Mutual Information
今天挺paper reading的时候,听到了最大化互信息,还不清楚互信息是个什么东东,google了一下,从
http://en.wikipedia.org/wiki/Mutual_information
摘过来了:
Definition of mutual information
Formally, the mutual information of two discrete random variables X and Y can be defined as:

where p(x,y) is the joint probability distribution function of X and Y, and p1(x) and p2(y) are the marginal probability distribution functions of X and Y respectively.
In the continuous case, we replace summation by a definite double integral:
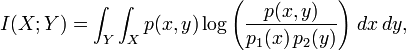
where p(x,y) is now the joint probability density function of X and Y, and p1(x) and p2(y) are the marginal probability density functions of X and Y respectively.
These definitions are ambiguous because the base of the log function is not specified. To disambiguate, the function I could be parameterized as I(X,Y,b) where b is the base. Alternatively, since the most common unit of measurement of mutual information is the bit, a base of 2 could be specified.
Intuitively, mutual information measures the information that X and Y share: it measures how much knowing one of these variables reduces our uncertainty about the other. For example, if X and Y are independent, then knowing X does not give any information about Y and vice versa, so their mutual information is zero. At the other extreme, if X and Y are identical then all information conveyed by X is shared with Y: knowing X determines the value of Y and vice versa. As a result, the mutual information is the same as the uncertainty contained in Y (or X) alone, namely the entropy of Y (or X: clearly if X and Y are identical they have equal entropy).
Mutual information quantifies the dependence between the joint distribution of X and Y and what the joint distribution would be if X and Y were independent. Mutual information is a measure of dependence in the following sense: I(X; Y) = 0 if and only if X and Y are independent random variables. This is easy to see in one direction: if X and Y are independent, then p(x,y) = p(x) × p(y), and therefore:

Moreover, mutual information is nonnegative (i.e. I(X;Y) ≥ 0; see below) and symmetric (i.e. I(X;Y) = I(Y;X)).
[edit] Relation to other quantities
Mutual information can be equivalently expressed as

where H(X) and H(Y) are the marginal entropies, H(X|Y) and H(Y|X) are the conditional entropies, and H(X,Y) is the joint entropy of X and Y. Since H(X) ≥ H(X|Y), this characterization is consistent with the nonnegativity property stated above.
Intuitively, if entropy H(X) is regarded as a measure of uncertainty about a random variable, then H(X|Y) is a measure of what Y does not say about X. This is "the amount of uncertainty remaining about X after Y is known", and thus the right side of the first of these equalities can be read as "the amount of uncertainty in X, minus the amount of uncertainty in X which remains after Y is known", which is equivalent to "the amount of uncertainty in X which is removed by knowing Y". This corroborates the intuitive meaning of mutual information as the amount of information (that is, reduction in uncertainty) that knowing either variable provides about the other.
Note that in the discrete case H(X|X) = 0 and therefore H(X) = I(X;X). Thus I(X;X) ≥ I(X;Y), and one can formulate the basic principle that a variable contains more information about itself than any other variable can provide.
Mutual information can also be expressed as a Kullback-Leibler divergence, of the product p(x) × p(y) of the marginal distributions of the two random variables X and Y, from p(x,y) the random variables' joint distribution:

Furthermore, let p(x|y) = p(x, y) / p(y). Then

Thus mutual information can thus also be understood as the expectation of the Kullback-Leibler divergence of the univariate distribution p(x) of X from the conditional distribution p(x|y) of X given Y: the more different the distributions p(x|y) and p(x), the greater the information gain.
[edit] Variations of the mutual information
Several variations on the mutual information have been proposed to suit various needs. Among these are normalized variants and generalizations to more than two variables.
[edit] Metric
Many applications require a metric, that is, a distance measure between points. The quantity
- d(X,Y) = H(X,Y) − I(X;Y)
satisfies the basic properties of a metric; most importantly, the triangle inequality, but also non-negativity, indiscernability and symmetry. In addition, one also has  , and so
, and so

The metric D is a universal metric, in that if any other distance measure places X and Y close-by, then the D will also judge them close.[1].
[edit] Conditional mutual information
Sometimes it is useful to express the mutual information of two random variables conditioned on a third.

which can be simplified as

Conditioning on a third random variable may either increase or decrease the mutual information, but it is always true that
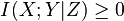
for discrete, jointly distributed random variables X, Y, Z. This result has been used as a basic building block for proving other inequalities in information theory.
[edit] Multivariate mutual information
Several generalizations of mutual information to more than two random variables have been proposed, such as total correlation and interaction information. If Shannon entropy is viewed as a signed measure in the context of information diagrams, as explained in the article Information theory and measure theory, then the only definition of multivariate mutual information that makes sense is as follows:
- I(X1) = H(X1), I(X1 | X2) = H(X1 | X2)
and for n > 1,

where (as above) we define
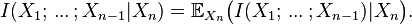
(This definition of multivariate mutual information is identical to that of interaction information except for a change in sign when the number of random variables is odd.)
[edit] Applications
Some have criticized the blind application of information diagrams used to derive the above definition, and indeed it has found rather limited practical application, since it is difficult to visualize or grasp the significance of this quantity for a large number of random variables. It can be zero, positive, or negative for any 
One high-dimensional generalization scheme that maximizes the mutual information between the joint distribution and other target variables is found be useful in feature selection.
[edit] Normalized variants
Normalized variants of the mutual information are provided by the coefficients of constraint (Coombs, Dawes & Tversky 1970) or uncertainty coefficient (Press & Flannery 1988)
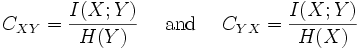
The two coefficients are not necessarily equal. A more useful and symmetric scaled information measure is the redundancy[citation needed]
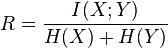
which attains a minimum of zero when the variables are independent and a maximum value of
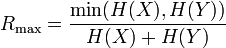
when one variable becomes completely redundant with the knowledge of the other. See also Redundancy (information theory). Another symmetrical measure is the symmetric uncertainty (Witten & Frank 2005), given by
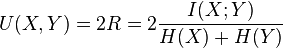
which represents a weighted average of the two uncertainty coefficients (Press & Flannery 1988).
Other normalized versions are provided by the following expressions (Yao 2003, Strehl & Ghosh 2002).
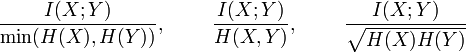
The quantity

is a metric, i.e. satisfies the triangle inequality, etc. The metric  is also a universal metric.[2]
is also a universal metric.[2]
[edit] Weighted variants
In the traditional formulation of the mutual information,

each event or object specified by (x,y) is weighted by the corresponding probability p(x,y). This assumes that all objects or events are equivalent apart from their probability of occurrence. However, in some applications it may be the case that certain objects or events are more significant than others, or that certain patterns of association are more semantically important than others.
For example, the deterministic mapping {(1,1),(2,2),(3,3)} may be viewed as stronger (by some standard) than the deterministic mapping {(1,3),(2,1),(3,2)}, although these relationships would yield the same mutual information. This is because the mutual information is not sensitive at all to any inherent ordering in the variable values (Cronbach 1954, Coombs & Dawes 1970, Lockhead 1970), and is therefore not sensitive at all to the form of the relational mapping between the associated variables. If it is desired that the former relation — showing agreement on all variable values — be judged stronger than the later relation, then it is possible to use the following weighted mutual information (Guiasu 1977)

which places a weight w(x,y) on the probability of each variable value co-occurrence, p(x,y). This allows that certain probabilities may carry more or less significance than others, thereby allowing the quantification of relevant holistic or prägnanz factors. In the above example, using larger relative weights for w(1,1), w(2,2), and w(3,3) would have the effect of assessing greater informativeness for the relation {(1,1),(2,2),(3,3)} than for the relation {(1,3),(2,1),(3,2)}, which may be desirable in some cases of pattern recognition, and the like. There has been little mathematical work done on the weighted mutual information and its properties, however.
[edit] Absolute mutual information
Using the ideas of Kolmogorov complexity, one can consider the mutual information of two sequences independent of any probability distribution:
- IK(X;Y) = K(X) − K(X | Y).
To establish that this quantity is symmetric up to a logarithmic factor ( ) requires the chain rule for Kolmogorov complexity (Li 1997). Approximations of this quantity via compression can be used to define a distance measure to perform a hierarchical clustering of sequences without having any domain knowledge of the sequences (Cilibrasi 2005).
) requires the chain rule for Kolmogorov complexity (Li 1997). Approximations of this quantity via compression can be used to define a distance measure to perform a hierarchical clustering of sequences without having any domain knowledge of the sequences (Cilibrasi 2005).
[edit] Applications of mutual information
In many applications, one wants to maximize mutual information (thus increasing dependencies), which is often equivalent to minimizing conditional entropy. Examples include:
- The channel capacity is equal to the mutual information, maximized over all input distributions.
- Discriminative training procedures for hidden Markov models have been proposed based on the maximum mutual information (MMI) criterion.
- RNA secondary structure prediction from a multiple sequence alignment.
- Mutual information has been used as a criterion for feature selection and feature transformations in machine learning. It can be used to characterize both the relevance and redundancy of variables, such as the minimum redundancy feature selection.
- Mutual information is often used as a significance function for the computation of collocations in corpus linguistics.
- Mutual information is used in medical imaging for image registration. Given a reference image (for example, a brain scan), and a second image which needs to be put into the same coordinate system as the reference image, this image is deformed until the mutual information between it and the reference image is maximized.
- Detection of phase synchronization in time series analysis
- In the infomax method for neural-net and other machine learning, including the infomax-based Independent component analysis algorithm
- Average mutual information in delay embedding theorem is used for determining the embedding delay parameter.
- Mutual information between genes in expression microarray data is used by the ARACNE algorithm for reconstruction of gene networks.
[edit] See also
- Pointwise mutual information
[edit] References
- ^ Alexander Kraskov, Harald Stögbauer, Ralph G. Andrzejak, and Peter Grassberger, "Hierarchical Clustering Based on Mutual Information", (2003) ArXiv q-bio/0311039
- ^ Kraskov, et al. ibid.
- Cilibrasi, R.; Paul Vitányi (2005). "Clustering by compression" (PDF). IEEE Transactions on Information Theory 51 (4): 1523–1545. doi:.
- Coombs, C. H., Dawes, R. M. & Tversky, A. (1970), Mathematical Psychology: An Elementary Introduction, Prentice-Hall, Englewood Cliffs, NJ.
- Cronbach L. J. (1954). On the non-rational application of information measures in psychology, in H Quastler, ed., Information Theory in Psychology: Problems and Methods, Free Press, Glencoe, Illinois, pp. 14—30.
- Kenneth Ward Church and Patrick Hanks. Word association norms, mutual information, and lexicography, Proceedings of the 27th Annual Meeting of the Association for Computational Linguistics, 1989.
- Guiasu, Silviu (1977), Information Theory with Applications, McGraw-Hill, New York.
- Li, Ming; Paul Vitányi (1997). An introduction to Kolmogorov complexity and its applications. New York: Springer-Verlag. ISBN 0387948686.
- Lockhead G. R. (1970). Identification and the form of multidimensional discrimination space, Journal of Experimental Psychology 85(1), 1-10.
- Athanasios Papoulis. Probability, Random Variables, and Stochastic Processes, second edition. New York: McGraw-Hill, 1984. (See Chapter 15.)
- Press, W. H., Flannery, B. P., Teukolsky, S. A. & Vetterling, W. T. (1988), Numerical Recipes in C: The Art of Scientific Computing, Cambridge University Press, Cambridge, p. 634
- Strehl, Alexander; Joydeep Ghosh (2002). "Cluster ensembles -- a knowledge reuse framework for combining multiple partitions" (PDF). Journal of Machine Learning Research 3: 583–617. doi:.
- Witten, Ian H. & Frank, Eibe (2005), Data Mining: Practical Machine Learning Tools and Techniques, Morgan Kaufmann, Amsterdam.
- Yao, Y. Y. (2003) Information-theoretic measures for knowledge discovery and data mining, in Entropy Measures, Maximum Entropy Principle and Emerging Applications , Karmeshu (ed.), Springer, pp. 115-136.
- Peng, H.C., Long, F., and Ding, C., "Feature selection based on mutual information: criteria of max-dependency, max-relevance, and min-redundancy," IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 27, No. 8, pp.1226-1238, 2005. Program
- Andre S. Ribeiro, Stuart A. Kauffman, Jason Lloyd-Price, Bjorn Samuelsson, and Joshua Socolar, (2008) "Mutual Information in Random Boolean models of regulatory networks", Physical Review E, Vol.77, No.1. arXiv:0707.3642.
Mutual Information相关推荐
- 机器学习特征筛选:互信息法(mutual information)
机器学习特征筛选:互信息法(mutual information) 互信息法多为分类问题的分类变量的筛选方法 经典的互信息也是评价定性自变量对定性因变量的相关性的,为了处理定量数据,最大信息系数法被提 ...
- Feature Selection Based on Mutual Information:Criteria of Max-Dependency, Max-Relevance,and Min-Redu
Feature Selection Based on Mutual Information:Criteria of Max-Dependency, Max-Relevance,and Min-Redu ...
- 双目立体匹配经典算法之Semi-Global Matching(SGM)概述:匹配代价计算之互信息(Mutual Information,MI)...
半全局立体匹配算法Semi-Global Matching,SGM由学者Hirschmüller在2005年所提出1,提出的背景是一方面高效率的局部算法由于所基于的局部窗口视差相同的假设在很多情况 ...
- Mutual Information Neural Estimation梳理
Mutual Information Neural Estimation 原文 参考:https://ruihongqiu.github.io/posts/2020/07/mine/ 背景 互信息可以 ...
- 机器学习笔记 - 互信息Mutual Information
1.概述 遇到一个新的数据集时重要的第一步是使用特征效用指标构建排名,该指标是衡量特征与目标之间关联的函数.然后,您可以选择一小部分最有用的功能进行初始开发. 我们将使用的度量称为"互信息& ...
- 概率机器学习中的互信息(Mutual Information)
1.Mutual Information概念 互信息是信息论中用以评价两个随机变量之间的依赖程度的一个变量 2.信息论的基础概念 信息量: 是对某个时间发生的概率的度量,通常来讲一个事件发生的概率越低 ...
- 互信息(Mutual Information)
本文根据以下参考资料进行整理: 1.维基百科:https://zh.wikipedia.org/wiki/%E4%BA%92%E4%BF%A1%E6%81%AF 2.新浪博客:http://blog. ...
- 互信息(Mutual Information)的介绍
互信息,Mutual Information,缩写为MI,表示两个变量X与Y是否有关系,以及关系的强弱. 如果 (X, Y) ~ p(x, y), X, Y 之间的互信息 I(X; Y)定义为: No ...
- Normalized Mutual information
在写论文做数据测试时有用到一个nmi(normalized mutual information)评价聚类的一种方法,不是很清楚,然后上网找了一下资料. 首先在理解nmi前,先说说mutual inf ...
- mutual information matlab,Mutual information and Normalized Mutual information 互信息和标准化互信息...
实验室最近用到nmi( Normalized Mutual information )评价聚类效果,在网上找了一下这个算法的实现,发现满意的不多. 浙江大学蔡登教授有一个,http://www.zju ...
最新文章
- Java 代码多线程问题
- Matlab画图小结(二)
- 数码管时钟程序C语言00到99,[单片机]ACT89C51数码管时钟程序
- 简洁明了——STL容器库之set头文件常用函数集合
- PHP开发erp账号登陆问题,浪潮ERP软件E系列创建账套时提示“由于登陆不正确、请重新登陆” | 浪潮888博客...
- Quartz作业调度框架及时间表达式的含义和语法
- 《阿里巴巴Android开发手册》v1.0.1更新,优化部分内容和示例代码
- RabbitMQ消息队列简单异步邮件发送和订单异步处理实战【应用解耦】【异步削峰】
- 过拟合解决方法python_欠拟合、过拟合及其解决方法
- Exchange 服务器可支持性矩阵
- kali linux之选择和修改exp与windows后渗透
- App.config 中读写appSettings、system.serviceModel终结点,以及自定义配置节
- 构建工具Bazel入门
- 移动App测试中Android测试和IOS测试有啥区别
- 【个人学习记录】RoboWare Studio安装使用
- 《Adobe Premiere Pro CS6中文版经典教程》——1.3 扩展工作流
- HTML5+CSS大作业——汽车自驾游(10页) 主题HTM5网页设计作业成品
- java aes 中文_java实现AES加密(解决中文解密后乱码问题,解决传输字符串后解密报错的问题)...
- 数据可视化 —— 小练习1 KMeans聚类并数据可视化图像像素点
- (11)EKF - (3) EKF3匹配度和Lane切换