NoSQL在腾讯海量数据中的应用与实践
一、前言
在腾讯过去的几年中,互联网社交平台取得令人瞩目的发展。包括平台用户基数、在线、应用数都取得突飞猛进的增长;另外随着开放的加剧,还有越来越多的第三方选择社交平台开发应用。这些外部条件的变化对技术平台的而言,也带来了新挑战:除需要为用户提供更强的海量服务外,同时还需要提供开放的软件基础架构来帮助第三方开发海量服务。
在解决这些问题的实践中,总结了很多经验。其中关键一点则是通过NoSQL技术来构建海量服务的数据层,并通过分析和总结出不同的业务场景和技术特点,为各种场景提供更合适的数据层解决方案。具体而言:
相册、日志等UGC类应用,主要是自我产生数据,他人以浏览为主,其技术特点是读取量巨大,修改量低于读取量一个量级,数据量从几百T至P级不等。提供SAS、SATA级的TDB、TFS解决方案。
农牧场等Social Game类应用,核心数据是用户背包数据,互动性很强,其技术特点是巨大读取量与修改量,数据量在百G级别。提供MEM级的TMEM解决方案。
信息中心的Feeds类应用,其技术特点是巨大的修改量与读取量,数据量也在几十T到几百T不等。提供SSD级的TSSD解决方案。

二、【2006~2008】因QQ相册而研发TFS、TDB
回顾NoSQL在腾讯的发展历程,需要从2006年腾讯分布式文件系统TFS 的研发开始谈起,TFS目的是在公司内部构建统一的存储平台,为各个BU提供文件系统服务。第一期的重点是要能够支持到QQ相册的快速发展。当时QQ相册使用传统企业级存储硬件+标准linux文件系统的老架构,在数百亿的图片数,每天近10亿长尾下载的规模下已难以为继。通过分析,老架构主要有下面三个问题:
采用FC-SAN等高端企业级存储硬件,这些硬件主要是针对电信、银行等高ARPU值的行业客户而生,价格通常比较贵,对盛行免费的互联网企业来说,成本压力大。
使用通用的linux文件系统,对相册海量小文件的场景,空间利用和IO性能都不能很好的满足要求。
元数据与对象数据耦合,扩展性和可维护性较差,单机故障以及扩容都是异常繁琐的运维操作。
TFS采用廉价的存储设备,在软件层面使用类似软raid的技术来满足系统基于不可靠硬件的可靠性要求。将对象数据与元数据分离:对象数据存储采用自研的CHUNK文件系统,inode节点更小,空间分配采用了基于append + delete更为紧凑的管理方式,使得单机最大可以支持数10亿的图片文件;元数据使用MYSQL存储。系统架构如下:

上面的架构很好的满足了数百亿级别规模下的QQ相册业务发展。大致在07的时候,QQ相册采用TFS的新架构趋于稳定,同时业务发展需要,对用户上传也放开了限制,用户上传浏览的活跃度上升的一个新的量级,用户目录、文件索引等元数据规模突破千亿。在使用MYSQL应对如此大规模的元数据的场景下,暴露出一些问题:
索引低效:在QQ相册的场景,上千亿的记录,使用MYSQL的B树索引索引的存储量消耗都在数TB到数十TB。 海量索引在无法全内存的情况会带来IO的多次访问,一方面增加了单次访问的时延,另一方面降低了磁盘的IO利用率。
数据搬迁:每天数亿的图片上传导致系统扩容,IDC分布策略,导致数据搬迁是常态。使用MYSQL,使用select逐条记录方式搬迁,不同的记录分散在不同的磁盘偏移,一方面搬迁速度较慢,另一方面由迁移导致的磁盘随机IO与业务正常访问相互交织在一起,从而影响到在线业务访问。
系统控制:MYSQL更多针对是各种数据通用场景所做的设计与开发,实现较复杂。在使用中遇到性能问题,异常故障时难以定位原因,对业务系统来说,已经是无法打破的天花板。
针对上面的问题结合业务需求,07年底研发出TDB用以替代MYSQL,TDB是一个典型的K-V存储系统。其特点是:接口简单,性能高效,具备优秀的扩展能力。
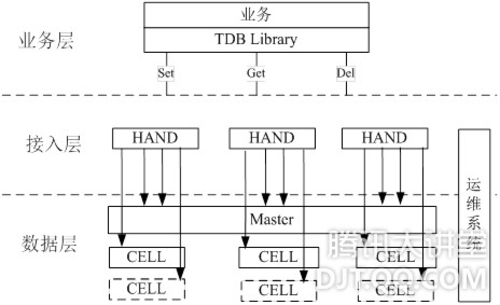
数据层面,索引设计使用HASH,通过KEY可直接定位磁盘物理偏移,避免B树设计导致的二次定位磁盘性能开销,解决索引低效的问题。同时采用16MB大磁盘块的设计,使得TDB的数据迁移速度可达网卡性能上限,解决迁移性能问题。另外系统可控性更强,一方面因为是专用场景,所以可以简化设计,方便定位问题与优化更新;另一方面打通了存储系统到磁盘IO的控制路径,避免MYSQL的系统天花板。
接入层面,为业务提供透明的访问代理,从而实现无缝的水平扩展。由于接口简单,并且是PAAS,业务使用非常方便,从07年底开始,在Qzone、朋友、群空间等社区应用中逐步取得了广泛应用。
三、【2009】Social Game催生的TMEM
09年有一款叫农场的游戏大家应该不会陌生,农场的火爆带动了一批Social Game应用的兴起。其典型特点(1)好友间互动性很强,用户背包数据会被频繁的修改与读取;(2)交叉访问,无明显热点数据;举个例子来说,对于传统的应用来说,用户间交互相对较弱,活跃用户数据就是热点数据;而对于Social Game而言,用户交互性强,通过交叉访问,活跃用户也会频繁访问与修改非活跃用户数据。(3)放大效果明显;比如用户每次登陆,通常会遍历好友的农场,会遍历菜地偷菜,捉虫,一次偷菜、捉虫会导致多个用户的多个背包数据修改。这些行为一方面导致整个系统中无明显热点数据,用户传统的读缓存+写落地的方式则难以很好的满足这些业务的需求;另一方面庞大的用户基数之上的火爆应用,往往单款应用就会有数百万次每秒的访问量,这种海量访问不光对存储层面,同时对网络通讯层面提出更高的性能要求。
针对以上新兴面临的问题,很明显TDB并不能很好的解决,所以09年围绕着网络通信,内存持久化两个方面,做了大量的设计与论证。09年底左右推出新的服务TMEM。
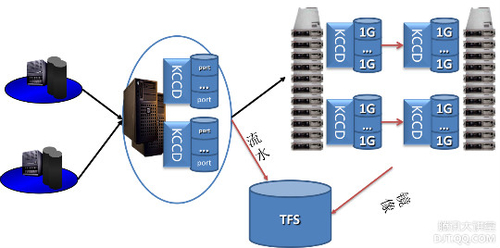
核心有两点:
提供内核级KCCD网络通讯组件,提升网络通信性能,在网络包量吞吐方面相对于应用层提升了接近1倍的性能。
通过将操作流水加数据镜像落地TFS,解决了内存持久化的问题。
TMEM的出现很好的满足了业务海量访问的需求。不过毕竟内存介质的成本比较高,所以TMEM在小数据量的场景下,性价比比较高。但针对于中大数据规模的海量访问的场景,使用TMEM的成本偏高,而使用SAS介质的TDB,则IO性能又不能很好的满足。比如社区中各类应用产生的Feeds,数据量数十TB至数百TB,每天访问量数十亿至数百亿,应对该场景传统的做法必须得是前端内存缓存加上后端落地存储。分级存储导致的内存数据保护,各级间数据一致性,另外最为关键的一点,与Social Game类似,Feeds也是典型交叉访问,热点不是非常明显,等等这些都是数据层亟需解决的难题。
四、【2010】顺SSD之势的TSSD
在10年的时候,引入了SSD存储介质,开始构建TSSD K-V存储系统。SSD的特点:有着很好的随机读取性能,往往单盘可达数万IOPS,远高于SAS、SATA的数百随机IOPS。容量方面也接近SAS盘的容量,可达数百GB。但SSD也有弊端:(1)寿命有限,随机写入的寿命相对于顺序写入为1/10左右;(2)随机写入场景,性能易受干扰,毛刺率较高;具体而言:受限于物理机制,SSD的存储单元只能先擦除才能写入,并且擦除次数有限,针对NAND芯片,在3000~5000次左右。其中擦除单元是512KB,写入单元是4KB。随机写入的场景,会带来写入放大。
因此应用SSD存储介质,必须优化随机写入性能。TSSD通过构建地址映射,增加随机写入内存缓冲区,实现随机转顺序的写入;通过定期的垃圾回收机制,回收垃圾数据。
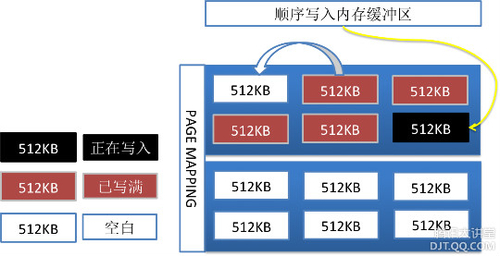
TSSD系统中,单机可以支持容量数TB,性能随机数万次IOPS。这样基于TSSD使用简单的架构,更少的机器便可支持到容量数十至数百TB,性能数十万IOPS的Feeds类应用。
五、NoSQL小结
至此,业已构建出基于内存、SSD、SAS、SATA的各类存储介质的存储系统,在上面也已提到各类存储系统所对应的使用场景。实际应用中,各种业务场景千变万化,有没有统一的方法来判别和选择合适的存储系统呢? 大致在 1987 年,Jim Gray发表了这个“五分钟法则”的观点,简而言之,如果一条记录频繁被访问,就应该放到内存里,否则的话就应该待在硬盘上按需要再访问。这个临界点就是五分钟。这个看似经验公式,隐含的是硬件性能和成本两个方面的因素。大约在97的时候,Jim Gray再次回顾了该法则,并引入了SSD,验证了该法则依然正确。这里不在赘述该法则。
很多情况下需要一种直接根据业务的访问模型,因此使用IO访问密度,即每GB的存储的IO访问次数,会更为直观。那看看目前常用的几种存储介质:
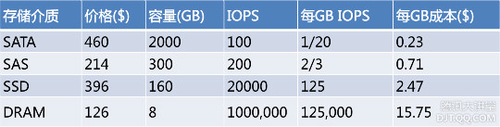
SATA:希捷2TB/7200转/SATA(ST32000644NS)
SAS:希捷300GB/15000转/SAS(ST3300657SS)
SSD:Intel 160GB X25-M G2 34nm
DRAM:三星8GB DDR3 1333 REG ECC
(中关村在线报价,人民币美元汇率:6.3157,2012/4/16)
根据业务IO访问密度,选择合适的存储介质,就是根据存储介质的IO访问密度特性与价格来选择性价比最高的存储介质,即找到每种存储介质之间IO访问密度的临界点。
临界点G(X,Y).IO per sec per GB = X.IO per sec per GB * Y.price per GB / X. price per GB,X与Y分别表示对比的两种存储介质,且Y.IO per sec per GB 大于 X.IO per sec per GB。
根据上面的公式,可以得到表格如下:

怎么理解上面的公式呢?举计算SATA与SAS之间的临界点为例,G(SATA,SAS).IO per sec per GB = SATA.IO per sec per GB* SAS.price per GB/SATA.price per GB = 1/20 * 0.71/0.23 = 0.15 per sec per GB。假设现在有1GB的数据,访问密度是X,X小于2/3,那么使用SAS介质则需要0.71$,如果选择SATA介质,则需要X/(1/20) * 0.23 $。当X为0.15时,选择SATA与SAS的成本是一样的,当大于0.15时,则使用SATA的成本相对于SAS则高;否则则低。SAS比SSD,SSD比DRAM也是类似。
实际上对于一款存储介质而言,IO访问特性与单位每GB的成本是决定了其存在与生命力的关键因素。通常来讲,其IO访问特性一般来讲不会有革命性的变化,而单位每GB的成本却是可以控制的,所以厂商总是会围绕容量来不断的深入优化。
六、开放的挑战
10年底开始,随着开放的加剧,越来越多的第三方选择社交平台开发应用。这些外部条件的变化对技术平台的而言,也带来了新挑战:除需要为用户提供更强的海量服务外,同时还需要提供开放的软件基础架构来帮助第三方开发海量服务。现有已成熟的NoSQL的架构能否被外部第三方接受,其关键的一点是接口的友好性和兼容性。采用的标准化的接口,会大大降低外部开发者的使用门槛。因此,在11年推出了CMEM 的NoSQL云存储服务,开发者可直接使用memcached接口,并即将支持redis接口。同时也提供了SQL云存储服务,开发者可用MYSQL客户端直接访问。后续推出CFS文件系统云存储服务,开发者可使用posix接口访问到TFS。

回顾TFS、TDB、TMEM、TSSD、CMEM、CDB、CFS等一系列存储系统过去近6个年头的演进发展。有两点经验可供分享:
1、 建议NoSQL开发者尽量选择构建PAAS服务。一方面对业务开发者而言,不需关心日常运维,使用更为方便,易于接受;另一方面更容易形成用户需求提出、实现与发布的闭环,从而方便小步快跑,快速迭代出完善的服务。
2、 建议中小业务开发者尽量使用云服务。通常一个NoSQL服务所面临的挑战有两个方面:一方面是大家所直观感受的产品本身;另一方面是服务背后的运营体系。类似与铁路系统、消防系统,用户所直观感受到的火车、铁路,消防栓、消防车只是整个服务其中一个部分,是冰山海平面之上的部分;用户所感受不到的铁路规划、调度系统、消防规划、消防演练,报警系统等后台运营体系通常是冰山海平面以下的部分,往往需要有大量的人力和财力投入,可能是中小公司难以投入的。而在没有稳固的后台运营体系支撑下,类似动车事故、火灾等生产系统故障难以避免,并最终为业务带来不可估量的损失。
从过去几年来看,硬件在变,存储介质的性能与容量在不断提升,并不断会有新存储介质的产生;业务在变,不断有新兴的产品和新的业务体验,并对后台系统提出新的挑战和需求;唯一不变的就是需要拥抱变化,为业务提供更贴切与更优化的存储服务。
NoSQL在腾讯海量数据中的应用与实践相关推荐
- 【实践】多模态内容理解技术在腾讯搜索中的应用及实践.pdf(附下载链接)
猜你喜欢 0.[免费下载]2021年11月热门报告盘点1.如何搭建一套个性化推荐系统?2.从零开始搭建创业公司后台技术栈3.全民K歌推荐系统算法.架构及后台实现4.微博推荐算法实践与机器学习平台演进5 ...
- NoSQL 在腾讯应用实践
NoSQL 在腾讯应用实践 吴悦,http://t.qq.com/iwuyue 腾讯大讲堂特约讲师,腾讯T4技术专家.先后参与腾讯分布式文件系统(TFS),K-V存储,SQL集群,接入网关(TGW)的 ...
- NoSQL在腾讯的应用实践
导读:本文针对腾讯的NoSQL应用,从研发TFS.TDB.TMEM.TSSD到NoSQL所面临的挑战作出了详尽的解析,极具参考价值! 关键词:NoSQL 腾讯 存储 一.前言 NoSQL的历史很长,最 ...
- Peacock:大规模主题模型及其在腾讯业务中的应用
Peacock:大规模主题模型及其在腾讯业务中的应用 2015/03/02分布式计算.机器学习.自然语言处理LDA.Peacock.数据并行.模型并行xueminzhao Peacock:大规模主题模 ...
- 腾讯员工中66%是研发,用C++最多,去年新写12.9亿行代码
乾明 发自 凹非寺 量子位 报道 | 公众号 QbitAI 在腾讯做研发是种怎样的体验?现在,"鹅厂"用官方数据给出了答案. 今天(3月10日),腾讯发布<腾讯研发大数据报 ...
- 海量数据中,寻找最小的k个数。
维护k个元素的最大堆,即用容量为k的最大堆存储最小的k个数,k1设为大顶堆中最大元素.遍历一次数列,n,每次遍历一个元素x,与堆顶元素比 较,x<kmax,更新堆,否则不更新堆. 1 // 海量 ...
- Peacock:大规模主题模型及其在腾讯业务中的应用-2015
Peacock:大规模主题模型及其在腾讯业务中的应用 作者:赵学敏 王莉峰 王流斌 孙振龙 严浩 靳志辉 王益 摘要 如果用户最近搜索了"红酒木瓜汤",那么应该展示什么样的广告呢? ...
- 找出一个字符串中出现次数最多的字_海量数据中找出前k大数(topk问题)
在海量数据中找出出现频率最好的前k个数,或者从海量数据中找出最大的前k个数,这类问题通常被称为top K问题. 针对top K类问题,通常比较好的方案是分治+Trie树/hash+小顶堆(就是上面提到 ...
- 如何在海量数据中查询一个值是否存在?
一般面试中考察的题目通常是由三类组成的,基础面试题.进阶面试题.开放性面试题,而本文的题目则属于一个开放性的面试题,但对于 Redis 这种以数据为核心的缓存中间件来说,实现在海量数据中查询一个值是否 ...
最新文章
- tomcat与iis公用80端口(已经发布.net项目现在开发Java项目时tomcat在eclipse中localhost:8080打不开问题)...
- jQuery的ajax的post请求json格式无法上传空数组
- 机器学习(五)——缓解过拟合
- 【职场】还真的遇到了个失业开滴滴的程序员
- SAP CRM Enterprise Search change pointer的存储数据库表
- 0.Overview----Machine Learning
- 美国IARPA发起人脸识别算法融合大奖赛
- 自动驾驶_感知_目标检测(基于图像)
- lopatkin俄大神精简系统Windows 10 Pro 18362.10006 19H2 PreRelease x86-x64 ZH-CN MICRO
- 五种常用大数据分析方法
- sast/dast/iast对比介绍
- SolidWorks中最好用功能最强的BOM汇总工具:DDBOM2010
- 生物信息学入门之基本概念之蛋白质同源检测和折叠识别
- python打开记事本并输入内容_打开记事本输入文字
- KDE-Graphics(KDE图形图像软件)先容
- Python自动玩俄罗斯方块小游戏
- 怎样理解大数据概念?大数据有什么用处?
- H1B政策大变,要集体涨工资了吗?
- LOL 和 Dota游戏设计的区别
- 【读书笔记】《奇特的一生》