十分钟解决爬虫问题!超轻量级反爬虫方案
本文将描述一种尽量简单的反爬虫方案,可以在十几分钟内解决部分简单的爬虫问题,缓解恶意攻击或者是系统超负荷运行的状况;至于复杂的爬虫以及更精准的防御,需要另外讨论。

爬虫和反爬虫日益成为每家公司的标配系统。爬虫在情报获取、虚假流量、动态定价、恶意攻击、薅羊毛等方面都能起到很关键的作用,所以每家公司都或多或少的需要开发一些爬虫程序,业界在这方面的成熟的方案也非常多;有矛就有盾,每家公司也相应的需要反爬虫系统来达到数据保护、系统稳定性保障、竞争优势保持的目的。
然而,一方面防守这事ROI不好体现,另一方面反爬虫这种系统,相对简单的爬虫来说难度和复杂度都要高很多,往往需要一整套大数据解决方案才能把事情做好,因此只有少量的公司可以玩转起来。当出现问题的时候,很多公司往往束手无策。
本文将描述一种尽量简单的反爬虫方案,可以在十几分钟内解决部分简单的爬虫问题,缓解恶意攻击或者是系统超负荷运行的状况;至于复杂的爬虫以及更精准的防御,需要另外讨论。
整套方案会尽量简单易懂,不会涉及到专门的程序开发,同时尽量利用现有的组件,避免额外组件的引入。内容上主要分为三大部分:
- 访问数据获取。采集用户的访问数据,用来做爬虫分析的数据源
- 爬虫封禁。当找到爬虫后,想办法去阻断它后续的访问
- 爬虫分析。示例通过简单策略来分析出爬虫
简单的数据获取
数据获取是做好反爬虫系统的关键,常见的几种模式
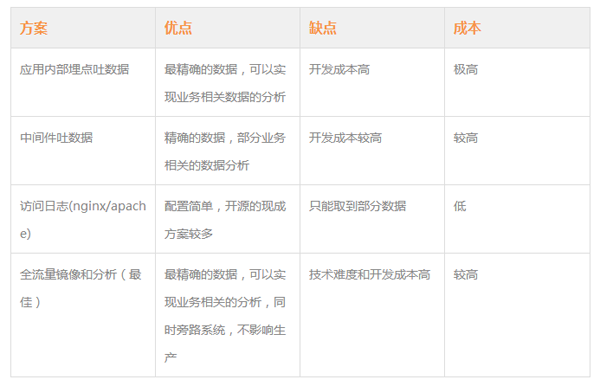
本篇,采用nginx的日志方式,这种只需要通过对常见的nginx最简单的配置就能从远程获取相应的访问日志
官方nginx配置:
- log_format warden '" "$remote_addr" "$remote_port" "$server_addr" "$server_port" "$request_length" "$content_length" "$body_bytes_sent" "$request_uri" "$host" "$http_user_agent" "$status" "$http_cookie" "$request_method" "$http_referer" "$http_x_forwarded_for" "$request_time" "$sent_http_set_cookie" "$content_type" "$upstream_http_content_type" "$request_body"\n';
- access_log syslog:server=127.0.0.1:9514 warden ;
tengine配置(编译时带上--with-syslog)
- log_format warden '" "$remote_addr" "$remote_port" "$server_addr" "$server_port" "$request_length" "$content_length" "$body_bytes_sent" "$request_uri" "$host" "$http_user_agent" "$status" "$http_cookie" "$request_method" "$http_referer" "$http_x_forwarded_for" "$request_time" "$sent_http_set_cookie" "$content_type" "$upstream_http_content_type" "$request_body"\n';
- access_log syslog:user::127.0.0.1:9514 warden ;
这里面需要注意的是:
- 由于较老的nginx官方版本不支持syslog,所以tengine在这块功能上做了单独的开发(需要通过编译选项来启用),在不确定的情况下,请修改配置 文件后先使用(nginx -t)来测试一下,如果不通过,需要重新在configure时加上syslog选项,并编译。
- 尽量获取了跟爬虫相关的数据字段,如果有定制的http header,可以自行加上 采用udp方式来发送syslog,可以将访问日志发送给远端分析服务,同时udp的方式保证nginx本身不会受到影响
- 访问日志拿不到响应的具体内容(nginx有办法搞定,但有代价),无法支持业务相关的防护
简单的爬虫封禁
反爬虫最后的生效,需要靠合理的封禁模式,这里比较几种模式:

本段将介绍基于iptables的方案,虽然适用范围较小;但是依赖少,可以通过简单配置linux就能达到效果。
第一步
- 安装ipset。ipset扩充了iptables的基本功能,可以提供更加高效的访问控制
- # centos 6.5上面安装非常简单
- sudo yum install -y ipset
第二步
在iptables中建立相应的ipset,来进行访问权限的封禁
- # 新增用于封禁的ipset
- sudo ipset -N --exist warden_blacklist iphash
- # 增加相应的iptables规则
- sudo iptables -A INPUT -m set --set warden_blacklist src -j DROP
- # 保存iptables
- sudo service iptables save
第三步
获取当前封禁的ip黑名单,并导入到iptables里面去
- sudo ipset --exist destroy warden_blacklist_tmp; sudo ipset -N warden_blacklist_tmp iphash; echo "1.1.1.1,2.2.2.2" | tr , "\n" | xargs -n 1 -I {} sudo ipset -A warden_blacklist_tmp {} ; sudo ipset swap warden_blacklist_tmp warden_blacklist
这里为了尽可能的提升效率,作了以下事情:
- 建立临时ipset,方便做操作
- 将当前封禁黑名单中的ip提取出来,加入到此ipset(示例中用了最简单的echo来展示,实际可相应调整)
- 将ipset通过原子操作与iptables正在使用的ipset作交换,以最小的代价将最新的黑名单生效
简单的爬虫策略
要能精确的分析爬虫,需要强大的数据分析平台和规则引擎,来分析这个IP/设备/用户分别在短时间区间/长时间范围里的行为特征和轨迹,这里涉及到了非常复杂的数据系统开发,本文将通过简单的shell脚本描述比较简单的规则
例子1,封禁最近100000条中访问量超过5000的ip
- nc -ul 9514 | head -100000 | awk -F '" "' '{print $2}' | sort | uniq -c | sort -nr | awk '$1>=5000 {print $2}'
这里面:
- udp服务监听nginx发过来的syslog消息,并取10000条,找到其中每条访问记录的ip
- 通过sort 和uniq来获取每个ip出现的次数,并进行降序排列
- 再通过awk找到其中超过阈值的ip,这就得到了我们所需要的结果。
例子2,封禁最近100000条中user agent明显是程序的ip
nc -ul 9514 | head -100000 | awk -F '" "' '$10 ~ /java|feedly|universalfeedparser|apachebench|microsoft url control|python-urllib|httpclient/ {print $2}' | uniq
这里面:
- 通过awk的正则来过滤出问题agent,并将相应ip输出
- 关于agent的正则表达式列出了部分,可以根据实际情况去调整和积累
当然,这里只是列举了简单的例子,有很多的不足之处
- 由于只采用了shell,规则比较简单,可以通过扩展awk或者其他语言的方式来实现更复杂的规则
- 统计的窗口是每100000条,这种统计窗口比较粗糙,好的统计方式需要在每条实时数据收到是对过去的一小段时间(例如5分钟)重新做统计计算
- 不够实时,无法实时的应对攻击行为;生产环境中,需要毫秒级的响应来应对高级爬虫
- .......
拼起来
所有模块组合起来,做一个完整的例子。假设:
- 负载均衡192.168.1.1,使用了官方nginx,并配置了syslog发往192.168.1.2
- 192.168.1.2启动nc server,每隔一段时间进行分析,找出问题ip,并吐给192.168.1.1
- 192.168.1.1通过iptables进行阻拦,数据来源于192.168.1.2的分析机器
除了nginx配置和iptables基本配置,前几段的配置略作改动:
- ### nginx conf@192.168.1.1
- log_format warden '" "$remote_addr" "$remote_port" "$server_addr" "$server_port" "$request_length" "$content_length" "$body_bytes_sent" "$request_uri" "$host" "$http_user_agent" "$status" "$http_cookie" "$request_method" "$http_referer" "$http_x_forwarded_for" "$request_time" "$sent_http_set_cookie" "$content_type" "$upstream_http_content_type" "$request_body"\n';
- access_log syslog:server=192.168.1.2:9514 warden ;
- ### 分析@192.168.1.2, 增加了结果会吐,同时每隔60分钟跑一次,把数据返回给192.168.1.1
- while true ; do nc -ul 9514 | head -100000 | awk -F '" "' '{print $2}' | sort | uniq -c | sort -nr | awk '$1>=5000 {print $2}' | tr '\n' ',' | awk '{print $0}' | socat - UDP:192.168.1.1:9515 ; sleep 3600 ; done
- ### 阻断@192.168.1.1
- #基础配置
- sudo ipset -N --exist warden_blacklist iphash
- sudo iptables -A INPUT -m set --set warden_blacklist src -j DROP
- sudo service iptables save
- #动态接收并更新iptables
- while true ; do sudo ipset --exist destroy warden_blacklist_tmp; sudo ipset -N warden_blacklist_tmp iphash; socat UDP-LISTEN:9515 - | tr , "\n" | xargs -n 1 -I {} sudo ipset -A warden_blacklist_tmp {} ;sudo ipset swap warden_blacklist_tmp warden_blacklist ; sudo ipset list ; done
以上只是简单示例,实际中还是建议换成shell脚本
总结
本文列出一种简单的反爬虫方案,由于过于简单,可以当做概念示例或者是救急方案,如果需要进一步深化,需要在以下方面去加强:
- 强化数据源,可以通过流量获得全量数据。目前爬虫等网络攻击逐渐转向业务密切相关的部分,往钱的方向靠近,所以需要更多的业务数据去支撑,而不仅仅是访问日志
- 更灵活的阻断,需要有多种阻断手段和略复杂的阻断逻辑
- 除却ip,还需要考察用户、设备指纹等多种追踪方式,应对移动环境和ipv6环境下,“IP”这一信息的力不从心
- 强化规则引擎和模型,需要考察更多用户行为的特征,仅仅从频率等手段只等应对傻爬虫,同时会造成误杀率更高
- 建立数据存储、溯源、统计体系,方便分析人员去分析数据并建立新的模型和规则。反爬虫是一件持续性行为,需要良好的平台来支撑。
- 可以根据实际需要去做好反爬虫系统的集成。比如nginx数据-->反爬系统-->nginx阻断;F5数据-->反爬系统-->F5阻断
作者介绍
陆文
岂安科技联合创始人,首席产品技术官,反爬虫专家
曾担任PayPal资深高级工程师,在可信计算,计算机风控等领域有深入的理论研究和成果;并在防欺诈和风险监控行业有多年且深厚的工作经历,擅长分布式系统和实时大数据计算。他参与岂安科技所有产品线的架构和设计,带领团队在数据挖掘、多媒体分析、跨数据中心分布式系统、高性能实时大数据计算、海量数据采集等领域进行前沿研究和产品化,帮助客户更好的解决内部的安全和风控问题。
十分钟解决爬虫问题!超轻量级反爬虫方案相关推荐
- 爬虫中的那些反爬虫措施以及解决方法
在爬虫中遇到反爬虫真的是家常便饭了,这篇博客我想结合我自己的经验将遇到过的那些问题给出来,并给出一些解决方案. 1.UserAgent UserAgent的设置能使服务器能够识别客户使用的操作系 ...
- python爬虫(二)——反爬虫机制
一.headers反爬虫 1.U-A校验 最简单的反爬虫机制应该是U-A校验了.浏览器在发送请求的时候,会附带一部分浏览器及当前系统环境的参数给服务器,这部分数据放在HTTP请求的header部分. ...
- python反爬虫策略_突破反爬虫策略
### 1.什么是爬虫和反爬虫 * **爬虫**是使用任何技术手段批量获取网站信息的一种方式,**反爬虫**是使用任何技术手段阻止别人批量获取自己网站信息的一种方式: ### 2.User-Agent ...
- python网络爬虫的基本步骤-十分钟教会你用Python写网络爬虫程序
在互联网时代,爬虫绝对是一项非常有用的技能.借助它,你可以快速获取大量的数据并自动分析,或者帮你完成大量重复.费时的工作,分分钟成为掌控互联网的大师. 注意:欲获取本文所涉及的文案,代码及教学视频的链 ...
- linux时间老是跳快6分钟,Linux超省时小技巧,让你原来要十分钟解决的问题现在只用一秒钟...
您是否在充分利用Linux?对于许多Linux用户而言,有许多有用的功能似乎可以节省时间.有时,这些省时的提示和技巧成为了需要.它们可以帮助您使用相同的命令集提高功能的效率. 这是每个Linux用户都 ...
- 【微信支付】十分钟解决内网穿透,实现微信支付本地测试
在微信小程序上调用微信支付功能.微信支付可以在本地进行测试,但无法拿到支付回调结果.也就是本地拿不到微信返回的订单号等.需要拿到支付结果回调的话,可采用服务器测试或者内网穿透到外网. 接下来分享一种内 ...
- 十分钟搞懂Java限流及常见方案
点击关注公众号:互联网架构师,后台回复 2T获取2TB学习资源! 上一篇:Alibaba开源内网高并发编程手册.pdf 文章目录 限流基本概念 QPS和连接数控制 传输速率 黑白名单 分布式环境 限流 ...
- python爬虫脚本ie=utf-8_Python反爬虫伪装浏览器进行爬虫
对于爬虫中部分网站设置了请求次数过多后会封杀ip,现在模拟浏览器进行爬虫,也就是说让服务器认识到访问他的是真正的浏览器而不是机器操作 简单的直接添加请求头,将浏览器的信息在请求数据时传入: 打开浏览器 ...
- python学习笔记分享(四十)网络爬虫(7)反爬虫问题,解决中文乱码,登陆和验证码处理
网络爬虫深度知识 一.反爬虫问题 (一)反爬虫原因 1.网络爬虫浪费了网站的流量 2.数据是私有资源 3.爬虫协议与原则 (二)反爬虫方式 (三)反反爬虫 1.原理 2.三种方法 二.解决中文乱码 ( ...
最新文章
- linux系统中find怎么用,linux系统中‘find’的详细用法
- [vue] vue生命周期总共有几个阶段?
- 1.极限——ε-δ例子_7
- php中header用法
- linux 网络io 监控,Linux教程:Linux性能监控-NetworkIO
- clr20r3 程序终止的几种解决方案_IT外包桌面解决方案——不慌,蓝屏而已
- 共享库方案解决WAS中JAR包冲突
- 开源alisql压测批处理性能
- vscode 字体太小的问题,安装新字体
- Cisco Packet Tracer 思科交换机模拟器常见命令
- 高速计数器转RS485Modbus RTU模块IBF150
- PAT 1007(简单粗暴)
- 相似度的几种常见计算方法
- SSD固态硬盘优化方案,让新买的SSD速度不再慢
- 2018总结以及2019展望
- android无法启动守护进程,Android Studio无法启动守护进程异常怎么解决?
- 微信公众号之刷卡支付
- Charles--分析网络封包的工具
- 解决hive查询parquet表报错NullPointerException异常问题(ProjectionPusher.java:118)
- jquery访问ashx文件示例