深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)(转)...
转自https://zhuanlan.zhihu.com/p/22252270 作者:ycszen
前言
(标题不能再中二了)本文仅对一些常见的优化方法进行直观介绍和简单的比较,各种优化方法的详细内容及公式只好去认真啃论文了,在此我就不赘述了。
SGD
此处的SGD指mini-batch gradient descent,关于batch gradient descent, stochastic gradient descent, 以及 mini-batch gradient descent的具体区别就不细说了。现在的SGD一般都指mini-batch gradient descent。
SGD就是每一次迭代计算mini-batch的梯度,然后对参数进行更新,是最常见的优化方法了。即:
其中,是学习率,
是梯度 SGD完全依赖于当前batch的梯度,所以
可理解为允许当前batch的梯度多大程度影响参数更新
缺点:(正因为有这些缺点才让这么多大神发展出了后续的各种算法)
- 选择合适的learning rate比较困难 - 对所有的参数更新使用同样的learning rate。对于稀疏数据或者特征,有时我们可能想更新快一些对于不经常出现的特征,对于常出现的特征更新慢一些,这时候SGD就不太能满足要求了
- SGD容易收敛到局部最优,并且在某些情况下可能被困在鞍点【原来写的是“容易困于鞍点”,经查阅论文发现,其实在合适的初始化和step size的情况下,鞍点的影响并没这么大。感谢@冰橙的指正】
Momentum
momentum是模拟物理里动量的概念,积累之前的动量来替代真正的梯度。公式如下:
其中,是动量因子
特点:
- 下降初期时,使用上一次参数更新,下降方向一致,乘上较大的
能够进行很好的加速
- 下降中后期时,在局部最小值来回震荡的时候,
,
- 在梯度改变方向的时候,
Nesterov
nesterov项在梯度更新时做一个校正,避免前进太快,同时提高灵敏度。 将上一节中的公式展开可得:
可以看出,并没有直接改变当前梯度
,所以Nesterov的改进就是让之前的动量直接影响当前的动量。即:
所以,加上nesterov项后,梯度在大的跳跃后,进行计算对当前梯度进行校正。如下图:
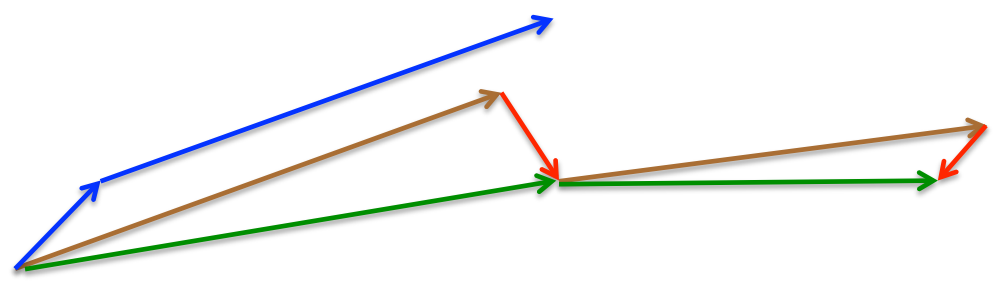
momentum首先计算一个梯度(短的蓝色向量),然后在加速更新梯度的方向进行一个大的跳跃(长的蓝色向量),nesterov项首先在之前加速的梯度方向进行一个大的跳跃(棕色向量),计算梯度然后进行校正(绿色梯向量)
其实,momentum项和nesterov项都是为了使梯度更新更加灵活,对不同情况有针对性。但是,人工设置一些学习率总还是有些生硬,接下来介绍几种自适应学习率的方法
Adagrad
Adagrad其实是对学习率进行了一个约束。即:
此处,对从1到
进行一个递推形成一个约束项regularizer,
,
用来保证分母非0
特点:
- 前期
较小的时候, regularizer较大,能够放大梯度
- 后期
- 适合处理稀疏梯度
缺点:
- 由公式可以看出,仍依赖于人工设置一个全局学习率
设置过大的话,会使regularizer过于敏感,对梯度的调节太大
- 中后期,分母上梯度平方的累加将会越来越大,使
Adadelta
Adadelta是对Adagrad的扩展,最初方案依然是对学习率进行自适应约束,但是进行了计算上的简化。 Adagrad会累加之前所有的梯度平方,而Adadelta只累加固定大小的项,并且也不直接存储这些项,仅仅是近似计算对应的平均值。即:
在此处Adadelta其实还是依赖于全局学习率的,但是作者做了一定处理,经过近似牛顿迭代法之后:
其中,代表求期望。
此时,可以看出Adadelta已经不用依赖于全局学习率了。
特点:
- 训练初中期,加速效果不错,很快
- 训练后期,反复在局部最小值附近抖动
RMSprop
RMSprop可以算作Adadelta的一个特例:
当时,
就变为了求梯度平方和的平均数。
如果再求根的话,就变成了RMS(均方根):
此时,这个RMS就可以作为学习率的一个约束:
特点:
- 其实RMSprop依然依赖于全局学习率
- RMSprop算是Adagrad的一种发展,和Adadelta的变体,效果趋于二者之间
- 适合处理非平稳目标 - 对于RNN效果很好
Adam
Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。公式如下:
其中,,
分别是对梯度的一阶矩估计和二阶矩估计,可以看作对期望
,
的估计;
,
是对
,
的校正,这样可以近似为对期望的无偏估计。 可以看出,直接对梯度的矩估计对内存没有额外的要求,而且可以根据梯度进行动态调整,而
对学习率形成一个动态约束,而且有明确的范围。
特点:
- 结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
- 对内存需求较小
- 为不同的参数计算不同的自适应学习率
- 也适用于大多非凸优化 - 适用于大数据集和高维空间
Adamax
Adamax是Adam的一种变体,此方法对学习率的上限提供了一个更简单的范围。公式上的变化如下:
可以看出,Adamax学习率的边界范围更简单
Nadam
Nadam类似于带有Nesterov动量项的Adam。公式如下:
可以看出,Nadam对学习率有了更强的约束,同时对梯度的更新也有更直接的影响。一般而言,在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果。
经验之谈
- 对于稀疏数据,尽量使用学习率可自适应的优化方法,不用手动调节,而且最好采用默认值
- SGD通常训练时间更长,但是在好的初始化和学习率调度方案的情况下,结果更可靠
- 如果在意更快的收敛,并且需要训练较深较复杂的网络时,推荐使用学习率自适应的优化方法。
- Adadelta,RMSprop,Adam是比较相近的算法,在相似的情况下表现差不多。
- 在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果
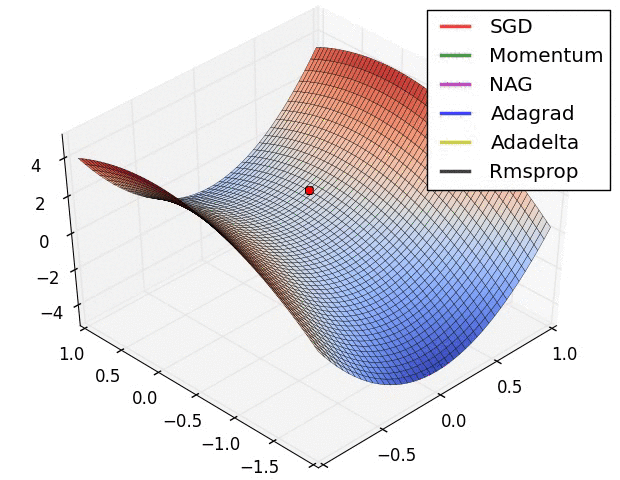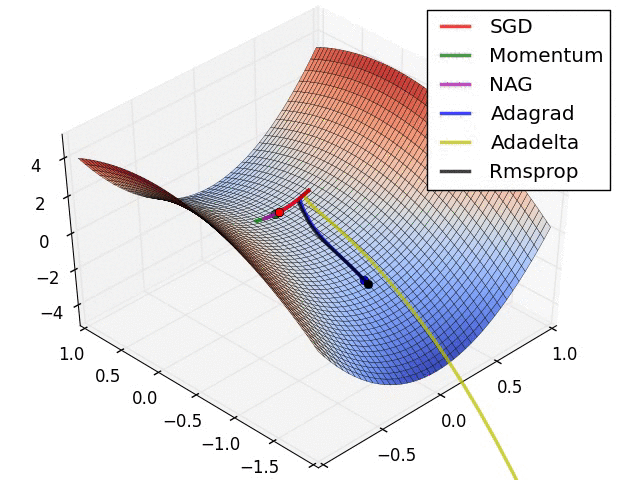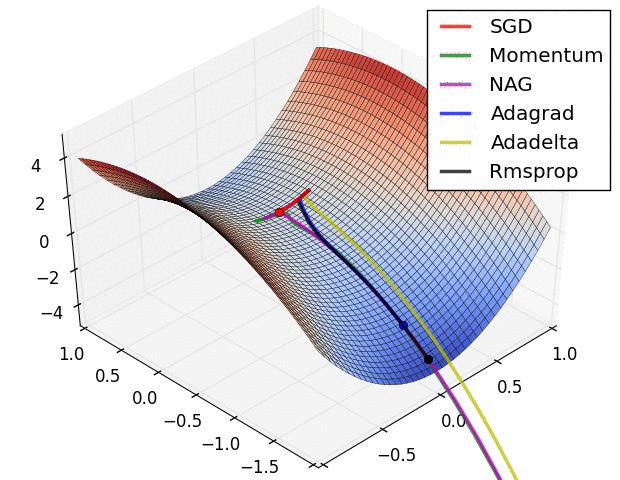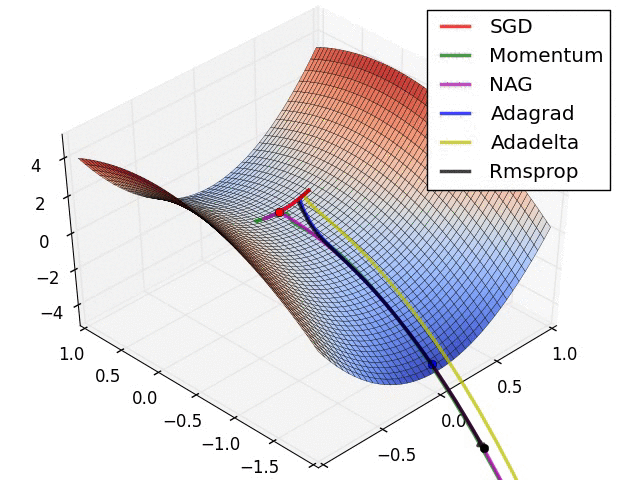
最后展示两张可厉害的图,一切尽在图中啊,上面的都没啥用了... ...
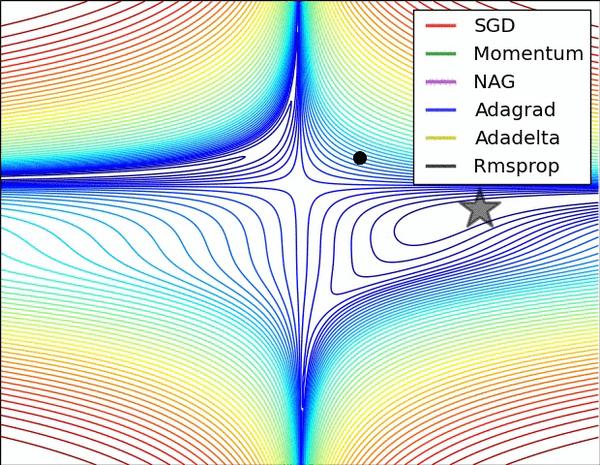 损失平面等高线
损失平面等高线
 在鞍点处的比较
在鞍点处的比较
转载须全文转载且注明作者和原文链接,否则保留维权权利
引用
[1]Adagrad
[2]RMSprop[Lecture 6e]
[3]Adadelta
[4]Adam
[5]Nadam
[6]On the importance of initialization and momentum in deep learning
[7]Keras中文文档
[8]Alec Radford(图)
[9]An overview of gradient descent optimization algorithms
[10]Gradient Descent Only Converges to Minimizers
[11]Deep Learning:Nature
转载于:https://www.cnblogs.com/ocean1100/articles/7648681.html
深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)(转)...相关推荐
- 深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)
前言 (标题不能再中二了)本文仅对一些常见的优化方法进行直观介绍和简单的比较,各种优化方法的详细内容及公式只好去认真啃论文了,在此我就不赘述了. SGD 此处的SGD指mini-batch gradi ...
- 深度学习——误差反向传播法
前言 通过数值微分的方法计算了神经网络中损失函数关于权重参数的梯度,虽然容易实现,但缺点是比较费时间,本章节将使用一种高效的计算权重参数梯度的方法--误差方向传播法 本文将通过①数学式.②计算图,这两 ...
- 2017年深度学习优化算法最新进展:改进SGD和Adam方法
2017年深度学习优化算法最新进展:如何改进SGD和Adam方法 转载的文章,把个人觉得比较好的摘录了一下 AMSGrad 这个前期比sgd快,不能收敛到最优. sgdr 余弦退火的方案比较好 最近的 ...
- 深度学习必备:随机梯度下降(SGD)优化算法及可视化
补充在前:实际上在我使用LSTM为流量基线建模时候,发现有效的激活函数是elu.relu.linear.prelu.leaky_relu.softplus,对应的梯度算法是adam.mom.rmspr ...
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
深度学习笔记(一):logistic分类 深度学习笔记(二):简单神经网络,后向传播算法及实现 深度学习笔记(三):激活函数和损失函数 深度学习笔记:优化方法总结 深度学习笔记(四):循环神经 ...
- USC提出拟牛顿法深度学习优化器Apollo,效果比肩SGD和Adam
©作者 | Xuezhe Ma 单位 | USC助理教授 研究方向 |NLP.机器学习 摘要 本文介绍了 Apollo,一种针对非凸随机优化的拟牛顿方法.它通过对角矩阵逼近 Hessian,动态地将损 ...
- 深度学习:优化方法——momentum、Nesterov Momentum、AdaGrad、Adadelta、RMSprop、Adam
深度学习:优化方法 1. 指数加权平均(Exponentially weighted average) 2. 带偏差修正的指数加权平均(bias correction in exponentially ...
- 深度学习系列之随机梯度下降(SGD)优化算法及可视化
补充在前:实际上在我使用LSTM为流量基线建模时候,发现有效的激活函数是elu.relu.linear.prelu.leaky_relu.softplus,对应的梯度算法是adam.mom.rmspr ...
- 【pytorch EarlyStopping】深度学习之早停法入门·相信我,一篇就够。
这个方法更好的解决了模型过拟合问题. EarlyStopping的原理是提前结束训练轮次来达到"早停"的目的,故训练轮次需要设置的大一点以求更好的早停(比如可以设置100epoch ...
最新文章
- eclipse git:Transport Error: Cannot get remote repository refs. invalid advertisement of
- 【转】VB中NEW的用法(申请内存空间)
- linux内核代码container_of
- 【机器人】项目疑难杂症
- oracle 高级dba,DAVE老师Oracle DBA高级运维深入解析实战班 高级DBA运维视频 Oracle视频教程...
- 有关彩票的python编程教程入门_python入门教程NO.6 用python做个简单的彩票号码统计分析工具...
- 53、Docker镜像仓库(搭建私有的镜像仓库(浏览器可以访问))
- iOS清理缓存的简单实现
- powerpoint预览_如何调整PowerPoint模板的大小
- day23面向对象第一篇
- 活动并发测试-1000个不同用户同时并发请求报名笔记
- 微信小程序出现报错:Uncaught ReferenceError: __g is not defined
- 关于使用ComponentName连接俩个Activity运行闪退的问题
- Emgucv使用中常用函数总结
- IntelliJ IDEA 2019 激活注册码
- (47)【漏洞发现】漏扫工具合集、WAF绕过分类
- 一个2层隐层神经网络解决抑或问题
- AXI USB 2.0设备IP Core指导手册(第一章)
- web前端100道面试题
- 马哥linux学习笔记 重定向
热门文章
- Lc101对称二叉树
- 2017 ACM-ICPC 亚洲区(乌鲁木齐赛区)网络赛 E. Half-consecutive Numbers
- 七种方法实现单例模式
- swagger -- 前后端分离的API接口
- LuaForUnity1:Lua介绍与使用
- Codeforces Round #202 (Div. 1): D. Turtles(Lindström–Gessel–Viennot lemma定理+DP)
- bzoj 3355: [Usaco2004 Jan]有序奶牛(拓扑排序+bitset)
- bzoj 1786 bzoj 1831: [Ahoi2008]Pair 配对(DP)
- c#实现linux中gzip压缩解压缩算法:byte[]字节数组,文件,字符串,数据流的压缩解压缩
- labelme批量json_to_dataset转换