Data Structure_Sort Algorithm
排序算法
Tool implement
//generate a array of n elements, range [rangL, rangeR]int *generateRandomArray(int n, int rangL, int rangeR) {assert(rangeR >= rangL);int *arr = new int[n];srand(time(NULL));for (int i = 0; i < n; i++) {arr[i] = rand() % (rangeR - rangL + 1) + rangL;}return arr;}template<typename T>void showArray(T arr[], int n) {for (int i = 0; i < n; i++) {cout << arr[i] << " ";}cout << endl;}
生成随机的n个数量的数组,输出数组每一个元素的内容。测试排序算法使用的标准就是运行时间和排序的正确性,所以需要一个验证正确性和计算排序时间的:
template<typename T>void testSort( string sortName, void(*sort)(T[], int), T arr[], int n){clock_t startTime = clock();sort(arr, n);clock_t endTime = clock();if (isSorted(arr, n)){cout << sortName << ": " << double(endTime - startTime)/CLOCKS_PER_SEC << "s" << endl;} elsecout << "sort function is wrong!" << endl;return;}template<typename T>bool isSorted(T arr[], int n){for (int i = 0; i < n-1; i++){if (arr[i] > arr[i+1])return false;}return true;}
 的排序
的排序
这种算法应该是属于比较慢的算法了,编码简单,易于实现,是一些简单场景的选择。在一些特殊情况下,简单的排序算法更容易实现且更有效。从简单的算法演变到复杂的算法,循序渐进,作为子过程改进跟复杂的算法。
选择排序——SelectionSort
选择排序比较简单,如果是最简单的一个了。基本思想就是遍历每一个位置,选择这个位置之后最小的元素与当前元素对换:

比如这个数组,一开始是第一个位置,然后选择2到n个位置最小的元素,找到就是1了,然后和第一个元素互换:

也就是挨个挨个位置找到最小的元素。很明显,毫无疑问,他的复杂度肯定就是
。
代码实现:
template<typename T>
void SelectionSort(T arr[], int n) {for (int i = 0; i < n; i++) {int minIndex = i;for (int j = i; j < n; j++) {if (arr[j] < arr[minIndex])minIndex = j;}swap(arr[minIndex], arr[i]);}
}由于是模板类,所以还可以用来排序string,运算符重载还可以用来对类排序。
定义一个学生类用于排序:
struct student{string name;float score;bool operator<(const student &otherStudent){return score < otherStudent.score;}friend ostream& operator<<(ostream &os, const student &otherStudent){os << "Student: " << otherStudent.name << " " << otherStudent.score << endl;return os;}};

插入排序——InsertionSort
插入排序也是一个的排序算法。

一开始先比较了第一和第二位,如果顺序是正确的,那么就不换,继续比较第三第四位,2比8小交换位置,比6有小交换位置,直到适合它的位置即可。

以此类推最后排序完成。如果要判断的元素是刚刚好大于之前的元素的时候,那么就不用比较了,所以插入排序操作是可以比选择排序要快的,来看一些代码实现:
template<typename T>
void InsertionSort(T arr[], int n){for (int i = 1; i < n; i ++){for (int j = i; j > 0; j --){if (arr[j] < arr[j-1]){swap(arr[j], arr[j-1]);} elsebreak;}}
}
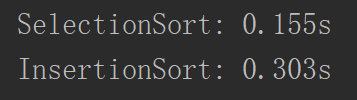
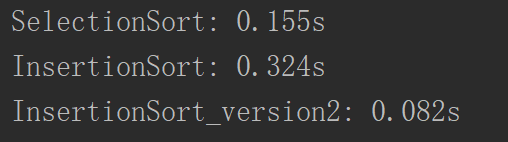
然而事与愿违,时间反而多了一倍。这是和插入排序的一些交换操作引起的,插入排序虽然可以终止某些交换操作,但是在遍历的时候同时也做交换了,每一次交换就有三次赋值的操作,再加上索引数组这些时间,就远大于选择排序了。为了减少这种交换的次数,我们改进一下:
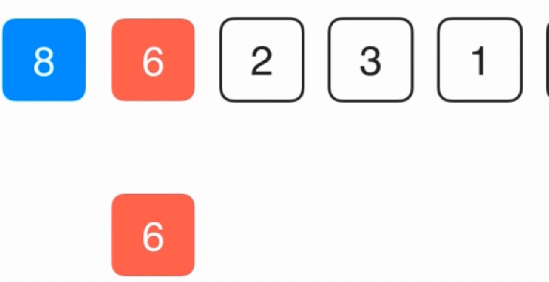
一开始只做比较不做交换,复制一份6出来,比较6和8,如果8是大于6的,就证明这个8是不应该在当前位置的,所以8覆盖6,然后6往前移动,按照正常套路进行比较下去。
代码实现:
template<typename T>
void InsertionSort_version2(T arr[], int n){for (int i = 1; i < n; i ++){T temp = arr[i];int j = 0;for (j = i; j > 0 && arr[j-1] > temp; j --){arr[j] = arr[j-1];}arr[j] = temp;}
这次就正常了:
对于插入排序还有一个比较好的性质,如果当前数组是一个基本有序的数组那么基本插入排序每一次就基本被终止了,那么就会很快。
 的排序
的排序
在小数据量的情况下,两者的差别都不会特别大,但是当数据量变大的时候,两者的差别就会越来越大了。
归并排序——MergeSort
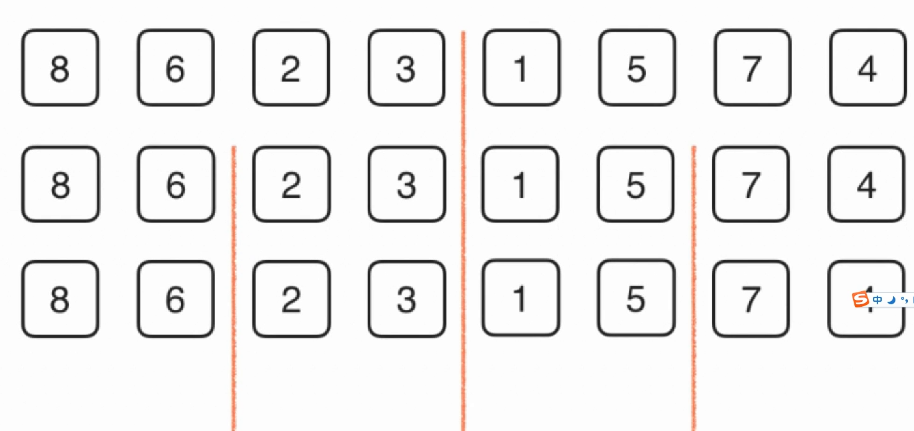
步骤其实很简单,首先进行划分,当划分到一定的细度的时候就不能划分了,然后就进行归并
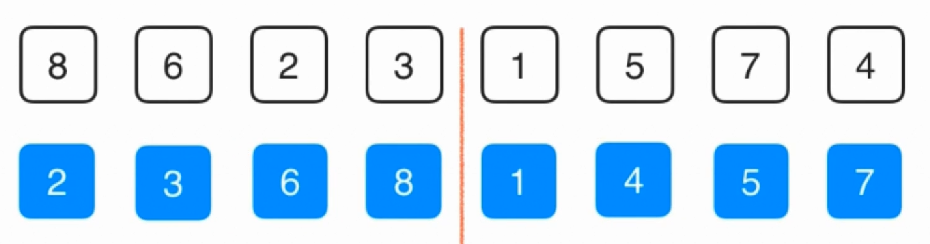
然后往上归并即可。划分的时间是
,归并的时候就是
了,所以一共就是
级别了。那么主要的困难就是归并的时候了:

如何把如上的两个归并的数组合并?

需要用到三个索引,两个红色的索引代表的就是已经排好序的两个数组,蓝色的指向了一个临时空间:
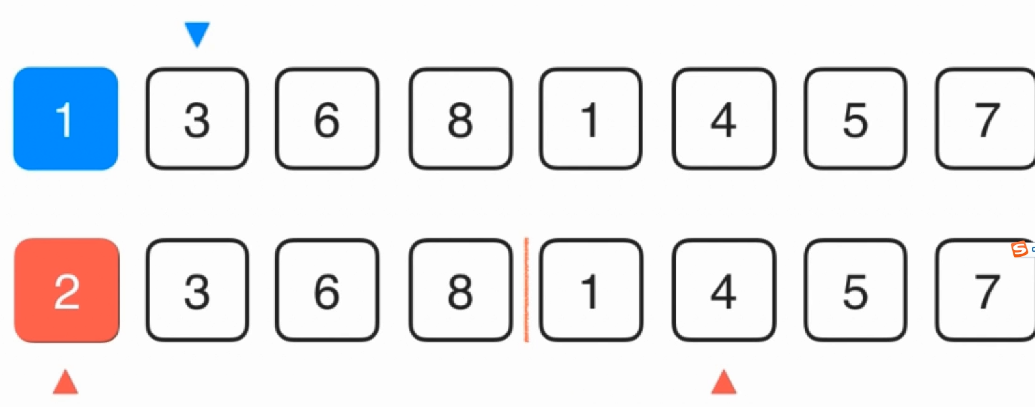
一开始2和1比较,1比较小,那么1就填在了蓝色索引的位置,蓝色索引加一,因为1填进去了,所以右边的红色索引加一,以此类推,到最后哪边没有完就直接整块扔进去就好了。代码实现:
template<typename T>
void __merge(T arr[], int l, int mid, int r) {T *temp = new T[r-l+1];for (int i = l; i <= r; i++) {temp[i - l] = arr[i];}int i = l, j = mid + 1;for (int k = l; k <= r; k++) {if (i > mid) {arr[k] = temp[j - l];j++;} else if (j > r) {arr[k] = temp[i - l];i++;} else if (temp[i - l] < temp[j - l]) {arr[k] = temp[i - l];i++;} else {arr[k] = temp[j - l];j++;}}delete[] temp;
}template<typename T>
void __mergeSort(T arr, int l, int r) {if (l >= r) {return;} else {int mid = (l + r) / 2;__mergeSort(arr, l, mid);__mergeSort(arr, mid + 1, r);__merge(arr, l, mid, r);}
}template<typename T>
void MergeSort(T arr[], int n) {__mergeSort(arr, 0, n - 1);
}
最主要的就是Merge函数了。对于temp数组是存在有偏移的,所以是需要减去一个偏移量,因为到最后l和r不一定是从0开始的。
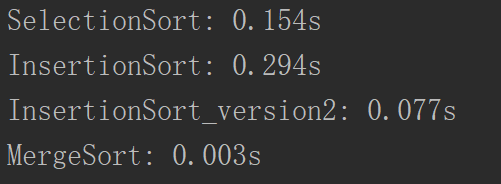
可以看到对于一万个数组排序的时间很快,其实归并排序就是典型的用空间换时间的,每一次递归就开了一个空间,每一次递归的时候还有一个缓冲数组,所以使用的空间复杂度比一般的排序算法要大。
如果是十万个数据那么差距就更加大了:
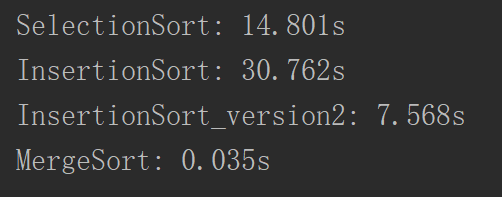
但是对于这个代码来说,还是可以优化的,因为在归并的时候,我们是无论两边的数组是个什么情况都进行一个归并,但是事实上这样是不严谨的,因为事实上如果一边的最大的元素小于另一边的最小的元素,就可以说完全大于了,所以加上判断:
void __mergeSort(T arr, int l, int r) {if (l >= r) {return;} else {int mid = (l + r) / 2;__mergeSort(arr, l, mid);__mergeSort(arr, mid + 1, r);if (arr[mid] > arr[mid + 1]) {__merge(arr, l, mid, r);}}
}
加上一个判断即可。
自底向上的归并排序——upMergeSort
其实思想都是一样的,都是分而治之的思想,先两个两个的排,然后四个四个的排,然后八个八个的排,以此类推:

先两个两个的排,然后四个四个:

之后8个一起,这个过程其实不需要递归,直接迭代实现即可。
template<typename T>
void upMergeSort(T arr[], int n){for (int sz = 1; sz <= n; sz = sz + sz){for (int i = 0; i + sz < n; i += sz + sz){__merge(arr, i, i+sz-1, min(i+sz+sz-1, n-1));}}
}
可以看到代码量很少。
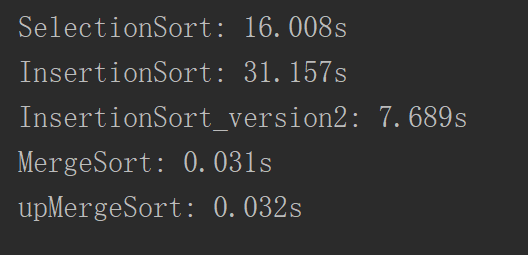
时间差不多。
快速排序——QuickSort
归并排序和快速排序不同的就是,归并排序是无论什么情况直接就一分为二两部分,快速排序也是分成两部分,但是快速排序是先找到对应的一个元素的位置,然后直接找到这个元素应该在的位置:
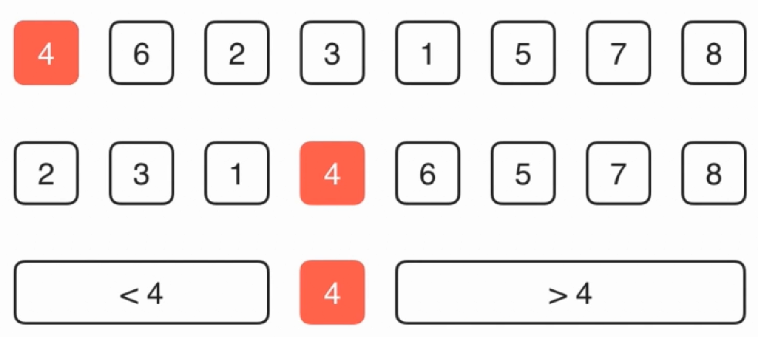
比如4,找到这个元素所在的位置。这个时候这个数组就有一个性质了,左边的元素一定比4小,右边的一定比4要大。那么接下来的主要操作就是在于如何找到4这个元素对应的位置。

v是要分割的数字,e就是当前要判断的数字。有两个情况要判断,如果是大于V的,那就简单了,直接i++,如果是小于V,那就把i和j+1的数字进行交换即可,然后j++,最后i++即可。
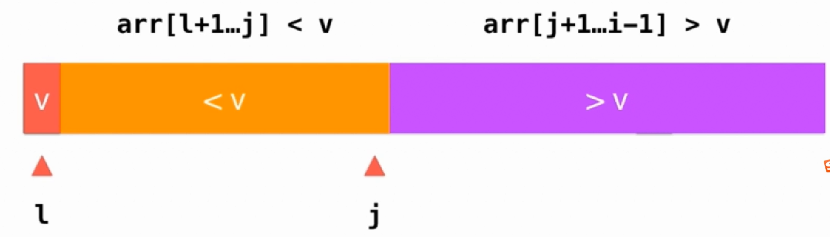
最后就是这个样子,只需要j和l换即可。
代码实现:
template<typename T>
int __partition(T arr[], int l, int r) {T v = arr[l];int j = l;for (int i = l + 1; i <= r; i++) {if (arr[i] < v) {swap(arr[j + 1], arr[i]);j++;}}swap(arr[j], arr[l]);return j;
}template<typename T>
void __quickSort(T arr[], int l, int r) {if (l >= r) {return;}int p = __partition(arr, l, r);__quickSort(arr, l, p - 1);__quickSort(arr, p + 1, r);
}template<typename T>
void QuickSort(T arr[], int n) {__quickSort(arr, 0, n - 1);
}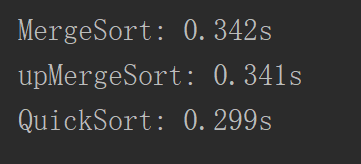
.可以看到效果还是有的。快速排序之所以是
是因为每一次都会分成两个,但是是不均等的两个:
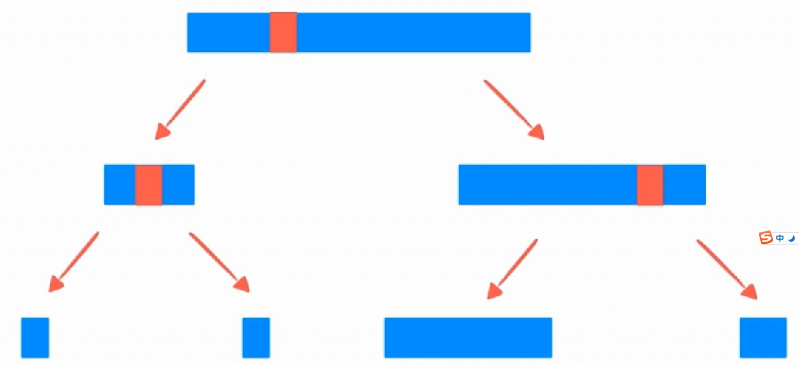
这样,问题就来了,如果这个数组是一个基本有序的数组,那么大概就是这样了:
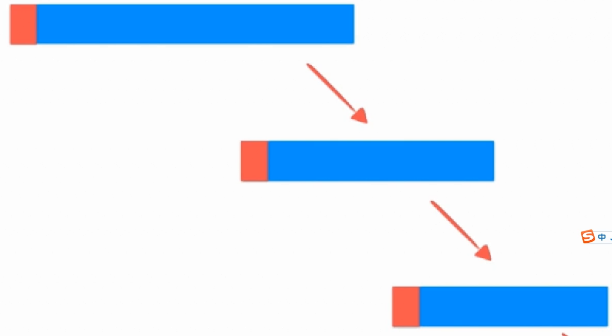
退化成了
的问题,因为我们选择的是第一个个元素进行排序,所以改进我们就可以随机选择一个元素做分割,改进一下。选择一个随机:
template<typename T>
int __partition(T arr[], int l, int r) {swap(arr[l], arr[rand()%(r-l+1)+l]);T v = arr[l];int j = l;for (int i = l + 1; i <= r; i++) {if (arr[i] < v) {swap(arr[j + 1], arr[i]);j++;}}
效果就不出了。
接下来还有一个问题,如果这个数组是一个基本有序的数组,测试一下数据:

可以看到快速排序还是慢了点。为什么会这样,我们考虑一下partition函数:

当拥有大量重复元素的时候问题来了:

那么切分的时候自然又回到刚刚的情况了。
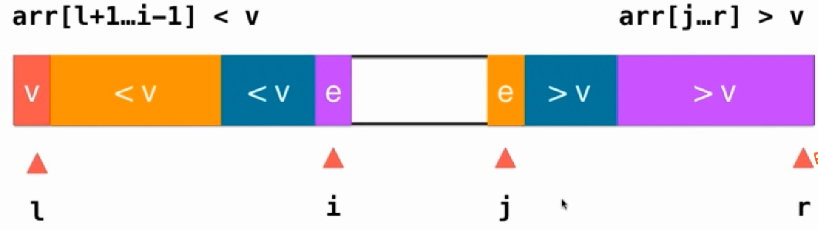
我们可以用这种方法进行改进,把大于和小于的放在两边,找到i和j大于V和小于V就停下,交换两个的值。
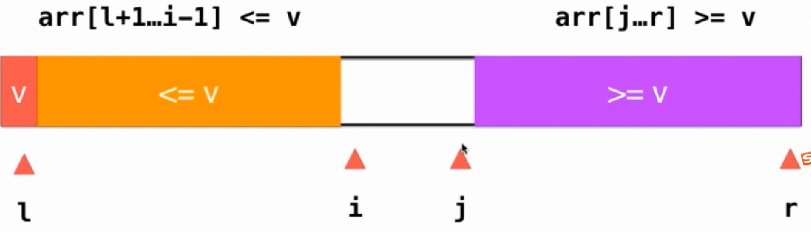
按照如上的这一种结构就算是有大量的重复的数值也可以平均分开,达到两边是相同的数量。
代码实现:
template<typename T>
int __partition_version2(T arr[], int l, int r) {swap(arr[l], arr[rand() % (r - l + 1) + l]);T v = arr[l];int i = l+1, j = r;while (true){while (i <= r && arr[i] < v){i++;}while (j >= l+1 && arr[j] > v){j--;}if (i > j){break;} else{swap(arr[i], arr[j]);i++;j--;}}swap(arr[l], arr[j]);return j;
}
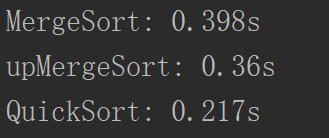
这样效果就好很多了。
实现带有重复元素的数组快速排序还有一个更加经典的实现方法,就是三路排序了。
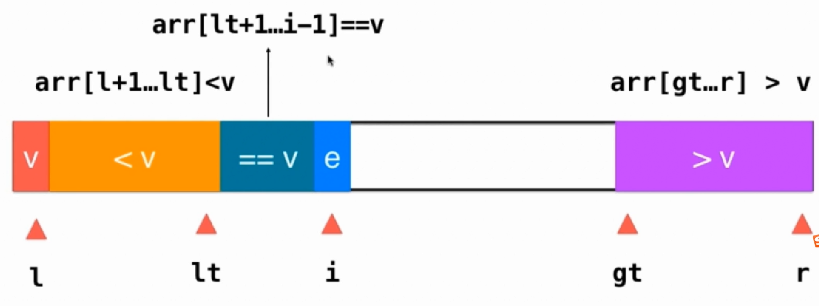
代码实现:
template<typename T>
int __partition_version3(T arr[], int l, int r){swap(arr[l], arr[rand() % (r - l + 1) + l]);T v = arr[l];int lt = l, gt = r+1, i = l+1;while (i < gt){if (arr[i] < v){swap(arr[i], arr[lt+1]);lt++;i++;} else if (arr[i] > v){swap(arr[i], arr[gt-1]);gt--;} else{i++;}}swap(arr[l], arr[lt]);return lt;
}
堆排序——HeapSort
堆是一种比较常用的数据结构,常用的堆有二叉堆,费波纳茨堆等等。堆是一颗完全二叉树,除了最后一层其他的每一层都是满的,而最后一层都的子节点都是集中在了左边。堆的实现在DataStructure里面提到,实现很简单。因为实现的是最大堆,出来的元素就是最大的:
using namespace std;
template<typename T>
void HeapSort_version1(T arr[], int n){MaxHeap<T> heap = MaxHeap<T>(n);for (int i = 0; i < n; ++i) {heap.insert(arr[i]);}for (int j = n-1; j >= 0; --j) {arr[j] = heap.pop();}
}
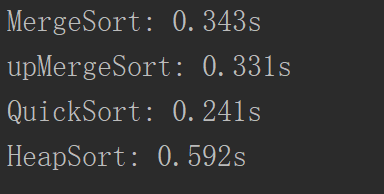
但是有一个小问题,每一次都是插入这样效率不高,所以我们可以直接在原数组上操作
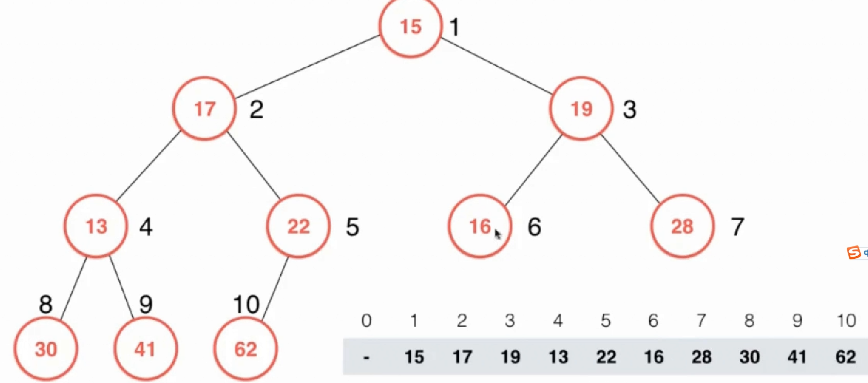
比如这就并不是一个正确的最大堆,需要用heapify转变一下。注意到每一个叶子都是一个堆,而且是符合规定的堆,所以肯定是从最底层开始。第一个不是堆的节点一定是最后一个叶子除2。所以第一个要做的就是对第一个不是堆的节点进行排序,很明显就是22这个元素了,对比交换,这个过程其实就是一个shitDown的过程,而我们要shitdown的元素是那5个不是堆的元素,所以对于这个数组直接做5次循环对每一个不是堆的元素进行shiftDown操作即可。
MaxHeap(item arr[], int n){data = new item[n+1];capacity = n;for (int i = 0; i < n; ++i) {data[i+1] = arr[i];}count = n;for (int j = count/2; j >= 1; --j) {shiftDown(j);}}
之后就可以使用heapify来代替迭代插入,其实效果差别不大。堆排序在现实中其实蛮少用到的,常用的还是对于动态数据结构的维护。
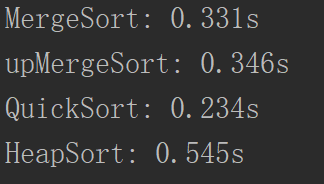
事实上这个版本的和上一个版本的差别是不大的。刚刚的一个一个元素插入堆里面的计算复杂度是
,而使用heapify的复杂度是
。上面的排序每一次都是复制一个数组出来排序,但是如果原地在原数组上进行排序,速度是可以快很多的,这个就是原地堆排序。

当前数组是一个最大堆,那么他的第一个元素就是v,那么v就是最大的元素,这个最大的元素应该在最后,所以和最后一个元素调换位置;

这个时候前面的几个元素就不是堆了。这个时候继续对第一个元素进行shifDown操作,之后再交换即可。但是如果是这样,那就需要调整一下索引,之前是1开始,那么现在就要从0开始了。
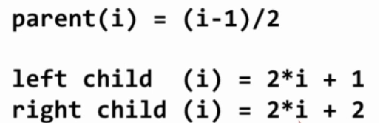
自然公式就要变一下。这个时候最后一个非叶子节点的索引就是(count-1)/2。所以,第一步就是先建立一个堆,就在当前的数组上建立;建立好堆之后那么第一个元素就是最大的元素了,这个时候最大的元素应该是在最后的,所以第二部就是要将第一个元素和最后一个元素交换,然后把最后一个元素之前的(n-1)个元素进行heapify操作,之后又交换又heapify直到前面就剩下一个元素即可。所以首先要重写shiftDown操作,因为这个操作的索引已经是从0开始了:
template<typename T>
void __shiftDown(T arr[], int n, int i){while (2*i + 1 < n){int change = 2*i + 1;if (change + 1 < n && arr[change] < arr[change+1]){change ++;}if (arr[i] >= arr[change]){break;}swap(arr[i], arr[change]);i = change;}
}接下了就是按照上述流程排序:
template<typename T>
void HeapSort_version2(T arr[], int n) {//heapify,create a max heap;for (int i = (n-1)/2; i >= 0; --i) {__shiftDown(arr, n, i);}for (int j = n-1; j > 0 ; --j) {swap(arr[0], arr[j]);__shiftDown(arr, j, 0);}
}
看看效果:
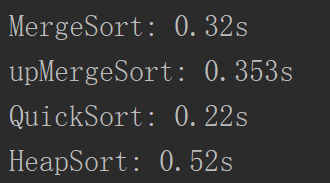
差别不是特别大,但是总的来说还是快了,因为它不需要进行额外的空间,也不需要赋值的操作等等,相对会快点。
排序算法总结
| 平均时间复杂度 | 原地排序 | 额外空间 | 稳定性 | |
|---|---|---|---|---|
| Insertion Sort |
|
是 |
|
是 |
| Merge Sort |
|
否 |
|
是 |
| Quick Sort |
|
是 |
|
否 |
| Heap Sort |
|
是 |
|
否 |
快速排序的额外空间是logn,因为递归的次数就是logn,而每一次递归就需要一个栈空间来存储。
最后附上GitHub代码:https://github.com/GreenArrow2017/DataStructure/tree/master/SortAlgorithm
Data Structure_Sort Algorithm相关推荐
- 论文笔记|A Block-sorting Lossless Data Compression Algorithm
文章目录 1 简介 1.1 创新 2 方法 2.1 编码 2.2 解码 3 实验 1 简介 论文题目:A Block-sorting Lossless Data Compression Algorit ...
- [Data Structure Algorithm] 哈希表
哈希方法(Hashing) - 散列 通过函数h将K映射到表T[0..M-1]的下标上,这样h(Ki)就是对应结点Ki的存储地址 哈希表 - T 哈希表长 - M 哈希函数 - h 冲突(Collis ...
- 用Java实现几种常用排序算法(先实现一个org.rut.util.algorithm.SortUtil)
先实现org.rut.util.algorithm.SortUtil这个类(以后每个排序都会用到): package org.rut.util.algorithm; import org.rut.ut ...
- [转]Data mining with WEKA, Part 3: Nearest Neighbor and server-side library
原文地址: http://www.ibm.com/developerworks/opensource/library/os-weka3/index.html by : Michael Abernet ...
- k Nearest Neighbor Algorithm
k Nearest Neighbor Algorithm k Nearest Neighbor(kNN) algorithm算法和k-Means算法一样,都是简单理解,但是实际效果出人意料的算法之一. ...
- 【python】Algorithm
枚举法 递推 与枚举算法思想相比,递推算法能够通过已知的某个条件,利用特定的关系得出中间推论,然后逐步递推,直到得到结果为止.由此可见,递推算法要比枚举算法聪明,它不会尝试每种可能的方案. 在日常应用 ...
- 卡尔曼滤波算法-Kalman Filter Algorithm
1.简介 1.1 滤波是什么 所谓了滤波,就是从混合在一起的诸多信号中提取出所需要的信号. 1.2 信号的分类: (1)确定性信号:可以表示为确定的时间函数,可确定其在任何时刻的量值.(具有确定的频谱 ...
- 每周大数据论文(二)Data Mining with Big Data
日常声明:论文均来自于谷歌学术或者其他国外付费论文站,博主只是读论文,译论文,分享知识,如有侵权联系我删除,谢谢.同时希望和大家一起学习,有好的论文可以推荐给我,我翻译了放上来,也欢迎大家关注我的读论 ...
- C语言实现DES,3DES以及基于3DES的文件加密系统
C语言实现3DES文件加密系统 DES算法 密钥操作 明文操作 3DES算法 C语言代码实现 代码效果展示 DES算法 DES(数据加密标准)是一种分组密码.明文,密文和密钥的分组长度都是64位. D ...
最新文章
- 致首次创业者:如果做到了这三点,想不成功都难(转)
- mysql 保留两位小数
- 2016年第七届蓝桥杯 - 国赛 - Java大学C组 - A. 平方末尾
- php通过url传递变量,PHP:如何在模态URL中放置和传递变量
- 在互联网行业呆了这么多年
- access month函数用法_掌握时间智能函数,同比环比各种比,轻松搞定!
- oracle 手动链库,Oracle 数据库干数据库链(Database links)的两个例子
- Java基础Character类、Math类、Date类、DateFormat类、Calendar类
- D02-R语言基础学习
- Logism · 八位可控加减法器 实验
- 中国诗歌艺术9诗的魅惑:中国诗歌的几个基本元素之诗的节奏与韵律
- at指令 meid_【技术分享】使用AT调制解调器命令解锁LG Android屏幕
- FishEye Crucible分析
- vue.jsv-html,关于vue.js v-bind 的一些理解和思考,vue.jsv-bind
- html显示svg图片,HTML5/CSS3系列教程:使用SVG图片
- linux dumpe2fs命令
- Android 列表视图制作古诗词
- 【示波器专题】示波器探头不同的衰减比对测量的影响
- ORA-15064 ORA-03113 - 测试库案例
- Day-1 HTML基本标签和CSS常用样式
热门文章
- Volley源码分析
- 在IntentService中使用Toast与在Service中使用Toast的异同,intentservicetoast
- 线程池之ScheduledThreadPool学习
- Android性能优化典范第二季
- 【Android View绘制体系】invalidate
- java gui 项目解密,java GUI(实例小项目--列出磁盘目录)
- python转cython_用Cython加速Python到“起飞”(推荐)
- (转)spring源码解析,spring工作原理
- Ubuntu16.04LTS安装集成开发工具IDE: CodeBlocks 和Eclipse-cdt
- git pull 显示的冲突---解决办法git stash