VAE--就是AutoEncoder的编码输出服从正态分布
花式解释AutoEncoder与VAE
什么是自动编码器
自动编码器(AutoEncoder)最开始作为一种数据的压缩方法,其特点有:
1)跟数据相关程度很高,这意味着自动编码器只能压缩与训练数据相似的数据,这个其实比较显然,因为使用神经网络提取的特征一般是高度相关于原始的训练集,使用人脸训练出来的自动编码器在压缩自然界动物的图片是表现就会比较差,因为它只学习到了人脸的特征,而没有能够学习到自然界图片的特征;
2)压缩后数据是有损的,这是因为在降维的过程中不可避免的要丢失掉信息;
到了2012年,人们发现在卷积网络中使用自动编码器做逐层预训练可以训练更加深层的网络,但是很快人们发现良好的初始化策略要比费劲的逐层预训练有效地多,2014年出现的Batch Normalization技术也是的更深的网络能够被被有效训练,到了15年底,通过残差(ResNet)我们基本可以训练任意深度的神经网络。
所以现在自动编码器主要应用有两个方面,第一是数据去噪,第二是进行可视化降维。然而自动编码器还有着一个功能就是生成数据。
我们之前讲过GAN,它与GAN相比有着一些好处,同时也有着一些缺点。我们先来讲讲其跟GAN相比有着哪些优点。
第一点,我们使用GAN来生成图片有个很不好的缺点就是我们生成图片使用的随机高斯噪声,这意味着我们并不能生成任意我们指定类型的图片,也就是说我们没办法决定使用哪种随机噪声能够产生我们想要的图片,除非我们能够把初始分布全部试一遍。但是使用自动编码器我们就能够通过输出图片的编码过程得到这种类型图片的编码之后的分布,相当于我们是知道每种图片对应的噪声分布,我们就能够通过选择特定的噪声来生成我们想要生成的图片。
第二点,这既是生成网络的优点同时又有着一定的局限性,这就是生成网络通过对抗过程来区分“真”的图片和“假”的图片,然而这样得到的图片只是尽可能像真的,但是这并不能保证图片的内容是我们想要的,换句话说,有可能生成网络尽可能的去生成一些背景图案使得其尽可能真,但是里面没有实际的物体。
自动编码器的结构
首先我们给出自动编码器的一般结构
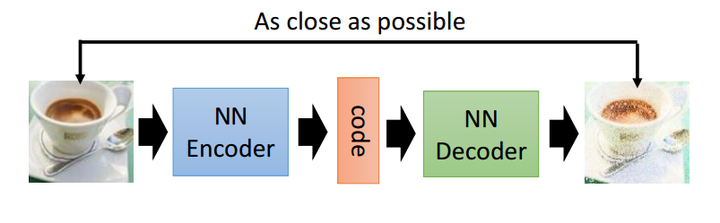
从上面的图中,我们能够看到两个部分,第一个部分是编码器(Encoder),第二个部分是解码器(Decoder),编码器和解码器都可以是任意的模型,通常我们使用神经网络模型作为编码器和解码器。输入的数据经过神经网络降维到一个编码(code),接着又通过另外一个神经网络去解码得到一个与输入原数据一模一样的生成数据,然后通过去比较这两个数据,最小化他们之间的差异来训练这个网络中编码器和解码器的参数。当这个过程训练完之后,我们可以拿出这个解码器,随机传入一个编码(code),希望通过解码器能够生成一个和原数据差不多的数据,上面这种图这个例子就是希望能够生成一张差不多的图片。
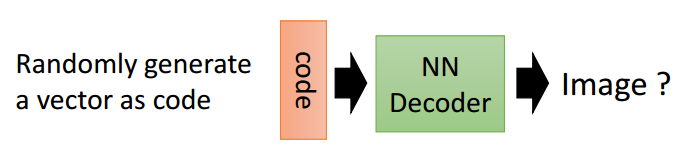
这件事情能不能实现呢?其实是可以的,下面我们会用PyTorch来简单的实现一个自动编码器。
首先我们构建一个简单的多层感知器来实现一下。
class autoencoder(nn.Module): def __init__(self): super(autoencoder, self).__init__() self.encoder = nn.Sequential( nn.Linear(28*28, 128), nn.ReLU(True), nn.Linear(128, 64), nn.ReLU(True), nn.Linear(64, 12), nn.ReLU(True), nn.Linear(12, 3) ) self.decoder = nn.Sequential( nn.Linear(3, 12), nn.ReLU(True), nn.Linear(12, 64), nn.ReLU(True), nn.Linear(64, 128), nn.ReLU(True), nn.Linear(128, 28*28), nn.Tanh() ) def forward(self, x): x = self.encoder(x) x = self.decoder(x) return x 这里我们定义了一个简单的4层网络作为编码器,中间使用ReLU激活函数,最后输出的维度是3维的,定义的解码器,输入三维的编码,输出一个28x28的图像数据,特别要注意最后使用的激活函数是Tanh,这个激活函数能够将最后的输出转换到-1 ~1之间,这是因为我们输入的图片已经变换到了-1~1之间了,这里的输出必须和其对应。
训练过程也比较简单,我们使用最小均方误差来作为损失函数,比较生成的图片与原始图片的每个像素点的差异。
同时我们也可以将多层感知器换成卷积神经网络,这样对图片的特征提取有着更好的效果。
class autoencoder(nn.Module):def __init__(self):super(autoencoder, self).__init__()self.encoder = nn.Sequential(nn.Conv2d(1, 16, 3, stride=3, padding=1), # b, 16, 10, 10nn.ReLU(True),nn.MaxPool2d(2, stride=2), # b, 16, 5, 5nn.Conv2d(16, 8, 3, stride=2, padding=1), # b, 8, 3, 3nn.ReLU(True),nn.MaxPool2d(2, stride=1) # b, 8, 2, 2)self.decoder = nn.Sequential(nn.ConvTranspose2d(8, 16, 3, stride=2), # b, 16, 5, 5nn.ReLU(True),nn.ConvTranspose2d(16, 8, 5, stride=3, padding=1), # b, 8, 15, 15nn.ReLU(True),nn.ConvTranspose2d(8, 1, 2, stride=2, padding=1), # b, 1, 28, 28nn.Tanh())def forward(self, x):x = self.encoder(x)x = self.decoder(x)return x
这里使用了nn.ConvTranspose2d(),这可以看作是卷积的反操作,可以在某种意义上看作是反卷积。
我们使用卷积网络得到的最后生成的图片效果会更好,具体的图片效果我就不再这里放了,可以在我们的github上看到图片的展示。
变分自动编码器(Variational Autoencoder)
变分编码器是自动编码器的升级版本,其结构跟自动编码器是类似的,也由编码器和解码器构成。
回忆一下我们在自动编码器中所做的事,我们需要输入一张图片,然后将一张图片编码之后得到一个隐含向量,这比我们随机取一个随机噪声更好,因为这包含着原图片的信息,然后我们隐含向量解码得到与原图片对应的照片。
但是这样我们其实并不能任意生成图片,因为我们没有办法自己去构造隐藏向量,我们需要通过一张图片输入编码我们才知道得到的隐含向量是什么,这时我们就可以通过变分自动编码器来解决这个问题。
其实原理特别简单,只需要在编码过程给它增加一些限制,迫使其生成的隐含向量能够粗略的遵循一个标准正态分布,这就是其与一般的自动编码器最大的不同。
这样我们生成一张新图片就很简单了,我们只需要给它一个标准正态分布的随机隐含向量,这样通过解码器就能够生成我们想要的图片,而不需要给它一张原始图片先编码。
在实际情况中,我们需要在模型的准确率上与隐含向量服从标准正态分布之间做一个权衡,所谓模型的准确率就是指解码器生成的图片与原图片的相似程度。我们可以让网络自己来做这个决定,非常简单,我们只需要将这两者都做一个loss,然后在将他们求和作为总的loss,这样网络就能够自己选择如何才能够使得这个总的loss下降。另外我们要衡量两种分布的相似程度,如何看过之前一片GAN的数学推导,你就知道会有一个东西叫KL divergence来衡量两种分布的相似程度,这里我们就是用KL divergence来表示隐含向量与标准正态分布之间差异的loss,另外一个loss仍然使用生成图片与原图片的均方误差来表示。
我们可以给出KL divergence 的公式
这里变分编码器使用了一个技巧“重新参数化”来解决KL divergence的计算问题。
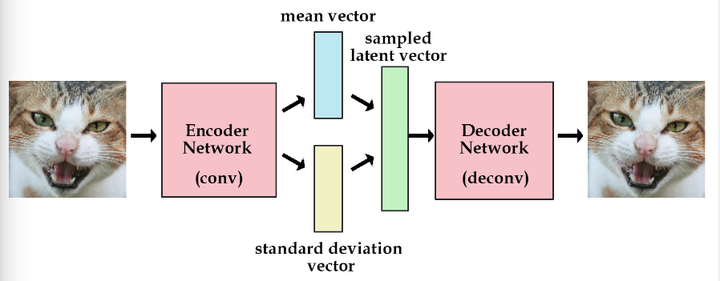
这时不再是每次产生一个隐含向量,而是生成两个向量,一个表示均值,一个表示标准差,然后通过这两个统计量来合成隐含向量,这也非常简单,用一个标准正态分布先乘上标准差再加上均值就行了,这里我们默认编码之后的隐含向量是服从一个正态分布的。这个时候我们是想让均值尽可能接近0,标准差尽可能接近1。而论文里面有详细的推导如何得到这个loss的计算公式,有兴趣的同学可以去看看推导
下面是PyTorch的实现
reconstruction_function = nn.BCELoss(size_average=False) # mse loss def loss_function(recon_x, x, mu, logvar): """ recon_x: generating images x: origin images mu: latent mean logvar: latent log variance """ BCE = reconstruction_function(recon_x, x) # loss = 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2) KLD_element = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar) KLD = torch.sum(KLD_element).mul_(-0.5) # KL divergence return BCE + KLD 另外变分编码器除了可以让我们随机生成隐含变量,还能够提高网络的泛化能力。
最后是VAE的代码实现
class VAE(nn.Module): def __init__(self): super(VAE, self).__init__() self.fc1 = nn.Linear(784, 400) self.fc21 = nn.Linear(400, 20) self.fc22 = nn.Linear(400, 20) self.fc3 = nn.Linear(20, 400) self.fc4 = nn.Linear(400, 784) def encode(self, x): h1 = F.relu(self.fc1(x)) return self.fc21(h1), self.fc22(h1) def reparametrize(self, mu, logvar): std = logvar.mul(0.5).exp_() if torch.cuda.is_available(): eps = torch.cuda.FloatTensor(std.size()).normal_() else: eps = torch.FloatTensor(std.size()).normal_() eps = Variable(eps) return eps.mul(std).add_(mu) def decode(self, z): h3 = F.relu(self.fc3(z)) return F.sigmoid(self.fc4(h3)) def forward(self, x): mu, logvar = self.encode(x) z = self.reparametrize(mu, logvar转载于:https://www.cnblogs.com/bonelee/p/9470349.html
VAE--就是AutoEncoder的编码输出服从正态分布相关推荐
- 详解变分自编码器VAE(Variational Auto-Encoder)
前言 过去虽然没有细看,但印象里一直觉得变分自编码器(Variational Auto-Encoder,VAE)是个好东西.趁着最近看概率图模型的三分钟热度,我决定也争取把 VAE 搞懂. 于是乎照样 ...
- Keras【Deep Learning With Python】Autoencoder 自编码(看不懂你打我系列!)
文章目录 1 前言 2 Autoencoder 2.1 编码器 Encoder (-PCA主成分分析一个道理) 2.2 解码器 Decoder 3 代码实现 4 讲解 6 输出结果 1 前言 本文分为 ...
- 使用K-S检验一个数列是否服从正态分布、两个数列是否服从相同的分布(转载+自己笔记)
K-S检验全称: Kolmogorov-Smirnov检验 下面内容来自[1] 假设检验的基本思想: 若对总体的某个假设是真实的,那么不利于或者不能支持这一假设的事件A在一次试验中是几乎不可能发生的. ...
- ifix如何设画面大小_如何让你的视频又小又清晰?视频编码输出软件来了
如何让视频保持清晰 同时又让其体积尽可能的小? 这是很多小伙伴们都很头疼的问题 而且很多时候我们需要会在 微信或者朋友圈等社交平台 上传我们的作品 但它们对视频大小 有着比较严格的控制 所以蜜蜂菌就为 ...
- 回归的误差服从正态分布吗_盘点10大回归类型:总有一款深得你心
全文共2507字,预计学习时长5分钟 除了统计模型和其他的一些算法,回归是机器学习成功运行的重要构成要素.回归的核心是寻找变量之间的关系,而机器学习需要根据这种关系来预测结果. 显然,任何称职的机器学 ...
- java 字符串指定编码输出_java对字符的编码处理
在java应用软件中,会有多处涉及到字符集编码,有些地方需要进行正确的设置,有些地方需要进行一定程度的处理. 1. getBytes(charset) 这是java字符串处理的一个标准函数,其作用是将 ...
- 回归的误差服从正态分布吗_10大机器学习的回归类型,你会如何选择?
全文共2507字,预计学习时长5分钟 除了统计模型和其他的一些算法,回归是机器学习成功运行的重要构成要素.回归的核心是寻找变量之间的关系,而机器学习需要根据这种关系来预测结果. 显然,任何称职的机器学 ...
- Javascript 产生随机数——服从均匀分布随机数、服从正态分布(高斯分布)随机数、服从柯西分布随机数
文章目录 1 产生服从均匀分布随机数 2 产生服从正态分布随机数 3 产生服从柯西分布随机数 1 产生服从均匀分布随机数 大家都知道Math.random是 javascript 中返回伪随机数的方法 ...
- python 服从正态分布下概率密度函数
python 服从正态分布下概率密度函数 服从正太分布下,概率密度函数公式 公式解释: f(x): 是某样本(样本以数值形式表现)为某数值时发生的概率 0<f(x)<1 x: 是随机抽样的 ...
最新文章
- liunx学习笔记(一:常用命令)
- Python创建和访问字典
- 系统更新链接服务器超时,Win10系统更新后Dr.com连接认证服务器一直超时如何解决?...
- error LNK1104: 无法打开文件“ComService.lib”
- JUC并发编程八 并发架构--ReentrantLock
- windows下mysql安装配置启动
- BZOJ 3456 城市规划 (组合计数、DP、FFT)
- (素材源代码) 猫猫学iOS 之UIDynamic重力、弹性碰撞吸附等现象牛逼Demo
- 聊聊机器翻译界的“灌水与反灌水之战”!
- 淘宝山寨IOS sdk
- DSL(Domain Specific Language)介绍
- NBear.Mapping使用教程(5):实体对象与NameValueCollection,Dicitonary以及NBear.Mapping性能
- 不能使用泛型的形参创建对象_数据类型之----泛型
- Flink CDC 系列 - 实现 MySQL 数据实时写入 Apache Doris
- 浅谈高等数学和工程数学在信号与系统中的应用
- Allegro 16.6使用说明及技巧
- 测试技术总监需要具备哪些能力
- 涠洲岛日出日落时间表_涠洲岛日出日落
- php手册经常见到,什么是“二进制安全”?
- OSS定制自定义response header
热门文章
- c语言数据结构线性表LA和LB,数据结构(C语言版)设有线性表LA(3,5,8,110)和LB(2,6,8,9,11,15,20)求新集合?...
- mongocollection java_mongodb与java的整合
- linux安装显卡驱动的run文件,Linux系统下安装NVIDIA显卡驱动(run格式文件)
- 查询qt中的数据_EXCEL在多表中查询数据(函数中引用工作表的办法)
- mysql memcached 使用场景_memcache的应用场景?
- java cxf 入口统一_分分钟带你玩转 Web Services【2】CXF
- java设计一个顺序表类的成员函数_顺序表代码讲解以及实现
- 【性能优化实战】java嵌入式开发pos
- 多层感知器(MLP)详解【基于印第安人糖尿病数据】
- python【力扣LeetCode算法题库】1111- 有效括号的嵌套深度