Generative Adversarial Networks 生成对抗网络的简单理解
1. 引言
在对抗网络中,生成模型与判别相竞争,判别模型通过学习确定样本是来自生成模型分布还是原始数据分布。生成模型可以被认为是类似于一组伪造者,试图产生假币并在没有检测的情况下使用它,而判别模型类似于警察,试图检测假币。 在这个游戏中的竞争驱动两个团队改进他们的方法,直到假冒与真正的物品难以分别。
生成模型和判别模型对抗的结果是,两者都提升了自己的能力。生成模型提高了模拟原始数据分布的能力,判别模型提高了分辨的能力。
GAN之所以叫生成对抗网络,是因为判别模型和生成模型都是用的神经网络模型,如果选择其他模型的话,可能就要叫GAXX了
2. 生成模型
2.1 GAN是生成模型的一种

“生成模型”表示任何一种可以接受训练集(从一个分布p_{data}pdata 采样的样本)学会表示该分布的估计的模型。其结果是一个概率分布p_{model}pmodel。有些时候,模型会显式地估计p_{model}pmodel,比如说图上半部分所示。还有些时候,模型只能从 p_{model}pmodel 中生成样本,比如说图下半部分。有些模型能够同时这两件事情。虽说 GANs 经过设计可以做到这两点,我们这里把精力放在 GANs 样本生成上。
- 作者虽然说GANs可以都做,但是现在的应用一般都是在样本生成上
- 关于判别模型和生成模型的区别,请参考《统计学习方法》第17-18页
2.2 GAN与其他生成模型的对比

上图是作者将要与GAN比较的集中生成模型
GANs是针对其他生成式模型的缺点进行设计的:
作者原话:GANs were designed to avoid many disadvantages associated with other generative models,相当直白,毫不客气
- 相对于FVBN,可以并行生成样本,而不是随 x 的维度变化的运行时间。
- 相对于玻尔茨曼机,生成器函数的设计只有很少的限制。在玻尔茨曼机中,只有很少概率分布能够给出易解的 Markov chain 采样。而非线性ICA中生成器必须是可逆的而且隐含编码 z 必须要和样本 x 有着同样的维度。
- 相对于玻尔茨曼机和GSNs,不需要 Markov chain。
- 不需要有变分界,在 GANs 框架中可用的特定模型族已经证实是通用近似子,所以 GANs 其实是渐进一致的。某些 VAEs 被猜想是渐进一致的,但还没有被证实。
- 主观上判断 GANs 能够产生比其他方法更好的样本。(仅仅是主观,ian 本人也说,这事儿没法衡量什么是「好」或「不好」)
- 同时,GANs 也有新的缺点,训练 GANs 需要找到博弈的 Nash 均衡,这个其实是一个比优化目标函数更加困难的问题。
3. 生成对抗网络
GANs 的基本思想是设置两个参与人的博弈。其中一个是生成器(generator)。生成器的目的产生来自和训练样本一样的分布的样本(制作跟真币一样的假币)。另外一个判别器(discriminator)。判别器检查这些样本来确定他们是真实的还是伪造的(识别真币和假币)。判别器使用传统的监督学习技术进行训练,将输入分成两类(真实的或者伪造的)。生成器训练的目标就是欺骗判别器。

博弈中的两个参与人由两个函数表示,每个都是关于输入和参数可微分的。判别器是一个以 x (真实数据)作为输入和使用 \theta^{(D)}θ(D) 为参数的函数DD 定义。生成器由一个以 z(噪音数据即假数据) 为输入使用\theta^{(G)}θ(G) 为参数的函数 GG 定义。
双方的 cost functioncostfunction都有双方定义的参数。判别器希望仅控制住 \theta^{(D)}θ(D) 情形下最小化 J^{(D)}(\theta^{(D)}, \theta^{(G)})J(D)(θ(D),θ(G))。生成器希望在仅控制 \theta^{(D)}θ(D) 情形下最小化 J^{(G)}(\theta^{(D)}, \theta^{(G)})J(G)(θ(D),θ(G))。因为每个人的cost functioncostfunction都依赖于另一个人的参数,但是每个人都不能控制别人的参数,这个场景其实更为接近一个博弈而非优化问题。优化问题的解是一个局部最小,而一个博弈的解是一个纳什均衡。在这样的设定下,Nash 均衡是一个元组,(\theta^{(D)}, \theta^{(G)})(θ(D),θ(G)) 既是关于 \theta^{(D)}θ(D)的 J^{(D)}J(D) 的局部最小值和也是关于\theta^{(G)}θ(G)的 J^{(G)}J(G) 局部最小值。
3.1 生成模型
生成器是一个可微分函数GG。当zz 从某个简单的先验分布中采样出来时,G(z)G(z) 产生一个从 p<em>{model}</em>p<em>model</em> 中的样本 xx。一般来说,深度神经网络可以用来表示 GG。注意函数 GG 的输入不需要和深度神经网络的第一层的输入相同;输入可能放在网络的任何地方。例如,我们可以将zz 划分成两个向量 z(1)z(1) 和 z(2)z(2),然后让 z(1)z(1) 作为神经网络的第一层的输入,将 z(2)z(2) 作为神经网络的最后一层的输入。如果 z(2)z(2) 是 Gaussian,这就使得 xx 成为z(1)z(1) 条件高斯。另外一个流行的策略是将噪声加到或者乘到隐含层或者将噪声拼接到神经网络的隐含层上。总之,我们看到其实对于生成式网络只有很少的限制。如果我们希望 pp{model} 是 xx 空间的支集(support),我们需要 z 的维度需要至少和 xx的维度一样大,而且 GG 必须是可微分的,但是这些其实就是仅有的要求了。特别地,注意到使用非线性 ICA 方法的任何模型都可以成为一个 GAN 生成器网络。GANs 和变分自编码器的关系更加复杂一点;一方面 GAN 框架可以训练一些 VAE 不能的训练模型,反之亦然,但是两个框架也有很大的重合部分。 最为显著的差异是,如果采用标准的反向传播,VAEs 不能在生成器输入有离散变量,而 GANs 不能够在生成器的输出层有离散变量。
3.2 训练过程

训练过程包含同时随机梯度下降 simultaneous SGD。在每一步,会采样两个 minibatch:一个来自数据集的xx 的 minibatch 和一个从隐含变量的模型先验采样的zz的 minibatch。然后两个梯度步骤同时进行:一个更新 来降低 J(D),另一个更新 θ^(G) 来降低 J(G)。这两个步骤都可以使用你选择的基于梯度的优化算法。 Adam (Kingmaand Ba, 2014) 通常是一个好的选择。
很多作者推荐其中某个参与人运行更多步骤(包括14年的文章上,算法过程在上图),但是在 2016 年的年末,观点是最好的机制就是同时梯度下降,每个参与人都是一步。
下面这张图可能更加容易理解训练过程
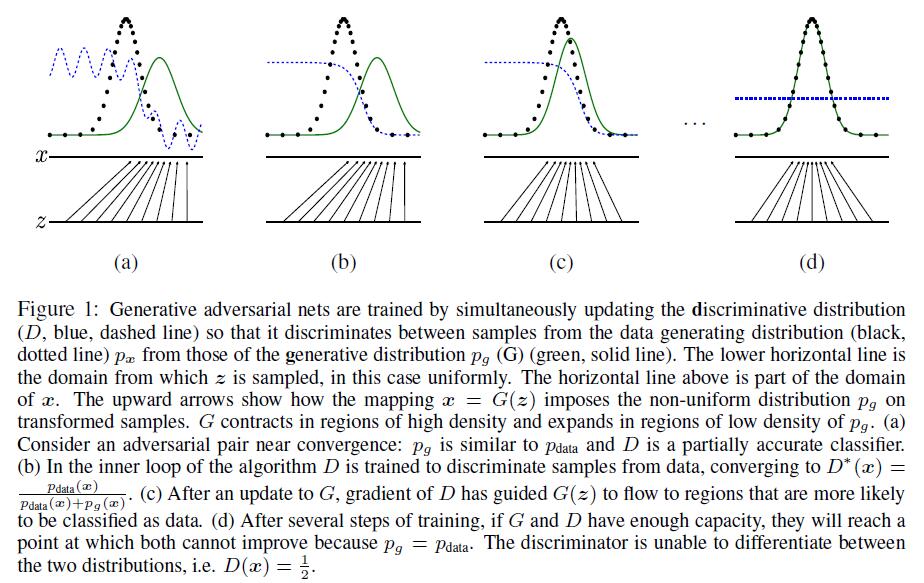
训练对抗的生成网络时,同时更新判别分布(D,蓝色虚线)使D能区分数据生成分布px(黑色虚线)中的样本和生成分布 p_g (G,绿色实线) 中的样本。下面的水平线为均匀采样z的区域,上面的水平线为x的部分区域。朝上的箭头显示映射x=G(z)如何将非均匀分布p_g作用在转换后的样本上。G在pg高密度区域收缩,且在pg的低密度区域扩散。(a)考虑一个接近收敛的对抗的模型对:p_g与p{data}相似,且D是个部分准确的分类器。(b)算法的内循环中,训练D来判别数据中的样本,收敛到:D^∗(x)={p{data}(x)} \over {p{data}(x)+pg(x)}。(c)在G的1次更新后,D的梯度引导G(z)流向更可能分类为数据的区域。(d)训练若干步后,如果G和D性能足够,它们接近某个稳定点并都无法继续提高性能,因为此时p_g=p{data}。判别器将无法区分训练数据分布和生成数据分布,即D(x)=1 \over 2。
3.3 cost function
目前为 GANs 设计的所有不同的博弈针对判别器 J(D) 使用了同样的代价函数。他们仅仅是生成器 J(G) 的代价函数不同。
3.3.1 判别模型 cost function

其实就是标准的训练一个 sigmoid 输出的标准的二分类器交叉熵代价。唯一的不同就是分类器在两个 minibatch 的数据上进行训练;一个来自数据集(其中的标签均是 1),另一个来自生成器(其标签均是 0)。
GAN 博弈的所有版本都期望判别器能够最小化(8)式。所有情况下,判别器有同样最优策略。
3.3.2生成模型 cost function
- Minimax
最简单的博弈版本是零和博弈,其中所有参与人的代价总是 0。在这个版本的博弈中

- 启发式,非饱和博弈
在 minimax 博弈中用在生成器上的代价对理论分析很有用但是在实践中表现很糟糕。
最小化目标类和分类器预测的分布的交叉熵是很高效的,因为代价不会在分类器有错误的输出的时候饱和。最终代价会饱和到\theta,但是仅仅是在分类器选择了正确的类标的情况下。
在 minimax 博弈中,判别器最小化交叉熵,但是生成器是最大化同一个交叉熵。这对于生成器是不利的,因为判别器成功地以高置信度反对生成器产生的样本时,生成器的梯度会消失。
为了解决这个问题,一种方式是继续使用交叉熵来最小化生成器。不过我们不是去改变判别器代价函数的正负号来获得生成器的代价。我们是将用来构造交叉熵代价的目标的正负号。所以,生成器的代价函数就是:

-最大似然博弈
我们可能能够使用 GANs 进行最大似然学习,这就意味着可以最小化数据和模型之间的 KL 散度

有很多中方式能够使用 GAN 框架来近似(4)式:

上述不同损失函数的比较:

3.4 缺点
最大的缺点就是训练困难,导致无法收敛和模式崩溃


现在 GAN 面临的最大问题就是不稳定,很多情况下都无法收敛(non-convergence)。原因是我们使用的优化方法很容易只找到一个局部最优点,而不是全局最优点。或者,有些算法根本就没法收敛。
模式崩溃(mode collapse)就是一种无法收敛的情况,这在 Ian 2014 年的首篇论文中就被提及了。比如,对于一个最小最大博弈的问题,我们把最小(min)还是最大(max)放在内循环?minmax V(G,D) 不等于 maxmin V(G,D)。如果 maxD 放在内圈,算法可以收敛到应该有的位置,如果 minG 放在内圈,算法就会一股脑地扑向其中一个聚集区,而不会看到全局分布
不过值得庆幸的是,现在已经有算法解决这些问题,这也是2016年GAN才火的一个原因吧
4. 后续发展
github上有人总结的GAN的文章:AdversarialNetsPapers
5. 参考
Generative Adversarial Nets
NIPS 2016 Tutorial: Generative Adversarial Networks
GAN之父NIPS 2016演讲现场直击:全方位解读生成对抗网络的原理及未来
原文地址: http://www.datalearner.com/blog/1051488206986609
Generative Adversarial Networks 生成对抗网络的简单理解相关推荐
- Generative Adversarial Nets 生成对抗网络
Generative Adversarial Nets 生成对抗网络 论文作者 Yan 跟随论文精读 (bilibili李沐) 同时会训练模型 G,生成模型要对整个数据的分布进行建模,就是想生成 尽量 ...
- GAN(Generative Adversarial Nets (生成对抗网络))
一.GAN 1.应用 GAN的应用十分广泛,如图像生成.图像转换.风格迁移.图像修复等等. 2.简介 生成式对抗网络是近年来复杂分布上无监督学习最具前景的方法之一.模型通过框架中(至少)两个模块:生成 ...
- 【GAN ZOO阅读】Generative Adversarial Nets 生成对抗网络 原文翻译 by zk
Ian J. Goodfellow, Jean Pouget-Abadie ∗ , Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair † ...
- 【深度学习】Generative Adversarial Network 生成式对抗网络(GAN)
文章目录 一.神经网络作为生成器 1.1 什么是生成器? 1.2 为什么需要输出一个分布? 1.3 什么时候需要生成器? 二.Generative Adversarial Network 生成式对抗网 ...
- [深度学习-原理]GAN(生成对抗网络)的简单介绍
系列文章目录 深度学习GAN(一)之简单介绍 深度学习GAN(二)之DCGAN基于CIFAR10数据集的例子 深度学习GAN(三)之DCGAN基于手写体Mnist数据集的例子 深度学习GAN(四)之c ...
- 生成对抗网络(GAN)简单梳理
作者:xg123321123 - 时光杂货店 出处:http://blog.csdn.net/xg123321123/article/details/78034859 声明:版权所有,转载请联系作者并 ...
- GAIL生成对抗模仿学习的简单理解
文章目录 强化学习 模仿学习 模仿学习的三种方法 行为克隆 逆向强化学习 GAIL生成对抗模仿学习 强化学习 强化学习需要一个合适的reward函数去求解最优行动策略,但很多情况下不容易设以一个足够全 ...
- GAN生成对抗网络基本概念及基于mnist数据集的代码实现
本文主要总结了GAN(Generative Adversarial Networks) 生成对抗网络的基本原理并通过mnist数据集展示GAN网络的应用. GAN网络是由两个目标相对立的网络构成的,在 ...
- 自动驾驶轨迹预测论文阅读(三)Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks
[略读]GUPTA A, JOHNSON J, FEI-FEI L, et al., 2018. Social GAN: Socially Acceptable Trajectories with G ...
最新文章
- 那些人工智能未来式,没看过你就 OUT 了
- MobileIMSDK连接后频繁掉线重连,提示会话超时失效,对方非正常退出或网络故障
- java数据源是什么_《java数据源—连接池》
- 简述php语言的特点是_PHP语言有哪些优势和特点(一)
- js 取得input绑定的datalist中的值_原生JS写一个ToDo Demo
- Python 对字典循环遍历的两种方式
- SheetJS 读取excel文件转出json
- c语言include iostream,求助,虚拟机上#includeiostream一直报错
- STM32F030 定时器
- 华为马海旭:+智能,IoT行业云服务使能产业物联网
- ApacheCN 翻译活动进度公告 2019.5.17
- 传递组播与广播帧:数据待传指示传递信息(DTIM)
- shader篇-处理复杂光照
- pip install -t的意思
- 公司被告,晋升受阻,为刷考评互拆台...这届FB员工太难了
- 什么浏览器好用稳定速度快?
- 2.3 基于FPGA的UART协议实现(一)串口信号定义和接线方法-5针串口-9针串口-全功能串口
- Malware Dev 01 - 免杀之 PPID Spoofing 原理解析
- 阿里云DDNS动态绑定域名与IP实现远程调试远程办公
- 【持续更新】[2017-4-26]红米NOTE3双网全网-信号居左-时间居中-IOS状态栏-集合贴