A Multi-task Ensemble Framework for Emotion, Sentiment and Intensity Prediction
文章目录
- 前提
- Motivation
- 方法概述
- 方法详述
- Datasets
- Evaluation Benchmark Datasets
- Evaluation Transfer Learning Datasets
- Approach
- Encoder with Category Name Embedding
- Multi-Task Decoders
- Type 1
- Type 2
- Type 3
- Experiments
- 非增量学习
- 增量学习
- 想法
前提
- 这一篇论文的很大一部分关注点在于多任务学习方法应用于 (T)ACSA incremental learning tasks。
- 我对于 targeted aspectcategory sentiment analysis(TACSA) 任务的理解是,其与 ACSA 的不同在于,后者中的 aspect 都是针对某个 target 的;而前者中的 aspect 可能是针对不同的 target 的。
- TACSA 任务中每个 aspect 需要指明其对应的 target,所以正常需要预定义 target 和 aspect 及 target-category 对,英文中为 predefined target-category pairs,作者为了简明这部分的表达,将其简称为 predefined categories。
Motivation
目前的多任务学习模型在(T)ACSA任务的输入中缺少 “category name” 的特征。
根据(T)ACSA 任务中的预定义类别训练得到的模型在新应用遇到新类别时不灵活。示意图如下:
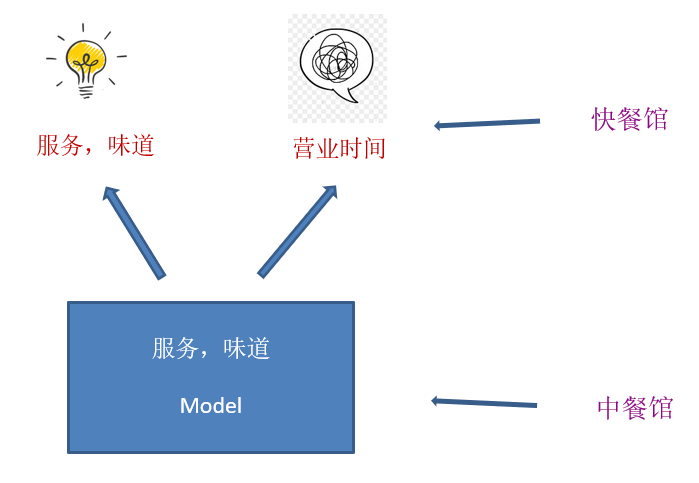
例如,我们源领域是中餐馆的评论,评论里只包含“服务”和“味道”,基于此我们训练了一个模型 A。但是可能因为快餐馆的评论不多,没办法用数据训练得到一个好的模型,所以我们希望用模型 A 来对快餐馆进行属性级情感分析,而快餐馆顾客多了一个“营业时间”类别,使得直接用模型 A 不现实。
为了解决这部分,作者用了增量学习。
迁移学习中比较常见也比较难解决的问题,即 catastrophic forgetting problem(灾难性遗忘问题)。
作者对于这部分的解决思路基于迁移学习中的正则化方法。那这个方法究竟做了什么呢?如下图:

这个方法的原理可以看成,新任美国总统上来,其他重要职务的人不要轻易地换,否则像特朗普这样大胆地人指不定将原来稳定的政治生态糟蹋成什么样。这个方法放到具体的任务中就如下图:
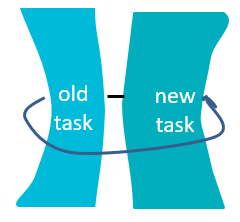
即在引入新任务时,要在原本的目标函数中加入一项正则化项,这个正则化项主要用来约束“新”模型与“旧”模型的差异性,让模型不要修改“旧”模型太多(即像图中所示一样,将“新”、“旧”绑在一起)。
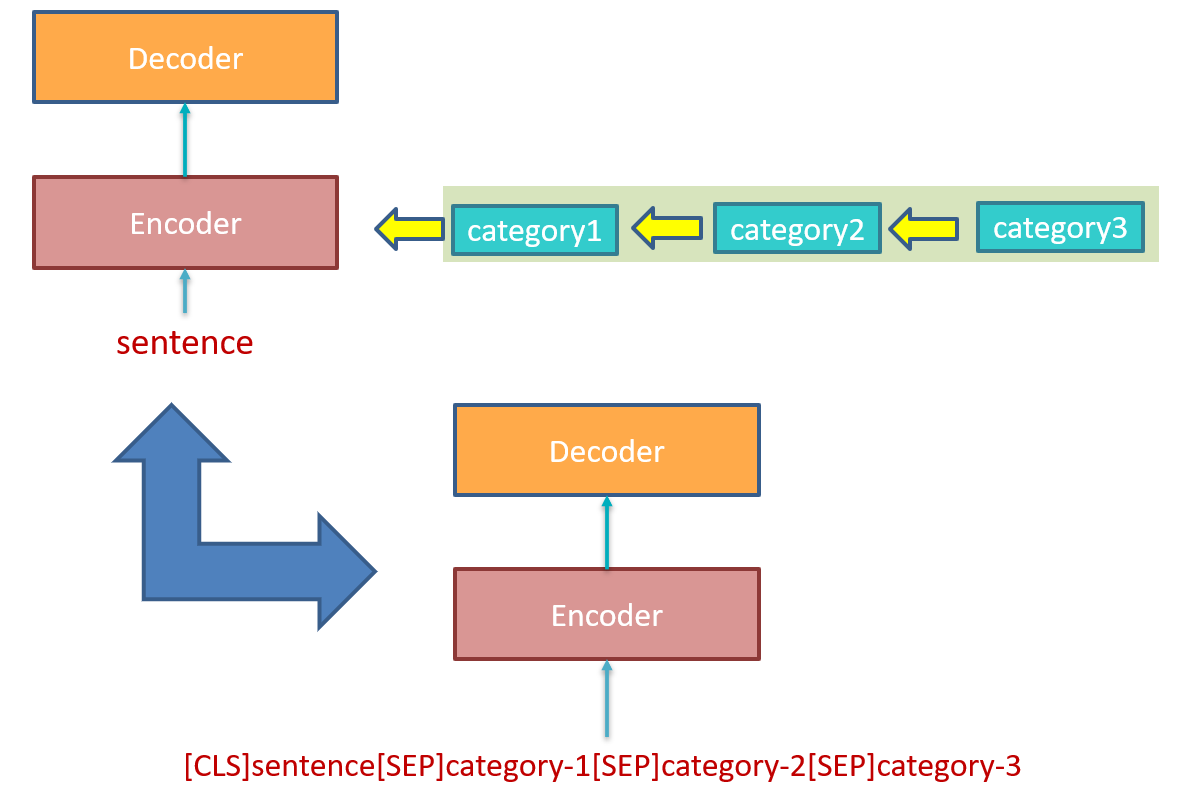
因为对于 (T)ACSA 任务增加的任务是增加新类别的情感分类,按刚刚说的正则化方法的思路,解决思路应该是“新”与“旧”差别别太大。而 (T)ACSA 多任务的做法之前都是 encoder 共享,decoder 按各个类别独立,所以想让差别变小,就应该让 decoder 之间别差太多,由此作者提出了 decoder 也共享的做法来解决灾难性遗忘问题。其变化如下图。
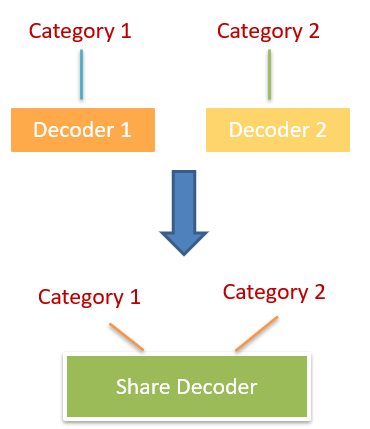
- 如果按作者共享 decoder 的做法,则会引起一个新的问题,即如何识别 encoder 和 decoder 共享网络中的每个类别?在作者的方法中,作者通过输入 category name feature 来解决类别识别问题。(这一点也变相解释了 Motivation 中的第一点)。方法的思路就如下图所示,我们很难分辨出韩国明星,所以我们给其加上名字就难不住啦。

方法概述
本文为了使多任务学习对增量学习可行,作者提出了 Category Name Embedding network(CNE-net)。作者在所有类别之间设置编码器和解码器均共享,以削弱灾难性的遗忘问题。除了输入句子外,作者还加入了另一个输入特征,即类别名称来取分不同任务(即预测不同的 categories 的情感极性)。
方法详述
Datasets
Evaluation Benchmark Datasets
作者用两个数据集来评价 CNE-net 模型的性能,即用 SemEval-2014 Task4 来评价 ACSA 任务以及 SentiHood 来评价 TACSA 任务。
(PS:作者是用一个 joint model(连接 ACD model 和 ACSA model)来完成 ACSA 任务的。)
Evaluation Transfer Learning Datasets
将 SemEval-2014 Task4 和 SentiHood 改动一下之后分别用于评价 ACSA 和 TACSA 的增量学习任务。改动方法为将原本的数据集划分为 sorce 和 target 两部分,具体如下图:
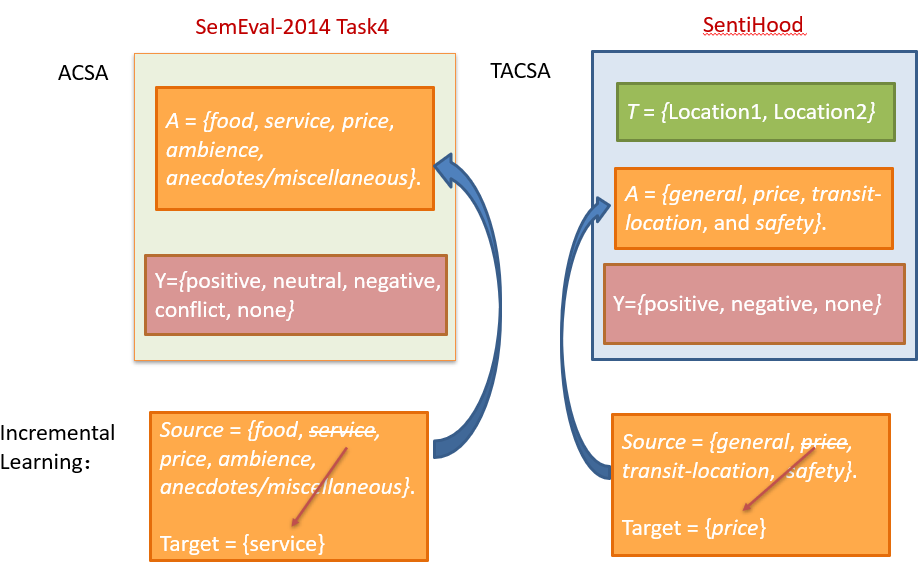
作者分别将 SemEval-2014 Task4 和 SentiHood 数据集中 aspect category 里的 “service” 和 “price" 作为 target domain 的 aspect category,剩下的作为 source domain 的 aspect category。
作者将处理后的数据集分别命名为 SemEval14-Task-inc 和 Sentihood-inc。下面为这个数据集中的一个具体的例子:

作者构造的数据集怎么用呢?其实就是先在 source data 上训练出 model,之后再在 target data 上微调即可。
Approach
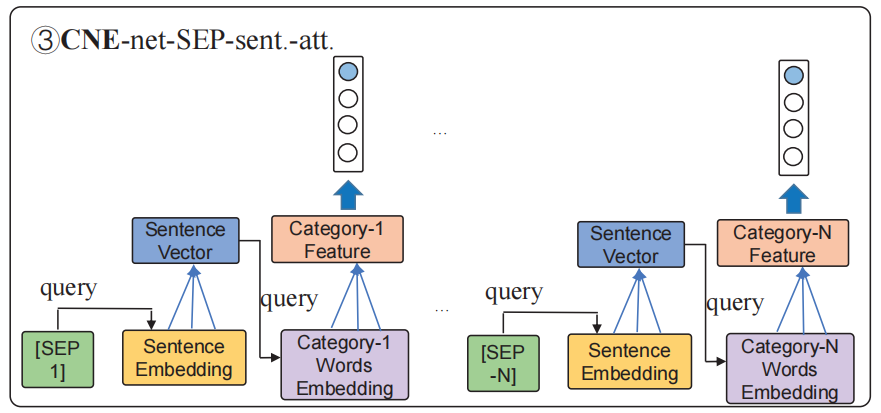
作者提出的模型是要利用 BERT 的。BERT 最经典的分类做法是输入 “[CLS] tokens in sentence [SEP]”,之后利用 [CLS] 的隐状态得到分类结果,而因为作者需要模型的输入加入 category name 来区别不同任务,并且要同时分析每个 category 的情感极性,所以作者要修改一下经典 BERT 的 encoder 和 decoder 部分。
整个模型的框架图如 Figure 1 所示:
Encoder with Category Name Embedding
与原始的 BERT 的做法不同,作者为了利用 category name 这一特征在增量学习中,在 input 中加入了 category name,形式为 “[CLS] sentence words input [SEP] category1 input [SEP] category2 input [SEP]…[SEP] categoryN input[SEP]”。
- ACSA 任务中 category name 为 “{food, service, price, ambiance, and anecdotes/miscellaneous}”。
- TACSA 任务中 category name 为 “{location-1 general, location-1 price, location-1 transit-location, location-1 safety, location-2 general, location-2 price, location-2 transit-location, and location-2 safety}”。
将 input 送入 encoder 之后得到隐状态,作者将各部分的隐状态分别标记如下:
- [CLS]:h⃗[CLS]∈Rd\vec{h}_{[CLS]} ∈ R^dh[CLS]∈Rd
- sentence:Hsent∈RLsent×d\Eta_{sent} ∈ R^{L_{sent}×d}Hsent∈RLsent×d,LsentL_{sent}Lsent 代表 sentence 中 word 的个数。
- [SEP]:HSEP∈Rncat×d\Eta_{SEP} ∈ R^{n_{cat}×d}HSEP∈Rncat×d
- category:Hcat−i∈RLcat−i×d\Eta_{cat-i} ∈ R^{L_{cat-i}×d}Hcat−i∈RLcat−i×d,其中 i 代表第 i 个 category(0<i<ncat0 < i < n_{cat}0<i<ncat),ncatn_{cat}ncat 为 categories 的个数,Lcat−iL_{cat-i}Lcat−i 为第 i 个 category 的 word 的个数。
其中 ddd 为隐状态的维数。
Multi-Task Decoders
作者提出了三种类型的 decoder,见 Figure 1 中的①、②、③。
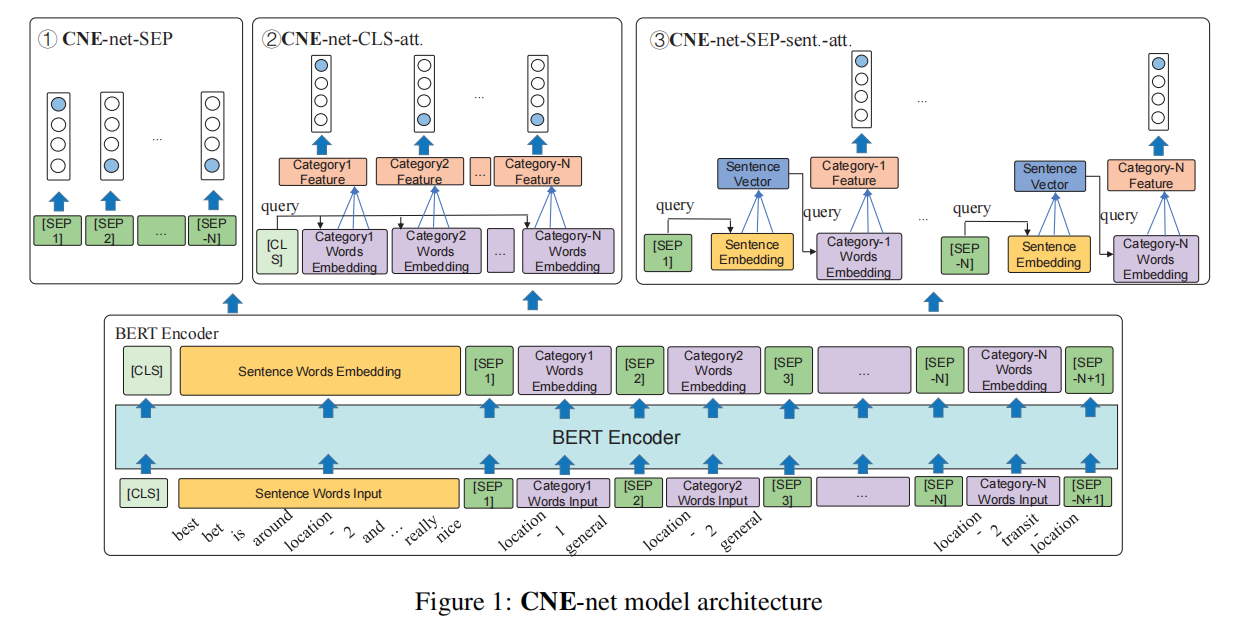
Type 1
CNE-net-SEP,这个 decoder 就是直接利用 [SEP] 的隐状态得到其后跟着的 category 的情感极性。示意图如下:
公式如下:
fi⃗=Wi⋅h⃗+b⃗i;pi⃗=softmax(f⃗i)(1)\vec{f_i} = W_i·\vec{h} + \vec{b}i;\vec{p_i} = softmax(\vec{f}_i) \tag1 fi
其中 fi⃗,pi⃗∈Rs\vec{f_i}, \vec{p_i} ∈ R^sfi,pi∈Rs,sss 为情感类别数(用于 ACSA 的 SemEval14-Task4 中,sss 为 5,5类具体为 {positive, neutral, negative, conflflict and none};用于 TACSA 的 Sentihood 中,sss 为 3,3 类具体为 {positive, negative and none})。
注意:作者设置 W1=W2=⋯=WncatW_1 = W_2 = \dots = W_{n_{cat}}W1=W2=⋯=Wncat 以及 b1⃗,b2⃗,…,bncat⃗\vec{b_1},\vec{b_2},\dots,\vec{b_{n_{cat}}}b1
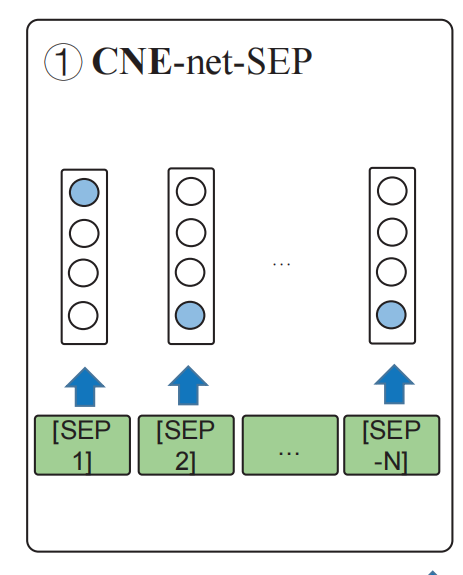
Type 2
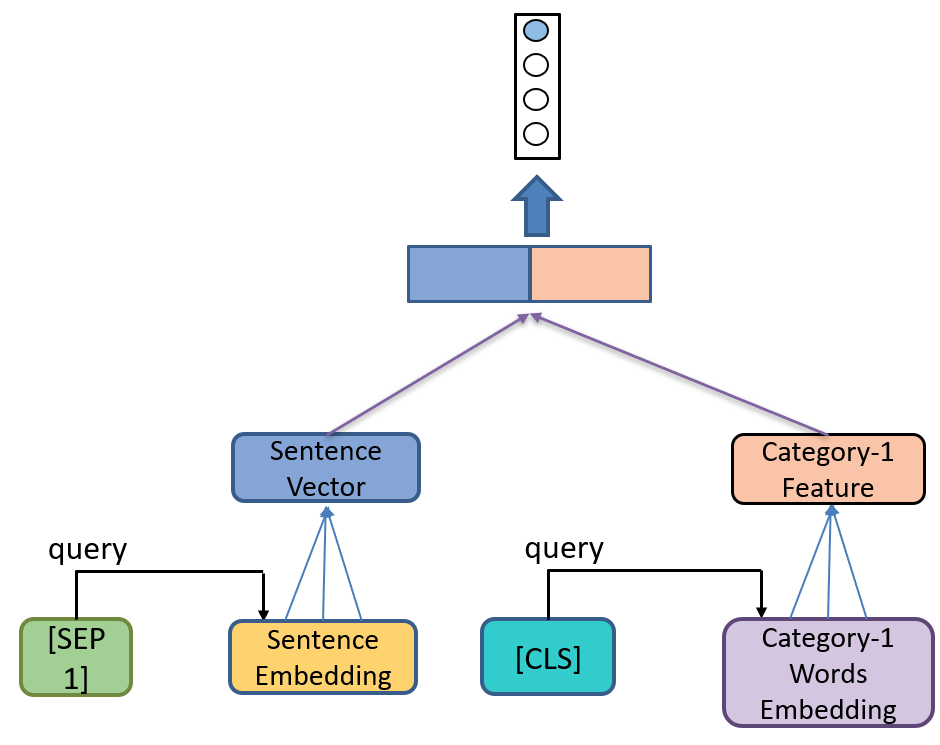
CNE-net-CLS-att,Type 1 没有考虑上下文对 aspect 的影响,所以 Type 2 加入了基于内容的注意力机制,示意图如下:
如图所示,针对每个 category 该模型都要用一次注意力机制,其中 [CLS] 的隐状态作为 query,待情感分类的 category 对应的 category words 的隐状态作为 key 和 value。公式如下:
e⃗cati=softmax(h⃗[CLS]⋅Hcat−i)⋅Hcat−i(2)\vec{e}_{cat_i} = softmax(\vec{h}_{[CLS]}·\Eta_{cat-i})·\Eta_{cat-i} \tag2 e
e⃗cati\vec{e}_{cat_i}ecati 为 category embedding vector,将其当成公式(1)中的 h⃗\vec{h}h,之后按公式(1)计算就可得到该 category 的情感极性。
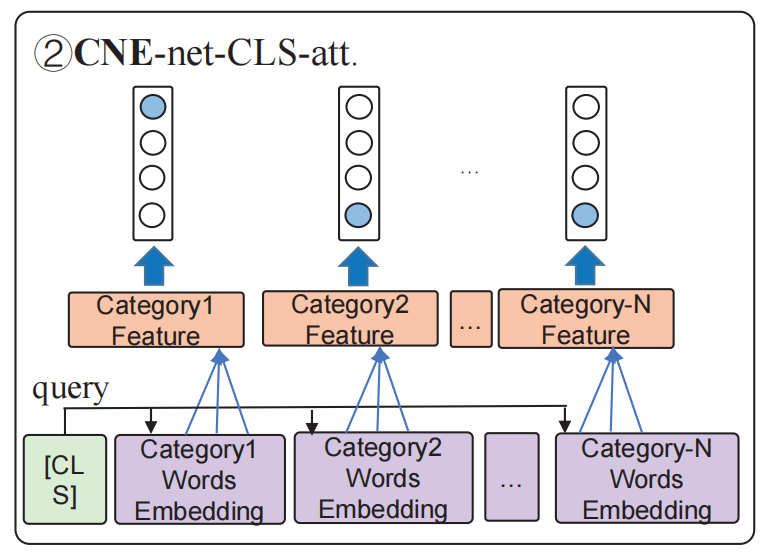
Type 3
CNE-net-SEP-sent.-att,之前 ABSC 的论文中提到,context 对考虑 aspect 有帮助,同样 aspect 也对考虑 context 有帮助,所以除了 Type 2 中做的利用 content 来得到 category embedding 以外,Type 3 还利用了 category name 来得到 sentence embedding。所以 Type 3 其实是对 content 和 category 都利用 attention 机制。示意图如下:
同样,利用 attention 也是针对每个 category 的情感分类的。
对于第 iii 个 category,首先根据这个 category name 得到 sentence vector h⃗sent−i\vec{h}_{sent-i}h
h⃗sent−i=softmax(h⃗[SEP−i]⋅Hsent)⋅Hsent(3)\vec{h}_{sent-i} = softmax(\vec{h}_{[SEP-i]}·\Eta_{sent})·\Eta_{sent} \tag3 hsent−i=softmax(h[SEP−i]⋅Hsent)⋅Hsent(3)
之后将 h⃗sent−i\vec{h}_{sent-i}hsent−i 当作 Type 2 中的 h⃗[CLS]\vec{h}_{[CLS]}h[CLS],计算得到 category embedding vector e⃗cati\vec{e}_{cat_i}ecati,公式如下:
e⃗cati=softmax(h⃗sent−i⋅Hcat−i)⋅Hcat−i(4)\vec{e}_{cat_i} = softmax(\vec{h}_{sent-i}·\Eta_{cat-i})·\Eta_{cat-i} \tag4 ecati=softmax(hsent−i⋅Hcat−i)⋅Hcat−i(4)
之后同 Type 2 的做法。
Experiments
非增量学习
首先实验结果如下:
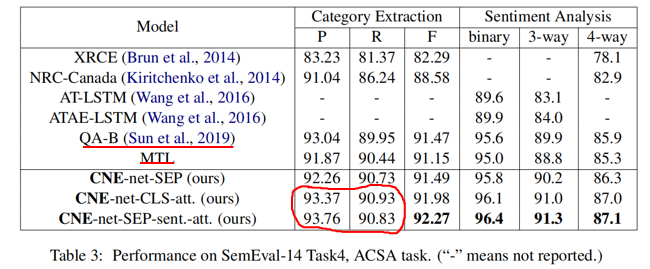
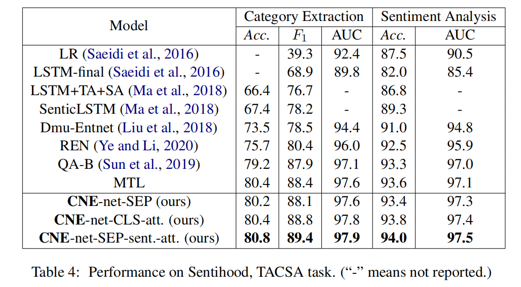
非增量学习时,QA-B(单任务模型) 和 MTL(多任务模型) 的结果差距不大,证明设计得好的单任务模型其效果也是不弱的。
ACSA task 中 CNE-net-SEP-sent.-att 的 Precision 和 Recall 分别大于和小于 CNE-net-CLS-att.,我认为这是因为前者在 SemEval-14-Task4 这个比较简单的数据集上想多了(比如,明明这句话没提到某个 category,但是其模型“想”得有点儿多,反而判断失误了。这就像司马懿中诸葛亮的空城计一般,是自己多疑造成的结果。)

而在更复杂一点儿的 Sentihood 数据集上 CNE-net-SEP-sent.-att 的 Precision 和 Recall 都大于了 CNE-net-CLS-att.,这也印证了我的猜想。
增量学习
实验结果如下:
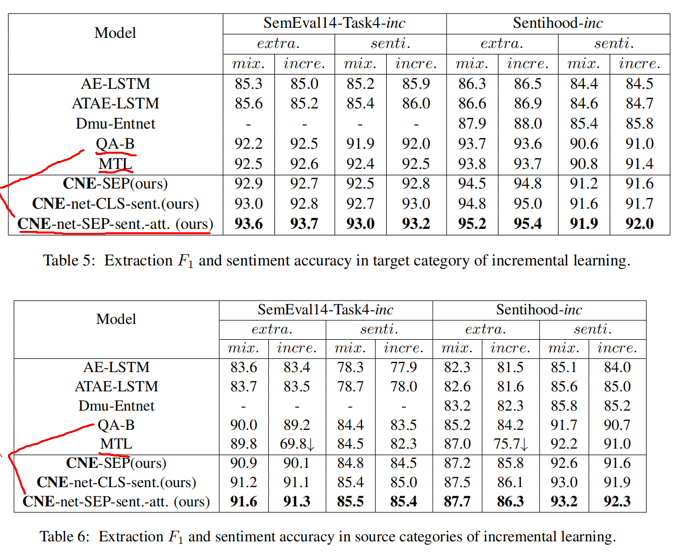
其实从两个表中可以看到 QA-B 和 CNE-net-SEP-sent.-att. 差别没有特别大,我认为这是因为作者提出的这种多任务方法其实本质上与单任务方法类似。
想法
- 其实我认为作者提出的这个方法的思想过程是一个鸡生蛋蛋生鸡的问题。为什么这么说呢,先看下面的示意图:
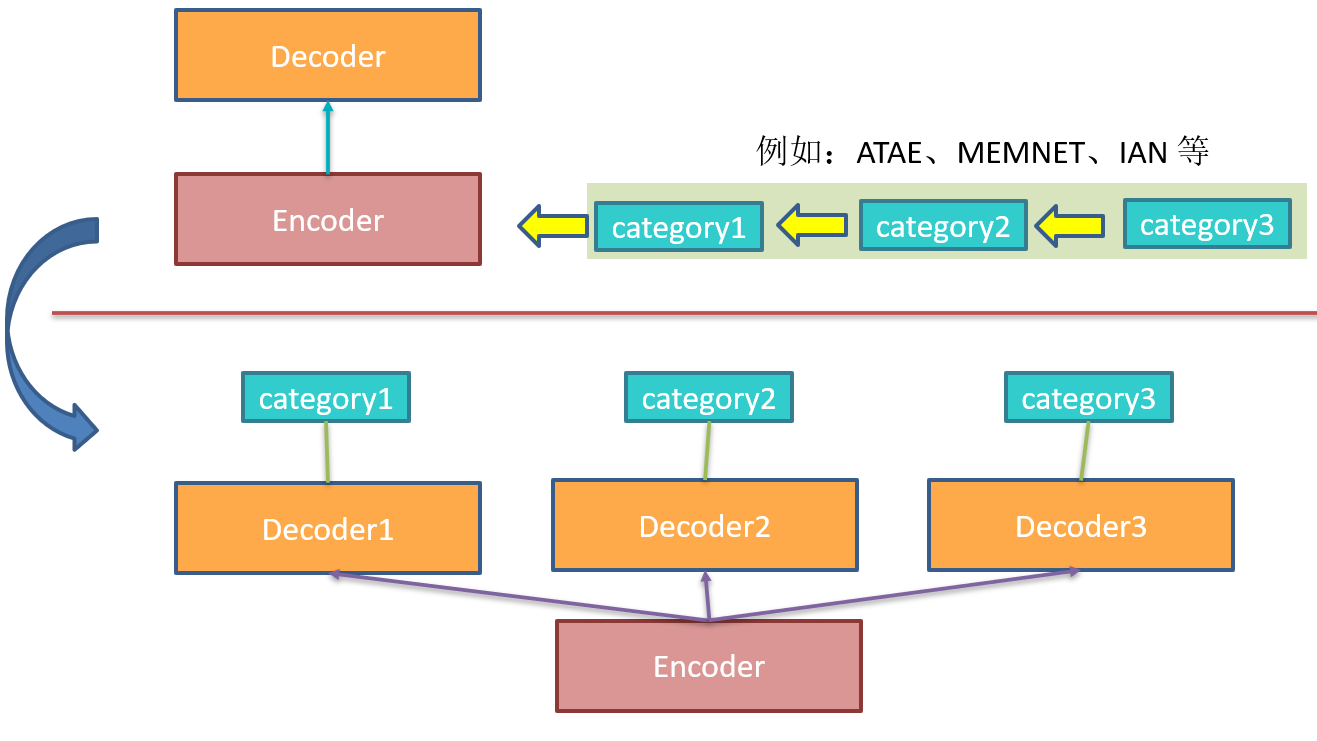
首先在前些年提出的解决 ACSC 问题的 model 中是不能同时预测多个 category 的情感极性,所以其实这些模型可以看成对一个 category 共享 decoder 的模型。之后为了同时预测多个 category 提出了多个 decoder 的 model。
之后根据该文的 Motivation 作者提出了共享 decoder 的思想,但是我们可以从上图看到,其实作者的这种做法与将多个 category 多次送入只预测一个 category 的 model 的做法区别不大,其做法仅仅是改变了输入的内容(即加上了多个 category name,但事实上,即使不加这些 name,而是额外地依次给每个 category 的信息也是可以的)。
我认为作者这种做法是抛弃了多个 decoder 的优势,所以我认为可以试着增加不同任务(预测不同 category 情感极性)之间的交互。
- 作者设计的共享 decoder 部分还是比较简单,所以我认为可以对这部分进行一些改进,举个简单的例子:
可以在 decoder 部分模仿 IAN 的方法(如上图所示)或其他更有效的方法。
A Multi-task Ensemble Framework for Emotion, Sentiment and Intensity Prediction相关推荐
- Multi task learning多任务学习背景简介
2020-06-16 23:22:33 本篇文章将介绍在机器学习中效果比较好的一种模式,多任务学习(Multi task Learning,MTL).已经有一篇机器之心翻译的很好的博文介绍多任务学习了 ...
- multi task训练torch_采用single task模型蒸馏到Multi-Task Networks
论文地址. 这篇论文主要研究利用各个single task model来分别作为teacher model,用knowledge distillation的方法指导一个multi task model ...
- 多智能体强化学习Multi agent,多任务强化学习Multi task以及多智能体多任务强化学习Multi agent Multi task概述
概述 在我之前的工作中,我自己总结了一些多智能体强化学习的算法和通俗的理解. 首先,关于题目中提到的这三个家伙,大家首先想到的就是强化学习的五件套: 状态:s 奖励:r 动作值:Q 状态值:V 策略: ...
- 17. A Unified Generative Framework for Aspect-Based Sentiment Analysis
A Unified Generative Framework for Aspect-Based Sentiment Analysis 论文地址:https://arxiv.org/pdf/2106.0 ...
- DeepGBM: A Deep Learning Framework Distilled by GBDT for Online Prediction Tasks
DeepGBM: A Deep Learning Framework Distilled by GBDT for Online Prediction Tasks 论文链接:https://dl.acm ...
- 论文笔记:《DeepGBM: A Deep Learning Framework Distilled by GBDT for Online Prediction Tasks》
论文笔记:<DeepGBM: A Deep Learning Framework Distilled by GBDT for Online Prediction Tasks> 摘要 1. ...
- multi task训练torch_Multi-task Learning的三个小知识
本文译自Deep Multi-Task Learning – 3 Lessons Learned by Zohar Komarovsky 在过去几年里,Multi-Task Learning (MTL ...
- Multi Task Learning在工业界如何更胜一筹
摘要: 本文主要介绍多任务学习和单任务学习的对比优势以及在工业界的一些使用.如何从单任务学习转变为多任务学习?怎样使AUC和预估的准确率达到最佳?如何对实时性要求较高的在线应用更加友好?本文将以淘宝实 ...
- multi task训练torch_Pytorch多机多卡分布式训练
被这东西刁难两天了,终于想办法解决掉了,来造福下人民群众. 关于Pytorch分布训练的话,大家一开始接触的往往是DataParallel,这个wrapper能够很方便的使用多张卡,而且将进程控制在一 ...
最新文章
- Multiple substitutions specified in non-positional format; did you mean to add the formatted=”false”
- 霸气侧漏HTML5--之--canvas(1) api + 弹球例子
- Framebuffer 机制
- android 自定义 进度条 旋转,Android_Android ProgressBar进度条使用详解,ProgressBar进度条,分为旋转进 - phpStudy...
- 【软件测试】测试计划书
- react.js 给标识ref,获取内容
- oracle学习总结1
- 用开源组件jcaptcha做jsp彩色验证码
- 再读《Java编程思想 》
- STM32 F072RB 低功耗 开发调试
- c语言中char有无符号,char代表有符号还是无符号?
- OSChina 周二乱弹 ——假装在睡觉等你搭讪等一路
- Ele SOA Container
- Java设计原则——依赖倒转原则
- PDF文件进行在线分割如何去操作
- 屏幕录制方法?如何在电脑进行屏幕录制
- dumpsys alarm 格式解读
- Windows服务器搭建Node-Media-Server视频服务器
- unity3D用图片当做字体显示————点阵字体概念
- F - Queen Collision (模拟题,找规律)
热门文章
- excel同一个单元格内多行数据拆分成多个单元格多行排列
- Java中方法调用参数传递的方式是传值,尽管传的是引用的值而不是对象的值。(Does Java pass by reference or pass by value?)
- 怎么退出自适应巡航_自适应巡航功能是何方神圣?“全速域自适应巡航”又有什么作用呢...
- CodeForces - 743B
- fni matlab,使用Matlab求解Van Der Pol方程的方法研究
- siri语音输入效果_如何输入Siri的语音命令
- 《数据结构与面向对象程序设计》第1周学习总结
- 我的网名为什么是ma6174????
- 后疫情时代的酒旅业,让用户“安心”成为行业复苏唯一解?
- 基于arduino的智能家居系统