设
- Pandas的MultiIndex多层索引使用