分布式场景实战第二节 分布式场景下es和mysql避坑指南
03 Elasticearch 注意要点:这三点你不得不知
02 讲中我们提到 Elasticsearch 能在短时间内搜索、分析大量数据,并作为查询数据的存储系统。坦白地说,Elasticsearch 确实是个好东西,毕竟它在分布式开源搜索和分析引擎中处于领先地位。不过它也存在不少的坑,以至于我身边几个好朋友经常跟我抱怨 ES 多么多么不好用。
对于 Elasticsearch 而言,我们想掌握好这门技术,除需要对它的用法了如指掌外,还需要对技术中的各种坑了然于心。因此,03 讲我结合个人实战经验总结出了关于 ES 的 3 大知识要点:如何使用 Elasticsearch 设计表结构?Elasticsearch 如何修改表结构?ES 的坑有哪些?
在正式讲解前,如果你使用过 ES,学习起来会更容易一些,没使用过也没关系,通过 03 讲的学习你也能了解 ES 的基本原理和 ES 的那些坑。
如何使用Elasticsearch 设计表结构?
我们知道 ES 是基于索引的设计,它没办法像 MySQL 那样使用 join 查询,所以,查询数据时我们需要把每条主数据及关联子表的数据全部整合在一条记录中。
比如 MySQL 中有一个订单数据,使用 ES 查询时,我们会把每条主数据及关联子表数据全部整合在下表中:
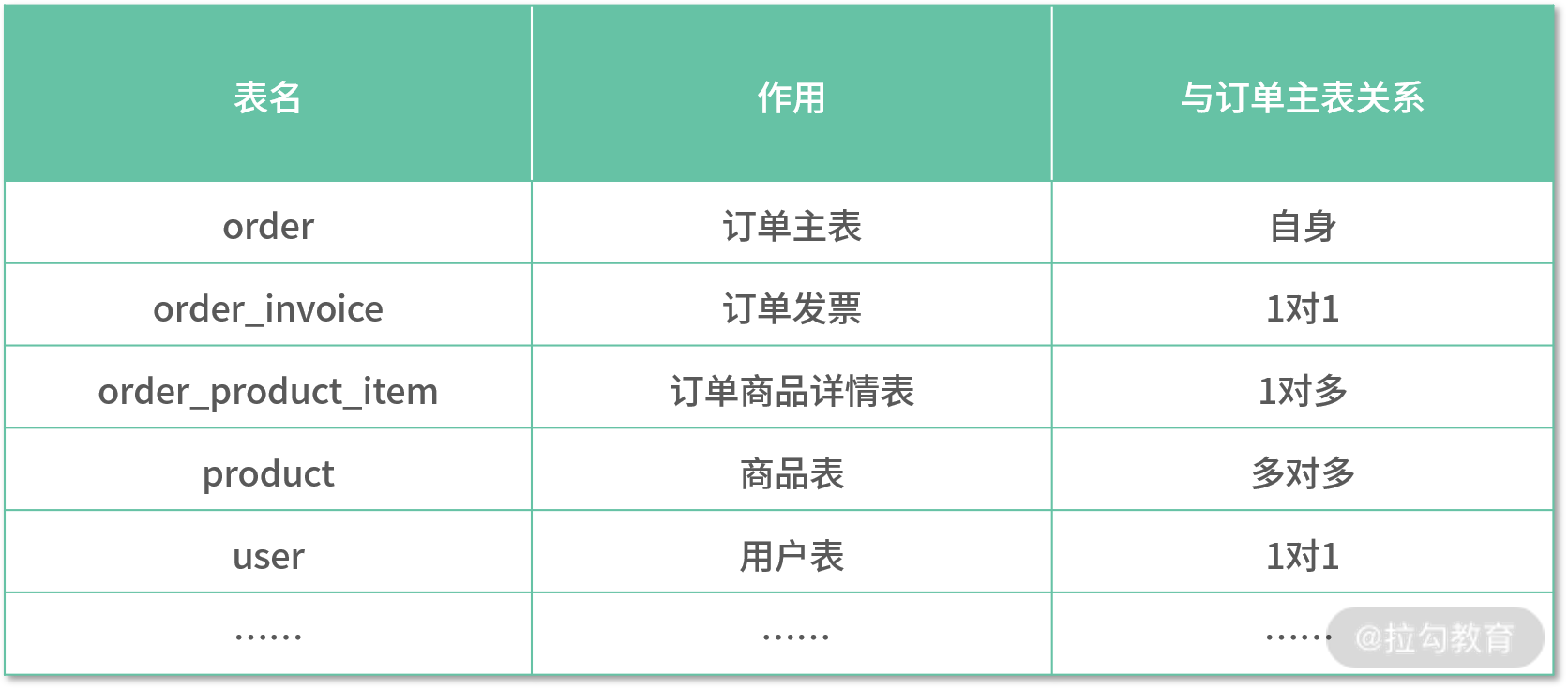
从上表中,我们发现:使用 ES 存储数据时并不会设计多个表,而是将所有表的相关字段数据汇集在一个 Document 中,即一个完整的文档结构,类似这样(此处我使用 JSON),代码示例如下:
{ "order_id": {"order_id": "O2020103115214521","order_invoice": {},"user": {"user_id": "U1099","user_name": "李大侠"},"order_product_item": [{"product_name": "乒乓球拍","product_count": 1,"product_price": 149},{"product_name": "纸巾","product_count": 2,"product_price": 1.4}],"total_amount": 20
}
到这,你是不是很疑惑:为什么我们把所有表汇聚在一个 Document 中,而不是设计成多个表?为什么 ES 不需要关联查询?这就涉及 ES 的存储结构原理相关知识,我们有必要先普及下。
ES 的存储结构
ES 是一个分布式的查询系统,它的每一个节点都是一个基于 Lucene 的查询引擎。下面通过 Lucene 和 MySQL 的概念对比,你就能真正理解 Lucene 了。
(1)Lucene 和 MySQL 的概念对比
Lucene 是一个索引系统,通过从易到难的方式,我们把 Lucene 与 MySQL 的一些概念简单做映射:
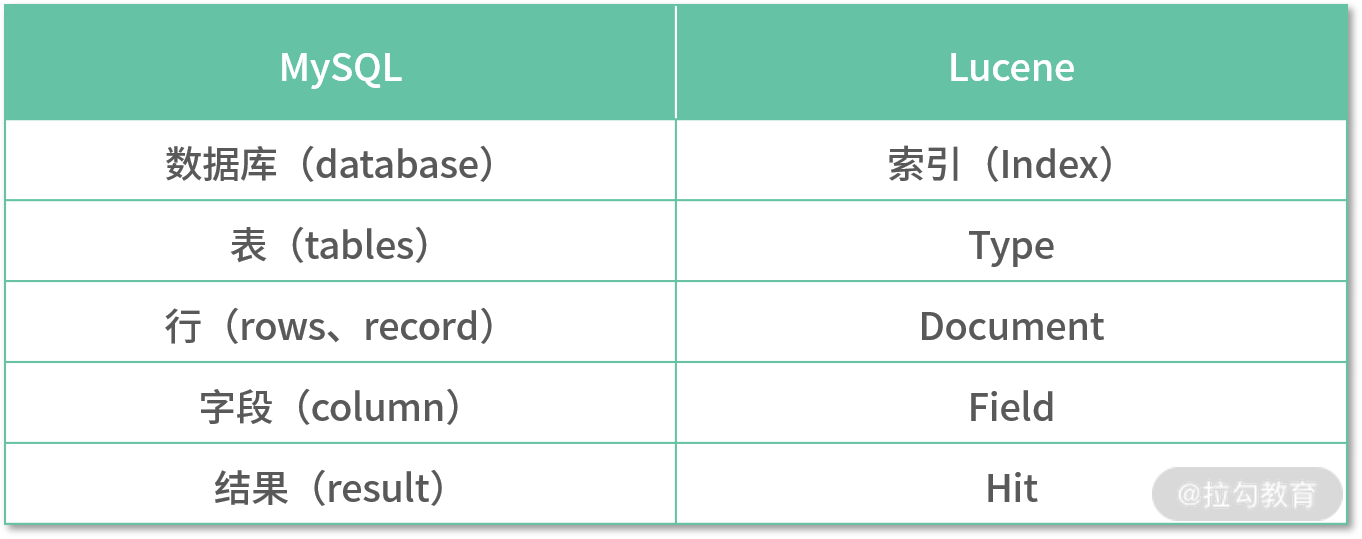
通过表中相关概念的对比,相信你已经理解了 Lucene 中每个概念的作用,这部分内容也是对上面内容的一个补充。
到这你可能还有一个疑问:Lucene 的索引 Index 到底是什么?我们继续讨论。
(2)无结构文档的倒排索引(Index)
实际上,Lucene 使用的是倒排索引的结构,具体是什么意思呢?先举个例子,你就能更好地理解了。
假如我们有一个无结构的文档,如下表所示:
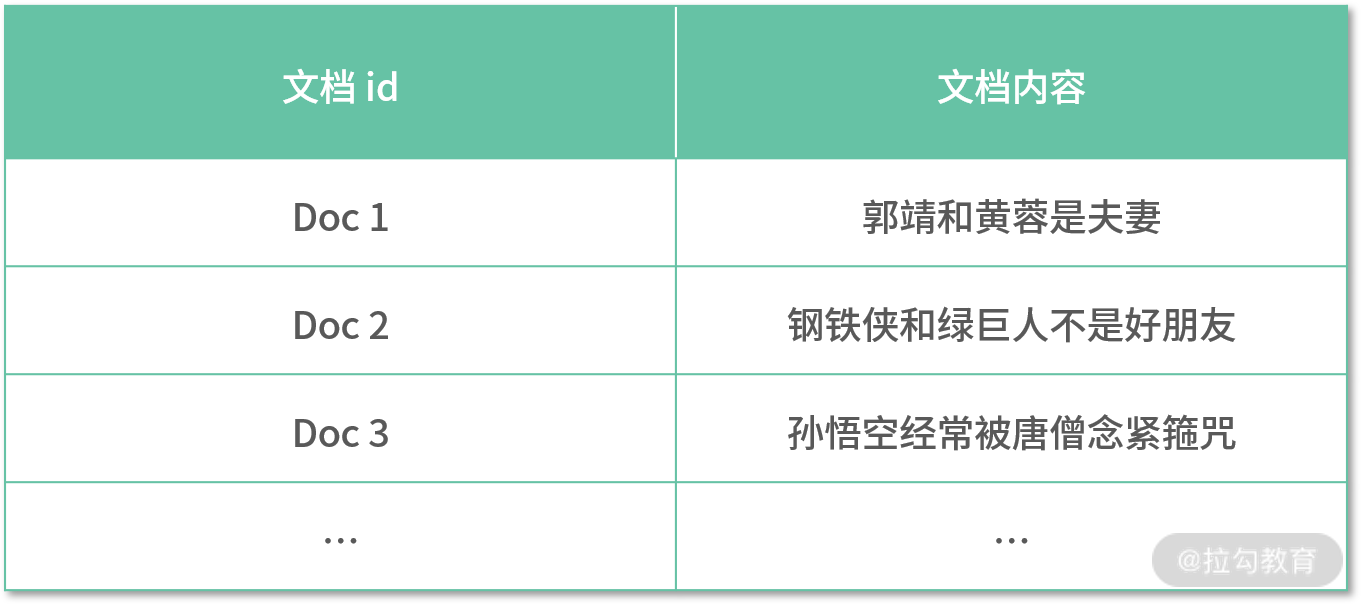
简单倒排索引后,显示的结果如下表所示:
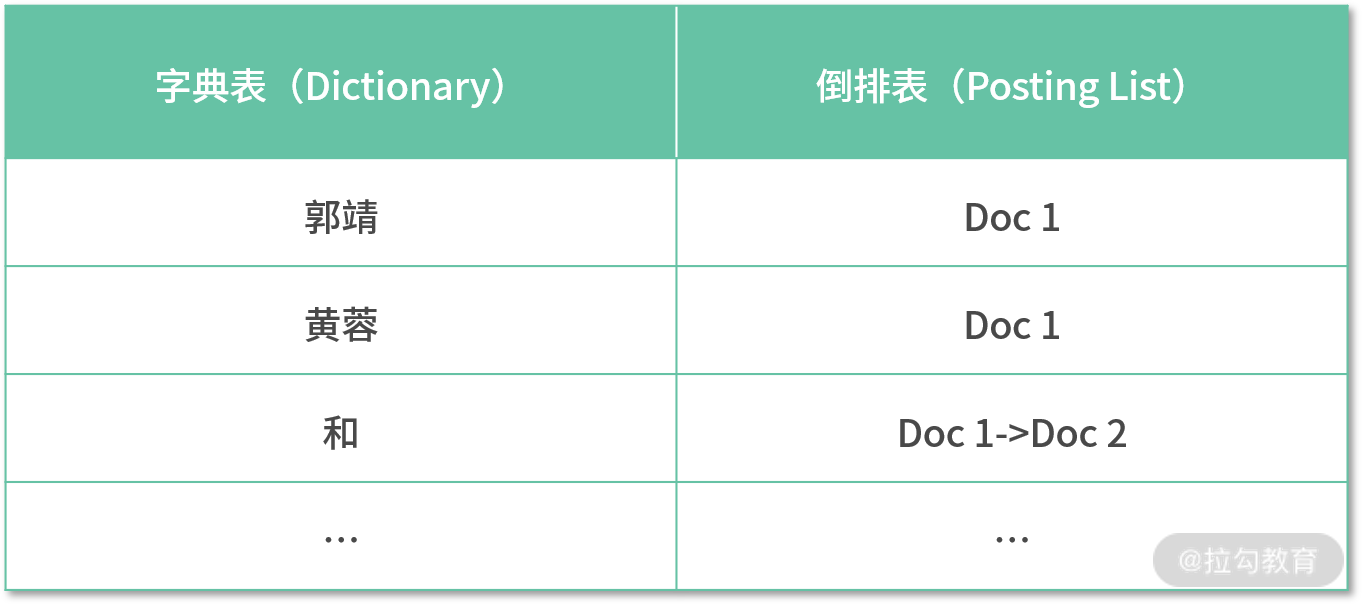
我们发现:无结构的文档经过简单的倒排索引后,字典表主要存放关键字,而倒排表存放该关键字所在的文档 id。
通过以上简单的例子,我们已经明白倒排索引的结构了,但是表数据往往是有结构的,并不是一篇篇文章。如果一个文档有结构呢,我们该怎么办?
(3)有结构文档的倒排索引(Index)
再来举一个更复杂的例子,比如每个 Doc 都有多个 Field,Field 有不同的值(包含不同的 Term),倒排索引的结构参考如下图所示:
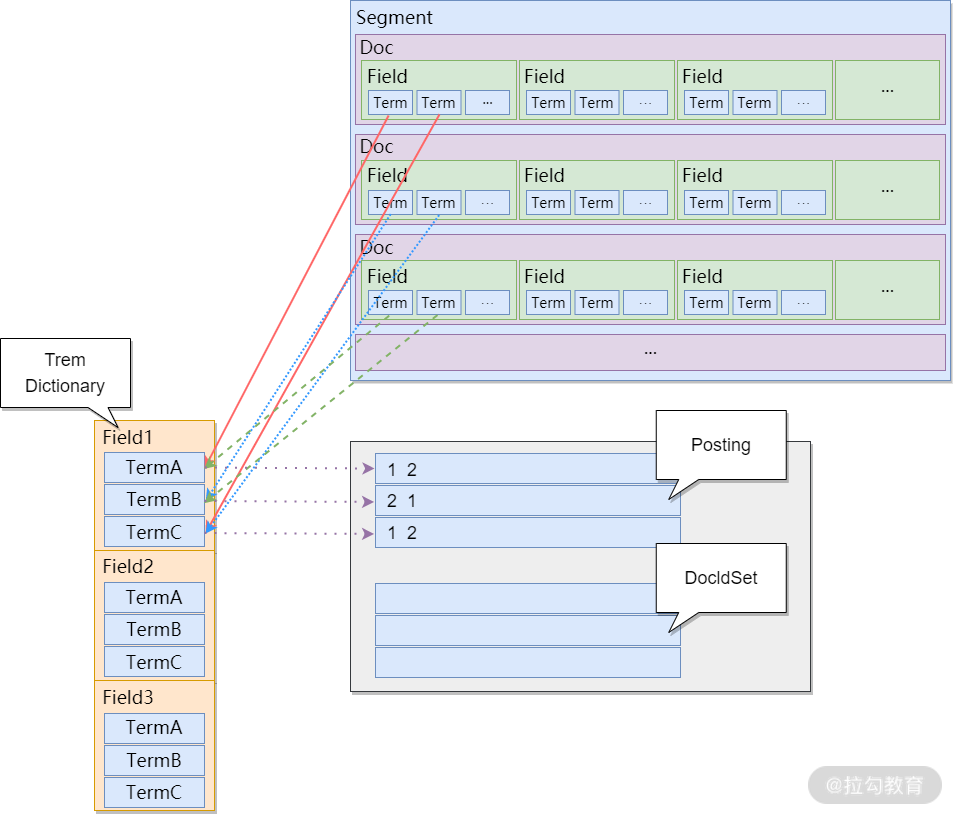
倒排索引结构示意图
也就是说:有结构的文档经过倒排索引后,字段中的每个值都是一个关键字,存放在左边的 Term Dictionary(词汇表)中,且每个关键字都有对应地址指向所在文档。
以上例子只是一个参考,实际上不管是字典表还是倒排表都是非常复杂的数据结构(03 讲我们先讨论到这个深度)。了解了 ES 的存储数据结构,我们就能更好地理解 ES 的表结构设计思路了。
讲到这,我们先讨论下:ES 的 Document 如何定义结构和字段格式(类似 MySQL 的表结构)?
(4) ES 的 Document 怎么定义结构和字段格式
前面我们讲解了 ES 的存储结构,从它是基于索引的设计来看,我们知道,设计 ES Document 结构时,并不需要像 MySQL 那样关联表,而是会把所有相关数据汇集在 1 个 Document 中,接下来我们看个例子。
我直接将刚刚 order 的 JSON 文档转成一个 ES 定义文档命令(这里需要注意:SQL 中的子表数据,在 ES 中需要以嵌入式对象的格式存储),代码示例如下:
{"mappings": {"doc": {"properties": {"order_id": {"type": "text"},"order_invoice": {"type": "nested"},"order_product_item": {"type": "nested","properties": {"product_count": {"type": "long"},"product_name": {"type": "text"},"product_price": {"type": "float"}}},"total_amount": {"type": "long"},"user": {"properties": {"user_id": {"type": "text"},"user_name": {"type": "text"}}}}}}
}
我们已经了解了 ES 表结构的设计,在实际业务中,我们往往会遇到这种情况:主数据修改了表结构,ES 也要求修改文档结构,这时我们该怎么办?这就涉及下面要讨论的第 2 个问题——如何修改表结构。
Elasticsearch如何修改表结构?
在实际业务中,如果你想增加新的字段,ES 支持直接添加,但如果你想修改字段类型或者改名,ES 官方文档里是这样写的(有兴趣的同学可以练练英文,没兴趣的可以直接跳过):
Except for supported mapping parameters, you can’t change the mapping or field type of an existing field. Changing an existing field could invalidate data that’s already Indexed.
If you need to change the mapping of a field in other indices, create a new index with the correct mapping and reIndex your data into that index.
Renaming a field would invalidate data already indexed under the old field name. Instead, add an alias field to create an alternate field name.
因为修改字段的类型会导致索引失效,所以 ES 不支持我们修改原来字段的类型。
如果你想修改字段的映射,首先需要新建一个索引,然后使用 ES 的 reindex 功能将旧索引拷贝到新索引中。
那什么是 reindex 呢?reindex 是 ES 自带的 API ,在实际代码中,你看下调用示例就能明白它的功用了。
POST _reIndex
{"source": {"Index": "my-Index-000001"},"dest": {"Index": "my-new-Index-000001"}
}
不过,直接重命名字段时,我们使用 reindex 功能会导致原来保存的旧字段名的索引数据失效,这种情况该如何解决?此时我们可以使用 alias 索引功能,代码示例如下:
PUT trips
{"mappings": {"properties": {"distance": {"type": "long"},"route_length_miles": {"type": "alias","path": "distance" },"transit_mode": {"type": "keyword"}}}
}
说到修改表结构,使用普通 MySQL 时,我并不建议直接修改字段的类型,改名或删字段。因为每次更新版本时,我们都要做好版本回滚的打算,为此设计每个版本对应数据库时,我们会尽量兼容前面版本的代码。
因 ES 的结构基于 MySQL 而设计,两者之间存在对应关系,所以我也不建议直接修改 ES 的表结构。
那如果我们真有修改的需求呢?一般而言,我们会先保留旧的字段,然后直接添加并使用新的字段,直到新版本的代码全部稳定工作后,我们再找机会清理旧的不用的字段,即分成 2 个版本完成修改需求。
介绍完如何修改表结构,我们继续讲解最后一个要点:ES 的那些坑。
ES 的坑有哪些?
坑一:ES 是准实时的?
当你更新数据至 ES 且返回成功提示(注意这一瞬间),你会发现通过 ES 查询返回的数据仍然不是最新的,背后的原因究竟是什么?这就要求我们对数据索引的整个过程有所了解,且待我们一步步揭开真实的面纱。
数据索引整个过程因涉及 ES 的分片,Lucene Index、Segment、 Document 的三者之间关系等知识点,所以我们有必要先把这部分内容串起来说明。
ES 的一个分片(这里跳过 ES 分片相关介绍)就是一个 Lucene Index,每一个 Lucene Index 由多个 Segment 构成,即 Lucene Index 的子集就是 Segment,如下图所示:
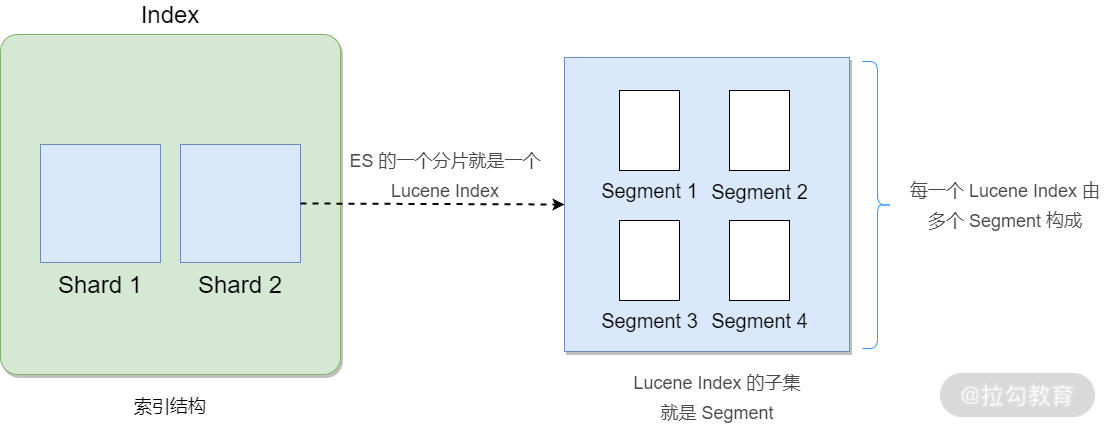
关于 Lucene Index、Segment、 Document 三者之间的关系,你看完下面这张图就一目了然了,如下图所示:
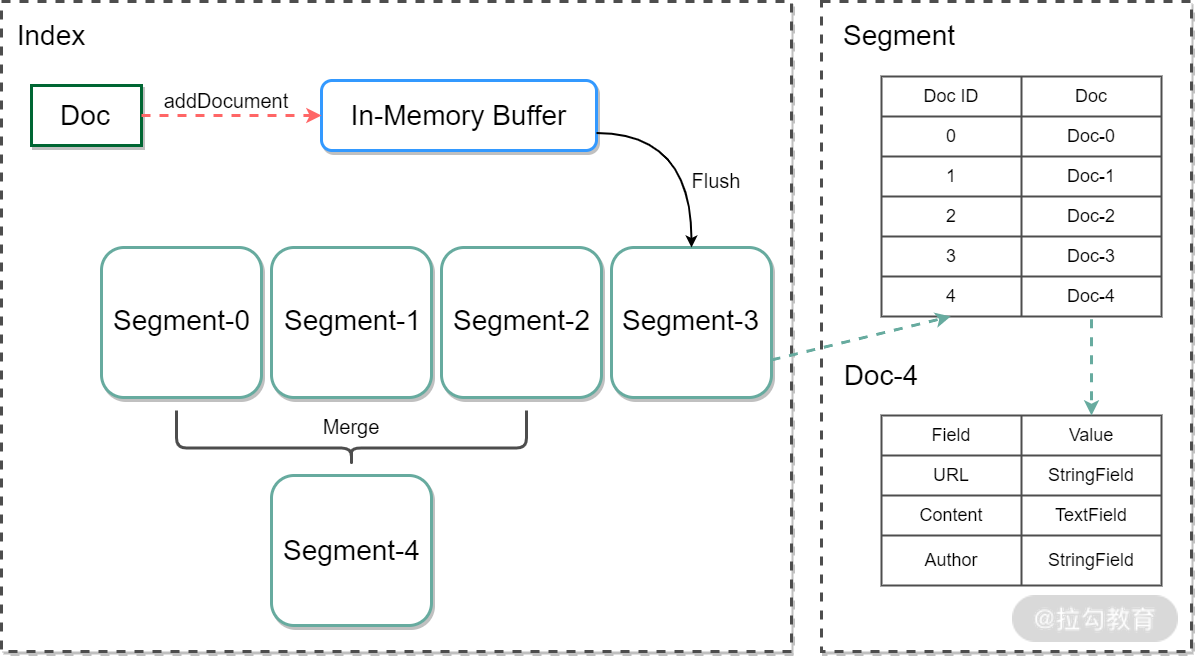
通过上面这个图,我们知道一个 Lucene Index 可以存放多个 Segment,而每个 Segment 又可以存放多个 Document。
掌握了以上基础知识点,接下来就进入正题——数据索引的过程详解。
第一步:当新的 Document 被创建,数据首先会存放到新的 Segment 中,同时旧的 Document 会被删除,并在原来的 Segment 上标记一个删除标识。当 Document 被更新,旧版 Document 会被标识为删除,并将新版 Document 存放新的 Segment 中。
第二步:Shard 收到写请求时,请求会被写入 Translog 中,然后 Document 被存放 memory buffer (注意:memory buffer 的数据并不能被搜索到)中,最终 Translog 保存所有修改记录。
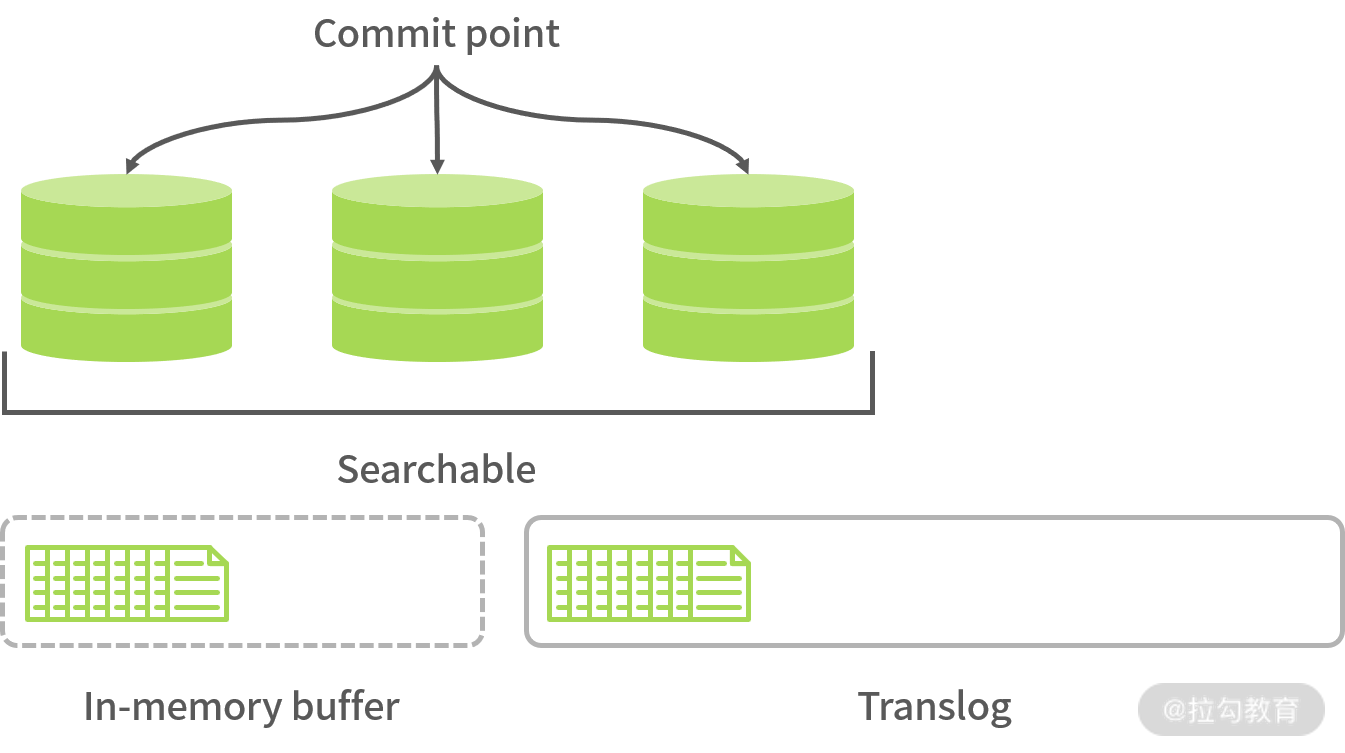
第三步:每隔 1 秒(默认设置),refresh 操作被执行一次,且 memory buffer 中的数据会被写入一个 Segment 并存放 filesystem cache 中,这时新的数据就可以被搜索到了,如下图所示:
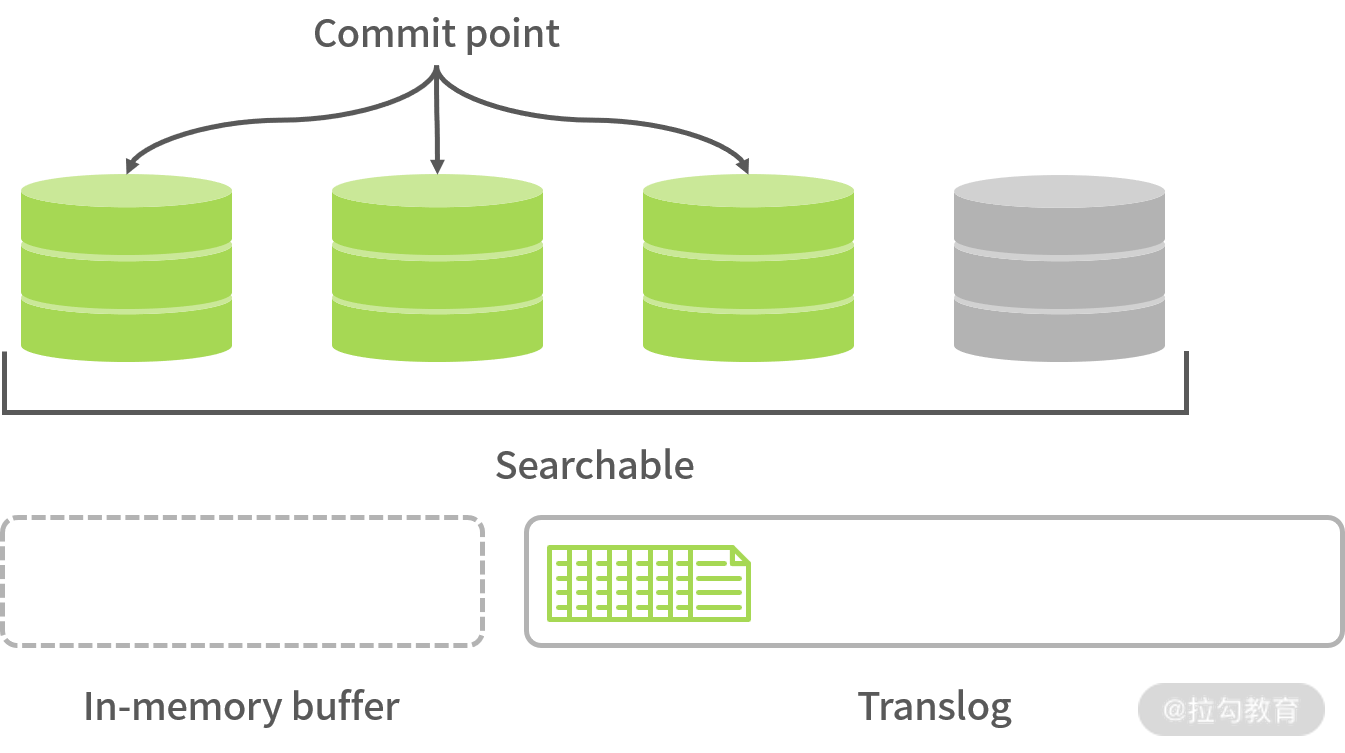
通过以上数据索引过程的说明,我们发现 ES 并不是实时的,而是有 1 秒延时,因延时问题的解决方案我们在 02 讲中介绍过,提示用户查询的数据会有一定延时即可。
讲到这里,感觉你开始打呵欠了,再坚持一下,再讲 2 个坑就结束了。如果我不先讲原理直接讲坑,你只知其然不知其所以然,更加记不住。
坑二:ES 宕机恢复后,数据丢失
在数据索引的过程这部分内容,我们提及了每隔 1 秒(根据配置),memory buffer 中的数据会被写入 Segment 中,此时这部分数据可被用户搜索到,但没有被持久化,一旦系统宕机了,数据就会丢失。
比如下图中灰色的桶,目前它可被搜索到,但还没有持久化,一旦 ES 宕机,数据将会丢失。
![]()

如何防止数据丢失呢?使用 Lucene 中的 commit 操作就能轻松解决这个问题。
commit 具体操作:先将多个 Segment 合并保存到磁盘中,再将灰色的桶变成上图中绿色的桶。
不过,使用 commit 操作存在一点不足:耗 IO,从而引发 ES 在 commit 之前宕机的问题。一旦系统在 translog fsync 之前宕机,数据也会直接丢失,如何保证 ES 数据的完整性便成了亟待解决的问题。
遇到这种情况,我们采用 translog 解决就行,因为 Translog 中的数据不会直接保存在磁盘中,只有 fsync 后才保存,这里我分享两种 Translog 解决方案。
第一种:将 Index.translog.durability 设置成 request ,如果我们发现系统运行得不错,采用这种方式即可;
第二种:将 Index.translog.durability 设置成 fsync,每次 ES 宕机启动后,先将主数据和 ES 数据进行对比,再将 ES 缺失的数据找出来。
强调一个知识点:Translog 何时会 fsync ?当 Index.translog.durability 设置成 request 后,每个请求都会 fsync,不过这样影响 ES 性能。这时我们可以把 Index.translog.durability 设置成 fsync,那么每隔 Index.translog.sync_interval 后,每个请求才会 fsync 一次。
坑三:分页越深,查询效率越慢
ES 分页这个坑的出现,与 ES 的读操作请求的处理流程密切关联,为此我们有必要先深度剖析下 ES 的读操作请求的处理流程,如下图所示:
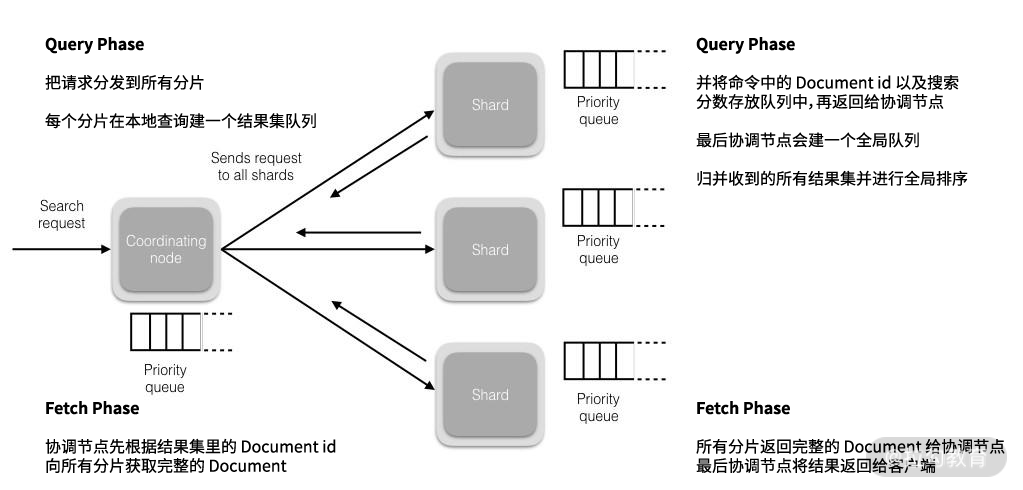
ES 的读操作请求的处理流程示意图
关于 ES 的读操作流程主要分为两个阶段:Query Phase、Fetch Phase。
Query Phase: 协调的节点先把请求分发到所有分片,然后每个分片在本地查询建一个结果集队列,并将命令中的 Document id 以及搜索分数存放队列中,再返回给协调节点,最后协调节点会建一个全局队列,归并收到的所有结果集并进行全局排序。
Query Phase 我需要强调:在 ES 查询过程中,如果 search 带了 from 和 size 参数,Elasticsearch 集群需要给协调节点返回 shards number * (from + size) 条数据,然后在单机上进行排序,最后给客户端返回 size 大小的数据。比如客户端请求 10 条数据(比如 3 个分片),那么每个分片则会返回 10 条数据,协调节点最后会归并 30 条数据,但最终只返回 10 条数据给客户端。
Fetch Phase: 协调节点先根据结果集里的 Document id 向所有分片获取完整的 Document,然后所有分片返回完整的 Document 给协调节点,最后协调节点将结果返回给客户端。(关于什么是协调节点,我们先忽略它。)
在整个 ES 的读操作流程中,Elasticsearch 集群实际上需要给协调节点返回 shards number * (from + size) 条数据,然后在单机上进行排序,最后返回给客户端这个 size 大小的数据。
比如有 5 个分片,我们需要查询排序序号从 10000 到 10010(from=10000,size=10)的结果,每个分片到底返回多少数据给协调节点计算呢?告诉你不是 10 条,是 10010 条。也就是说,协调节点需要在内存中计算 10010*5=50050 条记录,所以在系统使用中,如果用户分页越深查询速度会越慢,也就是说并不是分页越多越好。
那如何更好地解决 ES 分页问题呢?为了控制性能,我们主要使用 ES 中的 max_result_window 配置,这个数据默认为 10000,当 from+size > max_result_window ,ES 将返回错误。
由此可见,在系统设计时,我们一般需要控制用户翻页不能太深,而这在现实场景中用户也能接受,这也是我之前方案采用的设计方式。要是用户确实有深度翻页的需求,我们再使用 ES 中search_after 的功能也能解决,不过就是无法实现跳页了。
我们举一个例子,查询按照订单总金额分页,上一页最后一条 order 的总金额 total_amount 是 10,那么下一页的查询示例代码如下:
{"query": {"bool": {"must": [{"term": {"user.user_name.keyword": "李大侠"}}],"must_not": [],"should": []}},"from": 0,"size": 2,"search_after": ["10"],"sort": [{"total_amount": "asc"}],"aggs": {}
}
这个 search_after 里的值,就是上次查询结果的排序字段的结果值。
小结
03 讲关于使用 Elasticsearch 需要注意的要点我们就讲完了,04 讲我们开始讲分表分库。
在实际工作中,如果你还遇到了其他坑或者对 03 讲内容有什么建议,欢迎在评论区留言,与我互动、交流。另外,喜欢的同学可以将本课程分享给更多的好友看到哦。
04 分表分库:单表数据量大读写缓慢如何解决?
02 讲中,我们讲了查询分离的方案存在三大不足,其中一个不足就是:当主数据量越来越大,写操作缓慢,遇到这个问题我们该如何解决呢?
为此,04 讲我们主要围绕这个问题来讲解,其中我会结合个人真实的业务场景告知你拆分存储时如何进行技术选型?分表分库的实现思路是什么?分表分库存在哪些不足?
业务背景(架构经历三)
为了便于你理解,我们先从一个真实的业务场景(我的一次真实架构经历)入手。
曾经,我负责过一个电商系统的架构优化,该系统中包含用户和订单 2 个主要实体,每个实体涵盖数据量如下表所示:
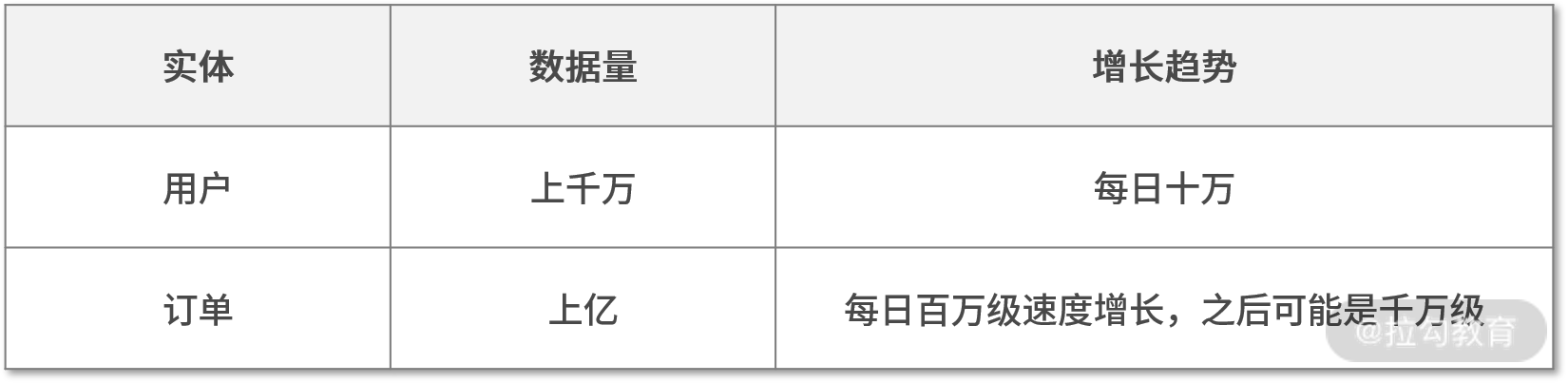
从上表中我们发现,目前订单数据量已达上亿,且每日以百万级的速度增长,之后还可能是千万级。
面对如此庞大的数据量,此时存储订单的数据库表竟然还是一个单库单表。对于单库单表而言,一旦数据量实现疯狂增长,无论是 IO 还是 CPU 都会扛不住。
为了使系统抗住千万级数据量的压力,我们尝试过很多解决方案,最终我们想到了先将订单表拆分,再进行分布存储,这也就是本节课我们要讲的内容——分表分库。
说到分表分库解决方案,我们首先需要做的就是搞定拆分存储的技术选型问题。
拆分存储的技术选型
关于拆分存储常用的技术解决方案,市面上目前主要分为 4 种:MySQL 的分区技术、NoSQL、NewSQL、基于 MySQL 的分表分库。
1.MySQL 的分区技术
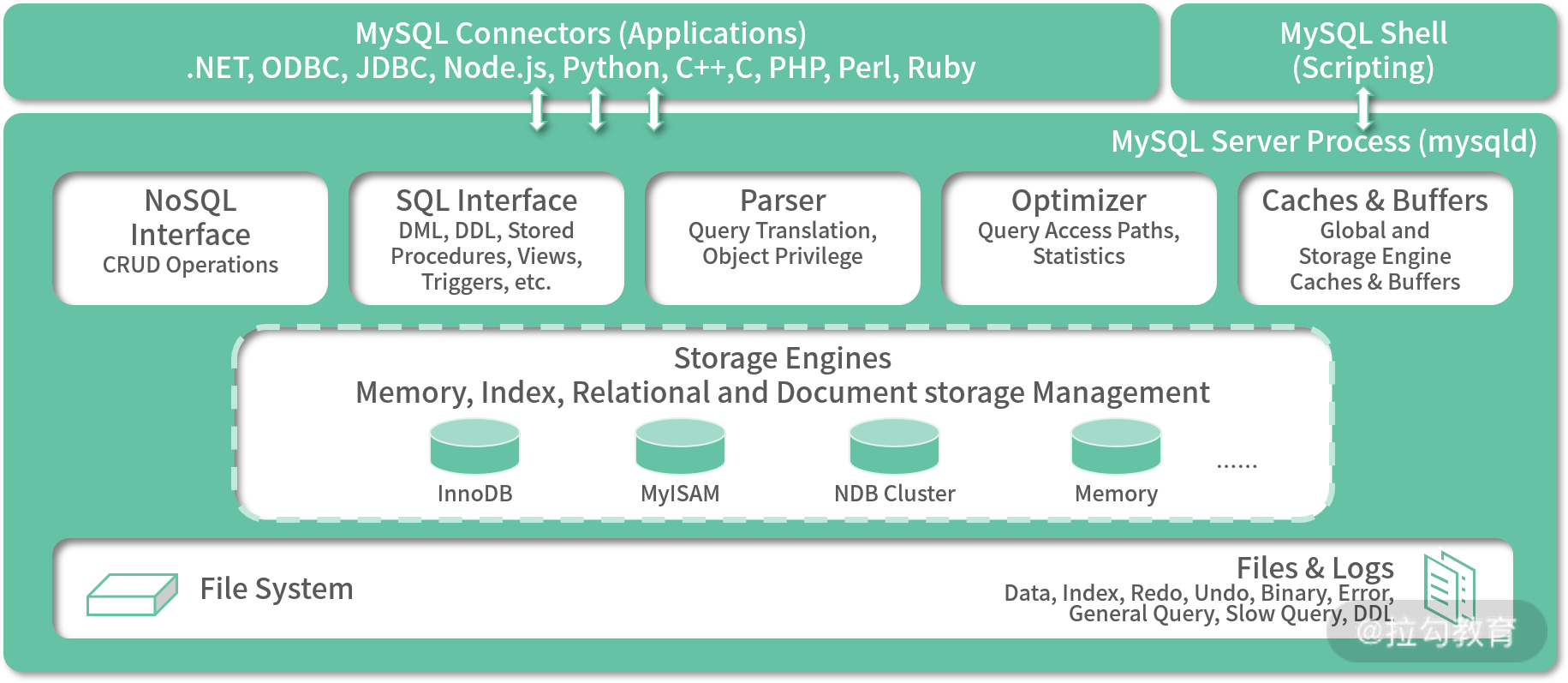
MySQL 架构图(来源:MySQL 官方文档)
从上面的 MySQL 架构图中,我们不难发现 MySQL 的分区主要在文件存储层做文章,它可以将一张表的不同行存放在不同存储文件中,这对使用者来说比较透明。
在以往的实战项目中,我们不使用它的原因主要有三点。
MySQL 的实例只有一个,它仅仅分摊了存储,无法分摊请求负载。
正是因为 MySQL 的分区对用户透明,所以用户在实际操作时往往不太注意,使得跨分区操作严重影响系统性能。
当然,MySQL 还有一些其他限制,比如不支持 query cache、位操作表达式等。感兴趣的同学可以打开这篇文章看看:https://dev.mysql.com/doc/refman/5.7/en/partitioning-limitations.html。
2.NoSQL(如 MongoDB)
比较典型的 NoSQL 数据库就是 MongoDB 啦。MongoDB 的分片功能从并发性和数据量这两个角度已经能满足一般大数据量的需求,但是还需要注意这三大要点。
约束考量: MongoDB 不是关系型数据库而是文档型数据库,它的每一行记录都是一个结构灵活可变的 JSON,比如存储非常重要的订单数据时,我们就不能使用 MongoDB,因为订单数据必须使用强约束的关系型数据库进行存储。
业务功能考量: 多年来,事务、锁、SQL、表达式等千奇百怪的操作都在 MySQL 身上一一验证过, MySQL 可以说是久经考验,因此在功能上 MySQL 能满足我们所有的业务需求,MongoDB 却不能,且大部分的 NoSQL 也存在类似问题。
稳定性考量: 我们对 MySQL 的运维已经很熟悉了,它的稳定性没有问题,然而 MongoDB 的稳定性我们没法保证,毕竟不熟悉,因此在我之前的拆分存储技术选型过程中,我没使用过 NoSQL。
3.NewSQL(如 TiDB)
NewSQL 技术还比较新,我们曾经想在一些不重要的数据中使用 NewSQL(比如 TiDB),但从稳定性和功能扩展性两方面考量后,最终没有使用,具体原因与 MongoDB 类似。
4.基于 MySQL 的分表分库
什么是分表分库?分表是将一份大的表数据拆分存放至多个结构一样的拆分表;分库就是将一个大的数据库拆分成多个结构一样的小库。
前面介绍的三种拆分存储技术,在我以往的项目中我都没使用过,而是选择了基于 MySQL 的分表分库,主要是有一个重要考量:分表分库对于第三方依赖较少,业务逻辑灵活可控,它本身并不需要非常复杂的底层处理,也不需要重新做数据库,只是根据不同逻辑使用不同 SQL 语句和数据源而已。
如果我们使用分表分库,存在 3 个技术通用需求需要实现。
SQL 组合: 因为我们关联的表名是动态的,所以我们需要根据逻辑组装动态的 SQL。
数据库路由: 因为数据库名也是动态的,所以我们需要通过不同的逻辑使用不同的数据库。
执行结果合并: 有些需求需要通过多个分库执行,再合并归集起来。
而市面上能解决以上问题的中间件分为 2 类:Proxy 模式、Client 模式。
(1)Proxy 模式: 直接拿 ShardingSphere 官方文档里的图进行说明,我们重点看看中间 Sharding-Proxy 层,如下图所示:
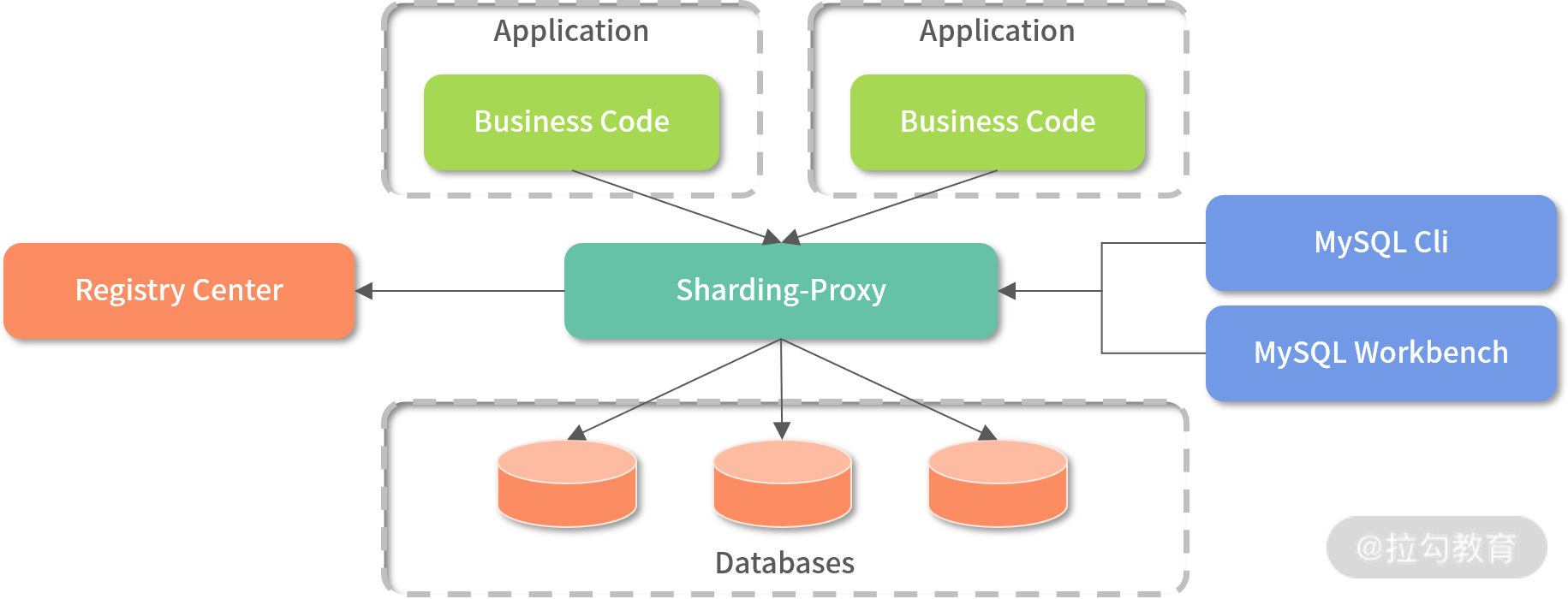
proxy 模式图(来源:ShardingSphere 官方文档)
以上这种设计模式,把 SQL 组合、数据库路由、执行结果合并等功能全部存放在一个代理服务中,而与分表分库相关的处理逻辑全部存放在另外的服务中,这种设计模式的优点是对业务代码无侵入,业务只需要关注自身业务逻辑即可。
(2)Client 模式: 还是继续借用 ShardingSphere 官方文档里的图来说明,如下图所示:
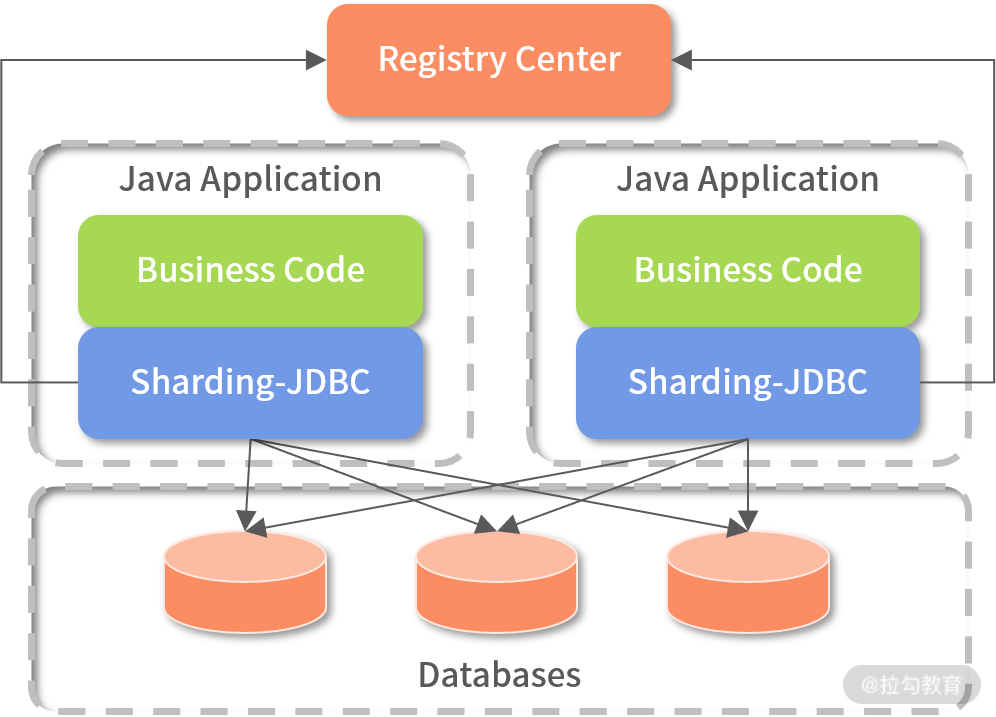
client 模式(来源:ShardingSphere 官方文档)
以上这种设计模式,把分表分库相关逻辑存放在客户端,一般客户端的应用会引用一个 jar,然后在 jar 中处理 SQL 组合、数据库路由、执行结果合并等相关功能。
市面上,关于这两种模式的中间件有如下选择:
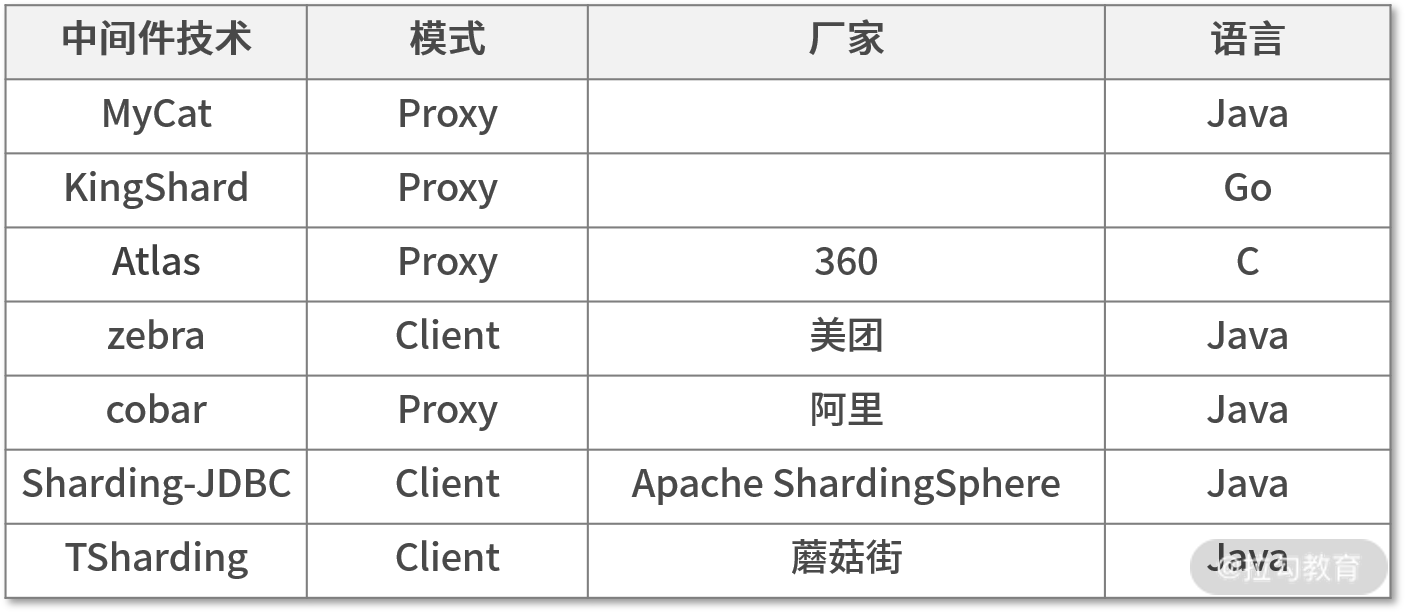
学到这,我们已经知道市面上开源中间件的设计模式,那我们到底该选择哪种模式呢?简单对比下这 2 个模式的优缺点,你就能知道答案了。
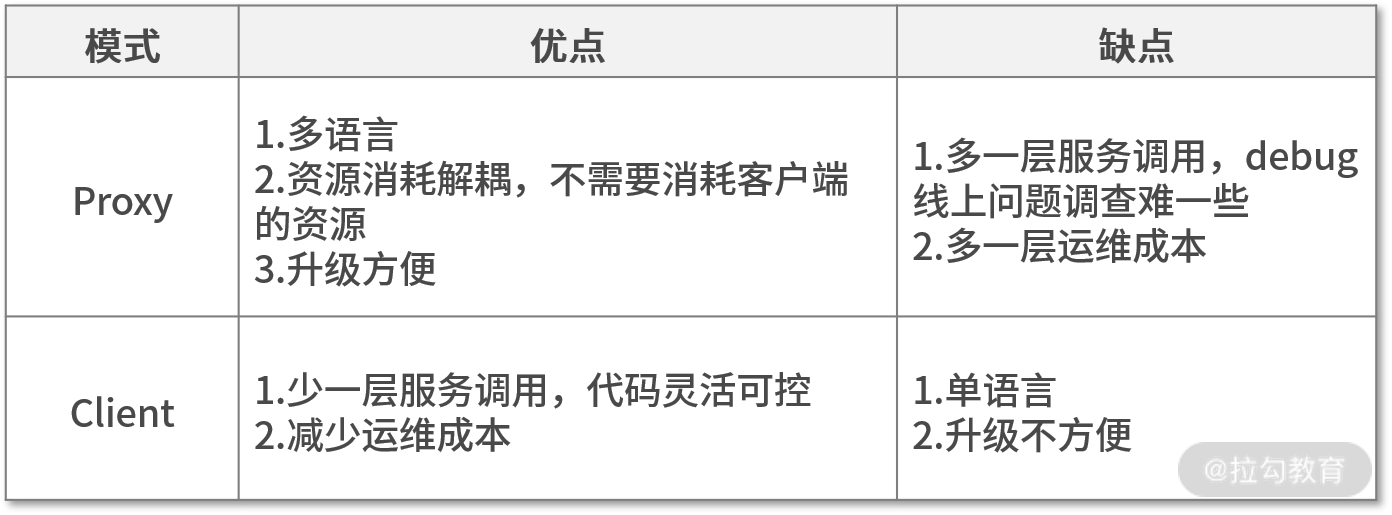
client 模式与 proxy 模式优缺点对比
当时因为看重代码灵活可控这个优势,所以最终我们选择了 Client 模式里的 Sharding-JDBC 来实现分表分库,如下图所示:
![]()

Client 模式—— Sharding-JDBC(来源:ShardingSphere 官方文档)
当然,关于拆分存储选择哪种技术,在实际工作中我们需要根据各自的实际情况来定。
分表分库实现思路
技术选型这一大难题解决后,具体如何落地分表分库解决方案成了我们亟待解决的问题。
在落实分表分库解决方案时,我们需要考虑 5 个要点。
1. 使用什么字段作为分片键?
我们先来回顾下业务场景中举例的数据库:

下面我们把上表中的数据拆分成了一个订单表,表中主要数据结构如下:
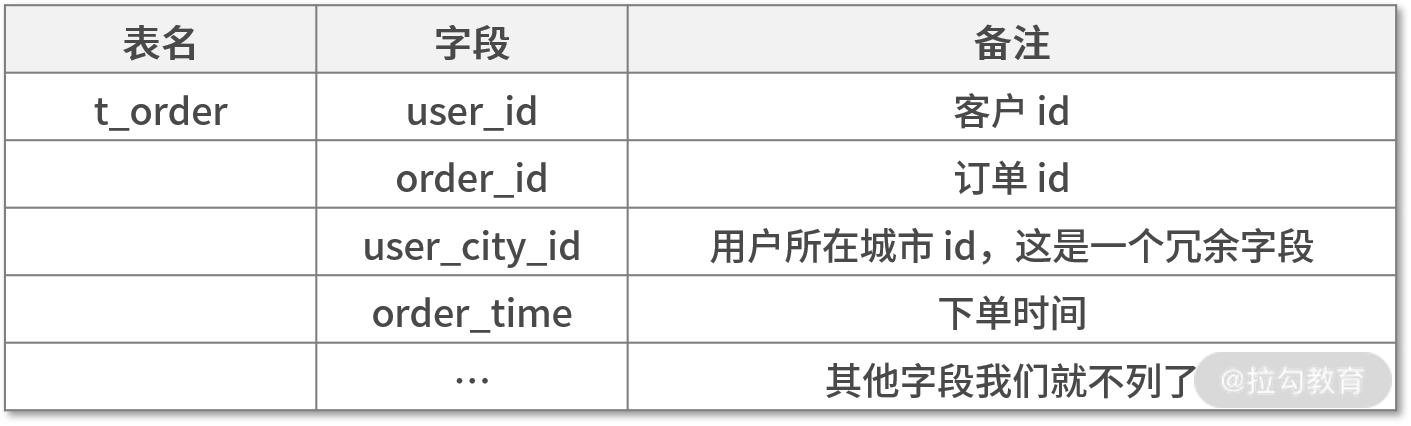
从上面表中可知,我们是使用 user_id 作为分片主键,为什么这样分呢,我来讲讲当时的实现思路。
在选择分片字段之前,我们首先了解了下目前存在的一些常见业务需求:
用户需要查询所有订单,订单数据中肯定包含不同的 merchant_id、order_time;
后台需要根据城市查询当地的订单;
后台需要统计每个时间段的订单趋势。
根据这些常见业务需求,我们判断了下优先级,用户操作也就是第一个需求必须优先满足。
此时,如果我们使用 user_id 作为订单的分片字段,就能保证每次用户查询数据时(第 1 个需求),在一个分库的一个分表里即可获取数据。
因此,在我们的方案里,最终还是使用 user_id 作为分片主键,这样在分表分库查询时,首先会把 user_id 作为参数传过来。
这里我需要特殊说明下,选择字段作为分片键时,我们一般需要考虑三点要求:数据尽量均匀分布在不同表或库、跨库查询操作尽可能少、这个字段的值不会变(这点尤为重要)。
2. 分片的策略是什么?
决定使用 user_id 作为订单分片字段后,我们就要开始考虑分片的策略问题了。
目前,市面上通用的分片策略分为根据范围分片、根据 hash 值分片、根据 hash 值及范围混合分片这三种。
根据范围分片: 比如用户 id 是自增型数字,我们把用户 id 按照每 100 万份分为一个库,每 10 万份分为一个表的形式进行分片,如下表所示:
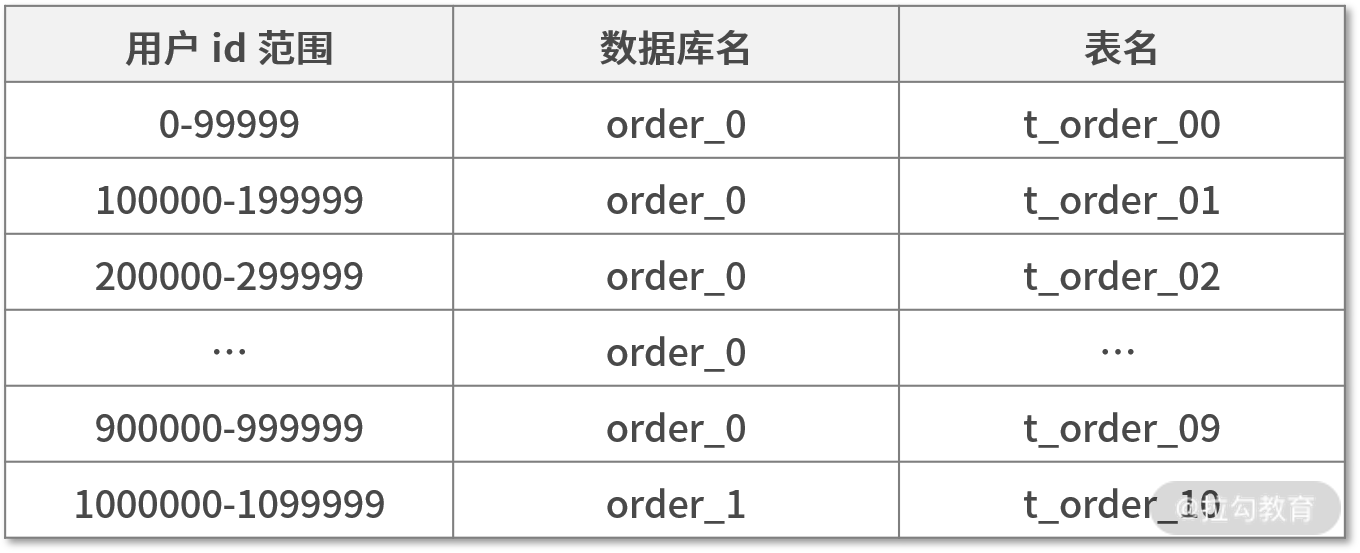
特殊说明:这里我们只讲分表,至于分库把分表分组存放在一个库即可,我就不另行解释了。
根据 hash 值分片: 指的是根据用户 id 的 hash 值 mod 一个特定的数进行分片。(为了方便后续扩展,一般是 2 的几次方。)
根据 hash 值及范围混合分片: 先按照范围分片,再根据 hash 值取模分片。比如:表名=order_#user_id%10#_#hash(user_id)%8,即被分成了 10*8=80 个表。为了方便你理解,我们画个图说明下,如下图所示:
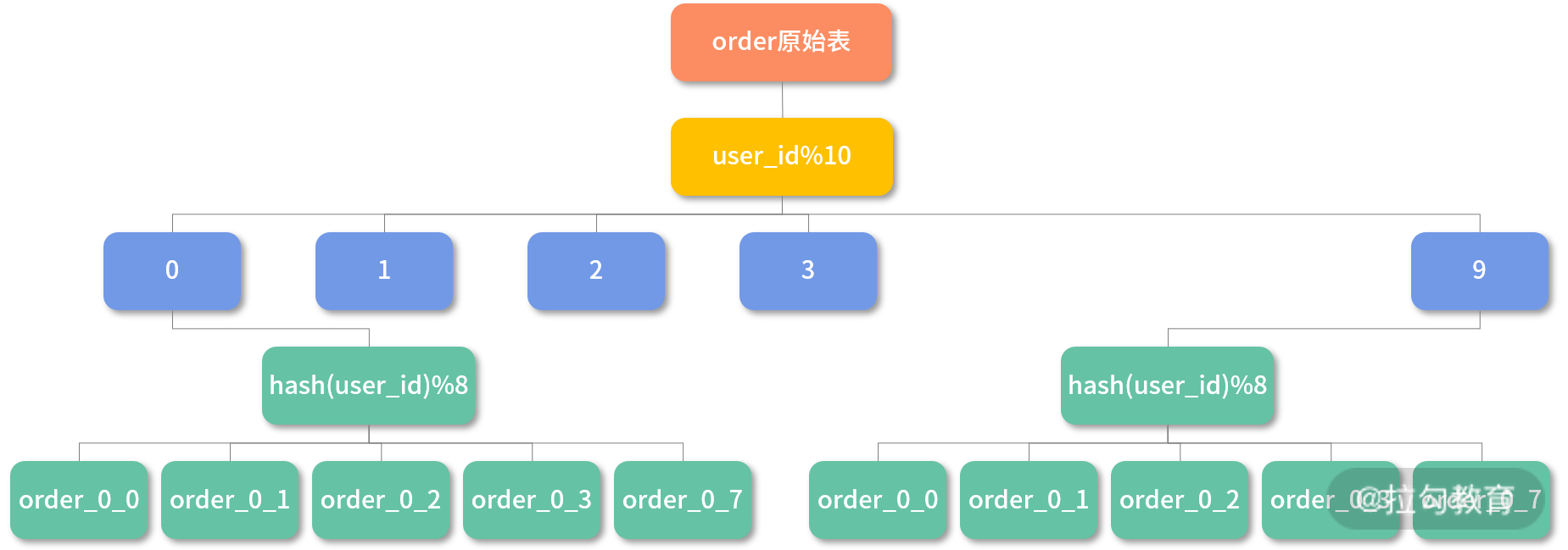
以上三大分片策略我们到底应该选择哪个?我们只需要考虑一点:假设之后数据量变大了,需要我们把表分得更细,此时保证迁移的数据尽量少即可。
因此,根据 hash 值分片时我们一般建议拆分成 2 的 N 次方表。比如分成 8 张表,数据迁移时把原来的每张表拆一半出来组成新表,这样数据迁移量就小了。
当初的方案中,我们就是根据用户 id 的 hash 值取模 32,把数据分成 32 个数据库,每个数据库再分成 16 张表。
我们简单计算了下,假设每天订单量 1 千万,每个库日增 1000万/16=31.25 万,每个表日增 1000万/32/16=1.95 万。而如果每天千万订单量呢?3 年后每个表的数据量就是 2 千万左右,也还在可控范围内。
因此,如果业务增长特别快,且运维还扛得住,为避免以后出现扩容问题,我们建议库分得越多越好。
3. 业务代码如何修改?
分片策略定完后,我们就要考虑业务代码如何修改了。因修改业务代码部分与业务强关联,所以我的方案并不具备参考性。
但是,在这里我想分享一些个人观点。近年来,分表分库操作愈发容易,不过我们需要注意几个要点。
我们已经习惯微服务了,对于特定表的分表分库,其影响面只在该表所在的服务中,如果是一个单体架构的应用做分表分库,那真是伤脑筋。
在互联网架构中,我们基本不使用外键约束。
随着查询分离的流行,后台系统中有很多操作需要跨库查询,导致系统性能非常差,这时分表分库一般会结合查询分离一起操作:先将所有数据在 ES 索引一份,再使用 ES 在后台直接查询数据。如果订单详情数据量很大,还有一个常见做法,即先在 ES 中存储索引字段(作为查询条件的字段),再将详情数据存放在 HBase 中(这个方案我们就不展开了)。
一般来说,业务代码的修改不会很复杂,最麻烦的是历史数据的迁移。
4. 历史数据迁移?
历史数据的迁移非常耗时,有时迁移几天几夜都很正常。而在互联网行业中,别说几天几夜了,就连停机几分钟业务都无法接受,这就要求我们给出一个无缝迁移的解决方案。
还记得讲解查询分离时,我们说过的方案吗?我们再来回顾下,如下图所示:
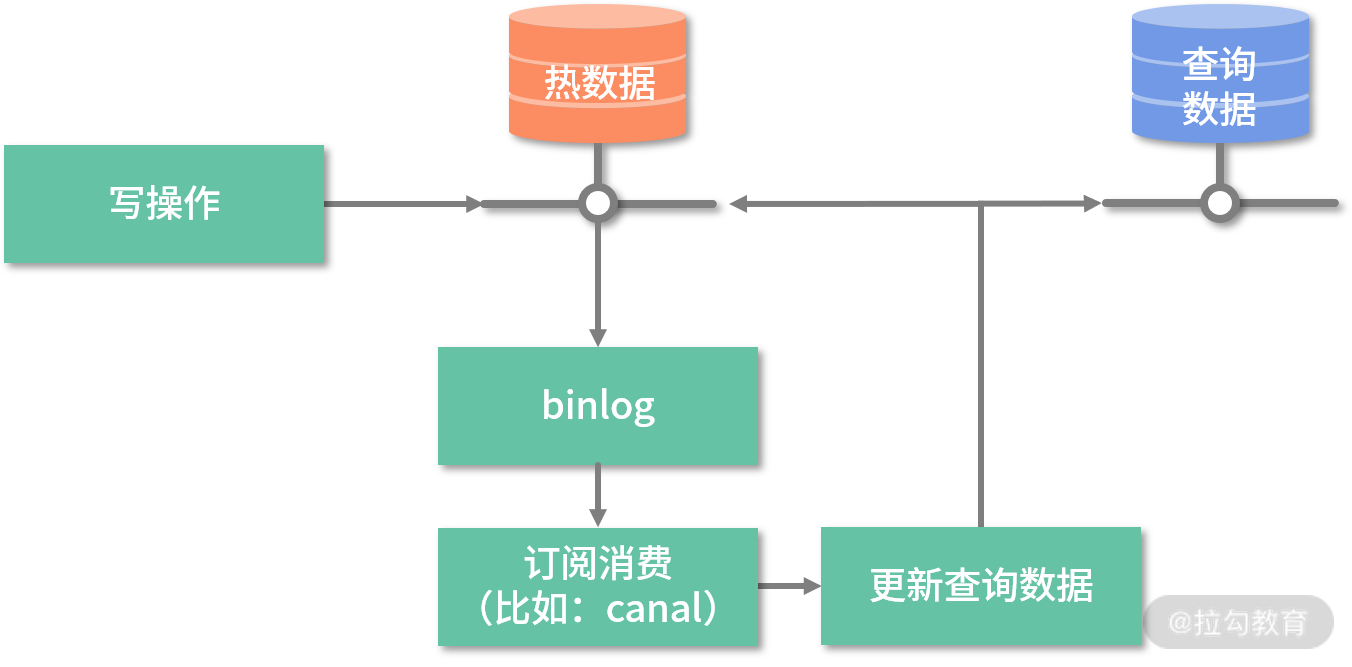
历史数据迁移时,我们就是采用类似的方案进行历史数据迁移,如下图所示:
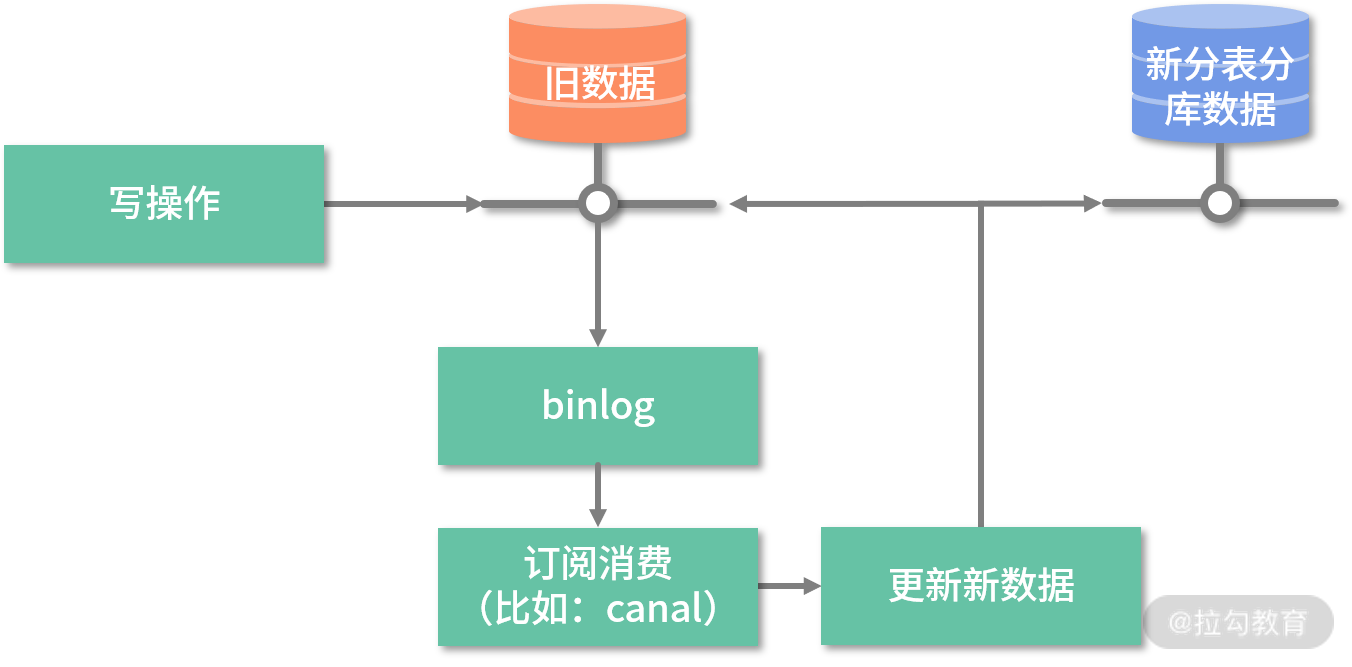
此数据迁移方案的基本思路:存量数据直接迁移,增量数据监听 binlog,然后通过 canal 通知迁移程序搬运数据,新的数据库拥有全量数据,且校验通过后逐步切换流量。
数据迁移解决方案详细的步骤如下:
上线 canal,通过 canal 触发增量数据的迁移;
迁移数据脚本测试通过后,将老数据迁移到新的分表分库中;
注意迁移增量数据与迁移老数据的时间差,确保全部数据都被迁移过去,无遗漏;
第二步、第三步都运行完后,新的分表分库中已经拥有全量数据了,这时我们可以运行数据验证的程序,确保所有数据都存放在新数据库中;
到这步数据迁移就算完成了,之后就是新版本代码上线了,至于是灰度上还是直接上,需要根据你们的实际情况决定,回滚方案也是一样。
5. 未来的扩容方案是什么?
随着业务的发展,如果原来的分片设计已经无法满足日益增长的数据需求,我们就需要考虑扩容了,扩容方案主要依赖以下两点。
分片策略是否可以让新表数据的迁移源只是 1 个旧表,而不是多个旧表,这就是前面我们建议使用 2 的 N 次方分表的原因;
数据迁移:我们需要把旧分片的数据迁移到新的分片上,这个方案与上面提及的历史数据迁移一样,我们就不重复啰唆了。
分表分库的不足
分表分库的解决方案讲完了,以上就是业界常用的一些做法,不过此方案仍然存在不足之处。
ES+Hbase 做数据查询分离的方案: 前面我们讲了单独使用 ES 做查询分离解决方案,这里就不再单独展开了。
增量数据迁移: 如何保证数据的一致性及高可用性?这个问题在 13 讲中我们会单独展开。
短时订单量大爆发: 分表分库仍然扛不住时解决方案是什么?这个会在缓存和秒杀架构课程中单独展开。
各位亲爱的同学,04 讲分表分库解决方案中肯定还有一些遗漏的问题没有考虑到,欢迎你在评论区多多留言,与我互动、交流。
另外,喜欢的同学可以把本课程分享给更多的好友。
分布式场景实战第二节 分布式场景下es和mysql避坑指南相关推荐
- 分布式数据库实战第一节 分布式数据库的前世今生
开篇词 吃透分布式数据库,提升职场竞争力 你好,我是高洪涛,前华为云技术专家.前当当网系统架构师和 Oracle DBA,也是 Apache ShardingSphere PMC 成员.作为创始团队核 ...
- Win10下快速复现Mask_RCNN避坑指南
硬件环境:笔记本电脑win10系统.1050Ti显卡 软件环境:Anaconda.Pycharm 项目地址:https://github.com/matterport/Mask_RCNN 一.环境搭建 ...
- 分布式消息队列的避坑指南
在业务系统的开发当中,为了保障系统的高性能.高可用,基本都会使用分布式架构,采用消息队列将生产者(响应调用的服务)与消费者(发起调用的服务)进行解耦,让生产者服务和消费者服务可以并行处理更多的程序调用 ...
- ext列表禁止滑动_后台列表设计避坑指南(下)
编辑导语:列表页是后台界面的重要组成之一,上篇说了后台列表设计的"搜索"设计(详情见:后台列表设计避坑指南 上):本篇继续讲剩下的两个部分的"坑"和必坑指南,我 ...
- HarmonyOS实战 —基于hi3861芯片鸿蒙2.0的避坑指南
HarmonyOS实战 -基于hi3861芯片鸿蒙2.0的避坑指南 特别说明:本文章与卡片开发无关,想看卡片开发的不用往下读了 最近学习鸿蒙设备开发的过程中遇到了很多问题,因为目前几乎所有设备开发教程 ...
- python避坑指南_Linux下Python3.6的安装及避坑指南
Python3的安装 1.安装依赖环境 Python3在安装的过程中可能会用到各种依赖库,所以在正式安装 Python 3之前,需要将这些依赖库先行安装好. yum -y install zlib-d ...
- mac下编译android源码避坑指南(新)
截至目前mac环境下android源码编译最新避坑指南 避坑方法 配置(不说配置的都是耍流氓) 下载 编译 烧录 注意事项 避坑方法 源码.SDK.机型版本一定要清楚,有些特殊的版本需要特殊的方法,官 ...
- 门店管理系统怎么挑选?请收下这份避坑指南!
有些老板可能会混淆门店运营和门店管理,其实区别很简单-- 运营门店,主要以提升销量.为门店创造利润为目的:而管理门店,侧重点在于辅助销售,让门店一切正常运行. 门店管理包含的工作有很多,比如管理门店日 ...
- 凌恩生物资讯|细菌完成图,坑多专家少——请收下这份避坑指南
尝试做细菌完成图的你是不是有很多疑问 这份避坑指南请收好! 小坑1."1 +X Contig,0 Gap"代表什么? 答:"1 Contig,0 Gap"的承诺 ...
最新文章
- 阿里云MWC 2019发布7款产品:Blink每秒可完成17亿次计算
- 用jenkins搭建android自动打包环境
- OpenCvSharp中CV_8UC1,CV_8UC2等参数的解释
- 深入理解Android Paging分页加载库
- MySQL二进制日志的三种模式解析
- python select模块_Python之select模块解析
- java概述_Java 7功能概述
- python访问mysql_python连接mysql
- idea中每次push/pull都需要输入账号密码
- Python calendar日历模块的常用方法
- 漫步微积分十八——变化率问题
- HDU 3359 高斯消元模板题,
- 桌面环境选择_Fedora 30 正式版发布:引入 Deepin 桌面环境(DDE)
- 电能质量分析仪安装(access数据库版本 /WIN10系统) 出现
- Win10系统离线安装可选功能XPS查看器(XPS Viewer)的详细说明(修订版)
- spss导入Excel显示连接服务器超时,Excel里的日期在spss里怎么不正常显示
- 李南江html5教程资源合集,「李南江」HTML+CSS 基础入门教程全套视频 | HTML5+CSS3基础+案例...
- QTableWidget 数据添加与表头设置
- 安卓python编辑器-10 个平板电脑上的 Python 编辑器
- 仿百度文库解决方案——利用FlexPaper显示Flash(SWF)