逻辑回归 自由度_回归自由度的官方定义
逻辑回归 自由度
Back in middle and high school you likely learned to calculate the mean and standard deviation of a dataset. And your teacher probably told you that there are two kinds of standard deviation: population and sample. The formulas for the two are just small variations on one another:
回到中学和高中时,您可能已经学会了计算数据集的平均值和标准偏差。 您的老师可能告诉过您,标准差有两种:总体和样本。 两者的公式彼此之间只是很小的变化:

where μ is the population mean and x-bar is the sample mean. Typically, one just learns the formulas and is told when to use them. If you ask why, the answer is something vague like “there was one degree of freedom used up when estimating the sample mean.” without a true definition of a “degree of freedom.”
其中,μ是总体平均值,x-bar是样本平均值。 通常,人们只是学习公式并被告知何时使用它们。 如果您问为什么,答案是模糊的,例如“估计样本均值时使用了一个自由度。” 没有“自由度”的真实定义。
Degrees of freedom also show up in several other places in statistics, for example: when doing t-tests, F-tests, χ² tests, and generally studying regression problems. Depending on the circumstance, degrees of freedom can mean subtly different things (the wikipedia article lists at least 9 closely-related definitions by my count¹).
自由度还在统计中的其他几个地方出现,例如:进行t检验,F检验,χ²检验以及一般研究回归问题时。 根据情况的不同,自由度可能意味着微妙的不同(根据我的观点, 维基百科文章列出了至少9个紧密相关的定义¹)。
In this article, we’ll focus on the meaning of degrees of freedom in a regression context. Specifically we’ll use the sense in which “degrees of freedom” is the “effective number of parameters” for a model. We’ll see how to compute the number of degrees of freedom of the standard deviation problem above alongside linear regression, ridge regression, and k-nearest neighbors regression. As we go we’ll also briefly discuss the relation to statistical inference (like a t-test) and model selection (how to compare two different models using their effective degrees of freedom).
在本文中,我们将重点介绍回归上下文中自由度的含义。 具体来说,我们将使用“自由度”是模型的“有效参数数量”的含义。 我们将看到如何在上面与线性回归,岭回归和k最近邻回归一起计算标准差问题的自由度数。 在进行过程中,我们还将简要讨论与统计推断(如t检验)和模型选择(如何使用其有效自由度比较两个不同模型)的关系。
自由程度 (Degrees of Freedom)
In the regression context we have N samples each with a real-valued outcome value y. For each sample, we have a vector of covariates x, usually taken to include a constant. In other words, the first entry of the x-vector is 1 for each sample. We have some sort of model or procedure (which could be parametric or non-parametric) that is fit to the data (or otherwise uses the data) to produce predictions about what we think the value of y should be given an x-vector (which could be out-of-sample or not).
在回归上下文中,我们有N个样本,每个样本的实值结果值为y 。 对于每个样本,我们都有一个协变量向量x ,通常将其包括一个常数。 换句话说,对于每个样本, x向量的第一项均为1。 我们有某种适合数据(或以其他方式使用数据)的模型或过程(可以是参数化的也可以是非参数化的)来产生关于我们认为y值应赋予x向量的预测( (可能超出样本)。
The result is the predicted value, y-hat, for each of the N samples. We’ll define the degrees of freedom, which we denote as ν (nu):
结果是N个样本中每个样本的预测值y-hat。 我们将定义自由度,我们将其表示为ν(nu):

And we’ll interpret the degrees of freedom as the “effective number of parameters” of the model. Now let’s see some examples.
我们将把自由度解释为模型的“有效参数数量”。 现在让我们看一些例子。
均值和标准差 (The Mean and Standard Deviation)
Let’s return to the school-age problem we started with. Computing the mean of a sample is just making the prediction that every data point has value equal to the mean (after all, that’s the best guess you can make under the circumstances). In other words:
让我们回到开始时的学龄问题。 计算样本均值只是在预测每个数据点的值等于均值(毕竟,这是在这种情况下可以做出的最佳猜测)。 换一种说法:

Note that estimating the mean is equivalent to running a linear regression with only one covariate, a constant: x = [1]. Hopefully this makes it clear why we can re-cast the problem as a prediction problem.
注意,估计均值等效于仅使用一个协变量(常数:x = [1])进行线性回归。 希望这可以弄清楚为什么我们可以将问题重铸为预测问题。
Now it’s simple to compute the degrees of freedom. Unsurprisingly we get 1 degree of freedom:
现在,很容易计算自由度。 毫不奇怪,我们获得了1个自由度:

To understand the relationship to the standard deviation, we have to use another closely related definition of degrees of freedom (which we won’t go into depth on). If our samples were independent and identically distributed, then we can say, informally, that we started out with N degrees of freedom. We lost one in estimating the mean, leaving N–1 left over for the standard deviation.
要了解与标准偏差的关系,我们必须使用另一个密切相关的自由度定义(我们将不对其进行深入介绍)。 如果我们的样本是独立的并且分布均匀,那么我们可以非正式地说,我们从N个自由度开始。 我们在估计均值时输了一个,剩下N-1作为标准差。
香草线性回归 (Vanilla Linear Regression)
Now let’s expand this into the context of regular old linear regression. In this context, we like to collect the sample data into a vector Y and matrix X. Throughout this article we will use p to denote the number of covariates for each sample (the length of the x-vector).
现在,将其扩展到常规旧线性回归的上下文中。 在这种情况下,我们希望将样本数据收集到向量Y和矩阵X中。在整个本文中,我们将使用p表示每个样本的协变量数( x向量的长度)。
It shouldn’t come as a spoiler that the number of degrees of freedom will end up being p. But the method used to calculate this will pay off for us when we turn to Ridge Regression.
自由度的数量最终将为p不应成为破坏者。 但是,当我们转向Ridge回归时,用于计算此费用的方法将为我们带来回报。
The count of p covariates includes a constant if we include one in our model as we usually do. Each row in the X matrix corresponds to the x-vector for each observation in our sample:
如果我们像往常一样在模型中加入一个,则p个协变量的计数将包含一个常数。 X矩阵中的每一行对应于样本中每个观察值的x-向量:

The model is that there are p parameters collected into a vector β. Y = Xβ plus an error term. We’ll go through the derivation because it will be useful for us later. We pick an estimate for β that minimizes the sum of squares of the errors. In other words our loss function is
该模型是将p个参数收集到向量β中。 Y =Xβ加上误差项。 我们将进行推导,因为它对以后对我们很有用。 我们为β选择一个估计,以使误差平方和最小。 换句话说,我们的损失函数是
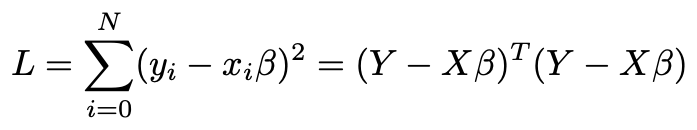
The first sum is in terms of each sample with row-vectors x labeled by i. To optimize L, we differentiate with respect to the vector β, obtaining a p⨉1 vector of derivatives.
关于每个样本,第一个和是行向量x标记为i的 。 为了优化L,我们对向量β求微分,得到一个导数为p⨉1的向量。

Set it equal to 0 and solve for β
将其设置为0并求解β

And finally form our estimate
最后形成我们的估计

We call the matrix H for “hat matrix” because it “puts the hat” on the Y (producing our fitted/predicted values). The hat matrix is an N⨉N matrix. We are assuming that the y’s are independent, so we can compute the effective degrees of freedom:
我们将矩阵H称为“帽子矩阵”,因为它“将帽子”放在Y上(产生拟合/预测值)。 帽矩阵是N⨉N矩阵。 我们假设y是独立的,因此我们可以计算有效的自由度:

where the second sum is over the diagonal terms in the matrix. If you write out the matrix and write out the formula for the predicted value of sample 1, you will see that these derivatives are in fact just the diagonal entries of the hat matrix. The sum of the diagonals of a matrix is called the Trace of matrix and we have denoted that in the second line.
第二个和在矩阵的对角项上。 如果您写出矩阵并写出样本1的预测值的公式,您会发现这些导数实际上只是帽子矩阵的对角线项。 矩阵对角线的总和称为迹线 的矩阵,我们已经在第二行指出了这一点。
计算轨迹 (Computing the Trace)
Now we turn to computing the trace of H. We had better hope it is p!
现在我们来计算H的踪迹。 我们最好希望它是p !
There is a simple way to compute the trace of H using the cyclicality of the trace. But we’ll take another approach that will be generalized when we discuss ridge regression.
有一种使用轨迹的周期性计算H轨迹的简单方法。 但是,在讨论岭回归时,我们将采用另一种将被推广的方法。
We use the singular value decomposition of X. (See my earlier article for a geometric explanation of the singular value decomposition and the linear algebra we are about to do). The trace of a matrix is a basis-independent number, so we can choose whatever basis we want for the vector space containing Y. Similarly, we can choose whatever basis we want for the vector space containing the parameters β. The singular value decomposition says that there exists a basis for each such that the matrix X is diagonal. The entries on the diagonal in the first p rows are called the singular values. The “no perfect multi-collinearity” assumption for linear regression means that none of the singular values are 0. The remaining N–p rows of the matrix are all full of 0s.
我们使用X的奇异值分解 。(有关奇异值分解和线性代数的几何解释,请参阅我的较早文章 )。 矩阵的轨迹是一个与基数无关的数,因此我们可以为包含Y的向量空间选择所需的任何基准。类似地,我们可以为包含参数β的向量空间选择所需的任何基准。 奇异值分解表示每个矩阵都有一个基础,使得矩阵X对角线。 前p行中对角线上的条目称为奇异值 。 线性回归的“没有完美的多重共线性”假设意味着奇异值均不为0。矩阵的其余N–p行全为0。
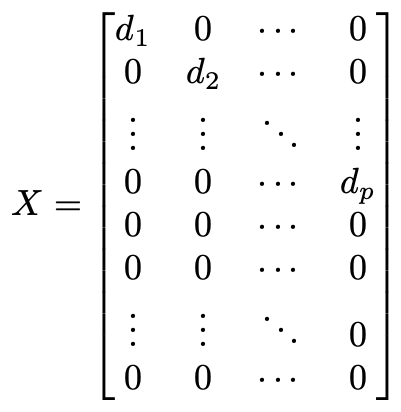
Now it’s easy to compute H. You can just multiply the versions of X by hand and get a diagonal matrix with the first p diagonal entries all 1 and the rest 0. The entries not shown (the off-diagonal ones) are all 0 as well.
现在可以很容易地计算出H。您可以手动乘以X的形式,并得到一个对角矩阵,其中前p个对角线条目均为1,其余为0。未显示的条目(非对角线条目)全部为0好。

So we conlude Tr(H) = p.
因此我们得出Tr(H)= p的结论。
模拟标准偏差:标准误差 (Analogue of the Standard Deviation: Standard Error)
In our previous example (mean and standard deviation), we computed the standard deviation after computing the mean, using n–1 for the denominator because we “lost 1 degree of freedom” to estimate the mean.
在前面的示例中(均值和标准差),我们在计算平均值后计算了标准差,对分母使用n-1 ,因为我们“损失了1个自由度”以估算均值。
In this context, the standard deviation gets renamed as the “standard error” but the formula should look analogous:
在这种情况下,标准偏差将重命名为“标准误差”,但公式应类似于:

Just as before, we compare the sum of squares of the difference between each measured value y and its predicted value. We used up p degrees of freedom to compute the estimate, so only N–p are left.
和以前一样,我们比较每个测量值y和其预测值之间的差的平方和。 我们用完了p个自由度来计算估计值,因此只剩下了Np个。
岭回归 (Ridge Regression)
In Ridge Regression, we add a regularization term to our loss function. Done properly, this increases bias in our coefficient but decreases variance to result in overall lower error in our predictions.
在Ridge回归中,我们向损失函数添加一个正则项。 如果做得正确,这会增加我们系数的偏差,但会减少方差,从而使我们的预测总体上降低误差。
Using our definition of degrees of freedom, we can compute the effective number of parameters in a ridge regression. We would expect the regularization to decrease this below the original number p of parameters (since they no longer freely vary).
使用自由度的定义,我们可以计算岭回归中参数的有效数量。 我们期望正则化将其减少到参数的原始数量p以下(因为它们不再自由变化)。
We go through the same steps to compute the hat matrix as in linear regression.
我们采用与线性回归相同的步骤来计算帽子矩阵。
- The loss function gets an extra term with a fixed, known hyper-parameter λ setting the amount of regularization.损失函数会得到一个额外的项,其中包含固定的已知超参数λ,用于设置正则化量。

2. We take the derivative, set it equal to 0, and solve for β. I is the identity matrix here
2.我们取导数,将其设置为0,然后求解β。 我是这里的身份矩阵
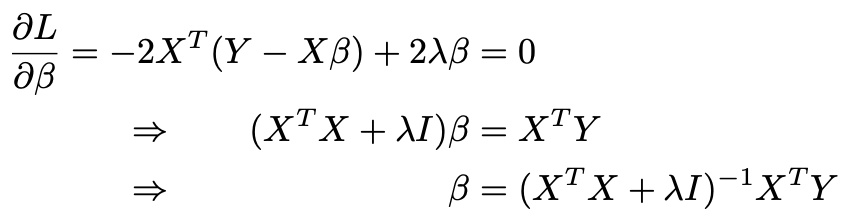
3. We compute the fitted values and extract the hat matrix H. The formula is the same as last time except that we add λ to each diagonal entry of the matrix in parentheses.
3.我们计算拟合值并提取帽子矩阵H。 该公式与上一次相同,只是我们在括号中的矩阵的每个对角线条目中添加了λ。

4. We use the singular value decomposition to choose bases for the vector spaces containing Y and β so that we can write X as a diagonal matrix, and compute H.
4.我们使用奇异值分解为包含Y和β的向量空间选择基数,以便我们可以将X编写为对角矩阵,并计算H。

Which leaves us with the following formulas for the degrees of freedom of regular (λ = 0) regression and Ridge regression (λ>0) in terms of the singular values d, indexed by i.
对于正则( d = 0)的正则(λ= 0)回归和Ridge回归(λ> 0)的自由度,我们得到以下公式: 由i索引。

讨论区 (Discussion)
The above calculations using the singular value decomposition give us a good perspective on Ridge Regression.
以上使用奇异值分解的计算为我们提供了有关岭回归的良好视角。
First of all, if the design matrix is perfectly (multi-)collinear, one of its singular values will be 0. A common case where this happens is if there are more covariates than samples. This is a problem in a regular regression because it means the term in parentheses in the hat matrix isn’t invertible (the denominators are 0 in the formula above). Ridge regression fixes this problem by adding a positive term to each squared singular value.
首先,如果设计矩阵是完全(多)共线性的,则其奇异值之一将为0。发生这种情况的一种常见情况是协变量比样本多。 这是常规回归中的一个问题,因为这意味着帽子矩阵中括号内的项是不可逆的(上式中的分母为0)。 Ridge回归通过向每个平方的奇异值添加一个正项来解决此问题。
Second, we can see that the coefficient shrinkage is high for terms with a small singular value. Such terms correspond to components of the β estimate that have high variance in a regular regression (due to high correlation between regressor). On the other hand, for terms with a higher singular value, the shrinkage is comparatively smaller.
其次,我们可以看到奇异值小的项的系数收缩率很高。 这样的项对应于在常规回归中具有高方差的β估计值的组成部分(由于回归变量之间的相关性很高)。 另一方面,对于奇异值较高的项,收缩率相对较小。
The degrees of freedom calculation we have done perfectly encapsulates this shrinkage to give us an estimate for the effective number of parameters we actually used. Note also that the singular values are a function of the design matrix X and not of Y. That means that you could, in theory, choose λ by computing the number of effective parameters you want and finding λ to achieve that.
我们完成的自由度计算完美地封装了这种收缩,从而可以估算出我们实际使用的有效参数数量。 还要注意,奇异值是设计矩阵X的函数,而不是Y的函数。这意味着从理论上讲,您可以通过计算所需的有效参数数量并找到λ来实现这一目的,从而选择λ。
推论与模型选择 (Inference and Model Selection)
In our vanilla regression examples we saw that the standard error (or standard deviation) can be computed by assuming that we started with N degrees of freedom and subtracting out the number of effective parameters we used. This doesn’t necessarily make as much sense with the Ridge, which gives a biased estimator for the coefficients (albeit with lower mean-squared error for correctly chosen λ). In particular, the residuals are no longer nicely distributed.
在我们的原始回归示例中,我们看到可以通过假设我们以N个自由度开始并减去所使用的有效参数的数量来计算标准误差(或标准差)。 对于Ridge来说,这不一定有意义,因为它为系数提供了一个有偏估计量(尽管正确选择的λ的均方误差较低)。 特别是,残差不再很好地分布。
Instead, we can use our effective number of parameters to plug into the AIC (Akaike Information Criterion), an alternative to cross-validation for model selection. The AIC penalizes models for having more parameters and approximates the expected test error if we were to use a held-out test set. Then choosing λ to optimize it can replace cross-validation, provided we use the effective degrees of freedom in the formula for the AIC. Note, however, that if we choose λ adaptively before computing the AIC, then there are extra effective degrees of freedom added.
相反,我们可以使用有效数量的参数插入AIC (Akaike信息准则),这是模型选择的交叉验证的替代方法。 如果我们使用保留的测试集,AIC会对具有更多参数的模型进行惩罚,并近似预期的测试误差。 如果我们在AIC公式中使用有效自由度,那么选择λ进行优化可以代替交叉验证。 但是请注意,如果我们在计算AIC之前自适应地选择λ,则会增加额外的有效自由度。
K最近邻回归 (K-Nearest Neighbors Regression)
As a final example, consider k-nearest neighbors regression. It should be apparent that the fitted value for each data point is the average of k nearby points, including itself. This means that the degrees of freedom is
作为最后一个示例,请考虑k最近邻回归。 显然,每个数据点的拟合值是附近k个点(包括其自身)的平均值。 这意味着自由度是

This enables us to do model comparison between different types of models (for example, comparing k-nearest neighbors to a ridge regression using the AIC as above).
这使我们能够在不同类型的模型之间进行模型比较(例如,使用上述AIC将k最近邻与岭回归进行比较)。
I hope you see that the degrees of freedom is a very general measure and can be applied to all sorts of regression models (kernel regression, splines, etc.).
我希望您看到自由度是一个非常通用的度量,可以应用于各种回归模型(内核回归,样条曲线等)。
结论 (Conclusion)
Hopefully this article will give you a more solid understanding of degrees of freedom and make the whole concept less of a vague statistical idea. I mentioned that there are other, closely related, definitions of degrees of freedom. The other main version is a geometric idea. If you want to know more about that, read my article about the geometric approach to linear regression. If you want to understand more of the algebra we did to compute the degrees of freedom, read a non-algebraic approach to the singular value decomposition.
希望本文能使您对自由度有更扎实的理解,并使整个概念不再是模糊的统计概念。 我提到过,还有其他与自由度密切相关的定义。 另一个主要版本是几何构想。 如果您想进一步了解这一点,请阅读我有关线性回归的几何方法的文章。 如果您想了解更多关于代数的知识,我们可以计算自由度,请阅读有关奇异值分解的非代数方法。
笔记 (Notes)
[1] Specifically I’m counting (a) the geometric definition for a random vector; (b) the closely related degrees of freedom of probability distributions; (c) 4 formulas for the regression degrees of freedom; and (d) 3 formulas for the residual degrees of freedom. You might count differently but will hopefully see my point that there are several closely related ideas and formulas with subtle differences.
[1]具体来说,我是在计算(a)随机向量的几何定义; (b)概率分布的自由度密切相关; (c)4个回归自由度公式; (d)剩余自由度的3个公式。 您可能会有所不同,但希望能看到我的观点,即有一些密切相关的想法和公式存在细微的差异。
翻译自: https://towardsdatascience.com/the-official-definition-of-degrees-of-freedom-in-regression-faa04fd3c610
逻辑回归 自由度
http://www.taodudu.cc/news/show-2722302.html
相关文章:
- 矩阵、方程自由度的理解
- 程序员如何实现财务自由?
- 自由职业一段时间后的感悟
- 统计学中的自由度
- 《自由在高处》读后感
- 什么是自由度?
- 不自由的自由职业
- t检验自由度的意义_在统计中自由度是什么?
- 自由
- t检验自由度的意义_统计学中自由度的理解和应用
- 自由度
- 哇,你也想自由职业啊
- 你口口声声想要的自由
- 想自由
- python opencv 读取mov文件
- 常见的文件格式
- html怎样自动播放视频,html5自动播放mov格式视频的实例代码
- NextCloud前端支持播放mov文件
- c语言lst文件,Keil C51 之LST文件
- mov 指令用c语言写,汇编总结:mov指令
- Unity3d 利用 AvproVideo 播放带透明通道mov视频在部分电脑无法播放的解决方案
- mov格式解析
- ffmpeg将mov格式的视频转换成mp4格式
- Mov文件字幕添加与播放
- 常见文件头 类型
- Mac上怎么把mov文件转成gif文件
- Mov文件格式对mdat和moov的分析
- [日常]mov文件转换为gif
- 使用Python 批量转移*.tif和*.mov文件
- Mov文件格式分析
逻辑回归 自由度_回归自由度的官方定义相关推荐
- java 回归遍历_回归基础:代码遍历
java 回归遍历 This article guides you through the basics of regression by showing code and thorough expl ...
- logistic回归 简介_金融专业进!逻辑回归模型简述
逻辑回归模型 逻辑回归属于机器学习中的较为经典的模型,在很多金融专业的实证部分都会用到逻辑回归.接下来分成以下几个部分对逻辑回归模型进行介绍. 1. 模型简介 逻辑回归中的"逻辑" ...
- 逻辑回归 数据_数据科学中的逻辑回归
逻辑回归 数据 逻辑回归 (Logistic Regression) Logistic regression is an applied mathematics analysis methodolog ...
- softmax分类器_[ML] 逻辑回归与 Softmax 回归
Logistic Regression (LR) 译为逻辑回归,但实际上这是一种分类模型(二分类或多分类).下面精要地把模型中的核心概念.推导梳理一下.本文主要内容如下: 逻辑回归的概率模型 逻辑回归 ...
- lasso回归_线性回归amp;lasso回归amp;岭回归介绍与对比
1. 回顾最小二乘法 详细的解释在以下这个链接 https://www.matongxue.com/madocs/818 简而言之,最小二乘法展现了平方误差值最小的时候,就是最好的拟合回归线. 2. ...
- lasso回归和岭回归_如何计划新产品和服务机会的回归
lasso回归和岭回归 Marketers sometimes have to be creative to offer customers something new without the lux ...
- xgboost算法_回归建模的时代已结束,算法XGBoost统治机器学习世界
作者 | 冯鸥 发布 | ATYUN订阅号 Vishal Morde讲了这样一个故事:十五年前我刚完成研究生课程,并以分析师的身份加入了一家全球投资银行.在我工作的第一天,我试着回忆我学过的一切.与此 ...
- 广义线性模型(逻辑回归、泊松回归)
线性回归模型也并不适用于所有情况,有些结果可能包含而元数据(比如正面与反面)或者计数数据,广义线性模型可用于解释这类数据,使用的仍然是自变量的线性组合. 目录 逻辑回归 使用statsmodels 使 ...
- R语言广义线性模型函数GLM、广义线性模型(Generalized linear models)、GLM函数的语法形式、glm模型常用函数、常用连接函数、逻辑回归、泊松回归、系数解读、过散度分析
R语言广义线性模型函数GLM.广义线性模型(Generalized linear models).GLM函数的语法形式.glm模型常用函数.常用连接函数.逻辑回归.泊松回归.系数解读.过散度分析 目录
最新文章
- 全网最具深度的三次握手、四次挥手讲解,深夜思考
- 内存体系 用共享段于进程间联系
- 零基础考信息系统项目管理师要怎么准备?
- itstime后面跟什么_被父母当成摇钱树是种什么体验?
- python中能够处理的最大整数是_实例讲解Python中整数的最大值输出
- vb.net 组合快捷键如何设置_你不知道的PPT快捷键
- Linux 命令(78)—— rmdir 命令
- 天津东软实训第八天------倒排索引
- PID算法C语言实现
- Unable to validate using XSD: Your JAXP provider does not support XML Schema
- 牛顿法求临界水深c语言程序,基于牛顿迭代法的圆形断面临界水深直接计算法邹武停.pdf...
- phpstorm官方下载地址
- 数据中台建设(四):企业构建数据中台评估
- GoodSync(最好的文件同步软件)
- POJ Haybale Guessing
- 【oracle】 字段属性为 date 的相关操作
- Mybatis---多表联合查询(1)
- Java8 lambda表达式,Comparator.comparing().thenComparing()报错
- java 编译期常量
- C++四种类型转换总结